
中国手语识别方法及技术综述
2024-05-18 22:25:20蒋贤维孙计领张艳琼王立平蒋小艳韩雪
现代特殊教育 2024年6期
蒋贤维 孙计领 张艳琼 王立平 蒋小艳 韩雪

【摘要】 中国手语具有自己独特的文化内涵和复杂表达,是近3000万听障人士融入社会的重要手段。手语识别技术能帮助听障人士走出信息孤岛,和健听人建立有效沟通。中国手语识别方法大致经历了传统技术识别和现代智能识别两个时期。前者主要包含数据收集、预处理、特征提取和分类识别四个主要阶段,主流技术有HMMs、SVM和DTW等,基于手语手形数据完成识别,不依赖海量样本数据;后者主要利用深度神经网络和人工智能技术,强调深度学习,迁移学习和技术融合,模型对样本数据量的依赖程度较高。我国已经开始广泛建设各类手语语料库,但需要进一步规范和推广。
【关键词】 手语识别技术;语料库;深度神经网络;迁移学习
【中图分类号】 G760
【作者简介】 蒋贤维,副教授,南京特殊教育师范学院数学与信息科学学院(南京,210038),jxw@njts.edu.cn;孙计领、张艳琼、蒋小艳,副教授,南京特殊教育师范学院数学与信息科学学院(南京,210038);王立平,教授,南京特殊教育师范学院数学与信息科学学院(南京,210038);韩雪,讲师,南京特殊教育师范学院数学与信息科学学院(南京,210038)。
一、引言
调查数据表明,作为我国残疾人群体中占比最大的听障人士,其数量约近3000万,听障人士能进行有效沟通,才能打破信息孤岛,融入社会[1]。手语是听障人士用于交流的重要手段。作为一种结构化的手势形式,它通过手形、运动、位置、运动方向和非手控特征等组合来传递信息。中国手语更是一种特殊的表达方式,具有自己独特的文化意义和审美意义,既结合了汉语的音、义来传递和表达语义,又以手势张扬汉语的特色,体现文化审美。手语识别指利用计算机技术将手语转换成其他可理解的信息,如自然语言、文本、音频、图像、视频等。目标是自动将手语表达翻译成相应的手语注释。由于手语词汇量大,语义丰富,表达方式多样,语法结构复杂,因此手语识别困难较多,是复合的跨学科挑战。但手语识别可广泛应用于日常交流、工作学习、翻译研究等,尤其是有益于各类特殊教育学校、有残疾学生就读的普通学校、残疾人康复机构的从业人员,特殊教育行政管理、科研人员和师生,以及热心特殊教育的社会各界人士,甚至还可以扩展到临近及相似的其他领域。因此,手语识别方法及技术研究具有深远的意义,它有助于特殊教育事业发展,有助于特殊儿童少年群体成长和特殊教育教师业务提升。本文基于近20年的中国手语识别方法及技术相关论文及数据,分别从传统手语识别方法和现代手语识别方法两条主线,探讨了手语识别的数据集及语料库建设、数据采集、预处理、特征提取、分类识别以及不同类型的深度神经网络和迁移学习等内容,分析了中国手语识别方法及技术的特点,并与国外主流手语识别方法和技术作对比。
二、数据集及语料库
语料库被认为是自然语言处理任务的数据集,手语识别技术的研究首先要有合适的手语语料库。世界各国都开展了本国手语语料库的建设。澳大利亚手语语料库AuslanSignbank是目前较为成熟型的手语语料库,主要用于手语的传承保护和词典编纂[2]。德国孤立词语料库有SIGNUM和DGS Kinect 40[3-4],连续语句语料库则以天气预报手语平行语料库PHOENIX Weather 2014为代表[5]。美国手语语料库有ASLLVD、ASLSKELETON3D、ASLLRP SignBank、WLASL2000和How2Sign[5-10]等。此外,典型代表还有英国手语语料库、希腊手语语料库、荷兰手语语料库等[11-14]。
我国《国家手语和盲文规范化行动计划(2015—2020年)》和《第二期国家手语和盲文规范化行动计划(2021—2025年)》提出,要加强国家手语语料库规划布局,加快手语语料库技术规范建设,为建成能贴近聋人手语语言生活、聋人教育,具有服务生活交流、服务教学、服务研究功能,权威的国家手语语料库提供有力支撑。目前我国的手语语料库处于建设和提升阶段,具代表性的有复旦大学龚群虎的通用手语语料库项目“基于汉语和部分少数民族语言的手语语料库建设研究”[15];南京特殊教育师范学院丁勇等人主持的国家语委重大项目“国家手语词汇语料库建设”[16]。此外,一些研究者和团队也自建了专用的手语语料库,如中国科学院计算研究所与微软亚洲研究院合作的基于Kinect的手语识别和翻译项目拍摄的DEVISIGN数据集[17];东北大学王斐等人创建的NCSL数据集[18];黄杰团队建立的连续手语数据集CSL-100[19];陈晓燕研究中国电视手语传译的非手部策略时建立的样本语料库[20];吴蕊珠等人提出的构建手语汉语平行语料库的方案[21];刘学达基于上海手语高频词建立的上海手语语料库[22];国家手语和盲文研究中心顾定倩教授团队主持修订了《国家通用手语词典》,收录了听力残疾人语言生活和教育中使用频率较高、比较稳定的手语常用词8214个[23];倪兰筛选出2500个左右的中国手语常用手势,编撰了《中国手语教程》[24]。这些语料库各有特色,肩负各自的创建使命,即目前的手语语料库资源建设大多出于某项研究需求,自定义规范较多。因此,它们没有相对统一的标准,无法较好地泛化和推广,只能局限在某个局部领域应用。由于缺乏合适的语料库和数据集,阻碍了手语研究的进一步深度挖掘。
三、传统手语识别方法及技术
传统手语识别方法主要通过捕获手部参数然后转换为相应的释义,机器学习相关技术是主流,一般不涉及大模型,對样本数据量的要求相对不高。它最常见的两种方式是基于传感器和基于视觉的手语识别。这两种识别也可以称为接触式和非接触式手语识别。从功能性、精度、舒适度和价格等方面来看,接触式手语识别通常精度高、功能强大,但价格较高;非接触式手语识别一般更舒适、方便,价格较低,但精度相对较低,所获得的图像很容易受到背景的影响,但可以包含面部表情,帮助增强意义识别。
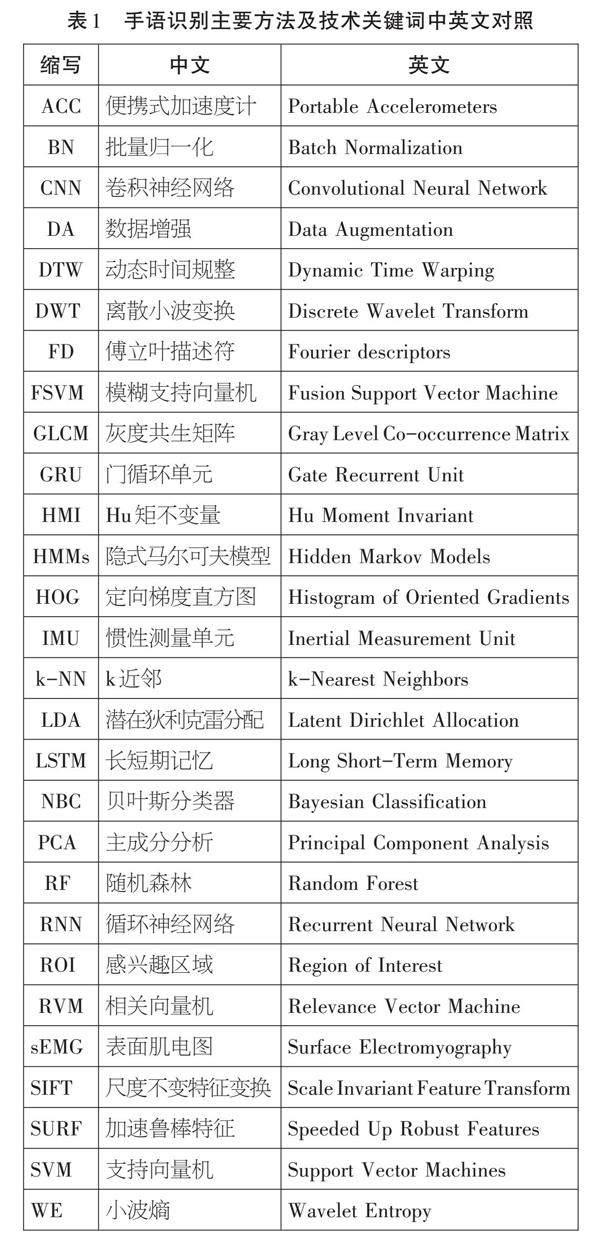
由于手语识别方法及技术研究中涉及较多专业术语和英文缩写,为了更准确地理解这些关键词,联通上下文,表1列出了主要识别方法及技术的中英文全名及其缩写词(按字母排序)。
接触式装备较早应用于手势识别,典型代表有数据手套、肌电信号臂环、惯性测量单元(IMU)、WiFi、雷达、智能手机、Leap Motion控制器和Kinect等。装备可以直接检测人手和各个关节的空间信息,并处理成输入数据。此外,在基于视觉的识别模型中,相机是获取输入数据的主要工具,用于获取手语图像和视频。基于视觉的方法采集成本低、设备依赖性弱,采集方便,但从视频流和关键帧中提取特征可能会带来额外的计算开销;同时,由于肤色、角度、光线等因素,基于视觉的识别准确率会降低。一般可以通过引入高性能计算机来解决这些问题。
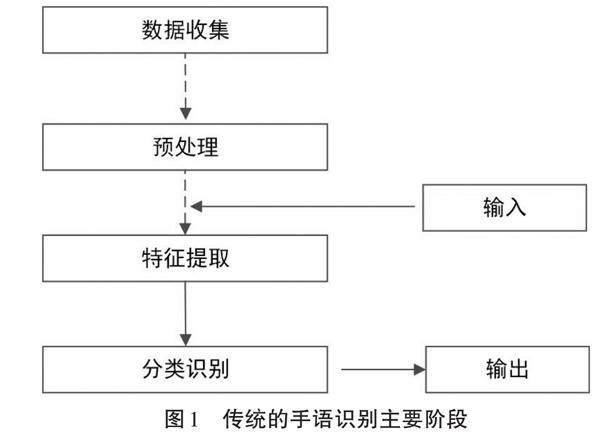
如图1所示,传统的手语识别方法大致可以分为数据收集、预处理、特征提取和分类识别四个主要阶段。每个阶段都引入了不同的技术,构成了不同的手语识别模型和系统。
(一)数据收集
数据手套等设备是早期手语数据收集常用手段,采集的手语特征参数有手形、运动轨迹和位置信息,后来一些研究人员开始简化或减除设备上复杂的传感器以降低成本。基于视觉的手语识别中,输入数据大多是预处理后的表征手语图像或视频。此外,体感相机等可以同时获得视觉图像信息、深度信息和骨骼信息,考虑了多模态手语信息的获取。
(二)预处理
为了减少无用信息并捕获最具代表性的信息,在提取特征或训练模型之前需要执行预处理。常用的预处理操作包括图像调整、形态变换、灰度转换、过滤、降噪、增强和归一化等。在手语识别研究中,肤色检测和过滤、RGB- HSV转换、灰度转换、手部分割和检测等方法常常被用来减少计算量、提高计算效率和获得ROI。
(三)特征提取
特征提取是指获取输入数据中需要的部分并转化为特征集。常用的特征提取方法有:灰度共生矩阵(GLCM),定向梯度直方图(HOG),小波熵(WE),主成分分析(PCA),Hu矩不变量(HMI),尺度不变特征变换(SIFT),傅立叶描述符(FD),加速鲁棒特征(SURF),潜在狄利克雷分配(LDA)等。
其中,灰度共生矩阵(GLCM)是一种基于灰度空间相关特性来表示纹理的方法。如图2所示,由于纹理是由空间位置上灰度反复变化形成,因此,图像空间中任意两个像素之间必然有灰度关系,这种关系称为图像中灰度的空间相关特性。1973年,Haralick等人首次提出使用灰度共生矩阵来描述纹理特征[25]。国内高亚岚等人使用灰度共生矩阵和模糊支持向量机进行中国手语手指语识别,准确率达到86.7%[26]。
方向梯度直方图特征是一种能够快速描述物体局部梯度特征的描述符[27]。定向梯度直方图(HOG)是密集网格中局部方向梯度的归一化直方图,它是一种广泛应用于计算机视觉和图像处理中的特征描述方法。包括物体方向在内,HOG对于几何变换和光度转换来说具有不变性[28]。此外,HOG还可以将样本数据转换到稀疏空间。因此,它特别适合图像中的目标检测。如图3所示,给出了HOG算法实现的主要流程。Mou等人提出了一种基于HOG特征的稀疏编码手语识别方法[29]。其中,手语识别通过监督、区分和基于学习加权局部特征的面向事件的字典被表述为稀疏表示问题。提取出每类手语样本的HOG特征,然后使用LC-KSVD算法学习面向事件和面向判别的词典。
小波熵(WE)是离散小波变换(DWT)和熵计算的组合方法,常用于处理复杂信号的时间特征。由于使用离散小波变换会增加计算量和存储量,因此引入熵来提高性能,熵表示图像纹理和信息不确定性的随机度量。小波熵可以定量地衡量信息分布的有序性和无序性,定性地反映一些有用的信息。图4描述了一个二阶二维离散小波变换的过程。朱兆松等人提出了一种结合小波熵和支持向量机(WE-SVM)的中国手语识别方法,总体精度达到85.69±0.59%[30]。
图像匹配是计算机视觉领域的重要研究内容,在图像处理中普遍采用尺度不变特征变换(SIFT),它可以对图像中的关键点进行检测,具有尺度不变性。SIFT的不变性主要体现在图像旋转和缩放上,对光照和拍摄角度仅保持部分不变。尺度不变特征变换算法生成图像特征集主要有四个阶段:尺度空间极值检测;关键点定位;方向分配;关键点描述。该算法的本质是关键点检测和描述符生成。Tharwat等人提出了基于尺度不变特征變换的方法构建阿拉伯手语识别系统[31]。
此外,主成分分析(PCA)作为一种使用正交变换将相关变量观测值更改为不相关变量值的数学运算,其变换本质是一种利用低维子空间来近似某个向量或图像。其优点是能够在充分保留有用信息的基础上有效降低原始特征向量维数,降低内存,减少计算量。Lowe提出了一种集成主成分分析、线性判别分析和支持向量机的新型层次分类方案,取得了更高的准确率[32]。Hu矩不变(HMI)可以用于不复杂的纹理特征,能较好描述目标形状。傅里叶描述符(FD)被定义为描述物体边界曲线信号的频域分析。这些曲线与原始运动和旋转无关。FD通常需要进行归一化,通过低频分量来计算手势图像的相似度差异。加速鲁棒特征(SURF)的稳健性在图像变换中表现较好,特征提取速度也比尺度不变特征变换(SIFT)更快,但需要高品质的图像,受环境影响较大,因此并不实用。
(四)分类识别
分类本质是找到一个函数来确定输入数据所属的类别。分类的准确率与构建方法、待分类数据特征以及训练样本数量等因素密切相关。机器学习模型中常见分类器有隐式马尔可夫模型(HMMs),支持向量机(SVM),动态时间规整(DTW),长短期记忆(LSTM),随机森林(RF),k近邻(k-NN),贝叶斯分类器(NBC),相关向量机(RVM),AdaBoost多标签多类分类器等。
其中,隐式马尔可夫模型(HMMs)是用概率表示变量的传统马尔可夫模型改进版本,通常被引入统计模式分析中[33]。当HMMs应用于手势识别系统构建分类器时,主要涉及学习和评估两个过程。学习应用于手势建模过程,可以理解为隐马尔可夫模型的训练问题;评估应用于手势识别过程,分类器建立后,采用前向算法计算先验概率,并对输入的观察序列进行判别。HMMs在一定程度上对时间轴上的局部变形(压缩和扩展)具有不变性,因此被广泛应用于自然语言建模、在线手写识别和生物序列分析等领域。陈梯等人基于快速鲁棒性特征和隐马尔可夫模型对手语视频中的8种手势进行识别,平均识别率达到93%,能有效克服光照、角度和复杂背景的影响[34]。
支持向量机(SVM)是一種监督学习方法,拥有优越的泛化能力、更高的精度和精细的数学易处理性等优点,但不能处理序列关系,不适用动态手语识别[35]。刘小建等人选择非线性径向基函数(RBF),利用网格搜索方法调整确定SVM参数,实现了高效、准确的手势识别[36]。
动态时间规整(DTW)可以将一个复杂的全局优化问题逐步转化为多个局部优化问题,因此被广泛应用于语音识别、动作识别、数据挖掘和信息检索等领域。由于手语基于时间序列表达,只需要计算两条手语表达数据之间的距离即可计算相似度。识别时,将待识别与参考手语特征序列依次进行匹配,选择输出的结果必须是最小总失真且不大于识别阈值的。该算法识别精度高、系统复杂度低,但匹配计算开销较大。张露提出了基于DTW单个手语识别算法,对数字0—9进行检测并取得良好识别效果[37]。魏秋月等人采用一种改进的DTW算法对特征数据进行模板训练,实现了基于轨迹匹配的动态手势识别,在14种手势上获得了98.7%的平均识别率[38]。
长短期记忆(LSTM)网络本质上是一种循环神经网络(RNN),通过增加一个处理器解决了传统RNN中存在的梯度消失问题[39]。其对间隙长度相对不敏感,通过为RNN提供可以持续数千个时间步的短期记忆,从而实现“长短期记忆”。LSTM不仅可以检测手语的时间变化,还可以学习手势变化之间的对应关系,从而增强手语的分类识别能力。毛晨思提出了基于卷积网络和长短时记忆网络的中国手语词识别,识别率达到了98.2%[40]。
随机森林(RF)由LeoBreiman于2001年提出,该算法在许多实际任务中表现出很强的性能。随机森林分类是由多种决策树分类模型组成复合分类模型。其基本思想是首先通过自举采样从原始训练集中提取m个样本集,每个样本集的样本量保持不变;其次,对这m个样本集建构对应m个决策树模型,并得到m个分类结果;然后基于m个分类结果对每条记录进行投票并确定其最终分类。随机森林可以为一些先验知识模糊、规则不明确、约束不完全、数据不完整的应用问题提供更好的解决方案。其缺点是会因决策树增加带来泛化误差。如Su等人提出了基于ACC和sEMG的非视觉手语识别方法,运用随机森林进行分析,识别率为98.25%,效果良好[41]。
四、现代手语识别方法及模型
传统手语识别方法提供了实用的解决方案,随着人工智能的崛起和大模型的推广,新技术和新方法成为研究者新的追求目标。尤其是近年来,深度学习、迁移学习以及基于深度神经网络的混合网络模型等,为手语识别提供了更好的解决方案。
(一)卷积神经网络
卷积神经网络(CNN)是一种具有卷积计算功能和深层结构的前馈神经网络。它利用多层叠加的方式从低层特征提取到高层特征,模拟了人脑的层次结构功能。由于其强大的特征提取能力和对图像信息有效、准确的分类能力,被认为是识别和分类领域最具代表性的深度神经网络。典型的卷积神经网络(如图5所示)由多个层组成,包括输入层、卷积层、池化层、全连接层和输出层。其中,卷积层通过卷积运算进行特征提取;池化层可以不断减小数据的空间大小,从而减少参数和计算的数量;全连接层扮演了“分类器”的角色。
大数据驱动的深度学习模型性能随着样本数量增加而提高,同样对样本量和网络训练提出了更高的要求。简单的CNN并不能获得更好的性能,因此,各种优化算法被融入卷积神经网络模型中。例如,批量归一化(BN)技术可以使层的输入保持更均匀分布。Dropout技术可以细化网络,有效减少过拟合,并实现一定程度的正则化。ReLU函数可以加速随机梯度下降的收敛速度[42]。数据增强(DA)技术可以有效扩展数据集并有助于缓解过度拟合[43]。赵一丹提出将CNN和LSTM相结合识别特定手语视频,实验识别准确率为99.256%[44]。
尽管CNN具有强大的特征提取能力,但其仅适用于处理单帧图像数据。手语运动过程表达涉及帧间的相关信息,3D卷积神经网络(3D-CNN)提供了解决方案。3D-CNN主要解决图片之间的相关性,增加了新的维度信息。3D-CNN可以捕获空间和时间维度的判别特征。杨光义等人提出一种基于注意力机制的复杂背景连续手语识别算法,并在大规模连续手语数据集CSL100上取得优异表现[45]。
(二)YOLO
YOLO(You Only Look Once)是计算机视觉领域著名的模型之一。该方法将任务合并为回归问题,无需将检测结果分为分类和回归,适用于实时物体检测任务。YOLO的发展经历了YOLO V1到YOLO V8。其中,YOLO V1算法将目标检测定义为单一回归问题,速度比传统算法要快得多。YOLO V1的优点是可以高速实时检测物体,理解广义物体表示,并且模型不会过于复杂,其缺点是当小物体出现在簇或组中时,模型的效果较差;YOLO V2在速度、精度和检测大量物体等方面都做出了较大改进;YOLO V3添加了逻辑回归来预测每个边界框的得分,还引入了Faster R-CNN方法;YOLO V4通过添加和组合一些新功能(加权残差连接、跨阶段部分连接、跨小批量归一化、自对抗训练等),实现了更优越和更高效性能;YOLO V5是一种单阶段目标检测算法,框架结构人性化,集成了大量计算机视觉技术,提高了训练速度和物体识别速度[46]。张晓晨等人提出了一种基于YOLO V5的中国传统手语拼音数据库模型[47];张强提出了一种基于改进的YOLO V3的静态手势实时识别方法,该方法对流视频静态手势的平均识别准确率为99.1%,对4个自定义连续动态手势的识别率为94%[48]。
(三)胶囊网络
胶囊网络(CapsNet)是一种新的深度神经网络模型,目前主要应用于图像识别领域。与传统神经元不同,胶囊的输入和输出都是向量。向量长度可以理解为传统神经元中的概率,而向量的方向代表其他信息。胶囊网络利用基于协议的动态路由来替代传统CNN中的最大池化(Max-Pooling)。胶囊将特征检测的概率定义为其输出向量长度,特征状态描述为向量方向。
胶囊网络(如图6所示)由六个神经网络层组成,包括卷积层、PrimaryCaps层、DigitCaps层、第一全连接层、第二全连接层和第三全连接层。前三层是编码器,后三层是解码器。
CapsNet对噪声数据更具弹性,并且还可以适应输入数据的仿射变换。同时,胶囊网络也被证明可以减少训练时间并最大限度地减少参数数量。它可以用来承担机器翻译、自动驾驶、手写字符和文本识别、目标检测、情感检测等任务。郝子煜等人设计了基于CapsNet的中国手指语识别算法,并获得了较好的识别效果[49]。
(四)迁移学习及融合网络
迁移学习(transfer learning)主要有两种策略,一是使用特定任务的标注语料,用监督学习的方式对预训练模型参数进行微调(fine-tune),取得更好性能。因为从头训练一个预训练语言模型,尤其是大模型,需要海量的数据,时间和计算成本非常高。因此,共享语言模型非常重要,只要在预训练好的模型权重上构建模型,就可以大幅地降低计算成本。二是冻结并重新训练,这涉及冻结除最后一层之外的所有层(权重不更新)并仅训练最后一层。如图7所示,迁移学习的好处是预训练模型很可能已有类似的数据集,通过激发在预训练过程中获得的知识,从海量数据中获得统计理解能力。由于模型已经在大量数据上进行过预训练,后续只需要很少的数据量就可以达到不错性能。此外,随着人工智能和神经网络技术的不断发展,各种先进的网络模型和技术不断涌现。集成了多种机器学习技术的融合网络,可以更有效地实现中国手语的识别和翻译。大多数情况下,往往也会结合多种主流技术和先进方法来实现更高效的网络模型建构。
五、国内外发展对比
中国手语泛指中国聋人使用的手语,理论上汇集了少数民族、港澳台地区和各类地方手语。但由于目前中国通用手语的标准化仅针对中国大陆,因此“中国手语”一词又仅指大陆听障人使用的手语。手语识别可以分为静态手语识别和动态手语识别两大类,对应的还可以细分为手指语识别、孤立词识别和连续手语识别,因此,研究者们提出了各种不同的识别方法和技术,并取得了不同的成效。如手指语识别由于内容组成有限,属于静态图像识别,背景环境相对可控,识别准确率几乎都在90%以上;孤立词识别介于手指语和连续手语识别之间,传统方法和现代智能方法都有提及,识别性能也相对较高;连续手语识别由于涉及时间动态和上下文信息,因此更具挑战。卷积神经网络、3DCNN、循环神经网络及其变体(LSTM、GRU等)、Transformer模型等带来了解决之道,但同时也面临海量数据量级和强大算法负载的考验。
基于2003至2023年的中國手语识别方法及技术相关论文及数据调研发现(如图8所示),中国手语识别的研究论文数量呈稳步增长趋势。其中,2012年前处于缓慢增长阶段,从2013年开始,手语识别的研究论文呈现高增长趋势。尤其从2014年开始,文献发表数明显增长,这主要得益于计算机视觉和人工智能技术的迅猛发展。同期,中国手语识别也从传统的研究方法转向基于视觉,尤其是深度神经网络等新方法、新技术。2019年以来这一趋势得到了更明确的印证。
传统技术的手语识别阶段(时间大约为2000年至2011年),HMMs、SVM和DTW等是主流技术。特别是将HMMs技术引入到手语识别领域,对手语的时序建模取得了较好效果。这一阶段,手语识别的研究主要集中在手指语和孤立静态手语(手势)识别,利用数据手套获取数据集。现代人工智能技术阶段(时间大约从2012至今),CNN、3D-CNN、YOLO和各类深度神经网络及其变型(如ResNet、VGG-Nets、Faster R-CNN、CapsNet等)出现。这一阶段,手语识别的研究主要集中在大规模手语和实时、连续手语识别,利用数据传感器(如Kinect、Leap Motin等)和高清摄影摄像获取更高质量的数据集。同时,面部表情识别、复杂背景处理和3D手语识别等也引起了学者的研究兴趣。另外,前期运用广泛的HMMs、SVM等技术也被嫁接应用到一些混合模型。总体而言,手语识别从传统技术向基于计算机视觉和人工智能转变,从单一模型向混合模型转变。
在横向对比上,中国手语识别与其他手语识别技术研究典型代表(如美国手语、印度手语和阿拉伯手语等)相比,处于伯仲之间。如表2所示,其他国家的手语识别也采用了丰富的识别方法和技术,机器学习中的支持向量机和隐式马尔科夫模型在前期也应用频繁,近年来各国也更偏向于各类深度神经网络和多模型融合。英美手语有典型的主题和注解型结构,英国手语里普遍采用“宾语—主语—动词”语序句式,美国手语的简单句多采用“主语—动词—宾语”语序。美国手语更多的是一种视觉性语言,不是口头语言,它用一只或两只手来打手势,依靠手部形状、手势的空间摆放、打手势时手部的方向以及手部运动等视觉成分来表达意义,使用美国手势语不用说话,也不用扩声。相比而言,中国手语表达蕴含了中文的复杂内涵,涉及句型、语法和语义等多个方面,不像英语系的表达简洁明了,仅这点而言,中国手语识别的难度明显较大,对识别方法和技术提出了更高的要求。此外,从时间线上看,国内在一些热点技术研究上略微滞后。一方面说明我们的创新性还有待提升,同时也说明中国手语识别的转化和本土化需要过程。因此,我们需要挖掘一些更好更合适的中国手语识别方法和技术,反向来引领和指导普遍的手语识别。
六、总结及展望
本文对近20年来的中国手语识别方法和技术进行了回顾和总结,探讨了手语识别的各个方面,包括手语数据集、数据采集技术、特征提取、分类和识别方法以及不同类型的深度神经网络、迁移学习模型等。研究发现,前期中国手语识别方法遵循传统理念,划分若干主要阶段,以捕获手部参数为主进行分类识别,不需要海量的研究样本,主流技术包括HMMs、SVM、DTW等。后期随着现代人工智能技术的快速发展,基于深度神经网络的各种识别方法发挥着越来越重要的作用。以2012年为分水岭,中国手语识别已从传统研究方法转向基于视觉并融入深度学习和迁移学习,强调技术交叉和模型融合。
雖然目前中国手语识别整体上取得了良好的综合评价指标,但由于手语本身和手语数据集的独特性和复杂性,仍然存在以下值得研究的问题。
第一,优质的数据集。多数中国手语数据集规模过小、样本过少、不规范、无法泛化和横向比较,实验性质的研究占比高,无法应用推广。因此,需要扩充样本,建设标准化的合适数据集。
第二,高效识别、精准识别。即需要解决手语识别中实时性、鲁棒性、高精度和用户独立性问题。同时,为了更准确地转换释义,一些手语识别需要补充连续手语特征的融合信息以及嘴唇和面部表情的协调信息,还需要妥善解决手语行为受背景干扰,光线、角度和操作标准化的影响问题。
第三,新模型、新算法的使用。算法和模型的迭代更新非常迅速,因此要与时俱进,尝试更好的识别方法和模型,同时要注意协调模型精度和计算负荷的矛盾问题。
未来,新技术的不断发展和科学领域的交叉融合必将催化中国手语识别的进步和提升。混合网络模型、深度学习及人工智能技术等将进一步推动手语识别相关的理论研究和算法创新,中国手语识别必将取得更大更高质量的发展。
【参考文献】
[1]闫思伊,薛万利,袁甜甜.手语识别与翻译综述[J].计算机科学与探索,2022(16):2415-2429.
[2]Johnston T,Schembri A.Australian sign language(Auslan):An introduction to sign language linguistics[M].New York:Cambridge University Press,2007:1-10.
[3]Von Aaris U,Kraiss K F.Towards a video corpus for signer-independent continuous sign language recognition[C]. Lisbon:Springer,2007:2-10.
[4]Cooper H,Ong E J,Pugeault N,et al.Sign language recognition using sub-units[J].The Journal of Machine Learning Research,2012(13):2205-2231.
[5]Camgoz N C,Hadfield S,Koller O,et al.Neural sign language translation[C]. Salt Lake City:IEEE,2018:7784-7793.
[6]Neidle C,Thangali A,Sclaroff S.Challenges indevelopment of the American sign language lexicon video dataset(ASLLVD) corpus[C]. Paris:ELRA,2012:1-8.
[7]De Amorim C C,Zanchettin C.ASLS-keleton 3D and ASL-phono:two novel datasets for the American sign language[J]. ArXiv,2022(3):2-65.
[8]Neidle C,Oooku A,Metaxas D.ASL video corpora & sign bank:resources available through the American sign language linguistic research project(ASLLRP)[J]. ArXiv,2022(8):78-99.
[9]Li D,Opazo C R,Yu X,et al.Word-level deep sign language recognition from video:a new large-scale dataset and methods comparison[C]. Snowmass,2020:1459-1469.
[10]Duarte A,Palaskar S,Ventura L,et al.How 2sign:a large-scale multimodal dataset for continuous Ame-rican sign language[C]. Nashville:IEEE,2021:2735-2744.
[11]Fenlon J,Cormier K,Rentelis R,et al.BSL sign bank:a lexical database of British sign language[DB/OL].(2022-11-26)[2023-12-15].http://bslsig-nbank.ucl.ac.uk.
[12]Schembri A,Fenlon J,Rentelis R,et al.British sign language corpus project:a corpus of digital video data and annotations of British sign language[DB/OL].(2022-11-26)[2023-12-15].http://www.bslco-rpusproject.org.
[13]Adaloglou N,Chatzis T,Papastratic I,et al.A comprehensive study on deep learning-based methods for sign language recognition[J].IEEE Transactions on Multimedia,2022(24):1750-1762.
[14]Radboud Universiteit. NGT corpus[DB/OL].(2022-11-26)[2023-12-15].http://www.ru.nl/cor-pusngt/.
[15]全国哲学社会科学工作办公室.基于汉语和部分少数民族语言的手语语料库建设研究[R/OL].(2022-11-26)[2023-12-15].http://www.nopss.gov.cn/GB/352519/355466/.
[16]赵晓驰,任媛媛,丁勇.国家手语词汇语料库的建设与使用[J].中国特殊教育,2017(1):43-47.
[17]Chai X,Wang H,Chen X.The DEVISIGN Large vocabulary of Chinese sign language database and baseline evaluations[R]. Beijing:Technical Report VIPL-TR-14-SLR-001,2014.
[18]Wang F,Du Y X,Wang G R,et al.(2+1)DSLR:an efficient network for video sign language recognition[J].Neural Computing and Applications,2022(34):2413-2423.
[19]Huang J,Zhou W H,Zhang Q L,et al.Video based sign language recognition without temporal segmenta-tion[C]. Louisiana:AAAI,2018:275.
[20]陈晓燕.中國电视手语传译中的非手部策略[D].厦门:厦门大学,2014.
[21]吴蕊珠,李晗静,吕会华,等.面向ELAN软件的手语汉语平行语料库构建[J].中文信息学报,2019(33):43-50.
[22]刘学达.中国手语语料库高频词初步分析及标注探讨[D].上海:上海外国语大学,2022.
[23]北京师范大学国家手语和盲文研究中心.国家手语和盲文研究中心主持制定的《国家通用手语常用词表》发布[J].教育学报,2018(3):54-54.
[24]倪兰,和子晴.上海手语翻译服务需求与现状调查[J].中国翻译,2022(43):113-119.
[25]Haralick R M,Shanmugam K,Dinstein I H.Textural features for image classification[J].IEEE Transactions on Systems,Man,and Cybernetics,1973(6):610-621.
[26]Gao Y,Xue C,Wang R,et al.Chinese fingerspelling recognition via gray-level co-occurrence matrix and fuzzy support vector machine[J]. ICST Transactions on e-Education and e-Learning,2020(20):166554.
[27]Silanon K. Thai finger-spelling recognition using a cascaded classifier based on histogram of orientation gradient features[J].Computational Intelligence and Neuroscience,2017(8):1-11.
[28]Ming H.A new facial expression recognition method for deep autoencoder[J].Journal of Southwest Normal University:Natural Science Edition,2019(7):81-86.
[29]Mou Y,Guo Y.Research on sparse coding sign language recognition method based on HOG features[J].Microprocessor,2020(5):50-57.
[30]Jiang X,Zhu Z.Chinese sign language identifica-tion via wavelet entropy and support vector machine[C]. Dalian:Spinger,2019:726-736.
[31]Tharwat A,Gaber T,Hassanien A E,et al. Sift-based Arabic sign language recognition system[C].Cham:Springer,2015:359-370.
[32]Lowe D.Distinctiveimage features from scale-invariant keypoints[J]. International Journal of Com-puter Vision,2004(2):91-110.
[33]Alexandre L,Salvador S J,Rodrigues J. Pattern vecognition and image analysis[C]. Cham:Springer,2017:419-426.
[34]陈梯,孙杳如.基于快速鲁棒性特征和隐马尔可夫模型的手语识别[J].现代计算机(专业版),2018(3):15-18+25.
[35]Zhang Y,Wang S,Dong Z.Classi-cation of alzh-eimer disease based on structural magnetic resonance imaging by kernel support vector machine decision tree[J]. Progress in Electromagnetics Research,2014(144):171-184.
[36]刘小建,张元.基于多特征提取和SVM分类的手势识别[J].计算机工程与设计,2017(4):953-958.
[37]张露.基于DTW的单个手语识别算法[J].现代计算机(专业版),2016(8):77-80.
[38]魏秋月,刘雨帆.基于Kinect和改进DTW算法的动态手势识别[J].传感器与微系统,2021(11):127-130.
[39]Sepp H,Jürgen S.Long shortterm memory[J].Neural Computation,1997(8):1735-1780.
[40]毛晨思.基于卷积网络和长短时记忆网络的中国手语词识别方法研究[D].合肥:中国科学技术大学,2018.
[41]Su R,Chen X,Cao S,et al.Random forest-based recognition of isolated sign language subwords using data from accelerometers and surface electromyographic sensors[J].Sensors,2016(1):100-105.
[42]Jiang X,Zhang Y D. Chinese sign language fing-erspelling via six-layer convolutional neural network with leaky rectified linear units for therapy and rehabilitation[J]. Journal of Medical Imaging and Health Informatics,2019(9):2031-2090.
[43]Jiang X,Lu M,Wang S H. An eight-layer convolutional neural network with stochastic pooling,batch normalization and dropout for fingerspelling recognition of Chinese sign language[J]. Multimedia Tools and Applications,2019(79):5697-15715.
[44]赵一丹.基于深度学习的手语识别算法研究[D].西安:西安工业大学,2019.
[45]杨光义,丁星宇,高毅,等.基于注意力机制的复杂背景连续手语识别[J].武汉大学学报(理学版),2023(1):97-105.
[46]Daniels,Steve,Nanik S,et al.Indonesian sign language recognition using YOLO method[C]. London:IOP Publishing,2021:12-29.
[47]Zhang X,Lei A,Su X.A Chinese traditional sign language pinyin database model based on YOLOv5[J].Television Technology,2023(4):38-42.
[48]張强.基于改进YOLOv3的手势识别方法研究[D].合肥:合肥工业大学,2019.
[49]郝子煜,阿里甫·库尔班,李晓红,等.基于CapsNet的中国手指语识别[J].计算机应用研究,2019(10):3157-3159.
[50]Fatmi R,Rashad S,Integlia R.Comparing ANN,SVM,and HMM based machine learning methods for American sign language recognition using wearable motion sensors[C]. Las Vegas:IEEE,2019:290-297.
[51]Xie M,Ma X.End-to-end residual neural network with data augmentation for sign language recognition[C].Chengdu:IEEE,2019:1629-1633.
[52]Plouffe G,Cretu A M. Static and dynamic hand gesture recognition in depth data using dynamic time warping[J].IEEE Trans Instrum Meas,2015(2):305-316.
[53]Abhishek K S,Qubeley L C K,Ho D.Glove-based hand gesture recognition sign language translator using capacitive touch sensor[C]. Hong Kong:IEEE,2016:334-337.
[54]Pan T Y,Lo L Y,Yeh C W,et al.Realtime sign language recognition in complex background scene based on a hierarchical clustering classification method[C].Chengdu:IEEE,2016:64-67.
[55]Susa J A B,Macalisang J R,Sevilla R V,et al. Implementation of security access control using American sign language recognition via deep learning approach[C]. Jamshoro:ICETELL,2022:1-5.
[56]Amin M S,Rizvi S T H,Mazzei A,et al.Assistive data glove for isolated static postures recognition in American sign language using neural network[J].Electronics,2023(8):1904.
[57]Wadhawan A,Kumar P.Deeplearning-based sign language recognition system for static signs[J].Neural Computing and Applications,2020(5):7957-7968.
[58]Raheja J,Mishra A,Chaudhary A.Indian sign language recognition using SVM[J].Pattern Recog-nition and Image Analysis,2016(2):434-441.
[59]Sajanraj T D,Beena M.Indian sign language numeral recognition using region of interest convoluti-onal neural network[C]. Coimbatore:ICICCT,2018:636-640.
[60]Suri K,Gupta R.Convolutional neural network array for sign language recognition using wearable IMUs[C]. Noida:SPIN,2019:483-488.
[61]Vkishore P V,Prasad M V D,Prasad C R,et al.4-camera model for sign language recognition using elliptical fourier descriptors and ANN[C]. Guntur:IEEE,2015:34-38.
[62] De Castro G Z,Guerra R R,Guimar?es F G.Automatic translation of sign language with multi-stream 3D CNN and generation of artificial depth maps[J].Expert Systems with Applications,2023(2):119394.
[63]Sidig A A I,Luqman H,Mahmoud S A.Arabic sign language recognition using vision and hand tracking features with HMM[J].International Journal of Intelligent Systems Technologies and Applications,2019(5):430-447.
[64]Tubaiz N,Shanableh T,Assaleh K.Glove-based continuous Arabic sign language recognition in user-dependent mode[J].IEEE Transactions on Human-Machine Systems,2015(4):526-533.
[65]Mohandes M,Aliyu S,Deriche M.Arabic sign language recognition using the leap motion controller[C].Cham:Springer,2014:960-965.
[66]Saleh Y,Issa G.Arabic sign language recognition through deep neural networks fine-tuning[J].iJOE,2020(5):71-83.
[67]Deriche M,Aliyu S O,Mohandes M. An intelligent Arabic sign language recognition system using a pair of LMCS with GMM based classification[J].IEEE Sensors Journal,2019(18):8067-8078.
[68]Alawwad R A,Bchir O,Ismail M M B.Arabic sign language recognition using faster R-CNN[J].International Journal of Advanced Computer Science and Applications,2021(3):1-10.
[69]Latif G,Mohammad N,Khalaf R A l,et al.An automatic Arabic sign language recognition system based on Deep CNN:an assistive system for the deaf and hard of hearing[J].International Journal of Computing and Digital Systems,2020(4):715-724.
Review of Chinese Sign Language Recognition Methods and Technologies
JIANG Xianwei SUN Jiling ZHANG Yanqiong WANG Liping JIANG Xiaoyan HAN Xue
Abstract:Chinese Sign Language has its own unique cultural connotations and complex expressions,and it is an important means for more than 30 million hearing-impaired people to integrate into society.Sign language recognition technology can assist individuals with hearing impairments in bridging communication gaps and establishing effective communication with those who can hear.Chinese sign language recognition methods have gone through roughly two stages of traditional technology recognition and modern intelligent recognition.The former mainly includes four stages of data collection,preprocessing,feature extraction,and classification recognition.Hidden Markov Models(HMMs),Support Vector Machines(SVM),and Dynamic Time Warping(DTW)are mainstream technologies.It achieves recognition based on hand data without relying on extensive sample data.The latter mainly combines deep neural network and artificial intelligence technology,emphasizing deep learning,transfer learning,and technology integration.The model is highly dependent on the amount of sample data.China has started to extensively develop various sign language corpora,but it requires further standardization and promotion.
Key words:sign language recognition technologies;corpus,deep neural network,transfer learning
Authors:JIANG Xianwei,associate professor,School of Mathematics and Information Science,Nanjing Normal University of Special Education(Nanjing,210038),jxw@njts.edu.cn;SUN Jiling,ZHANG Yanqiong,JIANG Xiaoyan,associate professor,School of Mathematics and Information Science,Nanjing Normal University of Special Education(Nanjing,210038);WANG Liping,professor,School of Mathematics and Information Science,Nanjing Normal University of Special Education(Nanjing,210038);HAN Xue,lecturer,School of Mathematics and Information Science,Nanjing Normal University of Special Education(Nanjing,210038).
(特約编校:张居晓)
猜你喜欢
天津外国语大学学报(2020年1期)2020-03-25 13:29:26
科教导刊·电子版(2017年13期)2017-07-24 08:26:51
知识管理论坛(2016年6期)2017-05-27 19:44:03
振动工程学报(2017年1期)2017-04-21 10:24:46
作文评点报·低幼版(2017年13期)2017-04-18 18:15:11
电子技术与软件工程(2017年4期)2017-03-27 21:51:30
电脑知识与技术(2016年22期)2016-10-31 20:23:56
中国科技博览(2016年8期)2016-04-25 06:51:25
物联网技术(2015年9期)2015-09-22 09:23:43
现代电子技术(2015年14期)2015-07-22 21:50:36
