
基于改进支持向量机的数字档案多标签分类算法
2024-02-27 12:16张岚张向阳王金柯杨铁军刘骞
电子设计工程 2024年3期
张岚,张向阳,王金柯,杨铁军,刘骞
(国网河南省电力公司营销服务中心(计量中心),河南郑州 450000)
数字档案分类是一种新型的电子档案管理与协调方案,可以在电子计算机系统的作用下,对档案文本进行收集、保管与共享处理,从而使得客户端主机能够准确掌握数据信息参量在互联网体系内的传输情况[1-2]。然而随着数字档案信息存储量的增大,会造成错误的信息分类行为,还有可能使数字标签呈现出较为混乱的连接状态。基于多层极限学习机的分类算法虽然可以最大程度上保证数字档案信息的完整性,但却很难构建复杂的数字标签,这也是导致标签测试集基数与训练集基数之间差值水平不能得到有效控制的主要原因[3]。
为解决上述问题,针对基于改进支持向量机的数字档案多标签分类算法展开研究。支持向量机是在统计学习理论基础上具有分类能力与泛化处理能力的执行算法。模糊支持向量机是传统支持向量机的优化,能够针对非线性数据进行集中处理,不但加强了原有支持向量机算法的泛化处理能力,还可以最大程度上保证数据信息样本的传输完整性,使其对训练样本保持较强的敏感性[4]。然而,在样本数目较大时,模糊支持向量机算法的分类速度相对减慢,这就会导致噪声信息大量累积,从而使得主机失去准确辨别数据信息样本的能力。改进支持向量机算法在模糊支持向量机技术的基础上,重新约束了样本信息的存储形式,并从泛化应用、分类处理两个角度,确定核心数据集合对关联信息参量的影响能力。
1 标签挖掘
1.1 SVM函数
SVM 函数是基于改进支持向量机理论的机器学习算法,可以在监督样本参量传输行为的同时,建立一个最优分类超平面结构。对于数字档案信息样本而言,在建立分类标签结构时,主机元件可以根据SVM 函数表达式对信息参量进行分类,一般来说,满足超平面分类规则的信息数据可以被主机元件直接收录,而不满足超平面分类规则的信息数据则会在SVM 函数的作用下,进行再一次赋值[5-6]。设a表示数字档案信息样本的初始赋值,sa表示基于系数a的超平面结构定义向量,f表示待监督样本参量的传输系数,ḋ表示基于改进支持向量机理论的数字档案信息样本特征值,β表示信息样本赋值参量。联立上述物理量,可得SVM 函数表达式为:
在对数字档案信息进行取样时,要求系数ḋ的取值不能等于自然数“1”。
1.2 标签隶属度
标签隶属度表达式考虑到了野值点及噪声点对数字分类标签构建结果的影响[7]。噪声点所处位置表示了干扰性信息对数字档案多标签分类结果造成的影响,与野值点标记位置相比,该类型节点与中心分类节点之间的间隔距离更近,但其取值结果对于标签测试集基数的影响能力却更强[8]。基于SVM 函数,设h0表示中心分类节点标记系数,h′表示野值点标记系数,h″表示噪声点标记系数,δ表示标签信息定义项指标,χmin表示数字档案标签定义系数的最小取值结果,χmax表示最大取值结果。在上述物理量的支持下,联立式(1),可将基于改进支持向量机的标签隶属度表达式定义为:
由于数字档案信息样本的实时存储量不可能为零,因此标签隶属度g的计算取值也恒大于零。
1.3 数据信息挖掘深度
数据信息挖掘深度决定了改进支持向量机算法对于数字档案信息参量的处理能力。在标签隶属度表达式保持不变的情况下,挖掘深度指标的计算数值越大,就表示改进支持向量机算法对于数字档案信息参量的处理能力越强[9-10]。在建立标签向量时,待处理数字档案信息样本同属于一个数据集合空间,所以挖掘深度指标也可用于区别已存储的数字档案信息参量。规定j1、j2、…、jn表示n个随机选取的数字档案信息样本度量值,且j1≠j2≠jn的不等式条件恒成立,ε表示数据信息参量的挖掘置信度指标,ϕ表示基于改进支持向量机算法的数字标签定义系数。
数据信息挖掘深度计算结果为:
在改进支持向量机算法认知中,挖掘深度指标大于零,表示数字档案信息样本之间的关联程度较高。
2 多标签型数字档案分类方法
2.1 共享信息量
共享信息量是指数字档案信息在单位时间内的传输总量,由于改进支持向量机算法可以促进数字档案信息快速传输,所以在设置多标签分类节点时,要求共享信息量指标的计算数值应尽可能趋近其极大值取值结果[11]。在不考虑其他干扰条件的情况下,共享信息量计算结果受到数字档案信息分类标准、分类区间个数两个物理指标的直接影响。数字档案信息分类标准系数常表示为l,在改进支持向量机算法的影响下,该项物理指标的取值恒属于[1,+∞)的数值区间。分类区间个数常表示为γ,该项指标参量的取值越大,表示网络主机对于数字档案信息文本的处理越细致。联立上述物理量,可将共享信息量计算表达式定义为:
式中,b表示数字档案信息样本的共享系数,x̂表示分类标签节点处的信息样本向量特征值,ι表示数字档案信息样本在单一标签集合内的迭代次数。规定在标签隶属度条件相同的情况下,网络主机会优先处理量级水平较高的数字档案信息共享文本[12]。
2.2 容错系数
由于数字档案分类标签序列是随机生成的,不同标签链顺序会影响数字档案信息的分类结果,因此,为避免数据信息样本错误分类行为的出现,要求每一个标签链组织都必须具有较强的容错能力[13-14]。容错系数也叫容错定义参量,决定了标签链组织对于数字档案信息的承载能力,在改进支持向量机算法的作用下,该项指标参量的计算取值越大,表示已定义标签链组织对于数字档案信息文本的容错能力越强。
容错系数计算式如下:
其中,λ表示数字档案信息分类系数,c表示标签链序列定义项指标的初始赋值,μ、ν表示两个不相等的数字档案信息容错量差值,zμ表示基于系数μ的分类标签序列长度值,zν表示基于系数ν的分类标签序列长度值。求解容错系数表达式时,要求zμ-zν的计算结果必须大于零。
2.3 相似度
相似度指标决定了数字档案信息样本之间的相似性水平。对于网络主机元件而言,其在对标签节点进行分类时,首先需要根据数字档案信息之间的相似度差异性,经已存储数据参量分成多个数据包文件;然后将各个数据包文件依次输入网络主机元件;最后由网络主机元件求解出多个不同的分类标准[15-16]。设ϖ、ϑ表示两个不相等的数字档案信息样本区分向量,uϖ表示基于向量ϖ的标签节点分类特征值,uϑ表示基于向量ϑ的标签节点分类特征值。在上述物理量的支持下,联立式(5),可将数字档案信息分类标签节点的相似度指标求解表达式定义为:
至此,完成对各项指标参量的计算与处理,在不考虑其他干扰条件的情况下,完成对基于改进支持向量机的数字档案多标签分类算法的设计。
3 实例分析
3.1 实验设置与数据集
实验分别采用改进支持向量机算法、多层极限学习机算法作为数字档案信息文本的语言开发环境,其中前者作为实验组、后者作为对照组,实验环境的详细信息如表1 所示。
表1 实验环境
实验选择Emotions、Genbase、Scene、Flags、Yeast、Enron、Birds、Medical 八种数字档案信息作为实验对象,每种数字档案信息所属标签类型及其标签测试集基数的初始取值如表2 所示。

表2 数字档案的基本信息
表1 中,Emotions 信息是音乐领域的数字档案标签,Genbase信息与Yeast信息是生物领域的数字档案标签,Scene信息与Flags信息是图像领域的数字档案标签,Enron 信息与Medical 信息是文本领域的数字档案标签,Birds 信息是音频领域的数字档案标签。
3.2 结果与分析
对于数字档案信息而言,标签测试集基数(ω)与训练集基数(ξ)之间的差值(ψ)可以用来描述信息文本错误分类行为的出现概率,差值指标ψ的计算式如下:
若ψ≤350 个,表示标签测试集基数与训练集基数之间的差值水平较小,当前情况下,数字档案信息文本错误分类行为的出现概率相对较小;若ψ>350 个,表示标签测试集基数与训练集基数之间的差值水平较大,当前情况下,数字档案信息文本错误分类行为的出现概率相对较大。
图1 反映了实验组、对照组数字档案信息训练集基数(ξ)的实验数值。
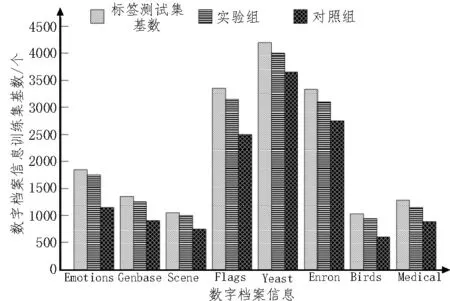
图1 训练集基数
根据图1 中训练集基数(ξ)的记录数值,对差值指标(ψ)进行计算,具体计算结果如表3 所示。

表3 标签测试集基数与训练集基数的差值
分析表3 可知,在实验分类方法应用下,八种数字档案信息的测试集基数与训练集基数差值始终小于350 个;对照组分类方法应用下,八种数字档案信息的测试集基数与训练集基数差值均大于350 个。综上可知,基于改进支持向量机的多标签分类算法可以有效降低数字档案信息标签测试集基数与训练集基数之间的差值,在解决信息错误分类问题方面具有更强的实际应用价值。
4 结束语
文中提出的数字档案多标签分类算法以改进支持向量机理论为基础,对数字档案标签完成深度挖掘,又通过定义共享信息实时传输量的方式,推导容错指标与相似度指标的具体数值。随着多标签分类算法的应用,数字档案信息标签测试集基数与训练集基数之间差值水平过大的问题得到了较好解决,能够有效避免数据信息错误分类行为的出现,符合实际应用需求。
猜你喜欢
四川劳动保障(2021年9期)2022-01-18
无锡职业技术学院学报(2019年4期)2019-12-27
小学生必读(中年级版)(2018年6期)2018-09-05
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
小学生学习指导(低年级)(2017年9期)2017-08-07
公民与法治(2016年10期)2016-05-17
计算机工程(2015年8期)2015-07-03
物理实验(2015年9期)2015-02-28
数学年刊A辑(中文版)(2014年4期)2014-10-30
