
基于轻量化模型的钢轨扣件缺陷检测系统
2023-12-19 05:33孟建军吕德芳祁文哲胥如迅陈晓强
仪表技术与传感器 2023年11期
张 元,孟建军,2,3,吕德芳,祁文哲,胥如迅,2,3,,陈晓强,2,3,
(1.兰州交通大学机电技术研究所,甘肃兰州 730070;2.甘肃省物流与运输装备行业技术中心,甘肃兰州 730070;3.甘肃省物流及运输装备信息化工程技术研究中心,甘肃兰州 730070;4.兰州交通大学机电工程学院,甘肃兰州 730070)
0 引言
钢轨是铁路轨道的主要组成部件,钢轨扣件作为具有刚性扣压件的钢轨与轨枕的紧固装置零件,是保障铁路运营安全的重要组成部分[1]。研究表明,钢轨扣件通常因为加工工艺不达标[2]或是长时间受恶劣自然环境甚至是恶意的人为因素的影响会出现松动或损毁的状况[3]。
钢轨扣件检测以人工检修为主,其检测结果严重依赖巡检工人的技术熟练程度和环境因素,误检率较髙。随着机器视觉技术的广泛应用,出现大量目标检测模型并被使用于轨道状态检测工作。J.Chen等[4]提出了基于YOLO的一个级联三阶段的缺陷扣件检测网络,实现了较高的检测率;Y.Li等[5]将深度可分离卷积和特征金字塔结合到YOLO V3网络中,以提高缺陷检测的精度。YOLO是一种典型的单阶段模型,YOLO V5模型大小仅为27 MB,检测速度快,但基于COCO数据集[6]的 mAP (mean average precision,平均精度的均值)性能指标仅约36%;若使用YOLO V4,尽管mAP 性能指标接近43%,但是检测速度有所降低,并且模型体积高达245 MB。因此,为保证较高的检测精度和检测速度,提出一种改进YOLO V5模型,设计基于轻量化模型的钢轨扣件缺陷检测系统,通过摄像头拍摄和模型计算,最后将检测信息反馈到显示屏,并对比搭载未改进的原生YOLO V5模型的系统检测结果,验证本文方法的有效性。
1 系统总体设计
图1为系统的总体设计结构及硬件结构,系统硬件部分由嵌入式设备Jetson TX2(包括充当视觉传感模块的板载CSI摄像头)、内存卡、键盘、鼠标和便携式显示屏组成。图2为Jetson TX2的结构简图,其中的Tegra X2为整个嵌入式设备的计算处理模块,为检测和训练过程提供图像处理的算力;Jetson TX2自身搭载的CSI摄像头对摄像头视场范围内的钢轨进行扫描,并拍摄钢轨扣件;便携式显示屏通过VGA电缆线连接到Jetson TX2上,用于检测信息的显示;内存卡中存放着系统的软件部分,将内存卡插入SD卡槽并开启Jetson TX2,用键盘和鼠标对系统进行交互操控。

图1 系统总体设计及硬件结构

图2 Jetson TX2结构简图
图3为系统软件结构示意图。Jetson TX2开机后进入内存卡中存放的Ubuntu 18.04操作系统,在轻量化模型主目录下,摄像头调用程序操控CSI摄像头对钢轨扣件进行图像自动采集;训练程序用于检测工作开始前调用轻量化检测模型对扣件图像数据集进行训练并生成一个权重文件;检测程序用于调用轻量化检测模型并使用训练得到的权重文件对CSI摄像头实时拍摄的扣件图片进行检测。

图3 系统软件结构
图4为系统进行扣件缺陷检测工作的流程,同时运行2个进程,分别实现对扣件进行自动拍摄和自动检测,提升效率。进程都是循环自动执行,当检测工作结束时只需关闭进程即可。

图4 系统检测钢轨扣件缺陷的流程
2 轻量化模型设计
图5为改进后的轻量化YOLO V5模型。在用于训练数据集时,将钢轨扣件图片压缩成特征图输入,经过主干网络backbone的卷积,扣件被分成S×S个网格,每个网格预测N个边界框和每个边界框的置信度和类别概率;而用于检测时,将整张图像输入模型,经过backbone的卷积后形成多维特征图,在Neck部分的Concat层进行特征图融合后,再经过UnSample层上采样提高图像分辨率[7],最后经过Detector部分的Conv2d卷积后输出所有扣件位置、类别和精度。改进点在于:将原生YOLO V5的主干网络更换为MobileNet V3,再向MobileNet V3的bneck层中引入CA协同注意力机制[7](coordinate attention)并修改激活函数为Mish,形成CAMish-MobileNet卷积网络(如图5所示),并以此网络构成轻量化模型。

图5 轻量化检测模型及轻量化网络结构
2.1 卷积网络的更换
MobileNet系列卷积神经网络[8]相较于Large版本,MobileNet V3-Small的基本单元bneck数量更少,在整体网络的参数量比MobileNet V2减少约20%,同时精度提高6.6%。MobileNet V3以深度可分离卷积为基本单元构建网络,深度可分离卷积由深度卷积和逐点卷积组成。深度卷积时,特征图的每个通道由一个卷积核进行卷积,卷积核数量等于通道数,其表达式如式(1)所示,F为输入特征图,C为宽W和高H的卷积核,特征图在第a通道上的(x,y)坐标经过宽和高2个方向的卷积核后得到该通道上的卷积核权重元素坐标(i,j)并输出为特征图G。
(1)
逐点卷积首先将卷积核尺寸设置为 1×1并使用深度卷积来提取每个通道的特征,再使用逐点的形式对通道的特征进行关联。深度卷积与逐点卷积累加的深度可分离卷积D的计算量如式(2)所示:
D=DC·DC·M·DF·DF+M·N·DF·DF
(2)
式中:DF、N分别为输入特征图F的边长和通道数;DC为深度卷积核的边长;M为逐点卷积的通道数。
相较于普通卷积,深度可分离卷积减少的计算量如式(3)所示:
(3)
当采用3×3的卷积核即DC=3时,深度可分离卷积的计算量约为普通卷积的1/9,达到轻量化的目标。
2.2 激活函数的修改
YOLO V5原生的激活函数是ReLU 6,若使用这种激活函数可能会出现梯度消失或梯度爆炸的问题。将激活函数修改为Mish,可解决包括MobileNet V3自带的Hard-Swish在内的大部分激活函数都无法解决的梯度消失或梯度爆炸的问题。计算公式如式(4)所示,x∈R时,f(x)无边界,避免了取值封顶而导致的饱和。这样平滑的Mish激活函数允许信息更好地深入,可减少卷积网络不稳定带来的不必要的计算量,在性能较低的嵌入式设备上运行更流畅。在原本参数量就较少的MobileNet V3卷积网络中使用Mish激活函数,最终检测精度比使用Hard-Swish和ReLU分别提高了0.494%和1.671%[9],达成了“轻量化但不损失精度”的目标。
f(x)=x·tanh[ln(1+ex)]
(4)
2.3 协同注意力机制的融入
包括MobileNet V3在内的众多卷积网络都采用了SE注意力机制,SE注意力机制仅考虑通道间的信息而忽略位置信息,致使全局信息全部压缩到通道中,当图片中出现多个扣件样本时会出现预测框位置不准确的情况。
为避免上述情况,引入一种高效注意力机制CA[7],它对于尺寸为C×H×W的特征图输入按照坐标为(i,j)的元素的水平W方向和垂直H方向进行池化,分别生成尺寸为C×H×1和C×1×W的特征图xC(h,i)和xC(j,w),如式(5)所示:
(5)
通过式(5)信息嵌入的变换后,接下来将C×H×1和C×1×W的特征图zh和zw进行拼接,之后使用1×1的卷积模块F1×1对其进行变换,将其维度降低为原来的C/r,经σ(即Sigmoid函数)激活得到特征图f,如式(6)所示:
f=σ(F1×1([zh,zw]))
(6)
如式(7),此时利用另外2个代表空间方向的1×1卷积变换Fh和Fw分别将fh和fw经σ激活得到2个方向的注意力权重gh和gw,输入得到CA协同注意力机制的最终输出yc如式(8)所示:
(7)
(8)
CA注意力机制同时考虑2个空间位置(i,j)方向的信息xc和yc,帮助模型更好地定位和识别目标,维度的降低带来更小的计算开销,使检测模型轻量化。
3 系统部署与测试
3.1 系统部署
如图6所示,按照图1的硬件结构方案搭建钢轨扣件缺陷检测系统的硬件部分,图6中细节之处在图7中展示,其中Jetson的具体型号配置为NVIDIA Jetson TX2 8 GB搭载四核ARM Cortex-A57 MPCore处理器、配有256核心NVIDIA Pascal架构及8 GB 128位LPDDR4内存,内存卡型号配置为SanDisk Extreme PRO 32 GB。按照图3的软件结构方案构造钢轨扣件缺陷检测系统的软件部分,将训练程序train_model.py、调用摄像头程序camera.py、检测程序detect_defects.py置于轻量化YOLO V5检测模型的主目录下,如图8所示。最后将系统安置在图9的轨道巡检小车上,在铁路上驾驶时实现钢轨扣件的自动拍摄与缺陷自动检测。

图6 系统硬件部分实物图

图7 Jetson TX2上的组件细节
3.2 模型训练
数据集有1 376张不同工况的钢轨扣件图片,包括扣件正常无缺陷(标注为normal)360张、扣件螺母丢失(标注为loss_nut)322张、扣件弹条缺失(标注为loss_sp)374张、扣件弹条断裂(标注为cracked_sp)320张,图像分辨率从128 pixel×98 pixel至750 pixel×1 000 pixel。整个数据集的1 376张钢轨扣件图片共有2 032个标注框,各工况的标注数量如表1所示。

图9 轨道巡检小车

表1 不同工况扣件的标注数量 个
在训练开始前,为了尽可能与未改进的YOLO V5清晰对比,超参数值设定使用与YOLO V5基本相同的配置[10]:模型初始学习率为0.005,训练迭代100轮,Batch Size(批归一化值)为8。
使用目标检测领域中常用的mAP@.5和mAP@.5:.95[6]作为模型训练的精度指标。
(9)
式中:n为类别数量;APk为第k类的平均精度;而mAP即所有k类平均精度的平均值。
实验中需预先设定预测框与真实框交并比IoU(intersection over union)阈值,mAP@.5是指IoU阈值取0.5时的mAP值,mAP@.5:.95是指当IoU阈值以0.05为步长,从0.5取至0.95时的mAP值的平均数。
运行训练程序train_model.py,使用设定好的超参数开始对钢轨扣件数据集进行训练。如图10所示,训练过程中,mAP@.5和mAP@.5:.95随着迭代次数的增加而增加。

(a)mAP@.5与迭代次数的关系
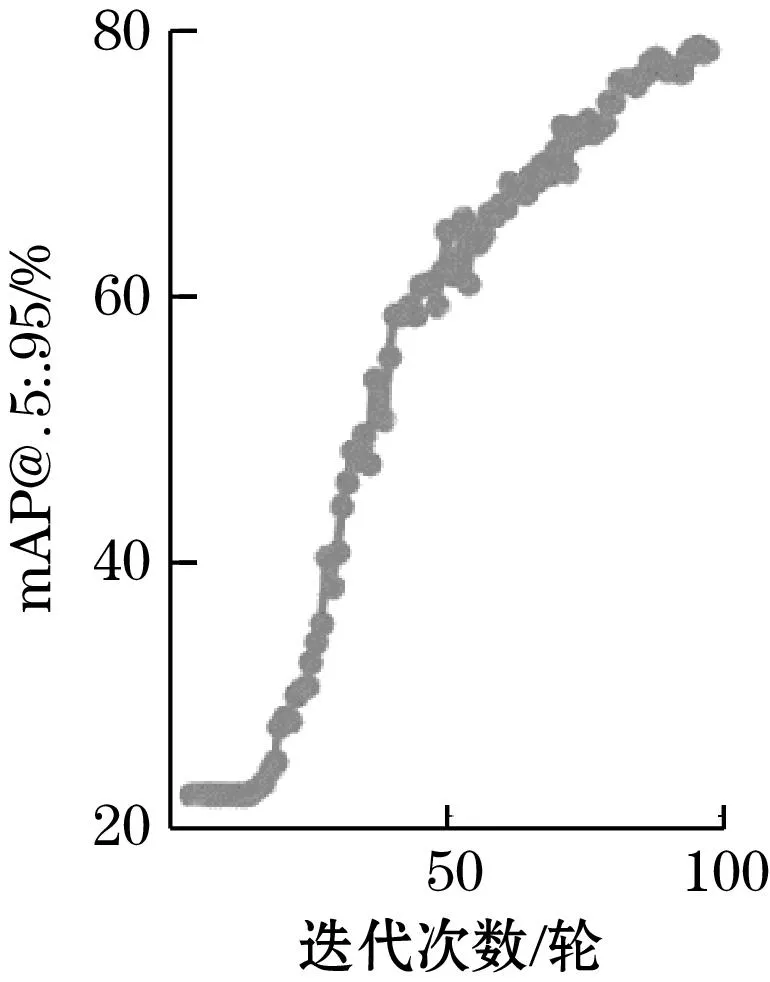
(b)mAP@.5:.95与迭代次数的关系
同理,使用原生YOLO V5训练数据集。将改进前后的模型的训练结果进行对比,mAP性能指标、模型大小和显存占用的情况如表2所示。

表2 模型改进前后对钢轨扣件数据集的训练性能比较
与原生YOLO V5模型对比可知,经过改进的轻量化YOLO V5训练精度mAP指标更高,模型体积更小且占用更少的显存,满足轻量化需求。
3.3 系统测试
巡检工人驾驶轨道巡检小车在铁路上行驶,同时操作部署在巡检小车上的钢轨扣件缺陷检测系统。如图11所示,打开终端,运行摄像头调用程序开启图像采集进程,摄像头对准钢轨扣件,每隔10 s拍摄1张新图片,本次测试拍摄了69张钢轨扣件图片,其中包含100个扣件样本,图片存放在fastener_pic目录下。

图11 系统拍摄钢轨扣件
将3.2节中经过轻量化模型训练数据集得到的权重yolov5-lightweight.pt如图8中置于轻量化检测模型的主目录下。同时打开另一个终端,运行检测程序,对fastener_pic目录下拍摄到的钢轨扣件图片进行检测,检测运行过程如图12所示。

图12 系统进行扣件缺陷检测
100个样本的扣件缺陷检测结果如表3所示。

表3 系统检测扣件缺陷结果 个
经系统检测输出后的部分扣件缺陷识别结果实物如图13所示。

(a)正确检测为“扣件正常”

(b)错误检测为“弹条断裂”

(c)正确检测为“弹条丢失”

(d)检测为“弹条丢失”但精度较低

(e)正确检测为“螺母丢失”

(f)错误检测为“扣件正常”
检测完成后,会在终端显示平均每张扣件图片的检测时间和FPS(frames per second,帧速率)。如表4所示,为使用改进前后YOLO V5得到的权重进行扣件缺陷检测的速度和FPS对比。结合上述检测结果,证明搭载轻量化模型的本系统具有实现检测速度更快、检测准确度更高的轻量化表现。

表4 改进前后的模型检测速度和FPS对比
3.4 系统改进
经过3.3节的测试,系统最终对于100个钢轨扣件样本的缺陷检测得到87%的准确率。进一步研究系统参数发现,在模型训练时,将超参数中的初始学习率进行修改,会影响最终系统检测的准确度。如图14所示,同样拍摄100个钢轨扣件样本,使用初始学习率设置为0.01时训练模型得到的权重文件来运行系统检测工作,误检个数仅为4个,准确度较学习率设置为0.005时提升10.3%。
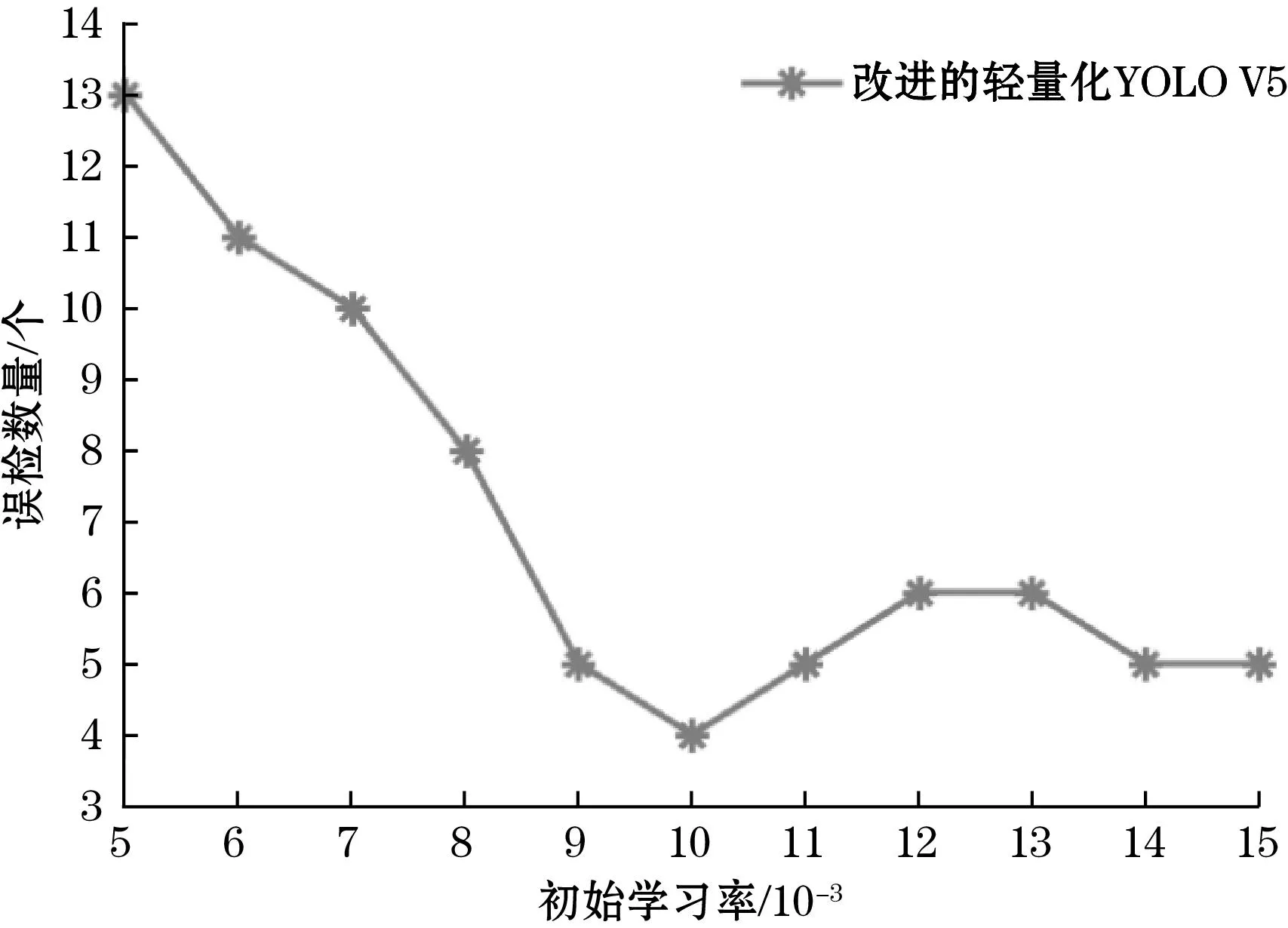
图14 误检个数与初始学习率的关系
4 结束语
设计轻量化模型,对YOLO V5目标检测模型的主干网络和激活函数进行修改,并融入协同注意力机制。调用经过训练扣件数据集得到的权重文件,对CSI摄像头拍摄到的钢轨扣件进行缺陷检测。
经实验测试,使用所设计的钢轨扣件缺陷检测系统,对单张扣件图片检测时间为56.8 ms,误检率为13%。对系统进行改进,增加初始学习率数值,发现将初始学习率设置为0.01进行训练得到的模型用于系统中,误检率仅为4%,相比系统改进之前,检测精度更高且速度不减,对算力和存储空间等硬件条件要求极低。
猜你喜欢
精密成形工程(2022年2期)2022-02-22
铁道建筑技术(2020年11期)2020-05-22
智富时代(2019年2期)2019-04-18
智富时代(2019年2期)2019-04-18
西南交通大学学报(2018年5期)2018-11-08
制造技术与机床(2017年8期)2017-11-27
西安建筑科技大学学报(自然科学版)(2016年5期)2016-11-10
专用汽车(2016年1期)2016-03-01
中国铁道科学(2015年5期)2015-06-21
中国铁道科学(2015年4期)2015-06-21
