
基于中位数的用户信誉度排名算法
2014-06-02 07:50:10牛军钰
计算机工程 2014年3期
鲍 琳,牛军钰,庄 芳
基于中位数的用户信誉度排名算法
鲍 琳,牛军钰,庄 芳
(复旦大学软件学院,上海 201203)
针对推荐系统易受Spammer攻击的影响,从而导致对象的实际得分不准确的问题,提出基于中位数的用户信誉度排名算法。通过衡量用户信誉度调整用户打分权重,根据中位数具有不易受极端打分影响的特性,选取用户打分与对象得分差距的中位数作为降低用户信誉度的标准,不断迭代调整用户信誉度以及最终得分直至收敛。在多个真实数据集上的运行结果证明,相比现有排名算法,该算法具有更合理的信誉度分布和更高的排名结果准确度,通过该算法预处理后的数据集在SVD++上运行可以得到更低的均方根误差。
推荐系统;用户信誉度;Spammer攻击;协同过滤;中位数;均方根误差
1 概述
基于Web的打分排名系统在电子商务与消费点评网站中有着广泛的应用,各类商品的评价排名结果影响着用户的选择,因此,排名系统成为了Spammer的重点攻击对象。如何提高排名系统的准确度,是近年来数据挖掘领域的研究热点。一个优秀的排名算法应足够健壮,以抵挡Spammer的攻击,并且具有可收敛等特性[1-2]。为此,现有较多研究引入用户信誉度[3]的概念,对用户的打分重新评估,减少Spammer对最终排名的影响。目前基于用户信誉度的推荐系统主要分为2种类型:内容驱动型[4-5]和用户驱动型。其中,用户驱动型主要是根据用户给对象的评分来评估该用户的信誉度。
本文在对文献[6]算法进行实验、分析的基础上,利用中位数不易受极端打分影响的特性,提出基于中位数的用户信誉度排名算法:L1MED和L2MED,以提高打分系统排名结果的准确度。
2 简单的打分系统
基于用户信誉度的排名算法的主要思想为:打分结果总是与用户群体打分差距较大的用户,其信誉度较低,应减少其打分在计算总分时的权重。

图1 简单的打分系统
3 基于用户信誉度的排名算法及其存在问题

实际上,在实现文献[6]提出的算法过程中发现,在L1MIN、L2MIN算法中,用户的信誉度基本没有减少,当得分收敛时,用户的信誉度几乎始终保持在1的位置,即L1MIN和L2MIN有退化为算术平均算法的趋势;而对于L1MAX、L2MAX与L1MIN、L2MIN则相反,用户的信誉度将会集中在区域的最左端,只在一个很小的范围内有值,相当于为所有的用户打分乘上了一个小于1的常数。这样的结果并不理想,本文希望得到一个较平均的信誉度分布。
为了检验L1AVG、L2AVG、L1MAX、L2MAX、L1MIN和L2MIN算法的效率性和强壮性,文献[6]分别计算这6种算法与算术平均算法(Mizz、YZLM、dKVD)之间的Kendall Tau距离,得出这6种算法与算术平均算法的Kendall Tau距离比Mizz、YZLM、dKVD算法的距离更小。由于L1MIN和L2MIN对用户信誉度的惩罚过少,根据L1MIN和L2MIN算法计算出的最终打分结果与算术平均算法的计算结果相差无几,因此,相近的距离无法证明这2种算法的有效性。
随机选取一些用户,并将其打分取反,例如,若满分为5,用户原本对某对象的打分为4,则将其打分改为1,然后观察这个改变对于用户信誉度的影响。
经过上述处理后运行文献[6]中的算法,得到表1的结果。可以发现,MIN算法的结果没有受到任何影响,这种情形是不合理的;MAX的2个算法受影响相对较小,AVG和MED表现较为正常,用户的信誉度有较明显的变化。L1MED和L2MED是本文提出算法,与其他6种算法相比,它们采用了用户评分与对象得分差距的中位数作为降低用户信誉度的标准。

表1 打乱用户打分对不同算法信誉度的影响
4 基于中位数的改进用户信誉度排名算法
根据上述分析和简单实验的结果,希望得到的算法应有2个基本特性:(1)用户的信誉度不应聚集在一起,而应更接近于正态分布;(2)其结果应与一个标准排序序列相似。
本文将中位数作为惩罚用户信誉度的标准。中位数的作用与算术平均数相近,在一个等差数列或一个正态分布数列中,中位数与算数平均数相等。在数列中出现了极端变量值的情况下,因中位数不受极端变量值的影响,使用中位数比使用算数平均更合理。对于打分偏极端的Spammer来说,或许中位数更能反映其打分的真实情况。由此,本文提出L1MED算法和L2MED算法。



一次迭代过程的伪代码具体如下:
Begin
for i←0 to 对象数
sum←0
count←0
for j←0 to 为对象objects[i]评过分的用户数
sum←sum + rating[i, userId] ×该用户的信誉度
count←count + 1
grades[i]←sum / count
for j←0 to 用户数
mid ← getMid(users[j])
reputations[j] ← 1 – λ * mid
End
表2是L1MED算法在数据集MovieLen上迭代的部分得分结果,取0.2,本文只选取其中一个片段。

表2 λ=0.2时MovieLen上迭代的部分得分结果
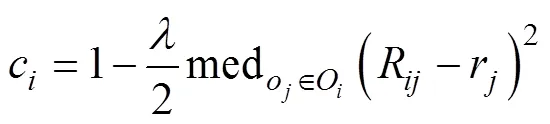
另外,添加系数1/2保证收敛,对应L2MED算法的信誉度相关公式如下:
5 实验与结果分析
在介绍所采用的数据集、评估指标和实验参数设置的基础上,对本文算法与现有算法进行比较,并对实验结果进行分析。
5.1 数据集
在实验过程中,本文使用以下数据集:(1)MovieLens 1M:该数据集是从MovieLens网站上收集而来的电影评分数据,包涵6 000个用户、4 000部电影的1百万条评分信息;(2)Epinions:该数据集是从Epinions(www.epinions.com)(一个产品评论网站)上收集而来,包括40 163个用户对139 738个产品的1 149 766条评分记录。
5.2 对比标准
在文献[6]中,使用算术平均算法作为与其他算法对比的基准线。算术平均是大多数信息检索(Information Retrieval, IR)社区使用计算得分的算法,它选择相信所有用户的打分真实性,不考虑用户的信誉度,但因为该算法的简易性及普及性,在此把它作为算法准确度的评价基准,并计算算术平均算法和各种排名算法两者之间得分向量的L1距离。
SVD++[10]是在Netflix比赛中获奖的一个协同过滤算法[11-12]模型,利用隐式反馈信息找到用户的偏好,依此将用户对电影的评分重新调整,从而向用户推荐适合他们的电影。
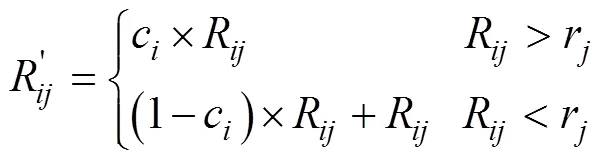
5.3 参数设定
在SVD++的实验部分,取迭代次数为20,学习率(learning rate)设定为0.001。
5.4 结果分析
图2、图3分别展示了算数平均算法和各种排名算法得分之间的相关性。图2展示了MovieLen数据集上8种算法与算数平均算法之间得分的L1距离,L1MIN、L2MIN与算术平均算法之间的差距极小,因惩罚过小,对对象得分的影响微乎其微;在距离计算方式下,MED比AVG结果更加接近算术平均算法;MAX因惩罚过大,与算术平均算法之间的差距为所有算法中差距最大的。图3说明了Epinions数据集上的运行结果,和MovieLen上得出的结论相近。
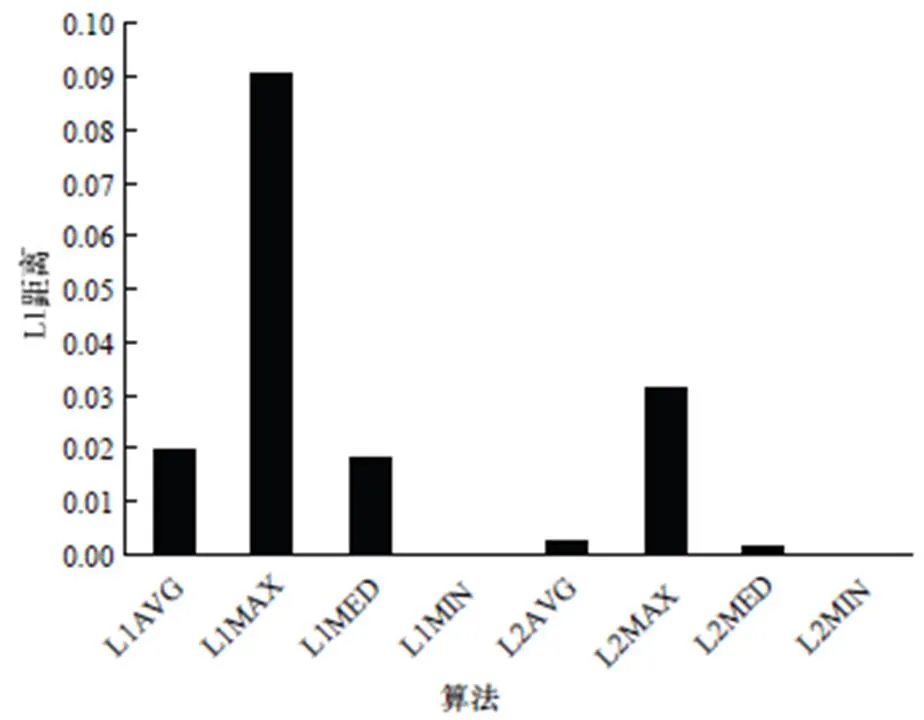
图2 MovieLen数据集上各算法与算术平均算法之间的L1距离
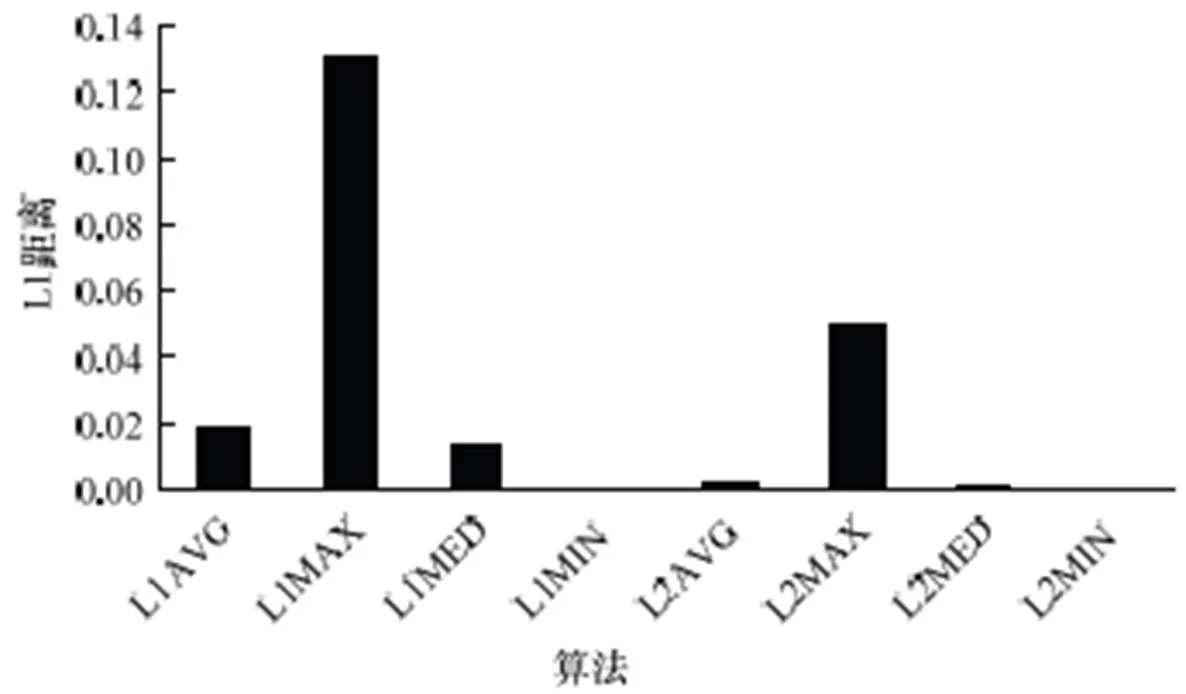
图3 Epinions数据集上各算法与算术平均算法之间的L1距离
图4显示了L1AVG、L1MED、L2AVG、L2MED算法计算出的用户信誉度的分布(由于L1MIN、L2MIN、L1MAX、L2MAX算法的信誉度分布过于集中,如放到同一张图中,无法看清其他算法的分布)。从图4可以看出,L1AVG和L1MED有比较平均且相似的分布;在曲线的中间段,L1AVG比L1MIN更加平滑;相对地,L2AVG和L2MIN也有比较相似的分布,但是两者用户信誉度都相对比较集中,只在一个很小的分数段内才有数值。

图4 λ=0.2时MovieLen上用户信誉度分布
经上述分析得出,L1MED和L2MED算法有相对平均的用户信誉度分布,并与算术平均算法的距离更接近。
表3列出了SVD++上运行MovieLen数据集后所得RMSE值,以及用L1AVG、L1MED、L2AVG、L2MED算法预处理MovieLen数据集后,运行所得RMSE值。

表3 原MovieLen和4种算法处理后的数据集RMSE
从表3可看出,预处理后的数据集对RMSE的值有所提升,符合期望。其中,L1MID的提升量最大,L1AVG次之,L2AVG和L2MIN相对MovieLen的原始数据集也有少量提升。在计算效率上,L1MED和L2MED由于需要寻找中位数,相对其他算法效率降低,但仍在可接受范围之内。
6 结束语
根据中位数不易受极端打分影响的特性,在已有基于用户打分的推荐系统基础上,提出2种新算法:L1MED和L2MED,这2种算法在2个不同的公开数据集上运行,将运行结果与已有算法做了比较,证明本文提出算法的准确性。同时,将算法预处理后的数据应用于SVD++上,结果比无处理的原始数据更优秀,证明了算法的有效性。下一步将考虑用户打分的时间顺序属性,分析用户打分受已有打分影响的可能性,并试图减少羊群效应所造成的影响,从而将本文算法推广到更广泛的应用场景中。
[1] Jøsang A, Golbeck J. Challenges for Robust Trust and Repu- tation Systems[C]//Proceedings of the 5th International Workshop on Security and Trust Management. Saint Malo, France: [s. n.], 2009.
[2] 许海玲, 吴 潇, 李晓东, 等. 互联网推荐系统比较研究[J]. 软件学报, 2009, 20(2): 350-362.
[3] Resnick P, Kuwabara K, Zeckhauser R, et al. Reputation Systems[J]. Communications of the ACM, 2000, 43(12): 45-48.
[4] Adler B, de Alfaro L. A Content-driven Reputation System for the Wikipedia[C]//Proceedings of the 16th International Conference on World Wide Web. New York, USA: ACM Press, 2007: 261-270.
[5] Adler B, de Alfaro L, Kulshreshtha A, et al. Reputation Systems for Open Collaboration[J]. Communications of the ACM, 2011, 54(8): 81-87.
[6] Li Ronghua, Jerry Yuxu, Huang Xin, et al. Robust Reputation- based Ranking on Bipartite Rating Networks[C]//Proceedings of the 2012 SIAM International Conference on Data Mining. [S. l.]: SDM Press, 2012: 612-623.
[7] Mizzaro S. Quality Control in Scholarly Publishing: A New Proposal[J]. Journal of the American Society for Information Science and Technology, 2003, 54(11): 989-1005.
[8] Yu Yikuo, Zhang Yicheng, Laureti P. Decoding Information from Noisy, Redundant, and Intentionally Distorted Sources[J]. Physica A: Statistical Mechanics and Its Applications, 2006, 371(2): 732-744.
[9] de Kerchove C, van Dooren P. Iterative Filtering in Reputation Systems[J]. SIAM Journal on Matrix Analysis and Applications, 2010, 31(4): 1812-1834.
[10]Koren Y, Bell R. Advances in Collaborative Filtering[M]//Ricci F, Rokach L, Shapira B, et al. Recommender Systems Handbook. [S. l.]: Springer, 2011: 145-186.
[11] 邓爱林, 朱扬勇, 施伯乐. 基于项目评分预测的协同过滤推荐算法[J]. 软件学报, 2003, 14(9): 1621-1628.
[12] Goldberg D, Nichols D, Oki B M, et al. Using Collaborative Filtering to Weave an Information Tapestry[J]. Communi- cations of the ACM, 1992, 35(12): 61-70.
编辑 陆燕菲
User Reputation Ranking Algorithm Based on Median
BAO Lin, NIU Jun-yu, ZHUANG Fang
(Software School, Fudan University, Shanghai 201203, China)
For the problem that the recommendation system is vulnerable to the impact of Spammer attack, which leads to the inaccuracy of the final item rating, this paper proposes a user reputation ranking algorithm based on median. The algorithm readjusts the weight of user’s rating by measuring user’s reputation. On the other hand, according to the median, it has the property of less susceptible to the effects of extreme rating, the algorithm selects the median from the distances between user rank and object rank as the criterion to decrease user reputation, then iterates until convergence to adjust the user reputation and final rating. Operation result of multiple real data sets shows that the algorithm obtains a more reasonable reputation distribution and a higher accuracy, and after preprocessing by this algorithm, the rating data can get a better Root Mean Square Error(RMSE) value on SVD++.
recommendation system; user reputation; Spammer attack; collaborative filtering; median; Root Mean Square Error(RMSE)
1000-3428(2014)03-0063-04
A
TP399
鲍 琳(1988-),女,硕士研究生,主研方向:推荐系统,社会网络,网络聚类;牛军钰,副教授;庄 芳,助理研究员、硕士研究生。
2013-02-04
2013-03-28 E-mail:by.mariana.trench@gmail.com
10.3969/j.issn.1000-3428.2014.03.013
猜你喜欢
小学生导刊(2018年34期)2018-12-18 01:53:14
统计与决策(2018年9期)2018-05-22 13:17:41
山东青年(2016年3期)2016-02-28 14:25:55
淮海医药(2015年2期)2016-01-12 04:33:19
试题与研究·中考数学(2015年2期)2015-06-05 10:19:34
试题与研究·中考数学(2015年2期)2015-06-05 10:13:02
母子健康(2015年1期)2015-02-28 11:21:33
党员文摘(2014年11期)2014-11-04 10:42:47
无线互联科技(2014年7期)2014-09-24 00:07:42
中学数学杂志(2014年6期)2014-03-01 03:48:18
