
基于演化聚类的网络舆情数据挖掘系统设计
2024-02-27 12:17曹宜丰
电子设计工程 2024年3期
曹宜丰
(河海大学商学院,江苏常州 213000)
网络舆情主要以网络为平台进行信息传播、讨论并产生社会影响。相较于传统纸媒,网络媒体是当今的主流,对社会风气、价值观、政策法规等都会产生一定影响,因此做好网络舆情工作至关重要。
文献[1]基于本体学习方法对网络舆情分析系统进行设计,从舆情本体出发,提取出其中的关键特征和子特征,从概念关系上进行舆情对比分析得到舆情的主要话题,但该方法缺乏数据分析,精准度不高。文献[2]基于数据挖掘技术对舆情分析系统进行设计,对舆情信息的数据进行挖掘,对大量信息数据进行智能化分析,从中推理归纳出数据特征,但该方法缺乏相关性分析,存在召回率和查准率较低的问题。针对传统方法的不足,该文设计一个基于演化聚类的网络舆情数据挖掘系统。
1 系统需求分析
1.1 综合需求分析
由于互联网技术的高速发展,传统的信息检索技术已无法满足当前个性化、多样化的服务需求,综合目前用户的普遍需求,网络信息搜索系统的发展应充分考虑以下方面:
1)精准性。搜索系统要做到精准定位,根据用户的关键词锁定用户真正的搜索需求,真正满足客户的信息服务需求。
2)提高召回率。当今社会生活节奏非常快,信息搜索系统要做到及时更新推送实时新闻,吸引用户关注,增强用户黏度,提高召回率。
3)提高查全率。系统内的信息应具备真实性、可信性,增强用户信赖,确保信息的全面性[3-4]。
1.2 功能需求分析
要实现个性化信息服务需求需要有功能全面的信息检索系统来支持,系统功能需求主要有以下几点:
1)个性识别。针对用户的搜索信息识别其个性偏好,有针对性地对用户搜索信息进行整理分类,从而挖掘其兴趣点,实现个性化信息服务。
2)信息采集。网络信息数量庞大,需要由搜索范围广、检索速度快、识别能力强的信息采集系统对海量数据进行高效抓取[5-6]。
3)舆情分析。在基于信息采集功能的基础上对信息进行分类,精准识别关键词,使用户能够根据个别词汇获取重要的舆情信息。
2 系统总体设计
为了实现个性化搜索需求,系统设计要对用户的信息进行收集、分析、提取,基于演化聚类设计思路,系统总体设计为垂直化结构,从下至上依次是支撑层、数据层、服务层、功能层[7-8]。
系统总体结构如图1 所示。

图1 系统总体结构
1)支撑层。主要包括系统的软件、硬件,以及信息采集器、传感器、储存器和基本网络资源等。
2)数据层。基于系统网络条件,包括网络的覆盖范围、网关规则、信息访问接口、数据库资源、资源分享平台等。
3)服务层。服务层主要面向客户,基于系统主要的软件应用和数据信息,向用户提供海量的数据搜索、资源获取、信息储存、权限维护等多样化服务,并针对用户的搜索偏好向其推荐个性化的服务内容。
4)功能层。是系统运行的主要层面,接收用户的搜索需求进行分析处理,满足其服务需求,同时还包括网页维护、资源控制、信息访问等多方面运行功能[9-10]。
3 系统功能的实现
该文引入演化聚类方法设计挖掘系统,选用演化聚类方法进行优化完善。演化聚类是将输入数据进行排序,针对数据特征设置阈值,通过多次迭代演化得到目标结果的一种自适应学习演化算法[11-12]。
3.1 网络舆情抓取功能实现
在舆情信息采集功能的基础上,采用演化聚类方法优化信息过滤与抓取功能。首先设定舆情信息抓取关键词词库,基于系统网页范围采用优先抓取策略进行信息过滤。过滤主要考虑关键词和点击量,基于关键词筛选符合搜索目标的网页信息,再根据点击量和搜索历史选择更为可靠的信息资源[13-14]。这一过程需要系统运算程序对网站的更新频率和点击量进行计算。网络舆情抓取流程如图2 所示。

图2 网络舆情抓取流程
演化聚类算法主要通过对数据进行编码,采用适当的演化方案进行演化操作,在对应的概率规则内根据一个或多个目标函数进行优化。
该文主要采取差分进化算法,随机演化初始向量可表示为:
其中,Xa(n) 为数据算子样本,a表示算子所属样本组序,n表示运算的迭代次数。根据演化结果进行演化运算,随机抽取三组其他样本组中的算子,分别计算他们的差再将结果进行求和,得到实验向量如下:
其中,β为误差缩放因子。下一步进行演化交叉运算,选择一个[0,1]之间的随机参数,与交叉因子进行比较得出差值α,演化出不同维度的目标向量Za(n):
根据式(3)分别进行运算比较,依照演化聚类的基本规则优胜劣汰,进入下一轮演化:
至此,差分进化算法完成了一轮迭代进化,根据运算结果是否符合目标要求决定是否再次重复迭代,直至结果达到预期标准,终止运算。
3.2 预警聚类分析功能
演化聚类方法能够很好地预测数据的演化方向,但由于数据漂移和时间问题可能会导致聚类偏差,因此需要完善预警聚类分析功能。
选择[0,1]之间的任意参数λ作为预警聚类的权重系数,tn表示算子对应的时刻,wn表示该时刻算子数据的误差范围,则适值函数Hx(n)可表示为:
至此,纠正了时间偏差对演化聚类的影响,预警聚类分析功能能够得到相对准确的数据分析结果,能够满足舆情挖掘系统对准确度的要求[15-16]。
4 实验研究
为了验证该文提出的基于演化聚类的网络舆情数据挖掘系统的实际应用效果,设定实验。同时选用基于本体学习方法的网络舆情分析系统和基于数据挖掘技术的舆情分析系统进行实验对比,分别验证挖掘系统的召回率、查准率和准确率。
召回率计算过程如式(6)所示:
其中,RECALL 表示召回率;TP 表示检测到且归类正确的网络舆情文档数据;FP 表示检测到却归类错误的文档数据。
查准率计算过程如式(7)所示:
其中,PRECISION 表示查准率;TN 表示检测错误却被归类到正确检测类别的网络舆情数据信息。
精度(准确率)计算过程如式(8)所示:
其中,ACCURACY 表示得到的舆情信息准确率;FP表示为检测到且未正确归类的舆情信息数据。
设定挖掘时间为40 s,分别选用该本文系统和传统系统进行实验对比,对比不同指标实验结果,判定方法的效果。
召回率实验结果如图3 所示。
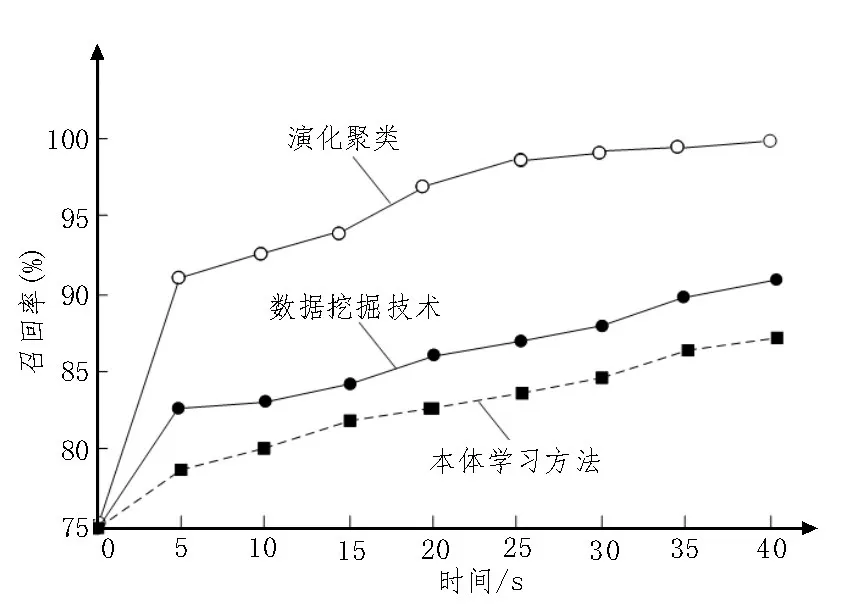
图3 召回率实验结果
观察图3 可知,该文提出的基于演化聚类网络舆情数据挖掘系统的挖掘召回率最高,当挖掘时间为5 s 时,召回率就已经达到90%以上,当挖掘时间接近于40 s 时,召回率已经接近100%。数据挖掘技术的挖掘效果相对较好,当挖掘时间接近于40 s 时,召回率已经接近90%,本体学习方法的挖掘效果最差,当挖掘时间为40 s时,挖掘召回率刚刚超过85%。
查准率实验结果如图4 所示。

图4 查准率实验结果
观察图4 可知,在查准率方面,该文提出的方法具有明显的优势,传统方法的查准率始终低于90%,而该文提出的系统查准率最高值达到了99%,具有极高的挖掘能力。
准确率实验结果如图5 所示。

图5 准确率实验结果
准确率是衡量挖掘效果的重要指标,观察图5可知,本体学习方法的挖掘准确率极低,在后期准确率仍然低于80%,无法实现精准挖掘,数据挖掘技术在后期虽然也能接近于90%,但是挖掘效果相对较差,而演化聚类方法的挖掘准确率最高。
综上所述,该文提出的挖掘系统具有极强的挖掘能力,具有较高的召回率和精度,确保二者都保持在90%以上,从而保证数据挖掘效果。
5 结束语
基于演化聚类方法对网络舆情数据挖掘系统进行了研究设计,该文方法的主要创新点如下:
1)改进预警聚类分析功能,降低时间偏差对演化聚类的影响,得到相对准确的数据分析结果,以此满足舆情挖掘系统对准确度的要求。
2)通过演化聚类方法对舆情信息热点进行挖掘抓取,相比于传统的网络舆情获取方法具有更高的精准性、实时性和可用性,能够满足当前对于个性化信息服务的需求。
通过实验验证,得出该文所设计系统的应用功能远优于传统系统,其有利于推动未来云计算环境中个性化网络服务的发展创新。
猜你喜欢
大众投资指南(2021年35期)2021-02-16
现代电子技术(2018年16期)2018-08-21
现代电子技术(2017年23期)2017-12-20
电力与能源(2017年6期)2017-05-14
计算机应用(2016年10期)2017-05-12
中国民政(2016年16期)2016-09-19
中国民政(2016年10期)2016-06-05
中国民政(2016年24期)2016-02-11
信息通信技术(2015年6期)2015-12-26
电子设计工程(2014年18期)2014-02-27
