
曲线笔触渲染的图像风格迁移
2023-12-23 10:14饶师瑾钱文华张结宝
中国图象图形学报 2023年12期
饶师瑾,钱文华,张结宝
云南大学信息学院,昆明 650504
0 引言
图像风格迁移(style transfer)可以将一幅图像的风格迁移到另一幅图像(Gatys 等,2015),模拟艺术化绘制方式,创造出更多类似大师手绘的作品。传统风格迁移算法(Hertzmann等,2001)通常采用像素到像素之间的映射(刘哲良 等,2019),或连续优化数字图像中的每个像素点,生成风格迁移图像。逐像素生成风格迁移图像的方法与艺术家绘画的方法不同,绘画需要按照一定的笔画顺序,逐笔绘制出图像的整体与局部特征。然而,艺术家在创作不同类型的作品时需要使用粗细、形状不同的画笔描绘图像中的背景和细节,不同的画笔、颜料以及绘画方式在纸张上会表现出不同的笔触痕迹,例如,墨汁在宣纸上作画会有晕染的效果,而用丙烯颜料作画,颜料之间的相互覆盖会在纸张上形成堆叠效果,产生层次感,这些复杂的笔触效果采用逐像素点优化的方式难以实现。
为了模拟人类绘画的真实过程,Hertzmann(2003)提出了基于笔触渲染(stroke-based rendering,SBR)的非真实感图像渲染算法。基于笔触渲染的风格迁移算法主要包括基于强化学习的算法(Xie等,2013;Ganin 等,2018;Zheng 等,2023;Huang 等,2019)和基于优化的算法(Hertzmann,1998;Liu 等,2021;Zou 等,2021)。强化学习算法在智能体与环境交互的过程中,通过长期激励,鼓励智能体学习如何将目标图像分解为多个笔触,再迭代地将笔触重新渲染到画布上,虽然强化学习算法可以较快渲染出图像,但是需要耗费很长时间训练智能体,在缺少学习样本的情况下,很难训练出稳定的智能体决策每一个笔触的位置和颜色等参数,此外,强化学习还需要考虑笔触之间的组合关系和覆盖关系,若两个笔触之间相互覆盖,强化学习方法生成的图像会产生十分明显的叠加效果和笔触痕迹。
图1(a)展示了强化学习(Huang 等,2019)算法生成的结果图像,图中人物面部笔触颜色差异大,边界明显,可以明显看到笔触痕迹。基于优化的笔触渲染算法通常采用贪心搜索策略,在较大的搜索空间中寻求满足条件的笔触参数集合。基于优化的笔触渲染算法主要分为两类,试错算法和Voronoi算法(Hertzmann,2003)。试错算法先将目标图像分割,再采用其他图形匹配目标图像的分割结果,例如,三角形、圆形、矩形等,如果当前匹配的形状放置到画布上能够使能量函数减小,就将该形状渲染到画布上;反之,则进行下一轮的预测,匹配新的图形。

图1 各类算法的绘画式重建效果Fig.1 Image to painting results of various algorithms((a)reinforcement learning algorithm;(b)trial-and-error algorithm;(c)Voronoi algorithm)
图1(b)展示了试错算法的结果图像,Song 等人(1998)采用Graph-cuts 算法对图像进行分割,再通过不规则图形拼凑图像,这类算法需要大量的时间不断试错。Voronoi 算法将目标图像分割成一系列子区域,在每个子区域中确定笔触的中心位置,然后将笔触渲染到图像中,再参考目标图像优化笔触的中心位置,笔触中心位置的优化过程与笔触密度有关,优化时间随着笔触密度的增加而延长。
图1(c)展示了Voronoi 算法的结果图像,Zou 等人(2021)采用由低分辨率到高分辨率的渐进渲染策略,在每一个渲染阶段,将画布分割为若干个相交的子区域,每一个子区域都需要进行相同次数的梯度下降并对区域中的所有笔触进行优化,子区域中笔触越多,程序运行时间越长。在真实的艺术作品中,艺术家通常采用弧形或不规则的笔触描绘图像色彩连续的区域,然而目前基于神经网络的笔触渲染算法通过对初始笔触进行仿射变换,使笔触满足目标图像分布的方法生成图像,与艺术家的绘画方式大相径庭,因为仿射变换产生曲线笔触较困难,并且采用单一的直线笔触绘画显得画作十分刻板,缺乏艺术感,无法绘制出图像中的细小纹理。
为了增强笔触的灵活度,保留风格迁移图像的笔触痕迹,降低程序运行时间,本文提出一种基于曲线笔触渲染的风格迁移算法,首先将图像前景和背景进行多尺度分割,再根据分割后的子图像选取多个节点,通过节点坐标,采用三次Bezier 曲线生成虚拟曲线笔触;其次,将曲线笔触从离散域变换到像素域,渲染到画布上;最后,将渲染后的图像与风格图像进行风格迁移。实验证明,本文提出的采用多尺度曲线笔触渲染图像的方法,图像中的细小纹理丢失更少,前景与背景之间的界限更清晰,生成的风格化图像色彩艳丽,且保留了真实绘画的笔触痕迹。
1 相关工作
1.1 风格迁移
单风格迁移模型仅能生成特定风格的图像。Gatys 等人(2016)提出采用卷积神经网络(convolutional neural network,CNN)最小化随机噪声图像与风格图像和内容图像之间的风格损失和内容损失,将风格图像的风格与内容图像的语义信息结合,生成一幅新的风格图像,但生成图像内容信息丢失严重。Johnson 等人(2016)在Gatys 等人(2016)的工作基础上采用感知损失函数训练前馈神经网络,减少内容图像的细节丢失,生成与风格图像接近、但内容结构保留更完整的风格化图像。Lin 等人(2021)提出一种基于前馈网络的LapStyle(Laplacian pyramid network)算法,采用拉普拉斯算法提取内容图像的轮廓,保存细节并在渐进过程中合成高清风格化图像。单风格迁移模型需要为特定风格重新搭建并训练模型,缺乏灵活性,而多风格迁移模型仅需一次训练即可以适用于多种风格迁移。An 等人(2021)提出基于可逆神经流的PFN(projection flow network)网络,既可实现图像的多风格迁移,又采用神经网络的正向与逆向流动机制,解决了大多数风格迁移网络中存在的内容泄露现象,实现无损风格迁移。与多风格迁移模型相比,任意风格迁移模型适用于任意一种风格。Li等人(2017)提出基于白化和着色变换的通用风格迁移算法,无需对每种风格单独训练即可生成高质量风格化图像。Wang 等人(2020)将正交随机噪声引入到Li 等人(2017)的工作中,增加任意风格迁移结果的多样性。谢斌等人(2020)提出基于相关对齐的图像风格纹理提取方法,可以有效抑制迁移过程中噪声的产生,生成的风格图像纹理分布更加均匀,并且图像生成效率更高。
1.2 超像素分割
超像素分割根据像素的颜色、纹理和位置等信息将视觉上相似的像素点分割为一个子区域,每个子区域表示一个超像素。超像素分割算法分为基于图论的算法和基于梯度上升的算法。基于图论的算法将图像映射为一幅图,图节点表示图像中所有的像素点,节点之间相连的边代表像素点之间的相邻关系,采用最大流、最小割算法最小化能量函数,生成超像素。Zhang 等人(2019)在风格迁移任务中,将图像的内容特征和风格特征作为图节点,通过Graph-cuts 算法对图像内容特征和风格特征进行语义和空间上的匹配,实现多模态风格迁移。基于图论的超像素分割算法,计算量随着图像尺寸的增大而增加,且能量函数的构造以及能量函数最小化问题都属于NP-hard 问题。基于梯度上升的超像素分割算法需要先初始化聚类中心,再对所有聚类中心迭代运用梯度上升算法更新聚类中心,直到每一个聚类中心都满足收敛条件为止。Achanta 等人(2012)提出的简单线性迭代聚类(simple linear iterative clustering,SLIC)算法,可以快速生成边缘贴合度高、分割大小均匀的超像素,提高了超像素分割算法的效率,但是SLIC 算法仅适用于分割规则图像,为了能够在非规则区域内同样达到SLIC 算法的效果,Irving(2016)提出可以在感兴趣区域分割出均匀超像素的maskSLIC算法,该算法优化了SLIC算法的初始聚类中心生成方法,使聚类中心能够均匀地散布在感兴趣区域内。超像素分割在医学图像分割(Amami 等,2019)、目标检测(Ghariba 等,2022)和风格迁移(Zhang 等,2019)上都有很广泛的应用。本文采用maskSLIC 算法对图像分割,获取图像分割后的标签,作为曲线笔触生成的预处理步骤。
1.3 笔触渲染算法
笔触渲染是计算机模拟人类绘画的方式,对自然图像进行艺术化渲染,生成非真实感图像的过程(Hertzmann,1998)。基于优化的笔触渲染算法采用直线笔触(Zou 等,2021;Liu 等,2021)或其他形状的图形绘制图像(Hertzmann,1998),Paint Transformer模型(Liu 等,2021)通过预测的笔触参数,变换初始油画笔触的形状、颜色和位置等,生成直线笔触,仅由直线笔触组成的绘画作品缺乏灵活性。与Paint Transformer 相比,Kotovenko 等人(2021)提出的参数化笔触渲染算法可以生成更加细小的笔触,但是由于受控制点数量、位置等因素的影响,该模型生成的笔触更加趋近于直线笔触,并且整幅图像均采用大小相同的笔触进行渲染,导致生成的图像前景轮廓不清晰,细节丢失严重。
2 本文方法
2.1 整体框架
图2 展示了本文方法的整体框架,首先通过maskSLIC 超像素分割算法将内容图像的前景、背景分割为不同尺度的子图像,在每一个子图像中分别取出4 个节点,作为曲线的控制点,根据实验结果,选取4 个节点,可以在保证算法效率的前提下,生成弯曲程度更佳的曲线笔触,采用3次Bezier曲线方程对4 个节点进行拟合,生成曲线笔触,将笔触渲染到空画布上,再通过风格损失和内容损失优化笔触的颜色、位置、形状和颜色等参数,最后将绘制出来的内容图像与风格图像进行风格迁移。

图2 整体框架Fig.2 Overall framework
2.2 基于掩膜的多尺度超像素分割
超像素分割算法先将图像从RGB 空间转换到CIELAB(international commission on illumination lab color space)空间,因为CIELAB 空间色域更广,对图像的原生色彩不会造成影响,再计算每个像素点在CIELAB 空间中的色彩距离和坐标距离,将颜色相近、位置相邻的像素划分到同一个区域。采用Achanta等人(2012)提出的像素点相似度衡量标准,计算子图像中每一个像素点与其他像素点的颜色差异和位置距离。具体为
式中,dcolor表示像素点在CIELAB 空间的颜色差异,li、ai、bi分别表示像素点i在CIELAB 空间中的明暗强度、红绿分量和蓝黄分量,dlocation表示像素点的空间距离,x和y分别表示坐标点的横、纵坐标,fdistance表示CIELAB 色彩空间距离和归一化后的空间距离之和,fdistance的值越大表示两个像素越相似,β表示空间距离dlocation的权重。由于maskSLIC 算法可以自定义超像素的数量,并将图像分割为大小均匀的子图像,所以本文采用maskSLC 算法对图像进行不同尺度的分割,生成不同尺度的笔触,分别渲染图像前景和背景。maskSLIC算法共分为两个步骤,具体如下
1)在掩膜区域中初始化聚类中心。采用Sk表示聚类中心集合,M表示掩膜区域内点的集合表示掩膜区域外点的集合,L表示掩膜区域外的点与聚类中心的集合,L=∪Sk。通过欧几里德距离变换公式初始化掩膜区域内的聚类中心,具体为
式中,D(x)表示M中的像素点x与L中的像素点y之间的距离变换,n表示图像的维度。
2)为了有效减少聚类中心优化的迭代次数,加快图像分割算法的效率,采用k-means++算法迭代优化聚类中心的位置,具体如算法1所示。
算法1:基于掩膜的超像素分割算法。
输入:图像I,超像素个数N,图像高度H,图像宽度W,图像掩膜M;
通过maskSLIC 算法,可以有效分割图像掩膜区域内的像素点,分别获取图像的前景背景标签,分割时可以通过改变掩膜区域的分割数量控制子区域的大小,从而调整后续生成笔触的大小,分割数量越少,分割后的子区域就越大,生成的笔触也就越大,图像丢失的细节就越多,反之,分割数量越多,分割子区域越小,生成笔触也就越小,能够更好地描绘出图像中的细节。
2.3 笔触生成和渲染
Kotovenko 等人(2021)采用起点、控制点和终点共3个节点生成曲线笔触,由于3个节点处于一条直线上,所以生成的笔触弯曲程度不明显,更接近直线笔触。为了模拟真实艺术作品中的绘画笔触,生成细长、弯曲程度显著的曲线笔触,本文采用4 个节点控制曲线笔触的生成,过多的节点和太复杂的曲线生成方式会大幅度降低笔触参数的生成效率。
图3 为本文采用的曲线笔触参数,包括形状参数p0,p1,p2,p3、颜色参数c、宽度参数w和位置参数x,y,共8 个参数,其中,4 个形状参数分别表示曲线笔触的起点p0、第1 个控制点p1、第2 个控制点p2和终点p3,位置参数x表示笔触的横坐标,y表示笔触的纵坐标。

图3 曲线笔触参数Fig.3 The parameters of curved stroke
形状参数的取点方式决定曲线笔触的整体形态以及弯曲程度,根据2.2 节中获取的图像前景背景标签,依次获取相同标签的像素点,在相同标签的像素点范围内计算其对应的凸包集合,再计算凸包集合中每个坐标点之间的距离,取相距最远的两个点分别作为曲线的起点p0和终点p3,将两个点之间的距离三等分,取第1 个三等分点处,子区域的第1 个边缘点作为第1 个控制点p1,取第2 个三等分点处,子区域的最后一个边缘点作为第2 个控制点p2。算法2 描述了由图像标签生成曲线笔触参数的详细过程。
算法2:笔触参数生成。
输入:内容图像的标签集合
为了能够在子区域的形状弯曲度比较大的情况下,生成弯曲程度较大的曲线笔触,子区域的形状贴近矩形时,生成弯曲幅度小的笔触,本文在选取控制点时尽量使两个控制点相距较远,图4 表示了在子区域中取点生成曲线笔触,并将笔触渲染在画布上的部分结果,图中p0,p1,p2,p3分别表示曲线笔触的起点、第1 个控制点、第2 个控制点和终点。

图4 曲线笔触渲染方法Fig.4 Curved stroke rendering method
曲线生成方程为
式中,t表示节点顺序,Stoke(·)表示笔触位置参数计算。
目前,主流的SBR(stroke-based rendering)算法通过神经网络将离散参数转化为矢量笔触图像,再将笔触映射到像素域,训练神经网络不仅需要花费大量的时间,而且需要占用大量的内存,所以本文采用简单的可微函数将笔触集合转换为画布上的像素值,具体为
式中,Renderer(·)表示渲染计算,Ioutput和C分别表示输出图像和输入图像,param表示笔触参数集合,渲染器接收笔触参数集合将所有笔触渲染到空画布上。
图5 展示了本文方法和Kotovenko 等人(2021)方法的风格化结果。图5(a)表示输入图像,由上至下分别表示内容图像和风格图像;图5(b)由本文方法生成,共3 000 条笔触;图5(c)由Kotovenko 等人(2021)的方法生成,共5 000条笔触。本文方法在笔触数量更少的情况下,生成的图像中松鼠的眼睛和耳朵轮廓更清晰,腿部形态更明显,背景中灰色部分更少,由于笔触痕迹明显、柔和、色彩鲜艳,因此图像整体视觉效果更佳。

图5 本文方法与Kotovenko等人(2021)方法的比较结果Fig.5 Comparison of results between Kotovenko et al.(2021)method and ours((a)input images;(b)ours;(c)Kotovenko et al.(2021))
2.4 损失函数
本文算法主要分为两个阶段,笔触渲染阶段和风格迁移阶段。为了能够增强合成图像的纹理信息,保留内容图像的结构特征,两个阶段均采用了风格损失和内容损失,在渲染阶段,采用曲率损失调整曲线控制点的位置,增强曲线弯曲度。
风格迁移损失可以在图像渲染阶段,逐渐使每一条笔触颜色趋近风格图像的色彩,风格迁移阶段使渲染后的图像增强风格化图像的纹理信息,计算为
式中,Irender表示渲染生成的内容图像,ϕl表示图像第l层的特征表示生成图像的Gram 矩阵表示风格图像的Gram 矩阵是第l层的归一化常数,El是第l层的风格损失,wl表示风格损失的权重,Lsty表示总风格损失。
内容损失可以衡量图像在优化过程中与内容图像的相似性,计算式为
式中,Icontent表示内容图像,Lcon表示内容损失。
曲率损失能抑制控制点之间处于同一条直线上,保证曲线的弯曲度,因为本文共采用4 个点控制Bezier 曲线,每3 个点即可控制一段曲线,所以本文将4个节点控制的Bezier曲线分为两段子曲线优化,p0,p1,p2作为第1 段子曲线的起点、控制点和终点;p1,p2,p3作为第2 段子曲线的起点、控制点和终点。曲率计算式为
式中,s表示曲线的起点,c表示曲线的控制点,e表示曲线的终点,Lse表示曲线的曲率。根据式(11),分别计算两段子曲线的曲率,再对两段子曲线的曲率求均值。
两段曲线的总损失Lcur为
式中,Lse1表示第1 段曲线的曲率,Lse2表示第2 段曲线的曲率。
3 实验结果与分析
3.1 欺骗率
欺骗率表示虚假风格图像能够欺骗神经网络,使神经网络判断虚假风格图像为真实风格图像的概率。为了客观评价风格化图像的风格特征与风格图像的风格特征是否接近,本文将Sanakoyue 等人(2018)提出的欺骗率作为客观评价指标。Sanakoyue 等人(2018)的方法将wikiart 数据集(Nichol,2016)作为分类训练集,训练VGG16(Visual Geometry Group16-layer)网络为600+种艺术风格进行分类,然后从wikiart 数据集中选取部分类型的艺术图像作为风格图像,将内容图像与风格图像进行风格迁移,从风格图像中裁剪出部分子图像,采用训练好的VGG16 为子图像进行分类,计算每种风格分类结果的平均值,即平均欺骗率。如表1所示,VGG16网络对wikiart 测试集中20 类真实艺术家图像的分类准确率为0.652,对内容图像的分类准确率为0.02。将AdaIN(Huang 和Belongie,2017)、WCT(whitening and coloring transforms)(Li 等,2017)、Gatys 等 人(2016)、AST(arbitrary style transfer)(Sanakoyue 等,2018)、Kotovenko 等人(2021)和本文方法采用平均欺骗率,判断相同内容图像和风格图像下,不同模型生成的风格迁移结果与真实艺术图像的风格相似度,结果如表1所示。

表1 欺骗率Table 1 Deception rate
然而,欺骗率的分数高低并不能代表生成图像质量的好坏,只能判断生成的风格图像与给定的风格图像是否接近。因此,增加了测试者欺骗率指标,对神经网络生成的风格化图像进行主观评价,由测试者根据自己的主观感受为结果图像打分。本次实验的测试者共有30 人,采用20 幅风格图像与20 幅内容图像交叉进行风格迁移,生成400 幅风格化图像,由测试者将本文方法与Kotovenko 等人(2021)、Gatys 等 人(2016)、AST(Sanakoyue 等,2018)、AdaIN(Huang 和Belongie,2017)和WCT(Li等,2017)等5 种方法的风格迁移结果进行比较。欺骗率指标的分数越高表示风格化图像与真实艺术图像越相似,表1展示了每种方法的欺骗率分数。本文方法在两个指标上获得的分数均为最高,说明本文方法的风格化图像在视觉效果上优于其他5 种方法。
3.2 实验时间比较
为了表明本文方法的高效性,将本文方法与GANILLA(Hicsonmez 等,2020)、Paint Transformer(Liu 等,2021)和StrokeNET(Zheng 等,2023)模型的运行时间进行比较。其中,GANILLA 为风格迁移模型,Paint Transformer 和StrokeNET 为图像绘画式重建模型,各个模型的渲染时间和训练时间如表2 所示,所有模型在渲染时采用相同的内容图像和风格图像。与GANILLA 和StrokeNET 相比,本文方法渲染时间长,但是本文方法通过图像分割算法,取点生成曲线笔触参数,无需额外的数据集训练模型,缩短了程序运行时间。此外,GANILLA 模型仅适用于插图风格图像的迁移,而本文方法可以生成多风格图像。与Paint Transformer 和StrokeNET 相比,本文方法生成的结果图像可以保留更多的图像细节。

表2 实验时间Table 2 Experimental time
3.3 实验结果
图6 展示了本文方法与Wang 等人(2021)、Gatys 等人(2016)和Kotovenko 等人(2021)等3 种风格迁移算法生成的结果图像。与Wang 等人(2016)的方法相比较,Wang 等人(2016)的结果图像更接近风格图像,但是Wang 等人(2016)在图像上色阶段加入了噪声扰动,导致结果图像中生成一些比较杂乱的纹理,影响结果图像的整体视觉效果。本文方法虽然采用多尺度笔触渲染图像前景和背景,但是结果图像整体减少了笔触杂乱堆积,而且笔触痕迹清晰,色彩艳丽,结果图像更接近艺术家的手绘作品。与Gatys 等人(2016)的方法相比较,Gatys 等人(2016)的方法保留了较多内容图像的风格,如图6(d)第1 行,Gatys 等人(2016)的方法过多地保留了大象原生的皮肤色彩,并且图像中颜色分布不均匀,图6(d)第2 行,Gatys 等人(2016)生成的图像整体色彩与风格图像整体色彩不一致,本文方法生成的结果图像在保留内容图像结构的同时,图像风格更加接近风格图像,因为本文方法可以更好地提取风格图像的色彩信息,将色彩信息与内容图像融合,结果图像中体现出更多风格图像的色彩。与Kotovenko 等人(2021)的方法相比,Kotovenko 等人(2021)生成的结果图像中,图像前景与背景基本完全融合,没有清晰的边界线,并且结果图像中的部分色彩饱和度高于风格图像中的色彩饱和度,图像整体色彩不协调,而本文方法生成的笔触纹理更加均匀、细腻、显著,生成图像的色彩更接近风格图像色彩,如图6(f)第2、4 行所示,本文方法生成的图像背景中灰色部分更少,图像饱满,前景与背景的边界更清晰,图像背景部分的笔触更多,结构保存完整。

图6 风格迁移效果图Fig.6 Style transfer results((a)content images;(b)style images;(c)Wang et al.(2021);(d)Gatys et al.(2016);(e)Kotovenko et al.(2021);(f)ours)
3.4 图像重建
为了进行图像重建的对比,将本文方法与Zou等人(2021)和Liu 等人(2021)的方法进行比较。所有模型均采用python 和pytorch 深度学习框架实现,在Nvidia RTX 2080 Ti GPU 上训练,Zou 等人(2021)的方法需要自定义所生成的笔触数量,在图像分割与笔触渲染的过程中,计算资源的需求量逐渐增大,所以实验中尽可能地生成最多笔触。实验结果如图7所示。Zou 等人(2021)需要对内容图像分割后渲染,内容图像分割的数量决定渲染图像的细节数量,随着分割数量的增加,程序运行时间延长,消耗的资源也逐渐增加。Liu 等人(2021)的方法采用矩形笔触渲染图像,矩形笔触无法描绘出图像细节,而本文方法采用曲线笔触渲染图像,不仅能够在细节层面上较好地还原源图像的细小纹理,而且运行时间短,如图7第3行中飞盘上的花纹、背景中砖块之间的缝隙、第4行中羊的眼睛、羊毛上的竖条纹理,本文方法保留的纹理比Zou等人(2021)和Liu等人(2021)的方法更多。此外,图7第4行,源图像中有3只羊,但是在Zou等人(2021)和Liu等人(2021)的方法中仅重建出两只羊,本文方法重建的图像中更好地保存了第3只羊的轮廓。与Liu 等人(2021)的方法相比,Liu 等人(2021)的方法每次生成8个笔触,在生成4个大笔触的基础上,再叠加4个小笔触,对于纹理较为丰富的图像,为了保留图像细节,很容易产生大量小笔触叠加的效果,导致图像模糊,本文方法在分割后不相交的子图像中生成笔触,所以本文方法生成的图像在保留更多细节的前提下,不会产生大量小笔触堆叠的效果。

图7 图像重建结果Fig.7 Image to painting results((a)source images;(b)Zou et al.(2021);(c)Liu et al.(2021);(d)ours)
3.5 消融实验
笔触宽度是决定生成图像质量的重要因素之一,图像分割数量即生成笔触的数量,图像分割数量多,生成的笔触较小,图像分割数量少,生成的笔触较大。无论分割后子区域的大小,都需要生成的笔触能够覆盖整个子区域,减少图像中的空白部分。图8 展示了Kotovenko 等人(2021)方法生成的两幅图像,每幅图像均分割为5 000个子区域,生成5 000条笔触。可以看出,图像中仍然有大量灰色背景没有被笔触覆盖。

图8 Kotovenko等人(2021)方法的结果Fig.8 The result of Kotovenko et al.(2021)method
为了使生成的笔触能够填满画布,本文采用临界值确定细粒度笔触宽度和粗粒度笔触宽度。首先确定细粒度笔触的宽度临界值,保证细粒度笔触能够绘制出更多的图像细节,再确定粗粒度笔触的宽度临界值。
如图9所示,将细粒度笔触的临界值设置为0.1时,图像重建的均方误差(mean square error,MSE)损失最小。
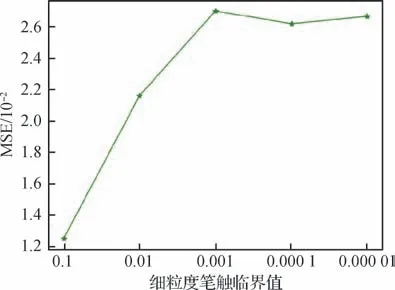
图9 细粒度笔触MSE损失Fig.9 The MSE loss of thin strokes
确定细粒度笔触临界值后,对粗粒度笔触宽度临界值进行MSE损失的消融。如图10所示,当选择10-1× 100 作为粗粒度笔触和细粒度笔触的宽度临界值时,图像重建的MSE 损失最低,并且图像中的笔触渲染更充分。

图10 粗粒度笔触MSE损失Fig.10 The MSE loss of thick strokes
本文方法生成结果如图11 所示。图11(a)中的海鸥由2 500条笔触组成,图11(b)中的松鼠由3 000条笔触组成。图8 中Kotovenko 等人(2021)生成的图像中有许多短小的直线笔触,图8 右图中整幅图像更倾向于由直线笔触构成,无法凸显出笔触的曲线形态,因为Kotovenko 等人(2021)的方法在优化过程中笔触颜色会趋近于背景颜色,导致图像看上去笔触较少,而且Kotovenko 等人(2021)对图像整体分割数量多,所以生成的笔触短小,趋近直线。但若图像分割数量减少,图像整体呈现的笔触也会减少。本文方法生成的图11 两幅图像的分割数量更少,生成的两幅图像在视觉效果上保留了更多的笔触,图像中的背景颜色更少,可以明显看到曲线笔触的形态。

图11 本文方法生成结果Fig.11 Our results((a)2 500 strokes;(b)3 000 strokes)
图12展示了更多本文方法生成的结果图像。

图12 粗粒度笔触与细粒度笔触相结合的视觉效果Fig.12 The visual effect of the combination of thick and thin strokes((a)content images;(b)style images;(c)style transfer results)
4 结论
本文提出一种基于曲线笔触渲染的风格迁移算法,根据自定义掩膜区域内的超像素数量,对图像前景和背景分别生成不同尺度的曲线笔触,曲线笔触经过多次迭代优化,逐步优化笔触的位置、颜色和控制点等参数,实现多风格迁移效果。实验结果表明,采用本文方法生成的结果图像色彩鲜明艳丽,图像细小纹理保存更完整,并且生成的笔触更加贴近真实艺术作品的曲线笔触形状。由于maskSLIC 算法分割后的图像块形状较为均匀,使得Bezier 方程生成的曲线笔触不一定都在图像块内,从而导致图像中产生部分空白。未来将采用图像插值算法改善算法缺陷,并且当图像整体分割数量较多时,maskSLIC算法的效率还有待进一步提高。此外,风格迁移网络仅能传输风格图像的色彩信息,下一步将考虑设计轻量级风格迁移算法,更好地提取风格图像的色彩特征和纹理特征,并采用更加客观、公正的指标进一步体现本文算法的有效性。
猜你喜欢
艺术家(2023年8期)2023-11-02
小哥白尼(军事科学)(2022年2期)2022-05-25
VOGUE服饰与美容(2021年4期)2021-03-24
红领巾·萌芽(2019年8期)2019-08-27
科普童话·百科探秘(2019年3期)2019-05-17
上海大学学报(自然科学版)(2018年5期)2018-11-02
金桥(2018年6期)2018-09-22
电脑知识与技术(2018年35期)2018-02-27
为了孩子(孕0~3岁)(2018年1期)2018-01-18
自动化学报(2017年11期)2017-04-04
