
小数据集复杂文本验证码识别
2024-02-27 12:16陈诗雨
电子设计工程 2024年3期
陈诗雨
(武汉邮电科学研究院,湖北 武汉 430070)
文本验证码因易于维护、用户体验感好等优点被广泛使用,暗网验证码通常为复杂文本验证码。在实际匿名网站中,通过网络瓶颈和反爬虫机制,可以获取的暗网验证码数量有限。对于小数据集复杂文本验证码识别,机器学习存在难以去噪和分割的问题,深度学习存在数据不足容易过拟合的问题。
文献[1]使用图像处理和深度学习技术做文本验证码识别;文献[2]使用对抗样本增强验证码安全性;文献[3]提出识别验证码的轻量级卷积神经网络;文献[4]使用迁移学习减少验证码破解复杂度和样本标注成本;文献[5]使用迭代对抗生成提高验证码防御能力;文献[6]优化卷积神经网络在复杂验证码识别中的应用;文献[7]使用深度学习识别背景噪声大、字符长度可变的文本验证码;文献[8]融合风格迁移和对抗样本技术增强验证码安全性;文献[9]研究基于粒子群优化算法的验证码识别;文献[10]实现暗网站点的验证码快速识别;文献[11]使用差分进化算法生成字符对抗验证码。
1 算法框架
针对目标文本验证码自身特点,提出了一种基于字符分割的小数据集复杂文本验证码识别方法,先使用深度学习方法进行去噪和分割,其中pix2pix算法用于去噪,YOLOv4[12]算法用于分割,再使用KNN 算法进行分类,从而实现小数据集复杂文本验证码识别。流程图如图1 所示。
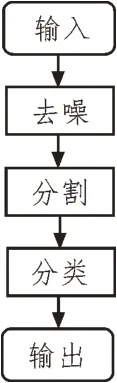
图1 实验流程图
1.1 pix2pix
pix2pix的核心技术有三点:基于CGAN(Conditional GAN)的损失函数、基于U-Net 的生成器和基于PatchGAN 的判别器。
GAN 通过生成器G(z)和判别器D(x)互相博弈来达到同时优化两个模型的目的,它的损失函数可以定义为对G(z)和D(x)的极大极小博弈。
在传统的GAN 中,模型的生成内容仅由生成器的参数和随机噪声z来决定,因此无法控制生成器生成的内容。在CGAN 的判别器中,将数据x及其标签y作为输入同时送到判别器中生成跨模态向量,然后再通过判别器判断x是真实数据还是生成数据。CGAN 的损失函数可以定义为对G(z|y)和D(x|y)的极大极小博弈。
pix2pix 在损失函数中加入L1 正则项来提升生成图像的质量,使其更清晰。
最终目标是在正则约束下的生成器和判别器的极大极小博弈。
U-Net 是一个全卷积模型,它分为两个部分,左侧是由卷积和降采样操作组成的压缩路径,右侧是由卷积和上采样组成的扩张路径,扩张的每个网络块的输入由上一层上采样的特征和压缩路径部分的特征拼接而成。网络模型整体是一个U 型结构,因此被称为U-Net。
不同于传统的GAN 将整图作为判别器的输入,pix2pix 提出了将输入图像分成N×N个图像块(Patch),然后将N×N个图像块依次提供给判别器,因此这个方法被命名为PatchGAN。根据N的不同大小来调整判别器的层数,进而得到最合适的模型感受野。
1.2 YOLOv4
YOLO 网络主要由Backbone、Neck 和Head 三个组件构成,Backbone 用于提取特征,Neck 用于提取更复杂的特征,Head 用于预测目标的类别和位置。YOLOv4 在YOLOv3 的基础上对Backbone、Neck 和Head 作出了改进。
YOLOv4 的Backbone是在YOLOv3 的DarkNet53的基础上通过借鉴CSPNet(Cross Stage Partial Network)[13]改进的CSPDarkNet53。CSPNet 直接对通道维度进行划分,而YOLOv4 是利用两个1×1 卷积核来实现两个分支信息在交汇处的拼接。
YOLOv4 的Neck结构主要采用了SPP(Spatial Pyramid Pooling)模块、FPN(Feature Pyramid Networks)+PAN(Path Aggregation Network)的方式。在SPP 模块中,使用最大池化方式将不同尺度特征图进行拼接,实现多尺度融合,增加感受野。YOLOv3 的Neck 只有自顶向下的FPN 对特征图进行特征融合,而YOLOv4 则是以FPN+PAN 的方式对特征做进一步的融合。相比于原始的PAN 结构,YOLOv4 实际采用的PAN 结构将addition 改为concatenation,使得特征图融合后实现维度扩张。如此一来,FPN 自顶向下传递强语义信息,PAN 自底向上传递强定位信息,达到更强的特征聚合效果。
YOLO 使用非极大值抑制(Non Maximum Suppression,NMS)保留最优解,NMS 是基于交并比(Intersection Over Union,IOU)实现的,IOU 反应了两个边界框的重叠度。YOLOv4 在Head 部分的主要改进是训练时损失函数采用CIOU_Loss[14],测试时采用DIOU_NMS 进行筛选。
IOU_Loss 主要考虑检测框和目标框重叠面积,其中,A 是两者的交集,B 是两者的并集。GIOU_Loss在IOU_Loss 的基础上,考虑边界框不重合的问题。DIOU_Loss 在GIOU_Loss 的基础上,考虑边界框中心点距离的信息。CLOU_Loss 在DIOU_Loss 的基础上,考虑边界框长宽比的尺度信息。
1.3 KNN
K 最邻近(K-Nearest Neighbor,KNN)算法是最简单的分类方法之一。该方法的思路非常简单直观:如果一个样本在特征空间中的K个最相似(即特征空间中最邻近)的样本中的大多数属于某一个类别,则该样本也属于这个类别。因为KNN 算法适合于样本数较少、典型性较好的样本集,所以实验选择KNN 算法构建分类模型。
2 实验
2.1 实验平台
实验在Ubuntu 系统上,由Anaconda 创建虚拟环境,使用开源的Python 机器学习库PyTorch 实现。
2.2 数据集
首先通过计算图像哈希值对从匿名网站获取的真实文本验证码进行去重,得到500 张不同的验证码图片,然后进行标注——即验证码图片命名格式为“六位数字字母_时间戳.jpg”,其中六位数字字母为验证码文本内容,验证码如图2 所示。

图2 真实文本验证码
验证码由数字和大小写字母组成,文本颜色随机,文本位置随机,并且每张验证码有六条粗细不一的干扰线。
2.3 去噪模型
实验使用pix2pix 进行图像去噪。考虑到由pix2pix 训练得到的模型是有偏的,所以根据真实文本验证码的字符集设置和字符参数设置,并且使用不同字体来自动生成两万对带有标签的合成文本验证码,每对文本验证码包含两张,一张是有噪的,另一张是对应的无噪的。合成文本验证码对如图3 所示。

图3 合成文本验证码对
对合成文本验证码对做预处理,使其符合pix2pix 训练网络标准输入格式,准备相关文件,开始训练去噪模型。生成网络的输入是一张有噪验证码图片,输出是一张被去噪的验证码图片。将被去噪的验证码和对应的无噪验证码同时输入判别网络,让判别网络对两者进行鉴别,目标是选出被生成网络去噪的验证码。生成网络和判别网络的目标相反,相互竞争,当判别网络的准确性低于5%时停止迭代,去噪模型训练完成。
常用的图像去噪方法有中值滤波、像素点法和腐蚀膨胀。这三种方法先对输入图像进行灰度处理和二值化,再进行去噪处理,二值化结果如图4所示。

图4 二值化结果
中值滤波适合处理颗粒噪声,中值滤波去噪结果如图5 所示。

图5 中值滤波结果
像素点法只能去除细干扰线,像素点法去噪结果如图6 所示。
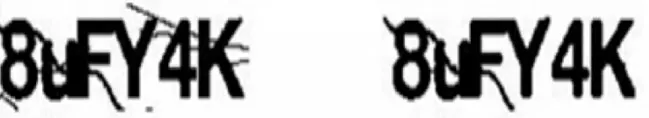
图6 像素点法结果
腐蚀膨胀是针对图像中的高亮(白色)部分进行的,腐蚀膨胀去噪结果如图7 所示。

图7 腐蚀膨胀结果
pix2pix 去噪结果如图8 所示。

图8 pix2pix结果
综上可得,中值滤波、像素点法和腐蚀膨胀三种方法均未达到理想的去噪效果,pix2pix 去噪效果最好。
2.4 分割模型
由于字符粘连导致使用基于连通域的分割方法或使用垂直投影法均不能达到理想的字符分割效果,所以实验使用目标检测进行文本单字符分割。
使用labelImg 标注数据,得到符合YOLOv4 训练网络标准输入数据格式——[类别class,目标区域中心x点,目标区域中心y点,目标区域宽度w,目标区域高度h]的标注文件。将500 张验证码及其标注文件按3∶1∶1 划分为训练集、验证集和测试集。制作和准备用于训练模型的图片路径,类别标签,网络配置和预训练权重等相关文件,迭代训练模型1 000次,保存迭代过程中在验证集上准确率最高的模型参数,作为分割模型。分割模型在验证集上各项评价指标结果如表1 所示。

表1 分割模型各项评价指标结果
分割模型检测分割文本单字符结果如图9所示。

图9 验证码分割结果
2.5 分类模型
将500 张验证码按4∶1 划分为训练集和测试集,首先对验证码进行去噪,再进行字符分割,单字符分割结果如图10 所示。

图10 单字符分割结果
对于分割下来的单字符,先对其进行二值化,单字符二值化结果如图11 所示。

图11 单字符二值化结果
再做图像大小归一化处理,单字符归一化结果如图12 所示。

图12 单字符归一化结果
最后使用经二值化和归一化处理的单字符构建KNN 分类模型。
2.6 实验结果比较
实验对比了五个开源模型和提出的无去噪KNN模型以及有去噪KNN 模型在测试集上的识别准确率,结果如表2 所示。

表2 各个模型的识别准确率
tesseractocr 模型在测试集上单字符识别准确率为0.7%,验证码识别准确率为0.0%;muggleocr 模型在测试集上单字符识别准确率为4.6%,验证码识别准确率为0.0%;easyocr 模型在测试集上单字符识别准确率为7.3%,验证码识别准确率为0.0%;ddddocr模型在测试集上单字符识别准确率为54.0%,验证码识别准确率为14.0%;paddleocr 模型在测试集上单字符识别准确率为45.2%,验证码识别准确率为17.0%;无去噪KNN 模型在测试集上单字符识别准确率为96.3%,验证码识别准确率为82.0%;有去噪KNN 模型在测试集上单字符识别准确率为98.7%,验证码识别准确率为94.0%。由此可见,相比开源模型,该文模型识别准确率更高,同时,去噪处理有助于识别准确率的提升。
3 结束语
文中提出一种基于字符分割的小数据集复杂文本验证码识别方法,该方法首先使用pix2pix 对验证码做去噪,再使用YOLOv4 进行单字符分割,最后使用KNN 进行分类。实验结果表明,该方法的单字符识别准确率达98.7%,优于开源模型识别结果,证明了该方法的可行性和有效性。在后续的研究中,将使用YOLOX[15]或者YOLOv7[16]训练分割模型,以实现更高效、更精确的字符分割,或者通过迁移学习技术实现小数据集复杂文本验证码识别。
猜你喜欢
电脑爱好者(2022年15期)2022-05-30
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
小学生学习指导(低年级)(2019年12期)2019-12-04
电子制作(2019年19期)2019-11-23
少儿美术(快乐历史地理)(2018年7期)2018-11-16
数学物理学报(2017年5期)2017-11-23
成都信息工程大学学报(2017年3期)2017-11-09
湖南城市学院学报(自然科学版)(2016年2期)2016-12-01
华东理工大学学报(自然科学版)(2015年2期)2015-11-07
