
融合注意力机制与多检测层结构的伪装目标检测
2024-01-22 10:26赖杰彭锐晖孙殿星黄杰
中国图象图形学报 2024年1期
赖杰,彭锐晖*,孙殿星,2,黄杰
1.哈尔滨工程大学青岛创新发展基地,青岛 266000;2.海军航空大学信息融合研究所,烟台 264001
0 引言
伪装目标检测是军事领域中的重要研究内容(李倩,2011),其核心内容是从复杂背景环境中识别出伪装目标的类别信息和位置信息(Guo 等,2019),是提升战场信息感知能力的重要一环,一直以来受到各个国家的广泛关注。与常规的显著性目标不同,伪装目标代表的是一类语义信息不足、特征匮乏的非显著性目标(余楚恒,2020),这类目标与周围背景环境融合度较高(梁新宇 等,2021)、在图像中所含像素信息较少、分辨率低且视觉边缘性差,给目标检测任务带来了巨大的挑战。
伪装目标作为目标检测对象之一,其检测方法随着目标检测算法变化而不断改进。传统伪装目标检测算法更多的是通过手工提取目标特征来实现检测与识别,如,Tankus和Yeshurun(2001)提出了一种直接应用于灰度图像的算子Darg,该算子可用于凹凸等三维物体的伪装破坏,从而实现对伪装目标的检测;武国晶等人(2015)提出了一种改进的三维凸面检测算法,通过引入三维凸面检测算子,实现了迷彩伪装目标的检测;Bhajantri 和Nagabhushan(2006)提出了一种对伪装目标识别的方法,该方法先采用基于共生矩阵的纹理特征算法在图像的一个小区域块内进行计算,然后利用聚类分析检测缺陷部分,最后使用分水岭分割算法通过背景与缺陷之间的纹理相似性实现了伪装目标的检测。综上所述,传统的伪装目标检测方法一般基于图像颜色、边缘或纹理等特征,利用图像分割、支持向量机等方法实现目标检测。存在过分依赖手工特征、检测效率低以及鲁棒性差等问题,难以大规模应用于真实战场中伪装目标的快速检测。
随着算力和数据的不断提升,目标检测进入到以卷积神经网络(convolutional neural network,CNN)为核心的深度学习时代(闫战伟,2020)。得益于深度学习的不断发展,基于CNN 的目标检测算法也开始应用到伪装目标检测中。如吴涛等人(2022)提出了一种基于改进YOLOv3(you only look once version 3)网络的伪装目标检测算法,通过将残差网络的级联方式由单级连跳改为多级连跳、同时在网络中加入注意力模块的方式改进了原网络,解决了传统伪装检测算法效率低下的问题,改进后的网络平均精度均值(mean average precision,mAP)提高了4.35%;王杨等人(2021)通过增加注意力机制凸显待检测目标的语义信息、增大原有的聚合网络的检测尺度、使用非对称卷积模块强化目标的语义信息等方式改进了YOLOv5 算法,提升了原网络对于伪装目标的检测精度;梁铭峰和李蠡(2021)提出了一个基于生成对抗网络去模糊网络模块与YOLO 相结合检测网络(blur YOLOv5,BL-YOLOv3),该网络使用生成对抗网络对图像进行预处理,保留图像中高质量纹理信息,生成接近真实场景的清晰图像,从而实现对战场中的模糊目标的精确检测;谭湘粤等人(2022)提出了一种基于递进式特征增强聚合的伪装目标检测算法,在COD10K(camouflaged target detection 10k)数据集上取得不错的效果。
Transformer(Vaswani 等,2023)最初应用于自然语言处理领域,采用了带有注意力机制的编码器—解码器模型,解决了CNN 在处理序列时的各种问题。由于Transformer 可以建模图像的全局依赖关系,能够更加充分地利用上文信息,已经逐步应用在计算机视觉领域,相较于CNN 具有更强的泛化能力。随着Carion 等人(2020)提出了一种新型的基于Transformer 的目标检测框架DETR(detection Transformer),奠定了Transformer 在目标检测任务中的重要地位;Liu 等人(2021)提出Swin Transformer 算法,进一步提升了Transformer 在目标检测领域的实用性。随着Transformer 技术的逐步成熟,有学者便将Transformer 应用到伪装目标检测上。如刘珩等人(2022)提出一种基于Transformer的图像处理与多头自注意力机制相结合的目标检测方法,实现了迷彩伪装目标的有效检测。
综上所述,基于CNN 的伪装目标检测方法大都是在当前主流的目标检测算法基础之上,改进网络结构,使用一些有效的tricks来增强网络对于目标特征的提取,在一定程度上提升了检测速度和检测精度。基于Transformer的伪装目标检测方法对特征提取能力更强、信息整合效果更好,但数据吞吐量较大、计算消耗量巨大,很难大规模应用。此外,在最终伪装目标检测算法评价时,仅用检测精度或检测速度这类单一指标,通常没有考虑到军事目标漏警带来的巨大危害,未能很好地反映伪装目标实际检测效果。
本文以检测精度和速度性能均衡的YOLOv5 为基础,提出了一种基于多检测层与自适应权重的伪装目标检测算法(algorithm for detecting camouflage targets based on multi-detection layers and adaptive weight,MAH-YOLOv5),解决了伪装目标检测精度低、漏检率大的问题。所做工作如下:1)在网络的预测头部设计了一个非显著目标检测层,通过4 层结构增强网络对特征信息不足目标的感知能力;2)在网络的特征提取骨架中融合注意力机制,调整卷积网络对于待检测目标特征提取的权重分配,提升伪装目标的识别概率;3)使用多尺度训练策略,在丰富数据集的同时提升目标检测模型的鲁棒性;4)定义了用于军事伪装目标检测的漏警和虚警指标,弥补单一评价指标不能更全面地满足实际战场需要的不足,按照不同分项指标的重要程度提出了伪装目标综合检测能力指数。
1 MAH-YOLOv5算法
本文在YOLOv5 算法网络基础上,通过在网络预测头部增加非显著目标检测层、在特征提取骨干中融合双通道注意力机制的方式改进了YOLOv5 算法,提出了用于伪装目标检测的MAH-YOLOv5算法。
1.1 非显著目标检测层
YOLOv5 算法一共有s、m、l 和x 共4 个版本(周福欢和柴鑫雨,2022),仅模型深度和宽度不同,其他网络结构完全相同。其中YOLOv5s 是系列中深度最小、特征图宽度最小的网络(刘元峰 等,2022),其他版本的深度和宽度依次变大。本文所用的数据集相对来说并不复杂,为了防止网络过拟合,选用模型参数量较小的YOLOv5s 作为基础网络。YOLOv5由输入端(Input)、特征提取网络(Backone)、特征融合网络(Neck)和多尺度预测(Head)4 部分组成(谈世磊 等,2021)。Input使用了数据增强、自适应锚框计算和自适应图像缩放,提升数据集质量,增大网络对非显著目标的检测效果以及整体的泛化能力。Backbone 环节包 括Focus、CBS(cross-stage backbone)、CSP(cross stage partial network)、快速空间金字塔池化(spatial pyramid pooling with feature pyramid network,SPPF)等模 块,其中,Focus 由 切片(slice)、拼接(concat)和CBS 组成,CBS 由卷积(convolution,Conv)、批量归一化(batch normalization,BN)和激活函数(sigmoid-weighted linear unit,SiLU)组成,CSP 由CBS、残差单元(residual unit,Resunit)和Concat 组成,SPPF 由CBS、最大池化(MaxPool)和Concat 组成,目的是强化网络对于图像特征信息的获取能力。Neck 采用的是FPN+PAN(feature pyramid network,FPN;path aggregation network,PAN)的结构。FPN 为自顶而下的特征金字塔,增强了语义信息但丢失了定位信息。通过在FPN后添加一个自下而上金字塔——PAN,将底层的定位信息传递上去,二者结合保证了特征信息的完善。Head 使用bounding box 损失函数和非极大值抑制(nonmaximum suppression,NMS),进一步提升了网络的预测能力。YOLOv5 网络针对常见的通用目标,设置了3个检测层。当输入图像尺寸为640 × 640像素时,80 × 80的检测层可检测大小在8 × 8像素以上的目标,40 × 40的检测层可检测大小在16 × 16像素以上的目标,20 × 20的检测层可检测大小在32 × 32像素以上的目标。即YOLOv5 通过以上3 个检测层能够满足常规目标的检测任务需求,实现了大、中、小目标的检测。
由于信息的敏感性,军事目标伪装数据通常极难获得,数据集存在实例较小、尺度不一等问题,且部分伪装背景下的目标在图像中的像素占比极低,这使得YOLOv5 网络对于这类目标检测的检测精度低、虚警率高,因而在YOLOv5 多尺度预测头中设计了一个160 × 160 大小的非显著目标检测层,可检测大小为4 × 4 以上的目标。改进之后的网络结构如图1 所示,其中Head 中红色虚线框就是所设计的非显著目标检测层。结合其他检测层,4 层的结构可以应对小样本数据集中目标尺寸急剧变化带来的不利影响。添加的新检测层是从低级别、高分辨率的特征图生成,因此该特征图对像素占比低的目标更加敏感。同样地,4 层结构也会带来计算和存储之上的消耗,但网络对于特征信息不足目标的检测效果得到了提高。
1.2 CBAM注意力机制
常规卷积神经网络在提取目标特征时对每部分分配了相同权重大小,不能专注于有效特征的提取,不仅得到无效特征,而且还会造成资源的浪费。注意力机制模仿人类视觉注意特点,将焦点集中到有用信息上(Nguyen 等,2020)。本质上注意力机制就是一种资源分配机制,在神经网络中是通过自适应调节权重来获取感兴趣目标更多的特征信息,因而注意力机制的引入能够极大提高网络对于图像的处理效率、准确度和速度(任欢和王旭光,2021)。
为解决伪装目标检测精度低、漏检率大的问题,使卷积网络更加关注于待检测目标,本文使用了一种双通道注意力机制CBAM(convolutional block attention module)(Woo等,2018),能够自适应调节卷积网络权重配比,结构如图2所示。
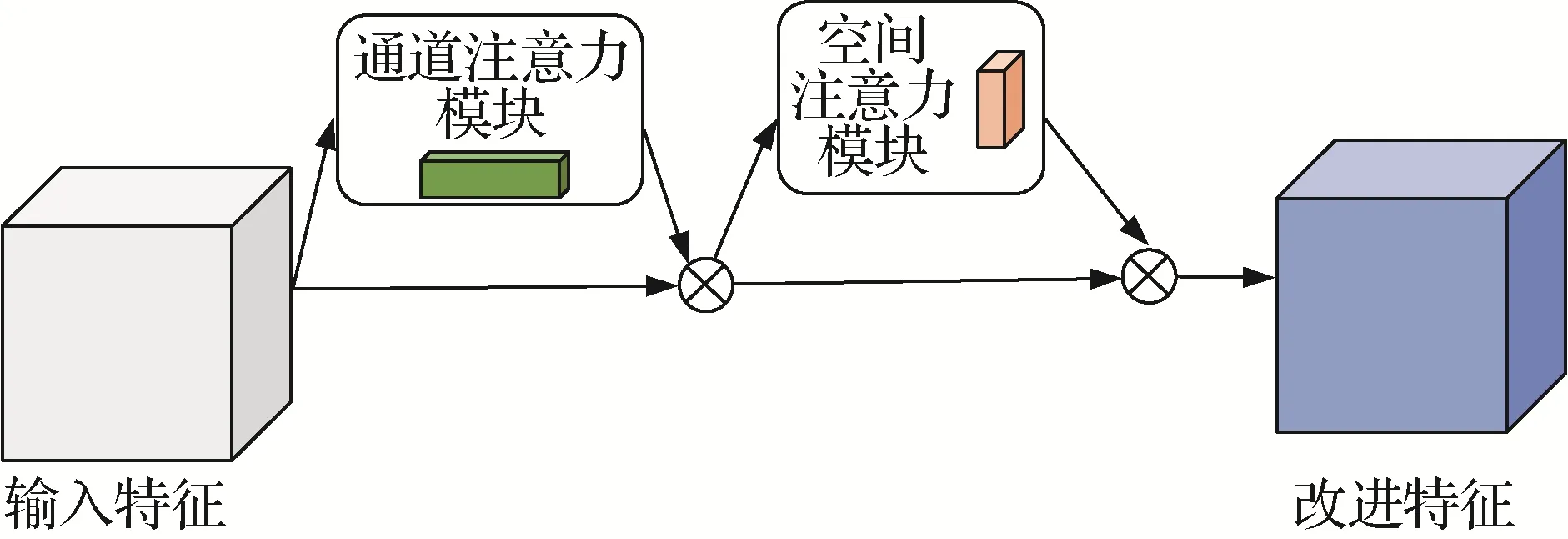
图2 CBAM注意力机制通道图Fig.2 CBAM attention mechanism channel diagram
该机制由两个不同维度的模块组成,分别是通道注意力模块(channel attention module)和空间注意力模块(spatial attention module)(赵兴运和孙帮勇,2022)。空间注意力可使神经网络更加关注图像中对分类起作用的像素区域而忽略其他无关紧要区域;通道注意力则用于处理特征图通道的分配关系。CBAM 对给定的特征图从通道与空间两个维度上进行注意力特征融合,最大程度地节省了参数和计算力,轻量化程度高,而且易于集成到其他网络结构中。经过CBAM 后,新的特征图将得到通道和空间两个不同维度上的注意力权重,大大提高各个特征在通道和空间上的联系,更加有利于提取目标的有效特征,从而提高网络对伪装目标的检测准确率。
具体计算流程如下:首先输入特征与其通过一个通道注意力机制模块之后得到的结果进行加权,然后经过一个空间注意力模块,再次进行一次加权得到最终的改进后特征。其中通道注意力结构如图3 所示,该通道首先通过平均池化和最大池化将特征图在空间维度压缩得到一个一维矢量,然后将压缩后的矢量送入多层感知器进行参数共享,继而对感知器输出的结果进行合并、求和,最后通过激活函数产生通道注意力图。具体为
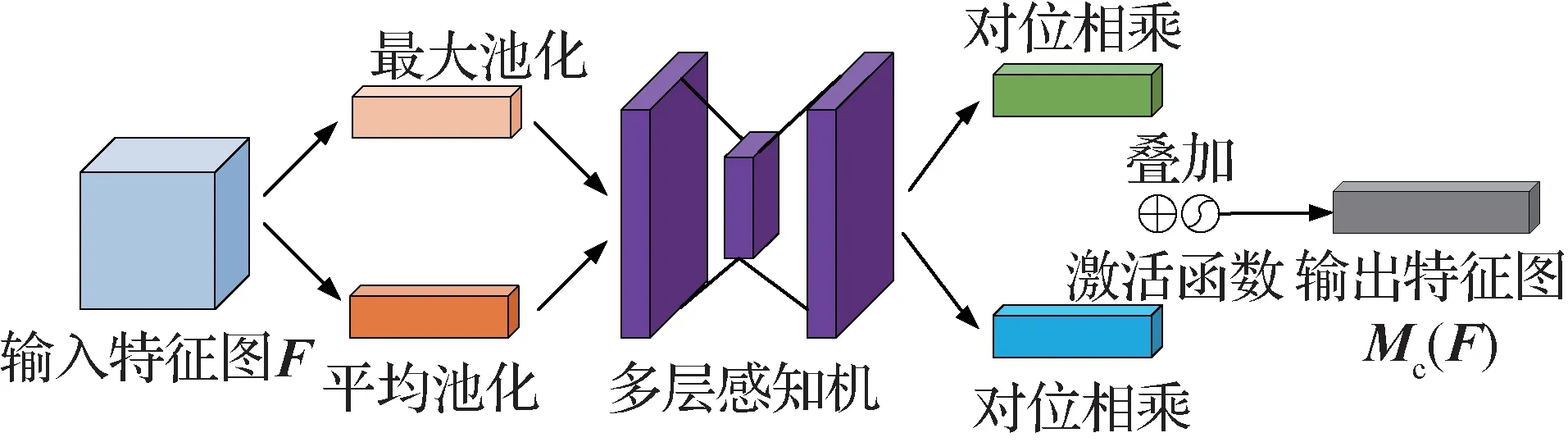
图3 通道注意力机制结构图Fig.3 The structure of the channel attention mechanism
式中,F为输入特征图,δ为sigmoid 激活函数,MLP为多层感知机,AvgPool()为平均池化,MaxPool()为最大池化。
空间注意力结构如图4 所示,该通道首先依次对输入的特征图进行最大池化和平均池化,并将得到的两个特征图合并,再利用卷积层提取合并后的特征图,最后通过一个sigmoid 激活函数输出空间注意力特征图。具体为
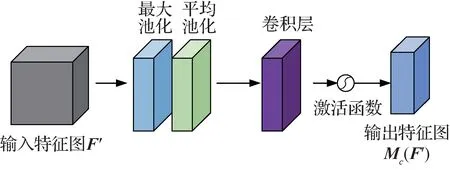
图4 空间注意力结构图Fig.4 Spatial attention structure diagram
式中,F′为输入的特征图,δ为sigmoid 激活函数,f为卷积层运算,AvgPool()为平均池化,MaxPool()为最大池化。
2 实验验证
采用课题组收集的军事伪装目标数据集进行所提算法的实验验证。实验平台主要环境配置如下:AMD R7 6800H CPU,16 GB RAM,Nvidia GeForce RTX3060 6 GB GPU,win11 专业版操作系统,python3.9.12 语言,CUDA11.3 并行计算架构,CUDNN7.6.5 深度神经网络加速库,Pytorch1.11.0深度学习框架。
2.1 军事伪装目标数据集
军事伪装目标暂无可用的公开数据集,为解决这一难题,课题组前期组织了数据采集工作,收集了6 种尺寸不一的军事模型,包括卡车(truck)、火箭车(rocket_car)、坦 克(tank)、装甲车(armored_ vehicle)、急救车(ambulance)和火炮(howitzer),模型尺寸信息如表1 所示。分别在迷彩伪装网、草丛和草坪等环境下,利用6 种军事目标模型采集了具有一定伪装效果的可见光图像作为数据集。本文所制作的数据集由4 300 幅图像组成,图像分辨率为1 920 × 1 080 像素。每幅图像中至少有1 种类别目标,目标数量信息如表2 所示。目标在图像中尺度不一,各类目标尺寸信息如表1所示。然后按照3∶1的关系划分训练集(3 200)、验证集(1 100),并使用Labelimg 标注软件标注所有的数据,各个类别的标签数量如表3所示。
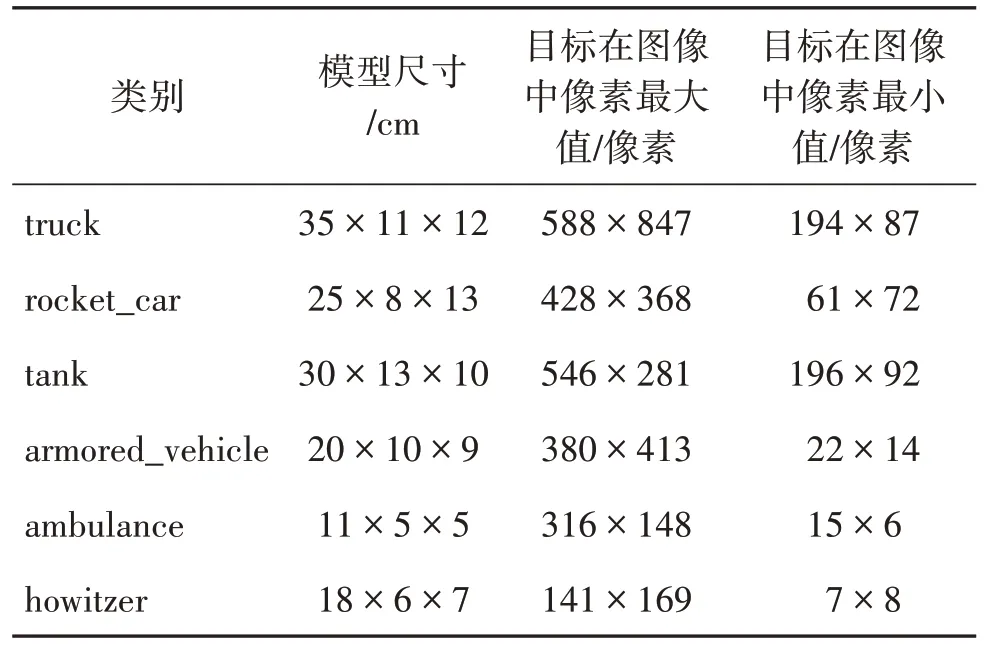
表1 模型尺寸及目标在图像中的像素尺寸Table 1 Model size and target pixel size in the image

表2 不同目标个数所在图像总数Table 2 Total number of images with different number of targets
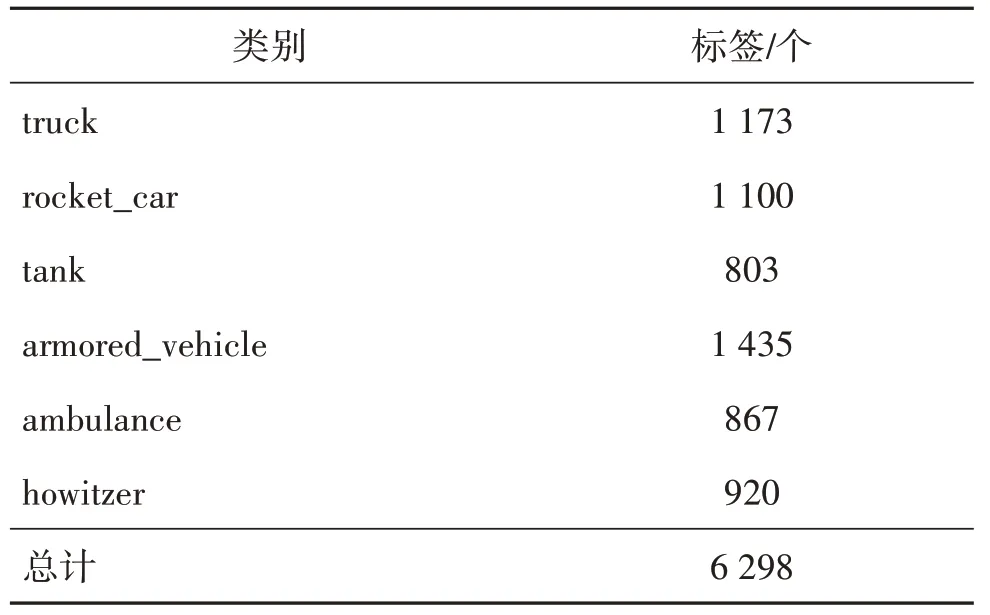
表3 标签个数Table 3 Number of labels
对于可见光图像来说,图像的质量与外界环境有很大关系,如光照、气温等因素会对最终的成像效果产生影响。所以在采集数据时选择了晴天和阴天两种天气,分别在早、中、晚不同时段进行数据采集,丰富数据集类型、增强数据质量,提升模型对于不同环境的泛化能力。此外,本文选择拍摄的环境与军事目标的外表颜色极为接近,最大程度提升目标的伪装效果,部分伪装目标如图5所示。

图5 部分伪装目标Fig.5 Part of the camouflage target
2.2 实验设置
2.2.1 评价指标
目标检测模型的好坏是通过评价指标来定量评判的,常用的评价指标包括精度评价指标和检测速度评价指标。其中精度评价指标有精确度(precision)、召回率(recall)、交并比(intersection-overunion,IOU)、平均精度(average precision,AP)和平均精度均值(mean average precision,mAP);检测速度的评价指标是通过每秒检测的帧数(frames per second,FPS)来表示。本文选用mAP 和FPS 两种不同类型的指标来评判网络模型的性能。目标检测的结果有4 种可能表示,分别是真阳性(true positive,TP)、假阳性(false positive,FP)、真阴性(true negative,TN)和假阴性(false negative,FN)。4 种检测结果含义如表4 所示,由此,可得出精确度和召回率的计算式为

表4 检测结果分类及其含义Table 4 Classification of test results and their meaning
由精确度P和召回率R可绘制P-R曲线,通过曲线可求得AP,即曲线下方的面积。具体为
本文所用的精度检测指标mAP 可用来评价模型的好坏,具体为
式中,m表示目标类别总数,APi表示第i个类别目标的精确度。
除此之外,使用GFLOPs(giga floating operation per second)和Parameter两类指标对模型进一步深入评估。其中,1个GFLOPs表示每秒10亿次的浮点运算,数值越大意味着每秒处理的数据量越大,可用来衡量模型的复杂程度;而Parameter 表示模型训练中所需要训练的参数总数,只与网络结构有关,用来衡量模型的大小。
由于军事背景的特殊性,仅从目标检测模型的mAP、FPS 来评价军事伪装目标识别算法性能无法满足实际应用要求,须将算法的性能放在相应的军事应用背景下进行评估。在比较了雷达目标检测中的漏警与虚警概念后(Quan 等,2020),建立了军事伪装目标检测的漏警(miss alarm,MA)和虚警(false alarm,FA)指标,具体为
式中,Ni是第i幅图像中所含伪装目标个数,Di为检测算法对第i幅图像中预测正确的伪装目标个数,Ei为检测算法将第i幅图像中非伪装目标识别为伪装目标的个数,n为参与检测的图像总数。
在伪装目标检测算法性能实际评估中,若将各个评估指标独立评判,得到的结论往往比较孤立,难以从整体和系统的角度对其评价,无法定量描述算法的综合性能。为了统一量纲,更好地衡量不同指标下目标检测算法的性能,上述部分指标需要进行正相关化和归一化。其中,漏警率(MA)、虚警率(FA)作为评价指标之一,取值范围为[0,1],值越小表示伪装目标检测算法性能越好,因此需对其进行正相关处理,具体为
此外,需对每秒检测帧数(FPS)进行线性归一化。考虑到不同算法在目标检测速度上差异较大,得到的FPS 值数据分化程度较大,因此选用对数非线性归一化方法通过将原本离散的数据限制在[0,1]内,该方法可以避免极端值对最终评价结果的影响,具体为
式中,Wα为权重大小,可根据不同指标在伪装目标检测中所占权重的大小Wα调整对不同性能的关注度,且该指标具有很好的开放性,能够根据实际需要不断拓展分项指标,其取值范围为[0,1]并满足式(13);λα为指标分项,分别表示等指标,N为分项指标的总数量。
2.2.2 训练参数设置
实验过程中选择官方提供的YOLOv5 预训练权重,可以在训练开始使模型参数得到一个好的初始化,有助于网络的训练学习。优化器选择SGD(stochastic gradient descent),实验输入的图像大小调整为640 × 640 像素,初始学习率、动量因子、权重衰减系数分别设置为0.01、0.937、0.000 5,训练批次(batch_size)为16、训练轮数(epochs)为100。
2.3 模型训练
为了在保证模型训练效果的同时,快速高效完成训练任务,在模型训练过程中使用了一些有效的训练技巧,使用了多尺度训练策略来提升模型训练效果。
多尺度训练是指设置几种不同的输入尺度,训练时每隔一定的迭代次数随机选取一种尺度训练,通过输入更大、更多尺寸的图像进行训练。该方法训练时从多个尺度中随机选取一种尺度,将输入图像缩放到该尺度并送入网络中,是一种简单且有效提升多尺度物体检测的方法。虽然一次迭代时都是单一尺度的,但每次都各不相同,增加网络鲁棒性的同时,又不至于增加过多的计算量。多尺度类似于数字图像处理中的图像金字塔,即将输入图像缩放到多个尺度下,每一个尺度单独地计算特征图,并进行后续的检测。这种方式虽然一定程度上可以提升检测精度,但由于多个尺度完全并行,耗时巨大。
2.4 实验结果及分析
2.4.1 本文方法实验结果及分析
表5 给出了本文算法改进及训练策略调整在伪装目标数据集上的6 项评价指标。按照算法改进的步骤和训练策略调整设置5组实验,具体如下:
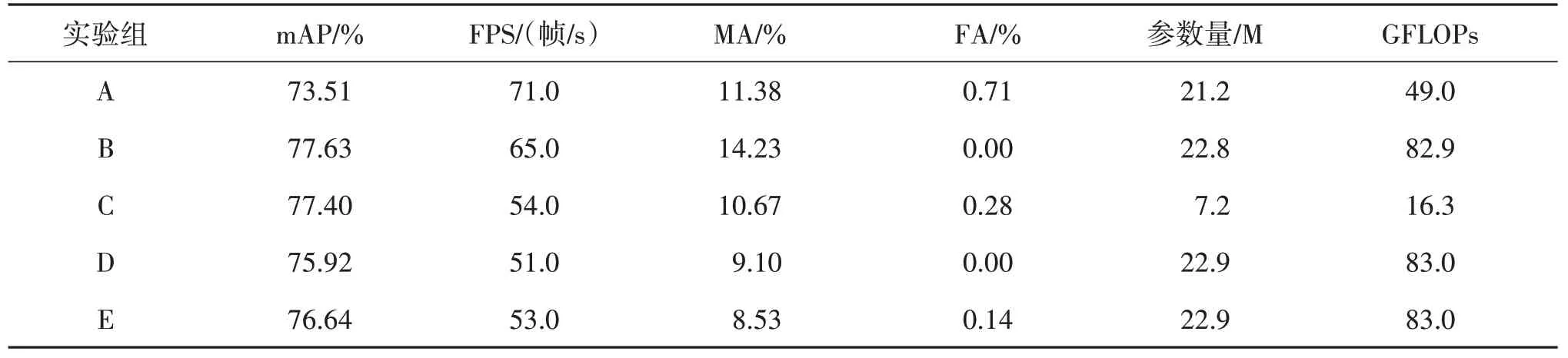
表5 不同改进方法的评价指标结果Table 5 Evaluation index results of different improvement methods
A组:原始的YOLOv5算法;
B组:在原算法中加入非显著目标检测层;
C组:在原算法中加入CBAM注意力机制;
D 组:在原算法中加入非显著目标检测层和CBAM注意力机制;
E组:在D组的基础上使用多尺度训练。
A 组→B 组:在增加非显著目标检测层后,YOLOv5 算法检测的平均精度均值(mAP)提升4.12%,虚警率(FA)减少0.71%,每秒检测帧数(FPS)有所下降,漏检率(MA)略有上升,参数量(Parameters)提升9.42%,浮点运算数(GFLOPs)几乎增加1 倍。由此说明非显著目标检测层通过增强网络复杂程度、提升每秒处理速度,使检测网络能够关注到分辨率极低的伪装目标,从而提升YOLOv5网络对多尺度伪装目标的识别能力,但也增大了网络模型。
A 组→C 组:在融合CBAM 注意力机制后,YOLOv5 算法检测的平均精度均值(mAP)提升3.89%,虚警率(FA)减少0.63%,漏检率(MA)减少0.71%,每秒检测帧数(FPS)有所下降,参数量(Parameters)降低65%,浮点运算数(GFLOPs)降低66%。可见,注意力机制在降低网络复杂程度和计算量的同时,能够调整网络的权重配比,使得网络更加关注有效特征,从而提升检测模型的检测精度,降低伪装目标检测的虚警率和漏警率。
A 组→D 组:在同时使用非显著目标检测层和注意力机制后,YOLOv5 算法检测的平均精度均值(mAP)提升2.41%,较B、C 组提升幅度较小;漏检率(MA)减少2.28%,优于B、C 组;虚警率(FA)减少0.71%,与B、C 组相比变化不大;每秒检测帧数(FPS)下降很大,与B、C 组相差较大。而参数量(Parameters)和浮点运算数(GFLOPs)相较于B组变化不大。由此说明同时使用非显著目标检测层和注意力机制对于伪装目标的漏检有很好的改善,然而由于增加了模型的复杂程度,导致检测速度大幅下降。
A组→E组:同时使用非显著目标检测层及注意力机制,并利用多尺度训练策略训练网络后,原YOLOv5 算法检测的平均精度均值(mAP)提升3.13%,漏检率(MA)减少2.85%,虚警率(FA)减少0.56%,每秒检测帧数(FPS)有所下降,参数量(Parameters)和浮点运算数(GFLOPs)几乎不变。由此说明多尺度训练对模型结构并无影响,而是通过数据的多尺度变化提升模型的鲁棒性,在提高检测精度的同时,有效降低漏检率。
从实际应用角度出发,本文所提的4 项评价指标在伪装目标检测算法性能评价中贡献从大到小依次是:漏检率(MA)、平均精度均值(mAP)、每秒检测帧数(FPS)、虚警率(FA),权重Wα分别取值为0.4、0.3、0.2、0.1。利用式(9)和式(10)对MA 及FA 正相关化、式(11)对FPS归一化后,通过式(12)求得不同算法的伪装目标综合检测能力指数,结果如表6所示。可以看出,本文提的MAH-YOLOv5 算法在伪装目标检测上性能最好、综合检测能力最强,较原YOLOv5算法提升0.74%。
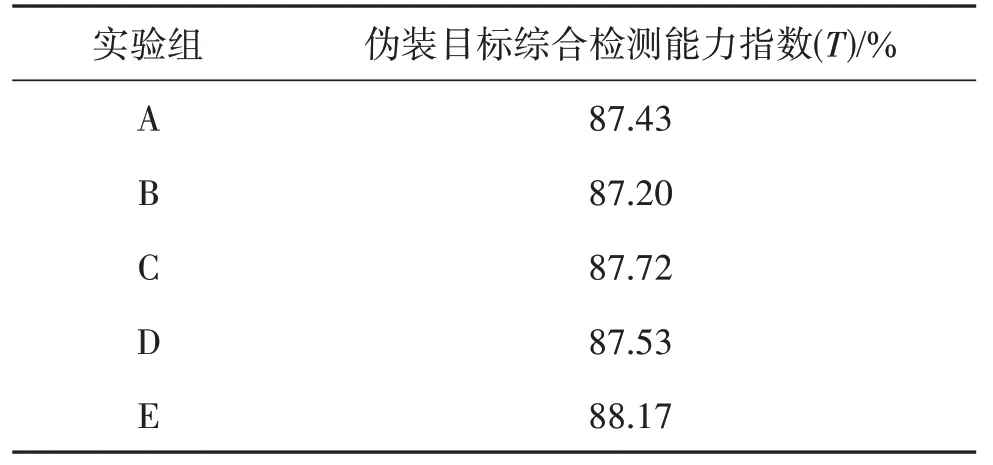
表6 不同改进方法的伪装目标综合检测能力指数Table 6 Comprehensive detection ability index of different improvement methods
图6 是不同方法改进YOLOv5 算法后的实际检测结果。很明显,YOLOv5 算法没有检测出伪装效果非常好的伪装目标(armored_vihivle),而改进的算法都能识别出隐藏在草丛里面的伪装目标,且检测的置信度越来越高。

图6 不同改进方法的检测结果Fig.6 Detection results of different improvement methods((a)A;(b)B;(c)C;(d)D;(e)E)
为了进一步验证本文方法的真实性,课题组从网上公开资源中收集了104 幅军事目标的真实场景图像,包含坦克、装甲车、火炮、卡车等目标,共计125 个实例。使用本文方法进行推理验证,结果表明在真实场景中本文算法的识别率为88%,虚警率为1.6%,部分检测结果如图7 所示。可以看出,本文方法在真实场景中依然具有不错的检测效果。
综上可知,本文算法能够提取尺度不一、背景融合度高这类伪装目标的有效特征,进而提升目标检测算法的检测精度、降低漏检率。利用多尺度训练提升模型的鲁棒性,在保持检测精度变化不大的情况下,进一步降低漏检率。对于军事目标检测来说,漏报所带来的伤害是很严重的。
2.4.2 多种方法性能对比实验
为了进一步验证本文改进的YOLOv5 算法对军事伪装目标检测的有效性,选取了Faster R-CNN(Ren等,2017)、YOLOv4-tiny(Bochkovskiy等,2020)、SSD(single shot multibox detector)(Liu 等,2016)、DETR(detection Transformer)、YOLOx、YOLOv7、YOLOv8 等多种目标检测算法与本文所提的MAHYOLOv5进行对比实验。其中,Faster R-CNN 是两阶段中的代表算法、具有较高的检测精度;DETR 是基于Transformer 技术的目标检测算法;SSD、YOLOv4-tiny、YOLOx、YOLOv7、YOLOv8 是属于一阶段检测算法,具有良好的检测精度和检测速度。表7 给出本文方法与对比算法在自制伪装目标数据集上的各种性能对比。
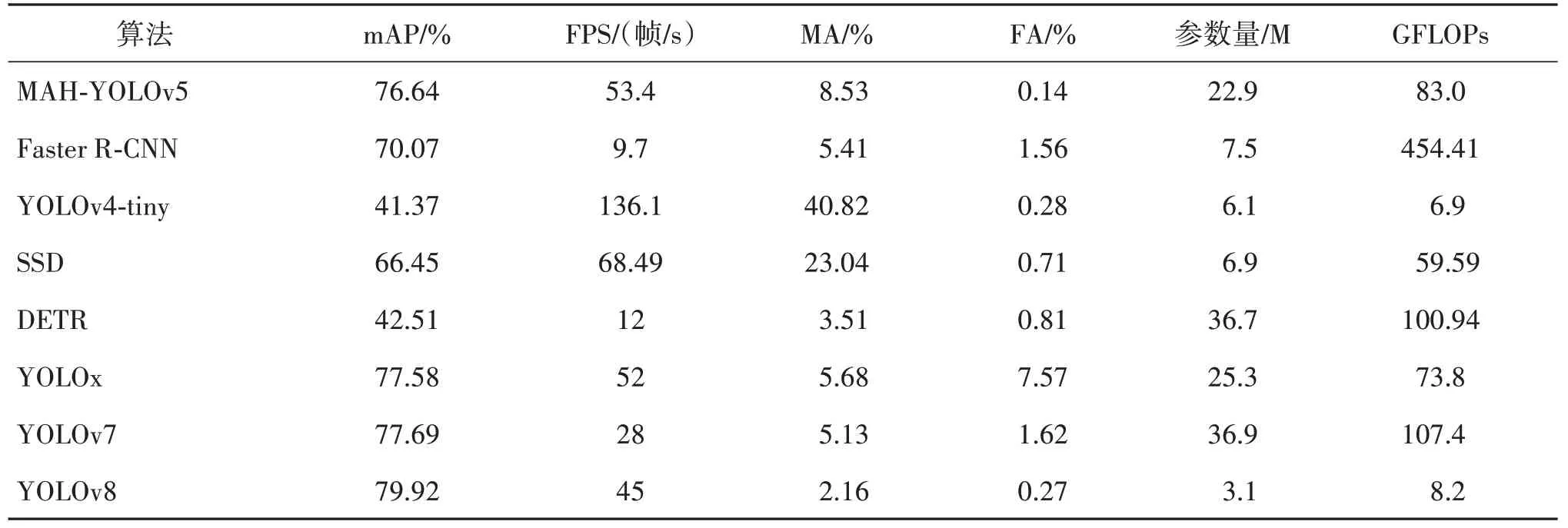
表7 不同算法的评价指标结果Table 7 Evaluation index results of different algorithm models
从表7 可以看出,本文方法在保证较低的模型复杂度的同时,还具有较好的检测效果。其中,mAP值明显高于Faster R-CNN、YOLOv4-tiny、SSD、DETR等,略低于YOLOx、YOLOv7、YOLOv8 等最新算法;在检测速度上,本文方法远高于Faster R-CNN、YOLOv4-tiny、DETR、YOLOv7、YOLOv8等算法;在漏检上,本文方法仅优于YOLOv4-tiny 和SSD 算法,而最先进的YOLOv8 有着最低的漏检率;在虚警上,本文方法的虚警率最低,其中YOLOx的虚警率比本文MAH-YOLOv5 高出约54 倍,YOLOv7 的虚警率比MAH-YOLOv5 高出约10 倍,YOLOv8 的虚警率比MAH-YOLOv5高出约1倍。
同理,通过归一化和正相关化后,利用式(12)求得不同算法的伪装目标综合检测能力指数,结果如表8所示。从表8可得,本文算法的伪装目标综合检测能力指数略低于YOLOx、YOLOv8 等最新算法,而与Faster R-CNN、YOLOv4-tiny、SDD、DETR、YOLOv7相比均有着很大优势。
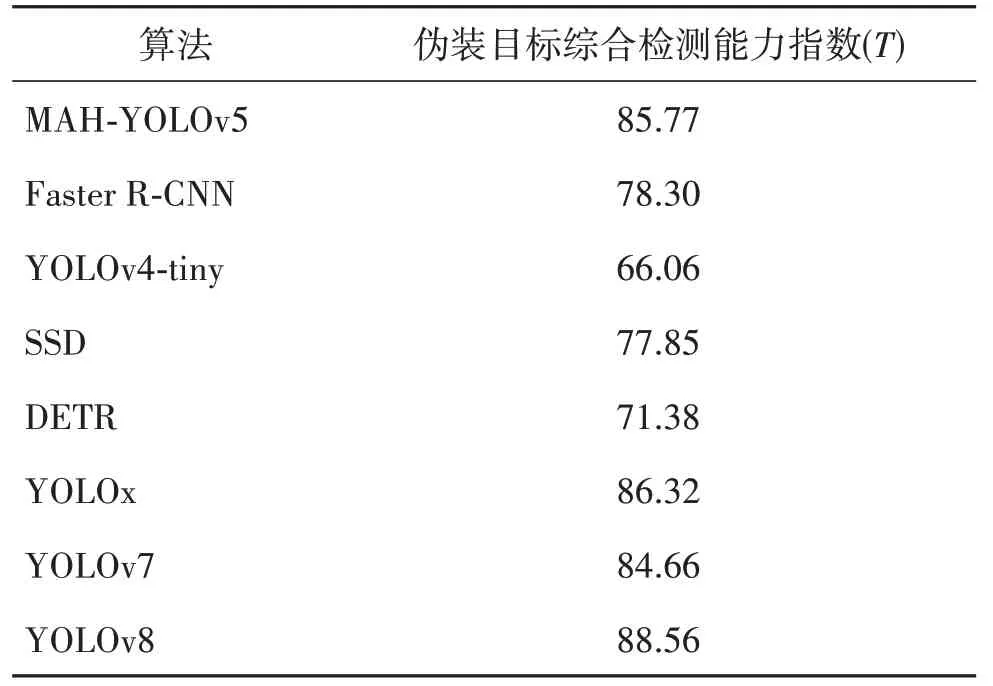
表8 不同算法伪装目标综合检测能力指数Table 8 Comprehensive detection ability index of different algorithms/%
图8 给出了对比算法在单帧图像的实际检测结果。可以看出,Faster R-CNN 算法虽然检测精度很高,但是存在虚警;YOLOv4-tiny、DETR、YOLOx、YOLOv7 等算法均存在不同程度的漏检;YOLOv8 算法虽然没有漏检,但各个目标的置信度不如本文方法。在综合考虑处理速度、虚警率等指标后,本文提出的MAH-YOLOv5具有较好的工程应用优势。

图8 不同对比算法的检测结果Fig.8 Different comparison algorithms’ detection results
综上可知,本文方法在伪装目标检测性能上优于Faster R-CNN、SSD、YOLOv4-tingy、DETR、YOLOv7等算法,而与当前最先进的YOLOx、YOLOv8 等算法在性能比较中也表现出不错的竞争力,并且本文方法具有更小的计算开销,这充分体现出本文方法的有效性和实用性。
3 结论
本文提出了一种伪装目标检测算法——MAH-YOLOv5,该算法通过在YOLOv5 网络预测头部增加非显著目标检测层,进一步增强了网络对特征信息不足目标的感知能力;在特征提取骨干中嵌入CBAM 注意力机制提升网络对待检测目标的注意程度,从而可以捕获复杂背景下多尺度伪装目标的有效特征信息。此外,在模型训练过程中使用了多尺度训练策略,利用仅有的小样本数据进一步提升算法的鲁棒性;最后,从军事应用背景出发,提出了针对军事目标检测的漏警、虚警指标,结合目标检测模型的平均精度均值、检测速度等指标,在考虑不同指标权重大小的基础上提出了伪装目标检测指数。
实验结果表明,在使用非显著目标检测层、CBAM 注意力机制后,网络能够关注到特征信息不足这类目标的特征、调整权重分配比例,提高伪装目标的发现概率、降低漏警率和虚警率,在使用多尺度训练之后进一步提升了网络模型的鲁棒性。与原YOLOv5 算法相比,本文改进方法平均精度均值提升3.13%、漏检率减少2.85%、虚警率减少0.56%、伪装目标综合检测能力指数提升0.74%。本文方法在保持一定检测精度和检测速度的同时,有着较低的漏警率、虚警率,伪装目标综合检测能力指数最高,可为战场伪装目标的快速高精度检测识别提供技术支撑和借鉴参考。
然而,本文方法也存在不足之处。MAH-YOLOv5算法在目标之间遮挡程度较高时检测效果较差,可能的原因是当遮挡面积很大时,不同目标之间的语义特征会相互影响,且在多尺度预测过程中非极大值抑制算法(NMS)的高阈值使得重叠度高的目标带来了更多误检。
在接下来的工作中,一方面,将考虑使用密集目标感知模块提升模型对遮挡目标的探测能力;另一方面,将改进现有的NMS 算法,对同一个网格预测出来的多个目标不再进行抑制,减少误检。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2018年11期)2018-08-04
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
太空探索(2016年5期)2016-07-12
测绘科学与工程(2016年5期)2016-04-17
电子设计工程(2015年3期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
河南科技(2014年14期)2014-02-27
