
基于链表管理的PCIe 交换机动态缓存技术
2024-02-27 12:17王周祝红彬高昌垒
电子设计工程 2024年3期
王周,祝红彬,朱 喜,高昌垒
(深圳市国微电子有限公司,广东深圳 518000)
多设备之间的互联与信息交互通常使用交换机[1-3]来进行处理。三代PCIe 交换机[4]单端口带宽在其16 条lane 时可达100 GT/s 以上[5-6],所以需要较大缓存空间进行数据存储转发[7]。缓存的快速消耗造成拥塞[8]通常是端口之间速率/带宽的不同造成[9]。现有交换机通常为各端口分配固定缓存,确保一定转发带宽,同时设置共享缓存空间,当某端口缓存不足时使用,但端口不使能时,预先分配的固定缓存就造成了浪费。
针对此,提出一种基于链表管理的PCIe 交换机动态缓存技术,能够实时监测PCIe 交换机有效端口的使能情况,动态地将未使能端口缓存空间链接到活跃端口,并通过空闲链表RAM 和链表节点来管理新组链的缓存区,缓存利用率可达100%。同时取消了传统共享缓存空间,在满足交换机功能和性能的同时有效节省芯片面积。
1 PCIe交换机缓存结构
该研究中PCIe 交换机共设有12 条x4 lane 的PHY,分为3 组,每组称为一个Station。每个Station有4 个x4 lane 的PHY,共16 个物理lane[10],可用来设置逻辑端口,即每个Station 最多可设置4 个逻辑端口,逻辑端口lane 数可配置范围为x16/x8/x4[11-12]。
Station 内第一个端口Port0 固定连接x16-controller,第二个端口Port1 连接x8-controller,第三个端口Port2 和第四个端口Port3 均连接x4-controller。端口lane 配置组合如表1 所示。

表1 交换机的端口配置
输入输出侧缓存模块均设置有缓存RAM,完成报文Header 和Data 的写入和读出。缓存结构如图1所示。
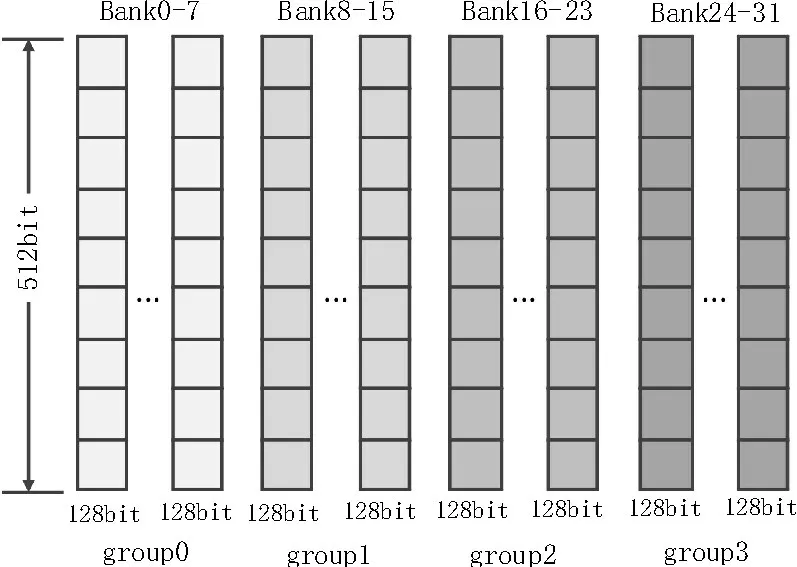
图1 缓存结构
考虑到线速要求和Station 内的调度策略,存储策略缓存采用半共享的方式,以128 bit 为单位[13]存储数据和包头(Header)。缓存空间根据端口lane 配置来分配4 个group 内的空闲地址,原则上不能出现读写冲突,并保证缓存的利用率。
group 内的缓存编址范围为0~511,每个地址对应8 个128 bit 的存储单元,称为slice,即每个地址对应4 个物理block。报文存储过程中,每个地址的8个slice 可以存储不同报文的128 bit 数据或者Header,以充分利用缓存,同一个地址的4 个物理block 只能存储一个队列的报文。
2 动态缓存池队列及链表管理
2.1 队列设计方案
PCIe 根据数据包类型Type 将报文分为三类:P、NP、CPL。不同类型的报文之间存在调度与仲裁,所以缓存管理时需要按报文类型,将同一类报文存储在相同的缓存池内。该设计中输入侧缓存与输出侧缓存链表管理共享同一个模块,但队列数量不同。
输入侧:
单播队列:{端口、目的端口、P/NP/CPL}
多播队列:{端口、P}
输出侧:
单播队列:{端口、P/NP/CPL}
多播队列:无
输入侧队列链表管理:队列链表根据报文类型和入端口、输出端口入队;空闲链表管理给出空闲地址,空闲链表收到报文输入有效标识即给出空闲地址,报文写入之后,根据报文路由结果将空闲地址添加到对应的队列链表的tail即可。
输出侧队列链表管理:空闲链表向输出buff 和报文描述符(PD)缓存提供写入地址,根据输入侧给出的源端口和目的端口信息,将空闲地址添加到对应的输出侧队列链表tail。管理输出侧队列,接收来自输出侧排序和调度的结果,给出出队队列的首地址,输出buff 将首地址作为读地址读出报文数据,转发给出片处理模块。
2.2 链表管理设计
链表管理模块(QM)设置为通用的链表管理,并进行参数化设置,由空闲链表RAM 和链表节点RAM组成,链表节点RAM 放在QM 模块外,空闲链表管理模块放在链表管理模块内部。但是本质上链表节点RAM 也属于链表管理的一部分,如图2 空闲链表RAM 存储空闲地址,空闲链表管理模块管理空闲地址的分配和回收;链表节点RAM 存储队列的节点,存储虚拟输出队列(VOQ)中各个队列的节点地址。链表管理模块为输入侧和输出侧共用模块,参数化传参。

图2 链表管理的RAM
空闲地址管理分为两组,以应对VOQ 队列释放2 个地址的场景。报文输入申请地址时,将FIFO的第一个数据弹出,轮流取两个FIFO 的空闲地址;当报文出队后地址释放时,空闲地址轮流写入2 个空闲地址FIFO;当VOQ 队尾报文出队,需要释放2 个地址时,将2 个地址分别写入2 个FIFO。空闲地址FIFO 共15 个,均为预取FIFO(pre-fetch)。链表节点RAM 中实际存储的地址是PD 存储的地址,与数据存储(DM)中数据的存储首单元地址对应,经过映射后得到DM 存储地址。PD 在进行报文调度的时候,每个队列会有4 个首PD 直接写入排序与分类模块,队列选中之后,向队列链表管理模块读取下一跳PD;队列为空时,PD 直接写入分类模块。
交换机初始化后读取端口配置信息,当存在非活跃端口时,链表管理模块会将非活跃端口的RAM纳入活跃端口的RAM 列表,动态的扩展活跃端口的缓存池,使其能够有较大的缓存空间用于流控交互和数据包缓存转发。
在各种lane 通道数配置组合里,Station 内与4 个端口对应的缓存group 根据端口和lane 配置实际组合分配地址,group 内缓存地址分配如表2 所示。

表2 group内缓存地址分配
3 验证与综合
对该设 计基于SV(System Verilog)的UVM 验证方法学搭建Module 级和System 级验证平台;使用SVA 进行形式验证或协议检查;使用covergroup进行功能覆盖率收集。EDA 整体验证流程如图3所示。
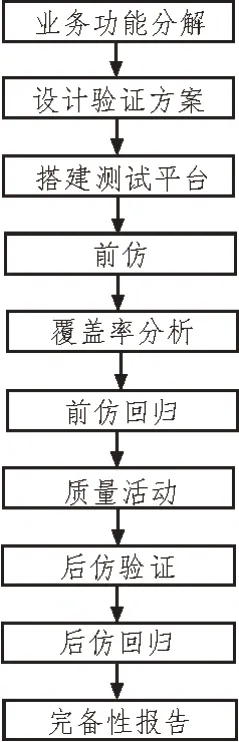
图3 验证流程
验证的lane 覆盖率、FSM 覆盖率、条件覆盖率均可达100%。在质量活动阶段进行功能点分解和TestCase 的反标,做各种专项检查。后仿验证阶段对PR 后的设计网标进行时序反标后的功能和时序验证。不同的工艺角最佳、最差时序下均验证通过,功能与性能满足需求。
同时在对该设计进行EDA 测试过程中FPGA 原型验证会同步开展,对功能设计做进一步验证。
在插入DFT 扫描链和MBIST 之后,根据后端提供的def 文件进行DCG 综合,分析优化时序,使时序收敛。后端也可以通过插buff 的方式优化时序,或者更换低阈值Cell 等方式进一步使时序收敛。对模块进行时序分析、一致性检查以及COT 等检查,均能满足项目要求。
4 仿真结果分析
该文研究的基于链表管理的PCIe 交换机动态缓存技术采用SMIC 40 nm 工艺,使用SYNOPSYS 仿真工具进行仿真验证。
配置交换机3 个Station 的端口,Station0 内仅端口0 有效为x16 端口,Station1 内为3 个端口有效分别为x8、x4、x4,Station2 内为4 个端口全部有效为全x4的端口。
Station1 内端口缓存资源地址管理以及x8 端口的动态链接仿真波形如图4 和图5 所示,x8 端口ram_wr_addr[127:0]动态链接在一起,用于数据缓存。两个x4 端口之间缓存地址管理相互独立。

图4 Station1_x8x4x4模式下x8仿真波形

图5 Station1_x8x4x4模式下x4x4仿真波形
Station0 内端口缓存资源地址管理以及端口的动态链接仿真波形如图6 所示,此时仅一个端口有效,所以ram_wr_addr[255:0]全部动态链接在一起,由该端口独享用于数据缓存。

图6 Station0_x16模式下的仿真波形
Station2 内端口缓存资源地址管理仿真波形如图7 所示,此时Station 内4 个端口全部有效,各个端口之间ram_wr_addr 相互独立,分别管理各自的数据缓存。

图7 Station2_full_x4模式下的仿真波形
表3 为提出的基于链表管理的PCIe 交换机动态缓存技术与相关文献在交换机的缓存分配方案、不同模式下的缓存利用率对比。相较于其他文献端口固定+共享缓存的分配方式,在固定缓存上造成了缓存空间浪费。该设计方案将固定缓存设计为动态缓存,缓存利用率可达100%,同时缓存空间的面积资源消耗相当于只消耗了固定缓存的空间,使芯片面积有所减小。
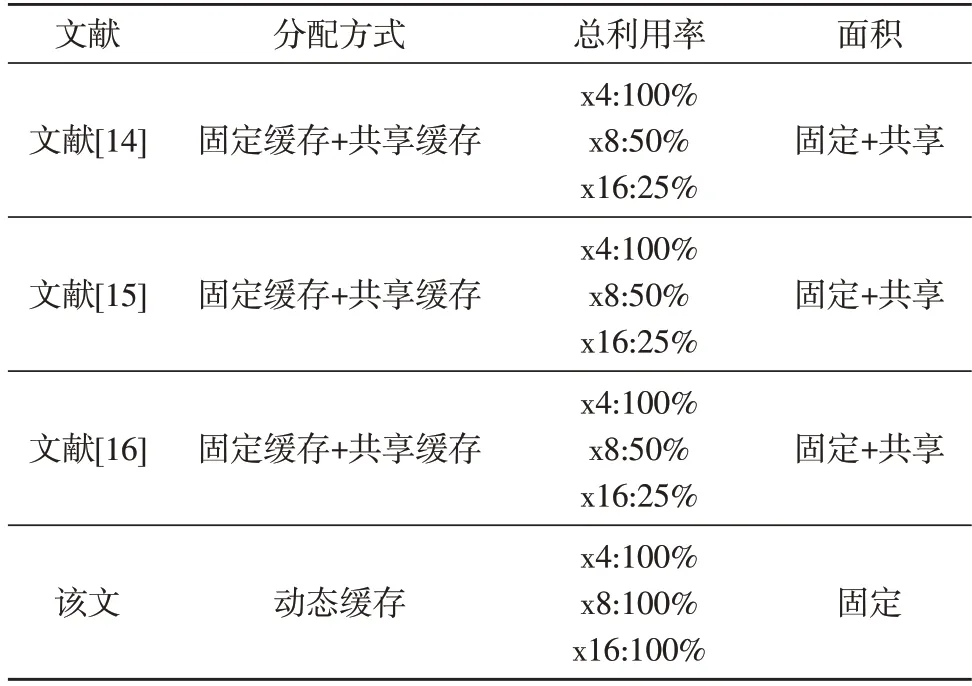
表3 该文与其他文献的缓存处理方式
5 结论
该文提出一种基于链表管理的PCIe 交换机动态缓存技术并进行实现,能够根据交换端口的实际有效情况,通过链表管理动态的将非活跃端口的缓存链接到活跃端口,解决了传统方案固定分配缓存的资源浪费问题。模块设计经过EDA 测试、FPGA测试和综合、布局布线并流片后成功通过测试,在各种复杂的交换机配置环境下均能满足功能、性能及时序的要求。该技术交换机内部的缓存资源利用率可达100%,在满足芯片各项指标要求的同时能有效减小芯片面积,降低成本。
猜你喜欢
诗选刊(2023年7期)2023-07-21
小学生学习指导(低年级)(2020年4期)2020-06-02
软件(2020年3期)2020-04-20
小读者之友(2019年9期)2019-09-10
成都信息工程大学学报(2019年2期)2019-08-28
第二课堂(课外活动版)(2019年12期)2019-02-10
军营文化天地(2018年2期)2018-12-15
成都信息工程大学学报(2018年1期)2018-05-31
意林·少年版(2018年1期)2018-02-07
产品可靠性报告(2017年7期)2017-09-05
