
BMH2C单模匹配算法的研究与改进
2014-06-02 07:50:14王艳霞江艳霞王亚刚
计算机工程 2014年3期
王艳霞,江艳霞,王亚刚,李 烨
BMH2C单模匹配算法的研究与改进
王艳霞,江艳霞,王亚刚,李 烨
(上海理工大学光电信息与计算机工程学院,上海 200082)
BMH2C算法综合BMH和BMHS算法,利用当前窗口字符[]及其下一字符[+1]组成的双字符串来决定模式串右移量,具有比BM算法、BMH算法、BMHS算法更优的性能。但对于双字符串在模式串中出现一次及以上的情况,BMH2C算法中的模式串右移量仍有待进一步增大,从而减少当前窗口右移次数,提高BMH2C算法的匹配效率。为此,在BMH2C算法的基础上提出一种改进算法,该算法考虑双字符串[][+1]在模式串中出现的次数,以及该双字符串在模式串中对应位置的后继字符与字符[+2]的相等关系。改进算法利用2个右移数组和1个模式串预处理数组,在匹配过程中通过判断字符[+2]与模式串预处理数组中相应字符是否相等,从而选择2个右移数组之一的对应值作为当前窗口的右移量。实验结果显示,在相同条件下,对于当前窗口移动次数和匹配所耗时间,BMH2C改进算法比BMH2C算法分别平均减少11.33%和9.40%,有效提高了匹配效率。
模式匹配;BMH2C算法;字符串;右移;预处理
1 概述
模式匹配是指在文本串=[0,1,…,-1]中找到一个模式串=[0,1,…,-1](≥),即模式串是文本串的子串[1]。模式匹配有单模匹配和多模匹配2种[2],经典的单模匹配算法有KMP算法[3]、BM算法[4]。KMP算法的字符比较是从左到右进行的,且模式串右移量一般较小,而BM算法采用了从右到左的匹配,其右移量由坏字符规则和好后缀规则共同决定,最大值可达到模式串的长度,因而BM算法比KMP算法更优,得到了极为广泛的应用[5]。与此同时,BM算法的各种改进算法也层出不穷,如BMH算法、BMHS算法、BMH2C算法等。这3种算法都只采用了坏字符规则,不同的是BMH算法利用当前窗口字符决定模式串右移量,BMHS算法利用当前窗口下一个字符决定右移量,而BMH2C算法利用当前窗口字符及其下一个字符组成的双字符串决定右移量。它们简化了预处理阶段的时间开销[6],匹配效率比BM算法高。而且BMH2C算法利用了双字符串在模式串中出现的概率比单个字符小的特点,匹配性能较前几者更佳。但是对于双字符串在模式串中出现一次及以上的情况,BMH2C算法无法做到每次获得最大右移量,匹配过程中当前窗口移动次数有待进一步降低以提高匹配效率。
针对上述BMH2C算法存在的缺陷,本文提出一种改进算法I_BMH2C。考虑到当前窗口双字符串[][+1]在模式串中出现的次数,以及双字符串的后继字符[+2]与该双字符串在模式串中的后继字符是否相等,I_BMH2C在BMH2C算法的基础上分别新增一个模式串右移数组和一个模式串预处理数组。匹配过程中通过判断字符[+2]与模式串预处理数组中相应字符是否相等,从而选择右移数组。
2 BM算法及其相关算法
2.1 BM算法
BM算法的三大特点是采用了从右至左的扫描方式、坏字符规则以及好后缀规则。首先文本串[0,1,…,-1]的最左端与模式串[0,1,…,-1](为文本串的长度,为模式串的长度,≥)的最左端对齐,然后在当前窗口字符[]处从右至左扫描,依次比较[]和[-1],[-1]和[-2],…,[-+1]和[0]。若发现某处不匹配,则根据预处理好的数组和数组,将模式串向右移动两者中较大者的距离,依次重复上述步骤,直到匹配成功或是文本串中的字符全部比较完。
2.1.1 坏字符规则
数组的定义分2种情况:字符不在模式串中。字符在模式串中,设为在模式串中最右位置处的下标。
数组的定义如下:
在从右至左的扫描过程中,若文本串中某个字符[-](0≤<)与模式串中的字符[--1]不相等,则称[-]为坏字符,根据预先处理好的数组将模式串向右移动[[-]]个字符。
2.1.2 好后缀规则
数组计算公式如下:
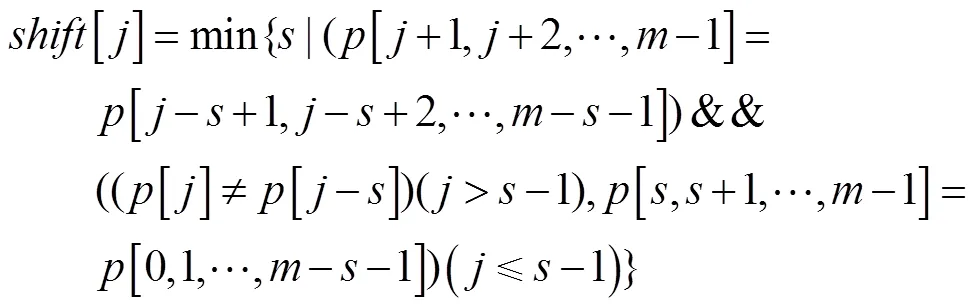
假设匹配进行到比较文本串字符[-+1,-+2,…,]和模式串字符[0,1,…,-1],从右至左的扫描过程中,发现[-++1]与[]失配的同时,已有[-++2,-++3,…,]与[+1,+2,…,-1]匹配成功,则称[-++ 2,-++3,…,]为好后缀。此时模式串根据预先计算好的[]值向右移动相应的距离。
关于坏字符规则和好后缀规则,文献[7]研究表明:BM算法中模式串的右移量在绝大多数情况下取决于坏字符规则,且坏字符规则较好后缀规则简单易于实现。
2.2 BMH算法及BMHS算法
文献[8]提出了一种改进的BM算法——BMH算法。该算法只使用了坏字符规则。在匹配过程中若发现某处不匹配,则根据当前窗口字符[]来启发模式串的右移量。令[]=,则具体的移动公式如下:
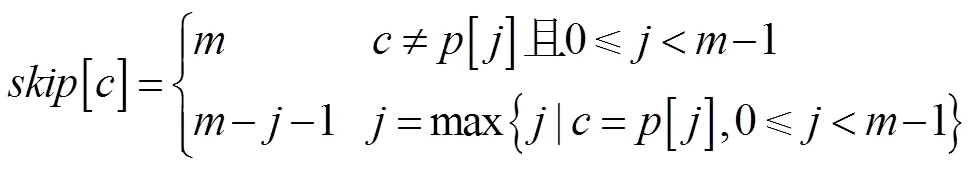
由于数组的预处理比数组的预处理要简单得多,而且BMH算法省去了两者比较大小这一步骤,因此在实际匹配过程中BMH算法效率要高于BM算法。
在BMH算法的基础上,文献[9]提出了BMHS算法,该算法与BMH算法的思想基本一致[10-11],不同之处在于BMHS算法是利用当前窗口的下一个字符[+1]来启发模式串的右移量。
2.3 BMH2C算法
模式匹配算法效率的高低主要取决于模式串向右移动的次数,即当前窗口向右移动的次数。当失配发生时,若模式串每次移动尽可能大的距离,显然减少了当前窗口总的移动次数,可以有效地提高匹配效率。因此,文献[12]在BMH和BMHS算法的基础上提出了一种新的改进算 法——BMH2C算法。该算法的基本思想也是基于坏字符规则,与BMH、BMHS算法的不同之处在于利用了当前窗口字符[]及其下一个字符[+1]所组成的双字符串[][+1]来启发当前窗口的右移距离:若双字符串[][+1]不在模式串中,且[+1]与[0]不相等,则模式串右移+1;若字符串[][+1]不在模式串中,但[+1]与[0]相等,则模式串右移;若[][+1]出现在模式串[][+1](0≤≤-2)处,则右移模式串使得两者对齐。
BMH2C算法的预处理部分可以用一个二维数组来表示,设字符集为ASCII码,大小从0到255,则数组预处理算法如下:
//将字符集中任意2个字符组成的字符串的skip值初始化为//m+1
for i=0 to 255{
for j=0 to 255{
skip[i][j]=m+1; j++;
}
i++;
}
//若任意2个字符组成的字符串的后一个字符与p[0]相等,则//重新赋值为m
for i=0 to 255{
skip[i][p[0]]=m; i++;
}
//模式串中的字符串根据其位置来确定skip值
for i=0 to m-1{
skip[p[i]][p[i+1]]=m-i-1; i++;
}
从右向左扫描的过程中,若遇到坏字符,则模式串向右移动[[]][[+1]]个字符。下面用一个实例来说明BMH2C算法的匹配过程,如图1所示:文本串=“decbedade abaccdcdeadbad”,模式串=“adbad”。由图可以看出,当前窗口一共向右移动了6次。
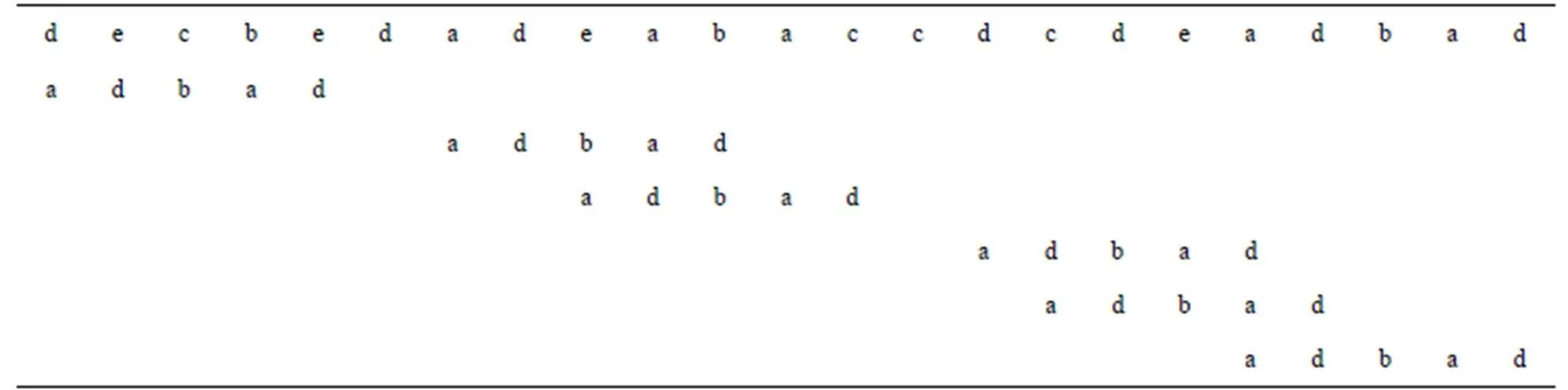
图1 BMH2C算法的匹配过程
设字符集中每个字符在模式串中出现的概率为(0<< 1),则2个字符同时出现在模式串中的概率为2。显然,双字符串出现在模式串中的概率远低于单个字符出现在模式串中的概率,在实际匹配过程中,BMH2C算法的平均移动量较BMH和BMHS算法都大,有效减少了模式串向右移动的次数,匹配效果更好。
3 改进的BMH2C算法
3.1 I_BMH2C算法设计思路
为了进一步提高BMH2C算法的效率,本文提出了I_ BMH2C算法。通过观察文本串和模式串可知:一部分双字符串不会在模式串中出现,另一部分双字符串仅在模式串中出现一次,还有较少一部分双字符串可出现2次或2次以上。此时需分3种情况讨论:
(1)当[][+1]在模式串中出现0次时,模式串右移,直接跳过该双字符串。
(2)当[][+1]在模式串中出现1次时,设在[][+1] (0≤≤-3)处:若双字符串[][+1]的后一个字符[+2]与双字符串[][+1]的后一个字符[+2]不相等,则模式串右移,直接跳过[][+1];若[+2]=[+2],则模式串右移--1个字符。另外还有一种特殊情况需单独考虑:当[][+1]出现在模式串[-2][-1]处时,由于[-1]后面没有字符,此时模式串向右移动一个字符。
(3)当[][+1]在模式串中出现2次或2次以上,模式串按从右向左统计,设第1次出现在[][+1](1≤≤-2)处,第2次出现在[][+1](0≤<)处:若[+2]≠[+2],则模式串右移--1个字符,否则右移--1个字符。
该算法的具体设计思路为:在BMH2C算法原有右移数组1的基础上新增一个模式串右移数组2,在匹配过程中若发现某处失配,则判断[][+1]的后一个字符[+2]和[][+1]的后一个字符[+2]是否相等,若不等则将模式串向右移动2[[]][[+1]]个字符,否则移动1 [[]][[+1]]个字符。其中,2数组的设计思想是:首先初始化2数组,方法同1数组;然后按模式串从右至左统计各双字符串[][+1](0≤<-1)在模式串中出现的次数,当统计值为2时,假设此时统计进行到[][+1] (0≤<-2),则将2[[]][[+1]]重新赋值为--1;此外还需单独考虑上述(2)中的一种特殊情况,由于[-1]后面没有字符,2[[-2]][[-1]]=1。由1和2数组的对比可知,2数组的值大于或等于1的对应值,因此,该算法可使得模式串每次向右移动尽可能大的距离,从而提高匹配效率。
3.2 I_BMH2C算法的预处理
预处理阶段需用到2个跳跃数组1和2。1的计算方法和BMH2C算法中的一样,此处主要讲解2的求解方法。
//将字符集中任意2个字符组成的字符串的skip2值初始化为//m+1
for i=0 to 255{
for j=0 to 255{
skip2[i][j]=m+1;j++;
}
i++;
}
//若任意2个字符组成的字符串的后一个字符与p[0]相等,则//重新赋值为m
for i=0 to 255{
skip2[i][p[0]]=m; i++;
}
//从右至左统计模式串中双字符串p[i]p[i+1]出现的次数
for i=m-2 to 0{
统计次数
//当统计到某个双字符串出现第2次时计算出对应的右移 //量,计算方法与BMH2C算法一样
if(字符串p[i]p[i+1]出现的次数==2)
Then skip2[p[i]][p[i+1]]=m-i-1;
endif
i––;
}
//当t[k]t[k+1]出现在p[m-2][m-1]处时,模式串向右移动一//个字符
skip2[p[m-2]][p[m-1]]=1;
由于在匹配过程中要判断[+2]与[+2]是否相等,预处理阶段还涉及到一个数组[][]。假设[][+1]出现在模式串[][+1]处,则[[]][[+1]]存放的是字符[+2],而+2又可用-1[[]][[+1]]+1表示,因此[[]][[+1]]=[-1[[]][[+1]]+1]。
//prep数组的预处理
for i=0 to 255{
for j=0 to 255{
prep[i][j]=p[m-skip1[i][j]+1]; j++;
}
i++;
}
3.3 I_BMH2C算法匹配过程
假设匹配进行到比较[0,1,…,-1]和[-+1,-+2,…,],从右至左比较[]和[-1],[-1]和[-2],[-2]和[-3],…,若发现某处失配,则判断[[]] [[+1]]与[+2]是否相等,此时分2种情况讨论:
(1)若不相等,则模式串右移2[[]][[+1]]。
(2)若相等,则模式串右移1[[]][[+1]]。
以上2种情况已包含了双字符串[][+1]不在模式串中的情况,所以不必单独考虑。匹配算法伪代码描述如下:
for k=m-1 to n-1
{//文本串与模式串的最左端对齐,t[k]为当前窗口字符
i=k; j=m-1;
While(t[i]==p[j])//从右至左依次扫描,若某处失配则跳出循环
i––; j––;
EndWhile
If(j==-1)
Then return(i+1);
//匹配成功,返回模式串在文本串中出现的指针
Endif
If(prep[t[k]][t[k+1]]!=t[k+2])
Then k=k+skip2[t[k]][t[k+1]];//采用改进的I_BMH2C算法//将当前窗口右移skip2[t[k]][t[k+1]]
Else Then k=k+skip1[t[k]][t[k+1]];
Endif
}
下面用实例来具体说明I_BMH2C算法的匹配过程,如图2所示。
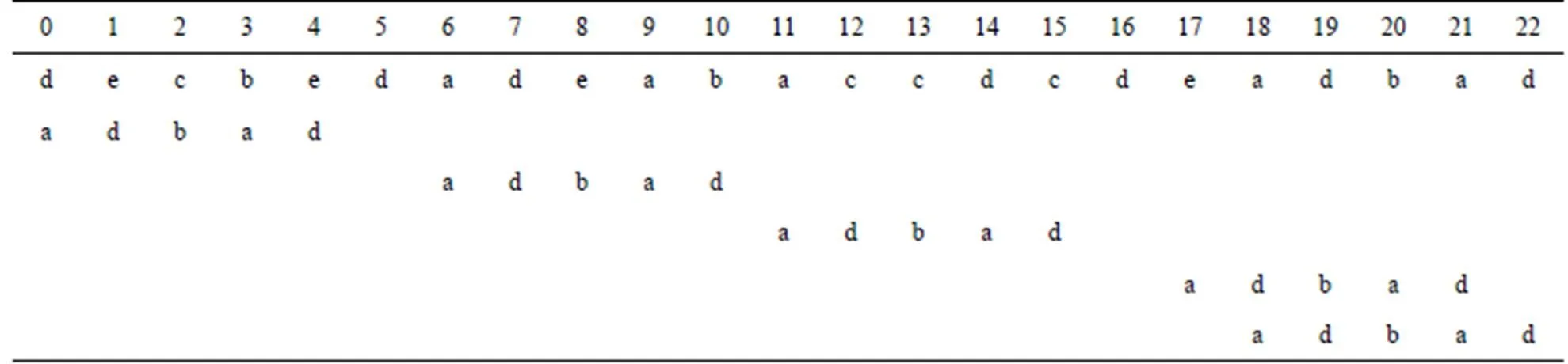
图2 I_BMH2C匹配过程
第1轮匹配时,当前窗口的指针=4,双字符串[4][5]不在模式串中,模式串右移1[[4]][[5]]=2[[4]] [[5]]=5+1=6个字符;第2轮匹配时,当前窗口的指针= 4+6=10,双字符串[10][11]在模式串[2][3]处出现1次,由于[4]≠[12],模式串右移2[[10]][[11]]=5个字符;第3轮匹配时,当前窗口的指针=10+5=15,双字符串[15][16]不在模式串中,模式串右移1[[15]][[16]]=2 [[15]][[16]]=6;第4轮匹配时,当前窗口的指针=15+6=21,双字符串[21][22]在模式串[3][4]处出现1次,模式串右移1[[21]][[22]]=1个字符;第5轮匹配成功。整个过程模式串右移了5次。
4 实验结果
从理论上来讲,I_BMH2C算法产生最大右移量的概率比BM、BMH、BMHS、BMH2C算法都高,当前窗口移动次数会相应减少,匹配效果更优。
本文实验是在虚拟机上进行的,实验环境为:物理机系统Microsoft Windows XP SP3,配置为Intel CPU 2.66 GHz,内存3.25 GB;虚拟机为VMware Workstation 9,系统Ubuntu11.10,配置为内存1 GB,硬盘50 GB,编译器为 gcc 4.6.1。
实验1采用的是一段纯英文文本,大小为20.5 MB,通过BM、BMH、BMHS、BMH2C、I_BMH2C这5种算法对不同长度模式串分别进行匹配,统计匹配过程中窗口右移次数;实验2是对大小为55.1 MB的纯英文文本统计各种算法匹配用时。
实验1测试5种算法的窗口右移次数,结果如表1 所示。
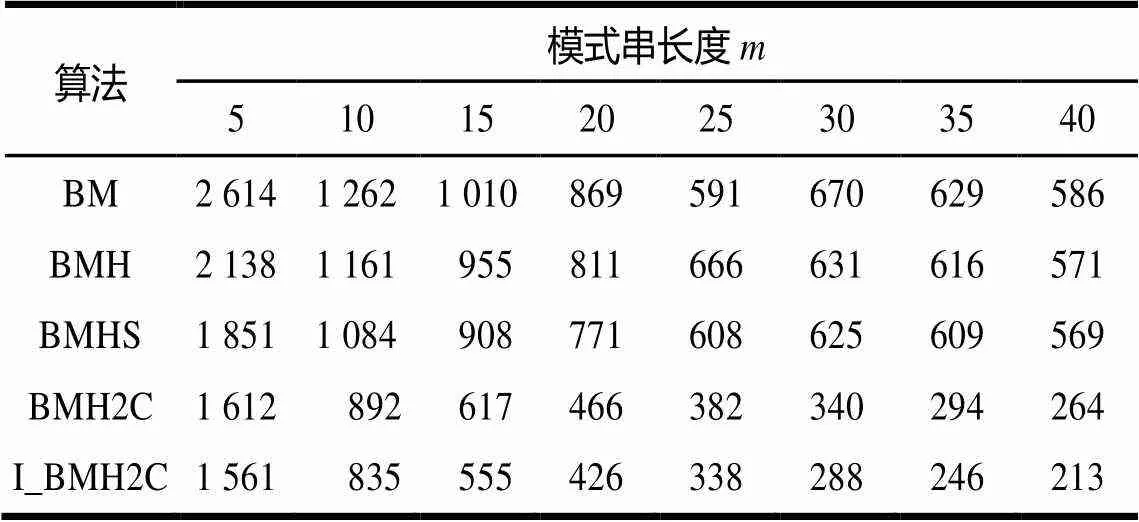
表1 窗口右移次数
实验2测试各种算法匹配用时,结果如表2所示。

表2 匹配消耗时间 ms
由实验1和实验2可以看出,在模式串一定的情况下,采用I_BMH2C算法所需的窗口移动次数和匹配所耗时间比BM、BMH、BMHS、BMH2C算法均小,且由计算可得:I_BMH2C算法的当前窗口移动次数比BMH2C的平均少11.33%;I_BMH2C算法的匹配所耗时间比BMH2C的平均少9.40%。因此,本文对BMH2C的改进算法I_BMH2C有效地减少了模式匹配过程中窗口右移次数,也减少了匹配所耗时间,提高了匹配效率。
5 结束语
模式匹配效率的高低直接影响到计算机系统性能的好坏。本文介绍了经典的BM算法及其改进算法BMH和BMHS算法,重点介绍了BMH2C算法,并在该算法的基础上提出了一种改进的I_BMH2C算法,I_BMH2C算法有效提高了产生最大右移量的概率,使得匹配过程中窗口移动次数减小,匹配速度更快,较BM、BMH、BMHS、BMH2C算法更优。
[1] 钱 颖, 刘国华, 陈子阳, 等. 模式匹配技术[J]. 燕山大学学报, 2006, 30(4): 340-344.
[2] 张 娜, 张 剑. 一个快速的字符串模式匹配改进算法[J].微电子学与计算机, 2007, 24(4): 102-105.
[3] 杨战海. KMP模式匹配算法的研究与分析[J]. 计算机与数字工程, 2010, 38(5): 38-41.
[4] Boyer R S, Moore J S. A Fast String Searching Algorithm[J]. Communications of the ACM, 1977, 20(10): 762-722.
[5] 揣锦华, 郑 景, 关 锐. BM模式匹配算法的研究和改 进[J]. 电子设计工程, 2012, 20(19): 52-54.
[6] 单懿慧, 蒋玉明, 田诗源. 面向入侵检测的改进BMHS模式匹配算法[J]. 计算机工程, 2009, 35(24): 170-173.
[7] 刘胜飞, 张云泉. 一种改进的BMH模式匹配算法[J]. 计算机科学, 2008, 25(11): 164-166.
[8] Horspool R N. Practical Fast Searching in Strings[J]. Software Practice and Experience, 1980, 10(6): 501-506.
[9] Sunday D M. A Very Fast Substring Search Algorithm[J]. Communications of the ACM, 1990, 33(3): 132-142.
[10] 张红梅,范明钰. 模式匹配BM算法改进[J]. 计算机应用研究, 2009, 26(9): 3249-3252.
[11] 万晓榆, 杨 波, 樊自甫. 改进的Sunday模式匹配算法[J].计算机工程, 2009, 35(7): 125-126, 129.
[12] 钱 屹, 侯义斌. 一种快速的字符串匹配算法[J]. 小型微型计算机系统, 2004, 25(3): 410-413.
编辑 顾逸斐
Research and Improvement of BMH2C Single Pattern Matching Algorithm
WANG Yan-xia, JIANG Yan-xia, WANG Ya-gang, LI Ye
(School of Optical-Electrical and Computer Engineering, University of Shanghai for Science and Technology, Shanghai 200082, China)
BMH2C algorithm combines BMH and BMHS algorithm. In BMH2C algorithm, the right shift distance of pattern string is determined by the double string, which is made of the character[] of the current window and the next character[+1]. BMH2C algorithm has better performance than BM, BMH and BMHS algorithm. Nevertheless, the right shift distance of pattern string in the BMH2C algorithm remains to be further increased, when the double string appears for one time or more than one time. Do like that, the number of window’s shift will be greatly reduced and the matching speed improved effectively. Therefore, an improved algorithm based on BMH2C algorithm is proposed. It takes the number of appearance in the pattern string of the double string[][+1] into account. And the equality relationship of character[+2] and the character which is followed the appropriate position of[][+1] in the pattern string is considered. The improved algorithm uses two right shift arrays and a pretreated array of the pattern strings. During the matching, the corresponding value of one of the two right shift arrays is selected as the right shift distance of current window, by judging the equality relationship of character[+2] and the corresponding character in the pretreated array. Experimental results show that the improved BMH2C algorithm is respectively 11.33% and 9.40% less than BMH2C algorithm on average in the same conditions, for the matching time and the number of window’s shift. With the algorithm, the matching speed is improved effectively
pattern matching; BMH2C algorithm; character string; right shift; pretreatment
1000-3428(2014)03-0298-05
A
TP301.6
国家自然科学基金资助项目(61074016, 61074087);上海市研究生创新基金资助项目(JWCXSL1202);上海市教育委员会科研创新基金资助项目(12ZZ144)。
王艳霞(1986-),女,硕士研究生,主研方向:3G/4G网络通信技术,模式识别;江艳霞,讲师;王亚刚,教授;李 烨,高级工程师。
2013-04-03
2013-06-02 E-mail:jiangyanxia@usst.edu.cn
10.3969/j.issn.1000-3428.2014.03.063
猜你喜欢
学苑创造·B版(2022年3期)2022-04-02 21:55:32
电子制作(2019年13期)2020-01-14 03:15:32
移动信息(2018年1期)2018-12-28 18:22:52
数学大王·中高年级(2018年11期)2018-12-17 08:13:54
中央民族大学学报(自然科学版)(2018年3期)2018-11-09 01:16:38
少林与太极(2018年8期)2018-08-26 05:53:58
山东工业技术(2015年21期)2015-07-27 08:18:10
软件工程(2014年5期)2014-09-24 11:53:38
电脑迷(2014年8期)2014-04-29 07:37:40
卷宗(2011年9期)2011-05-14 17:51:19
