
Redundant Data Detection and Deletion to Meet Privacy Protection Requirements in Blockchain-Based Edge Computing Environment
2024-04-01 02:08ZhangLejunPengMinghuiSuShenWangWeizhengJinZilongSuYansenChenHuilingGuoRanSergeyGataullin9
China Communications 2024年3期
Zhang Lejun ,Peng Minghui ,Su Shen ,Wang Weizheng ,Jin Zilong ,Su Yansen ,Chen Huiling,Guo Ran,Sergey Gataullin9,0
1 Cyberspace Institute Advanced Technology,Guangzhou University,Guangzhou 510006,China
2 College of Information Engineering,Yangzhou University,Yangzhou 225127,China
3 School Math&Computer Science,Quanzhou Normal University,Quanzhou 362000,China
4 Computer Science Department,City University of Hong Kong,Hong Kong 999077,China
5 School of Computer and Software,Nanjing University of Information Science and Technology,Nanjing 21004,China
6 Key Laboratory of Intelligent Computing and Signal Processing of Ministry of Education,School of Computer Science and Technology,Anhui University,Hefei 230601,China
7 Department of Computer Science and Artificial Intelligence,Wenzhou University,Wenzhou 325035,China
8 Guangzhou University Library,Guangzhou University,Guangzhou 510006,China
9 Central Economic and Mathematics Institute,Russian Academy of Sciences
10 MIREA-Russian Technological University,Moscow Region,Russia
Abstract: With the rapid development of information technology,IoT devices play a huge role in physiological health data detection.The exponential growth of medical data requires us to reasonably allocate storage space for cloud servers and edge nodes.The storage capacity of edge nodes close to users is limited.We should store hotspot data in edge nodes as much as possible,so as to ensure response timeliness and access hit rate;However,the current scheme cannot guarantee that every sub-message in a complete data stored by the edge node meets the requirements of hot data;How to complete the detection and deletion of redundant data in edge nodes under the premise of protecting user privacy and data dynamic integrity has become a challenging problem.Our paper proposes a redundant data detection method that meets the privacy protection requirements.By scanning the cipher text,it is determined whether each sub-message of the data in the edge node meets the requirements of the hot data.It has the same effect as zero-knowledge proof,and it will not reveal the privacy of users.In addition,for redundant sub-data that does not meet the requirements of hot data,our paper proposes a redundant data deletion scheme that meets the dynamic integrity of the data.We use Content Extraction Signature(CES)to generate the remaining hot data signature after the redundant data is deleted.The feasibility of the scheme is proved through safety analysis and efficiency analysis.
Keywords: blockchain;data integrity;edge computing;privacy protection;redundant data
I.INTRODUCTION
The rapid development of information technology makes IoT devices closer to people’s lives [1].IoT devices play a huge role in physiological health data[2].IoT devices in edge computing [3-6] can monitor and collect the user’s physical health data in time,the remote cloud server will perform statistical processing on the received data.However,cloud computing often cannot guarantee the timely processing of data.In this information age,users want their requests to be processed in a timely manner [7].The cloud computing-based architecture has strong computing power,but cannot guarantee the timeliness of data processing,and long-distance transmission causes a large delay.To solve this problem,the mobile-edge computing(MEC)technology was born[8].Edge nodes connect edge devices and remote cloud servers,providing quality services[9-11]for the users.but there are still the following problems.1)The storage space of edge nodes is limited,and the unreasonable distribution of data cannot guarantee the timeliness of data response.2)A lot of redundant and repeated data is stored in the edge node,which leads to a waste of storage space.3)Semi-trusted edge nodes and cloud servers may leak users’private data.To address these issues[12],some researchers propose to store original data that needs to be searched frequently in edge nodes to improve the hit rate and the timeliness of response,though the disadvantages still exist[13-15].How to ensure that the sub-data of the original data meets the requirements of hot data [16-18],how to ensure that the integrity of the data will not be damaged when the redundant data in the original data is deleted.In order to solve these problems,our paper proposes redundant data detection and deletion to meet privacy protection requirements under blockchain-based edge computing.The main contributions of this paper are described as follows:
1.Our paper proposes a redundant data detection method that meets the privacy protection requirements.By scanning the cipher text,it is determined whether each sub-message of the data in the edge node meets the requirements of the hot data.It has the same effect as zero-knowledge proof,and it will not reveal the privacy of users.
2.Our paper proposes a redundant data deletion scheme that meets the dynamic integrity of the data.We use CES to generate the remaining hot data signature after the redundant data is deleted.
3.In our scheme,content popularity meets the Zipf distribution.We can know the requirements that the hot data needs to meet according to the Zipf distribution.After deleting the redundant data of the edge node,we can ensure the timeliness of the response and improve the hit rate of the access data.
The paper is organized as follows: The second section reviewed on research status of redundant data detection and deletion under blockchain-based edge computing is provided.In Section II,the system model of this scheme will be described.The Workflow of the Scheme will be described in Section IV.Section V will make a reasonable analysis of the safety and performance of our scheme.Finally,the summary of this article and future prospects will be elaborated in Section VI.
II.RELATED WORK
In this section,we reviewed the research status of redundant data detection and deletion under blockchainbased edge computing.
Zhang et al.[19] proposed a resource allocation and trust computing scheme for blockchain-enabled edge computing system.In Zhang’s scheme,the cloud server sorts the keywords according to the search frequency of the original data,and stores the original data corresponding to the top keywords in the edge node’s hot data pool.Although storing the original data with a higher search frequency in the hot data pool of the edge node can improve the access hit rate,there are inevitably redundant data in the original data.The existence of these redundant data will reduce the access hit rate.and waste storage space.
He et al.[20] analyzed data deduplication techniques and studying the data de-duplication strategy,processes,and implementations for the following further lay the foundation of the work.Since users often use their own private keys to sign the original data,the integrity of the remaining data cannot be guaranteed after the redundant data is deleted.
Kang et al.[21]proposed a secure and efficient data sharing scheme.In this scheme,edge computing has powerful computing power and the ability to store certain resources.IoT devices can collect relevant information about vehicles in a timely manner.The information will be submitted to the edge node for processing.However,edge nodes are untrustworthy,they may leak the user’s sensitive data.
Our paper proposes a redundant data detection and deletion scheme to meet privacy protection requirements under blockchain-based edge computing.Our paper designs a redundant data detection method that meets the privacy protection requirements.By scanning the ciphertext,it is determined whether each submessage of the data in the edge node meets the requirements of the hot data.It has the same effect as zero-knowledge proof,and it will not reveal the privacy of users.In addition,for redundant sub-data that does not meet the requirements of hot data,our paper designs a redundant data deletion scheme that meets the dynamic integrity of the data.We use CES to generate the hot data signature after the redundant data is deleted.CES realized the separation of the hot data part and the redundant data part of the original data and ensure the integrity of the data.
III.REDUNDANT DATA DETECTION AND DELETION MODEL UNDER BLOCKCHAIN-BASED EDGE COMPUTING
3.1 Notations
The symbols and corresponding explanations in this article are given in the Table 1.
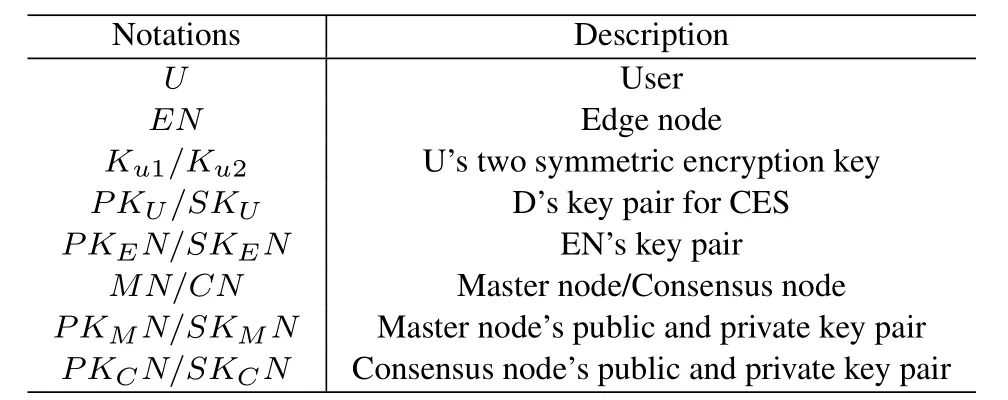
Table 1.Notations.
3.2 System Structure
It can be seen from Figure 1 that our model is divided into three layers.
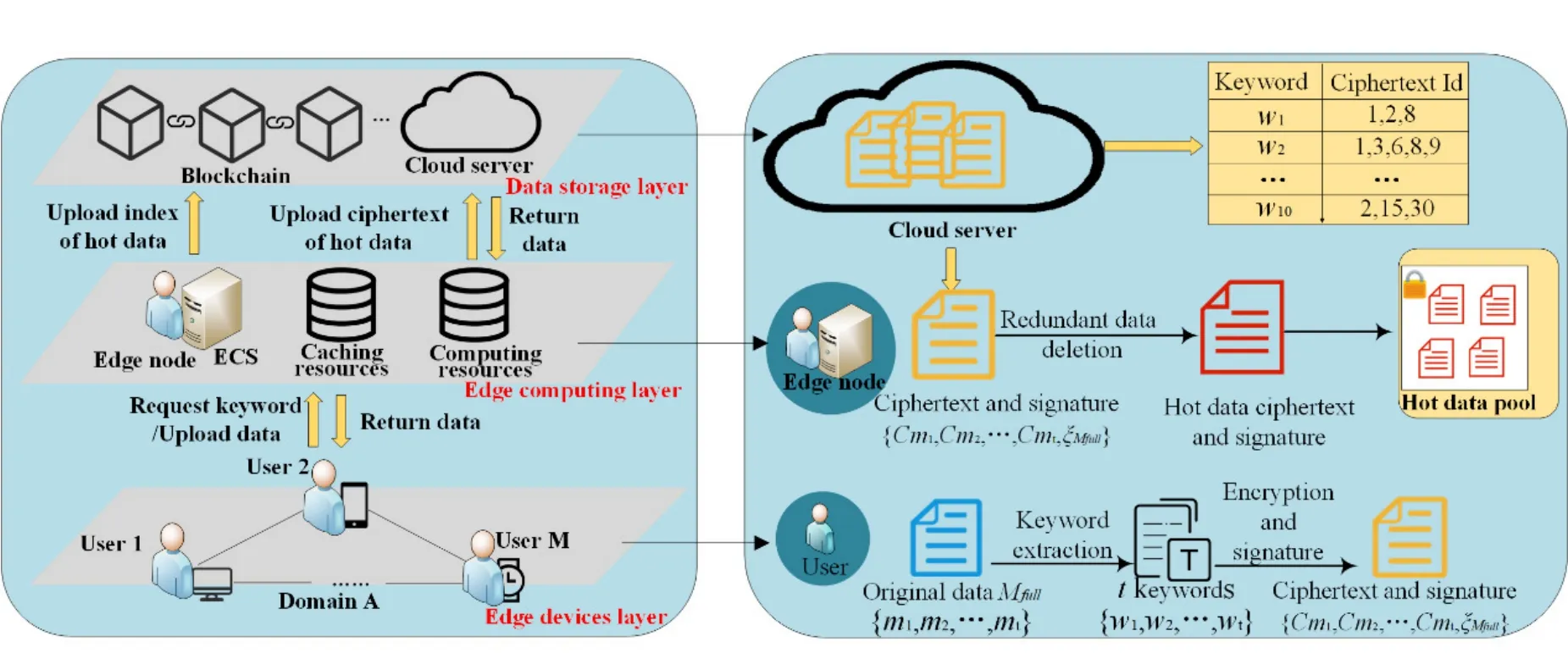
Figure 1.System overall framework.
Edge devices layer.Multiple IoT devices owned by users can collect user information in a timely manner.First,the user generates the keyword corresponding to each sub-message in the original data,and then uses its own symmetric key to encrypt each sub-message,finally the user uses CES to generate a complete signature of the ciphertext data.
Edge computing layer.After receiving the ciphertext data submitted by the user,the edge node uploads the data to the cloud by means of backup upload;the cloud will return all ciphertext data that meets the hot data conditions.Since the sub-messages in the data returned by the cloud may not meet the requirements of the hot data,the edge node will delete the redundant data in the data returned from the cloud,and generate the extraction signature of the hot data at the same time,finally the edge node will store the ciphertext of the hot data and the extraction signature in hotspot data pool.
Data storage layer.The server calculates the popularity of each keyword according to the search frequency,and the cloud server uses a database to store all the data in order according to the popularity of the content of the keyword.The index of each data will be stored in a tamper-proof blockchain.
IV.THE WORKFLOW OF THE SCHEME
4.1 Data Processing Stage
It is assumed that original dataMfullcollected by IoT devices contains t sub-message,Mfull={m1,m2,...,mt}.IoT devices scan each submessage in the original data to extract the keywords corresponding to each sub-message,keyword setW={w1,w2,...,wt}.In order to ensure that data is not leaked by semi-trusted edge nodes and cloud servers,users will useKu1to encryptmiandwi,i ∈[1,9].original dataMfull.The encryption process is shown in Eq.(1),(2).According to the above encryption calculation,Original data ciphertextCMfull={Cm1,Cm2,...,Cmt}.Next we first introduce U’s key pair generation method.
Key generation:Trusted authority selects two unequal prime numbers:handq.Then the trusted authority calculatesn=h×qand sets Euler function:ϕ(n)=(h-1)*(q-1) .Thirdly,Uselects an integerethat is prime withϕ(n)in the interval[1,ϕ(n)],and finds an integerdto satisfy(e×d)modϕ(n)=1.Finally,according to the above calculation,PKU={n,e}.SKU={n,d}.
Uwill generate’s signatureaccording to the following signature algorithm.

As there may be data leakage during the data storage process,the data needs to be encrypted,U will use symmetric encryption keyKU2to encrypt||Hi(i ∈[1,t])||ξfull||R),and usePKENto encryptKU2.ThenDsendsInfo1 toP,Info1 is shown in Eq.(3).
4.1.1 Data Storage Stage
After EN receive Info1,EN first decrypt to obtainKU2with private keySKEN,and EN obtains||Hi(i ∈[1,t])||ξfull||R)further.
EN needs to verify the correctness of the signature through the following two operations.
(1)EN calculates the hash valueH(||ri),wherei ∈[0,b].ENwill make a judgment based on whether the result obtained from the ciphertext is consistent with the calculated result.
(2) The base station needs to verify and calculateξH∧emodn.If H is consistent with the calculated result,it proves that the data is complete and accurate.
In our scheme,edge nodes will use backup uploads to store data in the cloud avoiding data flooding caused by centralized time upload.The cloud receives the ciphertext data uploaded by the edge node and the keyword ciphertext corresponding to the ciphertext data,it will assign a ciphertext id to each ciphertext data.In addition,the cloud server will maintain a database table for record which ciphertext IDs the keywords correspond to;Next,the cloud server will sort keywords according to the frequency of user searches.
We assume that the keyword set is described asK={k1,k2,···,ki,···,kH},the collection is sorted in descending order according to the frequency of occurrence.Content popularity in our scheme satisfies the Zipf distribution.The content popularity of the keywordkican be expressed as Eq.(4):
Whereadenotes the feature degree describing the distribution of caching data.Whenais large,popular contents occupy the most of the requested content.
According to the content popularity of keywords,the cloud server can predict search frequency of keywords and sort keywords according to the search frequency.In order to improve the access hit rate and response timeliness,the cloud server will filter out the topθkeywords and send the topθkeywords,the ciphertext id and ciphertext corresponding to the topθkeywords to the edge node.
4.1.2 Redundant Data Detection and Deletion Stage The edge node receives the topθkeywords ciphertext,the ciphertext id and ciphertext from the cloud.Each ciphertext data will be scanned,and the following algorithm will be used to generate the extracted signature after deleting the redundant data.

After the edge node obtains the hotspot data and the corresponding extracted signature,the data is stored in the hotspot data pool for sharing.Next,the edge node generates an indexIndexhotdataaccording to the storage address of the hot dataurlhotdata,and uploads the index of the generated hot data to the blockchain.
In this section,EN generatesMhotdata’sIndexhotdataaccording tourlhotdata.The index generation methods are introduced as follows.After EN receiveurlhotdata,EN first useSKENto signurlhotdata,the generated signature is defined asδurlhotdata,Finally,PstoreIndexshareto shared blockchain.Indexsharegeneration process is shown in Eq.(5).
V.PERFORMANCE ANALYSIS
5.1 Security Analysis
Security is a key issue in redundant data extraction and deletion under blockchain-based edge computing.
1.Anti-tampering: In our solution,the original data is encrypted and stored in the cloud server,and the index is stored in the tamper-proof blockchain.Therefore,the characteristics of the blockchain can ensure that the data will not be easily tampered with.
2.Data consistency: In the process of deleting redundant data,the edge node processed the original data corresponding to the topθkeywords sent by the cloud.On the basis of the original data,the redundant data is deleted,and only the hot data that meets the requirements is retained,so the consistency of the data will not be changed.
3.Privacy protection:In our scheme,before uploading the original data,users use their own symmetric key to encrypt each sub-message and corresponding keywords.Semi-trusted cloud servers and edge nodes cannot obtain plaintext data.In the process of deleting redundant data,it is determined whether each sub-message of the data in the edge node meets the requirements of the hot data by scanning the ciphertext.It has the same effect as zero-knowledge proof,and it will not reveal the privacy of users.
4.Data integrity:In the entire process from data collection to data processing and storage,we will use signatures to ensure the integrity of the data.
5.2 Efficiency Analysis
5.2.1 Effect of Data Searching When the Capacity of the Edge Node Is Different
The efficiency of search depends on the hit rate of data access.Here we use the hotspot data request ratio(PHDR)to indicate the ratio of hot data in all user requests.
In Zhang’s scheme,the cloud server sorts the keywords according to the search frequency of the original data,and stores the original data corresponding to the topθkeywords in the edge node’s hot data pool.But our scheme has further processed the original data corresponding to the top keywords before storing data in the edge node’s hot data pool.Our scheme will judge whether each sub-message in the original data meets the requirements of hot data,and will delete the redundant data in the original data.We compare average hit ratio of user requests between our scheme and other schemes when the capacity of the edge node is different,as shown in Figure 2.
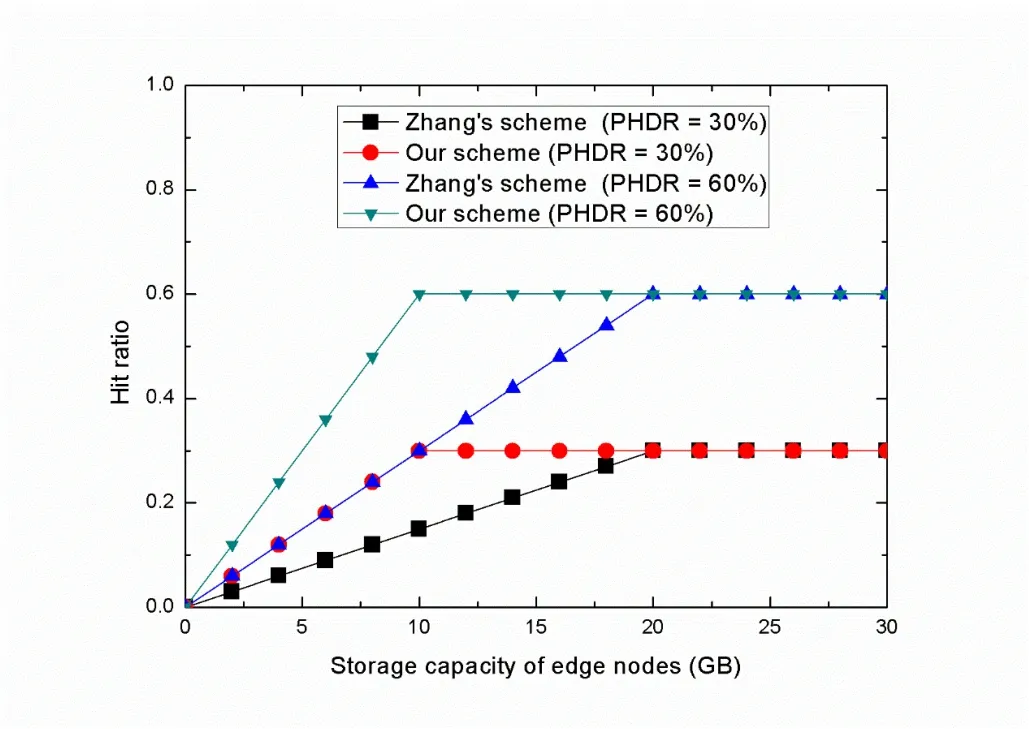
Figure 2.Average Hit ratio of user requests when the capacity of the edge node is different.
It can be seen from Figure 2 that PHDR account for about 30%and 60%of all requests.When the capacity of the edge node is greater than the total amount of hot data,regardless of PHDR,the average hit rate of requested data is equal to the proportion of hot data in all requests.But the capacity of the edge node is less than the capacity of the hot data and when the PHRD is unchanged,because the data stored in the edge node in Zhang’s scheme contains redundant data,our scheme realizes the deletion of redundant data and adds new hot data,so the average hit rate of our scheme is higher than the average hit rate of Zhang’s scheme.
5.2.2 Effect of Data Searching When the Data Update Method Is Different
In order to better evaluate our system model,we compare our content model with models such as FIFO,LRU and Zhang’s scheme.In Zhang’s scheme: The cloud server sorts the keywords according to the search frequency of the original data,and stores the original data corresponding to the topθkeywords in the edge node.
Comparing Figure 3,In FIFO scheme,if the capacity of the hotspot data pool is full,the new one will take the place of the content with the longest stay.LRU scheme removes data that has not been used for the longest time recently from the cache and the data in the cache is constantly updated and replaced.When the capacity of the edge node is greater than the size of the hot data,the above two schemes use data update and replacement methods,and there is no guarantee that hot data is stored in edge nodes.In our scheme,our hotspot data can all be stored in edge nodes,all our hotspot data can be stored in edge nodes.The hit rate of our solution basically depends on the proportion of hotspot data in our requests.
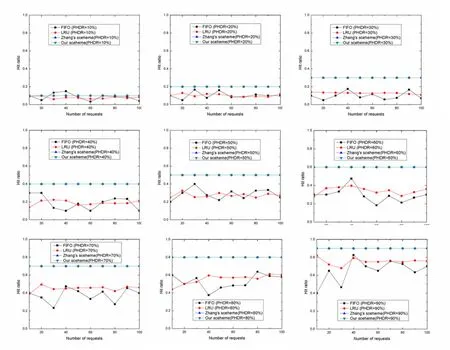
Figure 3.Average Hit ratio of user requests when the capacity of the edge node is greater than the size of the hot data and PHDR is different.
When the capacity of the edge node is lesser than the size of the hot data,we can find that as analyzed in Figure 4,When the hotspot data cannot be stored in all edge nodes,due to our fine-grained division of submessages,some non-hot-spot sub-message parts have actually been removed,while redundant parts have not been removed in the FIFO and LRU schemes,and the data replacement method in Figure 3 cannot guarantee the data hit rate.
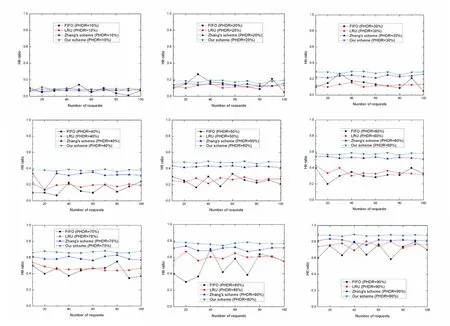
Figure 4.Average Hit ratio of user requests when the capacity of the edge node is lesser than the size of the hot data and PHDR is different.
5.2.3 Time and Space Costs to Ensure Dynamic Integrity Verification
At edge computing layer,before the redundant data is deleted and the hot data is uploaded to the hot data pool,edge node needs to ensure that the hot data is verifiable,the time and space cost comparison to ensure that the data is complete and verifiable during the redundant data deletion process are shown in Figure 5 and Figure 6.
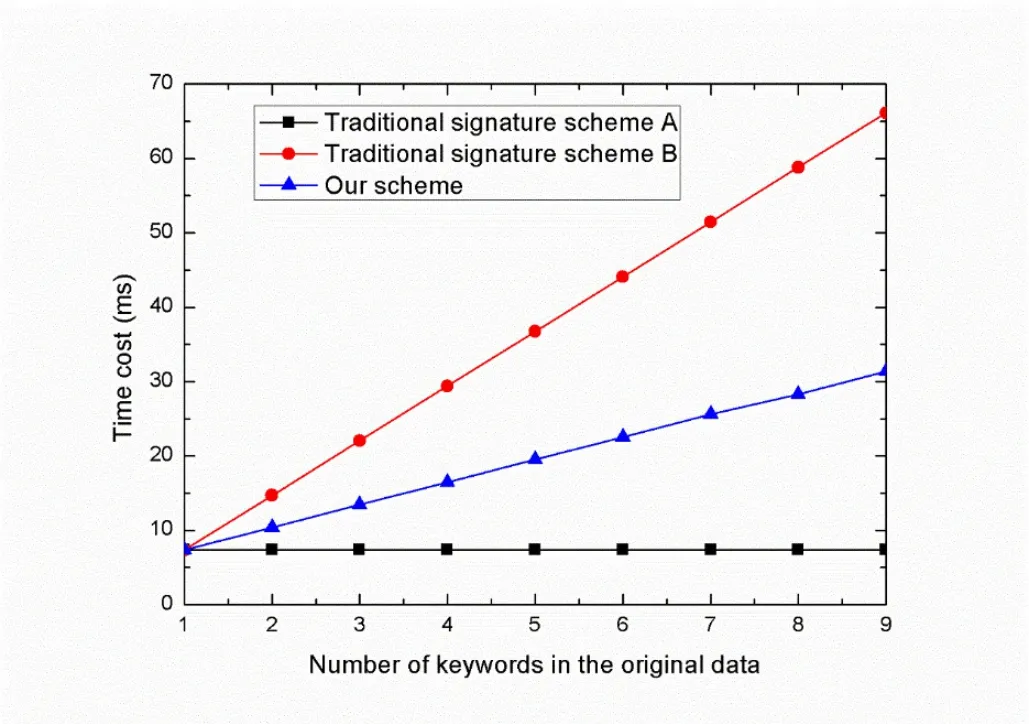
Figure 5.Signing time when the number of keywords in the original data is different.
Figure 5 shows that the signature scheme A signs the complete information.This method only needs to be signed once.Since we need to realize the separation of sub-messages,this kind of signature cannot ensure the integrity.Scheme B needs to individually sign each part of the complete message.Although it can solve the above problems,it will take a lot of time.Compared with the above two methods,our scheme can still generate the signature of the remaining data when deleting redundant data,and the time spent is between the two.
Figure 6 shows that the signature scheme A signs the complete information.This method only needs to be signed once.Since we need to realize the separation of sub-messages,this kind of signature cannot ensure the integrity.Scheme B needs to individually sign each part of the complete message.Although it can solve the above problems,it will take a lot of space.Compared with the above two methods,our scheme can still generate the signature of the remaining data when deleting redundant data,and the time spent is between the two.
VI.CONCLUSION
Our paper proposes a redundant data detection and deletion scheme to meet privacy protection requirements under blockchain-based edge computing.Our paper designs a redundant data detection method that meets the privacy protection requirements.By scanning the ciphertext,it is determined whether each submessage of the data in the edge node meets the requirements of the hot data.It has the same effect as zero-knowledge proof,and it will not reveal the privacy of users.In addition,for redundant sub-data that does not meet the requirements of hot data,our paper designs a redundant data deletion scheme that meets the dynamic integrity of the data.We use CES to generate the hot data signature after the redundant data is deleted.CES realized the separation of the hot data part and the redundant data part of the original data and ensure the integrity of the data.By comparing with existing schemes,our scheme takes less time and space to achieve data dynamic integrity verification,and by deleting redundant data in edge nodes,our scheme increases the hit ratio of user requests and ensures the timeliness of response.
ACKNOWLEDGEMENT
The authors would like to thank the reviewers for their detailed reviews and constructive comments,which have helped improve the quality of this paper.This work is sponsored by the National Natural Science Foundation of China under grant number No.62172353,No.62302114,No.U20B2046 and No.62172115.Innovation Fund Program of the Engineering Research Center for Integration and Application of Digital Learning Technology of Ministry of Education No.1331007 and No.1311022.Natural Science Foundation of the Jiangsu Higher Education Institutions Grant No.17KJB520044 and Six Talent Peaks Project in Jiangsu Province No.XYDXX-108.

- China Communications的其它文章
- Space/Air Covert Communications: Potentials,Scenarios,and Key Technologies
- Improved Segmented Belief Propagation List Decoding for Polar Codes with Bit-Flipping
- Scenario Modeling-Aided AP Placement Optimization Method for Indoor Localization and Network Access
- Off-Grid Compressed Channel Estimation with ParallelInterference Cancellation for Millimeter Wave Massive MIMO
- Low-Complexity Reconstruction of Covariance Matrix in Hybrid Uniform Circular Array
- Dynamic Update Scheme of Spectrum Information Based on Spectrum Opportunity Incentive in the Database-Assisted Dynamic Spectrum Management