
基于注意力机制的多尺度融合人群计数算法
2024-03-21 08:15谢新林尹东旭张涛源谢刚
计算机工程 2024年3期
谢新林,尹东旭,张涛源,谢刚
(1.太原科技大学电子信息工程学院,山西 太原 030024;2.太原科技大学先进控制与装备智能化山西省重点实验室,山西 太原 030024)
0 引言
人群计数任务可以为人群监督提供技术支持,减少或避免因人员聚集而引发安全事故,因此在体育馆、音乐会、集会等人群密集场所的应用越来越广泛。然而,在现实场景中因摄像机透视效应引起的人头尺度变化大和复杂场景下背景噪声高,使得不同场景下人群计数任务面临巨大挑战。在人群计数的早期研究中主要使用基于检测[1]和回归[2]的方法,但是当遇到高度拥挤的场景图像时,该方法无法提取足够的人群特征,计数精度较低。鉴于强大的深度特征表达能力,基于卷积神经网络(CNN)的人群计数算法被广泛提出,但仍存在多尺度信息提取不足、背景噪声区分错误率高的问题。
为有效应对人头尺度变化大的问题,现有人群计数算法通常引入多尺度特征融合模块来学习不同感受野大小的特征[3-5]。许多早期方法使用多列架构网络来处理大规模变化问题[6]。例如,文献[7]构建一种多列卷积神经网络,该网络由具有不同感受野大小的3 个分支组成。但是,该方法因多分支网络的引入,导致计算量增加、训练效率降低。因此,一些改进方法尝试将高级语义信息和上下文信息融合到深度网络中[8-10],这些信息有助于网络理解拥挤人群特征。其中,文献[11]搭建一种基于分组卷积的多通道融合结构,但该方法不能有效聚合上下文信息。文献[12]设计一种以VGG16 为前端、扩张卷积为后端的网络,用于提取具有更大感受野的特征,但不能有效融合深层和浅层信息。文献[13]提出一种规模聚合网络,采用不同大小的卷积核提取多尺度特征,但大卷积核容易造成计算量增大,且在整个图像中只采用卷积操作来获得多尺度特征,易导致网络丢失部分全局信息。文献[14]构建一种反馈网络,并在网络中使用空洞空间金字塔模块聚合上下文信息,但是该卷积操作易造成原始特征图中的空间细节信息丢失。然而,上述方法无法捕获足够的全局上下文信息,且在像素之间未建立全局关系,易通过卷积操作使网络丢失原始特征图的空间细节信息[15]。
针对拥挤场景下背景噪声高的问题,现有人群计数算法通常引入注意力机制对人头特征进行加权[16-18]。文献[19]构建一种双路径网络架构,并使用注意力图优化密度图,但所提注意力图只关注特征图的空间位置信息,忽略通道类别信息。为此,文献[20]介绍一种通道注意力模块对通道特征重新校准以充分学习通道类别信息,但该方法忽略了空间位置信息。文献[21]基于卷积和池化操作提出一种空间和通道融合的混合注意力网络,同时关注空间和通道信息,但由于卷积和池化操作只能使用局部信息进行加权,因此丢失了部分像素信息,使网络无法充分利用每个特征像素信息进行加权。尽管基于注意力的人群计数方法针对当前或先前层的特征,利用激活函数生成权重图加权空间信息,以消除背景噪声。
本文提出一种基于注意力机制的多尺度融合人群计数算法AMFNet。该算法能融合不同层不同尺度大小的特征信息来解决人头尺度变化大的问题,并通过像素级注意力机制对图片的通道和空间信息进行像素加权融合来处理拥挤场景下背景噪声高的问题。本文设计基于残差连接的空洞空间金字塔池化(ASPP-R),通过多分支卷积捕获多尺度头部目标特征的同时使用残差连接保留原特征图的空间细节信息;构建跨层多尺度特征融合模块融合深层和浅层的多尺度特征,并构建基于多分支的特征融合模块(FFS-MB)融合当前层不同感受野大小的特征信息。设计基于像素级特征的空间和通道注意力机制模块(AM-CS),通过矩阵相似性运算使网络提取像素级特征对空间和通道信息进行加权融合。
1 本文网络
针对现有人群计数方法头部尺度变化大以及背景噪声复杂的问题,本文提出一种基于注意力机制的多尺度融合人群计数网络。所提方法由3 个主要部分组成:基于残差连接的空洞空间金字塔池化、基于多分支的特征融合结构和通道、空间注意力机制模块。
1.1 基于残差连接的空洞空间金字塔池化
为提高网络对于多尺度头部目标的学习能力,本文构建基于残差连接的空洞空间金字塔池化,通过设计残差结构以及多个不同扩张率的空洞卷积捕获多尺度的头部目标特征。图1 所示为ASPP-R 模块结构。

图1 基于残差连接的空洞空间金字塔池化结构Fig.1 Structure of atrous spatial pyramid pooling based on residual connection
首先,针对输入特征信息,使用1×1 卷积将特征图的通道维度从512 降低为128,其目的在于减少模型的参数量。此外,引入批归一化层(BN),以加快网络的训练和收敛速度。
其次,为充分学习不同尺度大小的头部目标,设计扩张率为(1,3,7,13)的并行3×3 卷积。全局平均池化分支能够保留图像的全局上下文信息,为恢复输入特征的空间大小,引入双线性插值的方式进行上采样。此外,为了避免空洞卷积和全局平均池化造成信息丢失,引入残差连接保留输入特征的空间细节信息。
最后,为融合多尺度目标信息、全局上下文信息、输入特征信息,将多分支信息以通道拼接的方式进行融合。此外,为进一步减少计算量,本文设计1×1 卷积压缩通道维度从640 降低至512。
1.2 基于多分支的特征融合模块
特征融合模块通过融合低级与高级信息来增强不同尺度的特征表达,浅层网络具有较强的细节信息学习能力,有利于高度拥挤场景的人群计数,深层网络具有较强的语义信息学习能力,有利于区分人头、树叶、建筑物等复杂背景。因此,本文构建基于多分支的特征融合模块(FFS-MB)结构,其特点是设计不同感受野大小具有丰富特征信息的分支结构。图2 所示为FFS-MB 模块结构。
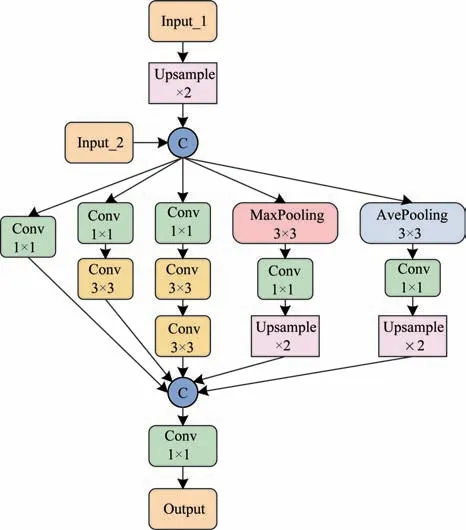
图2 基于多分支的特征融合模块结构Fig.2 Feature fusion module structure based on multi-branch
首先,融合主干网络相邻层级的特征信息。Input_1 为主干网络第n层的特征信息,Input_2 为主干网络第n-1 层的特征信息,通过双线性插值方式对Input_1 进行上采样,得到与Input_2 相同空间维度的特征信息。此外,引入通道拼接的方式实现相邻层级特征的初步融合。
其次,构建具有丰富特征信息的多分支结构。多分支结构包含3 个卷积分支和2 个池化分支。其中,1×1 卷积的目的是压缩通道维度信息以减少计算量。卷积的3 个分支结构分别具有不同大小的感受野,Conv 1×1 分支用于保存原始输入的特征信息,Conv 1×1、Conv 3×3 分支的有效感受野为3×3 卷积,Conv 1×1、Conv 3×3、Conv 3×3 分支的有效感受野为5×5 卷积,其特点是能够关注不同尺寸的头部特征。在池化的2 个分支结构中,为了抑制图像中复杂的背景噪声,本文设计MaxPooling 3×3、Conv 1×1 消除冗余信息,此外,为了防止在高度拥挤场景下MaxPooling 导致相似信息丢失,本文设计AvePooling 3×3、Conv 1×1 分支结构。
最后,融合多分支结构的特征信息。Conv 分支和MaxPooling 分支具有相同的通道维度,为了防止目标信息弱化,AvePooling 分支的通道维度为其余分支的1/2,然后以通道拼接的方式融合5 个分支的特征信息。此外,为减少计算量,本文使用1×1 卷积降低通道数为[512,256,128]。
1.3 基于通道与空间的注意力机制模块
为进一步突出图像中的人群区域,本文构建基于通道和空间的注意力机制模块(AM-CS),通过矩阵运算提取每个像素的空间和通道特征进行加权,分别用于加强网络对于背景和人头目标的辨别能力、自适应矫正位置信息。图3 所示为构建的AM-CS模块结构。
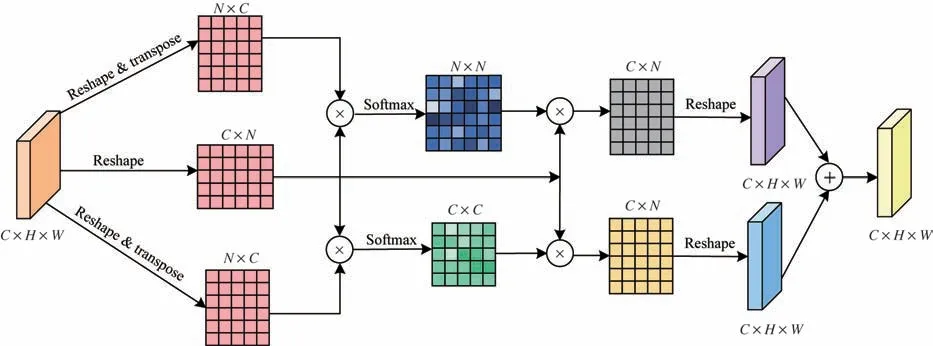
图3 基于通道与空间的注意力机制模块结构Fig.3 Attention mechanism module structure based on channel and spatia
首先,分别构建空间和通道注意力模块,对特征信息任意2 个像素之间的空间关系以及特征通道之间的相互依赖关系进行建模。将输入特征X∊RC×H×W重塑为A∊RC×N,其 中,N=H×W。通过AT与A之间的矩阵乘法计算空间相似矩阵,通过A与AT之间的矩阵乘法计算通道相似矩阵。Softmax函数用于生成空间注意力权重Patt∊RN×N及通道注意力权重Qatt∊RC×C,具体计算式如下:
其中:pij表示第i个位置对第j个位置的影响;qij表示第i个通道对第j个通道的影响表示AT的第i行;Aj表示A的第j列。
其次,融合通道和空间注意力机制。通过A与P之间的矩阵乘法计算融合空间注意力的特征信息,通过Q与A之间的矩阵乘法计算融合通道注意力的特征信息,采用逐像素相加的方式获得具有通道和空间注意力的特征信息,其过程如下:
其中:Reshape 将维度大小为C×N的特征信息重塑为C×H×W;Frefine表示注意力机制模块输出的特征信息。
基于注意力机制的多尺度融合人群计数网络结构如图4 所示(彩色效果见《计算机工程》官网HTML版),其中,Stage 1~Stage 4 为VGG16 前10 层的4 个阶段特征图,分别为原图1/2、1/4、1/8、1/16 的大小,Stage 3、Stage 4 为深层分支,Stage 1、Stage 2 为浅层分支。
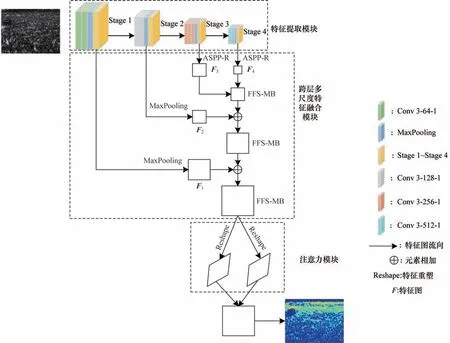
图4 基于注意力机制的多尺度融合网络总体结构Fig.4 Overall structure of multi-scale fusion network based on attention mechanism
2 实验结果与分析
为验证基于注意力机制的多尺度融合人群计数算法的性能,本文首先介绍人群计数数据集ShanghaiTech[7]和UCF_CC_50、评价指 标与实验配置、联合损失函数,然后通过消融实验验证本文所提模块的有效性,最后通过与先进算法进行定量和定性对比分析,验证所提算法的有效性。
2.1 数据集
ShanghaiTech 是目前评估算法模型性能最常用的人群计数数据集,共包含1 198 张带注释的图像,总计330 165 个人。根据人群密度和场景不同分为SHA 和SHB 2 个部分。SHA 是从互联网上下载的不同拥挤场景图像,人群密度更大并存在少量灰度图片,其包含人数从33~3 139 个人不等的300 张训练和182 张测试图片。SHB 是从上海街道拍摄相对稀疏的人群场景图像,且受摄像机视角不同的影响,图片具有人头尺度大小不同的特点,其包含人数从9~578 个人不等的400 张训练和316 张测试图片。
UCF_CC_50[22]是1 个极其拥挤并且训练样本极少的人群计数数据集,该数据集仅包括50 张不同分辨率、视角和光线的图像,包含体育馆、音乐会、集会、马拉松等场景。头部注释的数量从94~4 543 个人不等,平均为1 280 个。受复杂背景和密集人群分布的影响,数据集挑战难度较高。为了更好地评估模型在UCF_CC_50 数据集上的性能,本文设置数据集执行5 倍交叉验证[22],并把5 次实验结果均值作为最终评估结果。
2.2 评价指标与实验配置
本文通过平均绝对误差(MAE)和均方根误差(RMSE)来评估算法模型的计数效果,评价指标定义如下:
其中:N为测试集包含的图像个数;Ci和分别为预测人数和真实人数。MAE 反映计数的准确度,RMSE 反映算 法的鲁棒性。因 此,MAE 和RMSE 值越小表示性能越好。
此外,为了更直观地展示测试图片计数效果,本文采用计数差值(CD)来描述算法测试图片的效果,计算式如下:
本文算法实验配置参数:操作系统Ubuntu20.04;显 卡RTX2080Ti;深度学 习框架PyTorch 1.7.1;数据处理Python 3.8。
本文算法的权重衰减为1×10-4;优化器为Adam;学习率为5×10-4;epoch 设为700,使用高斯核模糊生成真值图DGT,计算式如下:
其中:x为像素在图像中的位置;C为头部注释的数量;参数μ为高斯核大小,μ=15;参数ρ为标准差,ρ=4。
在数据增强过程中,如果图像短边小于512,则先调整为512,使用400×400 像素的图像块在随机位置进行剪裁,使网络进行多批次训练。以概率0.2 将原图更改为灰度图,以概率0.5 随机水平翻转图像。
2.3 联合损失函数
欧氏几何距离损失通过逐像素度量预测密度图和真值密度图的差异,以获得高质量的人群密度图,但是没有针对预测人数进行损失。基于回归人数的损失度量预测人数和真实人数的差异,通过生成与图像真实人数相对应的数量特征信息,提高计数的准确性。为了在生成高质量密度图的同时提高计数的准确性,本文设计一种结合欧氏几何距离损失和基于回归人数损失的联合损失函数,计算式如下:
其中:N表示1 个训练批次中图片的个数;F(Xi;θ)表示人群密度预测图;Xi和θ表示网络学习参数和输入图像 ;D表示人 群密度 真值图 ;表示欧氏距离损失;Ci表示预测人数;C表示真实人数表示基于回归人数的损失;λ为加权比例,本文设置为1。
2.4 消融实验
为验证ASPP-R、FFS-MB、AM-CS 和联合损失函数的有效性,本文仅使用基础模块进行消融实验,将具有1×1、3×3、3×3、3×3 和ImagePooling 分支,扩张率为[1,6,12,18]的ASPP 结构作为基础ASPP 模块并用A 表示,将具有1×1、3×3、5×5、7×7 的多分支作为基础特征融合模块并用F 表示,基础损失函数为欧氏几何距离损失。
消融实验结果如表1 所示。相比Backbone+A+F,在基础网络Backbone 后接注意力机制AM-CS(Backbone+A+F+AM-CS)的MAE 和RMSE 分别降低1.4%和1.8%。相比Backbone+A+F+AM-CS,将基础模块A 和F 替换成本文所提的ASPP-R 和FFS-MB 后(Backbone+ASPP-R+FFS-MB+AM-CS),MAE 和RMSE 分别降低1.4%和3.1%。把基础网络使用的欧氏几何距离损失替换成本文所提的联合损失函数后,MAE 和RMSE 分别降低0.3%和0.1%。由此证明本文所提的ASPP-R、FFS-MB、AM-CS 模块、联合损失函数均能有效提高网络计数性能和鲁棒性。

表1 消融实验结果Table 1 Ablation experimental results
为验证AM-CS模块的有效性,本文对所提AM-CS与空间注意力模块[8](SAM)和SE通道注意力模块[20](SECAM)进行对 比实验,实验结果如表2 所示,加粗表示最优数据。
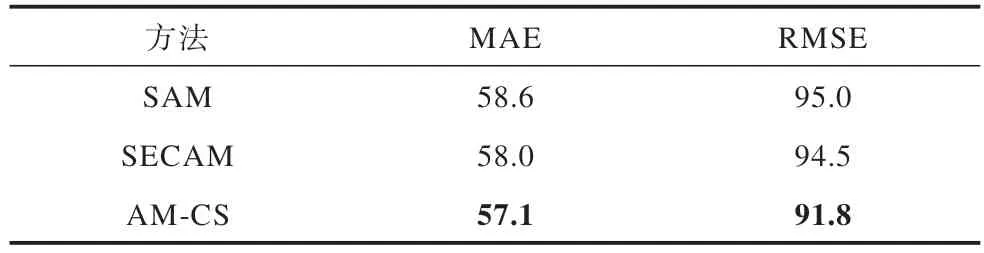
表2 基于注意力机制模块的对比结果Table 2 Comparison results based on attention mechanism modules
从表2 可以看出,本文所提AM-CS 模块相比SAM 模块,MAE 和RMSE 分别降低2.6%和3.4%,所提AM-CS 模块与SECAM 模块相比,MAE 和RMSE分别降低1.6%和2.9%。因此,本文所提AM-CS 模块的性能优于基于空间和基于通道的注意力模块。
2.5 实验结果
2.5.1 定量分析与比较
考虑到UCF_CC_50 数据集的数据量较小,本文使用基于SHA 数据集上预训练的模型进行网络训练。表3 所示为AMFNet 网络与近5 年先进方法在ShanghaiTech 和UCF_CC_50 数据集上的对比结果,加粗表示最优数据。
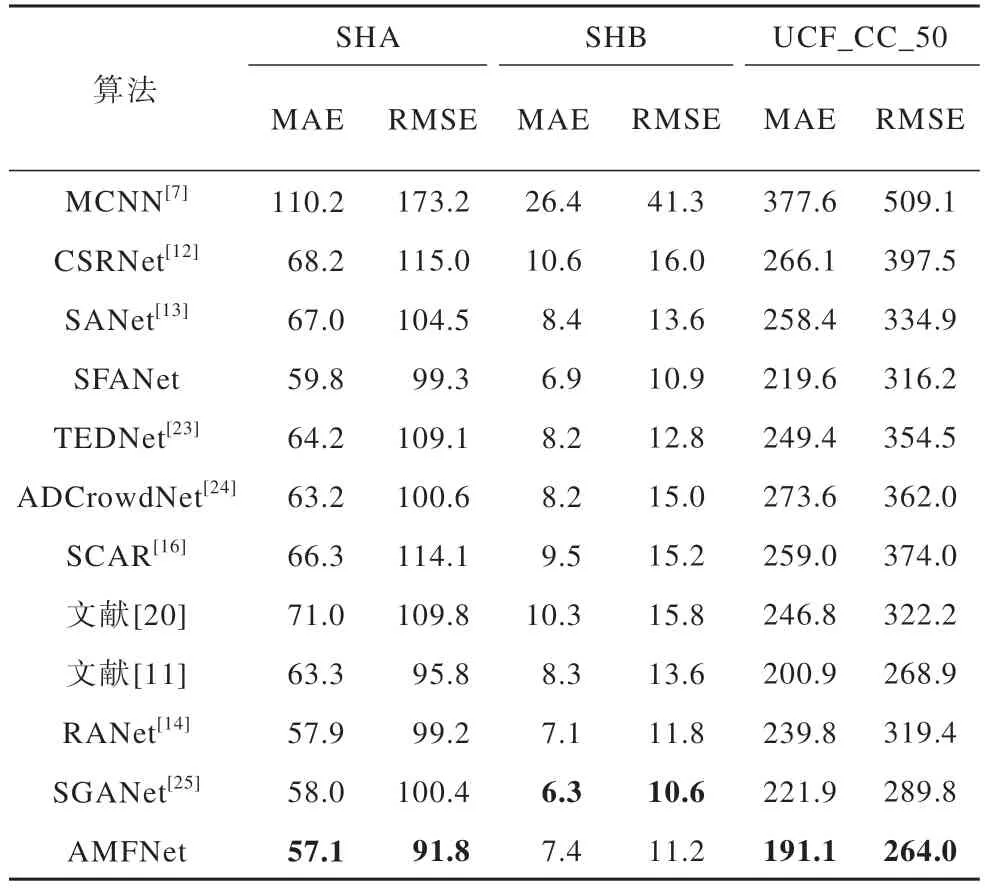
表3 不同算法在ShanghaiTech 和UCF_CC_50 数据集上的实验结果Table 3 Experimental results among different algorithms on ShanghaiTech and UCF_CC_50 datasets
从表3 可以看出,本文算法AMFNet 在更为密集且背景复杂ShanghaiTech 数据集的SHA 部分比其他最好算法MAE 和RMSE 分别降低1.4%和4.2%,证明AMFNet 算法能有效提高存在背景噪声的人群图片计数精确度和鲁棒性。在较为稀疏的SHB 数据集中也取得较小的计数误差,MAE 和RMSE 分别为7.4和11.2,证明网络能有效应对人群图片中因摄像机视角不同而引起人头比例变化较大的问题。SHB 数据集头部尺度变化较小,包含人数密度水平较低,背景简单,本文算法针对头部尺度变化较大且复杂背景干扰构建的跨层多尺度融合模块和注意力模块对SHB 数据集性能提升效果不明显,导致在SHB 数据集上性能不如SGANet,但是仍优于其他对比算法。本文算法在最密集的UCF_CC_50 数据集上比其他最优算法的MAE 和RMSE 分别降低4.9%和1.8%,证明AMFNet 算法在不同密度、背景、光照条件下具有较强的泛化性能。
与采用基础ASPP 来提取多尺度上下文信息和多层特征融合的RANet 相比,本文算法在SHA 和UCF_CC_50 数据集上均取得更小的误差,证明本文所提ASPP-R 模块的有效性。与采用不同大小的滤波器聚合多尺度特征的SANet、TEDNet 相比,本文算法在3 个数据集上均取得最优的效果,证明本文所提FFS-MB 模块可以更充分地融合多尺度特征。与只采用空间注意力机制的SFANet、SGANet 相比,本文算法在SHA 和UCF_CC_50 数据集上均取得更小的误差,验证了本文所提基于矩阵相似度运算的像素级空间通道注意力模块AM-CS 的有效性。
2.5.2 定性分析与比较
为了对所提算法AMFNet 进行定性分析,本文设计AMFNet 与MCNN、CSRNet、SANet、SFANet 网络在ShanghaiTech 和UCF_CC_50 数据集上的对比实验,给出不同对比算法在各数据集图片上测试的计数误差结果以及密度图可视化结果,分别如表4和图5 所示。
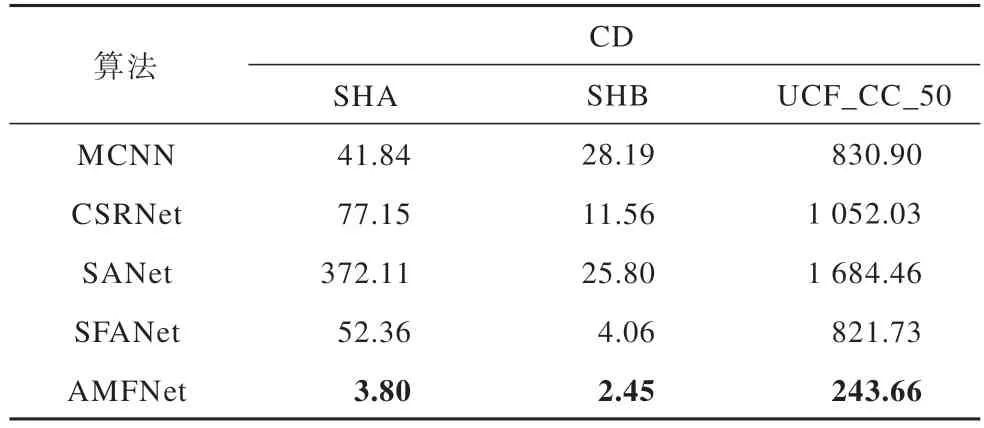
表4 不同对比算法的测试计数误差结果Table 4 Test counting error results among different comparison algorithms

图5 不同对比算法的密度图可视化结果Fig.5 Density map visualization results among different comparison algorithms
从图5 可以看出,由第1 行图可见,SHA 数据集原图中背景十分杂乱,包括椅子、帐篷、汽车、树叶和远处拥挤遮挡的人群,由表4 可知本文算法在SHA数据集上的误差仅为3.80,远小于对比算法中误差最小的SFANet,证明网络通过多尺度注意力图路径能有效抑制复杂的背景噪声。由第2 行图可见,SHB数据集原图中背景较为简单,但是由于摄像机的透视效应,因此出现了较大的人头比例变化。从表4可以看出本文算法的预测误差仅为2.45,小于其他所有对比算法的误差,说明通过多尺度感知模块使网络能有效缓解大规模的人头比例变化问题。由第3 行图可见,UCF_CC_50 数据集原图是极度拥挤密集且缺乏颜色信息的图像,由表4 可知本文算法的计数误差为243.66,是接近第2 小计数误差SFANet 方法的1/4,接近最大计数误差SANet 网络的1/7,表明本文算法对极度密集人群计数十分准确。在3 个不同背景、人群密度、摄像机视角、颜色信息的3 个数据集上,本文算法都能基本达到最优的MAE 和RMSE,具有较优的准确性和鲁棒性,同时还有较好的泛化性。
3 结束语
本文提出一种基于注意力机制的多尺度融合人群计数算法,用于解决人群计数图像人头尺度变化大、高背景噪声的问题。首先,将人群数据集输入到由基于VGG16 前10 层构建的特征提取模块,用于提取Stage 1~Stage 4 的浅层和深层信息;然后,通过基于残差连接的空洞空间金字塔池化和深层分支、浅层分支融合不同层的多尺度上下文语义信息;最后,通过注意力机制模块加强网络对于背景和人头目标的判别能力。在ShanghaiTech 和UCF_CC_50 数据集上的实验结果表明,本文算法具有较优的准确性和稳定性,并具有较优的泛化性。由于单视角图片包含拥挤场景下图片信息较少,因此下一步将对多视角人群计数方法进行研究,以提高算法在复杂场景下的计数准确性。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
数学小灵通(1-2年级)(2021年11期)2021-12-02
中等数学(2020年8期)2020-11-26
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
小学生学习指导(低年级)(2020年4期)2020-06-02
数学小灵通·3-4年级(2017年11期)2017-11-29
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
时代英语·高三(2014年5期)2014-08-26
