
Privacy-Preserving Federated Mobility Prediction with Compound Data and Model Perturbation Mechanism
2024-04-01 02:08LongQingyueWangHuandongChenHuimingJinDepengZhuLinYuLiLiYong
China Communications 2024年3期
Long Qingyue ,Wang Huandong,* ,Chen Huiming ,Jin Depeng ,Zhu Lin ,Yu Li ,Li Yong
1 Beijing National Research Center for Information Science and Technology(BNRist),Department of Electronic Engineering,Tsinghua University,Beijing 100084,China
2 China Mobile Research,Beijing 100032,China
Abstract: Human mobility prediction is important for many applications.However,training an accurate mobility prediction model requires a large scale of human trajectories,where privacy issues become an important problem.The rising federated learning provides us with a promising solution to this problem,which enables mobile devices to collaboratively learn a shared prediction model while keeping all the training data on the device,decoupling the ability to do machine learning from the need to store the data in the cloud.However,existing federated learningbased methods either do not provide privacy guarantees or have vulnerability in terms of privacy leakage.In this paper,we combine the techniques of data perturbation and model perturbation mechanisms and propose a privacy-preserving mobility prediction algorithm,where we add noise to the transmitted model and the raw data collaboratively to protect user privacy and keep the mobility prediction performance.Extensive experimental results show that our proposed method significantly outperforms the existing stateof-the-art mobility prediction method in terms of defensive performance against practical attacks while having comparable mobility prediction performance,demonstrating its effectiveness.
Keywords: federated learning;mobility prediction;privacy
I.INTRODUCTION
Predicting users’ future movement accurately is instrumental for many various applications in mobile communication networks,ranging from network optimization[1-5]to service optimization[6-9]and device optimization[10].However,training an accurate mobility prediction model requires a large number of user mobility trajectories[11],which contain sensitive information about users including which places they have visited and who they have met.Thus,the rising privacy concerns prevent us from applying the mobility prediction models in practice.
On the other hand,the rising paradigm of federated learning techniques provides a promising solution to this problem,which is a distributed machine learning framework with the goal of training machine learning models based on data distributed across multiple devices and protecting users’ privacy at the same time.Specifically,this goal is achieved by only sharing aggregated locally calculated intermediate results proceeded by privacy protection mechanisms,while not keeping any piece of the user data away from the device.It has shown success in some practical applications including personalized recommendation [12],keyboard prediction[13],etc.
Thus,a number of studies have investigated using federated techniques to implement human mobility prediction [14-17].However,most of them do not provide an analysis of the privacy-preserving performance.The only work that provides a privacy guarantee is PMF [14].However,they only focus on the privacy leakage in a part of the mobility prediction model,which has been shown to have a serious vulnerability based on our analysis(see§V).
In this paper,we mainly focus on developing a federated mobility prediction method with a privacypreserving guarantee,which is demonstrated by both theoretical analysis and privacy leakage in terms of practical attack.Specifically,we combine the techniques of data perturbation and model perturbation mechanism and propose a privacy-preserving mobility prediction algorithm,where we add noise to the transmitted model and the raw data collaboratively to preserve users’ privacy.Specifically,we propose three strategies to allocate noise with different energies to the data perturbation and model perturbation,including the model-dominated strategy,datadominated strategy,and piece-wise strategy.Then,we analyze the privacy-preserving performance of the algorithms in terms of practical privacy attacks,where we extend the attack method considered in [14] and further propose thetransition pattern inference attackto evaluate the privacy leakage of all the mobility prediction models.
In summary,our paper makes the following contributions:
• We propose a privacy-preserving mobility prediction algorithm by combining the techniques of data perturbation and model perturbation mechanisms,where noise is added to the transmitted model and the raw data collaboratively to preserve users’privacy.
• We propose three novel strategies to allocate noise with different energies to the data perturbation and model perturbation.In addition,we have implemented two different types of privacy attacks to evaluate the privacy-preserving performance of our proposed method in practice.
• Extensive experimental results show that our proposed method has significant improvement in terms of privacy-preserving performance against two different privacy attacks.In addition,our proposed method also has little performance gap compared with the state-of-the-art mobility prediction method without any privacy-preserving mechanisms,which has large privacy leakage risks.
II.RELATED WORK
Mobility Modeling.Due to the important applications of mobility prediction [18,4],numerous approaches have been proposed to predict users’ future movement.Some approaches utilize the classical probability-based model such a Markov model[19,20],hidden Markov model [21-23],probabilistic graphical models [24],Dirichlet process [25-27].In recent years,more approaches have been proposed to utilize deep learning techniques to predict users’future movement.Kong et al.[28] utilize the long short-term memory (LSTM) network to predict user mobility by introducing spatial-temporal factors into the gate mechanism and a hierarchical architecture to the neural network.Feng et al.[29] combine the deep attention mechanism with the recurrent neural network.Zhou et al.[30] propose a trajectory embedding model for learning hierarchical and sequential mobility patterns simultaneously based on the variational inference techniques.Wang et al.[31] integrate the deep attention mechanism into the traditional Markov model.At the same time,several studies utilize federated techniques to implement human mobility prediction[14-17].Different from them,our proposed model combines the data and model perturbation mechanisms to protect users’ privacy.What’s more,we propose a threat model by considering two different types of privacy attacks and further evaluate the performance in terms of both prediction accuracy and privacy leakage risks based on the proposed threat model.
Federated Learning.Federated learning has been a promising technique to meet the increasing demand for privacy protection.Although federated learning does not require communication with data,there still exist different kinds of information leakage problems[32,33],as an illustration,[33]has proposed an attack technique,which can recover the data that the transmitting gradient involves.Researchers have been devoted to developing a federated learning system with high security and privacy.Specifically,considers a very possible case when clients do not trust the server,then the differential privacy can be applied for secure aggregation,which can ensure the server does not learn any individual user information [34].Moreover,[35] proposes two strategies based on differential privacy,namely output perturbation and gradient perturbation.Specifically,in the output perturbation,the parties combine local models within a secure computation and then add the required differential privacy noise before revealing the model,while the gradient perturbation method mainly trains a global model collaboratively over clients via an iterative learning algorithm.Another problem in federated learning is the worker machines might be susceptible to errors,which may result from data crashes,software or hardware bugs,stalled computation,or even malicious and coordinated attacks,known as the Byzantine failures [36,37].To be specific,[36]proposes a communication efficient second-order distributed optimization,and it compresses the local information before sending it to the center and employs a simple norm based thresholding rule to filter out the Byzantine worker machines.Based on the federated optimization method SignSGD [38],a coding theoretic framework is proposed with a new informationtheoretic limit of finding the majority opinion when some workers could be attacked by adversary to guarantee Byzantine-robustness [37].Furthermore,random Bernoulli codes and deterministic algebraic codes are constructed to tolerate Byzantine attacks.
III.PROBLEM DEFINITION AND SYSTEM DESIGN
3.1 Mathematical Setup and Problem Overview
We consider the scenario where there are multiple users with their own mobile devices.Each device has recorded the historical mobility trajectory of the corresponding user.Specifically,the mobility trajectoryDuof useruis defined by a orderiof spatiotemporal points,i.e.,Du=,whereis the identifier of the visited location andis the identifier of the corresponding time unit.Specifically,We adopt the common setting of the existing mobility prediction methods by dividing time into 30-minute time units[11,14].We further define the set of users asU.Based on the above notations,the federated mobility prediction problem can be defined as follows:
Definition 1(Federated Mobility Prediction).Given a set of user U and their historical mobility trajectory {Du}u∈U,the goal of this problem is to train a model distributedly to estimate the visited location in the users’next movement.In addition,the privacy of each user in terms of their trajectory data should be preserved in this process.
To solve this problem,we train the mobility prediction model in the manner of federated learning,where the most common server-client architecture is used.Specifically,each client is a mobile device that contains the trajectory data of a user,and it trains the mobility prediction model,which is a neural network,locally on its private trajectory data.After several iterations,the local models of different clients are sent to the server,and the server aggregates the local models of different clients and obtains a global model,which is then sent to clients to update their local models.
In the following sections,we will first introduce the structure of the basic mobility prediction model used in our system.Next,we introduce how to train the mobility prediction model in the manner of federated learning.
For readability,we summarize the major notations used throughout the paper in Table 1.

Table 1.A list of commonly used notations.
3.2 Basic Mobility Prediction Model
We adopt the mobility prediction neural network with the classical three-layer structure composed of the location embedding layer,sequential modeling layer,and location prediction layer.This structure is widely adopted in modeling sequential data with discrete symbols,e.g.,natural language sentences [39],web click sequence [40],etc.The structures of the three layers are introduced in detail as follows.
Location Embedding Layer:Locations in the raw mobility trajectory data are represented by discrete symbols,which cannot be processed by the neural networks.To solve this problem,we must encode the symbols describing different locations into numerical vectors.A direct encoding strategy is one-hot embedding.|L|is the vector of visited locations.That is,map the|L| locations into the|L|-sized vectors with|L|-1 zero elements and a single one element corresponding to the visited location.However,this sparse encoding strategy regards each location as an independent item without modeling the relationship between them.Thus,we adopt a more widely-used encoding strategy by mapping locations into the vectors belonging to the same low-dimensional feature space,where the relationship between locations and future movement is captured.That is,locations that have a similar impact on users’future movement are mapped into similar vectors.
In addition,the temporal information of the mobility record should also be considered and extracted.Thus,for each mobility record,by denoting the corresponding one-hot embedding vectors of the location and time unit asliandti,the output of this layer can be summarized as follows:
wheretanh(·) is a nonlinear activation function,andWLandWTare the embedding matrixes of locations and time units,respectively.
Sequential Modeling Layer:The above layer mainly focuses on capturing the features of a single historical record.Based on it,this layer is further utilized to capture the sequential information of the historical mobility records from the trajectory-level perspective.
We utilize the powerful tool of recurrent neural networks (RNN) to capture the trajectory-level feature.Specifically,in RNNs,the hidden vectorhiis utilized to characterize the sequential information of mobility records before(li,ti),which is calculated recurrently.That is,hiis calculated based onhi-1and the feature vector of the current mobility recordsi,of which the process can be represented by the following equation:
whereg(·)is the kernel function describing the recurrent process of the RNN.By recurrently implementing(2),the sequential information of the whole trajectory can be extracted.
Location Prediction Layer:Based on the trajectory-level sequential features of the historical trajectory,this layer is further utilized to predict users’future movement.Specifically,this layer takes the sequential information of the whole trajectoryhas input,and maps it to an|L|-sized vectoryiwithl-th element representing the estimated probability of visiting locationlin the next movement.This process can be represented by the following equation:
whereWPis the projection matrix of this layer.
3.3 Federated Optimization
The above mobility prediction model is trained in the manner of federated learning,which will be introduced in detail in this section.
Specifically,the model is trained based on the cooperation between the clients and server,where the clients are in charge of training the model separately on their local privacy data and the server is in charge of coordinating different servers.
First,each client trains the mobility prediction model locally based on the stochastic gradient descent(SGD) algorithm,where we select categorical cross entropy as the loss function:
whereCdenotes the number of categories,andycis the indicator variable (zero or one),which is one of the predicted categories of the sample is the same as the true category(equal toc)and zero otherwise,anddenotes the predicted probability that the observed sample belongs to categoryc.
Specifically,the loss function of clientucan be represented as follows:
where〈·,·〉represent the dot product between two vectors,andis the local model of clientu.Based on the loss function (5),each client updates its local model based on SGD on its private trajectory data for several iterations.
Then,the local gradients of different clients based on the loss function (5) are sent to the server,and the server aggregates the local gradients of different clients and obtains a global model.By denoting the gradients sent by the clientuasand the aggregate model asat thek-th iteration,this process can be represented as follows.
whereλis the learning rate.Then,the obtained global model is sent to all clients.After receiving the global model,clients replace their local model with the global model and then continue to implement the local update and repeat the above procedures.After a sufficient number of communication rounds between the clients and server,we can obtain the well-trained mobility prediction model.
IV.THREAT MODEL AND PRIVACYPRESERVING MECHANISM
In the federated mobility prediction system introduced in Section III,the private trajectory data of each user is stored in his/her mobile device and is never uploaded to the server nor sent to other mobile devices,of which the goal is to protect user privacy.However,though only the model parametersxuare uploaded from the client,there still exist high risks of privacy leakage.Specifically,the server or the arbitrary third party that can sniff the communication between the server and clients are possible attackers.After obtaining the model parametersxuuploaded by useru,the attackers seek to infer the user’s privacy information fromu.Thus,the risks of privacy leakage in this process should be paid attention to and characterized.In the following part of this section,we will first present the threat model by modeling the attack process of the adversaries.Then,we focus on eliminating the privacy leakage risk by proposing a novel privacy-preserving mechanism by fusing the classical data perturbation mechanisms[14]and model perturbation mechanisms[41].
4.1 Threat Model
As mentioned above,the server or the arbitrary third party that can sniff the communication between the server and clients are possible attackers.Thus,We assume that the adversary can obtain the transmitted modelxubetween the server and the target clientu.Then,the attackers can compare the parameters of the global model received by the client and its locally updated and uploaded model to reveal sensitive information about the client.Specifically,we consider two different categories of attacks defined as follows:
Definition 2(Visited Location Inference Attack).The goal of this kind of attack is to infer whether the user has visited a certain location by comparing the parameters of the received global model and the locally updated model of the corresponding client.
As for the concrete method to implement thevisited location inference attack,we follow the existing literature[14],which infers users’visited location by comparing the weight of location embedding layer,i.e.,WLbetween the global modelreceived by the client and its locally updated and uploaded modelSpecifically,each column inWL,which represents different locations,is compared by calculating their Euclidean distance betweenandFor an arbitrary locationl,if the Euclidean distance of its corresponding column vectors is larger than a predefined threshold,this method infers that useruhas visited locationlin his/her historical mobility trajectories.To facilitate understanding of this attack,we show its detailed process in Algorithm 1,which is further visualized in Figure 1.In this example,we can analyze a user’s trajectory in whichl2andl3are greater than a certain threshold,butl1andl4are not greater than the threshold,so we conclude that he has visitedl2andl3,but notl1andl4.

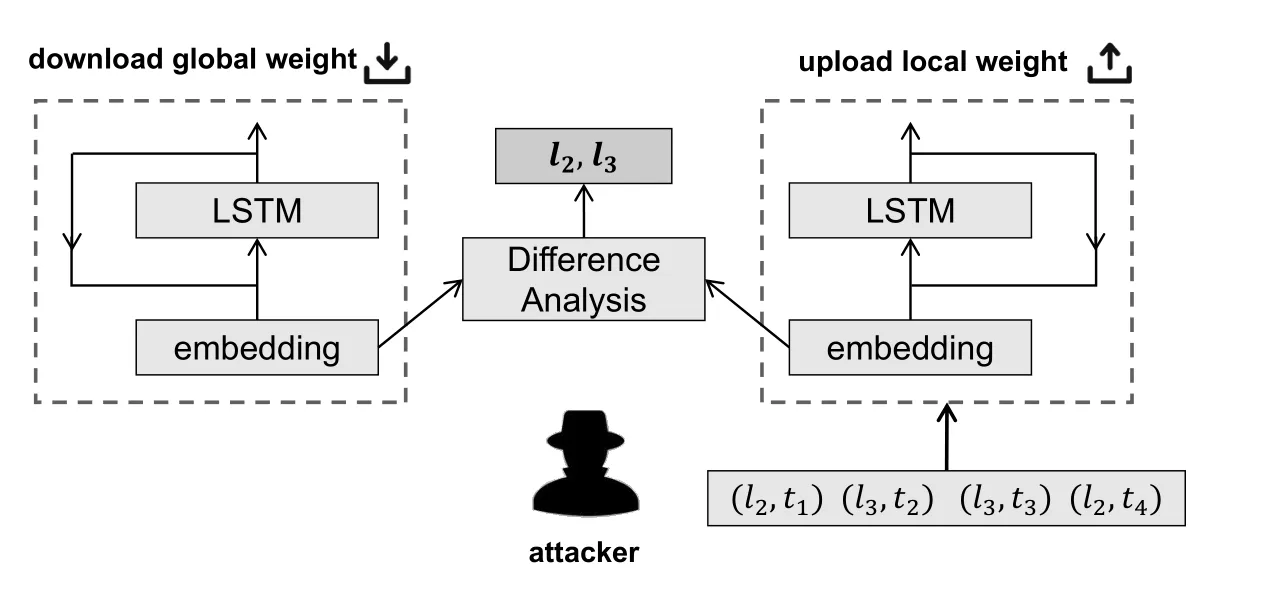
Figure 1.Visualization of visited location inference attack.
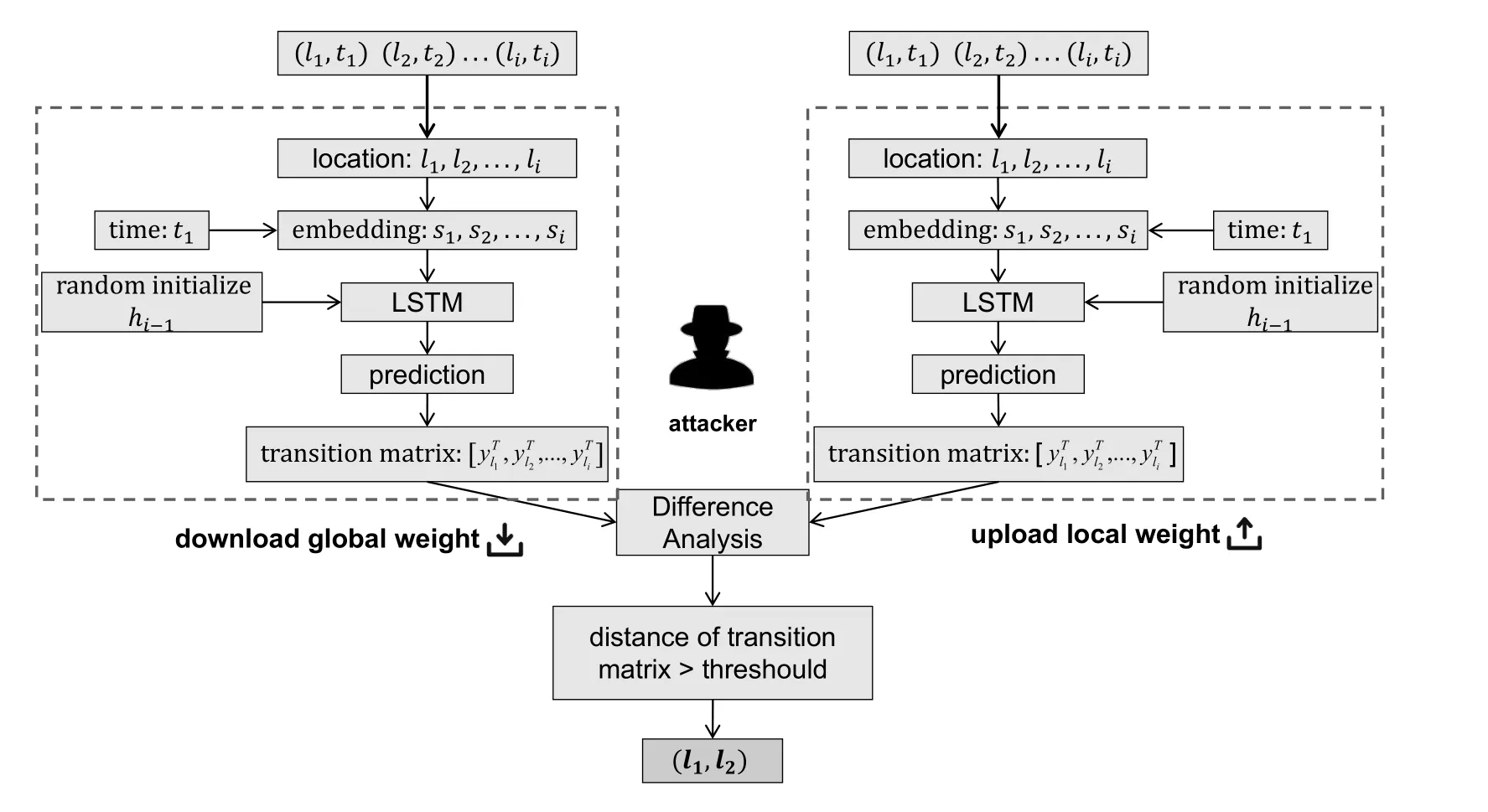
Figure 2.Visualization of transition pattern inference attack.
Definition 3(Transition Pattern Inference Attack).The goal of this kind of attack is to infer whether the user has a certain transition pattern,i.e.,moving from the target source region to the target destination region,by comparing the parameters of the received global model and the locally updated model of the corresponding client.
Feng et al.[14] only consider the privacy leakage from the location embedding layer,and they ignore the privacy leakage of the other parts in the neural networks.However,we argue that there exist high risks of privacy leakage in the sequential modeling layer.Thus,we propose a new type of attack to achieve thetransition pattern inference attackbased on it,of which the detailed process is shown in Algorithm 2 and Algorithm 3.


4.2 Privacy-Preserving Mechanism
To eliminate the privacy leakage risk in terms of the above threat model,privacy-preserving mechanisms should be added to the federated mobility prediction system.Existing approaches either choose to add perturbations to the trajectory data [14,42,43],or add perturbations to the transmitted models between the server and clients to protect user privacy[41].In this paper,we first introduce how existing works protect user privacy by adding perturbations to the data and the model,respectively.After analyzing their strength and weaknesses,we propose a compound perturbation mechanism that adds perturbations to the trajectory data and the mobility prediction model simultaneously to protect user privacy.
4.2.1 Data Perturbation Mechanism
To protect user privacy in the process of federated learning,some existing approaches are selected to add perturbations to the dataset of each client before the dataset is utilized to locally update the model.In terms of the privacy of location data,the most widely adopted data perturbation mechanism is the Laplace perturbation mechanism [44,14,42,43].The main goal of this method is to achieve the criterion ofϵ-Geo-Indistinguishability defined as follows.
Definition 4(ϵ-Geo-Indistinguishability).A randomized mechanism M:L → O satisfies ϵ-geo-Indistinguishability if and only if,for arbitrary location l1∈L and l2∈L,and subset O ∈O,we have Pr(M(l1)∈O)≤Pr(M(l2)∈O) +δ,where d(l1,l2)is a pre-defined distance between location l1and l2.
We follow the common settings of Geo-Indistinguishability by definingd(l1,l2) as the Euclidean distance between locationl1andl2,and further use the Laplace perturbation mechanism to achieveϵ-Geo-Indistinguishability.Specifically,for each original locationl,after adding Laplace perturbations,the distribution of the obtained locationpcan be expressed as follows:
It has been proven that the perturbation mechanism(7)satisfies theϵ-Geo-Indistinguishability[44].
To improve the model performance under the data perturbation mechanism,a group optimization trick is proposed in[14].This trick splits the whole modelxinto the risky componentχand the normal componentψ.Specifically,the risky component is the location embedding layer in this problem.Then,it utilizes the original data to train the whole model and then utilizes the noisy data to train the location embedding layerχwith the fixed normal componentψ.However,this method can only defend the privacy attack based on the location embedding layer while there still exist privacy leakage risks at the sequential modeling layer,which we will show in Section V.
4.2.2 Model Perturbation Mechanism
On the other hand,other approaches [41] choose to add noise to the model parameters uploaded by clients to protect their privacy.The corresponding criterion is the(ϵ,δ)-differential privacy,which is formally defined as follows.
Definition 5((ϵ,δ)-differential privacy).A randomized mechanism M:D → O satisfies(ϵ,δ)-differential privacy if and only if,for arbitrary adjacent datasets D1and D2,and subset O ∈O,we have Pr(M(D1)∈O)≤eϵPr(M(D2)∈O)+δ.
To achieve (ϵ,δ)-differential privacy,this mechanism adds Gaussian noise to the transmitted gradients.Further,a threshold is used to clip the gradient,then the Gaussian noise is added to the clipped gradient to achieve the differential privacy.This process can be represented by the following equations:
whereCis the clipping threshold of the gradient,andσ2C2is the variance of the added Gaussian noise.More specifically,the clip operation can be represented as follows:
where‖·‖2is the Euclidean norm.In addition,the relationship betweenC,σ,andϵhas been given by the moments accountant method[41].
From the Definition (4) and (5),we can observe that(ϵ,δ)-differential privacy is more strict compared withϵ-Geo-Indistinguishability.Specifically,for two locations that are far away from each other,ϵ-Geo-Indistinguishability only requires a loose bound,while the requirement in (ϵ,δ)-differential privacy does not change.Thus,the model perturbation mechanism might cause more damage to the performance of the trained model.
4.2.3 Compound Perturbation Mechanism
Considering that the data perturbation mechanism cannot defend the privacy attack based on the sequential modeling layer while the model perturbation mechanisms cause more damage to the model performance,we propose to fuse these two perturbation mechanisms.Specifically,the relatively smaller data perturbation is still added to the trajectory data,and at the same time,a model perturbation is added only to the sequential modeling layer.Based on the compound perturbation mechanism,we can overcome the limitations of the existing perturbation mechanisms.
Further,we propose three different strategies for allocating noise to the data and the model in the compound perturbation mechanism.
• Model-dominated strategy:In this strategy,the lowest level of data perturbation is added to the location data,and the model perturbation is dominant and adjusted based on the privacy-preserving requirement.
• Data-dominated strategy:In this strategy,the lowest level of model perturbation is added to the model gradient,and the data perturbation is dominant and adjusted based on the privacy-preserving requirement.
• Piece-wise strategy:This strategy does not require the lowest level of any perturbations.Specifically,it dynamically finds the perturbation that should be added to meet the higher requirement of privacy-preserving based on the greedy policy.
We summarize the process of federated learning based on the proposed compound perturbation mechanism in Algorithm 4.As we can observe,this algorithm takes the communication round,learning rates,and initial model parameters as input (line 1).Then,the algorithm will operate in an iterative manner,where each iteration represents a communication round between the server and clients.Specifically,in each communication round,the client will first replace the local modelxuwith the obtained global model in the last round and then divide it into two componentsχuandψu,which correspond to the location embedding layer and other layers (lines 4-5).Then,perturbation is added to the client’s local data(line 6).The original data is first used to calculate the gradient,and the model perturbation is added only to the gradient corresponding to the componentψu(lines 7-8).Further,the noisy data is utilized to only update the location embedding layer (lines 9-10).After obtaining the final local model,its difference compared with the initial model at the beginning of this round is sent to the server(lines 11-12).Then,based on(6),the server obtains the new global model of this communication round and sends it to all clients(lines 14-15).After a sufficient number of communication rounds,the mobility prediction model can be trained.

V.EXPERIMENTS
5.1 Dataset
NYC-Taxi:This dataset contains over 160 million taxi trips collected from 1 January 2013 to 31 December 2013 in New York.Trip data includes pick-up and drop-off date times,pick-up and drop-off locations,distances of the trips,and even more attributes.Considering the huge data volume of the complete dataset,we use about 100,000 records of January taxi trips to train our model.
5.2 Baselines
We compare our model with the following five baselines:
•Markov Model [45]:Markov model is widely used in the field of Mobility Prediction because it complies with the characteristics of time-series data.It uses historical trajectory data for location prediction by calculating the transition probabilities between these locations.
•LSTM[28]:LSTM network is good at handling sequential data and has the advantage of encoding long-term dependencies,which naturally be applied to location prediction.
•FPMC [46]:Factorizing personalized Markov chains combines the advantages of matrix factorization(MF)and sequential Markov chains(MC)method.
•APHMP[16]:APHMP applies an attention module to capture useful information in historical mobility records and integrates it into the recurrent neural network to predict location.
•ROI[47]:This method is based on recurrent neural networks and incorporates a small number of important regions of users,which are denoted as the region of interest(ROI).
5.3 Evaluation Metrics
In our experiments,two representative metrics are adopted for evaluating the performance of our model,i.e.,accuracy and attack risk.
Attack risk is used to measure the success rate of an attack.We define the attack risk for two types of attacks as below:
Visited Location Inference Attack:
wherelsdenotes the location set,lstruthandlsattackare the true location set and the inferred location set.
Transition Pattern Inference Attack:
whereTpdenotes the transition pattern,TptruthandTpattackare the true transition pattern and the inferred transition pattern.
5.4 Experimental Settings
The main parameters of our model consist of four components.The first part is the parameters of the mobility prediction,where we set the size of location embedding to 64,the size of time embedding to 10,and the size of the hidden state to 64.The second part is hyper-parameters for the local training of the mobility model,where we set the learning rate to 0.04 and the dropout rate to 0.3.The third part is hyperparameters for the global aggregation,where the number of clients is 50 and the local epoch is 1.The last part is the parameters of differential privacy,where we set clipping thresholdsC=1.0 andδ=10-5.As for the parameters of our proposed privacy-preserving mechanism,we denote the parameters corresponding to the privacy criteria corresponding to the data perturbation and model perturbation Mechanisms asϵdataandϵmodel,respectively.For the model-dominated strategy,theϵdatais set to be 10,which is the lowest level of data perturbation,whileϵmodelis dynamically adjusted.As for the data-dominated strategy,similarly,theϵmodelis set to be 10,whileϵdatais dynamically adjusted.
5.5 Experimental Results
Markov,FPMC,and LSTM are all centralized models,while APHMP and ROI are federated models.From Table 2,a comparison of our model with the three baselines shows that the deep learning-based model performs better in mobility prediction,i.e.,LSTM,APHMP,ROI,and our model performs better.In addition,the accuracy of our model is higher than Markov,FPMC,and ROI and slightly lower than LSTM and APHMP.
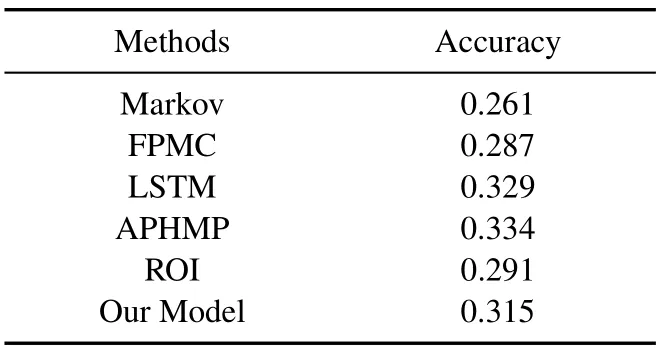
Table 2.Prediction performance.
Focusing on the trade-off between risk and performance under both attacks,Figure 3 and Figure 4 show that our method is effective in protecting personal privacy from attacks.
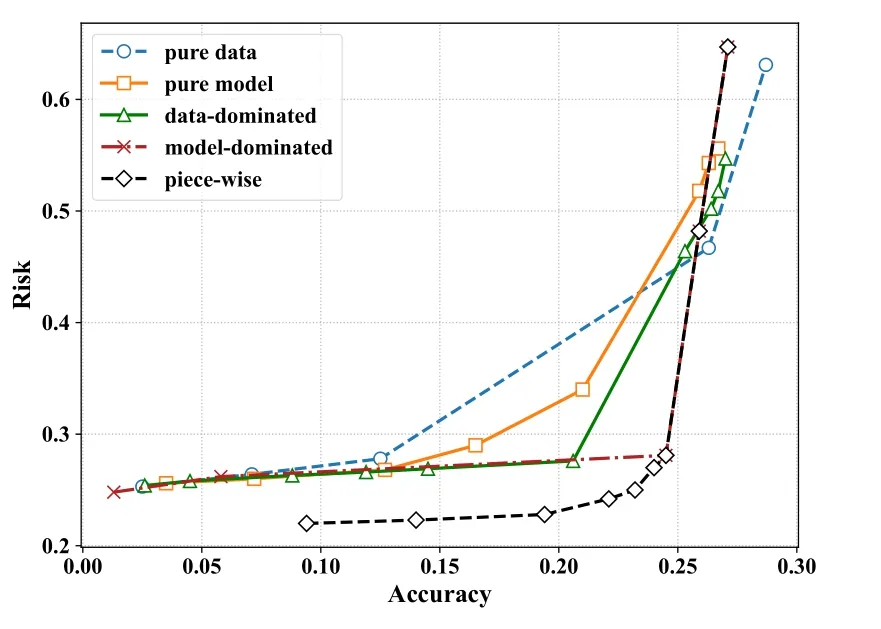
Figure 3.The trade-off between attack risk and prediction accuracy under Visited Location Inference Attack.
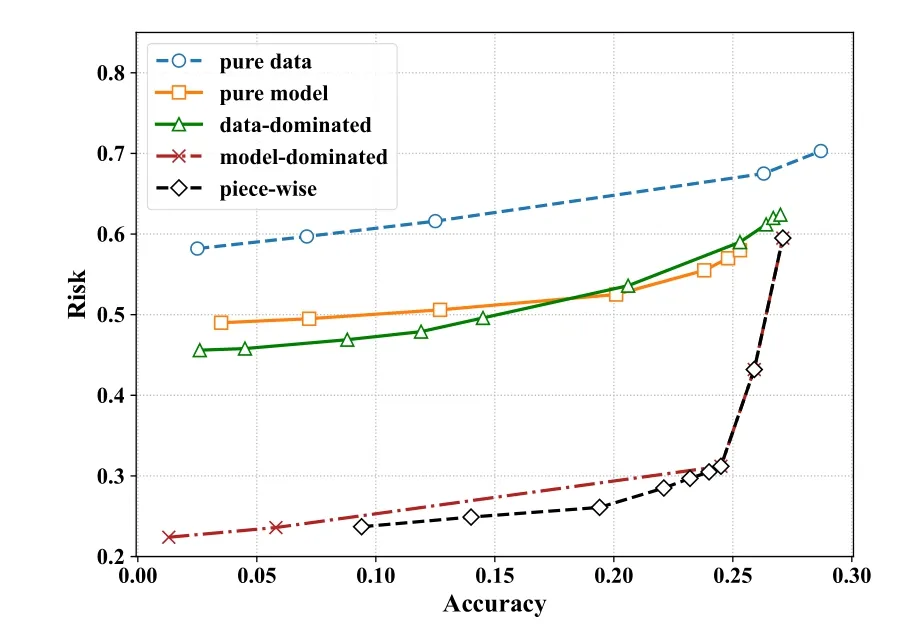
Figure 4.The trade-off between attack risk and prediction accuracy under Transition Pattern Inference Attack.
The light green dotted line is the risk of nonperturbation federated model,which shows the upper bound of risk.For the visited location inference attack,whenϵgets higher (less accurate and lower attack risk),several perturbation mechanisms perform similarly except for the piece-wise compound perturbation mechanism,where the performance of the pure model perturbation mechanism rapidly deteriorates at this point.However,when theϵgets lower(accuracy becomes better and attack risk becomes higher),our three compound perturbation mechanisms perform between the pure model perturbation mechanism and the pure data perturbation mechanism,indicating that our methods better balance risk and performance.
Under a transition pattern inference attack,there is a large gap between the performance of the model perturbation mechanism and the data perturbation mechanism.For the data perturbation mechanism,it cannot defend against transition pattern inference attacks.For the model perturbation mechanism,it has the advantage of being an effective defense against attacks,but it has the disadvantage that the performance deteriorates rapidly whenϵis small and we need to trade a large loss of accuracy for a small reduction in risk.For the compound perturbation mechanism,the model-dominated strategy and data-dominated strategy effectively reduce the attack risk with the same accuracy compared to the pure data perturbation mechanism,but do not maximize the advantages of the pure model perturbation mechanism.Compared with the other four mechanisms,the piece-wise strategy notonly mitigates the problem of trading a large accuracy loss for a small risk reduction at lowerϵ,but also balances risk and performance well at higherϵ,trading a small accuracy loss for a large risk reduction.Since the piece-wise compound perturbation mechanism performs best in terms of the trade-off between attack risk and prediction accuracy,we only show the metrics of the piece-wise compound perturbation mechanism as shown in Table 3.

Table 3.The variation of attack risk and accuracy of piece-wise compound Perturbation perturbation mechanism with different differential privacy parameter ϵ.
VI.CONCLUSION
In this paper,we propose a privacy-preserving federated mobility prediction model,which fuses the data perturbation and model perturbation mechanisms by overcoming their limitations to achieve a better performance in terms of both prediction accuracy and defending privacy attacks.Specifically,we propose three novel strategies to allocate noise with different energies to the data perturbation and model perturbation.What’s more,we have implemented two different types of privacy attacks to evaluate the privacypreserving performance of our proposed method in practice.Extensive experimental results show that our proposed method significantly outperforms the existing state-of-the-art mobility prediction method in terms of defensive performance against practical attacks while having comparable mobility prediction performance,demonstrating its effectiveness.
ACKNOWLEDGEMENT
This work is supported in part by the National Key Research and Development Program of China under 2020AAA0106000,the National Natural Science Foundation of China under U20B2060 and U21B2036.This work is also supported by a grant from the Guoqiang Institute,Tsinghua University under 2021GQG1005.

- China Communications的其它文章
- Space/Air Covert Communications: Potentials,Scenarios,and Key Technologies
- Improved Segmented Belief Propagation List Decoding for Polar Codes with Bit-Flipping
- Scenario Modeling-Aided AP Placement Optimization Method for Indoor Localization and Network Access
- Off-Grid Compressed Channel Estimation with ParallelInterference Cancellation for Millimeter Wave Massive MIMO
- Low-Complexity Reconstruction of Covariance Matrix in Hybrid Uniform Circular Array
- Dynamic Update Scheme of Spectrum Information Based on Spectrum Opportunity Incentive in the Database-Assisted Dynamic Spectrum Management