
Research on Risk Identification and Industrial Governance of Digital Education Products Based on Data Annotation Technology
2024-04-01 02:09TongLiliZengJiaDiYingWangNan
China Communications 2024年3期
Tong Lili ,Zeng Jia ,Di Ying ,Wang Nan
1 Faculty of Education Beijing Normal University,Beijing 100875,China
2 China Unicom,Beijing 102211,China
Abstract: The social transformation brought about by digital technology is deeply impacting various industries.Digital education products,with core technologies such as 5G,AI,IoT (Internet of Things),etc.,are continuously penetrating areas such as teaching,management,and evaluation.Apps,miniprograms,and emerging large-scale models are providing excellent knowledge performance and flexible cross-media output.However,they also expose risks such as content discrimination and algorithm commercialization.This paper conducts an evidence-based analysis of digital education product risks from four dimensions: “digital resourcesinformation dissemination-algorithm design-cognitive assessment”.It breaks through corresponding identification technologies and,relying on the diverse characteristics of governance systems,explores governance strategies for digital education products from the three domains of“regulators-developers-users”.
Keywords: digital education products;industry governance;risk identification
I.DEVELOPMENT TRENDS OF DIGITAL EDUCATION PRODUCTS
On November 10,2021,the United Nations Educational,Scientific and Cultural Organization released“Reimagining Our Futures Together: A New Social Contract for Education”.This publication reveals global trends in the transformative impact of digital technology on education and calls for collaborative exploration of its essential pathways.
The global outbreak of the pandemic has presented significant challenges and opportunities to the education industry [1],online learning has evolved from a supplementary form to an essential mode of learning.In February 2019,the“Modernization of Education in China by 2035” established the strategic task of “accelerating the transformation of education in the information age and forming a modern education management and monitoring system” [2].In 2022,the Ministry of Education officially initiated the Education Digitalization Strategic Action as outlined in its key work points.The Cyberspace Administration of China and seven other departments jointly issued China’s first regulatory document on artificial intelligence,titled“Interim Measures for the Management of Generative Artificial Intelligence Services”[3].It officially came into effect on August 15,2023.Looking globally,countries are continuously strategizing and laying out plans in the new arena of digital education,injecting new impetus into its development [4].The European Union’s“2021-2027 Digital Education Action Plan” establishes ethical guidelines for educators using artificial intelligence and data in teaching,aiming to identify and mitigate potential risks associated with these technologies [5].The latest curriculum framework in Australia incorporates information technology literacy as one of the general capabilities,emphasizing the importance of “using information technology according to social and ethical conventions”[6].
Simultaneously with the intensive formulation of policies,the types of digital education products are also continuously evolving.From the initial development of apps to various forms such as mini-programs,teaching cloud platforms,and subject resource libraries,by 2023,11 general large-scale models have completed filing and entered the public testing phase.The ongoing evolution of digital education product forms,accompanied by corresponding developments in regulatory technologies and governance strategies,is essential to ensure the full protection of education quality and student rights.The current types of digital education products are listed in Table 1.
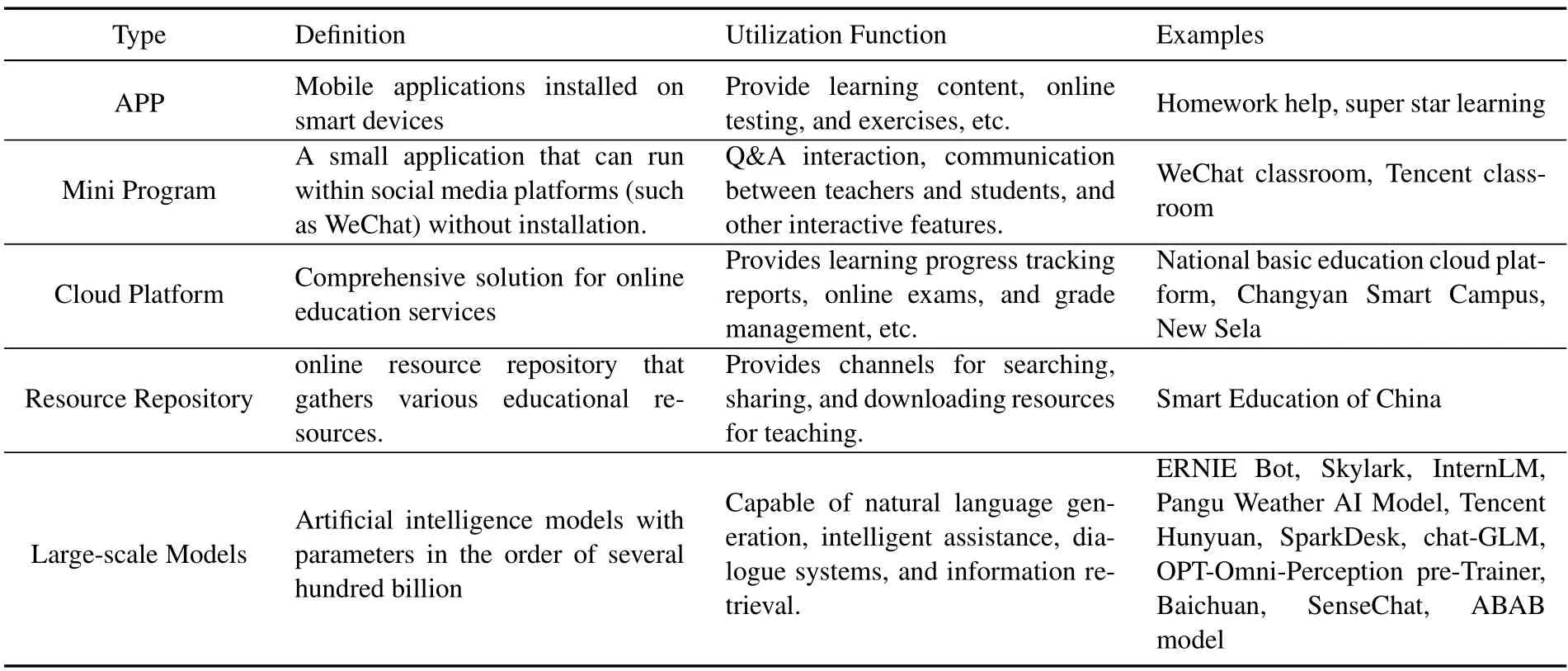
Table 1.Types of digital education products.
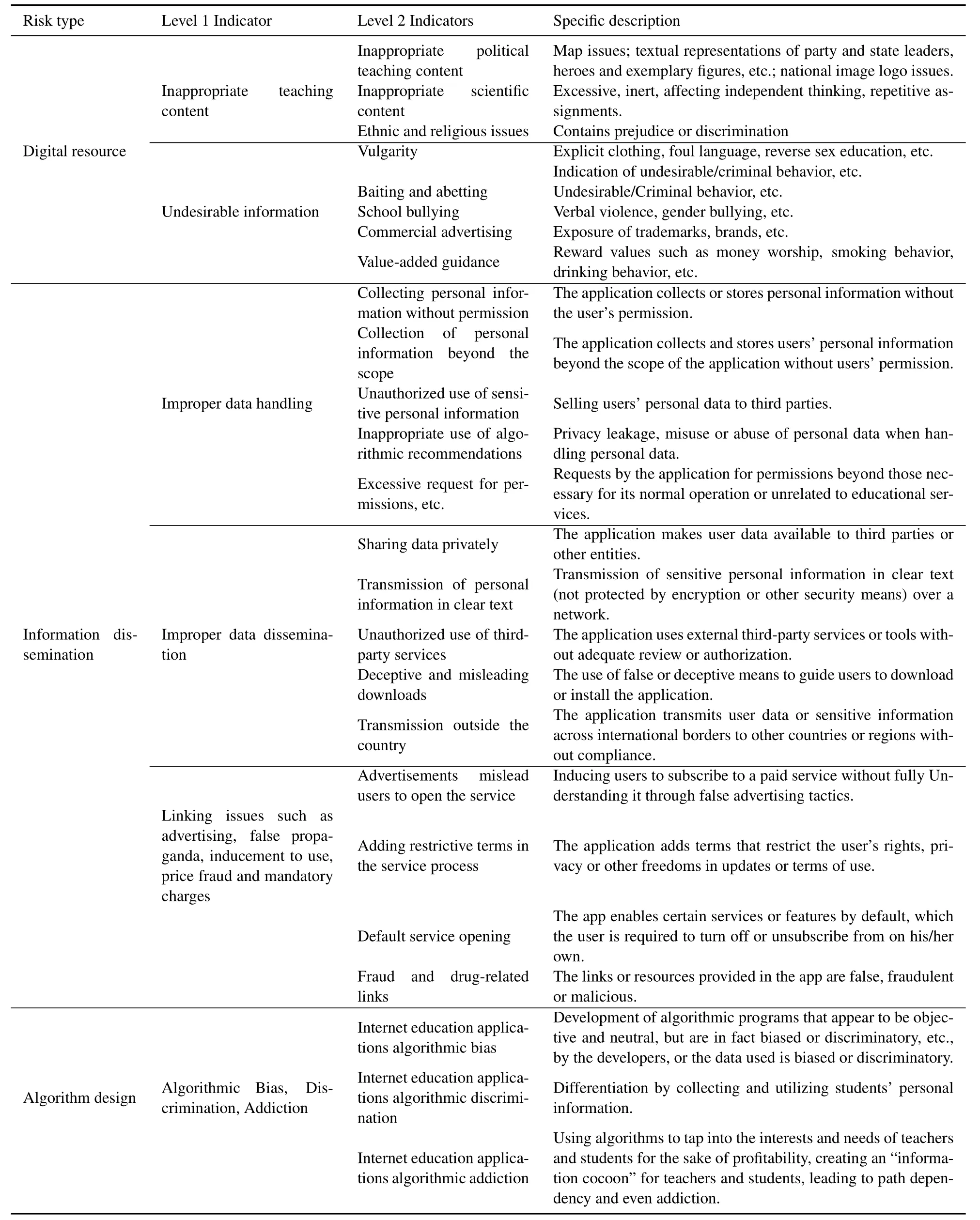
Table 2.4D risk analysis matrix for digital education products.
According to the “Insights into the Global Education App Market in 2022” report,from January to September 2022,education apps globally recorded 2.4 billion downloads,with 60.3% on Google Play and 39.7% on iOS.During the same period,the total revenue of global education apps reached $1.8 billion,with Apple users contributing a substantial 85.4%and income from iPad devices constituting 29%.Course purchases and subscriptions emerged as the primary in-app purchase methods for educational apps.North America,Europe,and Asia have been the three major markets witnessing significant revenue growth in the education app sector in recent years.
The unstoppable trend of digital technology revolutionizing education is evident.The rapid growth in the number of digital education products and their corresponding market shares will undoubtedly generate continued enthusiasm on the content supply side.Such competition and innovation will ultimately propel the digital education product ecosystem to higher levels of development,providing learners with increasingly enriched learning experiences.
II.TYPES OF RISKS IN DIGITAL EDUCATIONAL PRODUCTS
In alignment with the convenience brought about by the rapid iterations of digital technology,various forms of digital education products have emerged,presenting complex and dynamic application scenarios.Amidst the new wave of applications triggered by AIGC,it is imperative to recognize that demands and challenges coexist within educational applications[7,8].Currently,the potential risks linked to digital education products are outlined as follows:(1) User Privacy.Privacy and data security have evolved with the development of information technology and the internet [9].Whether it is large-scale models or the underlying algorithms,their internal logic and decision-making processes are often opaque,treated as“black boxes”Each time a user inputs information,there is a potential for the algorithm to store and utilize that data.For adolescents amid intellectual and emotional development,there is a high risk of personal information leakage and exposure of individual characteristics and interests.While teenagers can effectively avoid explicit messages,more discreet channels for information dissemination often challenge their ability to discern privacy protection.When relatively non-sensitive information undergoes integrated processing,it can become a significant threat to individual control over information.
(2)Content Discrimination.AIGC technology relies solely on data and patterns,lacking ethical judgment capabilities [10].This may result in the generation of content that includes unethical,offensive,or potentially harmful information.Due to biases in training data,AI-generated content may lack fairness and ethical judgment,posing a risk of discrimination against certain groups.For example,AIGC often assumes tendencies related to gender in abilities,resulting in unfair negative impacts on women in some question answers or generated content [11].Simultaneously,AIGC may amplify societal inequalities.
(3) Model Development.Whether it’s the globally popular ChatGPT large model or popular domestic models like ERNIE Bot and Pangu Weather AI Model,all rely on historical data training.This can lead to generated answers that do not align with the current reality,especially in today’s rapidly changing online landscape with complex and varied scenarios.
The underlying algorithms face technical bottlenecks incongruent with the growth patterns of minors and contradictions between cognitive assessments in online learning and the real situations of students.Continuous and in-depth research by model developers and developers is essential to address these challenges.Based on the risks mentioned above,this paper designs a 4-dimensional risk analysis matrix titled“Digital Resources-Information Dissemination-Algorithm Design-Cognitive Assessment”,as shown in Table 2.
(1) Digital Resources.Digital resources refer to teaching resources (content or materials) within digital education applications that may not comply with national laws,regulations,educational standards,and subject specifications throughout the entire “preevent-during-event-post-event” chain.This includes situations like harmful content,content exceeding the curriculum or standards,and content promoting passive thinking,adversely affecting students’ physical and mental health,values,and learning outcomes.
(2) Information Dissemination.Information dissemination pertains to the transmission of personal information within digital education apps,where risks of leakage,misuse,and tampering exist.Personal information may be exploited by malicious entities or third parties for purposes such as fraud,false advertising,or inappropriate advertisements.Such misuse can infringe upon students’right to information and choice,as well as their rights.Additionally,the widespread use of electronic signatures may lead to forgery,resulting in legal disputes and fraudulent activities.
(3)Algorithm Design.Algorithm design addresses issues related to the algorithms or artificial intelligence technologies used in digital education applications,such as lack of transparency,interpretability,and control.This contradicts the rule of law in algorithm governance and may unpredictably impact students’learning behaviors,cognitive development,and personality formation.For example,user preference algorithms,beneficial for boosting sales in consumer domains,may have adverse effects on basic education,leading to subject imbalances and posing potential threats to educational equity,quality,and efficiency.
(4) Cognitive Assessment.Cognitive assessment concerns the suitability of learning methods or approaches provided by digital education applications for students’age groups,learning needs,and cognitive characteristics.This may damage students’attention,memory,and thinking abilities or result in issues such as excessive reliance,lack of innovation,and communication deficits.
Big models and other digital education products are emerging,bringing unprecedented upgrades and disruptive changes to the field of education.However,the intelligence and autonomy of digital education products can also bring some unpredictable risks,including mutual attacks between models,content discrimination,and data authenticity issues.When multiple big models process the same data or task,they may encounter conflicts or mutual attacks.And it is highly likely to produce content discrimination,which refers to unfair evaluation or treatment of content for certainspecific groups or topics.For example,in search engines,the content of certain keywords or topics may be prioritized and displayed,while other content is ignored or ranked lower,resulting in unfair distribution of content.At the same time,if the model is trained using inaccurate or falsified data,its authenticity of the data source and output may be affected.
III.KEY TECHNOLOGIES FOR RISK MONITORING BASED ON DIGITAL ANNOTATION TECHNOLOGY
Building upon the foundation of the risk analysis matrix,more sophisticated risk identification technologies are needed to support the practical implementation of governance.Starting from the fundamental principle of people-oriented,this paper,targeting cognitive assessment and digital resource risks,designs advanced technologies that focus on annotating process-oriented data in addition to the existing emphasis on outcome-oriented academic data.For risks associated with algorithm design,the paper optimizes and introduces an intelligent diagnosis technology reflecting educational characteristics while inheriting the advantages of commercial algorithms.
In addressing risks related to information dissemination,the paper expands upon existing screenings for individual digital education products and introduces cross-platform alignment analysis technology to screen for risks arising from variations in product versions across platforms.
Figure 1 is a key technology diagram,the details are as follows:
Firstly,there is a breakthrough in the complex behavior sequence discrimination technology beyond deep learning,aiming to screen risks associated with deviations in subject knowledge and cognitive development.Building upon outcome-oriented labels such as daily activity rates and click-through rates,it incorporates process-oriented annotations closely aligned with educational principles.It screens for risk points in content based on application content,cognitive development in different stages,and mental development,initiating a monitoring mechanism for knowledge structure,cognitive association paths,and psychophysical development.
Secondly,the development of SDK dynamic extension analysis technology is focused on screening algorithmic vulnerabilities associated with user overconstrained behavior.Unlike past mobile plug-in technologies that supported localized functionality and single-point screenings for specific models/versions,this project emphasizes breaking through SDK dynamic extension analysis technology.It ensures compatibility with multiple hardware models and software versions,conducting closed-loop inspections of data storage,access,and the diffusion of sensitive data.This addresses algorithmic discrimination,black-box issues,and biases through intelligent self-healing and manual repairs,achieving reasonable user behavior according to specifications.
Thirdly,the development of multi-factor space similarity alignment technology aims to screen variation risks associated with cross-platform sharing.The project conducts cross-platform alignment analysis from dimensions such as sample structure,code logic,and resource content,screening for counterfeit,tampered,or underreported apps.It also provides exceptional warning monitoring,enhancing cross-platform stability and integration performance.
The 3 technologies mentioned above are all key technology application systems derived from digital annotation technology.The complex behavior sequence discrimination technology of deep learning utilizes deep learning models to learn and classify complex behavior sequences.Digital annotation is used to precisely label behavior sequences,providing training data for deep learning models.Deep learning models can learn the inherent laws and characteristics of behavior sequences from a large amount of labeled data,achieving accurate discrimination and classification of complex behavior sequences.SDK dynamic extension analysis technology is based on digital annotation technology to annotate and classify various elements in the software development process.By analyzing the usage and extension behavior of SDK,the functionality,performance,and potential security risks of software can be understood.Multi-factor spatial similarity alignment technology utilizes digital annotation to annotate and classify multi-dimensional data,and then calculates the similarity between data in a multi-dimensional space.By aligning and integrating the similarity of different dimensions,comprehensive analysis and understanding of complex data can be achieved.
IV.DIGITAL EDUCATION INDUSTRY GOVERNANCE STATUS AND STRATEGIC SUGGESTIONS
Starting from the existing data pools of education APP filing database,industrial algorithm database,and student cognitive development evaluation database,this paper forms a complete public data set and information coding database through the design of a 4-dimensional risk matrix and three key technological breakthroughs and reserves the theoretical,technical and dynamic data foundation for the comprehensive supervision platform.It is proposed to use empirical methods to warn and identify potential risks,explore the development norms,use rules and governance processes of digital education applications that conform to the laws of education,form a full process and multiagent governance pattern of access review,benign operation,and reasonable exit,and support large-scale demonstration applications.
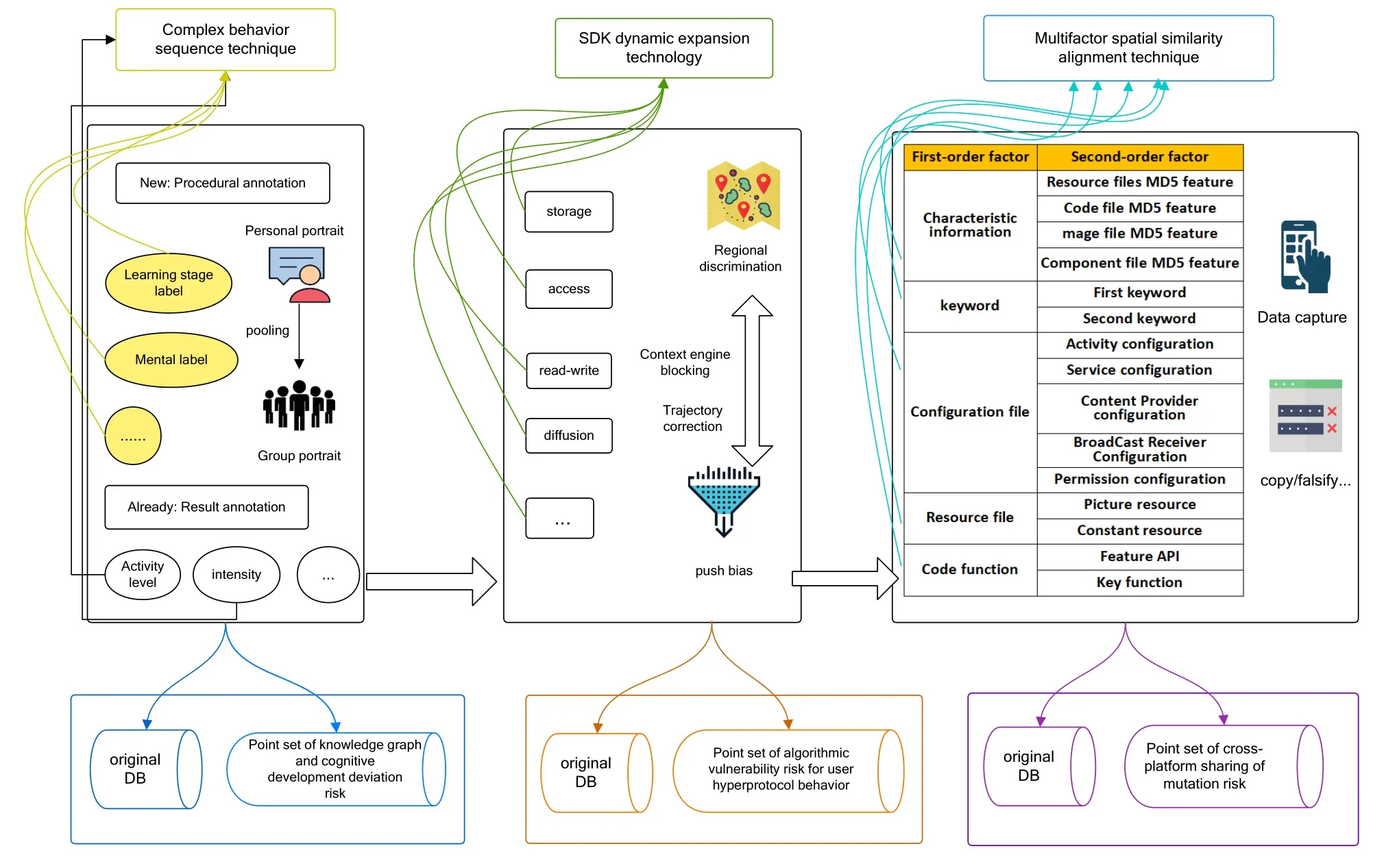
Figure 1.3 key data annotation technologies for risk monitoring.
According to the management idea of “pre-eventpost-event”,this paper puts forward the whole-cycle risk monitoring and early warning system of digital education product industry governance,as shown in Figure 2.
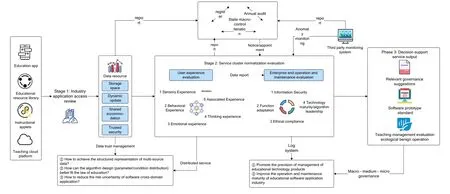
Figure 2.“Pre event-during event-post event”full cycle risk monitoring and warning system.
Stage 1:Industry application access review.Including the review of small program/web/APP storage space,dynamic updates,shared accommodation,trusted security,etc.Ensure adequate storage space for processing data sets,especially dynamic data sets,such as documented data,certification authority data,user experience data,and enterprise open data sources.Evaluate the acquired data,including data encryption,authentication mechanism,access control,etc.,to reduce the application risk uncertainty caused by crossdomain data.Combined with technical trends and user needs,data sharing and interworking are allowed to build a structured multi-source data representation,provide a more reliable data basis for algorithm design,and provide data support for stage 2 and stage 3.
Stage 2:Service cluster normalization evaluation.From the two aspects of user experience evaluation and enterprise side operation and maintenance evaluation,the normal monitoring capability of “personnel review+community reporting+technical selfexamination” is formed,and the governance strategy is started according to the risk level.The data reports formed by the client based on sensory experience,behavioral experience,and other dimensions provide data-driven decisions for the operation and maintenance evaluation of the enterprise side.The enterprise side regularly carries out operation and maintenance evaluations,including information security and function adaptability according to system requirements and user feedback.It uses technical means to“self-check”and repair system loopholes.Based on the above normal monitoring process,the monitoring problems are classified and assessed according to the risk level,corresponding governance strategies are launched according to different levels,the monitoring mechanism is continuously optimized,and the review and reporting mechanism is improved based on the actual situation,so as to ensure the sound operation of Internet education applications.Phase 2 and Phase 1 data resources are combined to create structured representations of multi-source data,facilitating the matching of algorithm design with educational laws thereby reducing risk and uncertainty in the application of software in different fields.
Stage 3:Monitoring underpins governance decisions.Based on the monitoring results of phases 1 and 2,Phase 3 will achieve the outputs of governance decisions.From the perspective of technical output,the data collection/invocation/iteration standard of Internet education applications is formed.By integrating assessment data and basic data resources,the potential rules and trends of data are found to guide the improvement of educational applications.From an advisory and administrative perspective,governance recommendations based on scientific monitoring data should be formulated.By analyzing monitoring data and associating different data sources,potential anomalies can be found to provide a basis for governance recommendations.The combination of“macro-meso-micro-governance” in stage 3 and the log system produced in stage 2 promotes the precision of educational technology product governance.It improves the operational maturity of the educational software application industry.Through the above two aspects,the benign operation of the teaching management and evaluation system is finally achieved to support the extensive application and demonstration effect of large-scale education application.
According to the multi-agent governance characteristics of “regulators-developer-users”,the collaborative governance framework proposed in this paper is shown in Figure 3.Regulators take pre-release standards,in-process sampling,and post-event governance as the main line,developers take pre-standard development,in-process monitoring,and post-event optimization as the main line,and users take pre-focused selection,in-process experience,and post-event effect as the main line.
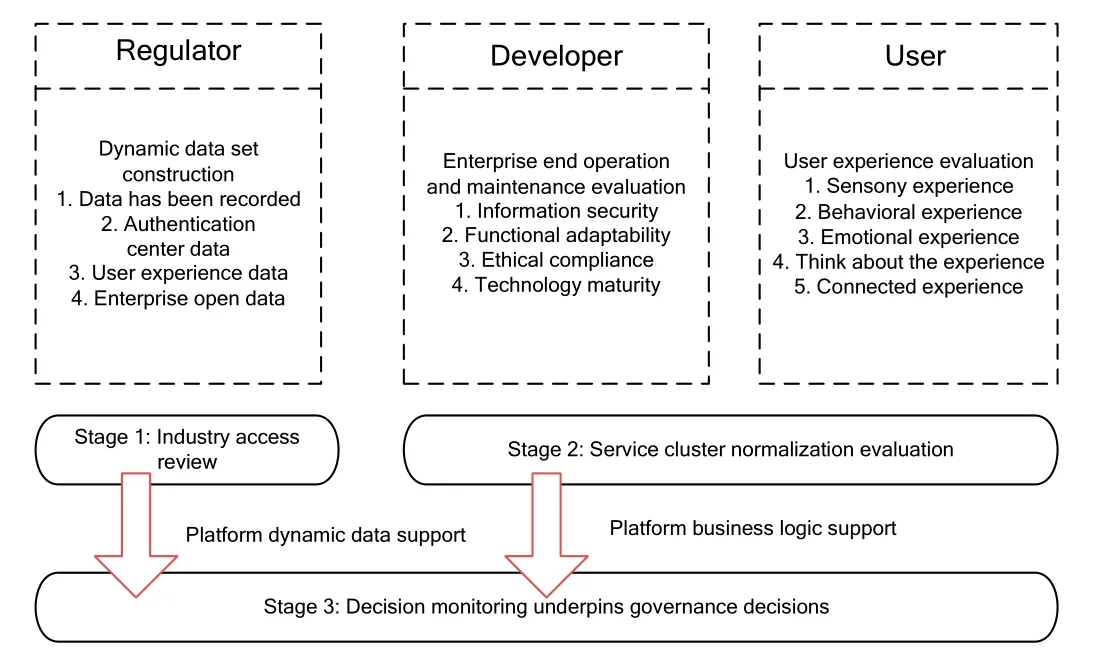
Figure 3.“Regulators-developers-users”3 agents collaborative governance framework.
V.FUTURE RESEARCH PROSPECTS
Starting from the hidden dangers faced by the development of digital education products,this paper proposes a 4-dimensional risk matrix of“digital resources-information dissemination-algorithm design-cognitive evaluation”,focuses on three key technologies,discusses the whole-cycle risk monitoring and early warning system of “pre-event-post-event” for digital education applications,and proposes a three-body collaborative governance framework of “regulatorsdevelopers-users”.It has accumulated basic research content for the research field of risk screening technology and industrial governance strategy of digital education products.
Based on the existing achievements,the team’s follow-up research directions include:
(1) Dynamic digital educational resources mining and cross-time learning feature representation Form a multi-dimensional portrait construction technology based on process annotation and result annotation,and combine static graphics+dynamic audio and video multi-modal data to realize the future learning state of specific user nodes or group learning state perception and prediction technology.Through the analysis of students’ online learning behavior trajectory and learning situation portrait,the dynamic assessment data of cognitive development are gathered to provide cross-modal and three-dimensional resource environment and technical support for the detection of the impact of digital education application on students’ cognitive development [12].Build a baseline test of students’cognitive development under the digital education application environment,etc.,and significantly improve the efficiency of large-scale and precise governance.
(2)Construct an AIGC governance rule base for the risk matrix Based on the existing AIGC digital resource governance rule base,including homonym/thesaurus,skin exposure area calculation model,etc.,the AIGC governance rule base of “information transmission-algorithm design-cognitive assessment”[13] is constructed,including detection technologies such as hook analysis and stain propagation.Research on the automatic detection methods of abnormal behaviors of advertisements and page links in digital education applications,research on intelligent evaluation algorithms for cognitive development,etc.,in order to alleviate problems such as difficult cross-domain monitoring,slow source tracing,and loose closed-loop governance.
ACKNOWLEDGEMENT
This work was supported by the 2022 National Natural Science Foundation of China (No.62277002) and the National Key Research and Development Program of China(2022YFC3303500).

- China Communications的其它文章
- Space/Air Covert Communications: Potentials,Scenarios,and Key Technologies
- Improved Segmented Belief Propagation List Decoding for Polar Codes with Bit-Flipping
- Scenario Modeling-Aided AP Placement Optimization Method for Indoor Localization and Network Access
- Off-Grid Compressed Channel Estimation with ParallelInterference Cancellation for Millimeter Wave Massive MIMO
- Low-Complexity Reconstruction of Covariance Matrix in Hybrid Uniform Circular Array
- Dynamic Update Scheme of Spectrum Information Based on Spectrum Opportunity Incentive in the Database-Assisted Dynamic Spectrum Management