
基于Transformer-LSTM网络的轴承寿命预测
2024-04-11 01:41姚德臣姚圣卓杨建伟王琰亮魏明辉胡忠硕
振动与冲击 2024年6期
张 帆, 姚德臣, 姚圣卓, 杨建伟, 王琰亮, 魏明辉, 胡忠硕
(1.北京建筑大学 机电与车辆工程学院,北京 100044;2. 北京建筑大学 城市轨道交通车辆服役性能保障北京市重点实验室,北京 100044;3. 北京交通大学 机械与电子控制工程学院,北京 100044)
现代机械工业大力发展,轴承的复杂程度、精细程度都有了很大的提升[1]。在实际工程应用中要保障轴承的安全运行,实际应用中需要实时掌握设备的运行状态,根据传感器所采集的数据进行预测。在过去的几十年里,机器维护策略已经从基于条件的维护策略发展为智能预测维护[2]。
随着近几年深度学习技术的快速发展,故障诊断方法得以快速提升。深度学习能够解决混合振动信号提取特征信息的问题,降低人工特征提取的难度[3]。当今的轴承寿命智能预测注重挖掘当前轴承状态数据与剩余使用寿命(remaining useful life, RUL)之间的潜在关系,这种数据驱动的方法已成为主流的轴承RUL预测[4]的方法。特别是随着深度学习[5]的突破性创新,该技术在轴承RUL预测[6]方面显示出了优势。在近些年的研究中,不同的研究者通过各自的研究将不同的预测方法应用于轴承寿命预测的领域中来,为轴承RUL预测提供了许多新方法。
Ren[7]等通过研究自动编码技术与DNN(deep neural network)结合,实现了对轴承寿命的预测。DNN神经网络能够较好地提取数据特征并进行预测,该网络经验能够实现预测精度的提升,为轴承寿命预测提供了新思路。Hinchi[8]等提出了一个基于卷积和长短期记忆时序神经网络(long short term memory, LSTM)循环单元的RUL估计的端到端深度框架。通过利用卷积层直接从传感器数据中提取局部特征,然后引入LSTM层来捕获退化过程,最后利用LSTM输出和预测时间值估计RUL。经过卷积神经网络特征提取的数据能为LSTM网络提供了特征更强的学习样本。但是,受制于LSTM的单向串行学习过程,数据在长时间尺度的预测中会出现梯度消散问题,导致特征的遗忘,数据泛化程低。Elsheikh[9]等为了提升LSTM网络的泛化性,提出了一种双向串行数据传递LSTM(bidirectional handshaking LSTM,BHLSTM)网络。该方法通过前向处理单元处理数据,并在最终状态开始反向处理。一定程度上提升了网络的预测性能。双向串行学习数据特征,更加满足RUL预测的需求。但是BHLSTM模型依旧是依靠串行处理方式对数据进行处理,双向学习只能一定程度上缓解特征的消散,解决这个问题需要将数据处理方式由串行转换为并行处理方式。
为了提升循环神经网络串行处理数据出现的特征消散的问题,姚德臣等[10]提出了一种基于注意力机制的门控循环单元(gated recurrent unit,GRU)神经网络预测模型。该方法通过在GRU计算之后的数据加入注意力机制,实现了网络的预测准确率上升。证明了在串行数据中引入并行特征提取单元能够提升网络预测性能。随着注意力机制的发展,一种完全基于编码与解码的Transformer自注意力神经网络于2017年被提出。该网络的提出深刻的影响了深度学习领域[11],研究者开始将Transformer应用于轴承寿命的预测。Transformer网络通过并行的编码层、解码层对信息进行学习,极大的提升了神经网络对信息学习的能力。
Mo等[12]引入经过Transformer编码层与门控卷积单元网络增强的卷积神经网络,实现了对NASA(National Aeronautics and Space Administration)公开航空发动机数据集C-MAPASS的寿命预测。其中在单工况双故障的FD003数据集的均方根差最小为11.42,较LSTM-FNN网络降低4.76。Mo等的研究为Transformer网络应用于轴承寿命RUL预测提供了支持。Transformer神经网络通过创新的多头注意力机制,能够更好提取轴承寿命数据特征,解决大数据预测时的准确率问题,提升预测的可靠性。随着Transformer系列网络的发展,越来越多的Transformer网络被提出,例如ViT(Vision Transformer)、Swin Transformer等网络。
Hao等[13]为了提升轴承预测精度,提升网络泛化性能,提出了一种双通道层次视觉Transformer(bi-channel hierarchical vision transformer,BCHViT)的滚动轴承RUL预测模型。文章通过将IEEE PHM 2012数据挑战赛数据集进行小波变换并转化为64×64图片放入BCHViT网络中,通过双时间尺度学习,一定程度上提升了网络的预测性能。Ding等[14]提出了一种将卷积模块与Transformer编码层结合的CoT (convolutional transformer)网络实现对轴承的信号特征进行全局和局部建模,提升了网络的特征提取能力,并同样在IEEE PHM 2012数据挑战赛数据集进行试验。最终证明改进网络能够提升轴承的退化。虽然Transformer系列网络的预测性能有了较大的提升,但是该系列网络依旧存在问题。Li等[15]指出Transformer网络在短时间序列预测问题上,存在预测效果不准确的问题。因此,本文提出了一种能够适应不同寿命时长的轴承预测神经网络Transformer-LSTM神经网络。该网络通过数据串并行结合的方式实现数据特征提取。在Transformer-LSTM网络中,Transformer负责数据并行处理,关注数据具体部分。在预测长寿命轴承时,能够保证特征不被遗忘,提升长寿命轴承预测精准度。LSTM负责数据串行处理,关注数据整体趋势。在预测短寿命轴承时,能够保证足够多的数据特征,提升短寿命轴承预测精度。
经试验验证,Transformer-LSTM网络拥有很好的泛化性与精度,能够实现跨数据集合的多组不同寿命时长的轴承寿命精确预测。
1 Transformer-LSTM网络搭建
1.1 位置编码层
编码层位于Transformer编码层之前,为模型运算提供对应的数据位置信息。在位置编码过程中,数据按照奇偶排列被分开,并分别赋予对应的数据的位置信息,位置编码如图1所示。计算公式如式(1)、式(2)所示
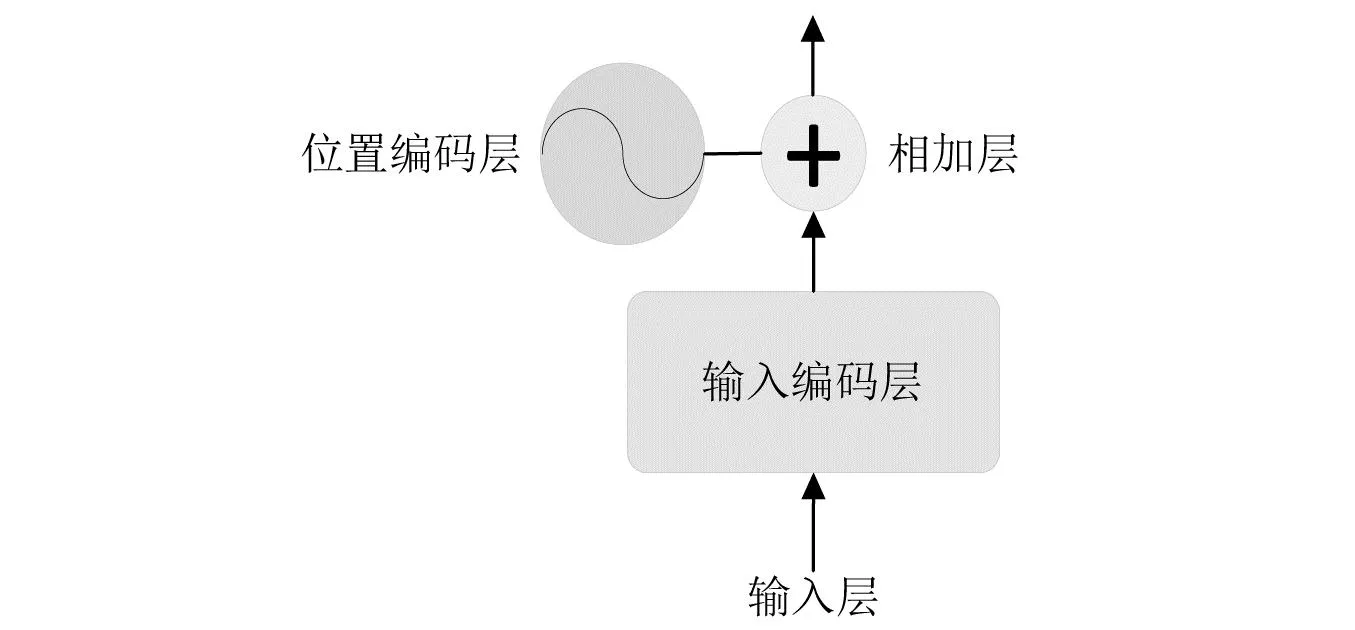
图1 位置编码层结构Fig.1 Positional encoding structure
(1)
(2)
式中:i为时间步长;s为维数;d为对应位置的数据编码。通过位置编码的原始数据被网赋予了顺序编码,从而实现学习位置信息的目的。在位置编码的最后需要将局部位置特征提取结果表示出来,公式如式(3)所示
fi=ei+pi
(3)
通过位置编码与局部特征提取的数据能够同时具有数据位置信息与特征信息,为Transformer编码层提供输入。
1.2 Transformer编码层
Transformer编码层能够为Transformer-LSTM网络提供具有注意力的数据,经过Transformer编码层处理的数据能够在长轴承寿命预测时提供更多的特征。数据通过Transformer编码层的点积运算从而产生对数据的注意力,并通过多个相同的Transformer编码层并行处理,实现对数据的预测。构成Transformer编码层的主要结构是多头注意力机制和前馈层。每个多头注意力机制和前馈层之后加入层规范化操作,经过层规范化处理的数据能降低梯度爆等问题,提升网络的稳定性。最后,在数据处理过程中一定程度地保留了原始数据特征,编码层加入了两个线性相加层,以此实现提升模型特征学习的效果。Transformer编码层结构如图2所示。
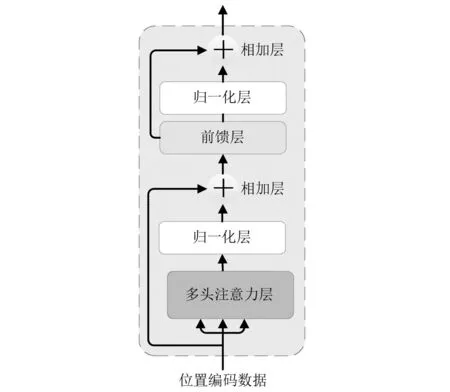
图2 Transformer编码层结构Fig.2 Transformer encoder layer structure
编码层核心部分为多头注意机制,这个部分是Transformer-LSTM模型实现精准预测的关键部分。多头注意实力机制由多个具有自注意力的头组成的。多头注意力机制中自注意过程可以描述为一个由查询向量和一组键-值向量矩阵求解的过程。其中查询向量(Q)、键向量(K)、权重向量(V)由之前一个输出转换而来。在实际运算中,模型同时计算一组查询向量上的注意力函数,并将其打包成矩阵Q,并将键向量和值向量打包成矩阵K和V。查询向量的输出结果实际上是由前一层编码的隐藏向量所决定的,矩阵K和V在自我关注中被赋予与Q相同的值。
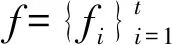
(4)
(5)
(6)
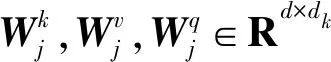
(7)
为了共同关注来自不同位置的不同表示子空间的信息,需要进一步优化,采用H个并行注意计算,在WA∈RHdk×d情况下,多头注意力机制计算过程如式(8)所示。
(8)
编码层的功能实现还经过了前馈层前馈网络由两个线性变换组成,中间通过一个ReLU激活函数相连接。它分别且相同地应用于每个时间步长。线性变换公式如式(9)所示。
y=WTx+b
(9)
1.3 LSTM解码层
本篇论文所提出的Transformer-LSTM网络模型的主要改进工作在于重构了原始Transformer的解码层。原始Transformer解码层能够,引入了Transformer解码层结构以适应自然语言翻译任务。但是在Transformer应用于时间序列预测领域时,解码层往往由线性层所替代,这样的预测模型在短数据集预测时会产生较大的偏差,因此本文提出了一种基于LSTM网络的重构解码层以提升网络的预测能力。重构的LSTM解码层由线性整流层、LSTM运算层以及全连接层所构成。其中核心部分为LSTM运算层。LSTM解码层如图3所示。
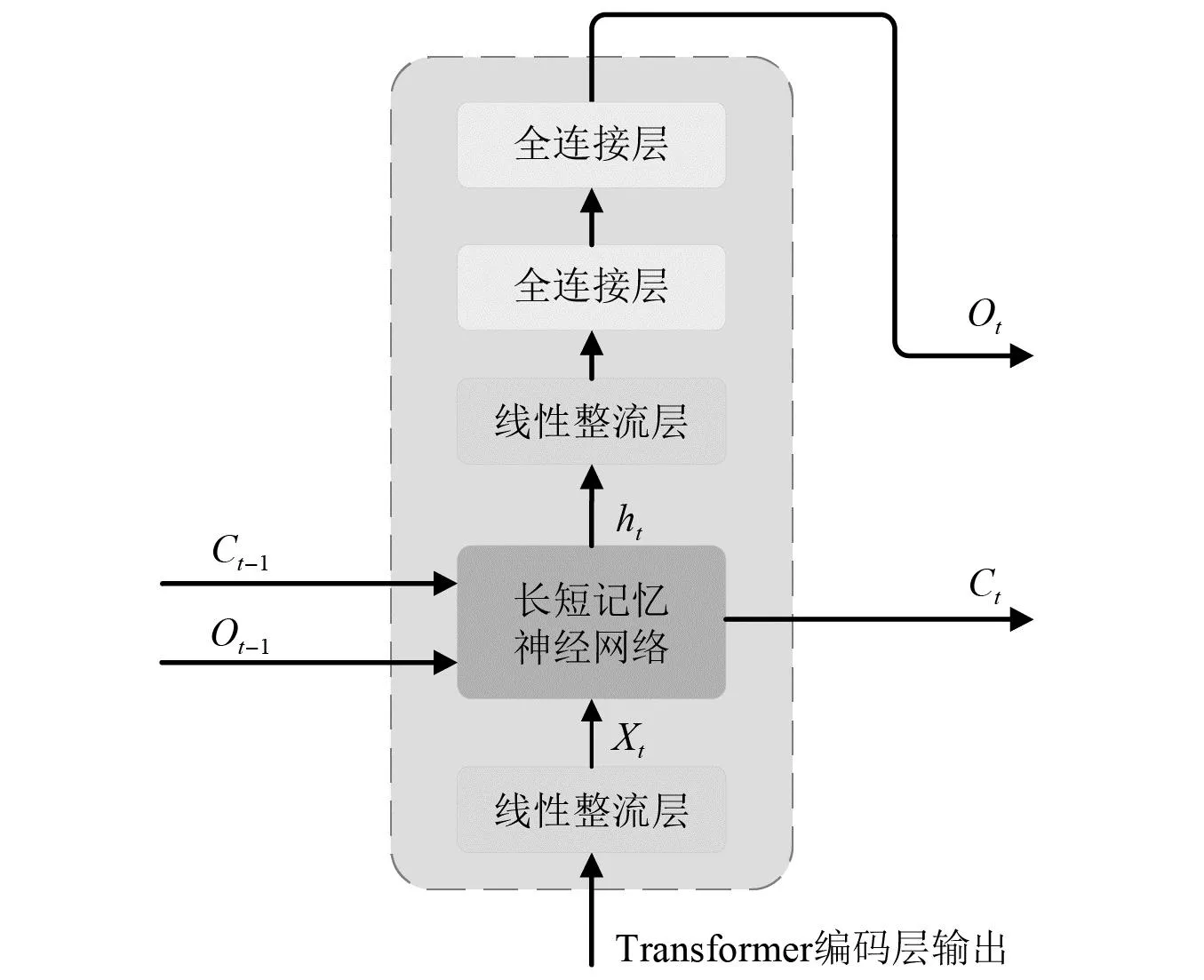
图3 LSTM解码层结构展示Fig.3 LSTM decoder layer structure
线性整流能够将Transformer编码层结果进行整流,将数据转化为匹配LSTM隐藏层的格式,从而为LSTM提供输入数据。
LSTM运算层由输入门、遗忘门、输出门以及细胞状态所组成。LSTM需要将Transformer编码层数据、上一时刻的隐藏层数据ht与上一时刻的细胞状态输出Ct作为共同输入,通过门控机制串行处理数据,实现对数据的处理[16]。LSTM网络结构如图4所示。
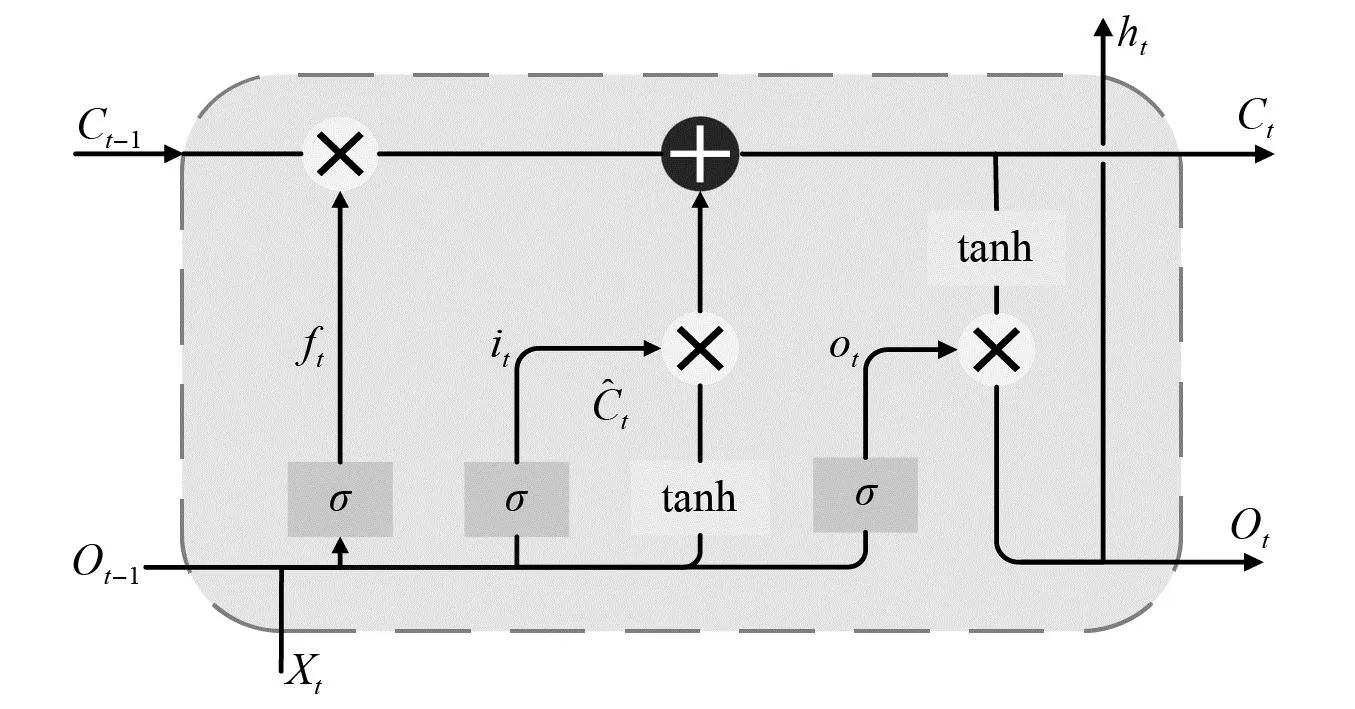
图4 LSTM网络结构Fig.4 LSTM neural network structure
数据在输入门中计算公式如式(10)所示
it=σ(Wi[ht-1,xt]+bi)
(10)
数据在遗忘门中计算公式如式(11)、式(12)所示
ft=σ(Wf[ht-1,xt]+bf)
(11)
(12)
数据在输出门中计算公式如式(13)所示
ot=σ(Wo[ht-1,xt]+bo)
(13)
经过三个门处理的数据,将会向下传递至两种记忆模块,在不同的记忆模块中,数据的长短期依赖性被选择处理,具体处理方式如下所示。
长记忆如式(14)所示
(14)
短记忆如式(15)所示
Ot=ot*tanh(Ct)
(15)
在重构的LSTM解码层输出结果之前,本模型引入了两个全连接层提升模型的鲁棒性,提升预测数据结果可靠性。
1.4 Transformer-LSTM网络整体结构
1.1节~1.3节介绍了Transformer-LSTM网络的位置编码层、编码层与解码层,本节将网络整体结构进行展示,并将数据流传递图进行讲解。
Transformer-LSTM网络处理数据的过程分为单元内数据处理与单元间数据处理。数据通过两种传递方式实现对轴承剩余寿命预测。其中单元内处理负责数据并行处理,单元外处理负责数据串行处理。
单元内数据处理依靠相互独立的位置编码层、Transformer编码层与本单元内的LSTM解码层。数据在单元内按照图5、图6中①路线前进,对每个时刻新的输入进行位置编码以及Transformer编码。经过编码的数据能够保留更多的特征,以保证在长寿命轴承预测过程中信号衰减程度降低,具体结构如图5所示。
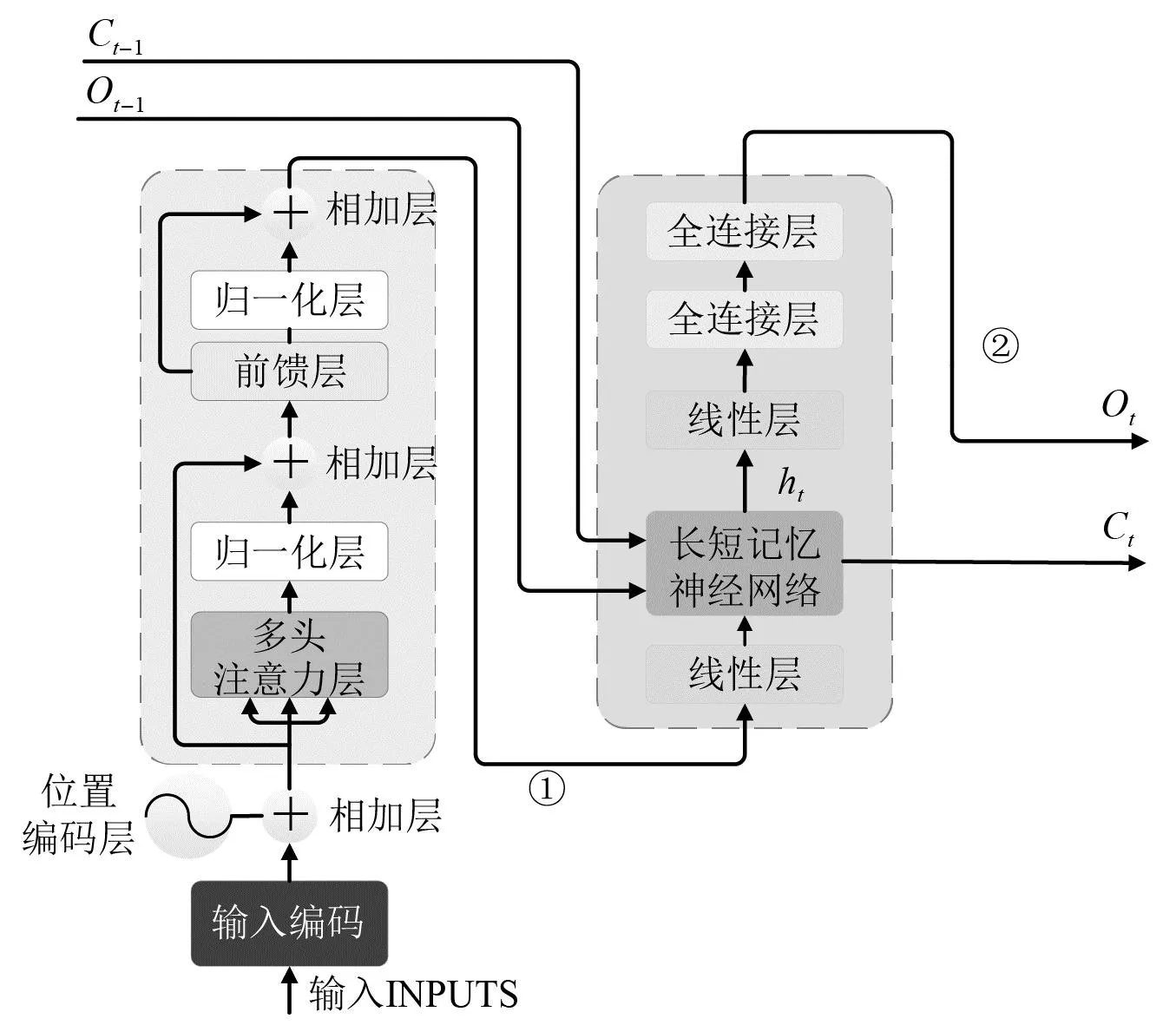
图5 Transformer-LSTM单元内网络结构Fig.5 Transformer-LSTM inner-unit network structure
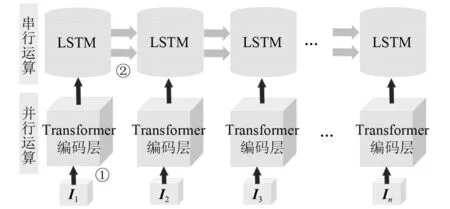
图6 Transformer-LSTM数据传递过程Fig.6 Transformer-LSTM outer-unit network structure
单元外数据处理依靠LSTM解码层实现,在LSTM网络中,时间序列能够被完整保存下来,这样的特点在短寿命时长轴承预测中将更多的时间特征保存下来,实现网络的串行数据处理能力,提升网络的预测性能。 在Transformer-LSTM单元外数据传递如图5、图6中②数据流所示。为了能更加直观展示网络的数据处理方式,本文搭建了数据传递模型图,如图6所示。
2 试验数据集构建
轴承寿命预测是根据轴承运行过程中所产生的信号的变化,通过特征提取、加工等方式,实现对轴承寿命的预测。一般来说,轴承寿命预测需要依靠轴承运行所发出的振动信号进行处理,通常来讲有方差信号、峰峰值、频谱信号、包络谱信号等多种信号处理方式[17]。
2.1 试验流程
本文构建的Transformer-LSTM模型通过以下的技术从而实现对轴承故障的预测,其中技术路线包括:①提取原始数据中提取多种时频域特征,并选择特征明显的指标作为特征数据集输入;②对特征数据集进行归一化处理;③搭建Transformer-LSTM模型;④训练集与验证集划分,训练集用于训练模型,验证集用于测试预测数据;⑤搭建训练-预测联合预测数据集并进行量化评估。技术路线如图7所示。
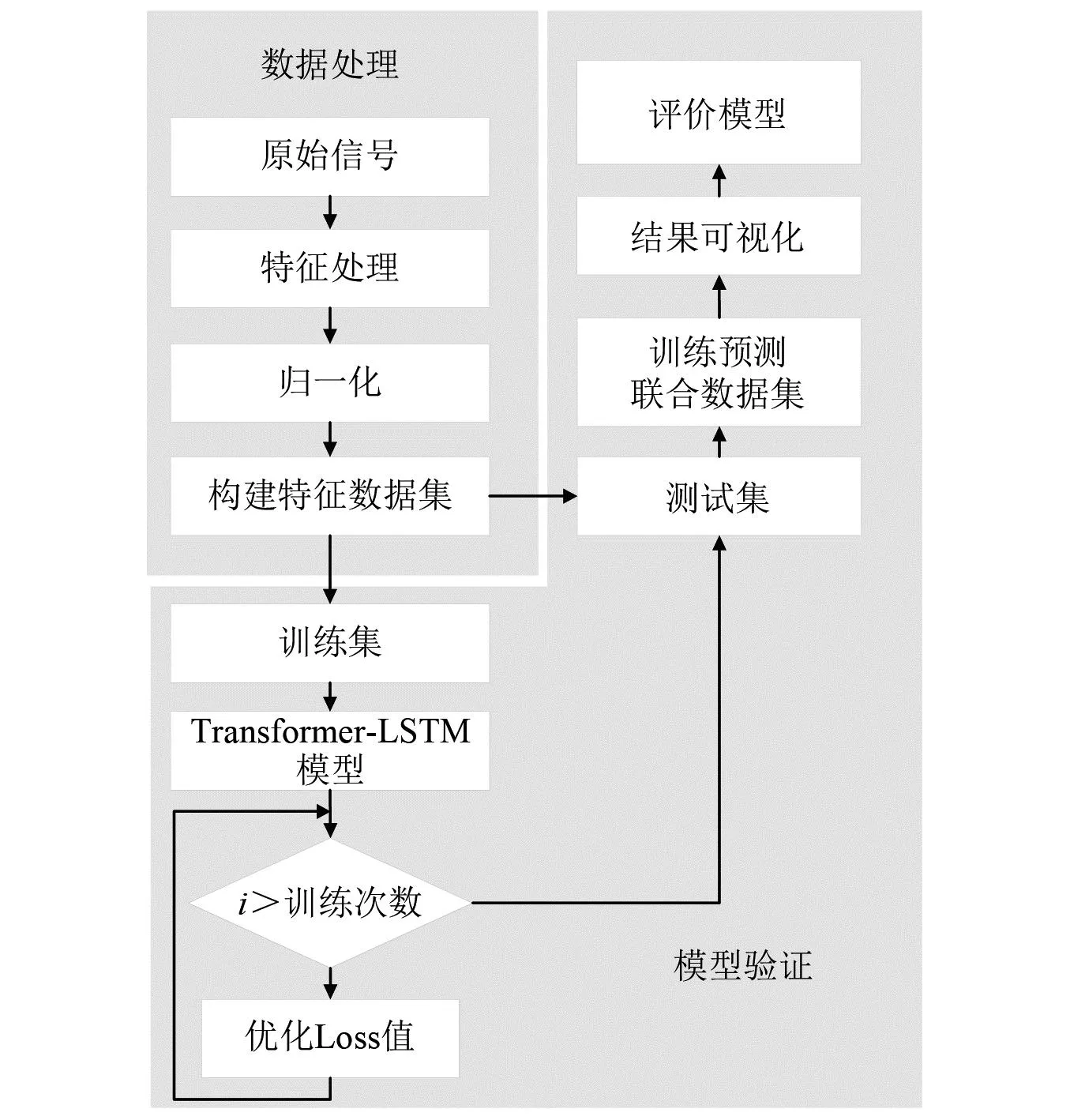
图7 技术路线Fig.7 Technology roadmap
2.2 振动加速度特征分析
特征提取与数据集构建是实现预测的基础,对于轴承寿命预测而言,在众多的特征中提取满足预测条件的特征才能够实现准确的预测。正常的轴承在运行过程中振动逐渐增加,因此可以通过振动加速度传感器进行采集。
以本文所使用的部分轴承有效信号为例,如图8所示。轴承的垂向振动加速度信号特征随着轴承性能退化而发展,振动信号逐渐增加,呈现出单调上升的趋势,并且在整个退化过程中整体平稳,不存在局部激励震荡的情况。因此选择该指标训练轴承寿命的预测。
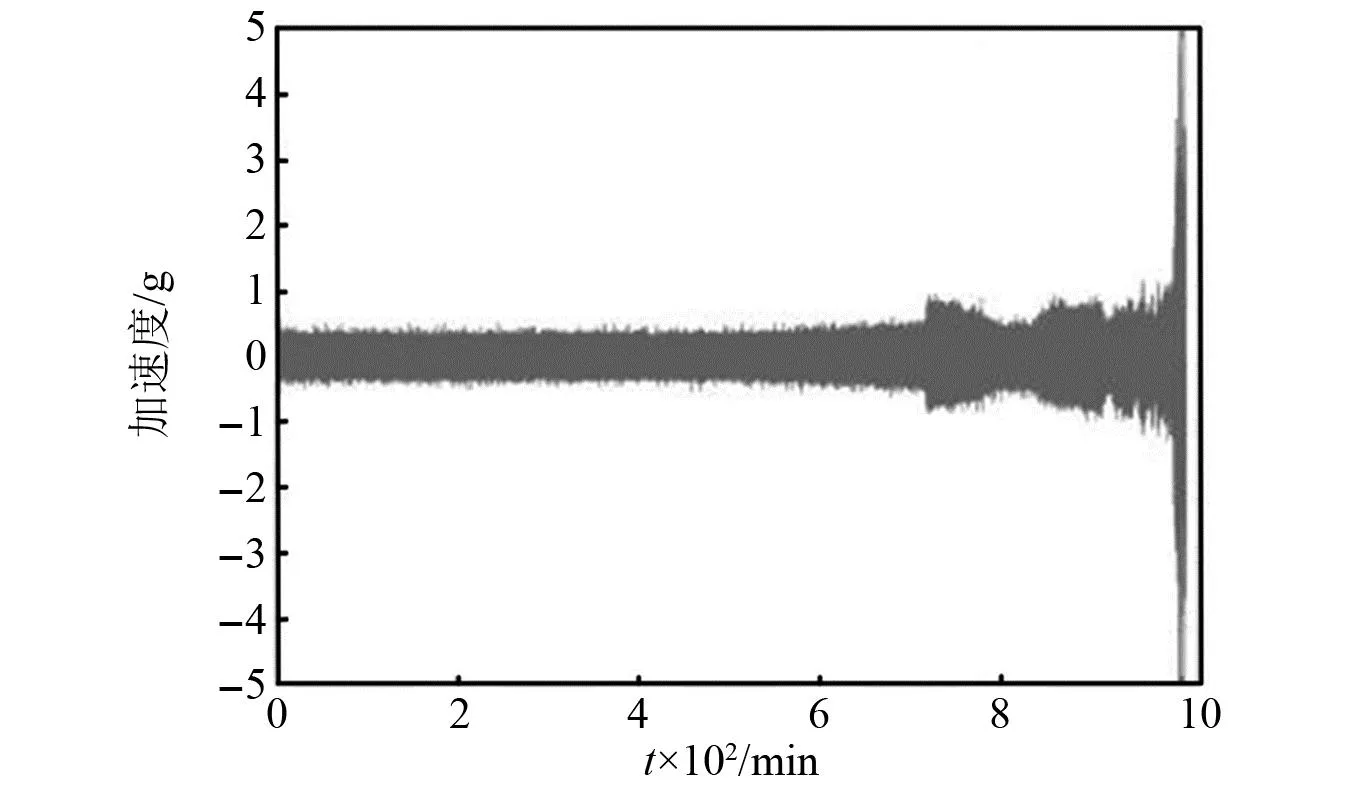
图8 轴承全寿命振动加速度原始信号图Fig.8 Original signal diagram of bearing full lifevibration acceleration
2.3 归一化处理
数据归一化是一种常见的数据处理方法,归一化能够使数据在一定程度上实现收敛,从而降低在预测过程中产生的梯度爆炸问题。本文采用的归一化方法是0~1归一化方法,如式(16)所示。该方法可以将原始数据通过线性变换,约束到0~1内,从而实现提升收敛速度、防止梯度爆炸。
经过归一化的垂向振动加速度信号在降低梯度爆炸的概率同时还保留了完整的特征趋势,相较于原始输入拥有更好的训练性,因此选择归一化后的垂向振动加速的信号作为网络输入。
(16)
2.4 训练-预测联合预测数据集
本文采用了一种训练-预测联合的数据集构建模式,该方法的做法是将训练结果与预测结果相结合,构建全新数据集的方法。
试验网络采用滑动窗预测的方式进行训练,将训练数据、预测数据按照设定的batch-size进行等分,分别对训练集数据进行训练。在训练过程中打乱时间顺序,通过位置编码层对各个标签进行位置编码,对训练集进行学习,优化训练损失,并设置loss为0,dropout为0.4,提升泛化性。在经历了设定的epoch之后,网络得到最终学习结果的权重。测试集根据训练集结果进行预测,最终的测试集结果即为试验所得到的预测结果。
通过滑动窗预测的方式,将每个测试轴承试验数据的前95%数据划分为训练集,学习轴承退化特征;将后5%的数据用作测试集,根据训练集学习到的结果预测测试集样本寿命数据。搭建训练-预测联合数据集能够更好的保存训练集的学习过程,将最后一次训练的结果与测试集数据结合,完整的保存下从学习到预测的全过程,提升数据的可观测性。联合数据集搭建如图9所示。
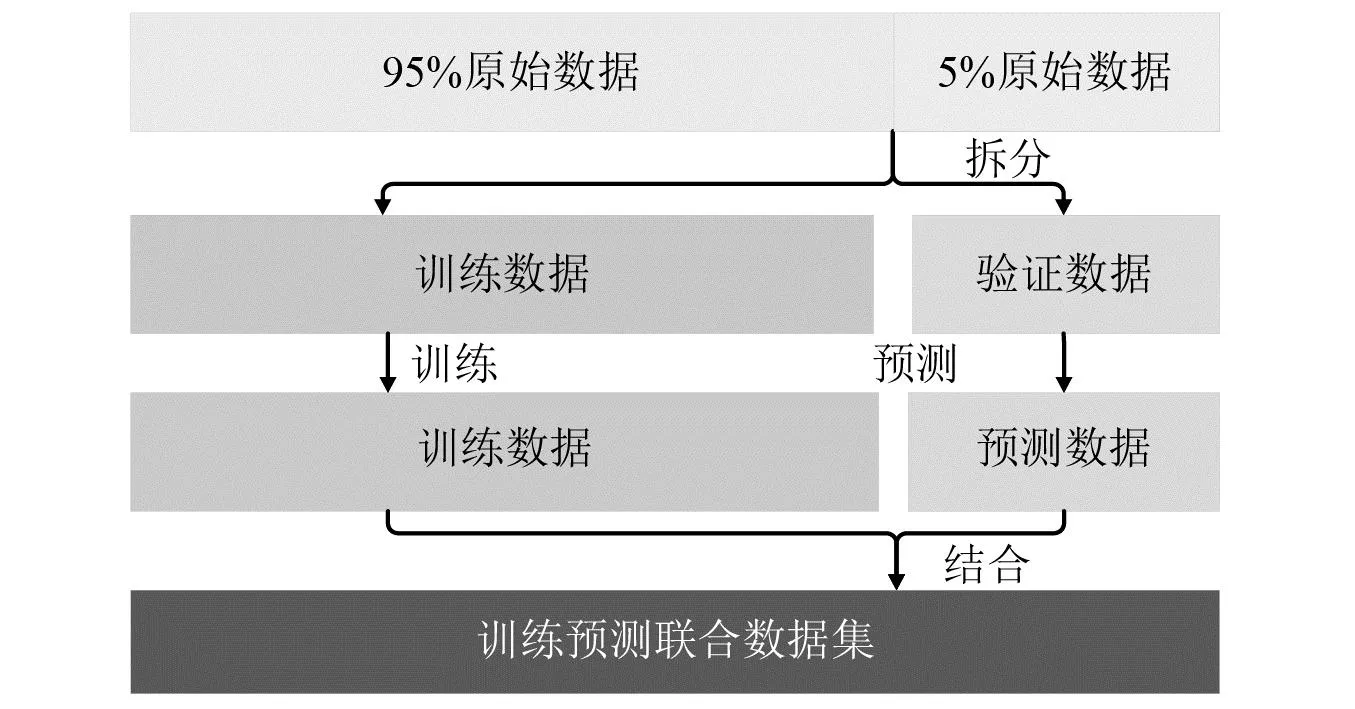
图9 训练-预测联合数据集构建示意图Fig.9 Trained-prediction combined data sketch
3 试验验证
本次试验通过多组试验数据来验证网络的性能。试验采用的数据集分别是辛辛那提大学轴承全寿命数据集(intelligent maintenance systems,IMS)以及西安交通大学轴承全寿命数据集。试验数据分别包含了小数据集、中等长度数据集以及长数据集3种,分别验证网络的精度与泛化性。
本文采用的预处理方式是平均化每个采样单元的振动加速度从而实现的。经过平均化采样的数据拥有更好的训练特征,网络收敛速度更快,能够关注到轴承损失的整体趋势,提升网络预测精度。
3.1 辛辛那提大学轴承全寿命试验
3.1.1 辛辛那提大学轴承全寿命试验数据集
辛辛那提大学试验选取的是IMS轴承全寿命数据集进行方法验证[18],试验装置如图10所示。该数据集共包含3组轴承数据,本次试验选取第2组轴承全寿命数据设计试验,共984个采集样本。轴承型号为Rexnord ZA-2115双排轴承,4组轴承同时旋转,通过PCB353B33传感器垂向和横向同时监测轴承信号变化,试验结束时,1号轴承发生外圈故障。试验各项参数设定为: 转速2 000 r/min,采样频率为20 kHz,每次采样时长为1 s,每个采样单元以10 min为一个采样单元,每个采样单元生成一个含有20 480采样点的数据文件,采样间隔10 min,附加径向载荷6 000 Ib,试验装置如图10所示。
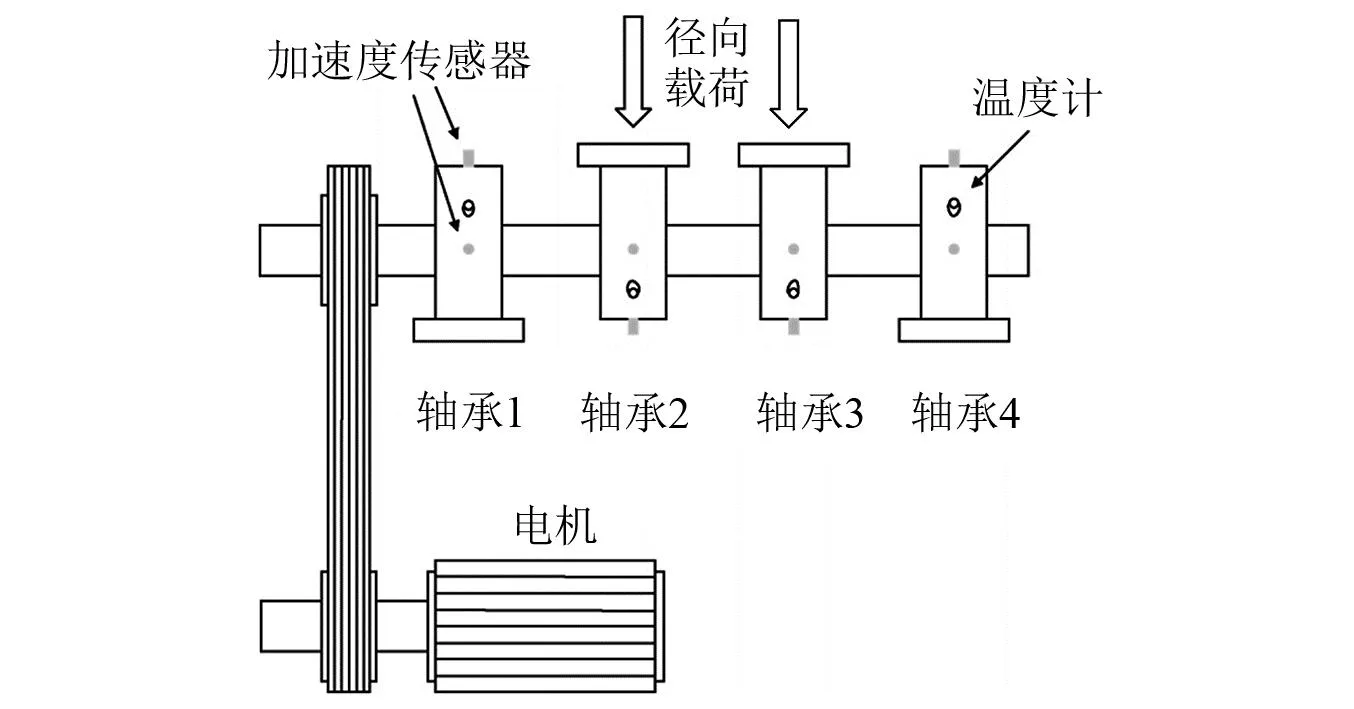
图10 辛辛那提大学IMS轴承全寿命试验装置示意图Fig.10 University of Cincinnati IMS schematic diagram of bearing full life test device
为了降低试验噪声对预测结果的影响以10 min采样单元进行平均化,将每个采样单元所得到数据进行平均处理,以每个文件的平均数据代表轴承在该单元内的振动特征信号,并参与网络计算。
3.1.2 辛辛那提大学轴承全寿命试验结果
试验在Intel i9 10900F,Nvidia RTX3070,PyTorch1.10.0-GPU,Python3.9环境下试验从而得到的。在试验中,设置训练网络参数为:训练集epoch为200,batch-size为50;测试集batch-size为50,learning-rate为0.000 1。根据本文2.4节所提出的训练集预测集划分规则,本文试验有984个平均化数据单元,划分95%训练集934个点作为训练集,划分最后5%测试集的50个点作为测试集。
试验寿命指标选择以2.4节所构建的训练-预测联合数据集的指数拟合曲线为评判。指数拟合曲线本文所采用的指数拟合,所使用的公式如式(17)所示,并通过Origin指数拟合迭代训练-预测联合数据集所得出的结果。拟合采用Levenberg-Marquardt算法进行实现,拟合曲线满足95%置信区间分布。当拟合曲线寿命达到1时,判定寿命达到极限,即轴承报废寿命。
y=y0+Ae-x/t
(17)
本组试验样本点984个,即轴承984 min报废,该样本满足长寿命样本数据预测条件,为了能够对比本文提出的Transformer-LSTM网络性能,本文选择了Transformer-LSTM without LSTM、LSTM、GRU 3种网络进行对比试验。试验对2.4节所提到的训练-预测联合数据集的最后测试集50个数据点进行展示,并通过平均绝对误差(mean absolute error,MAE)、均方误差(mean square error,MSE)、均方根误差(root mean squared error,RMSE)指标对预测数据进行量化分析,公式如式(18)~式(20)所示。
(18)
(19)
(20)
为了能够更加直观的展示出预测时间与试验真实报废时间之间的关系,本文引入了预测时间相对误差百分比Xerror来进行比较。其中:Ttest为对比试验预测误差时间;Ttl为本文提出的Transformer-LSTM网络的预测误差时间;Xerror的百分比越低越能够体现出对比网络与本文提出的Transformer-LSTM网络性能接近,反之亦然。Xerror计算公式如式(21)所示。
(21)
如图11所示,本文提出的方法效果最佳。将数据量化分析:Transformer-LSTM模型预测误差为108 min,Transformer-LSTM without LSTM预测误差为145 min,LSTM预测误差为261 min,GRU预测误差为455 min,而本文提出的Transformer-LSTM与对比网络相比较,Transformer-LSTM without LSTM的相对误差为34.26%,LSTM的相对误差为141.67%,GRU相对误差为321.30%。通过试验寿命预测值与相对误差可以看出,在长寿命数据集的预测过程中,本文提出的模型能够更好的预测出轴承的寿命,准确最高,优于并行数据处理的Transformer-LSTM without LSTM网络。为了更加直观展Transformer-LSTM预测效果,本文将预测评价指标进行展示,结果如表1所示。
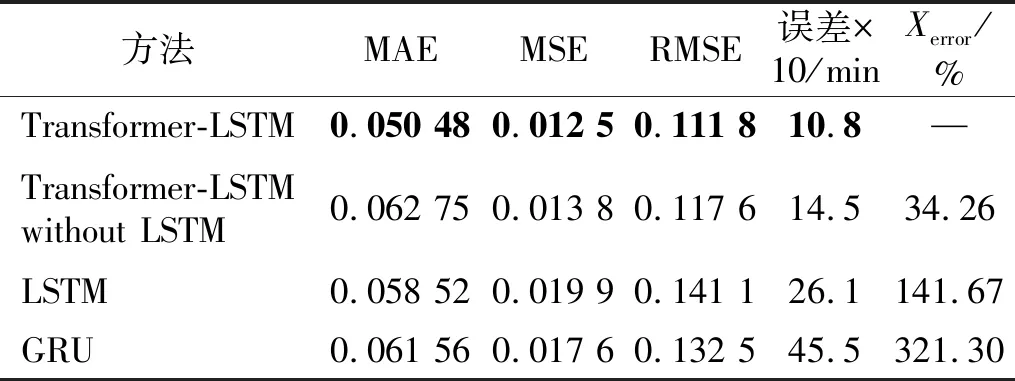
表1 IMS轴承全寿命数据集预测结果展示Tab.1 IMS bear bearing life data set prediction result

图11 辛辛那提大学IMS轴承全寿命试验预测效果图Fig.11 Prediction effect of different models uses University of Cincinnati IMS schematic diagram of bearing full life test
3.2 西安交通大学轴承加速寿命试验
3.2.1 西安交通大学轴承加速寿命试验数据集
西安交通大学轴承全寿命数据是轴承加速退化测试平台所采集到的[19]。在试验中:采样频率25.6 kHz,采样间隔为1 min,每次采样时长为1.28 s,以每分钟为一采样单元。通过在轴承的水平与垂直两个方向上安装两个PCB352C33型加速度计收集被测轴承的振动信号,采集轴承在试验过程中产生的振动加速度信号,并进行采集。采样频率为25.6 kHz,采样间隔为1 min,每次采样时长为1.28 s。试验采用的轴承型号为LDK UER204深沟球轴承,试验一共分为3个工况,试验装置如图12所示,工况如表2所示。

表2 试验工况Tab.2 Test conditions

图12 西安交通大学加速轴承失效试验设备图Fig.12 XJTU equipment diagram for accelerated bearing failure test
在每种工况下分别有5个轴承参与试验,以此保证试验的可靠性。最终形成了一个由15个轴承构成的数据集。本次试验选取了不同工况下的两种相同失效形式的轴承,分别是:①加载12 kN转速2 100 r/min工况下的第三号失效轴承;②加载11 kN转速2 250 r/min的5号失效轴承。这两个轴承都是因外圈失效报废的,有着相似的退化趋势。
试验在预处理中采用1 min单元的平均处理方式,将每分钟数据进行平均化,并代入网络进行计算。
3.2.2 西安交通大学轴承加速寿命试验结果
在该试验中,选取了两组不同工况下失效的轴承,验证网络的精度与泛化性,试验在相同训练环境下采用与上文相同的4种神经网络进行验证。设置训练网络参数为:训练集epoch为200,batch-size为16;测试集batch-size为16,learning rate为0.000 1。
首先采用加载12 kN转速2 100 r/min工况下的第三号失效轴承,本轴承实际失效时间为158 min,满足短寿命时长轴承。根据本文2.4节所提出的训练集预测集划分规则,本组试验有158个平均化数据单元,划分95%训练集150个点作为训练集,划分最后5%测试集的8个点作为测试集。
如图13所示,本文提出的方法预测时间以及趋势最准确。将数据量化分析:Transformer-LSTM模型预测误差仅为0.6 min,Transformer-LSTM without LSTM预测误差为2.7 min,LSTM预测误差为1.1 min,GRU预测误差为5 min。Transformer-LSTM与对比网络相比较,Transformer的相对误差为350.00%,LSTM的相对误差为83.33%,GRU预测误差为733.33%。通过试验寿命预测值与相对误差可以看出,本文提出的Transformer-LSTM串并行神经网络在短寿命轴承寿命预测过程中,准确率依旧最高,优于串行数据处理的LSTM神经网络。为了更加直观展Transformer-LSTM预测效果,本文将预测评价指标进行展示,结果如表3所示。
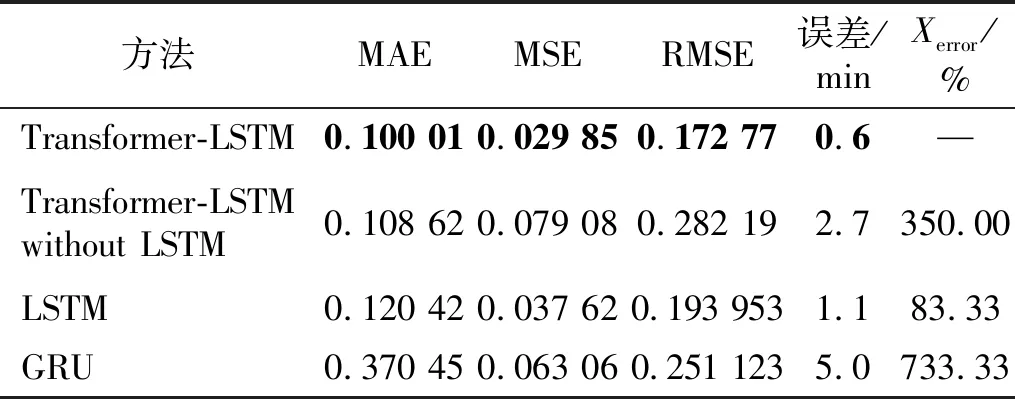
表3 西安交通大学轴承加速失效数据1-3预测结果展示

图13 辛辛那提大学IMS轴承全寿命试验预测效果图1-3Fig.13 Prediction effect of different models uses University of Cincinnati IMS schematic diagram of bearing full life test 1-3
为了加强验证试验数据的泛化性能,同时验证了加载11 kN转速2 250 r/min工况下的第五号失效轴承,本轴承实际失效时间为339 min。该轴承数据量适中,属于中等寿命时长轴承。本组试验有339个平均化数据单元,划分95%训练集322个点作为训练集,划分最后5%测试集的17个点作为测试集。
如图14所示,本文提出的方法效果最佳。将数据量化分析:Transformer-LSTM模型预测误差为5.8 min,Transformer预测误差为7.4 min,LSTM预测误差为8.8min,GRU预测误差为29.9 min。Transformer-LSTM与对比网络相比较,Transformer-LSTM without LSTM的相对误差为27.58%,LSTM的相对误差为51.72%,GRU预测误差为415.52%。通过试验寿命预测值与相对误差可以看出:在中等寿命时长的轴承预测过程中,Transformer-LSTM网络依旧能够准确的预测轴承剩余寿命,准确率仍然最高,这证明了Transformer-LSTM在轴承寿命预测的过程中泛化性很好,能够很好地解决单独的串行或并行网络在预测轴承寿命时对样本量的需求。量化试验结果如表4所示。
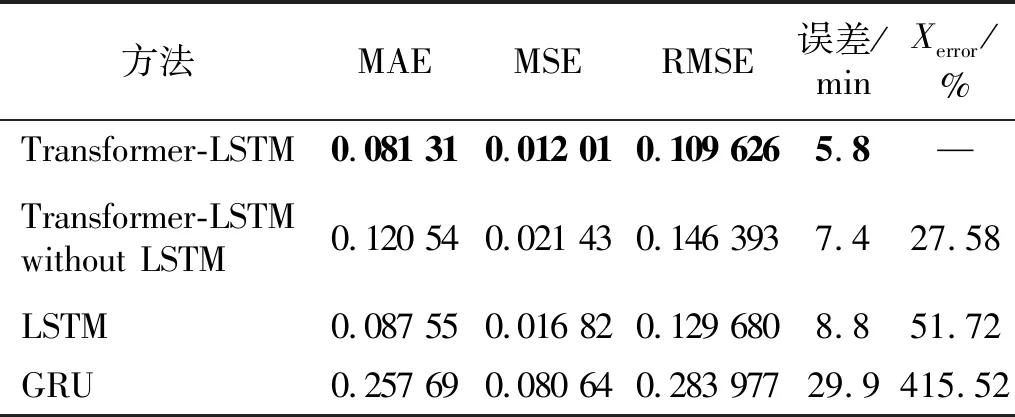
表4 西安交通大学轴承加速失效数据2-5预测结果展示

图14 辛辛那提大学IMS轴承全寿命试验预测效果图2-5Fig.14 Prediction effect of different models uses University of Cincinnati IMS schematic diagram of bearing full life test 2-5
4 结 论
本文针对轴承不同寿命时长预测不准确、模型泛化能力弱的问题,提出了一种能够预测不同寿命时长的Transformer-LSTM串并行神经网络预测模型。通过将Transformer解码层进行重构,并与LSTM网络结构融合,实现轴承寿命数据的串并行预测处理。得出以下结论:
(1)Transformer-LSTM网络性能不受轴承寿命时长影响,能够在不同时间尺度内保持精确的预测效果。预测的轴承寿命、MSE、RMSE均优于Transformer-LSTM without LSTM、LSTM、GRU 3种网络。
(2)Transformer-LSTM网络在寿命预测过程中,预测结果最接近实际报废时间,证明了本文提出的网络能够提取到更多的特征信息。
(3)Transformer-LSTM神经网络在不同数据集的多种工况下均能取得较好的预测精度,证明了本文所提出的模型具有良好的泛化性。
猜你喜欢
哈尔滨轴承(2022年2期)2022-07-22
中国石油石化(2022年12期)2022-07-16
哈尔滨轴承(2022年1期)2022-05-23
中老年保健(2021年8期)2021-12-02
哈尔滨轴承(2021年2期)2021-08-12
哈尔滨轴承(2021年1期)2021-07-21
作文评点报·低幼版(2020年3期)2020-02-12
中国外汇(2019年19期)2019-11-26
家庭影院技术(2018年11期)2019-01-21
家庭影院技术(2018年11期)2019-01-21
