
基于局部-邻域图信息与注意力机制的会话推荐
2024-03-21 01:49党伟超吴非凡高改梅刘春霞白尚旺
计算机工程与设计 2024年3期
党伟超,吴非凡,高改梅,刘春霞,白尚旺
(太原科技大学 计算机科学与技术学院,山西 太原 030024)
0 引 言
互联网技术的发展给人类生活带来了极大的便利,同时也让数字信息以指数级的规模增长。用户在获取其感兴趣的内容时遇到了阻碍。为解决大数据带来的信息过载问题,推荐系统应运而生。推荐系统在许多应用场景(例如电子商务、音乐和新闻)中可以帮助用户做出高效的选择[1]。传统的推荐系统大多是基于用户的配置文件、长期的交互历史完成推荐。但在许多场景下,用户的身份可能是未知的,历史交互信息只表示了用户的一般偏好,并且用户的短期偏好会随时间推移产生变化[2],而基于会话的推荐系统可以通过会话序列数据,捕获短期且动态的用户偏好,有效地解决上述问题。“会话”是指在一定时间内用户浏览网站发生的一系列交互行为[3]。会话数据所涉及的时间段往往较短,在一定程度上反映了用户短期的、动态的兴趣偏好。会话推荐系统是根据匿名用户会话序列中的先前行为来预测他的未来行为,如下一次点击[4]。以往的会话推荐大多是基于当前会话内有限的序列信息,例如用户的历史行为和基本信息。但除此之外,推荐系统还可以结合其它的辅助信息来优化预测结果,例如结合相似用户的偏好信息,可以提供更精确的推荐;结合当前用户上下文信息,可以帮助推荐系统更好地理解用户需求。总之,引入辅助信息,推荐系统可以准确分析用户的内在需求,提供更具相关性内容的推荐。然而,如何有效地整合和分析这些辅助信息,仍然是会话推荐中的一个挑战。
近年来,基于图神经网络(graph neural network,GNN)的方法因其具有探索结构信息的特点,成为了推荐系统中较受欢迎的方法。但许多方法仅关注当前会话中的项目转换信息,并未考虑邻域会话包含的协作信息。单个会话构建的会话图包含的节点和边较少,在建模不同会话间的项目转换方面存在缺陷。引入邻域会话可以辅助预测用户的未来行为,提高推荐精度。另外,不同的目标项与会话内的项目有不同的相关性。在预测特定的目标项目时,不需要将用户的所有兴趣嵌入到一个向量中,而是要有针对性地激活用户的真实兴趣,从而提高推荐的准确率。因此,本文提出基于局部-邻域图信息与注意力机制的会话推荐模型,称为SR-LNG-AM(session recommendation based on local-neighborhood graph information and attention mecha-nism),主要贡献如下:
(1)模型从当前会话和邻域会话两个角度构建会话图,使用简化图卷积神经网络(simple graph convolutional network,SGCN)学习项目转换特征,并融合两种类型的项目嵌入,得到最终的项目表示。
(2)使用软注意力机制为会话序列中的项目赋予不同的权重,聚焦更为关键的信息;同时使用目标感知注意力,对用户兴趣和目标的建模,根据用户的目标调整推荐策略,优化会话表示,提供更加满足用户需求的推荐结果。
1 相关工作
1.1 传统的会话推荐方法
在会话推荐中,传统的方法有基于项目的邻域方法[5]和基于马尔可夫链的序列方法[6]。基于项目的邻域方法根据项目的相似性矩阵来完成推荐,该方法忽略了项目的顺序且仅依据最后的点击项。基于马尔可夫链(Markov chains,MC)的方法强调了相邻项目序列之间的连续性[7],利用用户的上一操作预测其下一操作,但无法捕捉长期偏好。Zhan等[8]提出序列感知因子化混合相似性模型S-FMSM,对一般表示和顺序表示建模,并利用两个连续项目间的一般相似性优化顺序表示学习。
1.2 基于深度学习的会话推荐方法
深度学习技术拥有强大的序列数据建模能力,推荐系统因此迎来了深度学习浪潮[9]。例如基于循环神经网络(RNN)的方法在推荐系统取得了不错的效果。Hidasi等[10]提出了基于RNN的模型GRU4Rec,使用门控循环单元对短期偏好进行建模。Li等[11]提出NARM模型,使用RNN结合注意力网络来捕获用户的长短期偏好,为其赋予不同权重。Liu等[12]提出了一种短期记忆优先的模型STAMP,将一般兴趣和当前兴趣结合建模,用最后一次点击反映当前兴趣,强调了最后一次点击的重要性。但上述RNN模型仅能捕获连续项目之间的单向转换,忽略了同一会话中跨项目之间的上下文信息。Wang等[13]提出基于协作信息的推荐模型CSRM,使用上下文感知会话图提取跨会话信息。
近年来,图神经网络被广泛应用到会话推荐领域。图神经网络可以对项目间的复杂转换关系建模,在探索结构化信息方面有很大的优势。Wu等[14]提出SR-GNN模型,将会话序列建模为图结构化的数据,采用门控图神经网络(gated graph neural network,GGNN)捕获节点间的复杂依赖信息,并结合注意力机制区分用户短期偏好和长期偏好。Xu等[15]提出GC-SAN模型,将自注意力机制结合GGNN捕获相邻项间的局部转换信息和全局依赖关系。Yu等[16]提出TAGNN模型,在SR-GNN的基础上结合目标感知注意力,将目标项的特征集成到会话表示。Yang等[17]提出需求感知的图神经网络,使用全局需求矩阵结合图神经网络,捕捉商品之间的关系和用户的需求,提高了推荐的准确性。Li等[18]提出因子级的项目嵌入,使用注意力机制来捕获用户对不同因素的偏好,探索用户更细粒度的兴趣。
2 模型结构
为了充分利用会话上下文信息来生成准确的兴趣向量,模型将邻域会话作辅助信息,优化项目表示。即在当前会话类型的基础上,引入了邻域类型的会话。另外,在会话表示层,使用注意力机制优化会话表示的过程,从而预测用户行为。模型的架构如图1所示,主要包括4个部分:

图1 SR-LNG-AM的模型结构
(1)图神经网络,模型使用简化图卷积网络(simple graph convolution network,SGCN)分别从当前会话和邻域会话两个角度捕获项目转换信息,得到当前会话和邻域会话的项目嵌入。
(2)卷积融合,将两种类型的项目嵌入融合为最终的项目表示。
(3)注意力机制,通过软注意力机制生成全局嵌入向量,目标注意力机制生成目标嵌入向量。
(4)预测,将局部嵌入、全局嵌入及目标嵌入线性组合得到会话嵌入,再与节点的初始嵌入计算每个候选项的概率,预测下一个点击项。
2.1 问题描述

2.2 构建会话图模块
会话图是由当前会话s和邻域会话集Ns构建的,其中,Ns是由与当前会话s最相似的r个先前会话组成,而相似度是依据会话之间重复项的数量来计算。邻域会话的提取如图2所示,首先计算先前会话和当前会话的余弦相似度,相似度大于0.5的会话满足相似条件,之后再按照相似度降序排列,对Top-R个会话进行采样以构成邻域会话集Ns。

图2 邻域会话提取过程
在完成邻域会话的提取后,将当前会话s及其邻域会话Ns构建为会话图Gs,如图3所示。其中每个节点表示出现在会话s中或邻域会话集Ns中的项目。每条边 (vi,vj) 表示在会话s或Ns中的任何邻域会话中,用户点击项目vi之后又点击了项目vj。另外,Vs表示当前会话s中所包含的项目集,VNs表示邻域会话集Ns中包含的项目集。

图3 构建会话图
2.3 项目嵌入模块
图神经网络在处理结构数据和探索结构信息时有很大的优势。它采用嵌入传播来迭代聚合邻域信息,依据图神经网络的消息传递结构可以将项目转换信号编码到项目嵌入[9]。在图结构中,每个节点聚合其相邻项节点传递的消息。
构建的会话图是由当前会话s和邻域会话Ns的项目节点构建的,它们分别反映了用户的当前行为和全局协作信息,会对推荐结果产生不同的影响。因此,提取这两种类型的相邻项节点信息时应分开考虑。对于当前会话类型,仅聚合来自Vs中的相邻项节点的消息;对于邻域会话类型,仅聚合来自VNs中的相邻项节点的消息。当前会话和邻域会话都使用简化图卷积网络(SGCN)捕获会话图上的项目嵌入。SGCN在GCN的基础上消除了非线性,并折叠权重矩阵,只有相邻的嵌入传播到下一层,项目嵌入的更新过程如下
(1)
(2)


(3)
(4)
其中,Mi∈R2×d两种项目嵌入的串联,ck∈R1×d是滤波器的卷积结果。
2.4 目标嵌入模块
目标嵌入的构造是为了综合考虑与目标项目相关的历史行为信息,并将其用于预测候选项。其中,目标项也指所预测的候选项。对于目标项而言,用户在会话内的点击序列通常只符合其兴趣的一部分,需要有针对性地激活与目标项相关的用户兴趣。因此,目标注意力机制考虑了每个项目相对于目标项目的重要性,而不是仅计算它们的注意力权重。目标嵌入可以更准确地捕捉到每个项目与目标项目之间的关联程度,使得推荐系统可以更有针对性地关注相关的项目。目标注意力的公式为
(5)
式中:Wt∈Rd×d为可训练的参数,m表示所有会话中项目集合的大小,vt为目标项目。
最后,对于每个会话,用户对于目标项的兴趣表示为starget∈Rd×d,目标嵌入会随着目标项的不同而不同,其公式为
(6)
2.5 会话嵌入模块

(7)
(8)
其中,W1,W2∈Rd×d,q,b∈Rd×d均为可训练的参数;σ(·) 表示sigmoid函数。
最后,对局部嵌入、全局嵌入和目标嵌入串联进行线性变换,生成的最终的会话嵌入
s*=W3[starget;slocal;sglobal]
(9)
式中:W3∈Rd×3d为可训练的参数矩阵。
2.6 预测模块

(10)
(11)
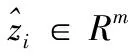
在训练过程中,采用交叉熵作为损失函数
(12)
式中:yi表示真实交互项目的one-hot向量。
3 实验与分析
3.1 数据集及预处理
本文的实验数据来自于推荐系统研究的常用数据集:Yoochoose数据集、Diginetica数据集。这两个数据集都是实际电子商务应用场景中收集的真实数据,包含了用户的点击和购买数据。另外Diginetica数据集还包含了产品的属性信息,如类别、描述等。为了公平地进行比较,本文按照文献[15]中数据集的预处理方式。具体来说,对于所有的数据集,过滤掉缺乏足够信息的会话及难以准确为用户推荐的项目,即长度为1的会话和在整个数据集中仅出现少于5次的项目。另外,删除了仅在测试集中与用户进行交互的项目,以确保模型在推荐过程中具有可靠性和准确性。表1中训练集会话数和测试集会话数的值表示增强后的样本数量。由于Yoochoose数据量庞大,实验只使用Yoochoose训练序列中最近的1/64。预处理后的数据集统计见表1。

表1 预处理后的数据集统计
3.2 评价指标
本文采用召回率(Recall)和平均倒数排名(mean reciprocal ranks,MRR)评估提出的模型的性能,指标的详细定义请参见文献[15]和文献[20]。Recall@N是正确推荐项占实际点击项的分数,MRR@N是衡量正确推荐项在推荐列表中的排名。
3.3 参数设置

3.4 相关方法比较与分析
为了验证本文所提模型SR-LNG-AM的优越性,在上述两个数据集下进行实验,并用以下几种基线模型进行对比分析:
(1)POP(popularity):根据物品在会话中的频率进行推荐,推荐的物品集中在与用户交互次数较多的项目上。
(2)Item-KNN[5](item based K-nearest neighbor):将两个物品在不同会话中共现的次数构建成项目间的相关性矩阵,以此度量项目之间的相似度,并使用K最近邻算法来为用户推荐项目。
(3)FPMC[19](factorizing personalized Markov chains):通过矩阵分解和马尔科夫链分别学习项目转换模式及顺序行为,以此预测用户的下一个行为。
(4)NARM[11]:采用RNN结合注意力机制,将顺序性和用户的总体偏好融合,捕获用户的主要兴趣。
(5)STAMP[12]:对最后一次点击所反映的当前兴趣进行建模,将当前兴趣和一般兴趣结合的同时突出了当前兴趣的重要性。
(6)CSRM[13]:将跨会话信息应用到推荐任务,构建了时序卷积网络模型,并通过会话相似性来优化会话表示。
(7)SR-GNN[14]:将会话信息视为一个会话图,通过GGNN对图中节点进行特征提取,并使用注意力机制捕获用户的长期兴趣。
(8)GC-SAN[15]:把普通的注意力机制改进为自注意力机制,并通过自注意力机制来考虑项目间的全局依赖关系。
(9)TAGNN[16]:使用目标感知注意力生成目标嵌入,并集成到会话嵌入。
与其它9个基准方法相比,本文所提出的模型SR-LNG-AM同样具有较好的表现。具体实验结果见表2,其中,加粗的字体为本文模型的实验结果。从表中可以观察到。
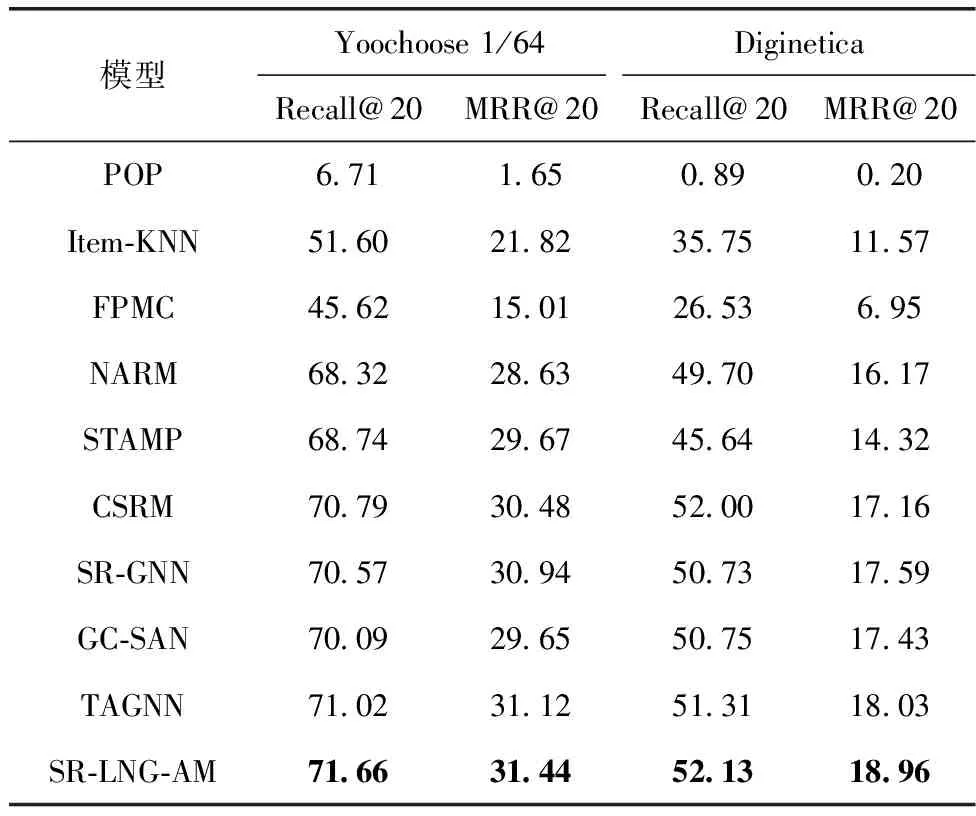
表2 不同模型在公开数据集下的性能对比
(1)在所有推荐模型中,POP只根据项目的频率来完成推荐,性能表现最差。Item-KNN考虑了项目之间的相似度,提高了推荐准确率。FPMC采用矩阵分解和马尔科夫链提升推荐结果。但传统的推荐方法忽略了项目的顺序性,在捕获项目转换信息方面存在缺陷。
(2)所有基于神经网络的推荐方法都优于其它传统的推荐方法。其中,基于注意力机制NARM和STAMP的性能明显提高,表明了深度学习可以挖掘出用户的潜在偏好,以及注意力机制可以聚焦于推荐任务中更为关键的信息。CSRM虽然考虑了多个会话之间的协作信息,提高了模型性能,但未能准确模拟出会话间的复杂项目转换。SR-GNN和GC-SAN使用图神经网络学习图节点的特征表示,从而捕获用户偏好,取得了不错的效果,体现图神经网络强大的特征提取和学习能力。TAGNN在SR-GNN基础上结合了目标感知注意力,优化了会话表示。
(3)本文所提模型在数据集的各项指标上比其它基准模型表现更好,验证了引入邻域会话可以增加会话上下文信息,为模型输入更多特征,辅助预测;另外使用目标注意力机制对目标相关性信息进行提取,验证了局部-邻域图模型与注意力机制结合的有效性,体现了SR-LNG-AM的优越性。
3.5 不同注意力机制比较与分析
SR-LNG-AM在会话表示层使用注意力机制优化了会话表示,以下实验比较了不同注意力机制下对会话嵌入的影响:
(1)普通注意力机制模型(AM-Soft):使用软注意力机制生成全局嵌入,再融合局部嵌入得到会话表示。
(2)自注意力机制模型(AM-Self):使用自注意力机制生成全局嵌入,再融合局部嵌入得到会话表示。
(3)自注意力机制结合目标注意力机制(AM-Self-Target):使用自注意力生成全局嵌入,使用目标注意力生成目标嵌入,再融合局部嵌入得到会话表示。
实验结果见表3,从AM-Soft与AM-Self对比可以看出软注意力机制在本文实验环境下捕获项目间全局依赖关系时比自注意力机制更适用;AM-Self-Target在自注意力机制的基础上,引入目标感知注意力,提高了推荐准确率,这验证了引入目标感知注意力可以根据目标项有针对性地激活用户兴趣,优化会话表示。SR-LNG-AM使用软注意力机制捕获项目的全局依赖关系,使用目标感知注意力生成目标嵌入,在实验过程中得到了最优的结果,表明了模型结合软注意力机制和目标注意力机制的有效性。

表3 不同注意力机制下模型的表现
3.6 不同邻域数量比较与分析
邻域会话包含了丰富的协作信息,通过相似用户的行为信息,辅助模型为当前用户生成更准确的推荐列表。引入邻域会话虽然可以扩大信息范围,增加会话上下文信息,但也会导致更多噪音。因此,本文设计了不同邻域会话数量的对比实验,以研究邻域会话数量对模型性能的影响。
从图4中可以观察到,当邻域数量为0时,即不引入邻域会话,模型的性能最低。在引入了邻域会话之后,模型的性能首先随着邻域数量的增加而提高,表明了邻域会话的协作信息的有效性。随后,在Yoochoose 1/64上邻域数量为120时模型指标达到最高;在Diginetica上邻域数量为100时模型指标达到最高。之后,指标开始下降,原因可能是由于会话相似度会随着邻域数量的增加而降低,相似度较低的会话引入了越来越多的噪声,导致捕获的项目转换关系不够准确。因此,合理利于邻域会话可以为模型提供补充信息,提高预测能力。

图4 不同邻域数量下的性能对比
4 结束语
为解决会话推荐问题中对会话上下文信息利用不足的问题,本文提出了基于局部-邻域图信息与注意力机制的会话推荐模型。模型通过当前会话来提取相似的邻域会话,将两种类型的会话序列构建成会话图,从两个角度提取项目转换信息,并融合成最终的项目表示;之后使用软注意力机制生成全局嵌入,使用目标注意力机制生成目标嵌入,并结合局部嵌入得到会话表示,在此基础上进行推荐。本文基于两个真实数据集进行实验,提高了各项指标,验证了邻域会话信息对推荐的辅助作用以及目标注意力机制对会话表示的优化作用。会话推荐的辅助信息除邻域会话外,还包括会话内项目的停留时间,停留时间往往隐含了用户的兴趣变化。在之后的研究工作中,通过分析用户历史行为数据中的时间间隔和用户在不同时间段的行为变化,模拟用户的兴趣演化过程,准确捕获用户兴趣,以进一步提升推荐准确性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
吉林大学学报(理学版)(2020年3期)2020-05-29
自动化学报(2018年7期)2018-08-20
传媒评论(2017年3期)2017-06-13
疯狂英语(双语世界)(2017年4期)2017-04-28
海外华文教育(2016年3期)2017-01-20
第二课堂(课外活动版)(2016年2期)2016-10-21
周口师范学院学报(2016年5期)2016-10-17
华东理工大学学报(自然科学版)(2014年2期)2014-02-27
山西大同大学学报(社会科学版)(2014年5期)2014-01-23
