
双分支结构的多层级三维点云补全
2024-05-11 03:34邱云飞王宜帆
计算机工程与应用 2024年9期
邱云飞,王宜帆
辽宁工程技术大学软件学院,辽宁 葫芦岛 125105
点云是三维点的数据集合,包含三维坐标、强度、颜色和时间戳等信息,具有存储空间小,操作灵活且能够极大程度上保留原始的几何信息等特点,是一种非常重要的三维数据表达形式。随着激光雷达、激光扫描仪和RGB-D 扫描仪等三维扫描设备的普及,点云变得更容易捕获,更是被广泛应用在各种视觉领域,例如三维场景重建[1]、立体视觉[2]、自动驾驶感知定位[3]、三维测量[4]、视觉引导[5]等。但在现实场景中对点云数据进行采集时由于传感器分辨率限制,物体遮挡、阴影以及拍摄角度等诸多外界因素的影响,往往造成获取到的点云数据不完整,进而无法准确描述物体的几何信息。在点云研究领域中,点云残缺的问题会严重影响点云相关技术的发展和应用,因此点云补全具有重要意义。
点云补全是由局部点云衍生而来的生成和估计问题,着重研究针对输入的残缺点云进行修复并预测出完整的点云形状的问题。由于基于深度学习的点云补全方法泛化性能强,不仅能够有效避免大量的内存消耗而且可以降低几何信息的误差,使其逐渐成为点云研究的一项重要课题。点云神经网络[6](PointNet)是最早被提出的能够直接作用在无序点集上的网络结构,在点云研究中具有里程碑式的意义。虽然其在点云分类和分割上都具有很好的表现,但是应用到点云补全时却只关注全局几何信息而忽略了局部信息。扩展点云神经网络[7](PointNet++)是PointNet 的延伸,在其基础上加入了多层次结构,使得网络能够在逐渐增大的区域上获取更高级别的特征,增强感知局部特征的能力,有效弥补了PointNet缺少局部特征的问题。点云补全网络[8](PCN)直接处理原始点云,不需要任何结构假设(如对称性)或底层形状的注释(如语义类),其解码器能够在保持少量参数的同时生成细粒度的补全。点分形网络[9](PFNet)采用基于特征金字塔网络[10](FPN)的解码架构,增强了包含在最终特征图中的几何和语义信息,充分利用提取到的特征去预测点云的几何形状,但在特征提取阶段PFNet仅使用下采样方法,从不同分辨率下提取点云特征,并未真正获得点云丰富的局部几何信息。2021年,首次提出了基于对抗网络逆映射的无监督点云补全方法,将生成对抗网[11]逆映射引入到点云补全中,网络框架利用梯度下降[12]的方法反传损失函数来更新潜码并且微调预训练的对抗网络,从而使生成的完整点云与输入的残缺点云的空间分布最为接近。另外,PMPNet[13]模拟移动行为,将不完整点云中的逐个点进行移动,根据基于点的总移动距离的约束为每个点预测唯一的点移动路径,以此来组成补全点云。但是,由于点云先天具有无序、离散等特点,导致生成式模型PMPNet 难以捕捉完整点云在细节处的拓扑结构,因此难以实现高质量补全。为此,PMPNet++[14]提出了一种非生成式的新网络结构,采用“变形”的方式来进行点云补全。具体来说,PMPNet++通过多步移动残缺形状的每一个点来完成从残缺点云到完整点云的变形过程,但是在此过程中不可避免会造成特征向量的信息缺失致使几何形变。最近,LAKNet[15]提出一种新颖的拓扑感知点云补全模型,通过对齐关键点定位,表面骨架生成和形状细化,恢复缺失点云。LAKNet基于几何先验和关键点设计了一种名为表面骨架的新型结构,从关键点捕获信息来表示完整拓扑信息,却难以应对原始形状的拓扑缺失情况。根据上述内容,不难发现现有的点云补全方法虽然在点云补全任务中已经取得一些成果,但仍存在对点云局部几何信息提取不充分,在解码时往往只是使用单层全连接结构作为输出层去预测点云,造成局部几何信息丢失进而导致目标物体的细节补全效果较为粗糙等问题。
针对目前点云补全问题和研究现状,提出一种双分支结构的多层级点云补全网络。网络整体采用编码器-解码器的结构。在编码器中采用双通道设计,同时对输入点云的全局特征和局部特征进行提取,不仅关注全局几何信息而且注重局部结构信息,有助于学习输入点云的特征。使用在多层感知机(multilayer perceptron,MLP)的基础上进行优化的五层联合感知机(five levels combinate perceptron,FLCP),将特征映射到不同维度并整合包含丰富特征信息的特征向量,促进点云特征的提取和编码。解码器使用从上到下的层级结构,利用三层全连接层去逐层预测点云形状,充分保留输入点云的原始结构。采用多层补全损失函数和基于鉴别器网络的对抗损失函数更加合理地评估模型误差,不断优化网络。实验证明,这种网络结构既能在特征提取阶段获取相对全面且具有代表性的语义和几何信息,又能够将提取到的特征信息有效地运用在预测点云形状的过程中,更加准确、细致地恢复残缺点云的形状,取得较好的补全效果。
1 相关工作
根据点云补全所采用的网络结构,将现有算法分成四种,分别是基于点、基于图、基于卷积、基于Transformer模型的方法。
基于点的补全方法主要通过利用MLP独立地建模每个点来实现,依据点云的变换不变性通过对称函数(如最大池化)聚集全局特征,然而整个点集中的几何信息和相关性却没有被充分考虑。由PointNet 首创并使用MLP 来处理和恢复点云。PointNet++和TopNet[16]结合了分层结构,用以考虑几何结构。Yu等人[17]受PointNet和PointNet++的启发,提出了PUNet(point cloud upsampling network),通过基于亚像素卷积层的特征缩放来学习多尺度特征。因为PUNet 主要用于从稀疏点云聚类生成单个密度更高的点云而不是完整点云,所以既无法填充大洞和缺失的部分也不能向点云的重采样部分添加有意义的点。另外,为了减轻MLP 带来的结构损失,Groueix等人[18]提出AtlasNet通过评估一组参数曲面元素重构完整输出,从中可以生成完整的点云。然而,基于点的方法也有一定的局限性。虽然其可以在局部水平上独立地处理点以保持排列的不变性,但同时忽略了点和其相邻点之间的几何关系,导致了局部特征的丢失,无法合成复杂的拓扑,在大型场景中不如基于卷积的方法。
由于点云和图像数据都可以看作非欧几里得结构(non-Euclidean geometry)的数据,通过将点或局部区域作为一些图的顶点来探索点或局部区域之间的关系是非常方便的。作为一项开创性的工作,Wang 等人[19]在DGCNN(dynamic graph convolutional neural networks)中引入了一种动态图卷积方法,在动态图卷积中,相邻矩阵可以通过来自潜在空间的顶点关系来计算。Hang等人[20]设计了一个基于图形注意的跨区域注意模块(cross regional attention network,CRA-Net),该模块量化了特定上下文中区域特征之间的潜在联系,并通过全局特征进行解释,每个条件区域特征向量都可以作为图的注意进行搜索。但是,构建基于图的网络仍存在以下两个挑战:第一,定义一个适合于动态大小邻域的算子,并维护CNN 的权重共享方案。第二,利用每个节点的邻居之间的空间和几何关系。
受卷积神经网络(convolutional neural networks,CNNs)在二维图像上的取得巨大成功的影响,一些工作尝试利用三维CNNs 来学习三维点云的体素化表示。然而,将点云转换为3D 卷积将会带来量化效应造成细节的丢失,难以表示细粒度的信息。因此,一些工作直接将CNNs应用于不规则、局部和缺失点云上进行三维形状补全。其中,Hua等人[21]在规则的三维网格上定义了卷积核,将这些点在同一网格中给予相同的权值。Chibane 等人[22]设计的隐式特征网络(implicit functions network,IFNets)用来处理拓扑结构,不但能够提供连续且完整的3D 形状,而且可以保存大量提取的隐式函数的信息在恢复细节信息上有非常好的表现。然而,卷积过程体素化会导致几何信息的不可逆损失。因此,Xie等人[23]引入了网格残差网络(gridding residual network,GRNet),并将三维网格作为中间表示来调整不规则点云。GRNet 采用Gridding 操作将无序的点云规则化至3D 网格,再经Gridding Reverse 转换回点云后由Cubic Feature Sampling从三维特征图中抽取点云中点的特征并保留上下文信息,但是GRNet的网格化表示仅适用于重建低分辨率的形状。为此,Wang 等人[24]开发了一种利用边缘生成的体素化补全网络,将无序点集转换为网格表示,以支持边缘生成和点云重建。但是基于体素三维数据表示仍存在一些局限性,通常包含扫描环境中非真实存在的部分,导致无效数据消耗计算机存储。其次,体素或网格的大小难以设置,不但影响输入数据的规模而且可能会破坏点之间的空间关系。
Transformer[25]最初被提出用于自然语言处理中的句子编码,之后在二维计算机视觉、领域流行起来。由Pointformer[26]、Point Transformer[27]首创的Transformer已经开启了点云处理的篇章。Yu 等人[28]认为点云补全是一个集到集的转换问题,因为基于Transformer 模型具有学习能力强且能够提取点之间相关性特征的优点,于是提出了一种用于点云补全的Transformer 结构,将点云表示为一组具有位置嵌入的无序点并设计了模拟局部几何关系的几何感知块。Lin等人[29]提出了一种在AtlasNet 的基础上融合Tansformer 的改进算法,利用Transformer的注意机制提取点云内的局部上下文,基于变形图集的点生成网络来预测缺失区域。然而,基于Transformer 的补全方法仍有不足,Transformer 参数的数量太大导致不易在设备上部署,而且Transformer 增强性能的机制难以解释。
综上所述,已有算法在特征提取过程中难以同时兼顾局部特征和全局特征,往往忽视局部几何信息的捕捉。为此提出了双分支结构的多层级点云补全算法,以缓解基于点的补全算法因为缺乏点云的局部特征导致无法恢复详细的形状和细微结构,从而影响点云补全精度的问题。
2 本文算法
2.1 算法整体架构
双分支结构的多层级点云补全算法架构如图1 所示,其主要功能模块是:
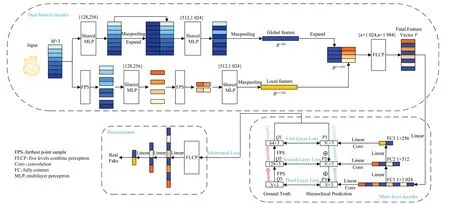
图1 基于双分支结构的多层级点云补全网络Fig.1 Multi-level point cloud complement network based on dual-branch structure
(1)双分支编码器。为了更好地提取部分点云的特定特征,提出了一种双分支编码器,分别提取点云的共性特征和个性特征,在学习对象的整体特征的同时又能够有效学习局部细节和特性。优化多层感知机为五层联合感知机,能够从部分点云的特征点中提取多维特征,这些多尺度特征包括低层特征和高层特征,增强了网络提取语义和几何信息的能力。
(2)多层级解码器。多层级的解码器利用三层全连接层以不同分辨率去分层预测点云,可以保持原始部分的空间排列和几何特征,有助于网络更好地感知缺失部分的位置和结构,恢复原始细节形状并生成高质量的缺失区域点云。
(3)联合损失函数。多级补全损失使网络更加关注特征点,基于对抗结构的鉴别器能够进一步改善同一类别不同物体间的特征会相互影响的问题,补全算法结合对抗损失和多级补全损失去优化网络,使ShapeNet数据集上的补全精度有了明显提升,呈现出更细致的可视化结果。
图中Shared MLP表示共享多层感知机,Maxpooling表示最大池化操作,Expand表示扩展操作,{}表示特征维度,FC(fully connected)表示全连接层,Linear表示线性层,N、N1、N2分别表示三层输出点云的数量,P1、P2、P3 表示不同分辨率的预测点云,Q1、Q2、Q3 表示不同分辨率的真实点云。网络采用双分支结构的编码器和多层级的解码器,引入鉴别器网络去判别真假点云并优化网络。编码阶段,将残缺点云作为输入,经过第一条通道PointNet网络逐点提取特征,获取点云的全局特征;同时经过第二条通道PointNet++网络对点云的局部特征进行提取,将提取到的全局和局部特征进行拼接和融合,使其扩展成维度统一的特征向量,然后通过五层联合感知机对特征向量进行编码并输送到解码器。解码阶段,特征向量经过从底端到顶端三个全连接层构成的多层级解码器,在每个全连接层中以不同的分辨率预测点云。最后,鉴别器网络将预测的缺失点云与真正缺失点云进行比较去构造对抗损失函数,并结合多级补全损失函数联合训练网络,通过最小化整体损失函数去不断优化网络。实验证明,这种网络结构既能在特征提取阶段获取相对全面且具有代表性的语义和几何信息,又能够将提取到的特征信息有效地运用在预测点云形状的过程中,更加准确、细致地恢复残缺点云的形状,取得较好的补全效果。
2.2 双分支编码器
由于点云补全任务往往要求网络基于潜在特征输出更准确、更复杂的结果,这意味着局部特征提取的波动很可能导致误报,所以现有的方法试图从部分点云的局部相邻点提取特征,通过牺牲局部特征提取提供的详细信息以保证全局特征提取提供的稳定。然而,在特征提取过程中上述方法总是难以平衡全局和局部特征,从而影响特征提取效果,因此具有局部特征感知模块的网络能够更好地重构目标对象的细节。事实上,PointNet的作者曾尝试在编码器中引入局部特征提取,但结果表明其性能不如仅使用全局池化的基于PointNet 编码器的方法。研究发现在PointNet 的主干中添加局部特征感知模块将明显改善点云分类或分割的网络性能,但是上述有效的点云生成和补全方法仍然坚持全局特征提取。为此,提出基于双分支结构的编码器,该编码器在全局特征提取网络PointNet 的基础上添加独立的局部特征提取单元PointNet++,使得网络对空间结构的细节更加敏锐,增强点云补全网络学习局部细节和特性的能力。
现有的大多数提取点云特征的方法,往往能够做到较好地提取全局特征,但又会不可避免地忽视局部几何信息的获取;或者关注局部特征提取的同时又无法对全局特征达到较好的提取效果。双分支编码器组合全局特征提取模块(PointNet)、独立局部特征提取模块(PointNet++)和五层联合感知机(FLC-P)模块三部分,通过并行的两个独立路径分别提取点云特征,有效避免在提取点云特征的过程中两者的相互干扰,既能提取到高质量的全局特征又能保证局部特征学习的准确性,将输入的点云数据中的几何信息编码为用于指导生成完整点云的最终特征向量。
第一部分采用PointNet网络提取点云的全局特征,结合逐点的MLP 和对称聚合函数,保证点云空间排列的不变性和扰动的鲁棒性,有利于在点云上进行有效特征学习。网络输入M个无序点云,构成M×3 的三维坐标矩阵,由共享多层感知机先将每个点坐标映射为{128,256}特征向量并构成特征矩阵,然后执行逐点Maxpooling得到初级全局特征,再将获得的初级全局特征与特征矩阵进行扩展和拼接生成特征增强矩阵并送入共享多层感知机,由MLP 进一步逐点映射为{512,1 024}维度的特征向量,接着再次采用最大池化操作得到1 024维的全局特征向量vi∈R1024,R 表示特征维度。
第二部分遵循PointNet++网络结构通过对输入点云的几个局部区域进行迭代最远点采样[30],单独提取局部特征,以此来独立编码局部特征向量。在第一个迭代最远点采样(FPS)层中,将局部区域的点数下限设置为8来保证局部特征提取的稳定性,将采样到的点经MLP逐步映射为{128,256}维度。接着,继续最远点采样过程,直到选择n个密集区域,同样利用共享多层感知机和最大池化对特征向量进行编码,最终提取n×1 024 维局部特征向量vj∈R1024,其中n表示区域个数。之后,网络将全局特征向量进行扩展形成与局部特征向量同等大小的向量并与独立提取的局部特征进行拼接,再将拼接后的特征向量送入五层联合感知机,组合五层维度的特征向量形成包含低级和高级特征信息的最终特征向量V∈RK,K=n×1 984,如公式(1)所示:
在之前的大部分工作中,将MLP 作为特征提取的编码器,每个点映射到不同的维数并直接从最后一层的感知机中提取最大值,形成全局特征向量。但是,这种方法不但忽视了前几层感知机的特征信息,而且根据L-GAN 和PointNet 可知该特征提取器的性能受到最大池化层的维数的强烈影响,进而限制下游任务的开展[31]。
为此,设计FLCP 结构如图2 所示。区别于MLP 使用最后的单层来提取特征向量,FLCP 依据编码过程中点云映射的维数,将特征点的信息编码成多个维度,在不同维度的五层{64,128,256,512,1 024}中均使用最大池化操作提取多层特征进而获取多维特征向量。这种结构不但充分考虑到了每一层感知机的特征信息,而且积极缓解最大池化层的维数对特征提取器性能的干扰,为后续特征解码提供帮助。
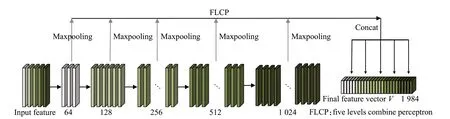
图2 五层联合感知机Fig.2 Five levels combine perceptron
2.3 多层级解码器
目前在解码阶段,大部分补全方法都是通过最后一层的全连接层来预测点云,导致只保留了全局特征而未充分利用提取到的局部特征[32],影响点云补全效果。另外,之前的方法总是从不完整的点云生成点云的整体形状,总是改变现有的点伴随着噪声和几何损失。为了更好地重建缺失点云,本算法设计了多层级的特征解码结构,将不完整点云作为输入,只输出缺少部分的点云而不输出整个物体。这种架构不但能够保留修复后的原始点云的几何特征而且有助于网络集中感知缺失部分的具体位置和细微结构。与现有的点云补全网络不同,多层级解码器针对编码器传递的特征向量进行不同维度的解码,充分利用多维度的特征信息,从稀疏到密集分层逐步完成点云补全操作,最大程度恢复缺失区域的详细几何结构,促进网络生成高质量的点云。
多层级解码器以最终特征向量V作为输入,对获取的特征进行降维,分层解码特征向量,输出三种尺度的点云数据。在解码过程中,最终特征向量V经过Linear在三层全连接层获得三个子特征向量{256,512,1 024},子特征向量遵循自顶向下的顺序,在每层采用卷积和线性变换操作得到64×3、64×2×3、128×4×3的特征矩阵,在各个层级间采取用扩展、添加操作和尺寸调整等操作,将上层结构中低分辨率的信息逐级传递给下层结构以此来补充语义信息用于高分辨率的预测。其中,第一层预测包含整体关键信息的主要点云P1,第二层预测中级点云P2,第三层预测包含更多细节信息的点云P3。多层级解码器采用分层解码结构在每个层进行单独预测,利用连续的层级结构渐进式增强下层必要信息,在上层预测点的基础上不断生成新的点云,通过监督每一阶段的点云来逐步提升预测点的质量,最后整合全部的预测结果生成从粗略到细致的点云,实现形状补全,具体过程如图3。

图3 分层预测点云Fig.3 Hierarchical prediction point clouds
根据图3可知,多层级解码器借鉴图像处理中经典的尺度不变特征变换算法[33],采用特征金字塔加粗样式的方式,对编码出的特征进行多尺度的解码,生成不同分辨率的点云。这种解码结构有效运用多种维度信息,通过三个联合层产生逐级递增的预测,输出不同数量的点云,使得预测结果具有更少的畸变,合理改善了点云补全精度较低的现状。
2.4 损失函数
本算法的损失函数由是多层级补全损失和对抗损失构成的,设置倒角距离(CD)和搬土距离(E-MD)[34]用来评估模型的预测值与真实值的误差大小。Q表示真实点云集合,P表示生成的点云集合,x、y是Q、P中的点云。在使用倒角距离计算补全损失时,先是对于P中的每个点找到其与Q中距离最近的点,计算欧氏距离后求和取平均,作为距离公式的第一部分;然后第二部分相似,对于Q中的每个点,找到其与P中距离最近的点,计算欧氏距离后求和取平均。其计算公式为:
搬土距离要求两点之间存在点对点单一映射,φ表示映射函数,其计算公式为:
多层级解码器预测出三种不同分辨率的点云,由此产生的多级补全损失Lcom包括式(2)中的三项,dCD1、dCD2和dCD3,利用超参数g加权。多级补全损失的设计增加了特征点的比例,使得网络更好地关注特征点。dCD1代表预测的骨架点与对应的真实点云之间的实际距离,dCD2、dCD3分别计算中级点云和细节特征点云与对应真实点云的损失。生成点云和真实点云之间的差值越小,表示点云补全的效果越好,质量越高。计算公式如下:
式(5)用于计算对抗损失,其中Ladv表示对抗性损失使用交叉熵损失计算,其中S表示Q、P点集的大小,i表示数据集中的点,在训练时使用Adam 联合优化生成点云网络和鉴别器D。
设计的鉴别器结构类似简化的FLCP,对MLP最后三层{64,128,256}进行最大池化操作得到特征向量,然后连接特征向量经过三层全连接层{256,128,16,1},最后通过sigmoid 分类器预测真假点云,输出二值结果。在计算整体损失函数时,对多级补全损失和对抗损失进行加权,设置权重τcom+τadv=1,L表示整体损失函数:
鉴别器的主要作用是区分生成点云和真实点云,使用生成的点云去“迷惑”鉴别器,通过判定结果计算对抗损失并调整神经网络参数,以优化整个补全网络,其目标是最大限度地提高识别真假点云的准确率,指导网络生成高质量的点云数据,提高点云补全的性能。
3 实验分析与讨论
3.1 数据集
实验选用ShapeNet数据集,ShapeNet是一个由对象的三维CAD 模型表示的形状存储库[35],其包含来自多种语义类别的三维模型,注释丰富而且规模庞大,成为计算机图形学和视觉研究的大规模定量基准。
在基准数据集ShapeNet中使用13类不同的对象来训练模型,将其中80%作为训练集,20%作为测试集,分别从包、飞机、滑板、耳机、帽子、汽车、桌子、杯子等类别中提取了模型,逐个训练每个类别的补全网络。在每个形状上均匀地采样2 048 个点来生成真实点云,在多个视点中随机选取一个视点作为中心,通过从已有的完整数据中去除一定半径内的点来获取不完整点云数据。对于每个模型,在实验中选用缺失率为25%的点云数据进行训练和测试,所有输入点云数据均以原始点为中心,将坐标归一化为[-1,1]。
3.2 实验设置
在Pytorch 框架上训练网络,进行了400 个周期的培训,批处理大小为36,使用初始学习率为0.000 1 的Adam优化器(adaptive moment estimation),编码器、解码器以及鉴别器均通过使用Adam 优化器进行交替训练[36]。在鉴别器中使用批归一化和正则化激活函数[37],加快模型收敛速度,但在多分辨率解码过程中,每个共享MLP 的隐藏层均采用RELU 作为激活函数,只在最后一层使用线性激活函数[38]。训练过程是在一台32 GB的Nvidia Quadro RTX 6000 GPU上实现的,配置深度学习环境为python3.6.13、cuda10.0、cudnn7.6.0。
设置PointNet 网络中第一个共享MLP 为{256,512},第二个共享MLP 的参数为{512,1 024};设置PointNet++中第一个共享MLP 为{256,512},第二个为{512,1 024},设置n=16;在解码阶段,根据每个形状的点数,通过改变N来控制最终预测点云的数量,设置N1=64,N2=128,N=512。
4 实验结果与分析
将本算法在ShapeNet数据集上的补全结果可视化,并与GRNet、PCN、3D-Capsule[39]、PFNet、SnowflakeNet[40]以及PMPNet++的补全结果相比较。GRNet设计了网格和网格反向方法将点云转换为三维网格解决点云体素化时引入量化误差从而丢失物体细节的问题,同时提出了立方特征采样层来提取相邻点的信息同时保存上下文知识,用于更好地补全缺失点云。PCN连续使用两个PointNet层对特征信息进行编码,在解码过程中采用折叠操作,先将一个规范的二维网格变换到三维空间,再变形成点云的表面形状。折叠操作本质是一个通用的二维到三维的映射,PCN以自监督的学习策略由粗到细的方式生成密集的完整点云。3D-Capsule 是一种无监督的胶囊网络,用于学习非结构化三维数据通用表示的自动编码器,采用类似PointNet的输入层来考虑点云的稀疏性,通过一个无监督的动态路由协议算法提供支持,尊重各部分之间的几何关系,显示出较好的学习能力和泛化属性。PFNet 只使用部分点云来预测缺失点云,通过降采样方式提取不同分辨率的点云特征,利用基于特征点的多尺度分层网络生成点云。SnowflakeNet将完整点云的生成转换成一种显式的且具有局部结构化特性的分裂过程,设计雪花反卷积(SPD)用于渐进地增加点数,通过按点分裂操作将父节点的形状特性转移到子节点当中,同时引入Skip-Transformer 用于捕捉局部形状特性和相邻SPD 之间的分裂模式,从而使SPD之间能够相互协作,并更好地生成具有良好细节特征的完整点云。PMPNet++整体上由三层点移动模块(PMD-module)组成,每一层PMD模块为点云预测逐点偏移向量从而达到变形补全的目的。相较于之前的PMPNet,PMPNet++在每一层PMD 模块的编码阶段引入Transformer,帮助网络利用注意力机制来更好地捕捉形状上下文信息,从而提高补全性能。
由于上述方法都是在不同的数据集中训练的,为了便于定量评价分析,实验采用同一数据集ShapeNet并按照相同方式对所有方法进行训练和测试。
4.1 ShapeNet补全结果
使用本算法对ShapeNet 数据集上的残缺点云进行补全测试,将倒角距离和搬土距离作为评价指标,倒角距离在训练形状补全网络时侧重整体的网络结构,搬土距离则是以局部细节为关键。计算得到的结果越小,表明网络预测生成的完整点云与实际点云越接近,网络补全点云的性能越好。误差主要分为前后两部分,前面是预测点云指向真实点云的误差(P→Q),用于衡量预测与真实情况之间的差异;后面是真实点云指向预测点云的误差(Q→P)可以反应真值表面被预测点云覆盖的程度。
不同方法下整体点云的CD 结果如表1 所示,每个倒角距离均乘以103,可以明显看出本算法在大多数类别上的性能都优于其他现有方法,除去汽车、电脑、滑板这些类别外,剩下的10 个类别均较其他方法中的最好结果有所提升,误差平均值也降低至0.519/0.385。
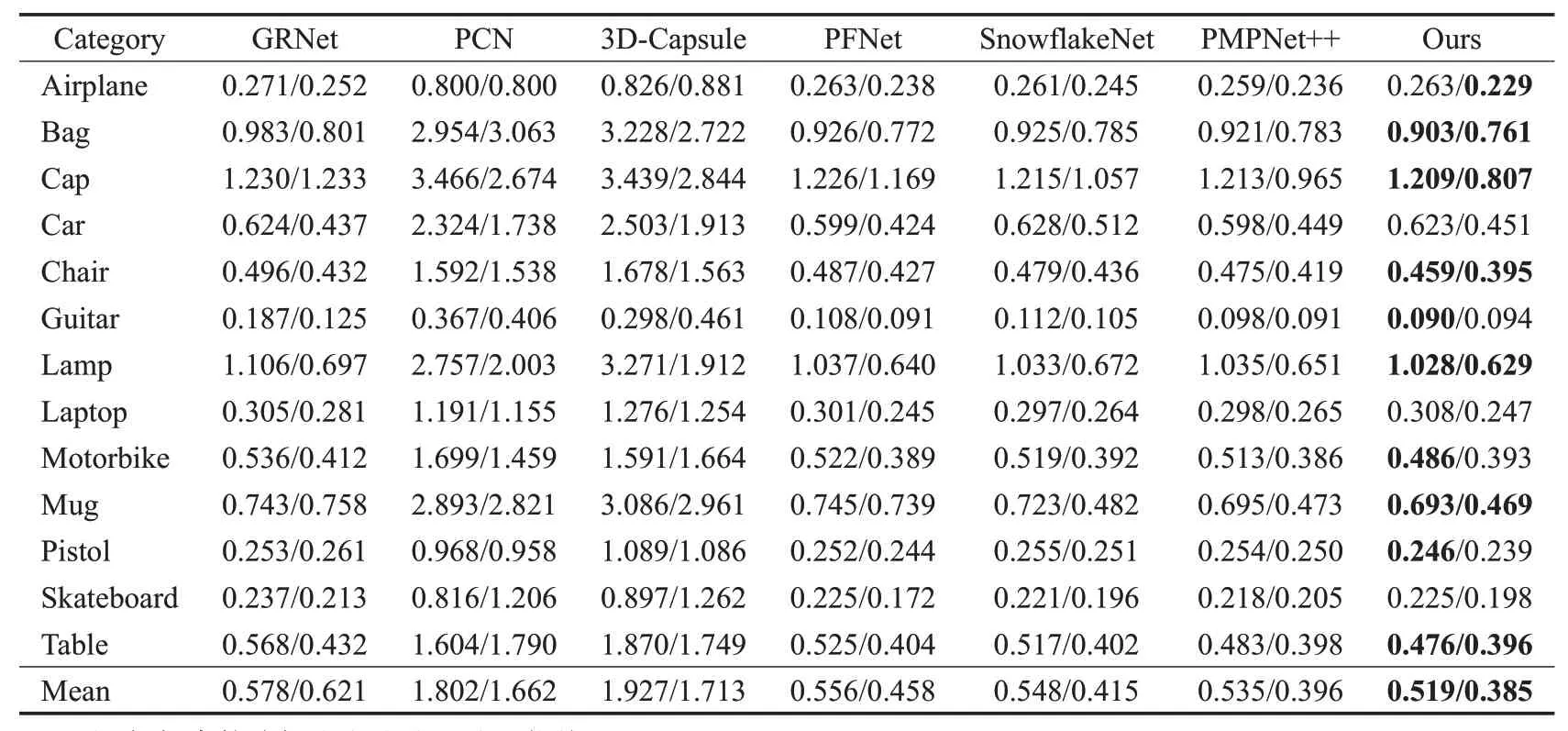
表1 不同方法下整体点云的倒角距离(dCD)Table 1 Chamfer distances of overall point cloud under different methods (dCD)
不同方法下整体点云的EMD 如表2 所示,每个搬土距离均乘以102,本算法在九个对象的补全过程中的预测点云指向真实点云的EMD 数值均小于其他方法,同时平均EMD也有所改善。这是因为多层级解码结构更有利于捕捉点云中逐点间的相关性信息,能够在补全过程中将核心放在关键性结构的生成上,而不是只关注如何降低点云EMD值。
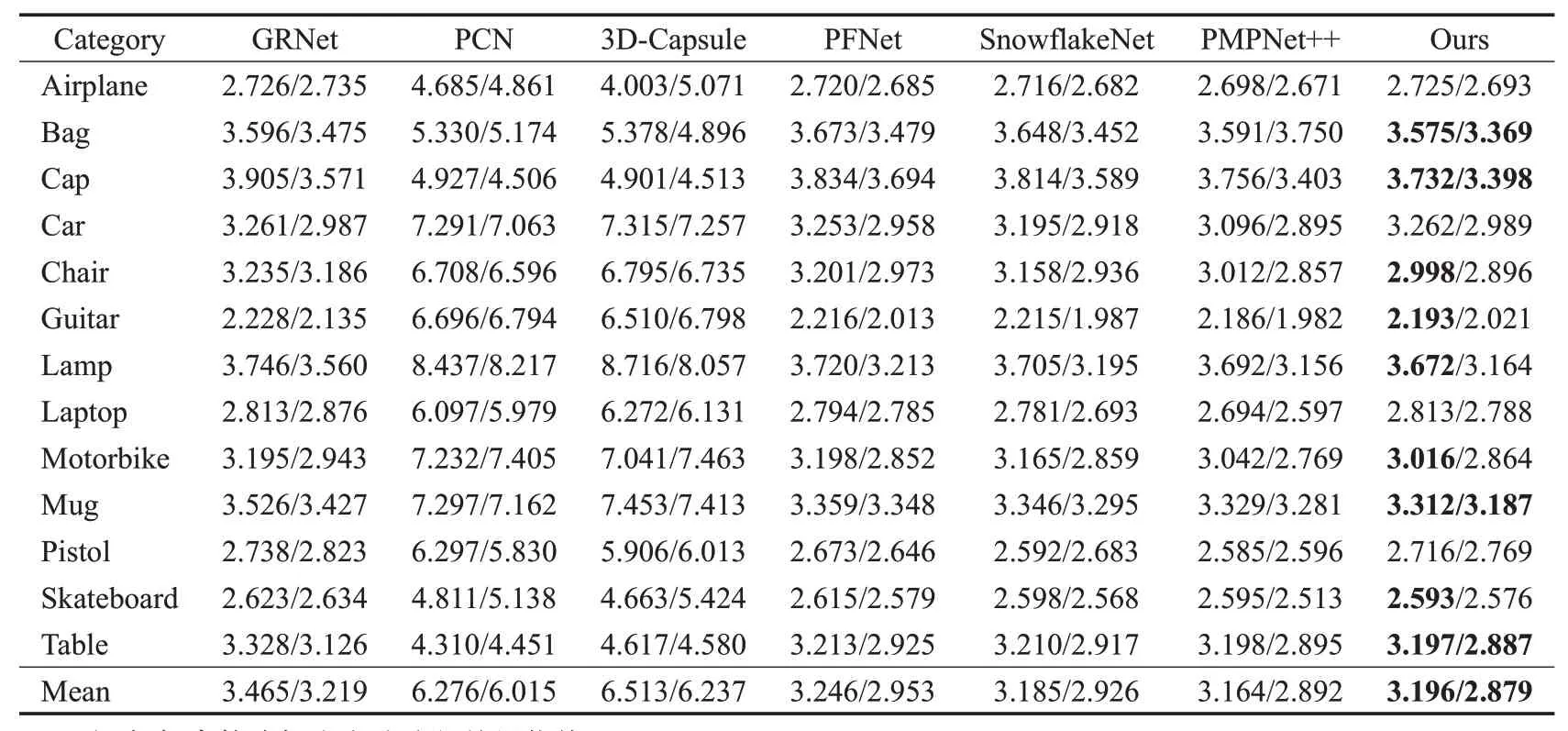
表2 不同方法下整体点云的搬土距离(dEMD)Table 2 Earth mover’s distances of overall point cloud under different methods (dEMD)
上述表格中整体点云补全产生误差由缺失区域的预测误差和原始部分形状的变化两部分组成。由于实验过程中将物体的部分形状作为输入,只输出缺失区域的点云,保留原有部分的形状而没有经过调整,因此表3同样计算了缺失区域误差以保证模型评估的合理性。具体来看,网络在飞机、包、帽子、椅子、吉他、台灯、杯子、滑板和桌子等九种类别的CD值优于其他网络,结果证明本算法无论在整体点云还是缺失区域点云的补全任务中,都可以生成精度更高、畸变更小的点云。

表3 不同方法下缺失区域的倒角距离(dCD)Table 3 Chamfer distances of missing regions under different methods (dCD)
比较六种方法与本算法在ShapeNet 数据集的补全性能,其可视化结果如图4 所示,图中依次包括残缺的输入点云、经过PCN、3D-Capsule、PFNet 和本算法得到的补全点云,以及对应的真实点云。
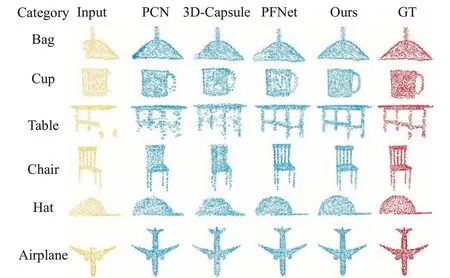
图4 不同方法下点云补全结果可视化Fig.4 Visualization of point cloud completion results under different method
其中,PCN 关注全局特征,解码时融合两种操作产生由粗到细的点云,但由于对局部特征的提取不充分,面对一些包含细微表面的物体时无法完整恢复这些结构,而且存在预测点云在空间中的分布不均匀的现象,如桌腿和带有空隙的椅背。3D-Capsule 运用自动编码器,在处理稀疏的3D点云的同时,能够有效保留输入数据的空间分布,相比其他自动编码的方法,其分类的精确度更高,但在面对原始表面较为复杂的补全任务时,会造成过度填充缺失结构的问题,进而导致物体形状失真。PFNet虽然利用多个全连接层输出预测结果,使点云生成过程更为平稳,但在编码时仅是在输入点云的基础上不断进行下采样提取特征,没有真正意义上学习到点云的全部局部特征,所以对一些细节结构进行恢复时产生结构连接断裂或错误补全结果,如杯子的手柄。本算法基于双分支编码器,独立编码全局特征和局部特征同时利用五层联合感知机获取多尺度特征信息,最后采用分层解码结构由粗糙到详细预测出三种规模的点云。在图中可以明显看出本算法的补全效果更好,针对不同类别的物体均给出了更精细的结果,始终提供一个平滑的全局形状(如包的边缘轮廓),且输出的点云在空间分布上具有较好的均匀性,很好地保留了输入点云的细节特性(如条状镂空的椅背),较大程度地提升了点云补全的性能。这说明本算法的重建能力强,预测的点云形状具有很强的空间连续性,对于细微结构也能实现较为精细的补全,有效提高了点云补全精度。
另外,在点云补全任务中GRNet虽然考虑了点云的空间结构和局部信息,但是在转换过程中容易造成特征信息冗余、增大量参数。SnowflakeNet作为一种局部结构化的点云生成方式,采用渐进式粗到细解码的方法进行补全形状,倾向于预测粗糙的缺失形状特别是对于具有平面或表面的几何图形。SnowflakeNet 虽然通过逆向卷积获取局部形状信息来更好地捕捉和还原物体的局部几何特性,但是忽视了全局信息的稳定性,产生局部聚集并生成散乱点。此外,PMPNet++将上层偏移特征将作为历史偏移信息来指导下次变形过程,不断整合当前与历史移动信息并传入下一层PMD指导下一次偏移,往往造成错误偏移信息持续传递,引发形状严重畸变。综上,本算法既能独立且全面地学习局部特征和全局特征,又能在不同层次上预测点云形状,拥有更精准的细微结构补全能力。
4.2 消融实验
为了进一步检验网络的合理性和有效性,使用不同缺失程度的点云数据来测试算法的补全性能。
实验选用飞机、椅子和桌子三个类别分别在三种缺失率25%、50%、75%下进行训练。考虑到网络的定量评价,通过改变解码器中的N来控制网络输出点的数量,以分别训练网络在多种缺失率下的修复能力。具体结果如表4,显示了本算法在测试集中的性能。
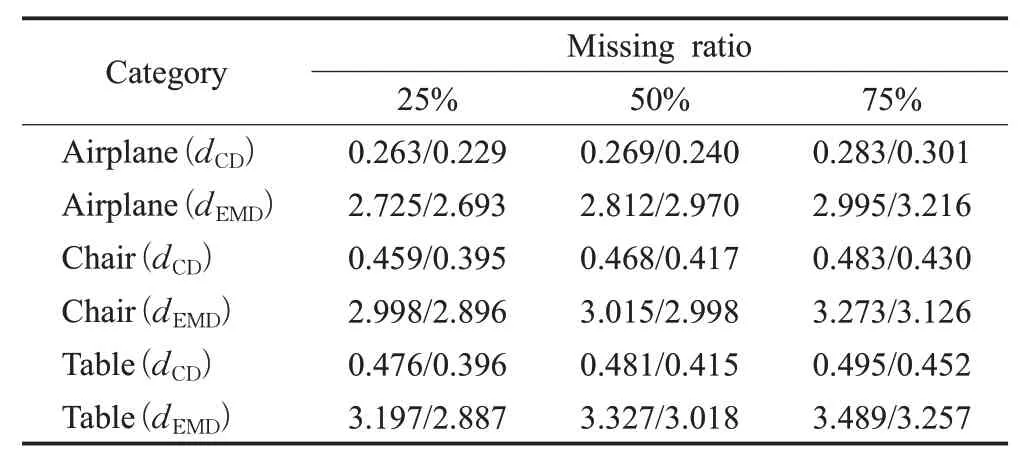
表4 不同缺失程度下点云补全性能Table 4 Point clouds completion performance under different missing ratio
图5 可视化了CD 值的变化过程,可以看出尽管输入点的数量相较于真实点云数据由25%逐渐减少至75%,网络的误差却始终保持相对稳定,没有呈现出较大程度的波动。实验结果表明,该网络在缺失大量点云时,仍然能够提供与残缺对象的真实形状非常接近的预测,这意味本算法无论是在稀疏还是稠密的点云空间分布下,都能够准确地识别并补全不同类别的对象,较大范围上保留了原始点云的几何细节,证明模型具有很强的健壮性,能够很好地适应各种数据缺失的情形,在点云补全任务中有较为出色的表现。
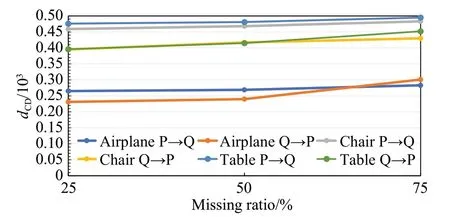
图5 不同缺失率下点云的补全结果折线图Fig.5 Visualization of point completion results under different missing ratio
为了评估网络中不同模块的性能,实验还分别统计了删除PointNet模块、删除PointNet++模块以及将MLP替换为FLCP的补全效果。保证网络其他结构不改动的基础上,进行了三个版本的消融实验。结果如表5 所示,单独使用PointNet 模块提取特征时,取得了最高的误差值,其CD 增加到0.605/0.568,EMD 扩大至3.429/3.353;单独使用PointNet++模块提取特征时其结果优于前者,CD 为0.595/0.559,EMD 为3.395/3.289;使用MLP代替FLCP 时,CD 达到了0.582/0.557,EMD 为3.314/3.282,取得了三组实验中的最优值。综上,无论是去掉PointNet 模块、PointNet++或者采用MLP 替代FLCP 都对点云的补全精度产生影响,表明三个模块对网络的补全性能均有所贡献。
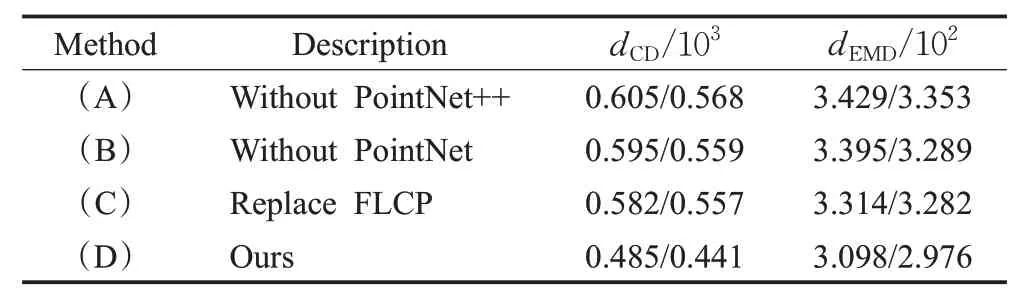
表5 消融实验的点云补全性能Table 5 Point clouds completion performance of ablation experiments
图6呈现了消融实验的可视化结果,完整的基于双分支结构的多层级补全网络的效果最佳。在图6(b)模型除去PointNet++结构补全椅子时,网络只关注整体形状的补全,对物体细节的恢复较差,难以给出相对平滑的预测形状。椅子边缘的点的空间分布较为稀疏,存在物体形状边界不清晰的现象,如两只椅子腿中间的横梁,说明了PointNet++模块能够加强网络对局部特征的学习能力。图6(c)删掉PointNet 结构的模型在进行补全时,整体轮廓较为分明,但对椅子靠背空白处产生错误填充且存在部分点聚集的情况,证明PointNet有助于本算法对全局特征的把握和对缺失对象的整体边框的还原。图6(d)显示了替换FLCP模块的补全效果,虽然在整体形状上已经非常接近真实值,但椅子周围仍有少量噪声点出现,椅背处存在模糊边界,说明F-LCP 在编码过程中能够充分获取点云数据的多维特征,有效提升了网络的重建能力。总之,上述三个模块都能够增强补全网络的预测能力,在本算法中有着十分重要的意义。
为了确定检验鉴别器网络在该结构中存在的必要性,在原有网络结构的基础上删掉鉴别器网络,实验结果如图7 和图8,分别是在相同条件不带有鉴别器网络的和带有鉴别器网络的CD 和EMD。根据图中数据所示,在大多数类别上带有鉴别器的网络的表现都要优于不带有鉴别器的网络,其平均损失函数值无论是CD还是EMD 都略小于不带鉴别器模型,说明引入鉴别器结构能够改善网络的补全效果,验证了其重要性。
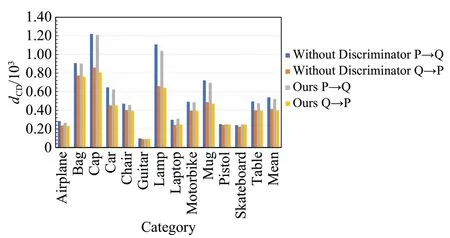
图7 带有/不带有鉴别器模块的CD补全结果Fig.7CD completion results with/without discriminator module
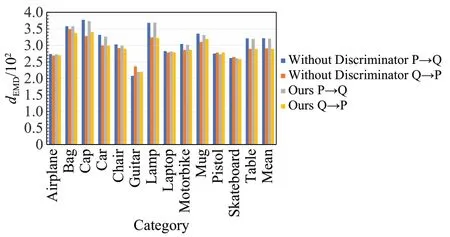
图8 带有/不带有鉴别器模块的EMD补全结果Fig.8 EMD completion results with/without discriminator module
5 结束语
在点云数据采集时,被测对象特性、测量方法和环境等因素可能会造成几何和语义信息的丢失,这就带来了点云数据缺失问题,论文以此为背景提出了一种双分支结构的多层级点云补全算法,有效解决了现有点云补全方法缺乏局部特征信息且仅从单一维度预测点云所造成的补全结果粗糙的问题。结合PointNet 网络和PointNet++网络构造双分支编码器,在并行的通道上独立地提取全局和局部特征,同时设计了多层级的解码器监督每一阶段的点云,以更好地保留不同维度的特征用于输出较高精度的预测结果,并且引入鉴别器促进网络优化。在ShapeNet上测试算法的补全性能,使用CD和EMD 去评估结果。实验结果表明,该算法生成的点云最接近地面真实值,不仅可以输出平滑的全局形状,而且可以提供尽可能多的细节,以更高的精度生成密集的完整点云,面对不同程度的点云数据缺失时仍能够高效地完成形状补全任务。
然而,模型针对汽车和台式电脑等一些表面结构较为复杂的物体补全时,在点的空间分布上存在部分点错误聚集而其余点较为分散的情况,甚至出现物体局部失真的现象。分析产生原因是网络缺少特征融合结构,对获得的全局特征和局部特征未能恰当选择和融合利用。之后将致力于构建特征融合模块去聚合局部和全局特征信息,以提高预测点云的均匀性和保真度,并尝试将该模型用于处理更复杂的真实点云场景。
猜你喜欢
通信学报(2022年10期)2023-01-09
九江职业技术学院学报(2022年1期)2022-12-02
数学物理学报(2022年4期)2022-08-22
数学物理学报(2022年2期)2022-04-26
保定学院学报(2022年2期)2022-04-07
国防科技大学学报(2019年4期)2019-07-29
金桥(2018年4期)2018-09-26
许昌学院学报(2018年4期)2018-05-02
中华建设(2017年1期)2017-06-07
系统工程与电子技术(2016年5期)2016-11-02
