
自适应权重更新的轻量级视频目标分割算法
2023-12-23 10:14汪水源侯志强李富成马素刚余旺盛
中国图象图形学报 2023年12期
汪水源,侯志强,李富成,马素刚,余旺盛
1.西安邮电大学计算机学院,西安 710121;2.西安邮电大学陕西省网络数据分析与智能处理重点实验室,西安 710121;3.空军工程大学信息与导航学院,西安 710077
0 引言
视频目标分割(video object segmentation,VOS)是一项基本的计算机视觉任务,在视频编辑、视频合成以及自动驾驶等领域有着广泛的应用(汪水源等,2021)。本文主要研究半监督视频目标分割问题,即在给定视频第1 帧目标真实标注掩码的情况下,预测剩余帧中由第1 帧标注指定的目标的分割掩码(李瀚 等,2021)。在视频序列中,由于连续的运动和可变的摄像机拍摄视角,目标对象会经历较大的外观变化;其次,如果出现其他物体的遮挡,目标对象可能在此帧中消失;最后,同类别的相似目标会使得分割特定目标变得更加困难。因此,尽管在第1 帧中提供了标注,半监督VOS 仍是一个极具挑战性的课题。
早些年,性能先进的半监督视频目标分割相关工作可以分为两类。第1 类工作大多使用单个带注释的帧对训练好的卷积神经网络(convolutional neural network,CNN)模型进行在线微调,并独立地分割每一帧。OSVOS(one-shot VOS)(Caelles 等,2017)算法做了这个方向的开创性工作。OnAVOS(online adaptation VOS)(Voigtlaender 和Leibe,2017)挖掘测试序列中的置信度区域以增加训练数据。OSVOS-S(Maninis 等,2019)集成了来自实例分割模型的语义信息以提高性能。PReMVOS(proposal-generation,refinement and merging for video object segmentation)(Luiten 等,2019)结合了在线学习、目标检测和光流和重识别等技术实现对目标的跟踪。DyeNe(tvideo object segmentation with joint re-identification and attention-aware mask propagation)(Li 和Loy,2018)提出自适应匹配检索丢失的目标实体,增强模型的鲁棒性。虽然在线训练有效地提高了模型对目标对象外观变化的泛化能力,但却十分耗时,例如,OSVOS算法分割一帧图像需要10 s,这对于许多应用来说是不实际的。此外,尽管这些方法可以学习到目标带有空间连续性的先验知识,但忽略了视频中潜在的时序信息,造成了极大的信息浪费。第2 类工作通过传播或匹配将目标信息传递给后续帧。Mask-Track(Perazzi 等,2017)将前一帧的预测掩码与当前帧的图像连接起来,以提供空间信息上的指导。Lucid(Khoreva 等,2019)在MaskTrack 的基础上使用首帧掩码进行数据增强。FEELVOS(fast end-to-end embedding learning for video object segmentation)(Voigtlaender 等,2019)使用语义上逐像素的嵌入以及全局和局部匹配机制来传递信息到当前帧。VideoMatch(Hu 等,2018)将当前帧特征和模板帧的前景和背景匹配,从而实现分割。OSMN(object segmentation via network modulation)(Yang 等,2018)使用双网络充分利用初始帧和前一帧特征信息,实现对当前帧的分割。RGMP(reference-guided mask propagation)(Oh等,2018)将掩码传播和目标检测思想相结合,利用参考帧以及前一帧信息指导分割当前帧。尽管这些方法不需要进行复杂的在线微调,但由于信息流传输效率低下,它们仍然无法达到较快的分割速度。此外,由于缺乏鲁棒的目标表示,它们可能会出现目标漂移现象。
后续的一些工作将视觉目标跟踪领域的相关方法迁移到视频目标分割任务中。FAVOS(fast and accurate online VOS)(Cheng 等,2018)提出目标分块跟踪,将目标部分区域信息与第1 帧信息进行匹配。SiamMask(Wang 等,2019a)在全卷积孪生网络基础上,增加掩码分支实现对目标的分割。RANe(tranking attention network)(Wang 等,2019b)提出一种排序注意力模块,分别处理视频每一帧的前景和背景。尽管取得了不错的效果,但这些算法并没有充分利用视频序列中的历史帧信息,性能无法进一步提升。
基于记忆网络的算法成为视频目标分割的热点方 向。STMVOS(space-time memory VOS)(Oh 等,2019)利用记忆网络存储更多的历史帧特征信息,在进行每一帧的分割时,它使用记忆信息与视频当前帧的特征信息进行逐像素匹配,其性能优于之前所有的方法,但由于计算复杂度较高,STMVOS 的分割速度较慢。FRTM(fast and robust models)(Robinson等,2020)同样采用记忆网络存储历史帧信息,不同于STMVOS,它只使用记忆信息更新自己所提出的目标模型,该目标模型以主干网络所传来的特征信息为输入,输出目标的粗略掩码,该粗略掩码会作为后续细化分割网络的输入,最终输出目标的精细分割掩码。在处理完每一帧后,FRTM 会将该帧的特征和掩码存入记忆模块,用于后续目标模型的更新。与STMVOS 相比,FRTM 在取得有竞争精度的同时,速度是前者的3.5倍。但是,FRTM 依然存在以下问题:1)FRTM 在处理完每一帧后都将对应的特征信息和掩码存入记忆模块,这无疑会导致记忆模块中存在许多重复和冗余的信息;2)FRTM 存储记忆帧时,仅是机械地对最新存入的特征信息赋予固定比例的权重,而并没有考虑当前帧的表征质量,这对训练一个具备强有力判别力的目标模型显然是不利的。
针对FRTM 算法所存在的问题,本文提出一种自适应权重更新的轻量级视频目标分割算法。首先,为了给表征质量更高的特征信息赋予更高的权重,所提算法通过掩码映射的方式,判定当前帧的表征质量并赋予对应的权重;其次,为了减少冗余信息,本文算法使用新的信息存储策略,构造了一个轻量级的记忆模块。实验结果表明,在常用的视频目标分割数据集DAVIS(densely annotated video segmentation)2016 和DAVIS2017 上,本文算法的性能和速度都明显优于FRTM,在近年来流行的视频目标分割算法中具有一定的优势。
1 本文算法
为去除记忆模块中的多余信息,建立一个目标判别性较强的视频目标分割模型,本文算法在FRTM 基础上,通过优化信息存储策略,重新构建了一个轻量级的记忆模块;使用新提出的特征表征质量判别方法,自适应地给存入记忆模块的特征赋予对应的权重。
1.1 FRTM简介
FRTM包括ResNet-101(residual network)主干网络、目标模型、高斯牛顿优化器、分割网络和记忆模块等5 个部分。算法整体框架如图1 所示。该算法用主干网络对视频的每一帧进行特征提取,目标模型以此特征作为输入,输出目标的粗略掩码并送至分割网络,分割网络利用主干网络所提取的浅层特征对粗略掩码进行逐级细化,输出目标的精细分割掩码,每一帧赋予权重后的特征信息和对应精细掩码都会保存至记忆模块,用于对目标模型进行在线更新。每帧的权重都是根据上一帧的权重线性更新的,以此保证最后处理的帧总是具有最高的权重,而具有更高权重的特征信息会对目标模型的更新做出更大的贡献。FRTM 将记忆模块的容量设置为80,每当记忆模块的容量达到8 的倍数时,高斯牛顿优化器就会利用该模块中的信息对目标模型进行在线更新,不同于以往对整个模型进行在线更新的方法,FRTM 的目标模型仅包括两层简单的卷积,这使得该算法分割速度可达21.9 帧/s,有效解决了在线更新耗时的问题。

图1 FRTM算法整体框架图Fig.1 Overall frame diagram of FRTM algorithm
1.2 特征通道多样性
深度卷积神经网络(deep convolutional neural network,DCNN)为计算机视觉领域带来了一系列突破。深层网络以端到端的多层方式自然地集成了低/中/高层次的特征,浅层主要包含目标的低级空间轮廓信息,深层则含有高级语义信息,二者都对目标的表征起着重要的作用。卷积核是DCNN 的主要组成部分,同层的每个卷积核都对上一层输出的特征进行卷积操作,并输出一个二维张量,此张量作为本层输出特征的一个通道,将这些张量堆叠起来就构成了本层输出的特征图。值得注意的是,每个卷积核所“关注”的目标类别(车辆、人、天空和动物等)是多种多样的,当卷积核处理的特征包含它所“感兴趣”的类时,输出的张量在对应位置就会表现出更高的激活值。本文在DAVIS2016 数据集中选取了3 组具有代表性的视频序列的一帧,并可视化了FRTM对其处理后保存至记忆模块的对应特征部分通道的热力图。如图2 所示,图2(c)在除目标外的背景区域上表现出更高的激活值,这表明对应的通道更加关注目标周围的干扰物而非目标本身,本文将其称为噪声通道(noisy channel);而图2(d)在目标区域上表现出更高的激活值,本文将其称为目标通道(target channel)。

图2 通道可视化热力图Fig.2 Visual thermal map of channel((a)frames;(b)ground truth;(c)noisy channel;(d)target channel)
在对目标模型进行迭代更新时,FRTM 只是不加区分地赋予最新的帧更高的权重,而并没有考虑特征本身对于目标的表征程度。考虑到目标模型主要学习目标的外观信息,本文提出了如下猜想:如果根据特征对于目标的表征程度和特征对应视频帧的先后顺序,综合赋予特征对应的权重,是否会对目标模型的优化更有帮助?因为最近的帧更能反映目标当前的运动状态与外观信息,而对目标表征程度更高的特征应当更有助于目标模型学习目标的外观信息。
为了验证这一想法,本文从特征目标通道的占比着手,提出了一种特征表征质量判别方法,并重新设计了特征权重计算方式,采用该计算方式后,算法的性能取得了明显的提升,详细的实验结果将在第2 节中介绍,具体的特征表征质量判别方法和特征权重计算方式将在1.3节中介绍。
1.3 自适应权重更新
基于上述分析,为了得到一个目标判别性更强的目标模型,本文利用掩码映射的方式判定每帧对应特征的表征质量。
式中,G为下采样函数,运算符号×表示逐点相乘对于特征本文采用表示xn的每个通道对目标的平均关注度,具体为
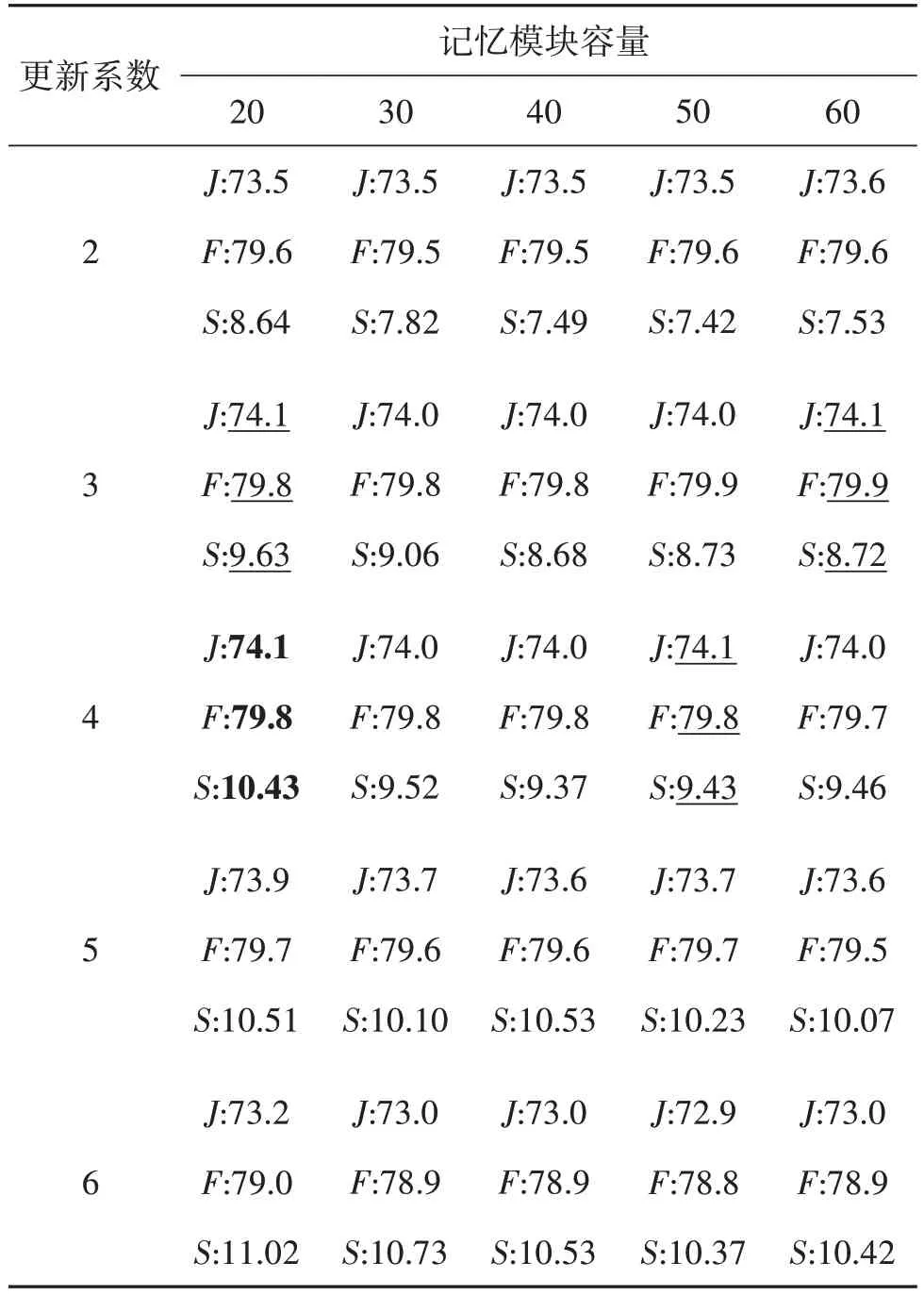
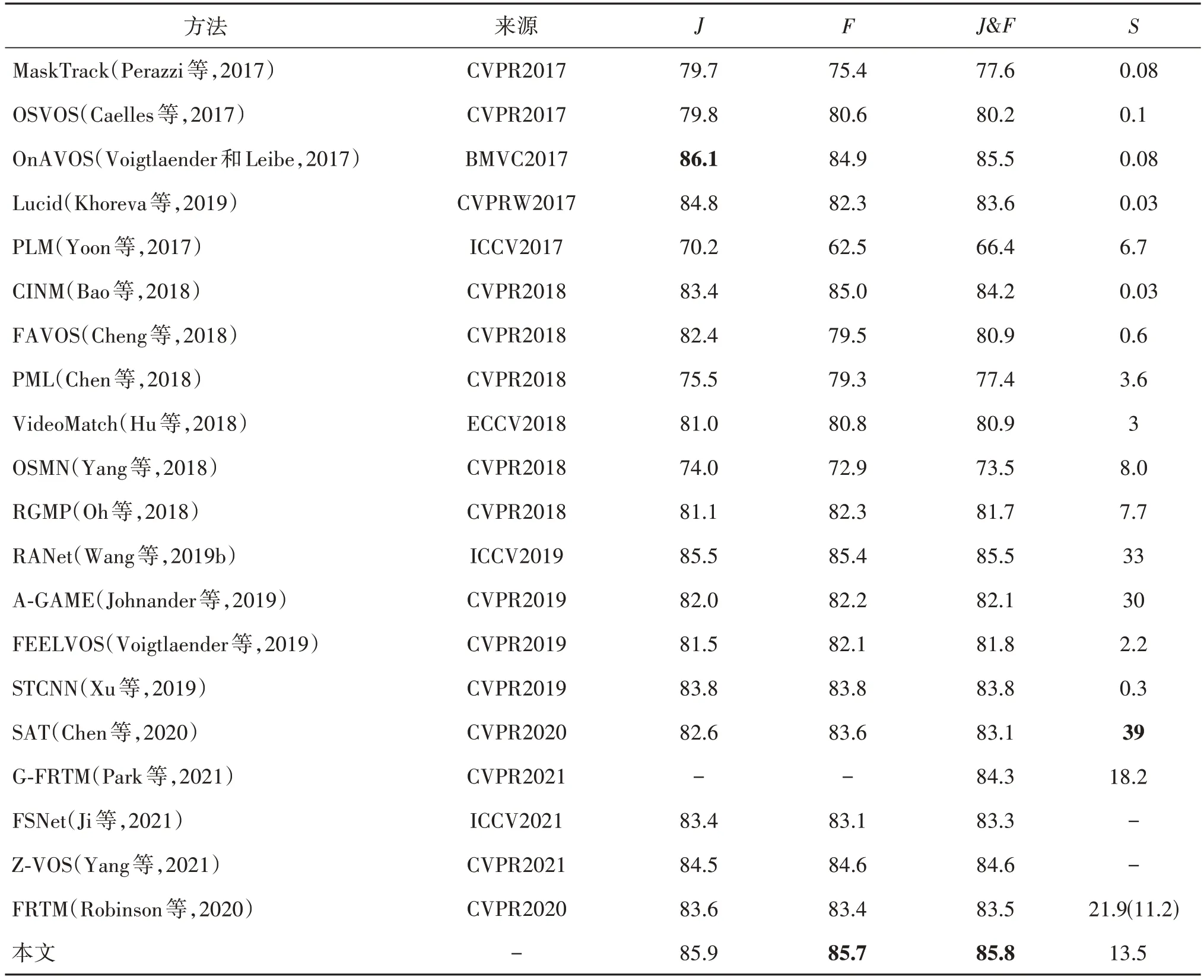
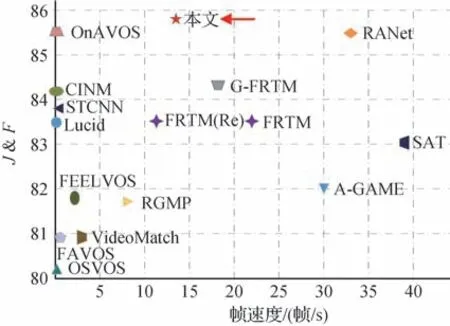
式中,c为特征xn的通道总数。对于特征xn对应的各个通道的目标关注度统计其中大于等于目标平均关注度Yˉn的总数量Pn(0 Pn数量越大,表明特征xn中对目标关注度较高的通道越多,本文认为该种特征对目标具有更强的表征能力,应分配更高的权重,重新定义权重γn,具体为 式中,lr为线性权重更新率,本文与FRTM保持一致,皆为0.1。FRTM原始的权重更新方式为 相比于式(4),式(3)在赋予权重时既考虑了帧的先后顺序,又考虑了特征xn对于目标的表征程度,从两方面综合自适应地赋予特征xn相应的权重,这对于训练一个具备强判别力的目标模型是非常有用的,新的权重更新方式更有助于目标模型捕捉目标对象的外观,输出准确和鲁棒的粗略掩码,给后续的细化操作提供一个强有力的可靠指导,第2 节的实验将对此进行证明。 在大部分的视频序列中,可以自然地发现相邻两帧之间的差异是很小的,FRTM 每帧都保存的处理方式不可避免地会引入更多的冗余信息,拖慢算法速度。因此,为了剔除记忆模块中不必要的冗余特征信息,保留关键特征信息,提升算法的运行速度,本文算法在DAVIS2017 数据集上,对记忆模块的容量设置,以及更新目标模型的时间做了大量相关实验。表1 给出了其中的部分结果,其中,更新系数代表当记忆模块的实存帧数达到相应的倍数时对目标模型进行在线更新;J和F为DAVIS2017数据集上的评价指标,分别代表与掩码真值相比,预测掩码相对应的区域相似度与轮廓准确度(数值采用百分比%);S代表算法的运行速度,单位为帧/s。不同于FRTM,本文仅将连续两帧中的一帧存入记忆模块。 表1 记忆模块容量及目标模型更新时机的实验结果Table 1 Experimental results of memory module capacity and target model update timing 结果表明,记忆模块的容量设置为20,实存帧数达到4 的倍数时更新目标模型,算法的性能与速度达到综合最佳。因此,本文算法对FRTM 的存储和更新策略调整如下:首先,本文算法只将相邻两帧中的一帧存至记忆模块,并将记忆模块的容量调整为20;其次,当记忆模块的实存帧数达到4 的倍数时,本文算法利用其中的特征信息对目标模型进行更新。采用新的策略后,记忆模块中保存的特征与掩码信息容量为原来的1/4,相对于FRTM,有效提升了在线优化目标模型的速度,且算法精度不受影响。 为验证所提算法的有效性,采用DAVIS2016 和DAVIS2017数据集进行评估。下面分别介绍算法的训练细节、定性分析、定量分析和消融实验,从多个角度验证本文算法的有效性。 本文使用DAVIS2017 和Youtube-VOS(video object segmentation)两个数据集对所提算法进行训练,从同一视频序列中随机选择一个参考帧和一个或多个验证帧,然后执行训练迭代。首先,基于参考帧来优化目标模型权重;随后,将完整的网络与学习到的目标模型一起应用到验证帧上,以预测目标的分割掩码。网络中的参数是通过相对于真实标注掩码的二进制交叉熵损失反向传播来学习的。 在离线训练过程中,本文算法使用ADAM 优化器训练和学习分割网络的参数,并冻结主干网络的权值。ADAM 优化器的初始参数设置如下,学习率α=10-3,指数衰减率β1=0.9,β2=0.999,权重衰减系数为10-5,训练大约106次迭代,分成120个epoch。然后将学习率降低到α=10-4,接着训练140个epoch。 训练使用的实验环境如下:显卡为一块NVIDIA GeForce RTX 3090,内存为32 GB,操作系统为64 位的 Ubuntu 16.04,PyTorch版本为1.8.1。 为验证本文算法的有效性,在DAVIS2016 和DAVIS2017 数据集上评估所提出的方法,DAVIS2016 数据集包含50 个视频(480 p),在总共3 455帧中密集标注像素级对象掩膜(每一个序列一个),分为一个训练集(30个视频)和一个验证集(20个视频)。DAVIS2017数据集包含多个对象的视频,是DAVIS2016 的扩展,它包含了60 个视频的训练集,30个视频的验证集以及3个视频的测试集。在所有的数据集中,训练集、验证集和测试集之间没有重复的视频序列。DAVIS系列数据集的评价指标主要有Jaccard index(J)和F-Measure(F)。Jaccard index 为分割结果和标注真值掩膜的交并比,度量了标注错误像素的数量。F-Measure 是综合准确率和召回率的评价指标,它衡量的是预测掩码与掩码真值之间的轮廓准确度。 表2 给出了本文算法与对比算法在DAVIS2016上的性能指标;图3给出了表2中部分算法与本文算法在DAVIS2016 上的性能—速度散点图。从中可以看出,所提算法的区域相似度J为85.9%,轮廓准确度F为85.7%,二者的均值J&F为85.8%,速度S为13.5 帧/s。对比早期的经典算法MaskTrack 和OSVOS,区域相似度J分别比它们提升了6.2%和6.1%;轮廓准确度F分别比它们提升了10.3%和5.1%;均值J&F分别比它们提升了8.2%和5.6%,速度S比它们快了两个数量级,性能大大领先。对比2017年—2021年的主流算法,所提算法的区域相似度J几乎实现了对它们的全部超越,仅略低于OnAVOS,而轮廓准确度F和二者的均值J&F均实现了对它们的全部超越。总体上,所提算法的性能具有明显的优势。 表2 DAVIS2016数据集上不同算法之间的性能对比Table 2 Performance comparison between different algorithms on DAVIS2016 dataset 图3 不同算法在DAVIS2016数据集的性能—速度散点图Fig.3 Performance-velocity scatter diagram between different algorithms on DAVIS2016 dataset 从表2 中可以看出,相比于FRTM,所提算法的区域相似度J和轮廓准确度F均提升了2.3%,同时速度S也更快。相比于同样针对FRTM 进行改进的G-FRTM(Park等,2021),均值J&F提升了1.5%。 表3 给出了本文算法与其他近年对比算法在DAVIS2017上的性能指标,图4给出了表3中部分算法与本文算法在DAVIS2017 上的性能—速度散点图。从中可以看出,所提算法的区域相似度J为75.5%,轮廓准确度F为81.1%,二者的均值J&F为78.3%,速度S为9.4 帧/s。对比早期的经典算法MaskTrack 和OSVOS,区域相似度J分别提升了24.3%和18.9%,轮廓准确度F分别提升了23.8%和17.2%,均值J&F分别提升了24%和18%,速度S依然快了两个数量级,相比于DAVIS2016,性能领先幅度更大。对比2017—2021 年的主流算法,所提算法的区域相似度J实现了全部超越,而轮廓准确度F仅略低于PReMVOS,二者的均值J&F实现了全部超越。从总体情况而言,所提算法的性能具有明显优势。其中,相比于FRTM,所提算法的区域相似度J和轮廓准确度F分别提升了1.7%和1.5%,同时速度S也更快。相比于同样针对FRTM 进行改进的GFRTM(Park等,2021),均值J&F提升了1.9%。 表3 DAVIS2017数据集上不同算法之间的性能对比Table 3 Performance comparison between different algorithms on DAVIS2017 dataset 图4 不同算法在DAVIS2017数据集的性能—速度散点图Fig.4 Performance-velocity scatter diagram between different algorithms on DAVIS2017 dataset 表2 和表3 都在S列中给出了FRTM 的速度,括号前的数值为FRTM 论文中的数据,对应图3 和图4中的FRTM,而括号内是本文使用FRTM 算法给出的权重模型在本地测试出的数据,对应图3和图4中的FRTM(Re)。FRTM 使用的GPU 为NVIDIA Tesla V100,而本文使用的GPU 为NVIDIA GeForce GTX1080Ti。由于硬件环境不同,导致两个数值存在一定差异。 图5 给出了本文算法与FRTM 在DAVIS2016 和DAVIS2017 上的分割效果图,前两行来源于DAVIS2016,后4 行来源于DAVIS2017。可以看出,在Scooter-Black 行中,FRTM 只分割出了目标“摩托车”的一部分区域,漏分了目标“摩托车”的尾部,所提算法则完整地将目标“摩托车”分割出来;在Soapbox 行中,FRTM 只分割出了“两车一人”中的一人和一车,漏分了位于左上位置的人,所提算法做到了没有遗漏的分割;在Camel 行中,FRTM 出现了明显的相似目标误判,误将目标“骆驼”旁边的骆驼也分割出来,而所提算法则避开了相似物的干扰,实现了目标“骆驼”的精准分割;在Drift-Chicane 行中,FRTM误将目标“赛车”带起的烟雾进行了分割,出现了背景误判现象,而所提算法则给出了目标“赛车”没有任何漂移的分割掩码;在Shooting 行中,FRTM 只实现了目标之一“枪”的部分分割,而所提算法则将其完整地分割了出来;在Dogs-Jump 行中,FRTM 没有识别到位于该帧图像中最右侧的目标“狗”,出现了目标丢失现象,而所提算法依然能精准地识别并分割出该目标。 为了验证所提算法各个策略的有效性,在DAVIS2017 数据集上进行消融实验,结果如表4 所示。其中,skip 表示是否采用新的记忆模块存储和更新策略,update 表示是否采用新的权重更新方式。结果表明,新的记忆模块存储和更新策略有效提升了算法的速度,对算法性能的提升也有一定的帮助,而新的权重更新方式在对算法速度影响很小的前提下,显著地提升了算法性能,二者结合之后又将本文算法的性能提升到新的高度。 表4 本文算法在DAVIS2017上的消融实验Table 4 Ablation experiment of this algorithm on DAVIS2017 本文提出一种自适应权重更新的轻量级视频目标分割算法。首先,为了更敏锐地捕捉到目标所在区域,削减噪声信息对目标模型的影响,算法对存入的特征信息表征质量进行评估后赋予对应的权重;其次,使用轻量级的记忆模块存储历史帧的相关信息。在DAVIS2016 和DAVIS2017 两个视频目标分割领域常用的数据集上,本文算法的平均性能皆超过了所有的对比算法,在一些有挑战性的场景下,依然能给出目标准确和鲁棒的分割掩码,这也证明了本文算法的有效性。但本文所提对特征表征质量的判别方法略显粗糙,并且由于本文算法会对每一帧的特征进行保存,指导后续帧的分割,导致计算量增大,造成速度无法满足实时性要求。下一步将继续深入研究特征表征质量判别方法,考虑使用一些模块对特征表征质量进行更准确和更精细的判断,以更好地对基于记忆模块的视频目标分割算法进行优化,综合提升算法性能与运行时速度。1.4 轻量级记忆模块
2 实验结果
2.1 算法训练细节
2.2 定量分析


2.3 定性分析
2.4 消融实验

3 结论
猜你喜欢
当代陕西(2020年17期)2020-10-28
通信学报(2019年5期)2019-06-11
人大建设(2018年5期)2018-08-16
通信技术(2018年3期)2018-03-21
电信科学(2017年6期)2017-07-01
作文周刊·小学一年级版(2016年27期)2017-06-03
新湘评论·下半月(2016年4期)2016-05-05
新湘评论·下半月(2016年4期)2016-05-05
海外文摘(2016年4期)2016-04-15
浙江大学学报(工学版)(2015年4期)2015-03-01
