
融合深度特征的改进KCF行人追踪算法
2023-12-14 12:19陈向阳周扬杨文柱
河北大学学报(自然科学版) 2023年6期
陈向阳,周扬,杨文柱
(河北大学 网络空间安全与计算机学院,河北机器视觉工程研究中心,河北 保定 071000)
行人追踪是计算机视觉领域中的一个重要研究方向,有着广泛的应用,如:视频监控、人机交互、行人流量观测、无人驾驶等.实际上追踪是通过确定某个特定的行人在视频每一帧中的位置来实现的.行人追踪的方法有基于神经网络的方法和传统的基于模板匹配的方法.主流的基于神经网络的方法是使用基于RPN(region proposal network)[1]的孪生神经网络[2]来进行追踪,Li和Yan提出的SiamRPN[3],不同于标准的RPN,SiamRPN在相关特征图谱上提取候选区域,然后把模板分支上的目标外观信息编码到RPN特征中来判别前景和背景.但SiamRPN模型还是很难区分图像中对象相似的情况.针对模型不更新以及抑制干扰物的问题,Zhu和Wang提出了干扰物识别模型DASiamRPN[4],并在检测过程中引入新样本实时更新模板,能有效地解决SiamRPN模型中存在的问题.在基于模板匹配的行人追踪方法中,可以使用SIFT(scale-invariant feature transform)特征[5]来确定行人的特征,把该特征作为模板,通过对下一帧的视频图像进行滑动窗口的匹配来确定行人的位置.Henriques提出了核相关滤波算法KCF[6]用于行人追踪,KCF算法使用行人图像信息和周围背景图像信息训练一个目标检测器,用于判断行人在下一帧中的位置.但KCF算法存在着3个缺陷:1)尺度自适应问题.目标检测器的大小不变,在视频中行人由于距离摄像头的远近不同,会导致行人目标大小的变化,最终导致目标检测框对目标追踪的不准确.2)KCF使用的HOG特征[7]存在缺陷.HOG特征使用梯度特征表示,所以对行人的姿势改变和颜色信息不敏感,从而导致追踪过程中出现追踪错误或者追踪丢失的问题.3)遮挡问题.检测器在行人目标被遮挡的情况下,没有办法在视频下一帧中给出行人目标的准确位置.
针对KCF算法的缺陷,设计了一种融合深度特征的改进KCF模型.使用用于目标识别的神经网络框架YOLO v3[8]来进行行人检测,结合KCF的预测位置,得到KCF新的模板,从而解决了KCF检测器不能随着目标尺度变化而变化的问题.在HOG特征不足以区分行人的特征时,融合了深度特征的度量方式来确定行人目标的位置.当行人被遮挡时,使用卷积神经网络获得被遮挡之前目标的深度特征并保留,将后续视频中出现的目标与保留的目标深度特征进行对比,如果相似度大于设定的阈值,则可以确定被遮挡的追踪目标重新出现.
1 基于尺度可变和深度特征融合的KCF行人追踪
1.1 KCF追踪算法
KCF全称为Kernel Correlation Filter 核相关滤波算法.自从2014年由Henriques等提出以后,由于其良好的追踪效果和追踪速度,引起了人们大量的关注.KCF算法引入多通道特征,利用追踪目标区域的图像提取出多通道HOG特征,然后对目标附近区域的图像采样,将采样作为训练样本,训练目标检测器.目标检测器训练好后,在下一帧中计算目标周围图像样本的HOG特征,使用高斯核函数计算样本和追踪目标图像HOG特征的相关性响应,响应值最大的图像就是追踪目标在该图像中的最新位置图像,之后在该图像中使用响应最大的图像重新训练目标检测器,使用离散傅里叶变换将上述过程从时域转为频域后,大大降低了计算量.
KCF算法采用式(1)的岭回归的方法来训练追踪器
(1)
其中,(f(xi)-yi)2为损失函数,λ为正则化参数,防止出现过拟合.
ω=(XTX+λI)-1XTy,
(2)
其中,X是一个矩阵,由采样数据向量xi组成,每一行代表一个样本;向量y由标签数据yi组成;I是单位矩阵.
在求解非线性函数中的ω时,由于不易确定非线性函数的形式,因此将xi映射到高维空间,就能将非线性问题求解转换为线性求解,因此ω可以用式(3)表示.
ω=∑iαiφ(xi),
(3)
将其带入线性回归函数f(z)中可以得到
(4)
其中,k表示核函数,KCF算法中使用的是高斯核函数.所以求得最小情况下的ω值,也就变成了求α的值.
通过核函数的岭回归算法对分类器建模,利用循环矩阵的傅里叶对角化对模型进行优化,实现了快速高效的追踪.
1.2 KCF的尺度自适应
KCF的追踪效果和追踪速度虽然不错,但当追踪目标尺度发生变化时,可能会丢失追踪目标.在KCF算法中,每次提取追踪目标图像的尺度始终不变,都是最开始的追踪目标的尺度大小,所以如果目标的运动导致离摄像头的距离发生变化,目标在图像中的相对尺度大小就会变化.如果目标框的大小不变,可能会导致提取的特征不完全,或者引入了变化的背景信息,从而导致追踪的失败.
针对KCF预测框不能随着目标尺度变化而变化的问题,引入与目标检测模型相结合的追踪方法,使KCF具有尺度自适应能力.因为目标追踪过程中,相邻图像帧中,追踪目标尺度变化幅度不会太大,这样就可以在新的一帧图像中,使用KCF预测出的新的目标坐标,结合目标检测模型,得出尺度大小符合追踪目标大小的新的目标框,使用新的目标框作为KCF目标检测器的训练模板,这样就实现了KCF的尺度自适应.流程如图1所示.
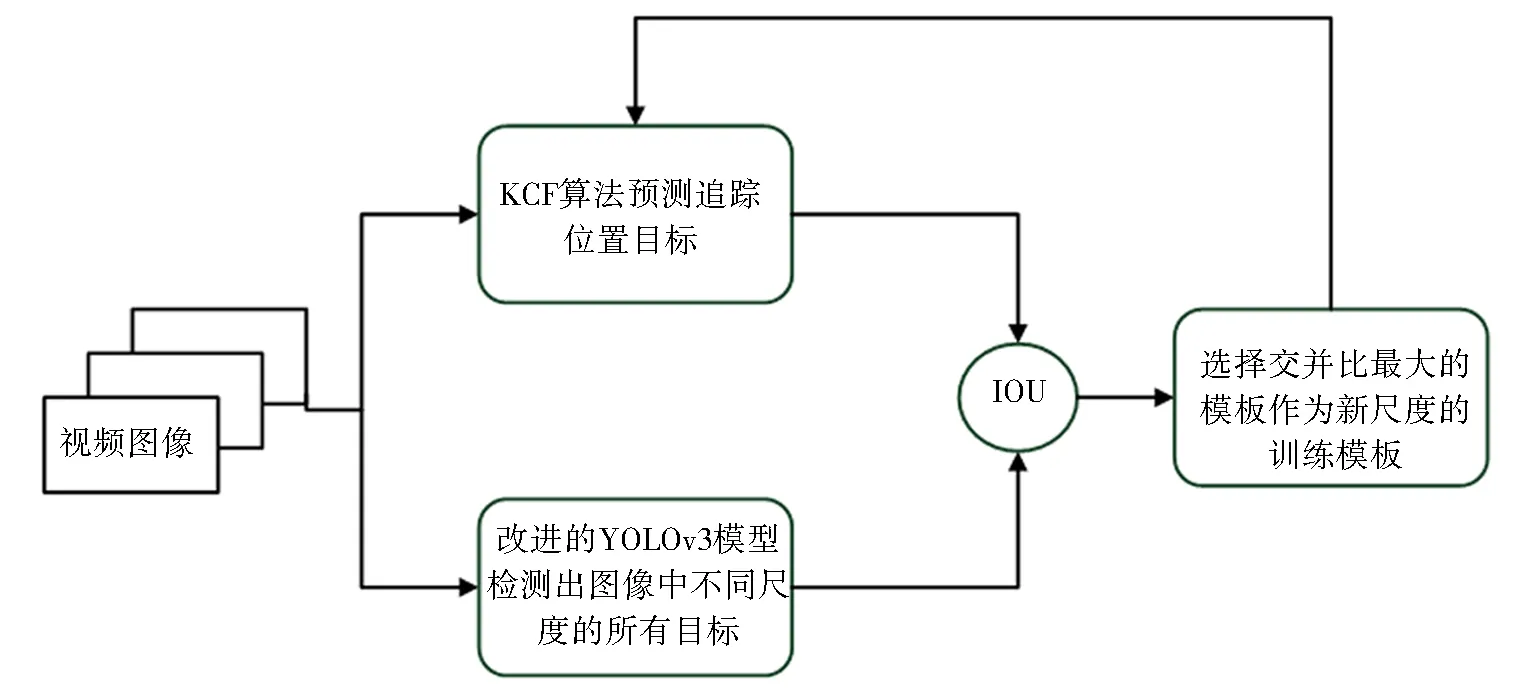
图1 KCF尺度自适应流程Fig.1 KCF scale adaptive process
使用改进的YOLOv3提取图像特征进行目标检测.YOLOv3是一个以darknet-53作为主框架的神经网络,由于darknet-53每个网络层的感受野不同,可以分别从它的不同网络层提取不同尺度的目标,总共识别了3个尺度大小,并默认使用MS-COCO数据集[9]来训练网络.
分别用52×52、26×26和13×13等3种不同尺度,将检测图像划分为3种大小不同的区域,每个区域作为1个锚点,在锚点处识别出3个不同形状的目标窗口.其中最小尺度的识别融合了中等尺度和最大尺度的识别所用到的特征图,从而增加了最小尺度识别的精确度.这样从3个尺度来识别,就可以实现了目标识别的尺度变化,类似于特征金字塔网络[10].
新尺度的图像目标框通过计算KCF预测框和YOLOv3检测框的交并比来确定
MR=argmaxRi{Pi|Pi=M⊗Ri,Ri∈R},
(5)
其中,MR为新尺度的图像目标框,M为原KCF的预测框,R为图像中所有目标的检测框集合,Ri为集合R中的一个目标检测框,⊗为交并比运算.
KCF尺度可变的原理如图2所示,图2a中,在一个行人检测的视频中,KCF检测出来的行人目标框用红色框标出,在下一帧中,也就是图2b中所预测的位置依然用红色标出,但是由于2帧图像之间摄像机进行了放大操作拉近了镜头,导致行人相对于图像的尺度发生了变化,而KCF检测框的尺度没有发生变化,导致不能完全覆盖目标,所以随着镜头的拉近,目标的尺度不断相对变大,继续使用KCF会导致追踪目标的丢失.这时候使用改进的YOLOv3模型检测出目标中的人物坐标,也就是蓝色框标出的目标.由于图像中可能出现多个行人目标,所以通过计算蓝色框和红色框的交并比大小,选择其中交并比最大的一个蓝色框作为新的目标检测器去训练KCF的目标分类器.

a.KCF检测的行人目标;b.YOLOv3检测的行人目标图2 KCF尺度可变原理Fig.2 KCF scale variable schematic
1.3 KCF中基于卷积神经网络的行人特征提取
KCF使用HOG特征,通过计算和统计图像局部区域的梯度方向直方图来构成特征,这种特征提取存在着很大的缺陷,如果行人的姿势改变,HOG特征将无法区分,而且对颜色信息不敏感,对噪点却很敏感,从而导致追踪过程中追踪错误或者追踪丢失.
为了弥补HOG特征对噪点敏感、形状改变时难以识别和无法感知颜色特征的缺陷,设计训练了一个卷积神经网络来学习和提取行人目标的深度特征.不像HOG特征,是人为选取的某些方面的特征,通过卷积神经网络提取的目标深度特征,具有更本质、更全面的特征表示,能利用颜色等其他特征综合识别,从而克服目标姿势的改变和噪点对目标识别的影响.
该网络是一个9层的卷积神经网络,网络结构如表1所示,由于整个网络很小,可以快速提取图像的深度特征.网络使用了大小为3×3,步长为1的卷积核,把YOLOv3识别的行人图像尺寸缩放为128×64的像素大小,并以RGB三通道的图像作为了整个网络的输入图像.网络使用了Adam下降算法[11],每一层都使用了L2正则化和纵向归一化.而且每一层都使用了ELU(exponential linear units)作为激活函数,使得收敛速度快,加快训练速度.
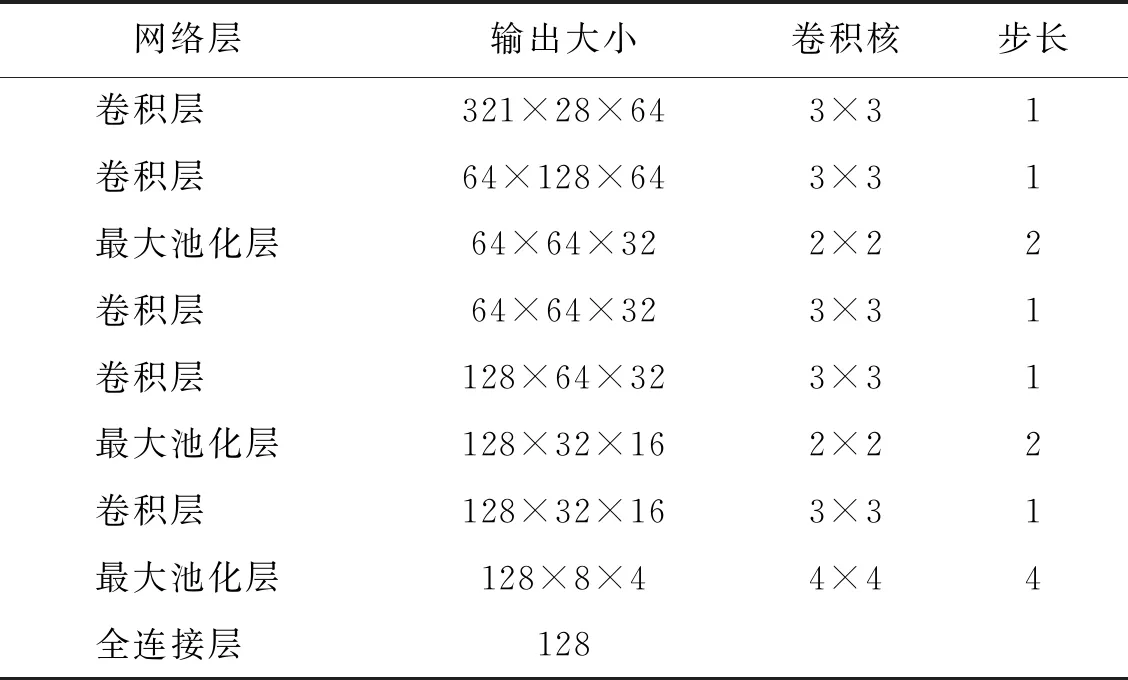
表1 深度特征提取的神经网络结构
该神经网络设计的层数,是根据感受野计算公式得出.使用神经网络计算提取行人特征,主要提取具有明显区别性的纹理特征.通过观察大概20×20像素的纹理特征就可以明显区别出不同穿着打扮的人,由于输入行人图像的大小为128×64像素,依照所需要的感受野大小和感受野计算公式,计算出网络的层数为8层,最后再加上一个全连接层计算出一个128维的特征向量.
感受野公式如下:
(6)
其中,Lk-1是第k-1层的感受野大小;Fk是当前的卷积核大小;Si是第i层的步长.
根据感受野公式,在第7层时,感受野大小为24×24像素.在第7层卷积层计算之后,得出了大小为32×16的特征图,之后使用一个4×4的池化层进一步去掉冗余的信息,同时减少了计算量,将特征图变为8×4的大小,最后使用一个全连接层提取出一个128维的特征向量作为行人目标的特征表示.
1.4 融合深度特征的行人重识别
当存在长期遮挡问题时,KCF算法会丢失追踪的行人目标.此时如果保留丢失的行人目标的深度特征,在接下来的图像中,对比新出现的行人目标的深度特征,如果相似度大于设定的阈值,就可以认为遮挡后的目标重新出现了,从而可以对其进行再次追踪.所以融合了尺度自适应和深度特征对比的KCF追踪方法,即IKCFMDF,可以解决KCF在遮挡情况下丢失行人目标的问题.
在得到计算深度特征的神经网络后,将追踪目标和行人目标之间深度特征的置信度和KCF预测位置的置信度相融合,就可以更准确的追踪行人的位置.其中融合的度量公式如下:
C=λCkcf+(1-λ)Dnetwork,
(7)
其中,Ckcf是KCF预测位置的置信度;Dnetwork是神经网络识别出的置信度,存在镜头晃动的时候λ取0即可.
IKCFMDF算法追踪示例如图3所示,图3a带有红色边框的人是追踪目标,用神经网络提取了他的128维向量的深度特征并存储,因为他的奔跑速度慢,在图3b中相对摄像机视角逐渐向左移动.图3c中,追踪目标完全不在摄影机视线范围内,KCF完全丢失了追踪目标,IKCFMDF此时将目标的深度特征与其他人进行比较,但没有找到匹配的对象.因此,在图3c中,目标丢失并且没有标记红色边界框.图3d中,目标重新出现,IKCFMDF将恢复的目标向量与新出现的人进行比较,然后再次找到目标,因此相应的边界框用红色标记.


a.跟踪目标标有红色边框;b.摄像机视图逐渐丢失目标;c.摄像机完全丢失了跟踪目标;d.算法重新找到跟踪目标图3 算法追踪示例Fig.3 Diagram IKCFMDF algorithm tracking example
2 实验结果与分析
2.1 深度特征提取网络的训练
使用market1501数据集[12]来训练行人图像特征提取的神经网络.数据集包含了1 501个行人32 668张图像.每个行人至少由2个摄像头拍摄,每个摄像头会拍摄有多张行人图片.
由于神经网络计算得出的是一个特征向量,所以训练使用了triplet loss[13]作为训练损失函数.
L=max(d(a,p)-d(a,n)+margin,0),
(8)
其中,L为训练的损失函数,a、p、n分别是作为训练数据的行人图像,a是一个人的训练图像,p是与a同一个人的不同拍摄角度的样本图像,n是其他人的样本图像.
d(a,p)是a和p的行人图像经过神经网络计算出深度特征后的欧氏距离,d(a,n)是a和n的行人图像经过神经网络计算出深度特征后的欧式距离.
实验结果如图4所示,对神经网络的训练,在30 000次迭代之后就达到了98%的准确度.
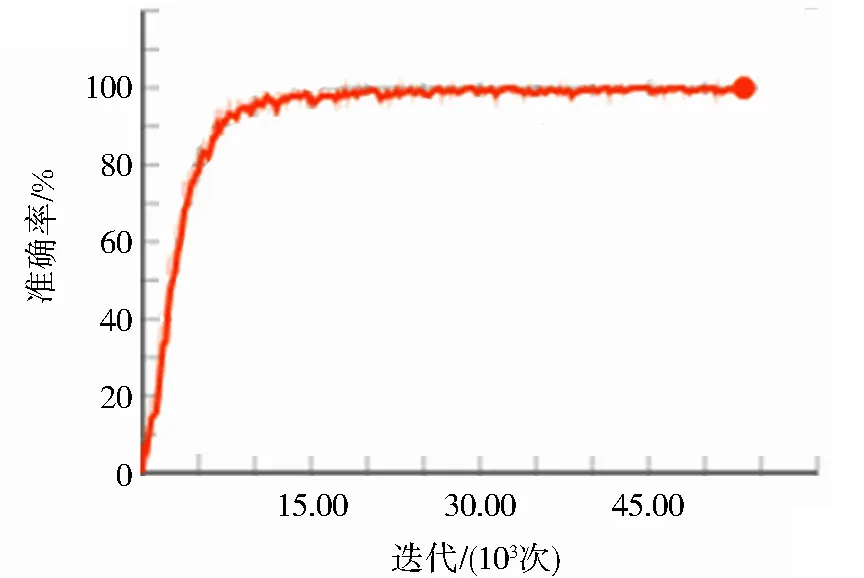
图4 行人图像特征提取网络的训练准确率Fig.4 Training accuracy of pedestrian image feature extraction network
2.2 追踪效果分析
模型使用OTB-100数据集[14]来测试准确度,由于是行人追踪,所以选择了其中几个包含有行人的视频来测试,包括了human6视频,woman视频和girl2视频.这些视频中有很多干扰因素,如追踪目标尺度有变化、追踪目标被遮挡或消失、追踪目标非刚性形变和光照变化等等,因此增大了追踪的难度.测试中,判断标准是当模型预测的交并比为0.5时即为正确追踪,对比的算法有KCF、ASLA(adaptive structural local sparse appearance model)[15]、TLD(tracking learning detection)[16]、DASiamRPN、SiamRPN.对于融合的度量方式,其中的λ设置为0.2,YOLOv3的行人检测置信度设置为了0.4,实验对比结果如图5所示.
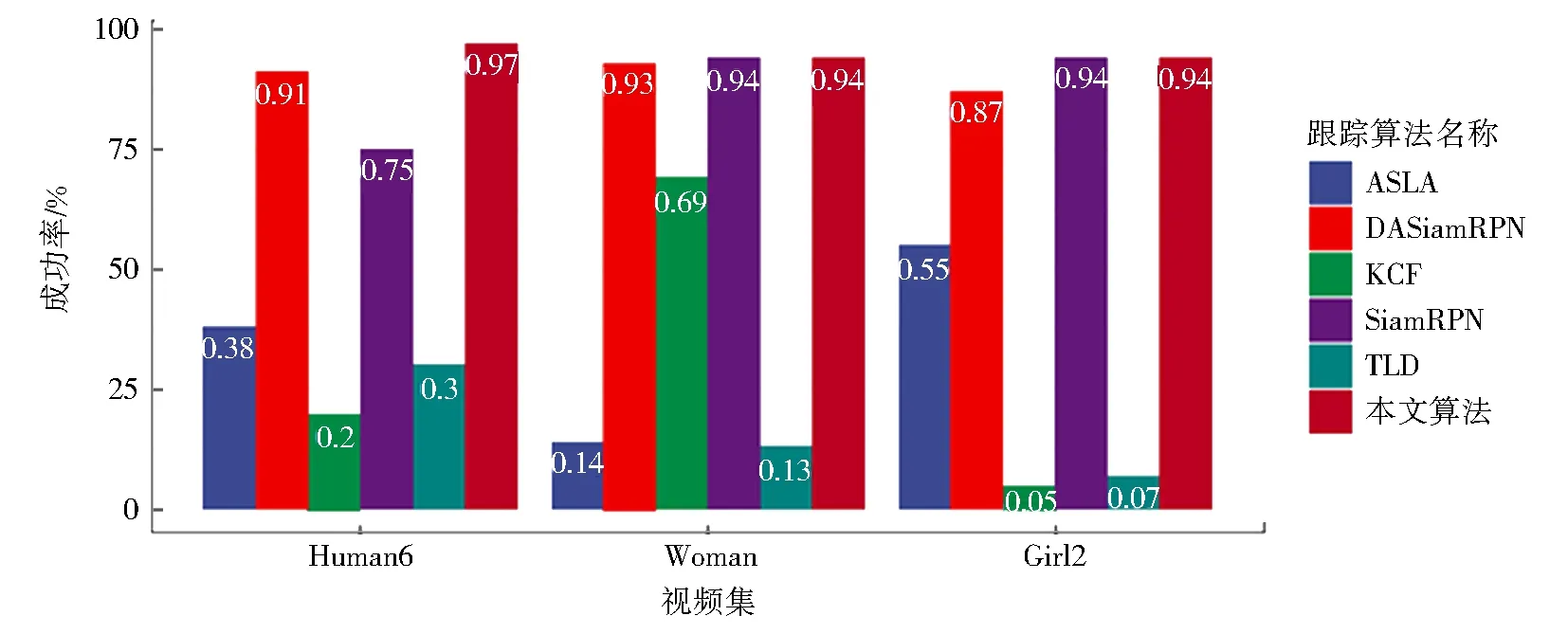
图5 几种跟踪算法在OTB-100数据集的几个行人视频中的跟踪成功率Fig.5 Tracking success of several tracking algorithms in several pedestrian videos from the OTB-100 dataset
从图5中可以看出本文提出的模型追踪成功率比KCF、ASLA、TLD传统算法有着很大的提升,对于DASiamRPN、SiamRPN基于神经网络的方法也有部分提升.
KCF、ASLA 和 TLD 方法尽管运行速度很快,但提取的特征对行人姿势的改变不敏感,在复杂情况下追踪效果并不好,本文模型使用神经网络提取深层特征,降低了噪点和动作改变的敏感性,与这些使用传统特征追踪的算法相比,具有更高的性能.
在Human 6 视频中,本文模型的效果比SiamRPN的效果有较大提升,是因为 Human 6 视频中行人的颜色更像背景,而其他视频中则没有这种情况.
本文模型与DASiamRPN相比,在3个视频集中的追踪效果差异均不大,因为DASiamRPN是基于SiamRPN的网络,其将distractor-aware模块添加到了DASiamRPN中,并且在追踪过程中,DASiamRPN还使用新样本实时更新了框架.
3 结束语
针对行人追踪中,KCF无法尺度自适应和不能解决目标遮挡问题,提出了融合深度特征的改进KCF行人追踪算法IKCFMDF.通过引入目标检测算法和深度特征,解决了追踪过程中目标尺度变化和HOG特征对颜色和姿势改变不敏感的问题,以及由于遮挡或者摄像视角改变引起的目标丢失问题,最终提升了追踪算法的准确度.
IKCFMDF算法还有很大的提升空间,其中的行人目标检测框架YOLOv3还可以换成未来更高效的检测框架,或在行人特征明显的环境下使用基于MobileNet网络[17]、YOLO-lite[18]、ShuffleNet[19]、FBNet[20]的目标检测网络用来减少计算量,提取深度特征的神经网络也可以换成其他高效的行人重识别算法,在保证追踪准确度的情况下,提升追踪速度.
猜你喜欢
意林(2021年5期)2021-04-18
内蒙古民族大学学报(社会科学版)(2020年2期)2020-11-06
电子制作(2019年19期)2019-11-23
扬子江(2019年1期)2019-03-08
小天使·一年级语数英综合(2017年6期)2017-06-07
太空探索(2016年5期)2016-07-12
重型机械(2016年1期)2016-03-01
大连工业大学学报(2015年4期)2015-12-11
海军航空大学学报(2015年4期)2015-02-27
时代英语·高三(2014年5期)2014-08-26
