
基于单张量辐射场的数字服装重照明方法
2025-01-01 00:00:00陈鑫磊郑军红金耀何利力
丝绸 2025年1期












摘要:针对现有基于三维表面重建的图像重照明方法存在纹理噪点、重照明质量不足及特征空间利用率低等问题,文章提出一种基于单张量辐射场的数字服装重照明方法。该方法首先利用球面高斯函数和多层感知机,分别模拟环境直射光和服装表面间的间接反射光,以构建一个精准的入射光场;接着通过引入梯度引导平滑策略,优化从特征空间中提取双向反射分布函数模型参数的过程。最后,利用简化的反射率方程,结合入射光场、双向反射分布模型及特征空间,成功地渲染出高质量的服装重照明图像。实验结果表明,该方法有效地减少了服装纹理噪点,显著降低了服装重照明的失真现象。相较于先进方法,该方法在生成服装新视角图像方面,各项评估指标的平均提升约9.922%;在服装重照明结果方面,各项评估指标的平均提升约4.549%。
关键词:单张量辐射场;特征空间;服装重照明;3D维重建;图像生成;双向反射分布函数
中图分类号:TS101.8
文献标志码:A
文章编号:10017003(2025)01008509
DOI:10.3969 j.issn.1001-7003.2025.01.010
基金项目:浙江省“尖兵” “领雁”研发攻关计划项目(2023C01224);浙江省科技计划重大科创平台项目(2024SJCZX0026)
作者简介:陈鑫磊(1999),男,硕士研究生,研究方向为智能数字化服装处理。通信作者:郑军红,讲师,博士,zjhist@zstu.edu.cn。
服装作为时尚元素的核心载体,不仅反映了时尚的潮流,更展示了人们对于个性和自我表达的内在渴望。随着生活品质的提升,人们对于穿着美感的要求日益精细。如在试穿服装前,人们往往需要了解服装在各种不同场合和光照条件下的呈现效果,并能从不同视角进行审视,以便作出更全面的评估。因此,如何让用户便捷且真实地预览服装在各种光照下的外观,即数字服装的重照明(relighting)[1-2]效果展示,是一个重要课题。传统的图像重照明方法[3-4]主要聚焦于对二维图像的处理。如文献[3]利用采样网络从输入图像中合成场景外观,并通过深层的重照明卷积神经网络对输入光照和图像进行编解码,从而得出原始图像的重照明效果。而文献[4]则采用输入的RGB与深度图像,通过解码网络获取物体的反照率、法向图等物理特性,再利用神经网络对物体表面的双向反射分布函数(BRDF)进行建模,最后经过合成网络得出重照明的结果。然而,这些传统方法在处理多视角的重照明任务时,由于其输入的二维图像缺乏三维信息,一般难以达到理想的效果。为克服这一局限,引入包含三维信息的网络模型显得尤为重要,而神经辐射场(Nerf)[5]相关技术则较好地满足这一需求。它利用一系列由同步相机拍摄的目标物体或场景图像来构建辐射场,并采用多层感知机(MLP)、体素网格[6-7]、多张量场[8]等方式来表示目标对象或场景,将刚体视为空间中相互遮挡的光源(即发射和吸收光的粒子),从而对整个空间进行优化。此外,张量辐射场[9](TensoRF)作为一种基于多张量场表示的辐射场模型,通过张量分解算法将高维张量分解为多个低维张量,不仅显著提升了模型的收敛速度,还能在其构建的场景特征空间中更准确地解码出目标对象的纹理、深度、法向量等特征。
近年来,众多研究以神经辐射场模型为基石,结合先进的神经网络和光照模型,实现了对简单场景进行多视角重照明的任务。Srinivasan等[10]就做了反射率方程与Nerf模型相结合的工作,其打破了闪光灯假设,并优化了环境照明建模:它考虑了单反射间接照明,并引入了可见度的概念来表示能够反射光的能量粒子的比例,从而提高了反射率方程的灵活性。Zhang等[11]采用两阶段策略,解耦了Nerf中的几何建模和颜色渲染:首先利用Nerf重建目标对象或场景的几何体,然后使用多个多层感知机来回归BRDF结果和重照明结果。此外,文献 [12-13]等方法更进一步地利用了球面高斯,这种更接近真实物理世界的球面逼近方式。通过将环境贴图数据映射到球面,这些方法更好地捕捉了环境中的光照和反射特性。然而,目前的研究主要应用于无边界的大场景或一些具有高光弧面的刚性物体,如头骨、玻璃球等。当其应用于三维服装数据时,会面临一些问题:首先是纹理噪点问题。由于服装表面通常带有复杂的纹理,使用Nerf作为基础的特征空间构建模型往往无法精确地从图像中提取服装的纹理信息,从而导致重照明结果中纹理的缺失。其次是重照明失真问题。服装作为柔性物体,与刚性物体在光照模型的适配上存在差异。直接使用多个球面高斯或神经网络来建立准确的光照模型是比较困难的,因而现有的光场模型容易导致服装重照明结果的光照亮度失真。
为了解决上述问题,本文提出了一种基于特征空间的服装重照明方法。针对重照明结果纹理失真问题,本文改进了文献[9]中的张量辐射场模型,并利用其构建数字服装的特征空间。这提升了特征空间从图像中获取纹理特征的能力,并有效地减少了纹理噪点。同时,为解决重照明失真问题,本文构建了一个更适合服装模型的入射光场。此外,在BRDF模型的训练过程中,本文引入了梯度引导平滑项,从而能够回归出更加准确的服装表面粗糙度和反照率。这使得本文的模型能够渲染出更加接近真实样本的重照明结果。
1 服装重照明方法
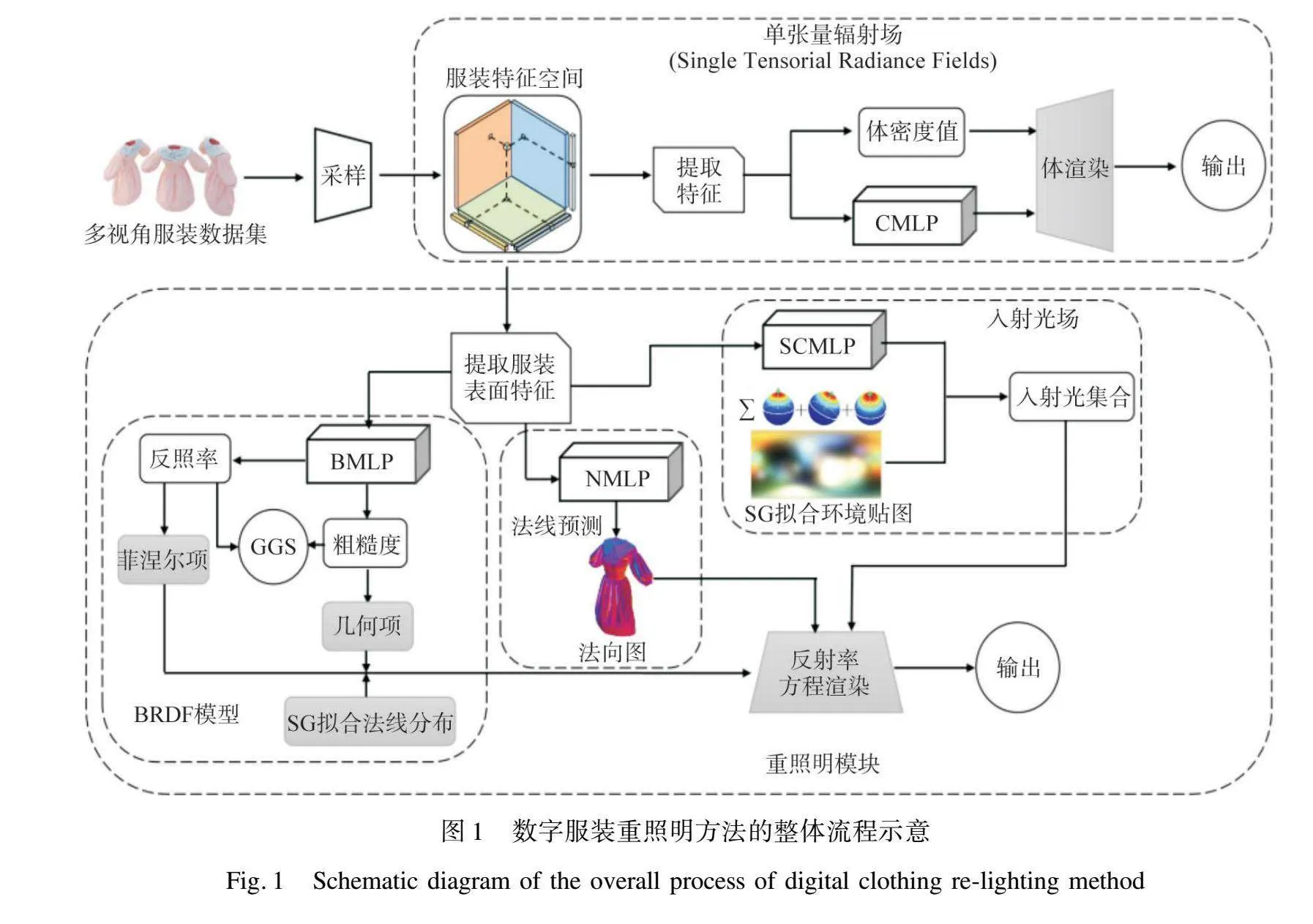
本文所构建的服装重照明方法通过反射率渲染方程进行计算,其输入由三个核心部分组成,即服装表面几何、环境光照信息及服装材质特性。各个部分的计算模型概述如下:
首先,需要提取服装表面的几何信息,该信息可以通过重建服装表面法线获取。为此,本文将服装表面的特征数据输入到法线解码网络(NMLP)中,以精确提取出服装表面的法向场。其次,为模拟真实的环境光照,本文构建了一个多因素入射光场模型,融合了球面高斯、间接光照及直射光、间接光的接收率,从而能够高度逼真地再现真实环境中的复杂光照条件。最后,为刻画服装的材质特性,本文对双向反射分布函数(BRDF)的参数进行估计,嵌入了一个参数解码网络(BMLP),它能够从服装的表面特征中精确地提取出反照率、粗糙度等关键的BRDF参数。此外,本文还引入了梯度引导平滑项(GGS),以进一步约束和优化BRDF参数的回归过程。
重照明方法的输入包括不同的相机视角、相应相机视角下的法向图、无背景的服装图像、含背景的服装图像,以及相应背景的环境贴图。单张量辐射场模块输出无背景的服装图像像素颜色值,重照明模块则输出含背景的服装图像像素颜色值。整个重照明方法的流程如图1所示,其中包含四个神经网络,分别为CMLP、SCMLP、BMLP、NMLP的四个4×128的多层感知机(MLP)。在后续的研究中,本文将详细阐述服装重照明方法的具体实现细节,以展现其完整的技术框架与流程。
1.1 单张量辐射场
本文在重照明方法中,首先对文献[9]的模型进行优化,构建了一个能够更加准确地提取重照明模型参数的单张量辐射场。
原模型[9]采用体密度张量场和颜色张量场分别存储三维场景的体密度和颜色特征,并使用了VM张量分解技术,在快速重建三维场景的同时保证了场景的细节质量。然而,要在其基础上添加重照明模块,则需要额外使用一个BRDF参数特征张量场。这种做法相当于完全解耦了三维场景的几何、外观与材质信息,从而丢失了场景属性之间的潜在关联。因此,假如直接使用这个方法作为重照明方法基础模型,虽然在模型训练速度上会有所提升,但重照明质量并不优于使用传统Nerf作为基础模型的重照明方法。本文将服装模型的体密度、颜色和BRDF参数特征融合为混合特征,并统一存储于单个张量场中。这一改进不仅进一步加速了模型的收敛速度,同时也提升了重照明结果的质量。本文在下文的消融实验也展示了使用单张量与多张量在重照明结果质量上的区别。
设服装模型的某个表面点坐标为X(x,y,z),则该点处的服装表面特征F就可表示为G(X)。F具体表达式为:
F=∑Rr=1vXr(x)MYZr(y,z)bXr(x)+vYr(y)
MXZr(x,z)bYr(y)+vZr(z)MXYr(x,y)bZr(z)(1)
式中:R是设定的张量分解量,在实验中设为16;vXr、 MYZr分别代表第r个对应X、 Y和Z坐标轴上的特征分量权重向量和矩阵因子;服装模型在表面点X处的特征向量即为48个分量特征的总和。
本文将特征向量的第一个元素定义为表面点的体密度特征值,记为F[0];而剩余的元素则构成服装的特征向量,记为F(1,l),其中l表示服装特征向量长度,实验中设为28。
单张量辐射场通过相机视角及其相应视角下的无背景服装图片进行训练。其目标函数为:
lossst=C(ray)-Cgt22(2)
式中:C(ray)为文献[5]中的体渲染公式计算出的像素颜色值,Cgt则是真实的像素颜色值。
通过逐像素最小化该目标函数,可以优化式(1)中每个张量分解量的特征分量权重向量和矩阵因子,最终得到一个包含体密度值和服装颜色特征的服装特征空间。详细的张量辐射场训练流程可以参考文献 [9]。
单张量辐射场首先会进行20 000次迭代,以获得一个基本的服装特征空间。需要注意的是,此时特征空间内的特征仅包含服装的外观特征,只能解码出服装的颜色值和体密度值。随后,重照明模块将进一步训练该特征空间,使其中的特征转化为混合特征。
1.2 法向预测网络
表面法向场是指垂直于给定表面上每个点的矢量。这些信息被存储在法向图中,使得在渲染时能够模拟出更加逼真的细节。在法向图中,每个像素的颜色值对应于表面在该点的法线方向。具体讲,法向图利用RGB颜色空间表示法向在空间坐标轴上的各个分量。
将前文提及的服装特征向量F(1,l)输入到法线解码网络(NMLP)中进行解码,从而获取服装表面的法向量。这一过程可以用下式来表示:
n=NMLP(F(1,l))(3)
对于每一个观察视角,该模块都可以生成相应的服装表面法向图。这些贴图将作为后续渲染方程中的几何信息输入,为渲染过程提供关键数据。
该模块需要数据集中某视角下的真实法向图进行训练,.输入为服装表面点处的特征向量F(1,l),输出为处的法线向量预测值,其目标函数为:
lossn=n-ngt22(4)
式中:n为式(2)中由NMLP解码得到的表面法向预测值;ngt真实法向值,通过对法向图逐像素最小化该目标函数,可以优化NMLP中的神经元权重。
1.3 多因素入射光场构建
本文在前文所述的单张量辐射场基础上,构建了一个多因素入射光场模型。该模型的主要目的是为反射率渲染方程提供可靠的环境光输入信息。
先前的重照明方法,如文献[12]和文献[13],在考虑服装表面某一微分点(即在某视角下服装图像的一个像素点)的入射光时,通常考虑环境直射光及物体之间的反射光(即默认存在多个物体,能够互相反射光线[14])。这种方法在重照明多物体场景时能够提供更加准确的效果,但往往以高昂的计算量为代价。
本文的重照明方法则针对单一服装的重照明。鉴于大多数常见的服装材质(如棉、聚酯纤维等)反光特性较弱,因而仅考虑服装自身表面点之间的间接反射光。为了减少计算量,仅使用一个多层感知机来近似计算该值。此外,本文的方法还额外增加了直射光和间接光接收率,以增加入射光场的灵活性,从而减少简化间接反射光计算所带来的重照明失真问题。
综上所述,入射光场将包含三个关键因素:首先是来自服装所处环境的直射光;其次是从服装其他表面点间接反射到该点的光线;最后是该点对直射光及间接光的接收率。
入射光场的示意如图2所示。图中,虚线箭头部分代表间接反射光,其充分考虑了从服装的其他表面点反射到目标点的光线。而服装表面点的最终颜色值,则是由间接反射光和直接光照(实线箭头部分)共同决定。使得本文的入射光场更加贴近现实情况,从而能够生成更为逼真的重照明图像结果。
由于服装表面间接反射光的精确计算颇具挑战,本文采用一种近似方法。将前文所述的服装特征向量输入间接光解码网络(SCMLP)中,通过解码得到的服装表面基色近似模拟服装表面的间接反射光。这一过程可以用下式来表示:
Lind(X,ωi)=SCMLP(F(1,l))(5)
某视角下的间接反射光可视化效果如图3(c)所示。
本文采用128个球面高斯函数对环境中的直射光进行拟合,并将此拟合结果记为:
Ld(ωi)=∑128k=1SG(ωi;ξk,λk,μk)(6)
式中:ωi表示用户输入的视角方向,而球面高斯函数的参数则包括振幅ξk、标准差λk和中心位置μk。这些参数共同决定了光照的强度和分布。
通过球面高斯拟合出的环境光效果如图3(b)所示。
直射光及间接光接收率实际上是一个权重值,以提升入射光场的灵活性。本文利用文献[5]中体渲染公式的不透明度部分近似计算直射光接收率,该值会在每轮单张量辐射场训练时计算得出,重复使用以减少模型运算量。使用一个球面高斯近似计算间接光接收率。综合上述因素,服装模型表面的最终入射光可以表示为:
Ltol(X,ωi)=Ld(ωi)Td(X,ωi)+Lind(X,ωi)Tind(ωi)Tind(ωi) = SG(ωi;ξj,λj,μj)(7)
式中:Td(X,ωi)代表的是文献[5]中提出的不透明度计算结果,用于近似直射光接收率;Tind(ωi)表示间接光的接收率;而Ld(ωi)和Lind(X^,ωi)分别代表通过式(3)模拟的环境直射光和通过式(4)模拟的服装表面反射的间接光。
1.4 BRDF模型的参数估计与优化
基于前文构建的入射光场可以计算出服装模型上每一个微分点的入射光集合,现介绍重照明模型的双向反射分布模型(BRDF)参数估计模块。该模型可表示服装表面的材质信息,其功能主要是根据入射光集合来计算反射光的强度。
该模块主要包含一个BRDF参数解码网络(BMLP),以及用于提升网络参数回归能力的梯度引导平滑项。其中BMLP的输入为前文提到的服装表面特征,输出为服装表面点的反照率及粗糙度,这一过程记作:
[s,Rn]=BMLP(F(1,l))(8)
式中:BMLP的输出包含4个通道,其中前三个通道代表反照率(albedo),而最后一个通道则代表粗糙度(roughness);这两个参数用于输入到后续的BRDF模型公式中计算。
直接使用多层感知机拟合服装表面点的反照率及粗糙度,可能导致网络输入的特征仅有细微空间上的差异时,反照率和粗糙度结果却发生急剧的变化。为了抑制这种不合理的变化本文引入梯度引导平滑项,通过惩罚大的反照率和粗糙度梯度,鼓励生成平滑的图像。约束公式如下:ls=1Pn∑P∈Id(式中:Pn表示在某视角图片Id上所采样的像素个数;而分别代表在像素坐标XP处的反照率和粗糙度的梯度,这些梯度信息可以通过反向传播算法解析得到;另外表示法向图在点XP的梯度,这个信息可以直接从本文1.2中的法线拟合网络中获取。
式(9)启发于传统图像处理中的双边滤波平滑算法[15-16],文献[15]中使用像素灰度值梯度的负指数函数来平滑金属度梯度和粗糙度梯度,进而平滑金属度值与粗糙度值,从而使得最终渲染出重照明对象具有更加真实的金属光泽。鉴于本文方法针对的是数字服装,默认重照明对象为非金属材质,因此将BRDF中的金属度参数设定为接近0的值。此外,本文采用法向图梯度的负指数函数e-来平滑反照率梯度和粗糙度梯度。相比于图像灰度值,法向图包含了更精确的几何形状和细节信息,其梯度变化能够更准确地反映服装表面的细微变化,从而更加精确地对过大的反照率梯度和粗糙度梯度进行惩罚,进而优化反照率及粗糙度结果急剧变化的现象,使得渲染出的服装重照明图像的纹理及外观更加平滑而且真实。
在本文2.3中的消融实验也展示了使用梯度引导平滑策略前后粗糙度的可视化对比。与之前相关研究类似,本文采用简化的Disney原则[17]的BRDF模型,其公式表示为:
bf(ω0,ωi,s,Rn)=Fr(ω0,h,s)G(ωi,ω0,n,Rn)D(h)4(n·ω0)(n·ωi)(10)
式中:正态分布项D,其揭示了表面微观结构如何影响反射光线的分布;菲涅尔项Fr,其反映了光线在表面发生反射时的强度变化;几何项,其G描绘了光线与表面之间的几何关系对光照强度的影响。各项的具体实现可以参考文献[12]与文献[13]中的实现方式。
1.5 反射率渲染方程及重照明方法目标函数
结合前文所构建的入射光场和BRDF模型,再应用反射率方程,可以渲染出带有环境光属性的服装颜色值,相关公式如下:
L(X,ω0)=2πLnum∑i∈SLbf(X,ω0,ωi)Ltol(X,ωi)(n·ωi)(11)
式中:X表示服装模型表面点的三维坐标向量,ω0表示视角方向,SL表示入射光集合,Lnum表示入射光的数量。
式(11)将服装在点X处的颜色视为多道入射光在该点微平面上ω0视角下反射光的分量之和。通过结合本文前面部分提到的法线信息n、环境光照信息Ltol及表面材质信息bf,可以计算出该点的颜色。通过逐像素最小化这个计算值与真实服装表面点颜色的损失,可以优化特征空间和解码网络。在本文中,服装模型的特征空间受到反射率方程渲染损失、单张量辐射场目标函数、法线目标函数及梯度平滑项共同约束和优化。因此,总目标函数可以表示为:
ltol=λ1L(X,ω0)-Cgt22+λ2C(ray)-Cgt22+λ3n-ngt22+λ4ls(12)
式中:L(X,ω0)-Cgt22表示反射率方程渲染结果与对应点真实像素值之间的损失,即为方法重照明部分的目标函数;C(ray)-Cgt22为1.1中单张量辐射场的损失;n-ngt22为1.2中法向网络的目标函数,ls表示式(10)中梯度引导平滑项的结果;而 λ1~λ4是自定义的损失权重。
需要注意的是,在达到一定的迭代次数之前(即在获得场景曲面之前,本文实验中设置为20 000次),λ1的值被设置为零。当迭代次数达到指定值后,λ2在随后的迭代过程中会逐渐减小。
2 实验结果
2.1 实验数据集及评估指标
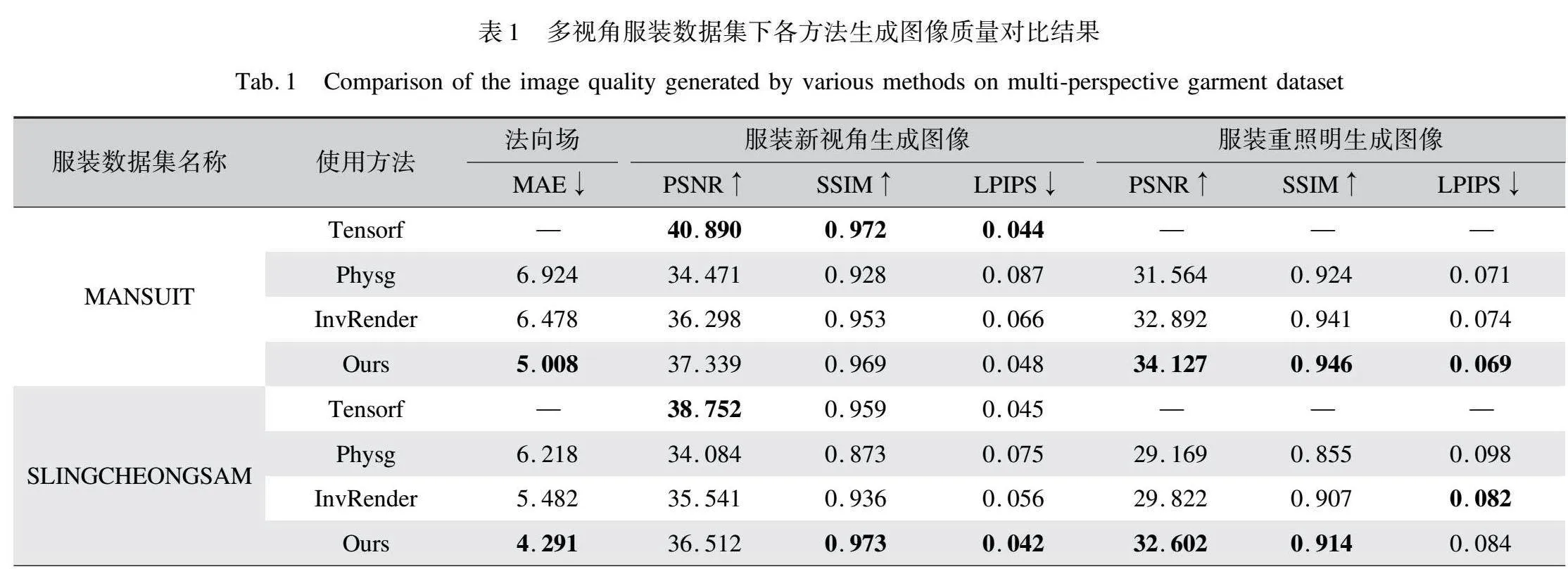
本文对三个多视角服装数据集进行了实验。针对每个数据集,本文都进行了重新渲染,以新的视角生成了图像、重照明结果和法向图。这些多视角服装数据集通过使用Blender对三个三维服装模型进行渲染生成,同时确保了相机位姿与文献[5]中提及的数据集位姿一致。在每个数据集中,本文均渲染了300个不同视角下的图像,这些图像具有各种环境照明条件,分辨率为800×800像素,并附带相应视角下的法向图。为了评估方法的性能,本文将数据集划分为训练集(包含200个样本)、测试集(70个样本)和验证集(30个样本)。本文与先进的重照明方法进行了实验结果比较,并确保在相同的相机位姿和评估指标下进行,如表1所示。
为了全面评估该方法在新视图合成和重渲染结果性能,本文采用了四种广泛认可的评估指标:
1)峰值信噪比(PSNR):通过计算信号的峰值与噪声的比值来量化图像或视频的失真程度。
2)结构相似性指数(SSIM[18]):通过比较原始图像和重建图像之间的三个关键组成部分(亮度、对比度和结构)计算。
3)感知上的图像相似性(LPIPS[19]):这是一个衡量图像之间感知相似性的指标。与PSNR和SSIM不同,LPIPS更加注重人类视觉系统对图像的感知和认知。
4)平均绝对误差(MAE):此指标用于衡量实际观测值与预测值之间的平均绝对差异程度。本文使用它来衡量方法生成的法向图的准确度,通过这些综合评估指标,能够更全面、更客观地评价方法的性能。
2.2 实验结果分析
为了验证本文所提方法的有效性,本文与文献[12]和文献[13]中介绍的两种基于三维重建表面的重照明方法进行了对比,可视化对比结果如图4所示。由图4可以明显看出,文献[12]的服装重照明结果存在较多的纹理噪点,并且环境光部分失真较为严重。这主要是因为该方法采用神经符号向量场(SDF)拟合服装表面,而SDF高度依赖于准确的法线信息。法线信息的缺失导致了服装表面重建的不准确和不平滑,进而引发重照明的失真。相比之下,文献[13]在减少纹理噪点和重照明失真方面有所改进,但服装表面仍略显不平滑。这源于其BRDF参数拟合得不够精确,从而影响反射率方程渲染结果的准确性。
而本文所提出的方法,得益于张量辐射场出色的表面重建能力及梯度平滑策略的有效性,不仅几乎消除了纹理噪点,还能准确渲染出更接近真实样本的不同环境光下的服装图像。结合图4和表1可以看出,无论是服装纹理细节还是整体光照准确度,本文方法都明显优于前两种方法。
为了更定量地评估不同方法生成的服装重照明结果质量,以及本文增加的重照明模块对原辐射场方法特征空间的影响,本文展示了服装几何表面法线估计、新视角合成,以及重新照明的定量比较结果(表1)。与最先进的基于隐式表面重建的重照明技术相比,本文方法在服装数据集中的表面法线生成质量提升了约20.600%,这得益于张量辐射场对场景几何表面的精确构建。同时,服装重照明图像质量也提升了约9.922%,这主要归功于梯度引导平滑策略使神经网络能够拟合出更准确平滑的BRDF参数,结合更准确的法线生成,从而渲染出更真实的重照明图像。尽管本文将服装表面颜色特征、体密度特征及物理属性特征整合在同一个特征空间中,可能在一定程度上干扰了原方法的外观特征,导致服装新视角生成图像的质量相较于文献[9]中的方法略有降低,但与可重照明的方法相比,本文方法在新视角生成图像的质量上仍提升了约4.549%。
2.3 消融实验
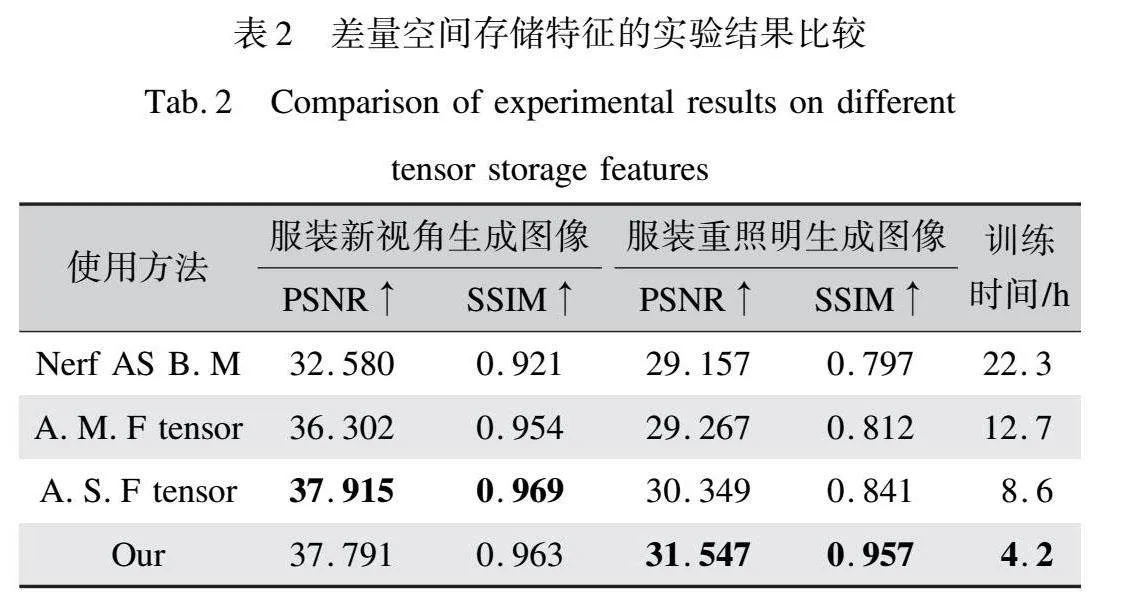
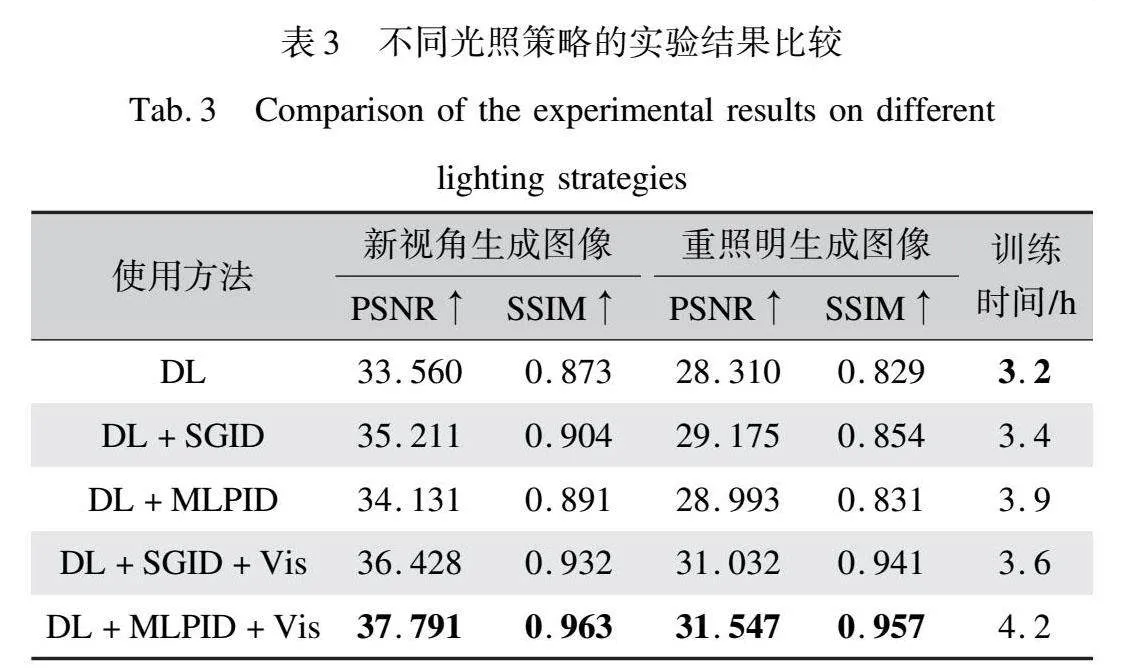
为了进一步验证本文方法的有效性,本文在PRINCESSDRESS数据集上开展了消融实验。该数据集为一件带有复杂纹理的公主裙的多视角数据集,其数据集结构与2.1中提到的结构一致,共300个根据相机视角划分的文件夹,每个文件夹中包含相应视角下的服装无背景图像、含背景图像、法向图与对应相机位姿数据,其由三维公主裙服装模型通过Blender渲染生成,由于其领口带有较为复杂的纹理结构,且裙摆和袖口带有大量褶皱,对其进行重照明更有难度,因而使用不同方法渲染出的结果差异性较大,所以选择该数据集进行重照明消融实验。这些实验旨在探究本文提出的梯度引导平滑策略及使用不同特征空间存储服装特征对实验结果的影响,相关实验结果如表2、表3所示。
由表2可以看出,采用额外多个特征空间来存储服装特征(即服装由密度特征空间、颜色特征空间和BRDF参数特征空间共同建模,记作A.M.F tensor)并未能提高服装图像的生成质量,反而增加了训练时间。而使用额外单个特征空间存储服装特征(即服装由体密度特征空间和外观特征空间建模,记作A.S.F tensor)虽然可以略微提升服装新视角的生成质量,但提升幅度非常有限,仅为0.476%,且这种提升是以模型训练时间增加近一倍为代价的。
相比之下,本文所采用的方法更为高效和有效。本文仅使用单个特征空间来存储服装特征,并通过多个MLP解码得到用于渲染公式的参数。这种方法不仅缩短了模型的训练时间,而且使服装重照明生成图像的质量相较于另外两种方法提升了近9.922%。这一显著提升的原因在于服装模型的体密度特征、颜色特征和BRDF参数特征之间存在潜在的相关性。通过避免解耦这些特征空间,本文方法能够更好地学习到这种潜在的相关性,从而提升服装图像的渲染质量。此外,表2还加入了以Nerf作为基础模型(Nerf AS B.M)的实验结果。结果显示,直接使用多张量辐射场进行重照明虽然在训练速度上有所提升,但重照明结果的质量与以NeRF作为基础模型的结果相差不大。因此,本文对张量辐射场的改进是有效的。
表3展示了使用不同方法进行服装图像渲染的实验结果对比,包括纯球面高斯直射光(DL)、直射光结合高斯拟合间接光(DL+SGID)、直射光结合多层感知机拟合间接光(DL+MLPID)、直射光加高斯拟合间接光再结合直射光接受率(DL+SGID+Vis),以及直射光加多层感知机拟合间接光再结合直射光与间接光接收率(DL+MLPID+Vis)。实验结果显示,采用直射光与间接光相结合,并辅以直射光接收率的入射光场策略,在服装图像渲染上取得了显著效果。相较于不使用直射光接收率及不使用间接光的方法,图像生成质量分别提升了9.948%和12.206%。在间接光的处理方式上,虽然在不加入直射光接收率的情况下,使用多层感知机(MLP)拟合间接光相较于球面高斯拟合方法下降了3.1614%,但在结合了直射光接收率后,MLP方法的图像质量反而提升了4.082%。
这些实验结果清晰地表明,间接反射光直射光接收率对于增强入射光场模拟的真实性至关重要。同时,MLP网络在使用直射光接收率的条件下能更有效地模拟和渲染复杂的间接光效果。
由表4可知,使用不同方法进行服装图像渲染的实验结果对比,包括梯度下降(GD)、梯度下降结合相对平滑损失项(GD+RSL),以及梯度下降结合本文提出的梯度引导平滑项(GD+GGS)。实验结果显示,相较于传统的相对平滑损失方法,本文的梯度引导平滑策略在服装新视角生成图像质量上提升了约4.583%,在服装重照明图像生成质量上提升了约6.096%。
本文对比了使用相对平滑损失和本文方法回归服装粗糙度的差异,如图5所示。由图5可以清晰地看到,本文方法回归出的粗糙度比传统方法更为平滑,且避免了将服装的纹理细节错误地训练到粗糙度中。这一点在服装衣领部分的粗糙度上尤为明显,因为服装纹理本应由服装模型表面颜色决定,此部分的粗糙度不应产生突变。本研究引入的平滑策略有效改善了这一现象,进一步验证了本文方法的有效性。
3 结 论
本文提出了一种基于单张量辐射场的三维数字服装重照明方法。该方法基于单张量辐射场方法,在其重建的特征空间基础之上增加了重照明模块。该方法结合了法线预测网络、多因素的入射光场、遵循Disney准则的BRDF模型及简化的反射率方程,使其能够实现任意视角下的服装重照明。
实验结果显示,本文的服装重照明方法有效利用了单张量辐射场的特征空间,显著提高了运行效率。同时,通过引 入梯度平滑损失策略,BRDF参数的提取准确度也得到了显著提升。这一方法不仅有效解决了服装数据集中常见的纹理噪点问题,还提升了重照明的精确度。与当前先进方法相比,本文的方法在生成服装新视角图像的各项评估指标上平均提升了约9.922%,在服装重照明结果的评估指标上更是取得了平均约4.549%的显著提升,从而验证了本文方法的有效性。
参考文献:
[1]HABER T, FUCHS C, BEKAER P, et al. Relighting objects from image collections[C]" 2009 IEEE Conference on Computer Vision and Pattern Recognition. Miami Florida: IEEE, 2009.
[2]CHEN Z, CHEN A P, ZHANG G L, et al. A neural rendering framework for free-viewpoint relighting[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. Seattle: IEEE, 2020.
[3]XU Z X, SUNKAVALLI K, HADAP S, et al. Deep image-based relighting from optimal sparse samples[J]. ACM Transactions on Graphics, 2018, 37(4): 1-13.
[4]QIU D, ZENG J, KE Z H, et al. Towards geometry guided neural relighting with flash photography[C]" 2020 International Conference on 3D Vision (3DV). London: IEEE, 2020.
[5]MILDENHALL B, SRINIVASAN P P, TANCIK M, et al. Nerf: Representing scenes as neural radiance fields for view synthesis[J]. Communications of the ACM, 2021, 65(1): 99-106.
[6]SUN C, SUN M, CHEN H T. Direct voxel grid optimization: Super-fast convergence for radiance fields reconstruction[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022.
[7]YU A, LI R L, TANCIK M, et al. Plenoctrees for real-time rendering of neural radiance fields[C]" Proceedings of the IEEE CVF International Conference on Computer Vision. Montreal: IEEE, 2021.
[8]JIN H A, LIU I, XU P J, et al. Tensoir: Tensorial inverse rendering[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. Vancouver: IEEE, 2023.
[9]CHEN A P, XU Z X, GEIGER A, et al. Tensorf: Tensorial radiance fields[C]" European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
[10]SRINIVASAN P P, DENG B Y, ZHANG X M, et al. Nerv: Neural reflectance and visibility fields for relighting and view synthesis[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. Nashville: IEEE, 2021.
[11]ZHANG X M, SRINIVASAN P P, DENG B Y, et al. Nerfactor: Neural factorization of shape and reflectance under an unknown illumination[J]. ACM Transactions on Graphics, 2021, 40(6): 1-18.
[12]ZHANG K, LUAN F J, WANG Q Q, et al. Physg: Inverse rendering with spherical gaussians for physics-based material editing and relighting[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. Nashvill: IEEE, 2021.
[13]ZHANG Y Q, SUN J M, HE X Y, et al. Modeling indirect illumination for inverse rendering[C]" Proceedings of the IEEE CVF Conference on Computer Vision and Pattern Recognition. New Orleans: IEEE, 2022.
[14]KAJIYA J T. The rendering equation[C]" Proceedings of the 13th Annual Conference on Computer Graphics and Interactive Techniques. New York: ACM, 1986.
[15]YAO Y, ZHANG J Y, LIU J B, et al. Neilf: Neural incident light field for physically-based material estimation[C]" European Conference on Computer Vision. Cham: Springer Nature Switzerland, 2022.
[16]TOMASI C, MANDUCHI R. Bilateral filtering for gray and color images[C]" Sixth International Conference on Computer Vision (IEEE Cat. No. 98CH36271). Bombay: IEEE, 1998.
[17]BURLEY B, STUDIOS W D A. Physically-based shading at disney[C]" Acm Siggraph. New York: ACM, 2012.
[18]WANG Z, BOVIK A C, SHEIKH H R, et al. Image quality assessment: From error visibility to structural similarity[J]. IEEE Transactions on Image Processing, 2004, 13(4): 600-612.
[19]ZHANG R, ISOLA P, EFROS A A, et al. The unreasonable effectiveness of deep features as a perceptual metric[C]" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. Salt Lake City: CVPR, 2018: 586-595.
A relighting method of digital garments based on a single tensor radiance field
CHEN Xinlei1, ZHENG Junhong1, JIN Yao1,2, HE Lili1,2
(1.School of Computer Science and Technology, Zhejiang Sci-Tech University, Hangzhou 310018, China;
2.Zhejiang Provincial Innovation Center of Advanced Textile Technology (Jianhu Laboratory), Shaoxing 310020, China)
Abstract:The technology of garment relighting carries substantial research significance in the domains of online garment sales, virtual fitting, and personalized customization. Moreover, relighting methods based on implicit 3D models have garnered considerable attention in the fields of computer vision and computer graphics. However, existing scene relighting techniques face inherent challenges when applied to garment datasets, such as texture noise and relighting distortion. To address these shortcomings, this paper proposes an innovative garment relighting method that operates in the feature tensor, to effectively mitigate these issues.
The relighting process involves incorporating the relighting component into the tensorial radiance fields to jointly optimize the feature space. To simulate the direct ambient light and the indirect light reflected between garment surfaces, Spherical Gauss and MLP techniques are employed to construct an incident light field. Additionally, a gradient-guided smoothing strategy is utilized to optimize the extraction of parameters from the bidirectional reflectance distribution function model, which are derived from the feature tensor. Finally, the garment relighting image is rendered by combining the incident light field, the bidirectional reflection distribution model, and the feature tensor using the simplified reflectivity equation.
This article presents experimental results on three garment datasets, comparing them with advanced methods such as Physg and InvRender. The results demonstrate that our method achieves an average improvement of about 4.549% in generating garment images from novel view and approximately 9.922% in generating garment images under relighting conditions, as evaluated using three indicators. The article visually demonstrates the effectiveness of our proposed method in reducing texture noise and reillumination distortion. Ablation experiments are also conducted, examining the impact of gradient-guided smoothing strategies and the use of single or multiple addition feature tensor for garment feature storage. The article shows that using multiple addition feature tensor does not enhance the quality of garment image generation but increases the training time. By comparison, using addition single feature tensor achieves a minimal improvement of only 0327% but significantly increases the training time. Our method, which employs a single feature tensor, significantly shortens training time and improves the quality of garment relighting images by approximately 8.870% compared to the other models. The article compares the experimental results of different lighting strategies (DL, DL+SGID, DL+MLPID, DL+SGID+Vis, and DL+MLPID+Vis) in garment image rendering. The results indicate that the combination of indirect light, direct light, and visibility achieves the best generation outcomes. The article compares experimental results obtained by employing different gradient descent strategies (GD, GD+RSL, and GD+GGS) in garment image rendering. The results indicate that our proposed gradient-guided smoothing strategy enhances the quality novel view garment images by approximately 4.583% and relighting garment images by about 6.096% compared to traditional relative smoothing loss methods.
This paper introduces a garment relighting model based on Tensorf for 3D garment relighting. The relighting module is integrated into Tensorf, which encompasses the incident light field combined with indirect light, the BRDF model based on the Disney principle, and the simplified reflectance equation. As a result, garment relighting from any perspective is achieved. The experimental results demonstrate that the proposed garment relighting model effectively leverages the feature tensor from Tensorf. The introduction of gradient smoothing loss contributes to the improved accuracy of BRDF parameters, reduces texture noise commonly encountered in existing methods applied to garment datasets, and enhances the accuracy of relighting. The evaluation indexes indicate that the model produces superior results compared to existing advanced methods for generating novel view images and relighting outcomes. However, it is worth noting that the surface reconstruction in this method relies on the tensor radiation field, which may result in rendering points with low effectiveness, leading to errors in the reconstruction of hollow areas on the surface. Future work will address this issue accordingly.
Key words:
single tensor radiance field; feature space; garment relighting; 3D reconstruction; image generation; bidirectional reflectance distribution function
猜你喜欢
数学物理学报(2021年6期)2021-12-21 06:24:38
数学物理学报(2021年1期)2021-03-29 03:13:38
五邑大学学报(自然科学版)(2020年4期)2020-12-09 06:28:48
应用数学(2020年2期)2020-06-24 06:02:50
数学年刊A辑(中文版)(2018年2期)2019-01-08 01:59:52
山西大同大学学报(自然科学版)(2016年2期)2016-12-12 03:19:27
中小学实验与装备(2014年3期)2014-09-17 01:21:52
河南科技(2014年19期)2014-02-27 14:15:33
河南科技(2014年3期)2014-02-27 14:05:45
物理教师(2011年11期)2011-07-24 08:24:02
