
面向众核处理器的阴阳K-means算法优化
2024-04-08 13:38:30周天阳王庆林李荣春梅松竹尹尚飞郝若晨
国防科技大学学报 2024年1期
周天阳,王庆林*,李荣春,梅松竹,尹尚飞,郝若晨,刘 杰
(1. 国防科技大学 计算机学院, 湖南 长沙 410073; 2. 国防科技大学 并行与分布计算全国重点实验室, 湖南 长沙 410073)
经典的K-means算法[1]是最重要的无监督学习算法之一,被广泛应用于数据挖掘、文档聚类、入侵检测等领域中。该算法包括两个步骤:样本点分配和中心点重选。两个步骤不断重复,直到每个中心点的位置不再改变或者迭代达到一定的次数。
当样本点数或中心点数较多时,经典的K-means算法往往运行缓慢。因此,学术界提出了许多优化方法来加速算法本身,例如中心点的初始位置优化[2]、算法结构优化[3-4]和三角不等式优化[5-7]。阴阳K-means[8]是基于三角形不等式优化的最流行实现之一,其通过三角形不等式有效地避免了大多数冗余的距离计算,从而性能得到大幅提升。
与此同时,许多学者在K-means算法的并行优化方面也开展了许多工作,以期通过并行计算的方式来减少其执行时间。例如:Wu等[9]在Intel MIC架构上实现了K-means算法的细粒度的单指令多数据(single instruction/multiple data, SIMD)并行;Kwedlo等[10]提出了Drake、Elkan、Annulus和阴阳四种K-means变种算法的MPI/OpenMP混合并行化;Zhao等[11]提出了一种基于MapReduce的并行K-means算法;Kumar等[12]实现了在多核超级计算机上使用大型数据集进行定量生态区域划定的并行K-means聚类。此外,现有研究还尝试面向GPU[13-15]、FPGA[16-17]等异构硬件平台进行K-means 算法的并行优化。例如,Taylor等[18]优化了阴阳K-means算法在GPU上的实现。因此,K-means算法的并行优化是学术界关注的研究热点。
目前,众核处理器已经成为高性能计算领域中的主流平台。考虑功耗与性能的平衡,基于SIMD方式运行的向量单元几乎成为众核处理器的标配,如x86 AVX-512[19]、ARMv8 Neon[20],从而也使得向量单元成为众核处理器计算性能提升的主要来源之一。同时,众核处理器还通常采用非一致内存访问(non-unified memory access, NUMA)架构,以扩展片上计算核的数量以及访存带宽。单个处理器的所有核心组织成多个NUMA节点,如AMD EPYC系列[21]、飞腾FT-2000+[22-24];或者多个处理器以NUMA方式组织成为一个多socket节点。
尽管现有阴阳K-means算法的开源多线程实现可以直接运行于众核处理器上,但其性能通常不是最优的。其原因主要在于这些开源实现既没有利用众核处理器中的向量单元,也没有面向NUMA架构开展针对性的性能优化。
本文主要面向众核处理器上的阴阳K-means 算法的高性能优化,通过向量化、NUMA亲和性内存访问优化以及数据布局优化等手段实现阴阳K-means算法的高效并行,设计了多组实验来评估优化方法的性能,并将本文提出的阴阳K-means实现与开源多线程阴阳K-means[25]实现进行性能对比。
1 背景介绍
1.1 阴阳K-means算法
传统阴阳K-means算法的伪代码如算法1所示。该算法随机选择k个样本点作为中心点,并将它们分为t个中心点组,然后初始化所有n个样本点(第1~3行)。算法的核心是使用一个三级过滤器过滤不必要进行距离计算的样本点或中心点。具体来说,算法每轮迭代使用全局过滤器(第9~11行)过滤不必要进行距离计算的样本点,使用组过滤器(第12~13行)和局部过滤器(第14~15行)过滤不必要进行距离计算的中心点,最后剩下的每个样本点与所有中心点进行距离计算,根据计算结果为每个样本点找到最近的中心点,如此反复迭代,直到迭代达到一定的次数或者所有中心点的位置不再改变。

算法1 传统阴阳K-means算法
样本点和中心点之间的距离使用欧几里得距离公式来计算:
(1)
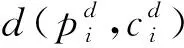
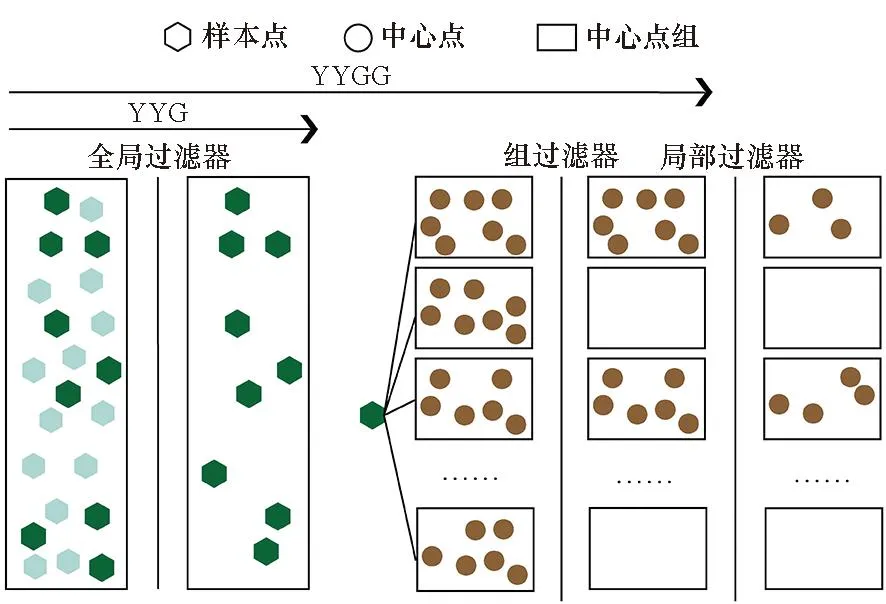
图1 阴阳K-means算法执行过程Fig.1 Execution process of Yinyang K-means algorithm
值得一提的是,本文提出的阴阳K-means算法的并行实现中没有考虑局部过滤器,因为Newling等的研究[26]表明局部过滤器会降低性能。
1.2 向量化技术
向量化也称为数据级并行化,它依赖于众核处理器中的向量处理单元以及对应的向量指令。以Intel Xeon Gold 6240为例,该处理器配备512位向量处理单元,在AVX-512指令集的支持下,可以利用向量乘加指令同时处理8个双精度浮点数或者16个单精度浮点数的乘加操作,大大提高了运算的并行性,从而可有效提高应用程序的性能。
1.3 非一致内存访问
NUMA是一种由多个节点组成的内存架构。 每个节点包含一个或多个处理器核心以及本地存储器,如图2所示。对于单个节点来说,每个节点内部的存储器称为本地内存,其他所有节点的存储器被称为远程内存,多个NUMA节点通过互联模块进行通信。在NUMA架构中,处理器核心访问内存的时间取决于内存相对于处理器核心的位置,任何处理器核心访问其本地内存的速度都比远程内存快得多。
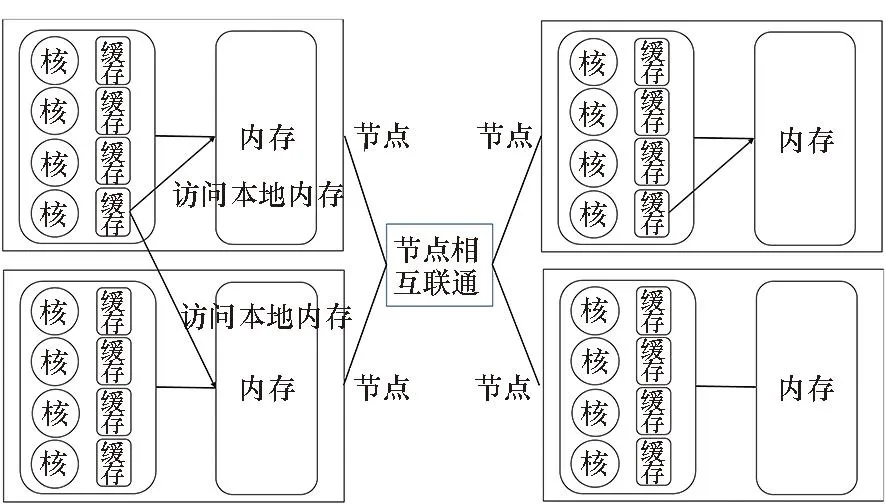
图2 典型NUMA体系结构Fig.2 Classic NUMA architecture
2 问题分析
由于现有的研究主要使用多线程技术来对阴阳K-means算法进行并行优化,却没有利用众核处理器的向量处理单元来进一步提高算法的性能,所以对阴阳K-means算法进行向量化并行优化是非常值得研究的。向量化是并行计算中最常见的优化技术之一,对阴阳K-means算法进行向量化优化之前需要确定基于样本点数据还是中心点数据进行向量化。前者将所有样本点数据视为一个长向量,一次计算多个样本点到每个中心点的距离;后者则将所有中心点数据视为一个长向量,一次计算多个中心点到一个样本点的距离。Wu等的研究[9]表明,如果需要获得良好的性能,所构建的长向量必须足够长才能有效隐藏相关单元的延迟,而样本点数量要比中心点数量大得多,从而可以为SIMD指令流构建更长的向量。因此,决定基于样本点数据进行向量化优化。考虑到阴阳K-means算法的执行特性,不仅可以在距离计算阶段引入向量化,在其他任何可以批处理的地方都可以引入向量化。例如,可以将全局过滤器条件中的标量距离界限的比较转换为向量距离界限的比较,从而一次检查多个样本点的全局过滤器条件。但是必须调整数据内存布局,使其更适合向量化并有更好的数据局部性。
NUMA架构良好的扩展性以及更高的访存带宽使其在超级计算机或服务器上得到了广泛应用。但是NUMA架构具有其天然的缺点,即远程内存访问成本高。因此,传统阴阳K-means算法的实现直接在NUMA架构处理器上运行时可能会因为数据没有合理分配而导致远程内存访问次数过多,从而可能会性能较差,当NUMA节点较多时性能下降尤其明显。所以如何减少远程内存访问量是提升算法性能的关键。 这个问题可以通过线程绑定、数据分配、工作负载分配三个步骤来解决。
3 优化方法
根据上述分析,为了提升阴阳K-means算法的性能,可以利用众核处理器的向量单元进行向量化优化、针对众核处理器的NUMA架构进行NUMA亲和性内存访问优化。此外,为了支持这两种优化方法,还需优化内存数据布局,以获得更好的数据局部性,以及便于在各个NUMA节点进行数据分配。
3.1 向量化
传统阴阳K-means算法由于没有利用众核处理器中的向量处理单元,所以处理样本点时单周期最多只能处理一个样本点,而基于样本点数据进行向量化后则可以在单周期内同时处理s(s为向量长度,且大于1)个样本点,进而算法的性能得到有效的提升。以ARMv8架构处理器为例,由于其配备了128位的向量处理单元,所以利用向量处理单元可在单周期内同时处理2个双精度存储的样本点(即向量长度s=2)。算法2展示了同时采用向量化优化和NUMA亲和性优化的阴阳K-means算法的执行过程,其中多处借助了向量处理单元以提升性能。如样本点初始化阶段需要计算所有样本点与中心点之间的距离时(第5行),一次可以同时计算两个样本点到一个中心点的距离。具体做法是遍历样本点和中心点的所有d个维度,将两个相邻样本点的同一个维度数据放入一个向量中,并将单个中心点的对应维度广播到另一个向量,最后使用SIMD指令计算两个向量的欧几里得距离。得益于分组聚合内存数据布局所带来的良好的数据局部性,计算多个样本点与一个中心点的距离所需的内存访问都是连续的,所以非常高效。又如for循环开始后,由于单次for循环处理两个样本点,所以利用SIMD指令可同时检查两个样本点的全局过滤器条件(第11行)。如果两个样本点所在簇的中心点的位置在本次迭代都不会发生变化,则可以跳过这两个样本点;反之,如果两个样本点中至少有一个样本点通过全局过滤器,即样本点所在簇的中心点的位置会在本次迭代中发生改变,则继续收紧两个样本点的距离上限,并使用SIMD指令再次同时检查它们的全局过滤器条件(第12~13行)。与样本点初始化阶段的距离计算过程相同,第18~23行详细阐述了利用向量化后的样本点数据计算两个样本点与通过筛选后的中心点的距离,并为两个样本点中通过全局过滤器的样本点找到离它最近的中心点,从而在单次for循环中完成了两个样本点的分配,循环次数也因此减半,但是总的迭代次数不变。以上向量化操作由ARMv8架构提供的内部指令(ARM Neon Intrinsic)实现。

算法2 并行加速阴阳K-means算法
3.2 NUMA亲和性优化
阴阳K-means算法在NUMA系统上运行时,所有样本点数据将被加载到单个NUMA节点的本地内存中,导致其他NUMA节点中的处理器核心对样本点数据的访问都是远程内存访问,过多的远程内存访问会明显降低算法的性能。阴阳K-means算法的执行特性表明单个NUMA节点中的各个处理器核心对样本点数据的处理是独立的,从而每个NUMA节点可以只持有部分样本点数据。理想的情况是每个NUMA节点需要的样本点数据都预先放在该节点本地内存中,从而每个NUMA节点都能快速且高效地访问自己所需的样本点数据[27]。此外,每个NUMA节点都需要持有所有中心点数据的一个副本。
根据对NUMA亲和性优化的分析,可以通过以下三个步骤实现具有NUMA亲和性的阴阳K-means算法:
1)线程绑定:该步骤指定线程如何绑定到处理器核心。OpenMP[28]4.0或更高版本提供了两个环境变量——OMP_PLACES和OMP_PROC_BIND,这两个环境变量通常结合使用。OMP_PLACES用于指定线程绑定到的机器上的位置;OMP_PROC_BIND指定绑定策略(线程关联策略),它规定了线程如何分配到位置。在算法2的并行加速阴阳K-means算法实现中,指定线程绑定到处理器核心上,并且将每个线程分配到靠近父线程所绑定处理器核心位置的处理器核心。为了充分利用处理器的并行能力,使用与处理器核心(core)数相同的OpenMP线程数。基于以上策略将每个OpenMP线程逐一绑定到不同的处理器核心(第1行)。
2)数据分配:线程绑定完成后,每个NUMA节点上运行的线程已经确定。因此,每个节点所需的样本点数据同样是明确的。OpenMP在NUMA节点之间提供了一种名为First Touch Policy的数据分配方法,当线程第一次访问某个样本点数据时,会将该样本点数据所在的页分配到距离该线程最近的内存中。所以在阴阳K-means算法开始之前,可以并行地对所有的样本点数据进行一次初始化(第2行),从而每个线程处理的样本点数据都存放在该线程所属节点的本地内存中。
3)工作负载分配:将所有的样本点处理任务均匀地分成m个部分,然后静态地分配给m个OpenMP线程(第8行),其中m大小等于众核处理器中计算核心的数量。
完成以上三个步骤后,每个线程都绑定了一个处理器核心,且每个线程需要的样本点数据都放在该处理器核心所属NUMA节点的本地内存中。因此消除了各个NUMA节点对样本点数据的远程内存访问,有效地降低了内存访问开销。
3.3 内存数据布局优化
假设有n个样本点,每个样本点有d个维度,这些样本点在内存中最常见的数据布局方式如图3所示,样本点与样本点以及单个样本点的每个维度之间都是顺序存储的。但是,当使用式(1)计算多个相邻样本点到一个中心点的欧几里得距离时,由于基于样本点数据进行向量化时需要访问多个样本点的相同维度来构造一个向量,经典内存数据布局将带来一个明显的缺点:相邻样本点的相同维度数据不连续,向量化存储访问开销较大。
图3 经典内存数据布局Fig.3 Classic memory data layout
如图4所示,为了使两个样本点的相同维度的内存访问连续,可以直观地将所有样本点的相同维度聚合在一起。但是,当访问样本点的下一个维度时,聚合内存数据布局将面临两次内存访问之间的跨度太大的问题,数据的空间局部性较差。并且,在进行NUMA亲和性优化时该内存数据布局不利于将样本点数据分配到各个NUMA节点。

图4 聚合内存数据布局Fig.4 Aggregated memory data layout
为了提高数据访问局部性以及便于在各个NUMA节点间分配样本点数据,提出了图5所示的分组聚合内存数据布局。以ARMv8架构处理器的128位向量处理单元为例,将两个样本点的数据划分为一组,并在组内使用聚合内存布局。至此,无论是访问两个样本点的相邻维度还是相邻的一组样本点,内存访问都是完全连续的。
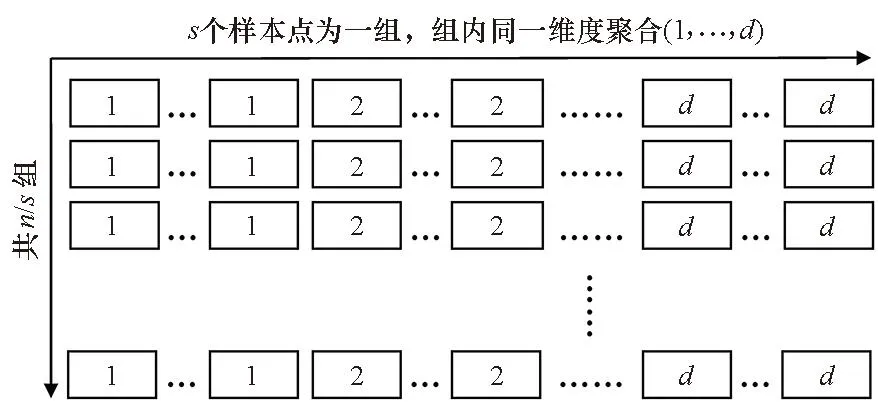
图5 分组聚合内存数据布局Fig.5 Group aggregated memory data layout
4 实验
4.1 实验设置
为了证明向量化和NUMA亲和性内存访问优化对阴阳K-means算法的有效性,实验使用四个大型的真实世界数据集,其中两个来自UCI机器学习数据库[29],另外两个来自Kaggle[30]。表1列出了四个数据集的参数。
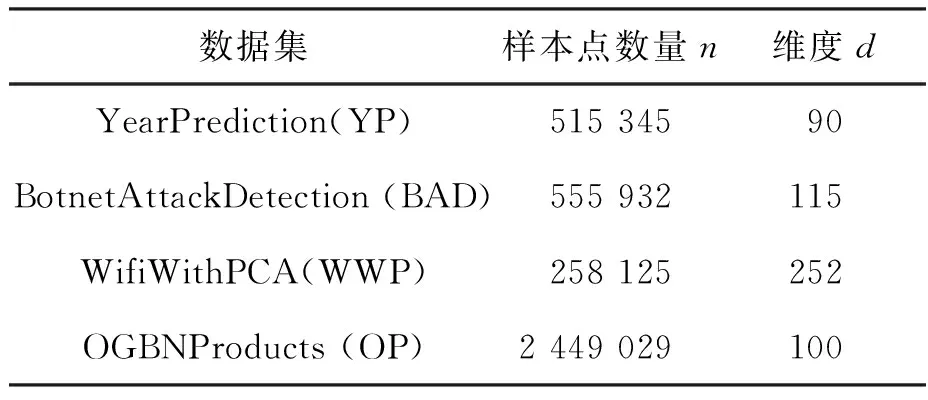
表1 真实数据集参数
实验使用以下两种阴阳K-means算法的实现:
1)YYG: 只使用全局过滤器的阴阳K-means算法。
2)YYGG: 使用全局过滤器和组过滤器的阴阳K-means算法。
此外,还使用一些缩写来表示应用不同优化方法的YYG(G)实现:
1)YYG(G)-SV: 标量阴阳K-means算法在CPU上的多线程开源实现[25]。
2)YYG(G)-VV: 仅采用向量化优化的多线程阴阳K-means算法。
3)YYG(G)-NUMA: 同时采用了向量化优化和NUMA亲和性优化的多线程阴阳K-means算法。
所有代码都是用C/C++编写,使用GCC编译器编译,并使用-O3级别的编译优化以及Intrinsic指令来实现向量化。算法的收敛条件是每个簇的中心点位置不再变化或迭代次数达到1 000。在中心点数量k∈{64,128,256,512}的条件下使用四个数据集进行了实验,每种情况下算法的性能测试重复三次,结果取平均值。所有数据都存储为双精度浮点值。实验使用以下三个平台:
1)Phytium FT-2000+平台: 由一块Phytium FT-2000+ARMv8 CPU构成,有8个NUMA节点,64个核心,核心的主频为2.3 GHz,每个核心配备一个硬件线程、32 KB私有L1指令缓存以及32 KB私有L1数据缓存。每4个核心共享2 MB的L2缓存[22]。
2)Marvell ThunderX平台: 两块Marvell ThunderX ARMv8 CPU构成一个NUMA系统,每块CPU配备48个2.0 GHz的核心,每个核心配备一个硬件线程、78 KB的L1指令缓存和32 KB的L1数据缓存。48个核心共享16 MB的L2缓存[31]。
3)Intel Xeon Gold 6240平台: 两块CPU构成一个NUMA系统,每块CPU配备18个2.6 GHz的核心,每个核心配备两个硬件线程,并分别配备576 KB的L1指令缓存和数据缓存。18个核心共享18 MB的L2缓存、24.75 MB的L3缓存。支持AVX-512向量指令集[32]。
4.2 向量化性能
为了验证向量化的效果,对YYG(G)-SV和YYG(G)-VV这两个算法进行了多次比较实验。同时为了在NUMA节点上获得稳定的性能,执行YYG(G)-SV和YYG(G)-VV算法时使用了Linux命令numactl--interleave=all来使所有数据均匀分布到各个节点。Phytium、Marvell和Intel三个平台的向量化优化实验结果所表现出的特征类似,分别最高获得了约4.6、1.9以及8.5的性能加速比。考虑到篇幅原因,本小节仅以Phytium FT-2000+为例进行详细分析。
表2展示了FT-2000+上向量化阴阳K-means算法相对于标量阴阳K-means算法的加速比。
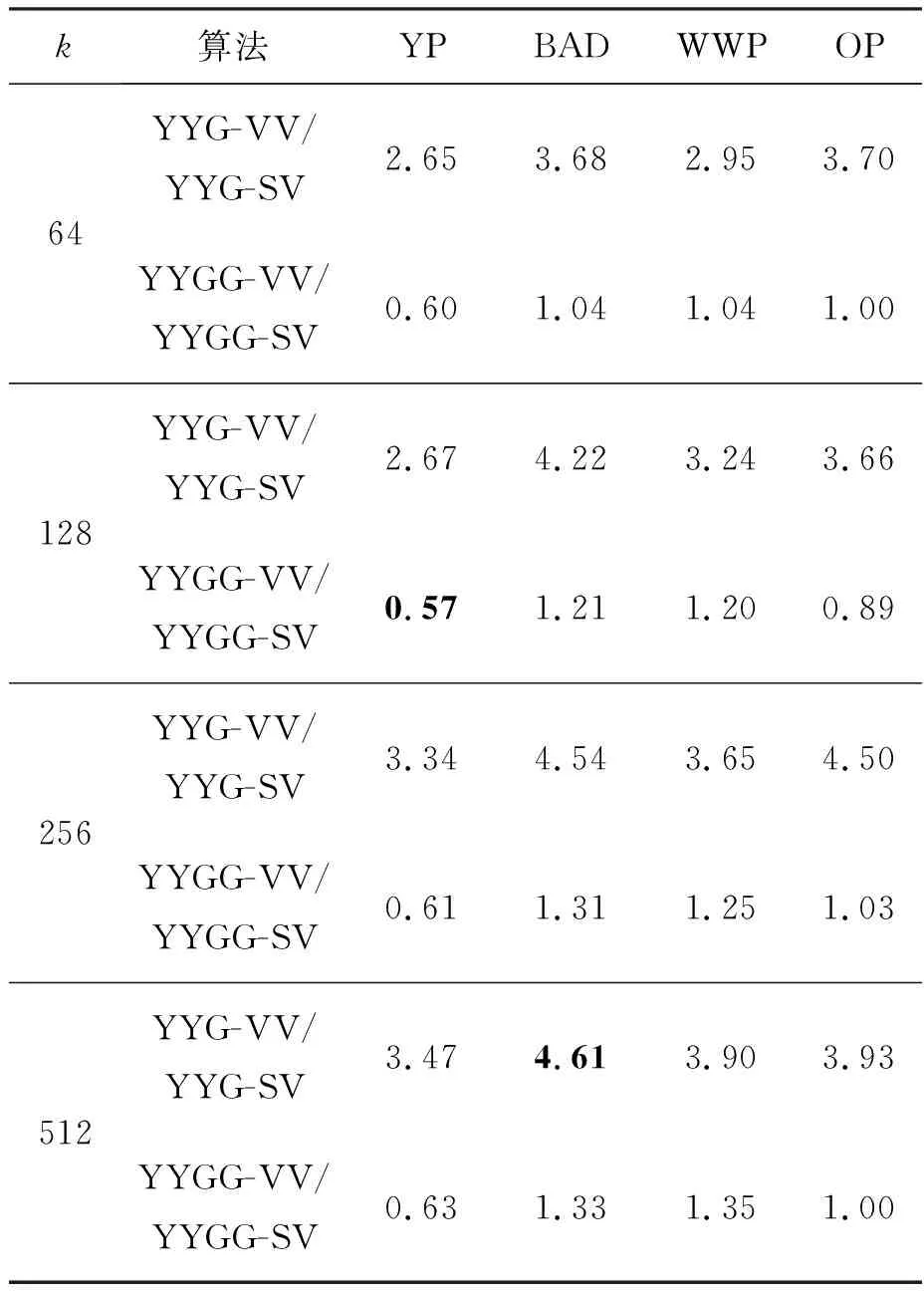
表2 Phytium FT-2000+平台上向量化YYG(G)算法 相对于标量YYG(G)算法的加速比Tab.2 Speedup of vectorized version of YYG(G) over scalar version on Phytium FT-2000+
由表可概括出如下几个关键特征:
1)向量化优化效果明显:在FT-2000+上,大多数情况下向量化算法的性能都优于标量算法,向量化算法的加速比最高达到约4.6。
2)向量化优化效果YYG算法明显强于YYGG算法:可以从两个方面来解释,一方面,前者只有全局过滤器,因此算法中的逻辑判断语句较少; 另一方面,后者筛选了部分中心点,进一步减少了样本点与中心点的距离计算次数,导致计算量进一步降低,所以向量化之后的性能提升相对较小。
3)超线性加速比:当不存在NUMA架构的影响时,FT-2000+上ARMv8的128位向量单元对应的向量化理论加速比是2。实验结果显示某些情况下向量化加速比远超过了2,主要是原始标量算法与优化向量算法受到NUMA架构的影响不一样导致的。为了屏蔽NUMA架构对向量化优化效果的测量,本文又在FT-2000+的单个NUMA节点上进行了实验,所有情况下向量化加速比都恢复到了小于2的正常范围。因此,超线性加速比表明向量化算法比标量算法受NUMA架构的影响更小。
4)低维度数据集实验效果不佳:在实验中观察到向量化算法在数据集YP上的性能比标量算法差。向量化在这些情况下不起作用的主要原因是该数据集的维度相对较低,从而计算量较小,指令流水线加载和排空的时间占总时间的比例较大,导致向量化性能不佳。因此,向量化更适合高维度的数据集。根据本文的测试结果显示,使用维度超过100的数据集的阴阳K-means算法在向量化后可以获得良好的性能。
5)加速比随k值的增大而增大:实验结果表明,随着k值的增大,加速比整体呈上升趋势。对于向量化算法来说,k值增大意味着中心点数量增多,从而样本点与中心点之间的距离计算显著增多,程序并行部分运行时间占总时间的比例增大,处理器数量不变,根据Amdahl定律可知加速比增大。
4.3 NUMA亲和性优化性能
为了评估NUMA亲和性内存访问优化带来的性能提升,将YYG(G)-NUMA算法与YYG(G)-VV进行性能比较。实验结果显示,当NUMA节点数较少时,如Intel平台、Marvell平台,以及仅使用两个NUMA节点的Phytium平台,NUMA亲和性优化效果甚微。但是,随着NUMA节点数的增加,NUMA亲和性优化性能显著增加。
表3和表4分别展示了同时使用向量化和NUMA亲和性优化的YYG(G)算法相对于仅使用向量化优化的YYG(G)算法在8节点和4节点的Phytium平台上的加速比。使用8节点的FT-2000+处理器时,YYG(G)-NUMA在四个数据集上的性能始终优于YYG(G)-VV,加速比为1.11~1.51。而对于使用4节点的FT-2000+而言,NUMA优化的加速比略低于8节点,最高只达到了1.34。因此,在NUMA节点数较多时,通过NUMA亲和性内存访问优化策略,可以有效地避免大量远程内存访问,实现性能提升。此外,随着k值的增大,加速比整体呈下降趋势,k值的增大意味着中心点数量增加,由于中心点只保存在主节点内存中,且中心点被所有NUMA节点共享,所以中心点数据增多导致其他NUMA节点访问主节点的内存访问开销占比增大,从而加速比下降。
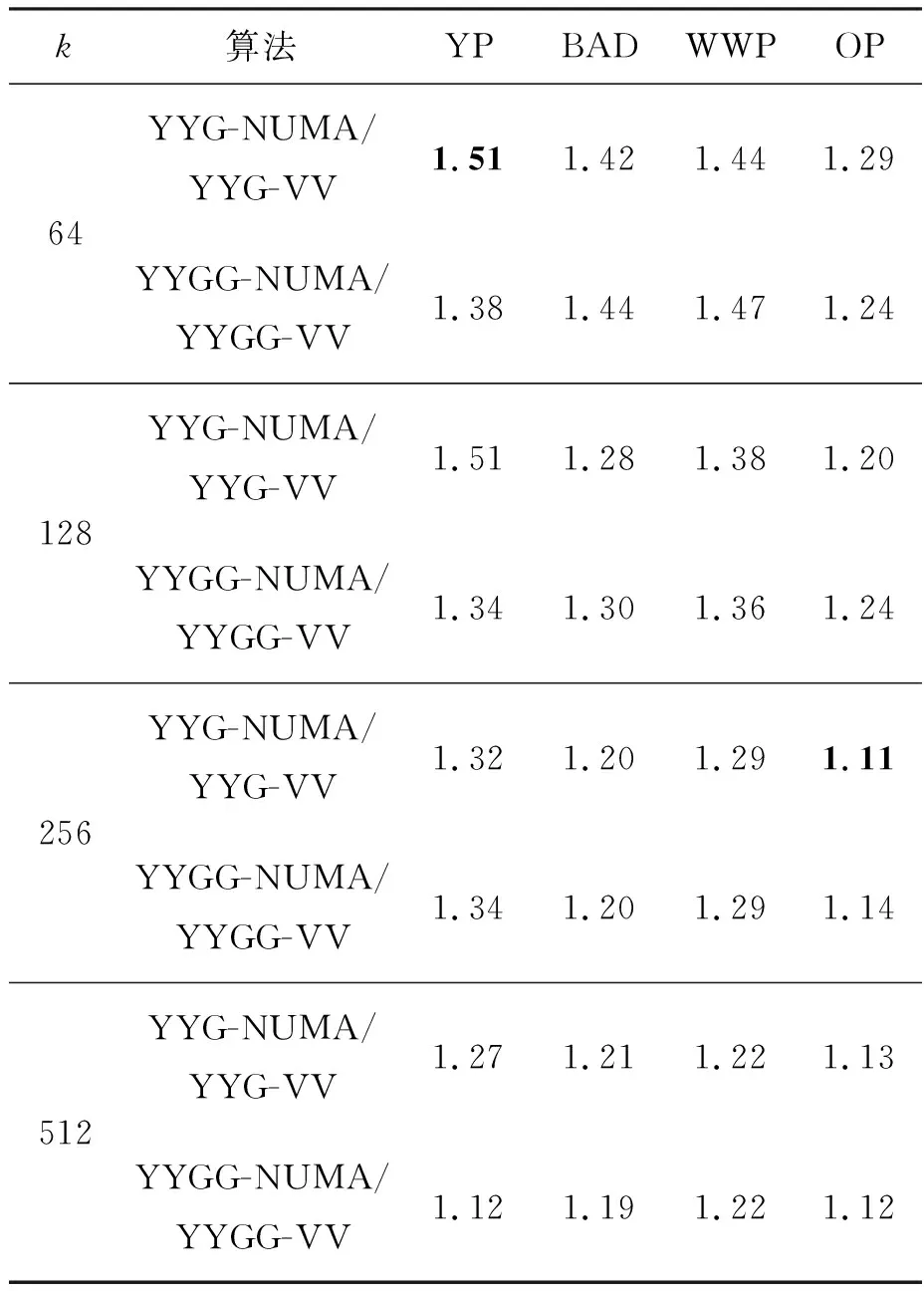
表3 Phytium FT-2000+平台上具有NUMA亲和性的向量化 YYG(G)相对于向量化YYG(G)的加速比(8节点)Tab.3 Speedup of NUMA-aware vectorized version of YYG(G) over vectorized version on Phytium FT-2000+(8 nodes)
4.4 整体优化性能
结合向量化优化和NUMA亲和性优化,YYG(G)-NUMA算法在Phytium平台、Marvell平台以及Intel平台上相对于标量算法的整体加速比分别如表5、表6和表7中所示。当数据集的维度比较高时,并行加速阴阳K-means算法相比传统阴阳K-means算法能实现较大的性能提升,这表明本文的优化方法可以有效地提高阴阳K-means算法在众核处理器上的性能,在Phytium平台、Marvell平台以及Intel平台上最高可分别获得约5.6、2.0和8.7的加速比。
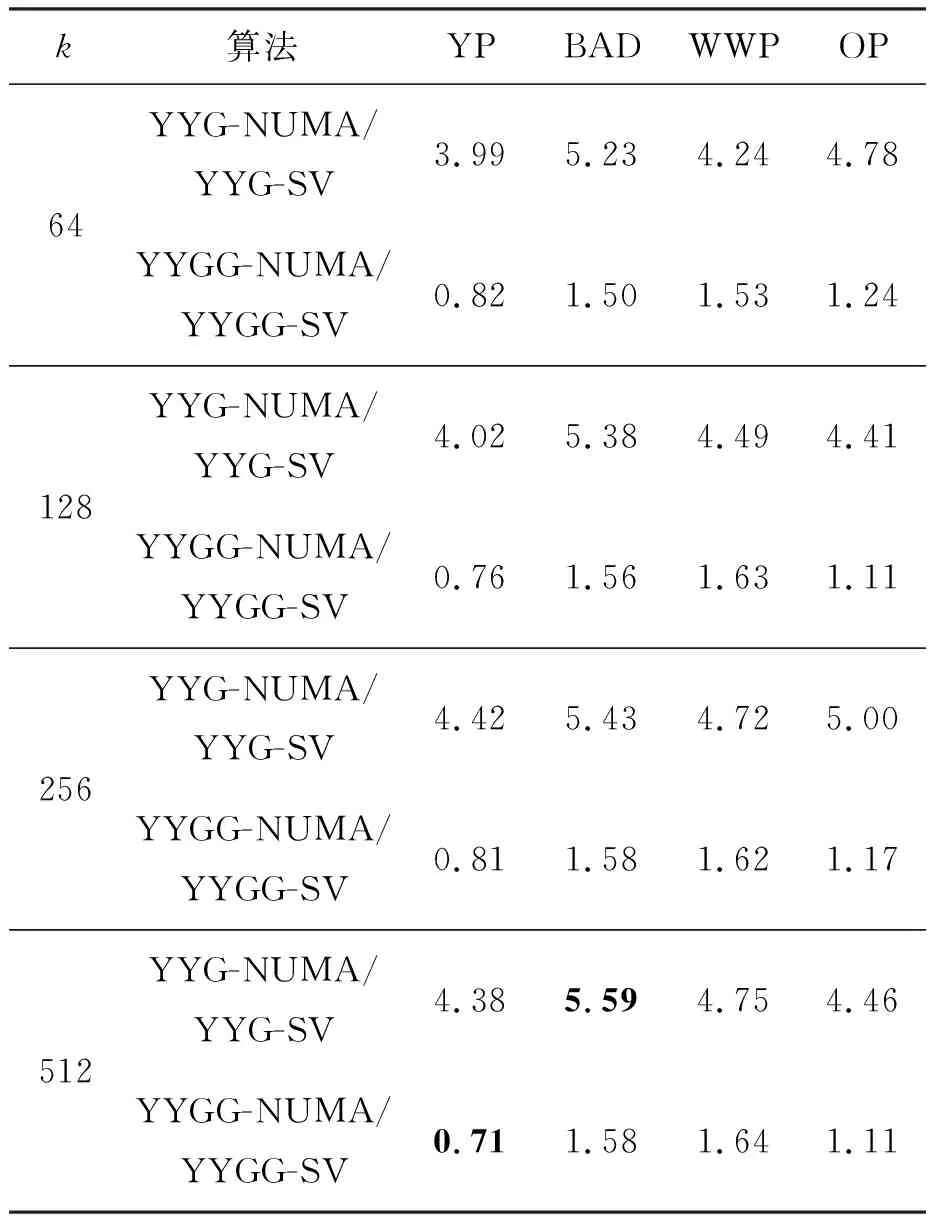
表5 Phytium FT-2000+平台上具有NUMA亲和性的 向量化YYG(G)相对于标量YYG(G)的加速比Tab.5 Speedup of NUMA-aware vectorized version of YYG(G) over scalar version on Phytium FT-2000+
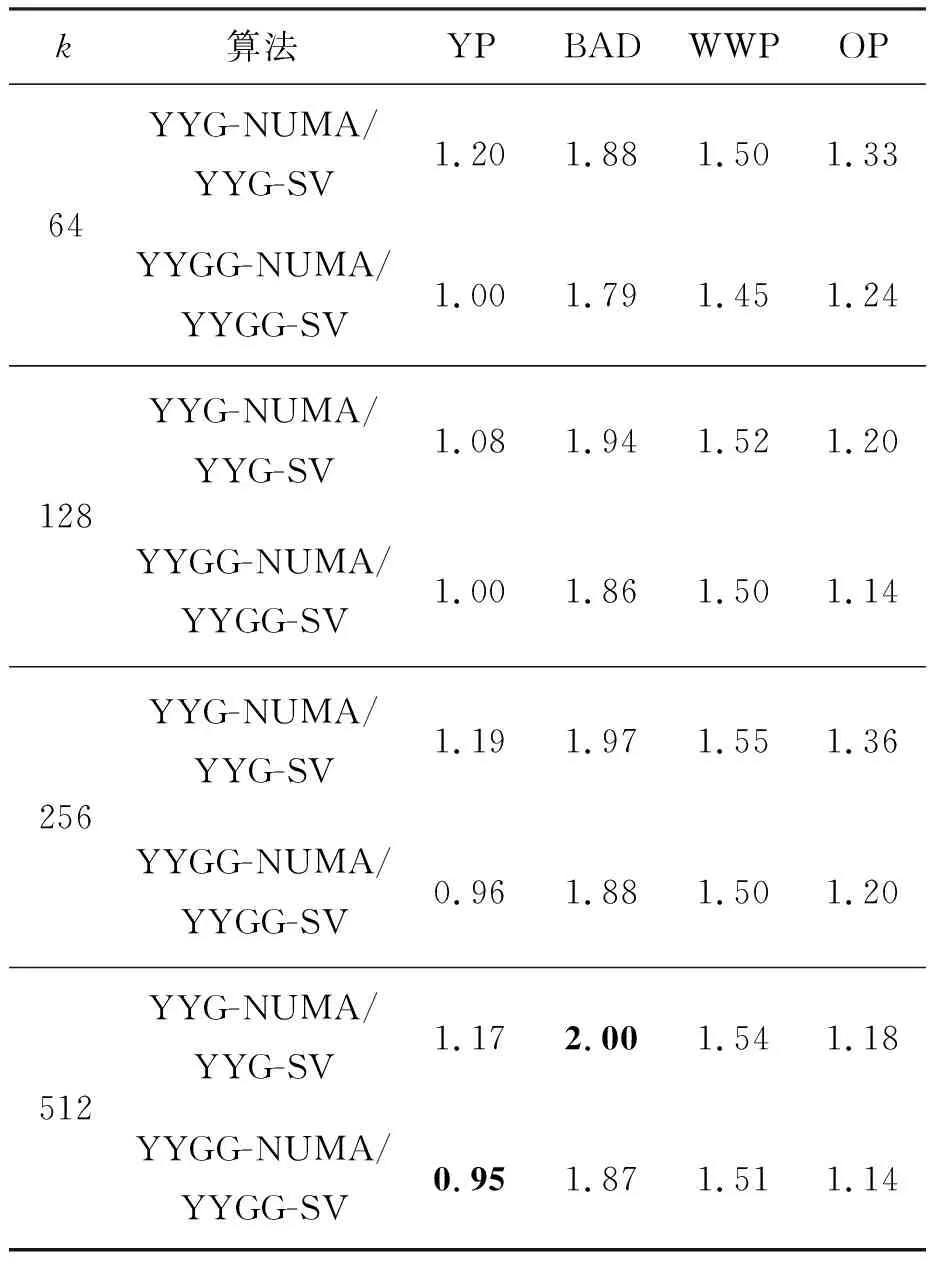
表6 Marvell ThunderX平台上具有NUMA亲和性的 向量化YYG(G)相对于标量YYG(G)的加速比Tab.6 Speedup of NUMA-aware vectorized version of YYG(G) over scalar version on Marvell ThunderX
对比测试结果可知,本文算法在Intel x86平台上的收益显著高于Phytium和Marvell两个ARMv8平台,主要原因有两点:一是Intel Xeon处理器配备了512位向量处理单元,相对于ARMv8架构128位向量处理单元,其向量宽度更宽,因此向量化优化收益更大;二是Intel平台每个核心配备了更大的L1缓存、L2缓存以及独有的L3缓存,使得本文数据布局优化的效果更加明显,从而提升了整体优化方案的效果。
4.5 扩展性
除上述实验外,在Phytium平台上以数据集WWP为例设计了一组实验来研究阴阳K-means算法并行加速实现的强扩展性。分别测试了并行加速阴阳K-means算法和传统阴阳K-means算法从单个NUMA节点扩展到8个NUMA节点时的强扩展效率,实验结果如图6和图7所示。图6表明向量化和NUMA亲和性优化都提高了YYG的扩展效率,YYG-SV的扩展效率经过向量化后从30%提升到60%以上,经过NUMA亲和性优化后进一步提升到85%以上。图7中传统的YYGG-SV算法的扩展效率已经高达90%以上,向量化大幅度提升了算法在单NUMA节点上的性能,从而计算出的扩展效率下降,但经过NUMA亲和性优化后,扩展效率恢复到仅使用多线程技术实现的水平。因此,并行加速阴阳K-means算法依然具有较好的扩展性。

图6 YYG算法的扩展性Fig.6 Strong scaling of YYG algorithm
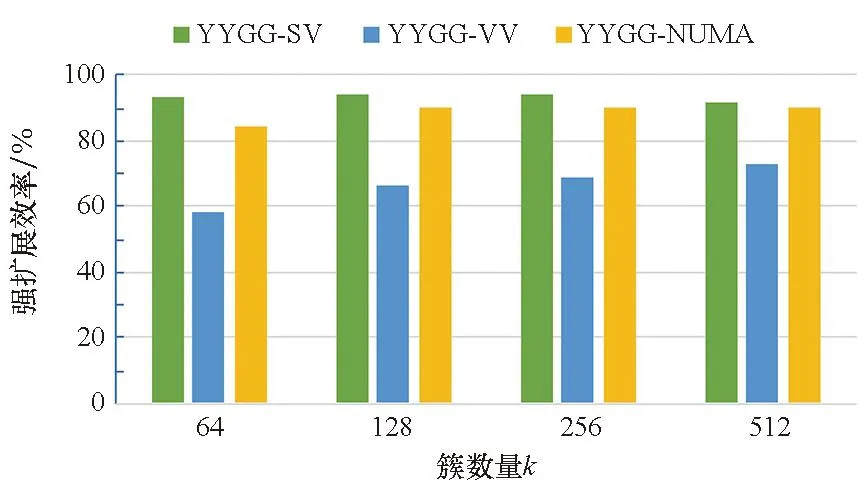
图7 YYGG算法的扩展性Fig.7 Strong scaling of YYGG algorithm
5 结论
本文使用向量化和NUMA亲和性内存访问优化对众核处理器上的阴阳K-means算法进行了优化,同时为了获得更好的数据局部性,还提出了一种新的内存数据布局来支持上述优化。实验结果表明,使用高维数据集时,向量化可以有效地提高阴阳K-means算法在众核处理器上的性能;NUMA亲和性内存访问优化在具有较多NUMA节点的NUMA系统上可以进一步提升阴阳K-means算法的性能。在ARMv8和x86众核平台上,本文提出的阴阳K-means算法的并行加速实现最终分别获得了最高约5.6倍与8.7倍的加速。
未来的研究拟将本文的阴阳K-means并行加速实现扩展到分布式系统中,以实现更大规模的并行。
猜你喜欢
园林科技(2021年1期)2022-01-19 03:13:54
中国果树(2020年2期)2020-07-25 02:14:22
电脑报(2020年12期)2020-06-30 19:56:42
电脑报(2019年4期)2019-09-10 07:22:44
当代陕西(2019年13期)2019-08-20 03:54:22
世界热带农业信息(2019年9期)2019-01-05 13:21:54
上海农业学报(2017年3期)2017-04-10 12:39:24
少儿美术·书法版(2016年1期)2016-02-06 00:59:39
大众摄影(2015年9期)2015-09-06 17:05:41
测绘科学与工程(2014年5期)2014-02-27 07:06:14
