
基于BM25 的勘察设计企业科研项目重复性检测方法研究
2024-04-09 05:53:24曹德威王剑刚钱常运
科技管理研究 2024年4期
王 扬,曹德威,王剑刚,钱 锋,钱常运
(上海勘测设计研究院有限公司,上海 200335)
0 引言
如今,中国的学术研究、技术研发蓬勃发展,多学科交叉日益相融,随之产生交叉立项、重复立项的现象,这种现象在科研院所尤为明显。其原因包括跨地域跨组织管控要求不一、查重信息库范围不足、重复性鉴定的技术壁垒等[1],这些问题在勘察设计行业仍然突出。为避免科研项目重复立项、科研成果重复产出,需大量的科研人员参与鉴定,不仅依赖科研人员的专业广度和深度,且枯燥低效[2]。而对于国内的高新技术企业和科改示范企业,每年约投入其营收的5%在科技研发中[3],重复立项带来的资金损失不言而喻。
从全球范围来看,多院校、多科研机构的多方投入有助于构建良性竞争机制,孵化尖端技术[4]。伍丹等[5]认为这种作用尤其集中体现在健康信息、人机交互、机器学习等领域。然而,Schimmack[6]、Tincani 等[7]研究指出,低难度、低质量的重复研究缺乏创新性且成果缺乏实际效用,甚至滋生经费欺诈。从中国来看,各地区对于科技研究的管理存在明显边界[8],如路鹏等[9]、王欣等[10]的研究指出,未建立统一的储备信息库,导致前期工作缺乏协同、调研数据重复采集、同一课题反复申报等弊端。为杜绝科研经费的重复投入,国内各地区明确科研经费的管理机制,但仍无法杜绝“重复包装”等现象。从勘测设计行业来看,能源规划、工程设计、智能建造、智能运维等领域孕育了大量的科技研究课题[11],其中不乏对“建筑信息模型(BIM)+地理信息系统(GIS)+物联网(IoT)”、人工智能、施工技术、数据挖掘技术的探索与研究,这些课题虽然有不同的聚焦场景,但研究内容存在紧密联系,技术路线可相互借鉴,有必要加强对前期资源的整合,减少重复性投入。
基于关键信息和文本语义对立项材料的重复性进行自动判定,是检测课题重复性的重要路径。随着企业信息化的应用深化,科研管理过程数据的结构化存储已基本实现,企业积累的历史科研项目数据库是BM25(Best Matching 25)算法应用的前提。为实现科研项目重复性的自动判定,在课题申报时对项目标题、研究背景、研究目标、建设内容进行检测,以量化结果干预立项工作。本研究在词频-逆文档频率(TF-IDF)、BM25 算法的基础理论上,提出一种聚焦勘察设计企业特征的科研项目重复性计算方法,并以新能源、工程数字化和信息化领域的真实课题加以验算,同时融入领域、专业、人员、部门等特征属性。
1 文本相似性相关研究
近年来,项目重复性检测的热点集中在文本相似度的自动识别和判定。Salton 等[12]提出的空间向量模型将词频和逆文档频率表示成数学向量的模式来计算文本文档相似度,该模型广泛应用于信息检索和文本检索等。Kim 等[13]以国家级的科研数据为基础建立各类课题项目的向量模型,通过计算余弦距离和欧几里得距离(Euclidean distance)来评估文本相似度。Al Qady 等[14]在TF-IDF 算法的基础上加入监督学习以细化聚类结果,从而提高文本相似度检测的准确性,进而应用于课题文档的相关度检测。
BM25 是一种用于结构化文本的概率计算模型,在文本搜索、文本匹配、语义判定等方向应用广泛。Liu 等[15]基于BM25 创建了基准数据集(LETOR)用于信息检索排名;Zhang 等[16]根据BM25 的原理,扩展引入bR*-tree 的新索引,进行空间关键词查询,提升了检索的响应时间;Singhal 等[17]在BM25模型基础上提出的枢轴归一化技术可用于缩小相关性概率与检索概率之间的差距;He 等[18]在不同的TREC 数据集上,计算词频并进行归一化参数调整,其调整方法在不同的 TREC 数据集上具备明显优势,而计算成本却微乎其微。BM25 算法应用于勘测设计企业科研项目重复性检测具有天然的优势,原因在于:勘测设计企业科研项目数据以“基本信息+文本”的形式存储,其中基本信息多为符合数据字典的固定值,且现有研究样本中超过95%的公司文本信息小于1 000 字符。在计算项目相似度时,在BM25 算法基础上综合各数据权重以获得最终值。
2 构建相似度模型
2.1 TF-IDF 相似性
使用TF-IDF 计算文本相似性,即词频与逆文档频率的乘积,计算式子如下:
式(1)~(3)中:ni,j表示词条ti在文档dj中出现的次数;|D|表示所有文档的数量,|j:ti∈dj|表示拥有词条ti的文档数量。
计算文本Q与文本库D中某文本d的TF-IDF相似度时,建立空间向量,以余弦距离表示,即
2.2 BM25 相似性
BM25 算法是对 TF-IDF 算法的优化,在词频的计算上,BM25 限制了文档中关键词的词频对评分的影响。与TF-IDF 相比,BM25 增加了词语饱和度k和字段长度规约b。以BM25 算法计算文本Q与文本库D中某文本d的相似度公式为:
式(5)中:Wi为文本Q中词语qi的权重;R(qi·d)为词语qi与文本d的相似度。
Wi通常取其IDF 值,即
式(6)中:N为文档总数;n(qi)为包含该词语的文本数目;为保证分母不为0,平滑系数取0.5。
式(7)(8)中:fi为qi在d中的频率;qfi为qi在Q中的频率;k根据经验值取1.20;dl 为d的长度;avg dl 为所有文本D的平均长度;b根据经验值取0.75。
综上可得,BM25 相似度可表示为:
2.3 科研课题模型
勘察设计企业的科研课题关键信息可以通过标题、项目属性、项目背景、建设目标和建设内容等数据来展示。根据历年科研项目的管理经验,分别对上述元素设置权重,分别如表1 和表2 所示。其中,标题是指科研课题标题,小于100 个字符;项目背景是指科研课题的建设意义、必要性,小于2 500 字符;建设目标是指科研课题的建设目标、考核指标,小于2 500 个字符;建设内容是指科研课题的实施方法、技术方案,小于2 500 个字符。

表1 科研课题关键元素权重

表2 科研课题关键元素数据类型
标题、项目背景、建设目标、建设内容的文本相似度由TF-IDF 算法、BM25 算法计算得出,项目属性的相似度单独计算。通过加权求和,获得输入课题P与项目库D中某课题Di的相似度,即
项目属性信息可进一步细分为项目领域、涉及专业、项目负责人、实施部门,各细项相似度计算方式如表3 所示。

表3 科研课题属性信息相关度
因此,项目属性的相似性可表示如下:
3 实验与分析
基于BM25 算法计算科研课题相似度的方法,其实验过程分为以下四步:(1)文本预处理;(2)建立匹配库;(3)根据TF-IDF 算法、BM25 算法分别计算输入课题与匹配库中课题的相似度;(4)分析计算结果。处理及计算过程的设备环境与运行环境为:64 位Win10、intel(R)Core(TM)、Python3.7。
3.1 文本预处理
预处理的目的在于聚焦文本的有效信息,对内容进行降噪、统一同类信息。将课题编号(ProjectID)作为唯一标志,信息预处理步骤包括文本分词、去停用词、去标点符、英文正则化。
文本分词:采用Krogh 等[19]提出的Jieba 分词模型进行处理。相较于Liu等[20]使用的HanLp、Li等[21]使用的Thulac 分词模型,Jieba 分词模型对中文语境中未登录词有较强的分析能力,对专业名称较多的科研课题具备优势,因此适合本文的使用环境。
去停用词:停用词库由虚拟词、语气词、代词等构成,覆盖中英文。其中,包括中文停用词843 个,英文停用词548 个。
去标点符:去除标点符,涵盖中英文。
文本正则化:英文单词统一以小写形式存储,避免因字母编码造成的词义误判。
3.2 建立匹配库
将历史科研课题进行批量处理,独立存储每个课题,建立匹配库并动态更新。匹配库共计803 个项目,按课题领域分类:水利有67 项,水电有91 项,新能源有242 项,输变电有3 项,生态环境有234 项,建筑市政有28 项,数字化信息化有82 项,其他有56 项。将上述过程以伪代码形式呈现,如图1 所示。

图1 建立匹配库伪代码
3.3 样本相似度计算
对样本课题P1(新能源领域)、P2(工程数字化和信息化领域)的文本进行预处理,并分别根据TF-IDF 算法及BM25 算法,将其与匹配库中所有课题一一进行相似度计算。样本课题的基本信息如表4所示。

表4 样本课题的基本信息
3.4 计算结果分析
3.4.1 课题P1的计算结果分析
根据课题P1的计算结果,从匹配库中选取3 个相似度较高的课题D1、D2、D3进行分析。具体地,课题P1涵盖抗台风、海上风电、海洋牧场、风机结构等细分场景,而由TF-IDF、BM25 所识别出的高相似度课题D1、D2、D3均属于新能源领域,且重点覆盖海上风电、基础结构、海洋渔业等细分场景,符合预期。从表5 可以看出,对于如标题的短文本,BM25 算法得出的相似度明显高于TF-IDF;而如课题背景的长文本,BM25 算法得出的相似度普遍低于TF-IDF。这是由于BM25 算法中对字段长度规约的设置,其值越大,在计算得分时对文档长度差异的惩罚越大,同样符合预期。

表5 匹配库课题与样本课题P1 的相似度
图2、图3 分别为通过TF-IDF 算法、BM25 算法计算课题P1 与匹配库中所有课题相似度的分布,并使用不同符号区分课题领域。从空间散点分析,同为新能源领域的课题与P1整体相似度较高。相较于TF-IDF,BM25 的计算结果分布中,非新能源领域的课题的相似度较分散、区间较大,这是由于BM25 算法实现了对词语权重的控制,扩大了课题相似性的区分度。从时间序列分析,2019 年9 月至2023 年8 月的匹配库课题在BM25 与TF-IDF 的计算结果体现出较高的一致性,未出现极端差异。
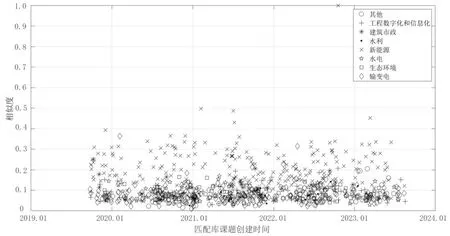
图2 基于TF-IDF 算法的样本课题P1 与匹配库相似度计算结果分布
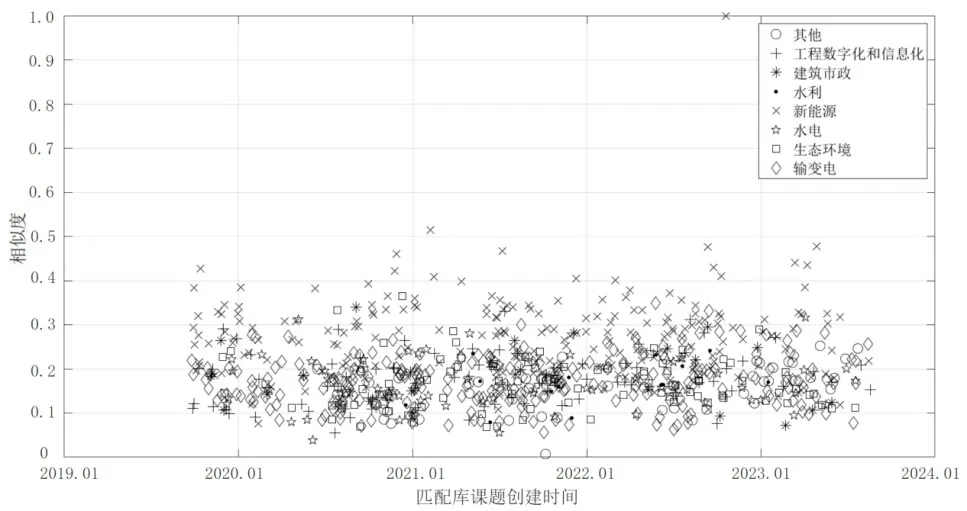
图3 基于BM25 算法的样本课题P1 与匹配库相似度计算结果分布
图4、图5 分别为通过TF-IDF 算法、BM25 算法计算课题P1与匹配库中各领域课题相似度的最大值、平均值、最小值。通过数据对比,BM25 算法在平均值、最大值明显高于TF-IDF,而最小值无明显差异,再次证明了BM25算法在区分度上的控制能力。

图4 基于TF-IDF 算法的样本课题P1 与匹配库各领域课题相似度分布
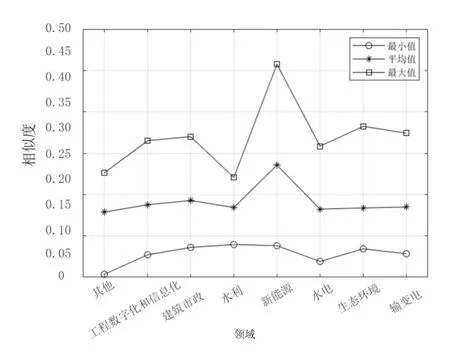
图5 基于BM25 算法的样本课题P1 与匹配库各领域课题相似度分布
3.4.2 课题P2的计算结果分析
课题P2涵盖抽蓄电站、机电设备、设备、智能管控等细分场景,如表6 所示,TF-IDF 与BM25 算法识别的高相似度课题均属于工程数字化和信息化领域,覆盖土方平衡、数字化施工、安全智能管理等场景。其中,课题D1’的标题文本较短,与课题P2存在“智能”“技术研究”重复关键词,致使P2与D1’基于TF-IDF 和BM25 算法在标题相似度上有较高得分。通过深入研读P2与D1’发现,两个课题分别聚焦于抽蓄电站设备的安装和土石方平衡计算,虽然在研究内容上均涉及人工智能(AI)、BIM 等数字技术,但经过人工复验,认为两者的综合相似度过高,处于非合理范围。这是由于TF-IDF 与BM25 算法在原理上通过词语、词频计算相似度,缺乏实际语义理解,从而产生误判。

表6 匹配库课题与样本课题P2 的相似度
图6~图9 分别展示了通过TF-IDF、BM25 算法计算课题P2与匹配库中各课题相似度分布、各领域课题相似度的最大值、平均值、最小值。与课题P1类似,课题P2的计算结果表明,BM25 算法相较于TF-IDF 表现出较大的区分度,且其计算均值、最大值较高,最小值接近。在图7 中,能够看到某一课题的相似度达到0.540,但在图6 中的相似度为0.289,并不突出,该课题标题为“海上风电数字化交付研究及应用示范”,与课题P2在建设内容(数字孪生、BIM 技术应用)上高度契合。这是BM25算法在调节平滑因子扩大区分度所带来的优势。
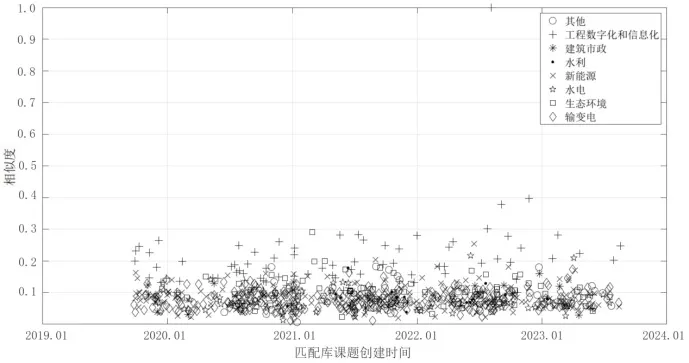
图6 基于TF-IDF 算法的样本课题P2 与匹配库相似度计算结果分布
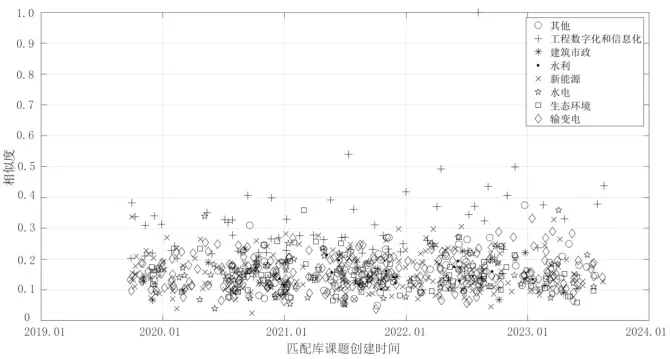
图7 基于BM25 算法的样本课题P2 与匹配库相似度计算结果分布
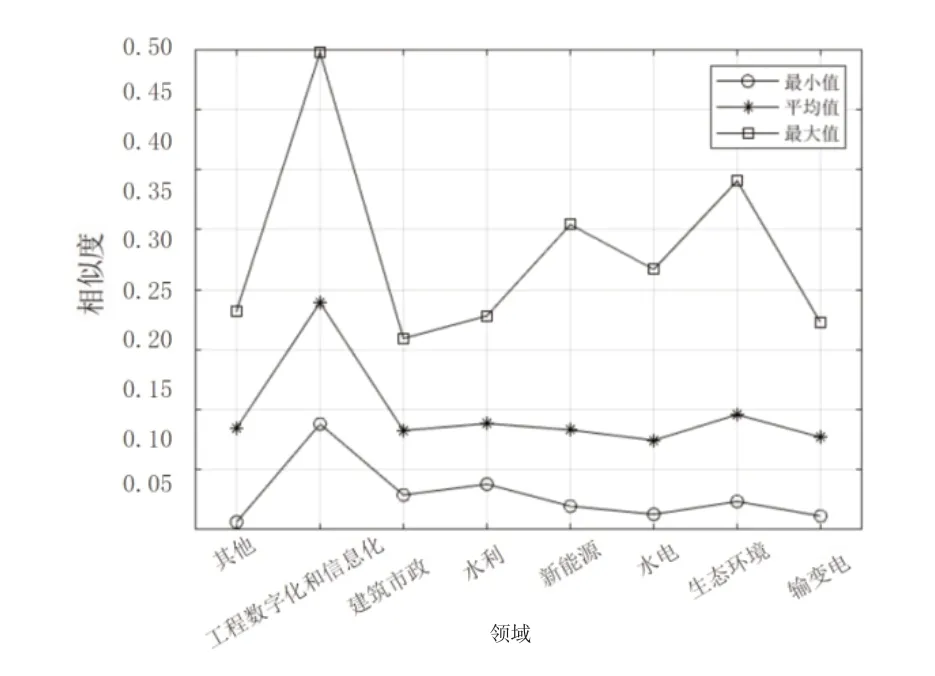
图8 样本课题P2 与匹配库各领域课题相似度(TF-IDF)
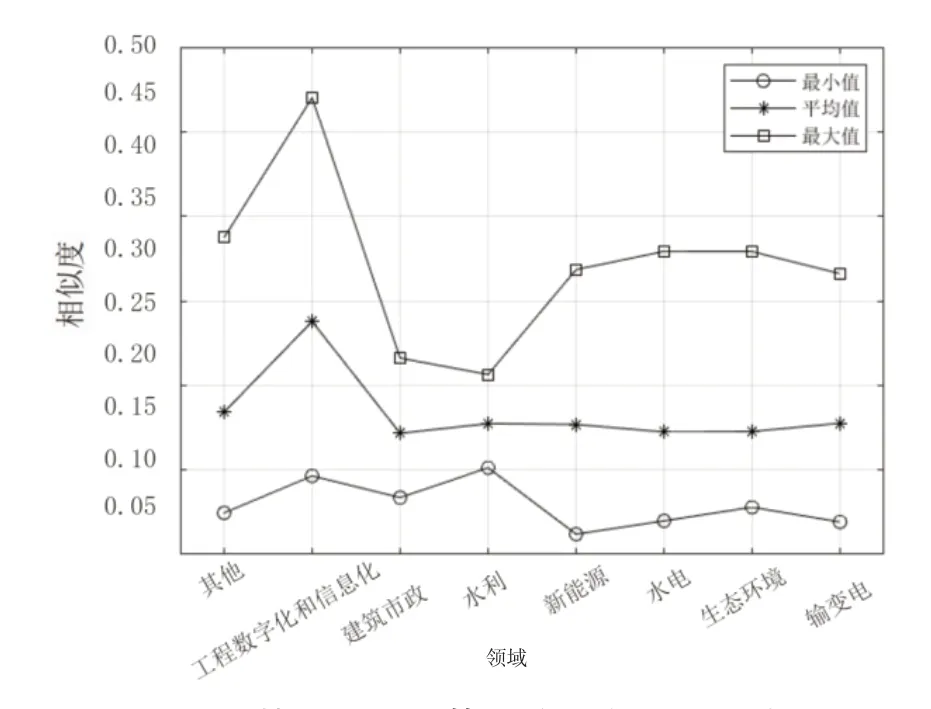
图9 基于BM25 算法的样本课题P2 与匹配库各领域课题相似度分布
3.4.3 TF-IDF 与BM25 的异同点分析
TF-IDF 与BM25 在科技课题的相似度判定中,在空间分布、时序分布上具备较高的一致性,即同领域课题普遍相似度高,不同领域课题相似度较低,且未出现较大偏差,符合常规认知。相较于TFIDF,BM25 算法通过词语饱和度和字段长度规约实现权重控制,计算结果有较高的区分度,有利于挖掘不同领域下高相似性的文本,最大程度避免了潜在重复课题的遗漏。TF-IDF 与BM25 在原理上通过词语、词频计算文本相似度,在文本较短且词语重合度较高的场景中存在局限,如TF-IDF 与BM25 均判定“智能土方平衡关键技术研究”与“智能吊装平衡关键技术研究”两个标题相似度得分较高,但实际语义存在较大差异。
4 结论
本研究提出了一种基于BM25 算法的勘察设计企业科研项目重复性检测方法,聚焦BM25 算法的基本原理,融入勘察设计企业特点,引入领域、专业、人员、部门属性值,在文本比对相似度的基础上强化属性值的计算权重,在判定课题重复性、辅助立项识别等工作上卓有成效。经新能源、工程数字化和信息化领域课题的实际验证,计算时间小于0.1 s,满足商用;计算结果经技术研发人员复验,准确性满足业务管理需要。除科研课题外,该相似度计算方法在工程项目、信息化项目、咨询服务项目等亦可应用。
但是,该算法仍存在以下局限,未来研究可从以下方面进行深入探讨:
(1)匹配库所使用的科研课题共计803 个,累计中文字符小于321 万字,在数据量上仍然不足,仅够满足企业内部自检,无法对横向课题、交叉性课题、区域性课题进行对比。如何构建跨企业、跨区域、跨行业的多源异构匹配库,相应的技术难度、管理难度值得深思。
(2)算法的内核是TF-IDF 算法的升级,虽引入了短文本的权重参数,但仍局限于词频及分布。机器学习算法能大大改善该缺陷,通过数据标注、语义库学习,理解上下文场景,强化语义理解在判定文本相似度时的作用。
(3)算法缺乏一套行之有效的评价模型,仅依靠技术研发人员的主观判断,而常用的检索统计指标,诸如查全率、查准率、评价准确率均值对于企业科研课题缺乏实际意义,因此建立适用于勘察设计行业的算法评价模型十分迫切。
猜你喜欢
海南开放大学学报(2021年4期)2022-01-24 13:13:22
园林科技(2021年3期)2022-01-19 03:17:48
昆钢科技(2021年2期)2021-07-22 07:46:56
Journal of Acupuncture and Tuina Science(2020年2期)2020-04-21 07:07:28
Journal of Acupuncture and Tuina Science(2018年3期)2018-06-28 09:27:58
职工法律天地(2018年12期)2018-01-22 22:55:10
水利信息化(2017年4期)2017-09-15 12:01:21
读者·校园版(2015年7期)2015-05-14 13:11:40
深圳大学学报(理工版)(2015年5期)2015-02-28 16:22:05
未来教育家(2014年1期)2014-03-20 22:39:40
