
自注意力融合调制的弱监督语义分割
2023-12-23 10:14石德硕李军侠刘青山
中国图象图形学报 2023年12期
石德硕,李军侠,刘青山
南京信息工程大学江苏省大气环境与装备技术协同创新中心,南京 210044
0 引言
语义分割是计算机视觉领域的一个非常重要且基础的研究方向,该任务利用计算机的特征表达来模拟人类对图像的识别过程,为给定图像的每一个像素分配一个语义类别标签。随着深度学习技术的快速发展,语义分割也取得了长足的发展与进步。作为一项密集型预测任务,语义分割模型(刘文 等,2021)的训练离不开大规模像素级标注数据,然而图像的像素级标注获取困难且耗时耗力。弱监督语义分割技术,由于其仅依赖弱标注数据训练分割模型,可以解决现有语义分割模型对于大量像素级标注数据的依赖问题,正在成为一大学术研究热点,常见的弱标注包括边界框标注,如SD(Isimple does it)(Khoreva 等,2017)利用边界框与Grabcut(Rother 等,2004)、MCG(multiscale combinatorial grouping)(Pont-Tuset 等,2017)生成的结果设计伪标签;涂鸦标注,如ScribbleSup(scribble-supervised)(Lin 等,2016)利用图模型将语义信息从涂鸦标注扩展到未标注像素;点标注,如SSPS(semantic segmentation with point supervision)(Bearman 等,2016)将点监督和图像通用先验融入损失函数,提高了伪标签质量;图像级标注,如DMG(dynamic mask generation)(陈辰 等,2020)利用网络多层特征动态生成伪标签。在上述弱监督标签中,图像级标注相比于其他方式更容易获得,同时,由于仅给出了图像中存在的具体目标类别信息,并没有指出目标类别在图像中的位置,基于图像级标注的弱监督语义分割也是最具有挑战性的,因此本文重点研究图像级标注下的弱监督语义分割方法。
基于图像级标注的弱监督语义分割方法通常采用卷积神经网络(convolutional neural network,CNN)生成类激活图,其可以精确定位目标位置,但对目标区域的覆盖范围往往过小,最终造成伪标签稀疏的问题。在Transformer(Vaswani 等,2017)的快速发展下,研究者们开始将视觉Transformer 引入弱监督语义分割任务,TS-CAM(token semantic coupled attention map)(Gao 等,2021)利用语义不可知的长距离自注意力对类激活图进行修正,从而得到更加完整的前景目标进行弱监督目标检测。MCTformer(multi-class token Transformer)(Xu 等,2022)引入多类token生成各个类别的注意力图,然后再利用自注意力图进行优化得到最终的目标类激活图。然而,现有的基于Transformer网络生成的类激活图往往包含过多的背景噪声,影响伪标签的精确度。实验发现,背景噪声的引入主要是由深层自注意力的不准确性导致的。
针对以上问题,本文提出了一种基于自注意力融合调制网络的弱监督语义分割方法。使用卷积增强的Transformer(Conformer)(Peng 等,2021)作为特征提取网络,能够得到更加鲁棒的特征表达。受卷积网络分支提取到的局部信息部分的影响,Transformer 结构的浅层自注意力会更加关注图像的局部细节特征,由浅层自注意力优化得到的类激活图往往包含较多的细节信息;深层自注意力则更加关注图像全局特征,其往往会错误地将前景和背景进行关联,对应的类激活图噪声很多,且准确度较低。将不同自注意力层直接进行叠加融合进而生成类激活图并不是最优的选择,缺乏对不同自注意力层重要性的考量。基于此,本文设计了一种自注意力自适应融合模块,根据自注意力值和层级重要性生成融合权重,融合之后的自注意力在保留目标细节的同时也能较好地抑制背景噪声。考虑到浅层自注意力对保持图像边界细节的贡献更大,深层自注意力对背景的引入较多,因此在融合过程中,对浅层自注意力赋予一个较大的权重,增大细节信息,对深层自注意力则乘以一个较小的权重,降低深层注意力的比重。尽管该操作会损失部分语义信息,但能够对背景噪声进行有效抑制。实验证明,部分语义信息的缺失并不会影响目标分类结果。此外,提出了一种自注意力调制模块,通过设计调制函数校准不同像素对之间的亲密度,增大前景像素间的激活响应。最后使用调制后的自注意力优化初始类激活图(融合卷积分支和Transformer分支得到),得到的类激活图可以覆盖较多的目标区域,同时有效抑制背景噪声,最终得到高质量的伪标签。
本文的贡献点总结如下:1)提出了一种基于自注意力融合调制网络的弱监督语义分割方法,得到的类激活图可以较为准确且全面地覆盖前景目标区域。2)针对Transformer浅层和深层自注意力的不同特性,设计了一种自注意力自适应融合模块,生成的类激活图在保留目标细节信息的同时较好地抑制了背景噪声。此外,构建了一种自注意力调制模块,通过校准像素对之间的亲密度关系增大前景像素激活响应。3)本文算法在常用的PASCAL VOC 2012(pattern analysis,statistical modeling and computational learning visual object classes 2012)数据集和COCO 2014(common objectes in context 2014)数据集上进行实验,其结果验证了所提算法的可行性与有效性。
1 相关工作
本部分首先介绍基于卷积神经网络(CNN)的弱监督语义分割方法,其次对Transformer 在弱监督语义分割中的应用进行分析。
1.1 基于CNN的弱监督语义分割
现有的图像级标注下的弱监督语义分割方法大都基于卷积神经网络训练分类器生成类激活图,之后使用类激活图生成伪标签训练分割网络。该类方法得到的类激活图往往覆盖较小且稀疏的目标区域,由此生成的伪标签不能达到训练分割网络的需要。后来工作的重心在于如何使得分类网络能够激活更大的前景目标区域,以获得高质量的伪标签。现有的方法主要分为两种,一种是基于擦除的思想,典型的方法是AE(adversarial erasing)模型(Wei 等,2017),该方法首先擦除原图中对应类激活图的高鉴别性区域部分,之后重新训练分类网络,迫使分类器关注剩余目标部分。SeeNet(self erasing network)(Hou 等,2018)对上述模型进行了改进,通过设置两个不同的阈值,划定擦除范围,防止过度擦除到背景部分。FickleNe(tLee等,2019)通过随机擦除学习到的特征,增强类激活图中前景的连贯性,以此扩大前景目标区域。CPN(complementary patch network)(Zhang 等,2021)网络将图像拆成互补的两部分,扩大类激活图响应区域。基于擦除的方法步骤复杂,不容易抑制背景噪声,且结果往往存在上限,很难得到最优的结果。区域生长是另一种较为流行的类激活图扩展方法,其中SEC(seed,expand and constrain)(Kolesnikov 和Lampert,2016)是一种最为经典的模型,该方法将分类网络产生的区域视为种子区域,之后设置扩张和抑制损失函数,对种子区域进行 扩张约束。DSRG(deep seeded region growing)(Huang 等,2018)对SEC 方法进行了改进,提出了在线更新种子区域的策略,得到的类激活图响应区域更大且更准确。MCOF(mining common object features)(Wang 等,2018)模型利用分割网络和分类网络相互迭代训练,逐步扩大图像中的前景区域。IRNe(tinter-pixel relations network)(Ahn 等,2019)则利用类激活图中的可靠区域获得目标边界,然后对种子区域进行随机游走,进一步提升分割性能。观察到分类器的关注区域不断变化的特点,OAA(online attention accumulation)(Jiang 等,2019)模型将不同的激活区域相累加以获得更加完整的前景目标。DRS(discriminative region suppression)(Kim 等,2021)方法通过抑制种子区域峰值,迫使分类器定位更多的目标区域。擦除或区域生长方式一定程度上增大了类激活响应区域,但不能完整准确地覆盖目标区域,获得伪标签的质量还有很大的提升空间。
1.2 基于Transformer的弱监督语义分割
不同于卷积神经网络,Transformer(Vaswani 等,2017)是一种基于全局自注意力的模型,在特征提取的过程中关注全局信息,其对生成具有准确前景目标的伪标签至关重要。ViT(vision Transformer)(Dosovitskiy 等,2021)模型将Transformer 引入到视觉领域,在图像分类问题中具有较好的表现。TSCAM(Gao 等,2021)首次将Transformer 引入到弱监督目标检测领域,利用与类别无关的自注意力对类激活图进行修正扩大,这对弱监督语义分割任务很有启发意义。随后,MCTformer(Xu 等,2022)在生成类激活图的过程中,通过增加Transformer中token的数量解决了只使用一个token时类别不可分的问题。AFAne(taffinity from attention network)(Ru 等,2022)利用Transformer 挖掘图像像素之间的相似度关系,提出了一种可以对自注意力进行约束的端到端学习模型。TransCAM(Transformer CAM)(Li 等,2022a)通过简单叠加不同层次的自注意力,对卷积网络得到的初始类激活图进行扩张。然而,由于Transformer 关注于图像全局特征,通过自注意力得到的类激活图往往带有过多的背景噪声。本文重点关注于从浅层到深层的自注意力的不同特性,对注意力进行约束融合调制,进而优化类激活图,在突出前景目标的同时有效抑制了背景噪声,提高了伪标签的质量。
2 本文方法
本文提出了一种自注意力融合调制模型,用于图像类别标签下的弱监督语义分割任务,该模型主要由3 部分组成:1)结合卷积网络和Transformer 进行高鉴别性特征提取,充分利用卷积神经网络的局部信息和Transformer 的全局信息,生成初始类激活图;2)自注意力自适应融合模块,能够自适应度量多层级自注意力重要性,有效降低背景区域激活概率;3)自注意力调制模块,利用像素对之间的自注意力关系,设计调制函数,扩大前景和背景像素之间的距离,以突出前景。具体框架图如图1所示。

图1 自注意力融合调制模型Fig.1 Self-attention fusion and modulation model
2.1 初始类激活图生成
针对密集型语义分割预测任务,局部特征和全局特征的综合利用对于高质量伪标签的生成至关重要。卷积网络可以对局部区域进行很好地建模,但缺乏对全局信息的刻画,而Transformer 在得到全局特征的同时难于抽取细粒度的局部特征。因此,本文使用卷积增强的Transformer(Conformer)作为特征提取网络,具体结构如图1 灰色方框所示。Conformer 的核心在于两个分支之间的信息共享,通过设计特征耦合单元(feature coupling unit,FCU),使得学习的特征更加鲁棒,提取到的信息更加全面。Conformer 首先采用卷积提取初始特征,然后将初始特征输入到两个分支当中,上分支为用于提取局部特征的卷积网络,在网络的终端额外加入一层卷积层,将通道数改为类别数量,进而生成卷积类激活图(convolutional class attention map,ConvCAMs)。Conformer 的下分支为Transformer 结构,该分支首先利用一个卷积操作将初始特征映射为块嵌入(对应n个token),并额外增加1 个token,之后将n+1 个token 作为多头自注意力模块的输入,经过L个自注意力层进行特征提取。与卷积分支不同,这里将生成的特征向量进行重组(reshape),生成宽和高相等的特征图,之后利用卷积层改变通道数为类别数量,得到基于Transformer 结构的初始类激活图(Transformer class attention map,TransCAMs),具体为
式中,RS代表reshape 操作,Conv·表示1 × 1 的卷积操作,FC和FT代表对应卷积分支和Transformer分支的输出特征图。MC和MT分别为卷积分支和Transformer分支的初始类激活图。
2.2 自注意力自适应融合
卷积初始类激活图可以准确定位目标位置,但前景激活区域较为稀疏。相比于MC,Transformer 初始类激活图MT能够覆盖较多的目标区域,但并不能一致地突出整个目标部分。因此,需要联合MC和MT,充分利用两类初始类激活图之间的互补信息,并进一步优化联合后的结果,得到较为完整覆盖目标区域的类激活图。Transformer 分支的自注意力刻画的是像素对之间的亲密度关系,可以借助亲密度对类激活图进行调整。在Conformer 网络中,Transformer结构的前向传输计算为
式中,tl表示Transformer 中第l层的输入分别是线性转换参数,用来对图像块进行空间映射计算长范围的关系。为标准差,目的是防止出现过大的值,不利于网络训练。Al表示Transformer 网络中第l层中的注意力关系矩阵,可以刻画全图的亲密度关系。双分支信息共享后得到的Transformer不同层级的自注意力特性不同,浅层自注意力重点突出了图像的局部细节;深层自注意力则更加关注图像整体信息,并且受卷积网络深层卷积全局语义关系的引导,在计算Transformer 的深层自注意力过程中,部分前景背景像素间的亲密度值过大,导致前景和背景像素的错误关联,如图2 所示,其中左侧数字代表自注意力层级。

图2 Transformer自注意力结果Fig.2 The results of the self-attention in Transformer
对不同层级自注意力直接叠加融合,调整类激活图并不是最优的选择,会引入过多的背景噪声。本文设计了一种自注意力自适应融合模块,根据自注意力值和层级重要性生成融合权重。对此设计了一种加权系数,对每一层自注意力的重要性进行评估,然后相乘叠加,削弱噪声的影响。对于离散的自注意力,取值越大,重要性就越高。首先对所有层级的自注意力使用softmax 操作,获得各层级每个位置的权重。此外,考虑到由浅层到深层自注意力重要性的不同,浅层自注意力对像素对之间关系的刻画更为准确,融合的过程中应赋予较大的权重,而对于含有较多不准确亲密度值的深层自注意力赋予较小的权值。权值计算为
L层自注意力自适应融合之后的结果为
式中,Ak表示第k层自注意力图。融合之后的结果在保留原始特征图细节信息的同时,有效削弱了噪声的影响,大大提高了背景的纯度。
2.3 自注意力调制
自适应融合后的自注意力较好地刻画了像素对之间的相似度,为了进一步增大前景像素的激活响应,设计了自注意力调制模块。通常情况下,像素对之间的相似度越高,自注意力图中相应位置处的激活值就越大,反之激活值越小。通过抑制前景和背景像素对之间相似度值的同时增大前景像素间相似度较高的值,调整像素对之间的相似度,可以自适应调制自注意力,进而提高前景和背景之间的距离,达到突出前景区域的目的。本文采用指数函数对自注意力值进行调制,具体为
式中,N(⋅)表示归一化操作表示调制权重。之后利用哈达玛积将权重矩阵和注意力图相乘,得到调制之后的自注意力。具体为
式中,∘表示哈达玛积。
调制之后的自注意力较准确地刻画了像素对之间的相似度,包含了丰富的语义信息,因此可以用来优化初始类激活图(MC和MT)以生成具有更加完整目标的类激活图M,具体操作为
式中,Fusion表示融合操作。调制之后的类激活图能够覆盖较多的目标区域,同时有效抑制背景噪声。之后,使用随机游走获取伪标签,进而进行训练语义分割网络。
3 实验与结果
3.1 实验设置
本文模型是基于PyTorch深度学习框架实现的。在分类网络的训练阶段,采用Conformer 作为特征提取网络,并在推理阶段嵌入层级自适应融合模块和自注意力调制模块。在训练过程中,损失函数采用多标签交叉熵损失,优化器使用Adam 优化器,批量大小设置为6,epoch 设置为20。学习率取值为5 ×10-5,权重衰减为5 × 10-4。在数据预处理方面,将长边尺寸随机设置在320到640之间,并进行随机水平翻转,图像的亮度、对比度、饱和度值均取0.3。此外对图像进行归一化处理,同时进行随机裁剪。对于验证伪标签质量的DeepLabv2 网络(Chen 等,2018),训练20 000步,学习率、权重衰减分别设置成2.5 × 10-4和5 × 10-4。图像增强方面,将长边尺寸随机设置在200~800 像素之间的同时在左右方向进行随机翻转。
3.2 数据集和评价标准
本部分将在数据集PASCAL VOC 2012(Everingham 等,2010)和COCO 2014(Lin 等,2014)上验证所提模型的可行性与有效性。PASCAL VOC 2012 数据集是弱监督语义分割常用的数据集,训练集和验证集的图像数量分别为1 464 幅和1 449 幅,其中训练集通常采用额外数据(Hariharan 等,2011)扩充后的10 582 幅图像。测试集包含1 456 幅图像,由于测试集的标签没有公布,为了评估模型指标,需要将模型预测图提交到官网进行评价。PASCAL VOC 2012数据集一共包含20个目标类别,外加一个背景类。COCO 2014 数据集含有80 个目标类别,外加一个背景类,其中训练集的数量为82 081,验证集为40 137。本文采用的评价指标为平均交并比(mean intersection over union,mIoU),其度量的是预测图和真实标签之间的平均交并比,计算为
式中,P表示预测结果,G表示真实标签,area(·)表示对应区域面积,C为数据集中目标类别数量。
3.3 模型分析
3.3.1 消融实验
本文使用卷积增强的Transforme(rConformer)进行特征提取,之后设计了自注意力自适应融合模型和自注意力调制模型进行类激活图的计算。因此,本部分以卷积网络为基准,进一步验证Transformer分支、融合模块和调制模型的有效性。表1 列出了各个模块在PASCAL VOC 2012 训练集上得到的类激活图的平均交并比(mIoU)。

表1 不同模块的消融实验Table 1 Ablation experiments with different modules /%
如表1 所示,基准模型的平均交并比为27.7%,指标值较低的原因正是由于卷积分支类激活图的稀疏性造成的。在融合Transformer分支(记为Trans分支)之后,生成的类激活图其mIoU 达到了35.1%,该结果很好地验证了充分利用局部信息和全局信息的有效性及必要性。融入自适应融合模块之后,指标提升了14.4%,该实验充分说明,在考虑每个层级自注意力重要性之后,加权融合得到的自注意力可以高效抑制背景噪声。如表1 最后一行所示,加入调制模块之后,优化后的类激活图mIoU 值显著提升,相比基准模型提高了26.8%,比加入融合模块后的结果提高了5%。这些结果充分说明自注意力调制模块达到了区分前景和背景的目的,并且很好地突出了前景目标。
此外,图3 给出了不同模块得到的类激活图的可视化结果。如图3(a)所示,在双分支网络中,由卷积网络得到的类激活图可以有效定位目标位置,但鉴别性区域过小,而对应Transformer 分支得到的类激活图鉴别性区域较大,但同时带来了较多的背景噪声,如图3(b)所示。自注意力自适应融合之后对应的类激活图(融合CAMs)有效地较低了背景噪声。调制后的CAMs 有效扩大了前景和背景之间的距离,同时如图3(d)第3 行和第4 行所示,得到的类激活图还可以拉大不同目标类别之间的距离,以生成更加鲁棒的伪标签。

图3 不同模块对应的类激活图可视化结果Fig.3 Class activation maps recovered with different modules((a)C-CAMs;(b)T-CAMs;(c)fused CAMs;(d)modulated CAMs)
3.3.2 初始类激活图生成分析
图4 展示了初始类激活图生成示例。本文利用双分支的Conformer 特征提取模型作为骨干网络,使得卷积分支和Transformer分支上生成类激活图的方式达成一致,下面对对应的初始类激活图融合方式(如图1上半部分“融合”所示)进行分析。

图4 初始类激活图生成示例图Fig.4 Example map of initial class activation map generation((a)MC;(b)MT;(c)mutiply;(d)max;(e)mean)
如表2 所示,卷积分支的类激活图的mIoU 为27.7%,而对应Transformer 分支生成的类激活图的mIoU 值仅有25.2%,主要是因为该分支全局信息带来的大量噪声,导致背景部分过度激活。为了充分利用这两个分支的信息,需要将MC和MT进行融合。

表2 初始类激活图生成分析Table 2 Analysis of the initial CAMs generation
常见的融合方式包括:对应类激活图取大操作、相乘操作以及求平均操作。如表2 所示,取大操作带来的指标提升并不明显,分析主要原因是Transformer 分支生成的背景噪声,取大操作会保留大量的背景噪声,从而降低类激活图的质量。当采用两个类激活图对应位置相乘或取平均时,指标提升明显,mIoU 值分别达到34.1%和35.1%。相乘操作对应mIoU 值稍低主要是由于相乘会相应削弱Transformer 分支的语义信息。因此,在本文算法中,采用取平均的方式进行两类初始类激活图的融合,既可以保留两个分支的语义信息,又可以降低Transformer分支对应类激活图中背景噪声的影响。
3.3.3 自注意力融合分析
本文构建了一种自注意力自适应融合模块,以有效融合Transformer不同层级的自注意力。本部分将对不同的自注意力融合策略进行分析,主要包括4种情况:只使用最后一层自注意力、只使用第1层、L层求平均以及本文的自适应融合方法。其中第1种和第2 种方式是融合策略的两个特例。不用融合方式对应类激活图的mIoU 值如表3 所示。只使用最后一层的mIoU 指标仅有27.2%,该结果表明仅利用深层自注意力优化类激活图是远远不够的,原因在于深层自注意力的嘈杂性导致优化后的类激活图包含了过多的背景噪声,不能准确地挖掘出前景目标。当仅利用浅层自注意力进行优化时(使用第1 层),得到的mIoU 为38.7%,表明仅利用浅层的自注意力优化类激活图同样也不能得到高质量的伪标签。以上两个实验结果表明,单层的自注意力信息往往不够完整,因此需要将所有层的自注意力进行融合优化。如果将L层的自注意力直接相加而不考虑它们之间的重要性,mIoU 结果达到了44.9%,这表明了多层自注意力之间信息的互补性。然而求平均并不是最优的融合方式,因为深层自注意力错误的前景和背景关系,会导致背景区域被错误激活。当采用本文所提出的自适应融合方法时,实验效果达到了49.5%,相比于求平均融合方式提升了4.6%,该实验很好地说明了所提自注意力融合方式在优化类激活图时的有效性。自注意力融合示例如图5所示。

表3 自注意力融合分析Table 3 Analysis of the self-attention fusion

图5 自注意力融合示例图Fig.5 Example maps of self-attention fusion((a)images;(b)the first layer;(c)the last layer;(d)mean;(e)ours)
3.4 与先进算法的比较
3.4.1 伪标签对比
在生成类激活图之后,通常做法是利用IRNet(Ahn 等,2019)对其进行优化,然后使用分割网络的预测图得到伪标签,该操作称为后处理操作。在没有经过后处理操作的情况下,即直接对类激活图进行阈值化生成伪标签,其对应的mIoU 值为66.0%,如表4 所示。经过后处理之后,伪标签的mIoU 达到71.3%,提升了5.3%。同时,表4还给出了与最新其他方法生成的伪标签的对比结果,其中TransCAM(Li 等,2022a)方法使用了Transformer 提取特征,其他方法均为基于卷积网络的模型,在PASCAL VOC 2012 数据集的训练集上,本文方法取得了最优的伪标签结果。经过后处理之后,TransCAM 的mIoU 值为70.2%,本文方法比其高出1.1%。相比CPN(Zhang 等,2021)、AdvCAM(Lee 等,2021a)和SEAM(Wang 等,2020),本文方法伪标签的mIoU 值分别高出3.5%,3.5%,7.7%,该实验结果很好地证明了利用全局信息和局部信息恢复伪标签的有效性。
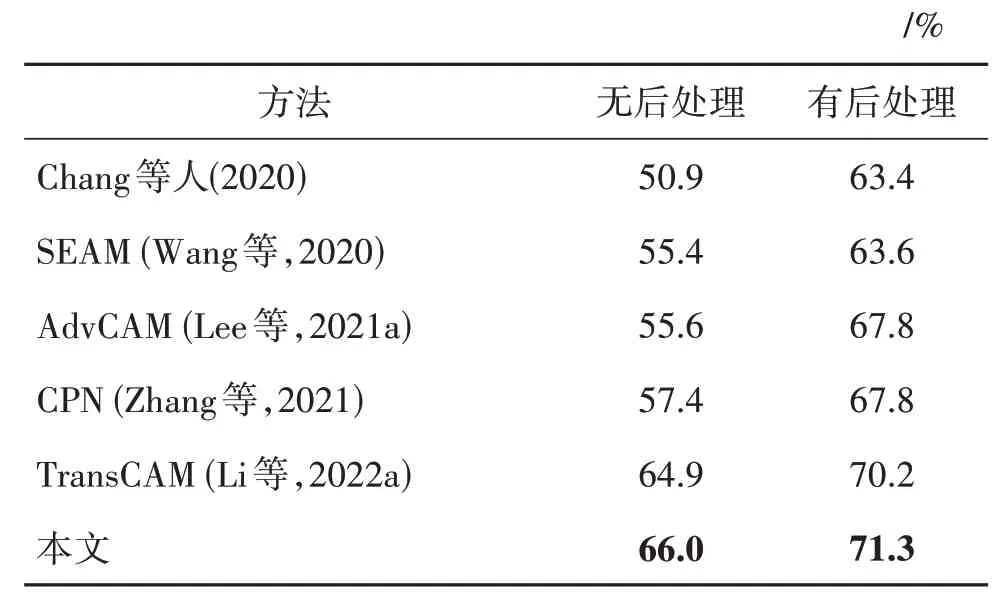
表4 伪标签对比实验Table 4 Comparison experiments of pseudo labels
同时,图6 给出在PASCAL VOC 数据集对应伪标签可视化示例,左侧一列代表原图和真值标签,右侧代表伪标签。从结果可以看出,本文方法得到的伪标签可以较完整地覆盖目标区域且具有干净的背景,并与真值标注十分接近。

图6 伪标签示例图Fig.6 Examples of the pseudo labels
3.4.2 分割结果对比
本小节将本文方法与最新的26 种基于图像级标注的弱监督语义分割模型进行分割性能比较,其中MCTformer(Xu等,2022)和TransCAM 在特征提取阶段使用了Transformer,其余24 种方法均为基于卷积神经网络的模型。值得注意的是,24 种基于卷积网络的方法中有14 种模型额外使用了显著性图信息。表5 给出了在PASCAL VOC2012 数据集验证集(val)和测试集(test)上,基于伪标签训练DeepLabv2模型得到的分割对比结果。其中,I 代表图像级标签,S代表显著性(saliency)信息。

表5 PASCAL VOC 2012 数据集上分割结果对比实验Table 5 Comparison experiments of segmentation results in PASCAL VOC 2012
如表5 所示,本文方法在PASCAL VOC2012 验证集上mIoU 指标为70.2%,测试集上达到了70.5%,在没有使用显著性信息的情况下,均为目前最优的结果。相比于基于卷积神经网络的模型,如IRNet(inter-pixel relations network)(Ahn 等,2019)、CIAN(cross-image affinity network)(Fan 等,2020b)、PMM(Li 等,2021)、AMR(activation modulation and recalibration)(Qin 等,2022)、SIPE(self-supervised image-specific prototype exploration)(Chen等,2022a),在验证集上mIoU分别高出它们6.7%,5.9%,1.7%,1.4%和 1.4%,较大的性能差距验证了卷积神经网络在生成伪标签时的局限性,即前景稀疏导致目标不完整的问题,此外,该结果也很好地验证了信息的完整获取对伪标签生成的重要性。对比基于Transformer 的模型,本文所提模型同样达到了最优,在验证集上,分别比MCTformer 和TransCAM 高出2%和0.9%;在测试集上,mIoU 相应高出2.1%和0.9%。相比较使用显著性图的方法,例如EPS(explicitpseudo-pixel supervision)(Lee 等,2021b)、NSROM(non-salient region object mining)(Yao 等,2021)、OAA(online attention accumulation)(Jiang 等,2019)等,所提模型也达到了相当的结果,甚至比大部分的模型还要好。本文方法摆脱了对显著性图提供背景信息的依赖,该结果也进一步验证了模型对背景噪声抑制的高效性。
表6 给出了在COCO2014 验证集上与其他方法的分割性能比较结果。其中,I 代表图像级标签,S代表显著性信息。所提模型同样达到了最优的效果,mIoU 值达到40.1%,比最新方法ReCAM(Chen等,2022b)高出0.5%。
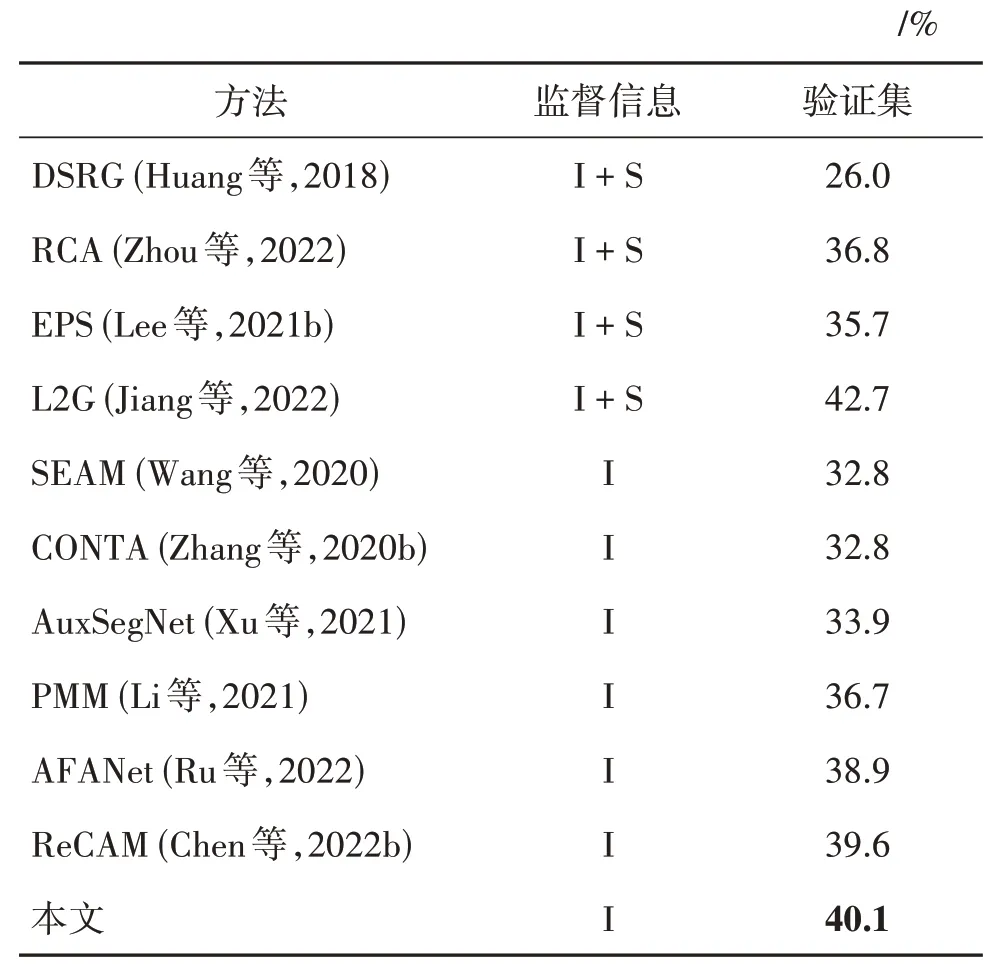
表6 COCO数据集上分割结果对比实验Table 6 Comparison experiments of segmentation results in COCO dataset
同时,图7 和图8 分别展示了在PASCAL VOC 2012 和 COCO 2014 的验证集上的分割结果示例。可以很清楚地看到,本文方法得到的分割结果与分割真值非常接近。

图7 在PASCAL VOC 2012验证集的分割结果示例图Fig.7 Examples of the segmentation results in PASCAL VOC 2012 validation dataset((a)images;(b)GT;(c)ours)

图8 在COCO 2014验证集的分割结果示例图Fig.8 Examples of the segmentation results in COCO 2014 validation dataset((a)images;(b)GT;(c)ours)
4 结论
为了解决伪标签前景稀疏和背景噪声过多的问题,本文提出了一种自注意力自适应融合调制的弱监督语义分割模型。利用Conformer 作为分类特征提取网络,其能够充分利用到卷积神经网络提取的局部特征和Transformer提取的全局特征。为了解决自注意力优化类激活图存在的背景噪声问题,提出了自注意力自适应融合模块,充分考虑到各层级自注意力的重要性,融合后的自注意力能够有效降低激活背景的概率。同时,为了扩大前景和背景的距离,更好地突出前景区域,设计了自注意力调制模块,利用指数函数对融合后的自注意力进行调制,增大前景的激活响应,最终得到具有较高准确性的伪标签以训练分割网络。一系列的对比实验充分证明了本文方法的优越性及其有效性。
本文方法提高了语义分割的精度,很大程度上降低了语义标签的标注成本,但是目前该方法也存在一定缺陷。如图9 所示,当图像中的目标经常同时出现时,例如火车和火车轨道,所得的类激活图往往不能很好地将它们区分开,导致前景目标边界不能很好地恢复。另外,当图像场景较为复杂时,分类器不能很好地定位目标,此时后续类激活图优化也会出现错误。

图9 失败示例图Fig.9 Failure examples((a)images;(b)GT;(c)our CAMs)
弱监督语义分割目前虽然已经取得了一定的发展,但是距离全监督分割精度还有一定的差距,所以首先可以继续提高伪标签的生成质量,解决上述缺点。其次,弱监督语义分割目前主流的方法是双阶段处理方式,即首先获取伪标签,然后再训练分割模型,这种方法虽然能够提高模型精度,但是无疑增加了弱监督语义分割任务的复杂性,因此端到端的弱监督语义分割方法是一大发展趋势。最后,弱监督在视频领域下的应用也有待挖掘。
猜你喜欢
噪声与振动控制(2022年3期)2022-07-04
小雪花·成长指南(2022年1期)2022-04-09
车迷(2018年11期)2018-08-30
海峡姐妹(2018年3期)2018-05-09
地震研究(2017年3期)2017-11-06
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
公民与法治(2016年10期)2016-05-17
应用海洋学学报(2015年1期)2015-11-22
计算机工程(2015年8期)2015-07-03
