
图像与点云多重信息感知关联的三维多目标跟踪
2024-01-22 10:26刘祥李辉程远志孔祥振陈双敏
中国图象图形学报 2024年1期
刘祥,李辉*,程远志,孔祥振,陈双敏
1.青岛科技大学信息科学技术学院,青岛 266061;2.哈尔滨工业大学计算机科学与技术学院,哈尔滨 150006;3.荷兰埃因霍芬理工大学工业工程学院,荷兰埃因霍芬 5612
0 引言
三维多目标跟踪(Wu等,2022)作为计算机视觉的核心技术之一,在自动驾驶(朱向雷 等,2021)、智慧交通、智能安防与智慧城市(Muzahid 等,2021)等领域起着至关重要的作用,是智能实时环境感知(Liu 等,2022;刘旖菲 等,2021)的主要组成部分。多目标跟踪的目的是对每一帧中的目标进行定位和识别,并将连续帧中的相同目标关联起来,随着时间序列形成运动轨迹(Zhang 等,2021)。现有的三维多目标跟踪方法主要遵循基于检测的跟踪范式(Weng 等,2020a),即首先利用现有的目标检测器(Huang 等,2020;Shi 等,2019;李宗民 等,2021;Wang等,2020)对所有目标进行检测,然后采用数据关联方法将不同帧中的相同目标关联。借助于深度神经网络(张珂 等,2021)强大的表示能力以及点云提供的精确位置信息,三维多目标跟踪(Liu 等,2022;Zaech 等,2022)取得了显著的成就,但是现有跟踪算法容易受到各种因素的干扰,在真实的三维场景中仍然面临着非常严峻的挑战。
激光雷达获取的点云能够提供深度信息,能精准地定位目标(李娇娇 等,2022),但具有稀疏、无序和范围有限等缺点,对于远距离的小目标,获取到的点比较稀疏,容易造成目标的漏检。相机获取的图像能够提供形状、纹理和颜色等丰富的语义特征信息,但是缺乏深度信息,无法有效地跟踪到被遮挡的目标。
因此,将点云和图像进行多模态特征融合,能够缓解纯点云的单模态跟踪存在的问题,提升三维多目标跟踪的性能,但是多模态融合的三维多目标跟踪仍然存在以下问题:1)研究表明,深度卷积神经网络的性能可以通过使用注意力机制(Hu 等,2020)进行提升,但是在BAM(bottleneck attention module)(Park 等,2018)和CBAM(convolutional block attention module)(Woo等,2018)中,通道和空间注意力是相互独立的,忽略了两者之间的信息交互性,未能达到最佳的效果。2)现有的多模态融合方法在融合不同模态的特征时采用简单相加的方式进行融合(Chiu 等,2021),或是仅对图像中的干扰信息进行抑制(Huang 等,2020),未考虑到点云中存在大量的背景点。3)数据关联阶段,现有的跟踪方法利用轨迹预测框和3D 检测边界框之间的交并比(intersection over union,IoU)(Weng 等,2020a)或欧氏距离(Kim 等,2021)来判断检测和轨迹是否匹配,然而,这些方法舍弃了IoU 较低的目标或目标的大多数几何特征,匹配度较低,容易造成轨迹的碎片化或目标之间的身份切换。
为了解决上述问题,本文提出一种图像与点云多重信息感知关联的三维多目标跟踪方法,主要研究贡献如下:1)提出混合软注意力模块(hybrid soft attention module,HSAM),采用通道分离技术,根据通道注意力图将特征图进行分组,更好地实现通道和空间注意力之间的信息交互,进一步对图像语义特征增强,减少图像中的干扰信息。2)提出语义特征引导的多模态融合模块(semantic feature-guided multimodal fusion module,SFGMF),采用语义特征引导的方式将点云特征、图像特征以及逐点图像特征进行深度自适应持续融合,利用注意力对特征中的干扰信息进行抑制,以充分利用点云和图像之间信息互补的优势,更好地解决现有方法融合不充分的问题。3)提出多重信息感知亲和矩阵(multiple information perception affinity matrix,MIPAM),将轨迹预测框和检测框之间的IoU、欧氏距离、方向相似性以及目标外观信息结合起来,构建多重信息感知亲和矩阵,设计联合检测和嵌入的跟踪框架,以实现高效的三维多目标跟踪。
1 相关工作
1.1 基于点云的三维多目标跟踪
借助于点云能够提供准确位置信息的特性,仅使用点云作为输入的多目标跟踪便已取得了优异的性能。Weng等人(2020a)提出AB3DMOT,首先利用现成的3D 目标检测器PointRCNN(Shi 等,2019)从点云中获得3D 检测,然后利用3D 卡尔曼滤波预测目标在当前帧中的状态,最后基于预测目标状态和当前目标检测之间的3D IoU,利用匈牙利匹配算法进行数据关联。然而基于边界框IoU 的方法不能将两个没有重叠的状态关联起来(李功 等,2023)。在使用卡尔曼滤波器解决3D 多目标跟踪问题的基础上,Chiu 等人(2020)从训练数据中估计初始状态和过程以及观察噪声的协方差矩阵,并利用马氏距离进行数据关联。3D 世界中的目标不遵循任何特定的方向,Yin 等人(2021)提出CenterPoint 将3D 目标表示为点,使用关键点检测目标的中心并将3D多目标跟踪简化为基于欧氏距离的贪婪最近点匹配。然而,基于距离的方法忽略了目标的大多数几何特征,不能为匹配阶段提供更具判别性的相似性度量。在之前的工作中,采用基于计数的方法来决定轨迹的初始化和终止,这对于改善多目标跟踪性能是次优的,为此,Benbarka 等人(2021)提出CBMOT,通过使用分数更新函数来增加匹配的轨迹分数,并降低不匹配的轨迹分数来改善跟踪结果,使用基于置信度的方法进行轨迹初始化和终止。Wu 等人(2022)提出PC3T,一种基于预测置信度引导的数据关联方案,首先采用恒定加速度运动模型来估计目标的位置,并输出预测置信度;其次,引入一种新的聚合成对成本来利用点云中目标的特征,以实现更快、更准确的数据关联。由于使用置信度分数来过滤低质量的检测以提高输入边界框精度的方法不利于召回,且基于IoU 和基于距离的关联度量具有不同的故障模式,Pang 等人(2022)提出SimpleTrack,该方法使用更为严格的非极大值抑制(non-maximum suppression,NMS)对输入的检测进行预处理,并将“广义IoU”(generalized IoU,GIoU)泛化到3D 空间中作为主要的关联度量。然而,由于该方法仅使用了目标的运动模型,未使用含有丰富信息的外观模型,不能有效地处理长期遮挡或暂时消失的目标,最终导致在跟踪过程中仍然存在较多的身份切换。
点云可以提供深度信息,能够精准地定位目标,但是自身存在的稀疏、无序以及相对于相机感知范围有限等缺点,导致无法准确地检测和跟踪远距离的小目标。相机图像包含形状、纹理和颜色等丰富的语义信息,但缺乏深度信息导致不能有效地处理被遮挡的目标。因此,多传感器联合感知对于3D多目标跟踪的可靠性和准确性至关重要。将点云和图像进行有效融合正好可以达到信息互补的目的(张燕咏 等,2020)。
1.2 基于点云和图像融合的三维多目标跟踪
Zhang 等人(2019)提出mmMOT(multi-modality multi-object tracking),它对交叉模态的邻接估计器进行联合优化,首次尝试对点云的深度特征进行编码,并用混合整数线性规划取代匈牙利匹配算法来执行数据关联。为了计算出检测和匹配分数,Frossard 和Urtasun(2018)使用一对前馈神经网络处理RGB 和点云数据,同时将跟踪问题表述为深度结构化模型中的推理问题。Baser 等人(2019)提出FANTrack,利用目标的外观信息和边界框信息构建局部相似度图,然后将数据关联表述为卷积神经网络中的推理问题。为了使不同目标之间的特征更具辨别性,Weng 等人(2020b)提出GNN3DMOT(graph neural network for 3D multi-object tracking),采用一种新的联合特征提取器同时从二维和三维空间中提取目标的外观和运动特征,并引用图神经网络在目标之间进行特征交互,从而使目标特征可以倾向于具有相似特征的目标,偏离具有不同特征的目标。Chiu等人(2021)提出了一个由不同的可训练模块组成的多模态、多目标跟踪方法,该方法融合从2D 图像和3D 点云中提取的特征来捕获目标的外观和几何信息,并将马氏距离和深度特征距离相结合,以获得更好的数据关联,但是融合过程只是进行了简单的特征相加,并未有效地利用点云和图像中的特征。此外,上述方法都是重新训练网络来对检测出的目标进行特征提取,这与检测阶段存在特征的重复计算,加大了计算量和内存的消耗,且严重依赖于检测器的质量。Kim 等人(2021)提出EagerMOT,该方法首先从图像和点云中获得两组检测,即2D 检测和3D 检测,然后提出一种简单而有效的两阶段数据关联方法,首先使用轨迹的3D 状态信息对3D 检测执行第1 阶段的数据关联,此后,第1 阶段未匹配的轨迹和2D 检测用于执行第2 阶段的数据关联,取得了具有竞争力的跟踪性能。Wang 等人(2022)提出DeepFusionMOT,在EagerMOT 的基础上设计了一种高效的4 阶段深度关联机制来执行数据关联,取得了更加优异的性能。但是以上两种方法在数据关联阶段只利用了目标的运动信息,并未使用目标的外观信息,这仅适用于相对简单的场景,而在复杂的场景中获得的亲和度关联矩阵判别性较差,容易造成目标轨迹的碎片化,影响跟踪的性能。
2 方 法
本文提出图像与点云多重信息感知关联的三维多目标跟踪方法,网络结构如图1 所示,主要包括3 部分:1)点云和图像特征提取;2)语义特征引导的多模态融合;3)多重信息感知数据关联。首先,网络以点云和图像作为输入用于提取对应特征,同时采用混合软注意力增强图像语义特征,接着语义特征引导的多模态特征融合模块将增强的图像语义特征和点云特征进行多次深度自适应融合,接着经过区域提议网络处理之后分别送入检测分支和嵌入分支,用于获取目标的位置信息和外观信息,然后构建多重信息感知亲和矩阵,并利用匈牙利匹配算法在第T帧检测和第T -1 帧轨迹之间进行匹配,最后对T帧中的目标轨迹进行初始化、更新或终止。
2.1 点云和图像特征提取
1)图像特征提取。以图像作为输入,然后利用4 个结构相同的卷积块进行图像特征提取,其中每个卷积块由卷积核大小为3 × 3的两个卷积层组成,为了扩大感受野,第2 个卷积层的步幅设置为2,得到的特征图表示为Fi(i=1,2,3,4)。接着利用具有不同步幅的反卷积将获得的特征图恢复到原始图像尺寸,得到4 个尺寸相同的特征图,再利用拼接操作将其拼接成一个完整的特征图FI。此外,提出了混合软注意力特征增强模块,分别以特征图Fi或FI作为输入,用于对图像语义特征增强。
2)点云特征提取。点云分支以点云作为输入,并将提取的点云特征用于生成3D 粗建议(3D coarse proposals)。该分支利用具有多尺度分组的Point-Net++(Qi 等,2017)作为主干网来对点云进行下采样、分组和提取紧凑的点云特征。如图1 中的点云主干网所示,其中的编码器由4 个SA(set abstraction)层组成,解码器由4 个FP(feature propagation)层组成,提取的点云特征分别表示为Si(i=1,2,3,4)和Pi(i=1,2,3,4)。同时,利用语义特征引导的多模态融合模块,将每个SA 层提取的点云特征Si与对应卷积块提取并增强的图像特征Fi融合,同时也将语义特征FI与点云P4特征进行融合,充分利用点云信息和图像信息互补的优势,为后续任务提供更丰富的特征。
3)混合软注意力特征增强图像语义特征增强方面,在网络中引入BAM(Park 等,2018)、CBAM(Woo等,2018)等注意力机制具有一定的性能提升,但是空间和通道注意力模块是相互独立的,未考虑到信息交互性,没能取得更优的效果。因此,本文利用通道分离技术,提出一种更有效的混合软注意力特征增强模块,网络结构如图2所示。该模块包括软通道注意力和软空间注意力两个子模块,在软空间注意力模块中,根据通道注意力图,采用通道分离机制沿着通道轴将通道增强特征分为两组,以充分利用两个模块之间的信息交互性,实现对图像语义特征增强。
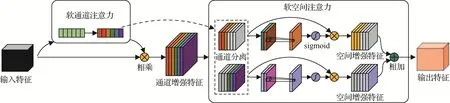
图2 混合软注意力模块Fig.2 Hybrid soft attention module
(1)软通道注意力子模块。首先,输入特征F经过全局平均池化层将空间信息压缩到通道特征向量中,为了利用在压缩操作中聚合的空间信息,接着使用两个全连接层来捕获通道之间的相关性,最后利用sigmoid 激活函数来获得通道注意力图CA,与原始特征相乘之后,获得通道增强特征FC。计算过程为
式中,Avg表示全局平均池化,fc表示全连接层,ReLU表示激活函数(rectified linear unit),Sig表示sigmoid函数。
(2)软空间注意力子模块。因为通道增强特征图中每个通道具有不同的重要性,重要通道的权重大于次重要通道的权重。因此,为了在空间注意力中有效地利用通道注意力图,本文利用通道分离机制沿着通道轴将通道增强特征分为两组,具体的空间注意力推理过程如下。
如图2 所示,首先利用通道分离技术将通道增强特征分为两组,其中一组为重要通道组FC1,另一组为次重要通道组FC2,且在分离的过程中不改变通道增强特征的通道顺序。接着在通道方向上对FC1和FC2执行平均池化和最大池化操作,将其输出拼接之后获得一对特征描述符,接着利用卷积核大小为7 × 7的共享卷积层生成一对注意力图。然后,这对注意力图经过归一化和激活之后获得各自的空间注意力图SA1,SA2。接着将空间注意力图与对应的特征图相乘,获得一对空间增强特征FS1,FS2,相加之后获得最终的增强特征FCS。具体的计算过程为
式中,Maxpool表示最大池化层,Cat表示拼接(concatenation)操作,conv表示卷积层。
2.2 语义特征引导的多模态融合
为了利用点云和图像信息互补的优势,StanfordPRL-TRI(Chui 等,2021)中采用简单的相加操作将两个模态特征融合,这反而会引入大量的干扰信息。EPNet(Huang 等,2020)中的融合方法对图像中的干扰信息进行抑制,但未考虑到点云中也存在大量的背景点。为此,本文提出语义特征引导的多模态融合模块。该模块将点云特征、逐点图像特征和图像特征进行深度自适应融合,利用注意力机制对每个模态中的干扰信息进行抑制,以捕获点云和图像中的关键信息,结构如图3所示。
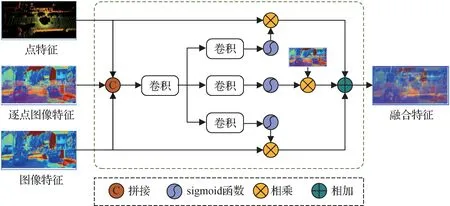
图3 语义特征引导的多模态融合Fig.3 Semantic feature-guided multimodal fusion
为了将点云和图像准确地匹配以便于融合,首先将点云映射到图像上,以获得逐点图像特征。具体来说,对于点云中的点P,将其与映射矩阵相乘可以得到该点在图像中的对应位置P′,具体为
式中,M为相机的内部参数。
在建立对应的关系后,由于投影点可能落在相邻像素之间,所以利用双线性插值计算图像上该点对应的语义特征,最终获得点云和图像对应的逐点图像特征。具体为
式中,Bi表示双线性插值函数,FP′表示采样位置P′的相邻像素的图像特征。
图像易受光照、遮挡等因素的影响,点云中存在大量的背景点,且两个模态数据之间具有差异性,简单地将它们相加或拼接会引入更多的干扰信息,所以在本文中利用注意力机制来抑制每个模态的干扰信息,以将它们进行自适应融合。如图3 所示,在映射到相同通道之后,首先将它们进行拼接得到特征Fcat,接着使用一系列卷积层来获取特征之间的相关性,经过sigmoid 函数之后获得各自的自适应权重,将自适应权重图和各自的原特征相乘之后获得各自的注意力特征,相加之后获得最终的融合特征FFU。具体融合过程为
式中,AttP表示点云特征对应得到的注意力图,AttI表示图像特征对应得到的注意力图,AttPWI表示逐点图像特征对应得到的注意力图。
2.3 多重信息感知数据关联
数据关联阶段,AB3DMOT(Weng 等,2020a)等方法仅使用IoU 进行关联,EagerMOT(Kim 等,2021)等方法仅使用欧氏距离进行关联,在复杂环境中效果不佳。本文设计多重信息感知亲和矩阵,将外观信息、IoU、欧氏距离和方向相似性等多重信息用于构建数据关联亲和矩阵,有效地解决了IoU 较低或为0,以及欧氏距离容易引起关联歧义等问题,减少了目标之间的身份切换以及轨迹碎片化,实现更加鲁棒的多目标跟踪。
如图1 所示,在获得融合的特征后,经过区域提议网络(region proposal network,RPN)获得3D 区域粗建议,然后额外引入与检测分支并行的嵌入分支。检测分支采用EPNet 中的区域循环网络(recurrent neural network,RCNN)进行边界框回归和目标分类,从而获取目标的位置信息。嵌入分支与重识别类似(re-identification,Re-ID),用于提取目标的外观信息,从第T-1 帧中选择M个维度为d的3D 建议,第T帧中选择N个维度为d的3D 建议,接着使用逐元素相减的方法将M个建议分别与N个建议相减,然后取绝对值,得到一个维度为d×M×N的张量,采用减法是因为将两个建议相减将获得它们之间的距离,间接表示了两个目标之间的相似性。对减法采用绝对值是为了让减法操作变得可交换,从而使模型更鲁棒,为节省计算量,采用1 × 1 的卷积将张量压缩成大小为M×N的矩阵R,矩阵R经过全连接层之后作为嵌入分支的输出,用于表示相邻帧目标之间的依赖关系。
1)亲和力计算。亲和力是数据关联中判断检测与轨迹是否匹配的主要参考信息。在数据关联之前,首先使用卡尔曼滤波预测第T-1帧中的轨迹在第T帧中的位置,即获得轨迹预测框。对于亲和度计算,同时使用了目标之间的外观亲和度和位置亲和度来构建所提出的多重信息感知亲和矩阵。
2)多重信息感知亲和矩阵。首先利用嵌入分支的输出经过softmax 函数排列之后作为目标之间的外观亲和度Aapp。然后利用轨迹预测框和检测框之间的IoU、欧氏距离计算目标之间的位置亲和度。因为相比于图像所在的2D空间中的目标,3D空间中的目标不遵循固定的方向,包含了方向属性,相对于垂直轴存在一定的旋转角度,因此引入了两个框的方向向量之间的归一化余弦距离,用于表示它们之间的方向相似性。位置亲和度矩阵的具体计算过程为
式中,E表示欧氏距离,a表示方向向量之间的归一化余弦距离。diag表示轨迹预测框和检测框的最小封闭矩形的对角线距离,BP和BD分别表示轨迹预测的边界框和检测的边界框,θP表示预测的目标运动方向,θD表示检测结果中目标的运动方向。
在获得外观亲和度矩阵Aapp和位置亲和度矩阵Apos之后,将其相加作为最终的多重信息感知亲和度矩阵MMIPAM,即
式中,β和γ为超参数,且β+γ=1。
数据关联的具体流程如图4 所示,在获得多重信息感知亲和矩阵MMIPAM之后,将其作为匈牙利算法的输入并完成轨迹和检测之间的匹配关联。对于匹配的检测和轨迹,对轨迹进行更新;对于未匹配的检测,将初始化为新的轨迹;对于未匹配的轨迹,将其保留τ帧,若在τ帧之内再次出现则对其更新,若未出现,则终止轨迹,至此完成多目标跟踪任务。
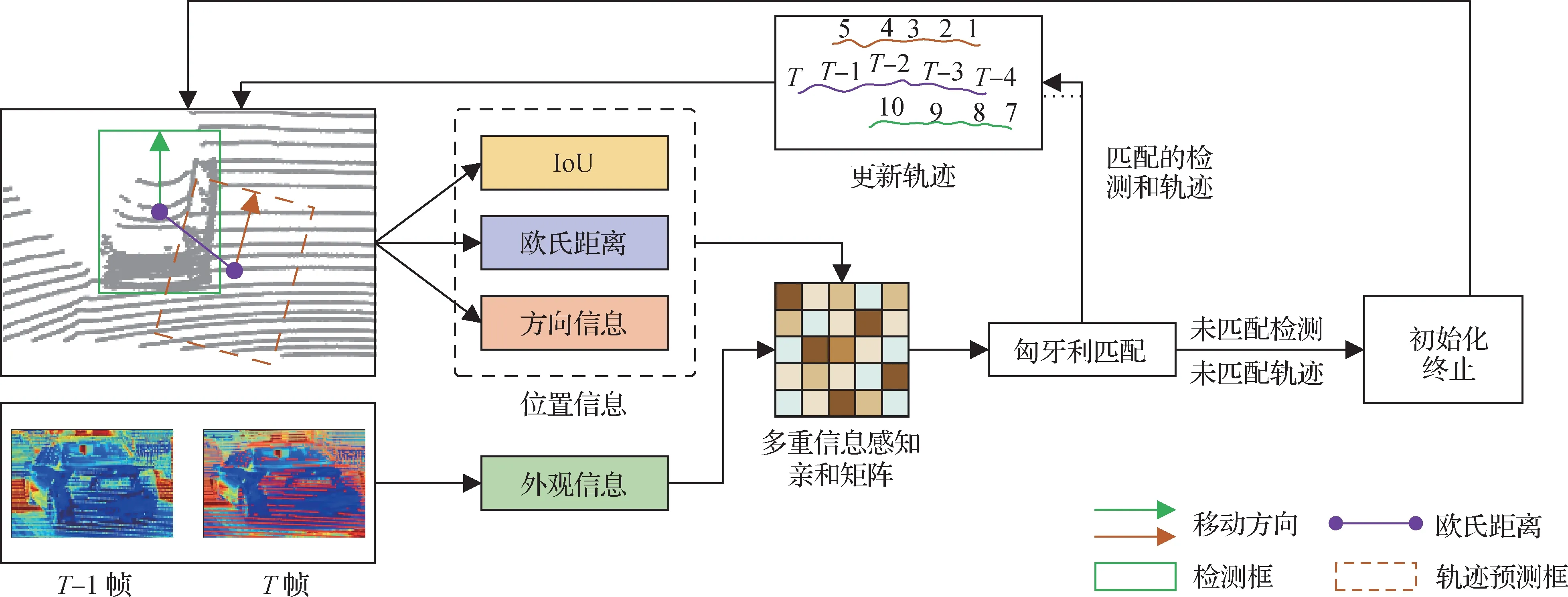
图4 多重信息感知数据关联流程图Fig.4 Flowchart of data association for multiple information perception
3 实 验
3.1 数据集和评估指标
3.1.1 数据集
KITTI 跟踪数据集(Geiger 等,2013)和NuScenes数据集(Caesar 等,2020)是主流的无人驾驶相关数据集,能够同时提供点云和相机图像数据,且所有数据都是在真实环境中采集的,所以为了验证提出方法的有效性,在KITTI 和NuScenes 数据集上训练和评估提出的方法,并与较先进的方法进行比较。KITTI 数据集由21 个训练场景和29 个测试场景组成,在训练和评估过程中,将21 个训练场景划分为11 个训练集和10 个验证集。NuScenes 数据集是规模更大的无人驾驶数据集,该数据包含1 000 个场景,每个场景的时长大约为20 s,其中训练集、验证集和测试集的数量分别为700、150 和150。相比于KITTI 数据集,NuScenes 数据集场景更加复杂,且包含的目标种类更多,且每一帧的数据由点云和6 幅覆盖360°全景范围的RGB图像组成。
3.1.2 评估指标
在KITTI 数据集上,使用最近提出的更高阶的跟踪准确度(higher order tracking accuracy,HOTA)作为主要指标,同时使用标准的CLEAR 指标(Bernardin 和Stiefelhagen,2008)对模型进行评估。主要包括多目标跟踪准确度(multi-object tracking accuracy,MOTA)、多目标跟踪精度(multi-object tracking precision,MOTP)、大部分跟踪到的目标(mostly tracked targets,MT)、大部分丢失的目标(mostly lost targets,ML)、误报总数(the total number of false positives,FP)、漏检总数(the total number of false negatives,FN)和身份切换的数量(number of identity switches,IDSW)。在NuScenes 数据集上,使用官方指定的指标对提出的方法进行评估,主要包括平均多目标跟踪准确度(average multi-object tracking accuracy,AMOTA)、平均多目标跟踪精度(Average multi-object tracking precision,AMOTP)、MOTA、FP、FN和IDSW,其中AMOTA是主要的参考指标。
3.1.3 实施细节
提出的方法采用主流的深度学习框架PyTorch实现,并在实验室配有的服务器上训练和测试提出的模型,服务器的具体配置信息如表1 所示。所提出的方法采用点云和图像作为输入,其中输入点的数量为16 384,图像的分辨率为1 280 × 384像素,采用自适应矩估计(Adam)对网络进行优化,初始的学习率设置为0.002,权重衰减系数和动量分别设置为0.001 和0.9。在KITTI 和NuScenes 数据集上,对应的训练轮次分别设置为70 和50,批处理大小batch分别设置为4和2。

表1 系统环境配置Table 1 System environment configuration
3.2 消融实验
为了验证提出的三维多目标跟踪方法中各个模块对跟踪性能的影响,在KITTI 验证集上,保证其他模块相同的情况下针对HSAM、SFGMF 和MIPAM 等各个模块进行了消融实验。
1)混合软注意力模块(HSAM)。在网络中删除、添加或替换混合软注意力特征增强模块,以验证该模块的有效性,如表2 所示,在对提取的图像语义特征应用注意力模块HSAM 后,HOTA 提升了2.89%,MOTA 提升了3.22%。SE、BAM 和CBAM 等先前提出的注意力机制均能不同程度提高模型性能,但是HSAM 对模型性能提升更明显。与3 种注意力机制中性能最好的CBAM 相比,HOTA 和MOTA分别提升0.92%和0.98%,证明了提出的混合软注意力特征增强模块是更有效的,即可以对各个卷积块提取到的图像语义特征进行增强。
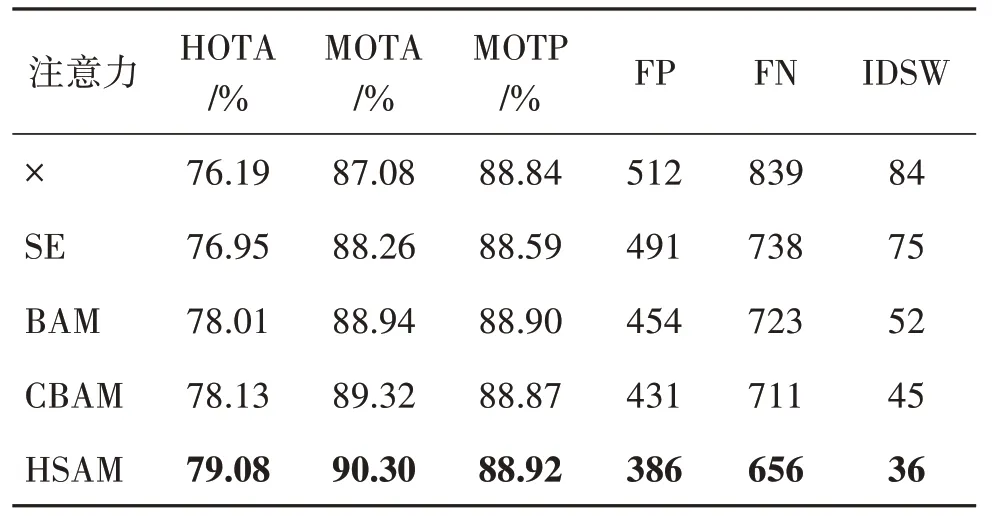
表2 混合软注意力消融实验结果Table 2 Hybrid soft attention ablation experiment results
2)语义特征引导的多模态融合模块(SFGMF)。为了验证提出的多模态特征自适应融合模块在融合点云和图像特征方面的有效性,如图5 所示,本文设计了不同的融合策略。
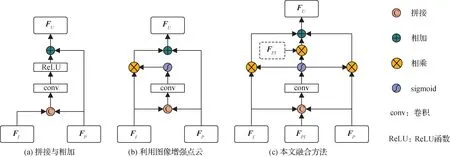
图5 多模态特征融合方法对比Fig.5 Comparison of multimodal feature fusion methods
图5(a)中的融合方法为将图像特征FI和点云特征FP进行简单地拼接和相加。图5(b)中的融合方法,首先将图像特征和点云特征进行拼接,然后利用注意力机制来抑制图像中的干扰信息,最后将增强后的图像特征和原始点云特征相加得到融合后的特征FU。图5(c)为本文提出的融合方法,除了点云特征和图像特征之外,还引入了逐点图像特征FPI,将其拼接之后,利用注意力机制来抑制每个模态的干扰信息,分别利用各自获得的注意力权重与原始特征相乘来得到增强的特征,最后将增强的特征相加得到融合后的特征。不同融合策略的实验结果如表3所示。表3的实验结果表明,跟踪性能容易受到多模态特征融合策略的影响,当使用图5(a)中的融合方法时,性能表现最差,这是因为未能有效地利用点云和图像中的特征,因为点云和图像中都存在一定的干扰信息,比如图像易受光照等因素影响,所以执行简单的拼接和相加操作可能会引入更多的干扰信息。相比于图5(a)中的方法,图5(b)中的多模态特征融合方法利用注意力机制对图像特征中的干扰信息进行抑制,将图像中的重要特征与原始点云特征进行融合,跟踪性能取得了一定的提升,但是该方法并不是最优的融合方法,因为在融合过程中,忽略了点云中存在的大量背景点等干扰信息。相比于上述两种方法,图5(c)的方法(提出的方法)将点云特征、图像特征和逐点图像特征进行融合,并利用注意力机制对3 类特征中的干扰信息进行抑制以提取出各自模态中的重要信息。相比于图5(a)的方法,HOTA 和MOTA 分别提升了6.01%和5.86%;相比于 图5(b)的 方法,HOTA 和MOTA 分别提升了1.09%和1.90%。从对比结果可以看出,提出的融合方法取得了更好的跟踪性能,在融合点云和图像信息方面更加有效。
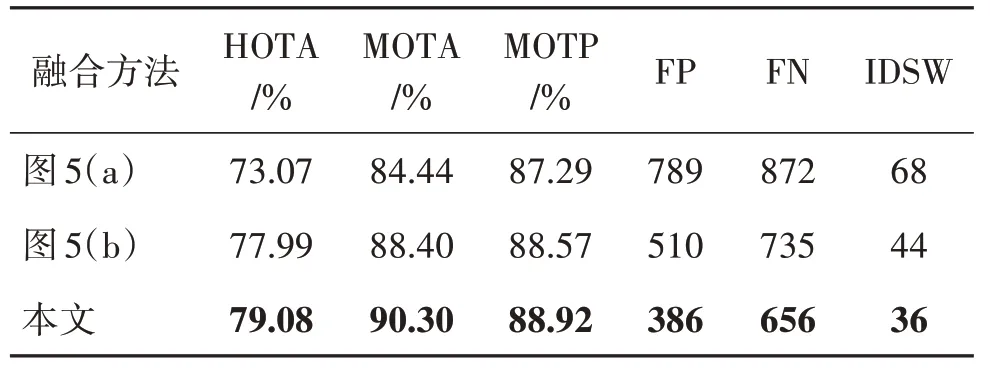
表3 多模态特征融合方法消融实验结果Table 3 Ablation experiment results of multimodal feature fusion method
3)多重信息感知亲和矩阵(MIPAM)。数据关联是三维多目标跟踪中最核心的部分,其关联的结果直接决定了跟踪的结果。目标的外观信息和位置信息是用来判断检测和轨迹是否匹配的主要信息。在仅基于点云的方法中仅使用目标的位置信息,无法检测和跟踪远距离的小目标;在基于点云和图像的三维多目标跟踪方法中,虽然大多数方法都采用了目标的外观信息和位置信息,但是利用效果并不佳;在基于IoU 匹配的方法中,通常对检测框和轨迹预测框之间的IoU 设置较高的阈值来判断检测和轨迹是否属于同一目标,然而该类方法忽略了IoU 较低或为零的情况;在基于欧氏距离的方法中,由于仅使用了目标中心点的位置信息,忽略了大多数的几何特征,容易造成跟踪的歧义性。
提出的方法中,在考虑IoU、欧氏距离、外观信息的同时,还额外考虑了目标之间方向的相似性,有效地提高了检测和轨迹关联的成功率。为了验证信息感知亲和矩阵的有效性,在消融实验中,构建了基于 欧氏距 离、IoU、IoU 和外观信息(appearance,APP)、信息感知亲和矩阵(MIPAM)等不同的亲和矩阵用于数据关联,结果如表4所示。
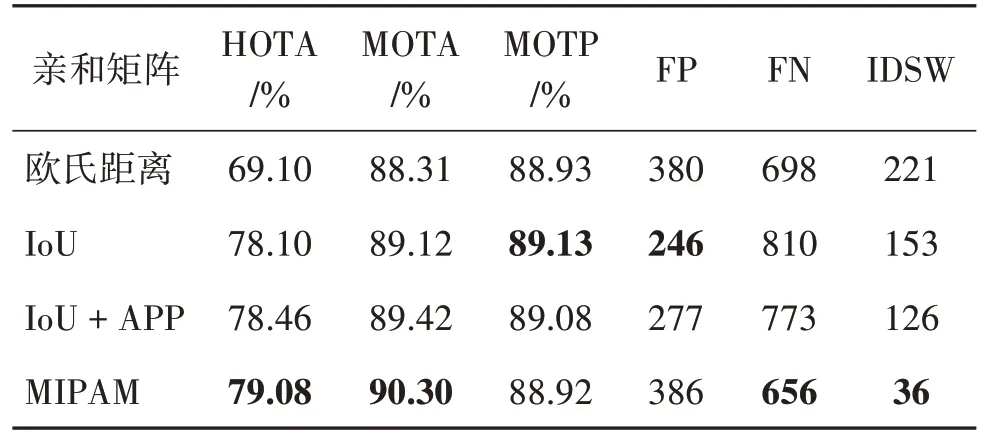
表4 亲和度矩阵消融实验结果Table 4 Affinity matrix ablation experiment results
从表4 中可以看出,提出的信息感知亲和矩阵在多个指标上均优于其他的亲和度矩阵关联方法。基于欧氏距离的方法整体性能表现最差。相比于欧氏距离的方法,基于IoU 的方法取得了很大的性能提升。在IoU 的基础上,引入目标的外观信息,可以进一步提升跟踪性能,这说明外观信息对于跟踪远距离的小目标具有重要的作用。相比于如前所述的3 类方法,提出的信息感知亲和矩阵取得了最好的跟踪性能,HOTA和MOTA分别为79.08%和90.30%,相比于欧氏距离的方法,分别提升了9.98%和1.99%。相比于IoU 的方法,HOTA 和MOTA 分别提升0.98%和1.18%。由此可见,本文提出的用于关联检测和轨迹的信息感知亲和矩阵是非常有效的,更加适合用于处理三维多目标跟踪任务。
4)模块间的消融实验。以EPNet(Huang 等,2020)和基于IoU 度量数据关联的方法作为基线,并依次将HSAM、SFGMF 和MIPAM 等模块添加到基线中进行实验,结果如表5 所示。从表中可以看出,每个模块都能以不同幅度提高模型的性能,证明了各个模块的有效性,将提出的3 个模块都加到基线中时,性能达到了最优,表明提出的方法是有效的。

表5 各个模块的消融实验结果Table 5 Ablation experiment results of each module
3.3 实验结果
3.3.1 定量评估
对提出的方法采用KITTI 和NuScenes 数据集进行评估,并从多个指标上与现有的三维多目标跟踪方法进行比较。
KITTI 数据集上的评估结果如表6 所示,与具有竞争性的方法相比,提出的方法在综合性能方面表现最优。具体地,HOTA 和MOTA 等主要指标取得了最优的结果,分别为76.94%和88.12%,比仅使用点云的AB3DMOT 方法提高了6.95%和4.28%,相较于纯图像的LGM(local-global motion)方法,分别提高了3.8%和0.52%,体现了多模态融合三维多目标跟踪的优势。与同样使用点云和图像作为输入,但仅使用欧氏距离进行关联的EagerMOT方法相比,HOTA 和MOTA 分别提高了2.55%和0.3%,IDSW减少了72,体现了多重信息感知亲和矩阵的有效性。与对比方法中先进方法DeepFusionMOT 相比,HOTA 和MOTA 分别提高了1.48% 和3.49%,但DeepFusionMOT 在IDSW 方面表现更出色,相较提出的方法减少了83,这是因为该方法使用了先进的2D和3D 单模态检测器,并同时使用2D 和3D 轨迹状态信息进行四阶段的数据关联,但仅适用于简单的场景,当面对点云较为稀疏或严重遮挡的复杂场景时,检测器可能会失效,造成场景不适应的问题。提出方法的每秒传输帧数(frame per second,FPS)为92帧/s,与排名第2 和第3 的方法较接近,但是相比排名第1的方法,仍然需要改进。此外,虽然提出的方法在FP、FN 和IDSW 等几个指标方面并未取得最优结果,但是在所有方法中也处于排在前面的位置,这足以表明提出的方法在处理三维多目标跟踪任务方面是有效的。
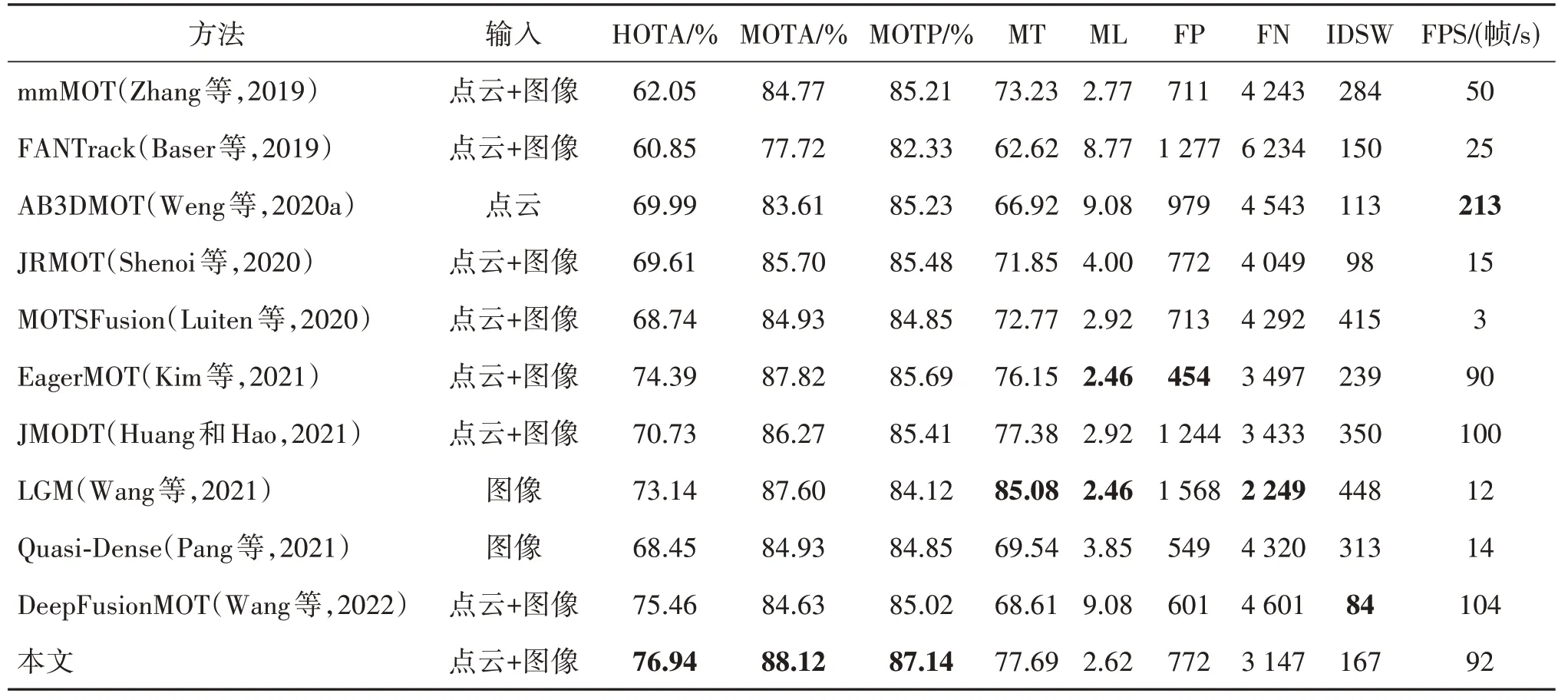
表6 KITTI基准数据集上的评估结果Table 6 Evaluation results on the KITTI benchmark dataset
NuScenes 数据集上的评估结果如表7 所示,无论是与纯点云的方法相比,还是与同时使用点云和图像的方法相比,提出的方法均表现出最优的综合性能,AMOTA 和MOTA 分别为68.3%,57.9%。相比于先进的纯点云方法SimpleTrack,AMOTA 和MOTA 分别提高了1.5%和1.3%,与EagerMOT 相比,AMOTA 和MOTA 分别提高了0.6%和1.1%,再次体现了多模态融合以及利用多重信息进行关联的跟踪优势。与DeepFusionMOT 方法相比,AMOTA 和MOTA 分别提高了4.8%和4.6%,IDSW 减少了一半,虽然此方法在KITTI 数据集上IDSW 优于提出的方法,但在更加复杂的NuScenes 数据集上的结果并不佳,表明提出的方法具有更强的场景适应能力和更好的跟踪鲁棒性。虽然提出的方法整体性能指标表现是最优的,处理速度为27 帧/s,但在FP、FN 和IDSW 等指标上,性能表现并没有达到理想的状态,与各个指标排名第1 的方法相比,仍然有提升空间,所以进一步提升网络对复杂环境的处理能力和速度仍是未来研究的目标。
3.1.2 定性分析
为了进一步验证提出的方法在各种复杂场景中的鲁棒性,将跟踪结果进行可视化,如图6 和图7 所示。其中,图6为KITTI验证集中随机选取一个场景的可视化结果,图7为KITTI测试集中随机选取一个场景的可视化结果。图6和图7中的第1行和第3行是图像中的跟踪可视化结果,第2行和第4行是对应点云中的跟踪可视化结果,跟踪结果用不同颜色且带有编号的三维边界框表示。

图6 验证集上的可视化结果Fig.6 Visualization results on the validation set

图7 测试集上的可视化结果Fig.7 Visualization results on the test set
在图6 中,92 号和103 号目标属于远距离点云较稀疏的小目标,95 号属于被严重遮挡的目标,170帧中的55 号目标在180 帧中因为遮挡消失在视野中,在185 帧再次出现在视野中,但是没有发生身份切换。在图6 中,106 号目标和122 号目标也属于远距离点云较稀疏的小目标,9 号和45 号属于被严重遮挡的目标。可以看出,无论是对于远距离的小目标、被严重遮挡的目标,还是在跟踪过程中消失后又再次出现的目标,提出的方法都能准确且稳定地跟踪到它们,且没有发生身份切换,体现了多模态特征融合以及信息感知数据关联是有效的,证明了提出的方法在目标跟踪方面的优势。此外,图6 为直线行驶的场景,图7 为经过交叉路口的驾驶场景,与图6 相比场景更加复杂,这表明无论是在场景相对简单的验证集上,还是在复杂的测试场景中,提出的方法都能表现出较好的跟踪性能,再次证明了提出的方法具有更好的跟踪鲁棒性。
4 结论
本文提出一种图像与点云多重信息感知关联的三维多目标跟踪方法,旨在解决三维多目标跟踪中存在的挑战,即点云稀疏导致远距离的小目标被漏检、目标之间遮挡导致身份切换以及现有关联方法导致轨迹碎片化等问题。提出的方法在KITTI 和NuScenes数据集上均取得了优异的跟踪性能。实验结果表明,提出的混合软注意力、语义特征引导的多模态融合和多种信息感知亲和矩阵等模块均能有效提升跟踪性能,整体上能有效解决远距离小目标被遗漏、目标之间身份切换和轨迹碎片化等问题,提高检测和轨迹的数据关联成功率,相比于现有的具有竞争性的方法,提出的方法具有更先进的跟踪性能,更加适合应用于自动驾驶环境感知、智慧交通和智慧城市等场景。
本文方法虽然提高了目标跟踪的准确度,取得了更先进的跟踪性能,但是目前该方法在建立点云和图像之间的对应关系时,根据数据集中提供的校准参数来进行一对一映射,而校准参数对传感器的时间和空间同步非常敏感,容易造成激光雷达和相机的错位,导致点云和图像之间无法准确对齐。同时,自动驾驶汽车对环境感知的精度和速度都有着极高的要求,而本文方法处理速度相对较慢,跟踪精度上仍然具有一定的提升空间。因此,如何有效地实现点云和图像之间的精确几何对齐,提高模型的处理速度和跟踪准确度将是未来研究的重点。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
新世纪智能(数学备考)(2021年9期)2021-11-24
当代陕西(2019年15期)2019-09-02
学苑创造·A版(2018年11期)2018-02-01
传媒评论(2017年3期)2017-06-13
读者(2017年5期)2017-02-15
第二课堂(课外活动版)(2016年2期)2016-10-21
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
