
面向GPU的5G新型无线电的高吞吐率LDPC译码器
2024-04-08 11:59:56李荣春王庆林
国防科技大学学报 2024年1期
李荣春,周 鑫,乔 鹏,王庆林
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 国防科技大学 并行与分布计算全国重点实验室, 湖南 长沙 410073)
低密度奇偶校验(low density parity check, LDPC)码[1]是一类前向纠错(forward error correction, FEC)码。LDPC码由于接近最佳性能,已经被WiFi、DVB-S2和WiMAX等通信系统所采用。LDPC码也被纳入5G标准,成为第五代新无线电的信道编码方案。目前,高吞吐率的LDPC译码器取得了一定的进展[2-5],但基于5G无线电的LDPC译码器工作目前并不多。首先,按照第三代合作伙伴计划(3rd generation partnership project, 3GPP)交付的标准描述,5G无线系统的速度将达到20 Gbit/s[6]。编码和译码的吞吐率必须足够高,才能满足高速数据传输的需求。因此,LDPC译码器需要提高译码吞吐率。在应用5G无线电时,需要更高吞吐率的LDPC译码器来实现高速信号传输。其次,5G新型无线电(new radio, NR)标准要求支持更广泛的码率和码长,利用一些新的结构特点,如码型设计和译码技术来实现更好的性能。
基于专用硬件平台(如ASIC和FPGA)的译码吞吐率可以非常高[7-11]。传统FPGA方案可以采用脉动阵列等方式来实现流水并行,提高译码吞吐率,降低译码延迟。同时其功耗较低,被广泛用于各种无线通信系统中。目前,图形处理单元(graphic processing unit, GPU)由于其强大的并行计算能力和灵活的编程形式,被广泛应用于各种科学计算、智能计算中。基于GPU的无线通信译码器也不断涌现,其吞吐率较高,甚至在某些情况下可以超越FGPA[12]。GPU译码器的优势之一是良好的灵活性,利用基于GPU的译码器,可以通过软件实现多标准、多模式的通信系统。基于GPU的译码器可以轻松实现对LDPC译码的不同码率和码长的支持,从而可以快速实现软件定义无线电平台。此外,开发时间短也使得基于GPU的译码器非常有吸引力。
WiFi和WiMAX系统采用准循环LDPC(quasi cyclic-LDPC, QC-LDPC)码,它是编码和译码复杂度较低的结构化LDPC码。5G无线电标准设计了新的QC-LDPC码。目前已有的基于GPU的QC-LDPC译码器都是特定码长的实现,如IEEE802.16e(2 304,1 152)的LDPC码[13],IEEE802.11n (1 944,972)的LDPC码[13]。但是其缺少支持5G无线电所需更长码长和更高码率的高吞吐率QC-LDPC译码器。
本文提出了一种基于GPU的5G新型无线电高通量QC-LDPC译码器。为了提高译码吞吐率,利用GPU实现了并行MSA算法。在消息更新过程中的最小值和符号计算在GPU上实现了并行计算。此外,实现了对数似然比(log-likelihood ratio, LLR)和中间值的量化,以合理的性能损失来节省片上和片下带宽。同时,还利用数据打包方法来降低GPU和中央处理器(central processing unit, CPU)之间数据传输的开销。在Nvidia RTX 2080Ti上测量了不同码长和码率的吞吐率。最终实验显示,基于GPU的译码器取得了较高的吞吐率和峰值性能利用率。最后,提出了一种评估方法来计算GPU上并行译码的最优线程设置。
1 用于5G无线电的QC-LDPC码
1.1 QC-LDPC码奇偶校验矩阵
LDPC码由M×N奇偶校验矩阵(parity check matrix, PCM)H构造,其中M代表校验节点(check node, CN)的数量,N代表变量节点(variable node, VN)的数量。将K表示为信息位的长度,K=N-M。PCM中的每一行代表一个奇偶校验方程,如式(1)所示。
c1⨁c2⨁…⨁ck=0
(1)
式中,⨁表示模2加,c1,c2,…,ck是行中的非零位。CN和VN之间的关系也可以用Tanner图[14]来描述。Tanner图中CNi和VNj之间的边对应于PCM中的非零条目,这意味着H(ij)=1,其中,i=1,2,…,M;j=1,2,…,N。
QC-LDPC码的PCM可以根据基础矩阵Hb来构造,Hb是一个mb×nb矩阵,由Z×Z右移标识和零矩阵组成。3GPP为NR定义了两个速率兼容的基础矩阵,即BG1和BG2。BG1的目标是编码长度较大(500≤K≤8 448)、码率较高(1/3≤r≤8/9);BG2的目标是编码长度较小(40≤K≤2 560)、码率较低(1/5≤r≤2/3)。Z是右移大小,代表右移单位矩阵的大小。3GPP对基本图使用8组右移尺度,值为Z=2j×a,其中a∈{2,3,5,7,9,11,13,15},j∈{0,1,2,3,4,5,6,7}。表1显示了不同a和j变化情况下Z的大小变化及数值集合,Z最大为384。

表1 5G新型无线电协议中的右移系数
假设偏移值
s=Hb(ib,jb)∈{-1}∪{0,1,…,Z-1}
(2)
式中,1≤ib≤mb, 1≤jb≤nb。
PCM通过使用该映射对Hb进行扩充和单位矩阵的右移来得到。
(3)
其中:Is是一个Z×Z单位矩阵,经过了s次的循环右移;0是Z×Z零矩阵。H的大小为(mb×Z)×(nb×Z)。对于BG1,mb=46,nb=68,信息列数量kb=nb-mb=22。在5G新型无线电中,mb和nb可以调整以适应码率。以下步骤描述了码率r和待编码的码长W条件下QC-LDPC的PCM构造过程。
步骤1:求满足以下条件的缩短长度Ns。
(4)
式中,kb为每行的非零条目,nb为校验矩阵宽度,Ns为缩短长度,d为最大码率偏差。按照上述构造方法,目标码率可能无法完全满足要求,因此允许最终码率与目标码率有微小的偏差。
步骤2:通过消除最右边的Ns列[15]来缩短基图,缩短后基图的大小为(mb-Ns)×(nb-Ns)。
步骤3:通过选择表1中的最小Z值来确定Z,使kb×Z≥K。
步骤4:根据修改后的基图,由右移的单位矩阵和零矩阵构成PCM,如式(3)所述。
5G新型无线电LDPC码的基图如图1所示。在5G新型无线电QC-LDPC码中,为了获得所需的信息块长度和高码率,对基图进行了缩短,剔除的列是扩展奇偶校验部分。

图1 5G新型无线电LDPC码的基图Fig.1 Base graph of LDPC code for 5G new radio
1.2 5G NR标准QC-LDPC编码
给定H,LDPC编码的目标是求解奇偶性方程
HcT=0
(5)
式中,c是编码后的码字,由信息位和奇偶校验位组成。QC-LDPC的编码方法包括高斯消除法、Richardson等[16]提出的RU方法以及Nguyen等[17]提出的为5G无线电设计的高效编码方法。一旦PCM被确定,生成矩阵G可以从H中得到。
c=uG
(6)
式中,u是要编码的信息位数组。在5G无线电中,编码的LDPC码字在传输前会被打孔。前2×Z位总是被打孔,而不是传输[18]。
2 QC-LDPC的译码算法
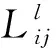
步骤1:初始化APP比和CTV消息。
(7)
Rij=0,1≤i≤M1≤j≤N
(8)
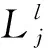
(9)
其次,更新Rij
(10)
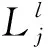
(11)
步骤3:在计算了所有层的CN和所有1≤l≤mb和1≤j≤N的VN后,信息位由最后一层的结果决定,其中,l=mb,
(12)
最终得到译码结果v。
3 基于GPU的高吞吐率LDPC译码技术
在本节中,描述了几种用于5G新型无线电的高吞吐率译码技术。重点介绍使用BG1构建的QC-LDPC码的并行译码过程。译码算法MSA是一种分层译码算法,可以在GPU上进行并行高效译码。为了实现高吞吐率译码,有必要进一步优化译码过程。此外,高码率和大码长对GPU的内存带宽提出了挑战。一般来说,内存访问的开销会影响译码速度。在5G新型无线电中,PCM的大小显著增加,对GPU的内存资源需求也相应增加。在译码时,合理分配GPU上的资源至关重要。
3.1 压缩数据结构
H是一个稀疏矩阵。一般来说,利用压缩结构,而不是将整个PCM传输到GPU。定位H中非零项的常用方法是在译码前生成一个查找表,可以在每一行中存储非零条目的位置。然而,H中每一行的非零条目数量并不完全相同。如果大多数行中的非零条目很少,那么执行相同次数的迭代会造成时间浪费。因此,不仅要记录每行非零位的位置,还要记录非零项的数量。
将Pik表示为H中第i行中第k个非零条目的指数。因为在H中每行最多有kb个非零条目,那么1≤k≤kb。设Ci为第i行的非零条目数,则CN和VN之间的联系可由Pik和Ci决定。压缩H的结构可以节省内存空间和访问时间。而且,压缩在GPU上很容易实现。
除了压缩H外,CTV消息R也可以被压缩。如上所述,VN和CN之间的连接在译码前是已知的。如果VNj和CNi之间存在连接的话,则只需要在第i行中保存VN的消息值。R的大小可以从(mb×Z)×(nb×Z)压缩到(mb×Z)×kb。注意到R的压缩也是GPU上内存凝聚的一种优化方法。CTV消息是译码过程的中间结果。将R压缩到连续空间有助于减少GPU上线程束内的块冲突。
3.2 并行层译码
本文采用的LDPC译码算法是MSA算法,MSA算法适合在GPU上进行并行译码。PCM是使用右移单位矩阵构建的,对于H中的每个Z×Z块,所有非零条目都来自不同的列。当计算CTV和VTC消息从i×Z到(i+1)×Z层时,不存在依赖性,其中i=0,1,…,mb-1。所以可以通过固定的线程分配来实现译码计算。本文为MSA的分层译码分配Z线程。对于5G新型无线电来说,最大的Z为384,不超过GPU上每个块的最大线程数。

(13)
(14)
那么,可以通过式(15)得到VNj的最小值。
(15)

(16)
然后通过式(17)得到S。
(17)
因为只有负值才会影响Sglobal的符号,所以只在Lik<0时更新Sglobal。同时,如果Lik≥0,S=Sglobal。基于此,乘法中的式(10)被式(16)~(17)所取代。这种替换减少了GPU上的计算量。
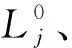

算法1 并行层译码算法
3.3 多块译码
如上所述,每块有Z线程并行译码。但在GPU上,每块最大线程数为1 024或2 048。虽然不建议超过Z的线程数,但最大Z是384,远远没有超过每块线程的最大限制。因此,有可能在同一块内分配更多的线程来译码多个码字。因此,我们实现了多块译码,提高GPU的并行度。让Np作为同一块中被译码的码字数量。那么每个块的线程数为Np×Z。因此,用Nc表示输入码字的数量,为译码内核分配Nc/Np块。有Nc/Np块一起被译码,每个块由Np×Z个线程进行译码。
3.4 存储层次
为了充分利用GPU上的内存资源,经常访问的值被存储在共享内存中。在本文实现中,f、s和L被存储到共享内存中。它们的大小分别是1×Z、1×Z和Z×nb。不建议将R放入共享内存中。因为R的大小是(mb×Z)×kb,BG1中kb=22,最大mb=46。R尺寸过大,以至于把它放在共享内存中可能会限制译码时常驻块的数量,所以本文将R存储在全局内存中。
L的大小只有nb×Z。本文只关心最后的结果,中间的结果会在后几层的迭代中被覆盖。由于译码时经常访问L,所以必须要将L放到离计算单元较近的存储层次中。在5G新型无线电中最大的nb=68,Zmax=384。L的大小小于GPU共享存储的容量。因此将L的值存储到共享内存中,便于GPU的CUDA核心快速访问到L。
3.5 两级量化
以往工作很多都提出了量化方案来提高LDPC的译码吞吐率[20]。在本文实现中,为了更有效地利用带宽,同时减少对性能的损失,提出了一种两级量化方案。
一般来说,GPU支持的内置类型的最小长度为8位。小于8位的量化方案不适合基于GPU的高吞吐率译码。因为较小的长度可能会引入许多类型转换,这些类型转换是为了适应CUDA中原生算术指令支持的最小长度而执行的。与加法和乘法等其他算术运算相比,类型转换在GPU上的吞吐率较低。此外,像AND、XOR以及移位等位元运算吞吐率也很低。

L和R的两级量化可以节省片上带宽。为了实现高吞吐率译码,片上带宽也是需要考虑的重要因素。
两级量化也节省了共享内存和寄存器的空间。驻留块受共享内存占用率的限制。节省共享内存和寄存器有助于实现更多的并行性。与8位方案相比,两级方案的性能损失可以忽略。
3.6 数据打包
数据打包可以减少CPU和GPU之间数据传输造成的译码延迟。译码器的输出是二进制比特位。虽然在GPU上实现比特运算效率不高,但不难发现,我们可以对译码结果进行打包来节省带宽。在本文实现中,每8个译码位在硬性决定后打包成一个8位char值。然后将打包后的数据传输给CPU。
图2显示了译码器在GPU上的内存层次结构和数据打包策略。在译码前,输入数据被量化为4位值,中间值为8位值。L,f和s存储在共享内存中;R存储在全局存储器中。8个译码后的信息位被打包成一个char类型的值。然后将打包后的数据传送给CPU。
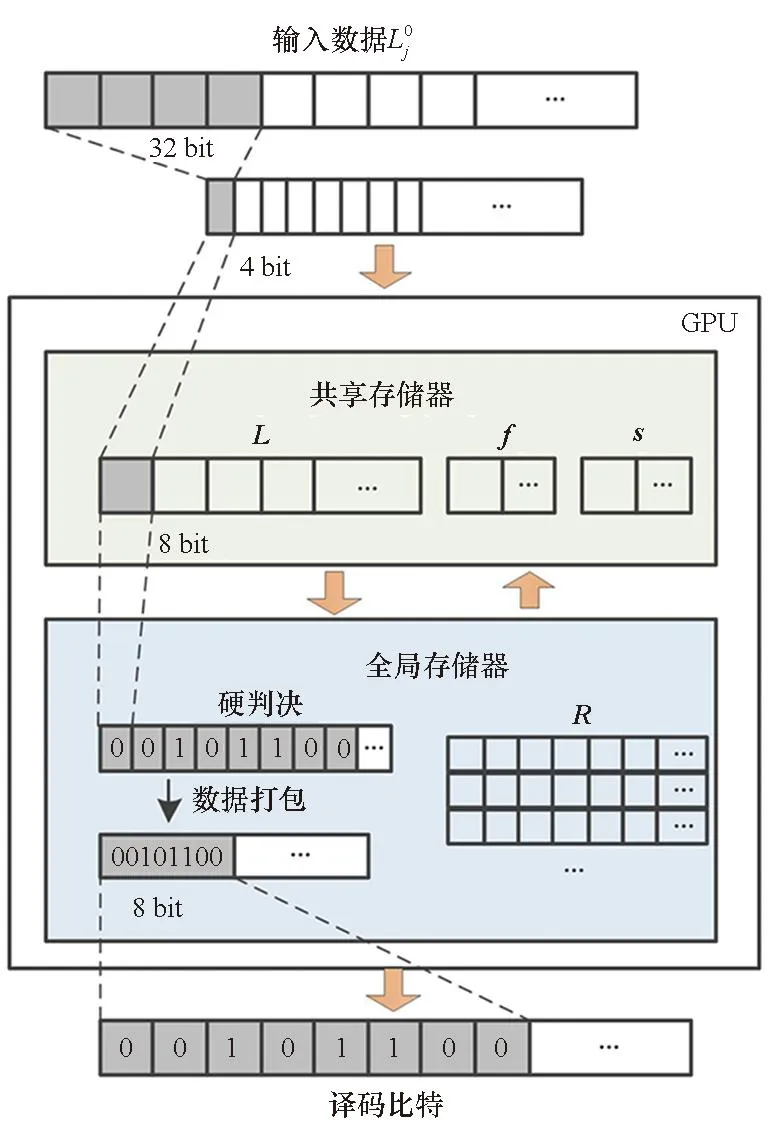
图2 内存层次和数据打包Fig.2 Memory hierarchy and data package
4 实验结果
4.1 实验设置
本文在基于图灵架构的Nvidia RTX 2080Ti上实现了QC-LDPC译码器,该译码器拥有4 352个CUDA核心、68个多处理器和11 GB的GDDR6内存,CPU为Inteli7-8700K,CUDA版本为10.2。
在生成编码值时,采用了正交相移键控调制方式,并用加法白高斯噪声作为信道噪声。MSA的尺度因子为0.75,信噪比为3 dB,d=0.15。在测量译码吞吐率时,不采用提前终止法,所以上述参数设置为常用值。
4.2 译码吞吐率
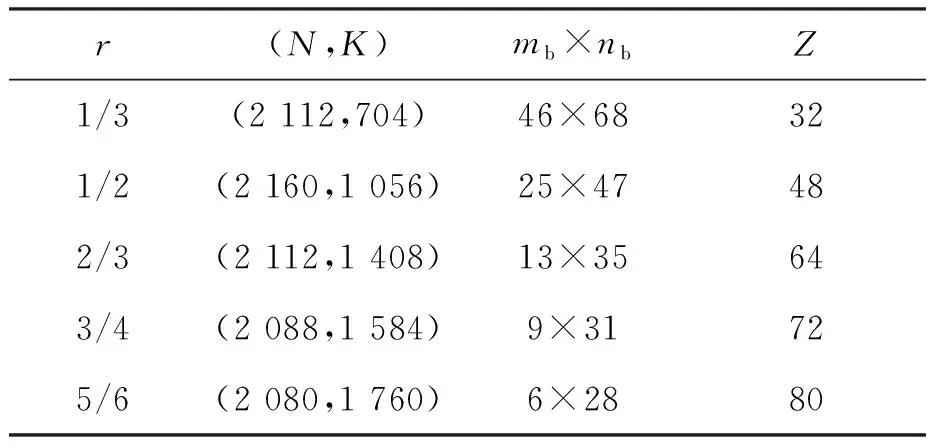
表2 不同码率的基图
采用不同优化方法的译码器的吞吐率结果如表3所示。采用两级量化的量化方式,吞吐率提升了2.1倍。采用多码块译码方法,吞吐率进一步提升了18.6%。此外,数据打包方案也有很好的效果,与不进行数据打包的方法相比,吞吐率获得了16.9%的提高。

表3 不同优化方法下吞吐率性能对比
本文同时测量了表2中不同码率的译码吞吐率。对于高码率,H会被缩短。如表2所示,mb和nb的大小随着码率的增加而减小。如此,迭代次数在水平和垂直方向上都相应减少,这就造成并行译码器的译码时间减少,而吞吐率显著增加。图3描述了不同码率下的译码吞吐率。多码率译码的吞吐率比普通译码的吞吐率平均提高了40%以上。

图3 不同码率下的译码吞吐率Fig.3 Decoding throughput under different code ratio
4.3 线程配置分析
为了最有效地利用GPU上的资源,线程的分配是根据码率来调整的。众所周知,每个线程块和每个多处理器的寄存器和共享内存的数量是有限的。此外,为了避免过载,还要考虑每个流多处理器(streaming multiprocessor, SM)的最大常驻块和线程数。本文将Np、Nr、Nm、Nt表示为每个块的码字数、寄存器数、共享内存数和线程数,并用RSM、MSM、TSM、BSM表示每个SM的最大寄存器、共享内存、常驻线程和常驻块,NSM为GPU上SM的数量,Nb为每个SM上的常驻块。
那么就可以得到相应的线程分配如下
(18)
同时被译码的码块数量可以用以下方法来评估
Nc≤NbNpNSM
(19)
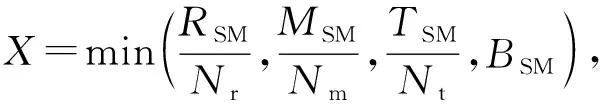
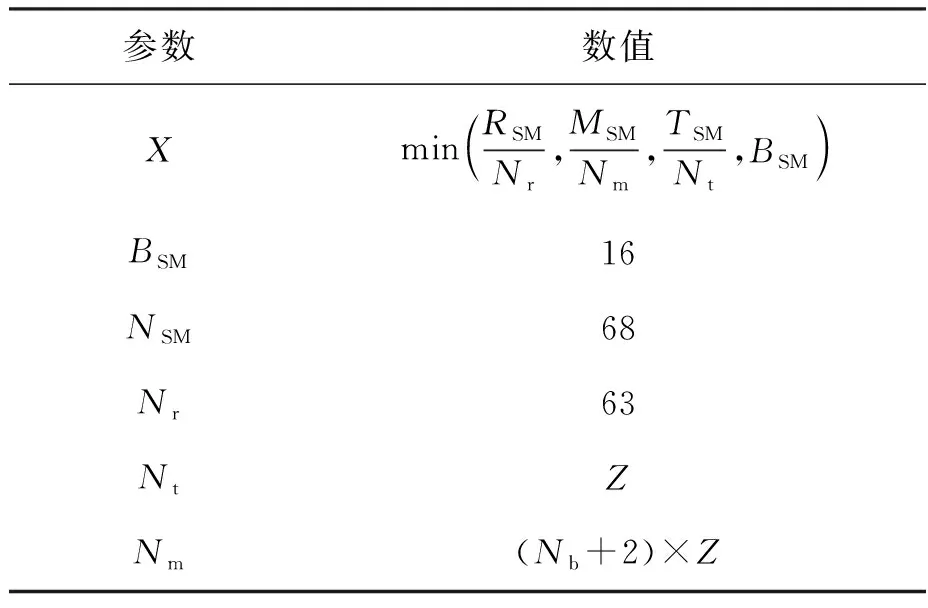
表4 GPU上资源的占用情况
表5描述了RTX 2080Ti上实现的线程参数配置情况下的吞吐率情况。为了实现更高的吞吐率,本文选择了一个合适的Np参数来实现。
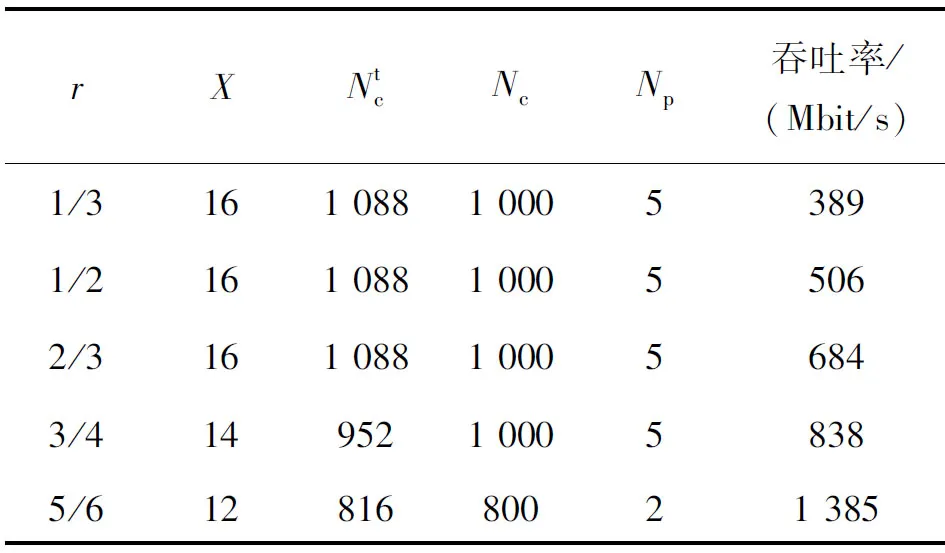
表5 最佳线程分配和吞吐率
图4显示了每个SM中的最大常驻块与GPU上的码率的变化关系。M、R、T、B分别代表共享内存、寄存器、常驻线程和每个SM的常驻块。在低码率情况下,Z很小,限制了每个SM的最大常驻块。在高码率情况下,Z较大,Np和Nc受到每个块的最大线程量和最大共享内存量的限制。最终的常驻块是M、R、T、B四个数值的最小值。

图4 每个SM中的最大常驻块与r的变化关系Fig.4 Changing relationship between the maximum resident block in each SM and r
4.4 性能比较
目前,基于GPU的5G新型无线电的QC-LDPC译码器很少。在5G新型无线电中,信息列的数量kb较多,达到22个,而 WiMAX中最大的非零条目是7个。表6为本文LDPC译码器和其他LDPC译码器的比较。其中,迭代次数为10次,译码算法为MSA的分层译码,表中的吞吐率用Mbit/s表示。虽然我们在译码时需要处理更多的迭代,但本文提出的译码器在高码率下实现了Gbit/s的吞吐率,超过其他相关工作。另外本文利用吞吐率/峰值性能的比值来衡量同样的峰值性能情况下实现的吞吐率,以此来比较不同的工作对GPU峰值性能的利用率。从最终结果可以看出,本文算法峰值性能利用率也是最高的,证明了本文GPU并行算法及优化方法的优越性。
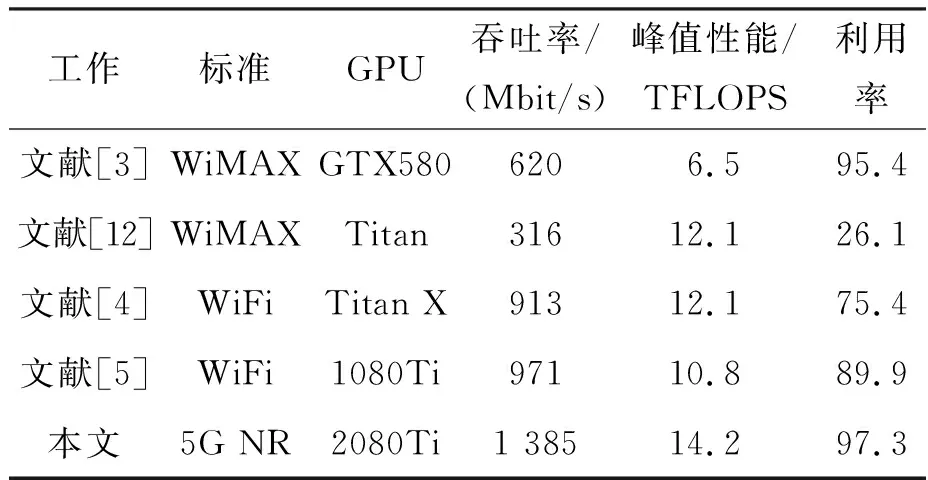
表6 不同GPU的译码器性能比较
5 结论
本文提出了一种基于GPU的5G新型无线电的LDPC译码器。同时提出了基于GPU的并行MSA算法。在实现细节上,本文利用多块译码方法实现了码块内的并行译码,提出了两级量化方案,以进一步节省GPU的片上和片下带宽。通过评估目标GPU的最佳线程分配,最终实现了基于GPU的高吞吐率5G新型无线电LDPC译码器。在(2 080,1 760),r=5/6的配置下,本文提出的译码器吞吐率最高可达到1.38 Gbit/s。
猜你喜欢
学苑创造·B版(2022年3期)2022-04-02 21:55:32
山西电子技术(2019年4期)2019-09-07 08:00:34
成都信息工程大学学报(2018年4期)2019-01-23 06:57:08
少林与太极(2018年8期)2018-08-26 05:53:58
时代英语·高一(2017年5期)2017-11-14 21:39:42
科技风(2017年20期)2017-07-10 18:56:06
软件工程(2014年5期)2014-09-24 11:53:38
电视技术(2014年17期)2014-09-18 00:15:48
计算机工程(2014年3期)2014-06-02 07:50:14
电子世界(2014年21期)2014-04-29 06:41:36
