
基于BERT-LDA 模型的短文本主题挖掘*
2023-12-09 08:50邱秀连
计算机与数字工程 2023年9期
张 震 汤 鲲 邱秀连
(1.武汉邮电科学研究院 武汉 430000)
(2.南京烽火天地通信科技有限公司 南京 210000)
1 引言
移动互联网的发展与智能手机的普及极大地促进了社交软件的发展,根据第48 次《中国互联网络发展状况统计报告》[1],截至2021 年6 月,我国网民规模达10.11亿,手机网民规模达10.07亿。网络中每天都在产生海量的数据,其中存在大量的短文本数据,如微博、评论以及视频弹幕等。这些短文本数据中蕴藏着巨大的商业价值,对这些数据进行主题挖掘,从海量的数据中挖掘潜在的主题,使得用户无需浏览全部的数据,通过生成的主题描述即可快速掌握文本的大致内容。
在对这些互联网数据进行主题挖掘时,由于其数据增长快,涉及主题复杂多样,使用有监督学习模型难以发现新的主题,且需要大量的人工参与。因此,对此类数据的主题挖掘多数采用无监督学习模型其中,其中,应用最多的就是LDA[2]主题模型,LDA 模型通过建立文档、主题、词的三层概率分布来挖掘主题,但是LDA 在短文本建模上存在词汇稀疏问题,导致模型效果很差。为了解决这个问题,国内外学者对LDA 模型作了大量的改进,文献[3]提出了Twitter-LDA模型,其认为每一个用户存在一个用户-主题矩阵,生成主题时从该矩阵生成,从而表现出不同用户的关注主题。黄波[4]等提出了基于向量空间模型和LDA 模型相结合的微博客话题发现,其主要思想是将LDA 模型提取的文档间语义信息和基于VSM 的Tf-idf 权重词向量融合在一起,计算文本间相似度。张景[5]等使用CBOW-LDA 模型,来降低LDA 模型建模输入的文本数据纬度。石磊[6]等提出一种基于RNN 和主题模型的突发话题发现方法(RTM-SBTD),使用RNN和IDF 来学习词的关系,同时通过构建词对解决短文本稀疏性问题。高鑫[7]等提出了一种使用Word2Vec 提取词向量特征,再通过基于KNN 改进的密度聚类算法来进行主题聚类。
本文针对短文本数据集特征,提出了一种结合BERT 和 LDA 的 主 题 特 征 提 取 方 法(BERT-LDA)。BERT是近年来在NLP领域内取得卓著成效的技术,通过双向深层的Transformer模型有效提取文本的语义特征。本文使用BERT 对短文本进行语义特征提取,将提取出的词向量输入K-means进行相似文本聚类,最后将聚类结果作为语料使用LDA模型进行主题建模。
2 模型介绍
2.1 BERT模型
BERT(Bidirectional Encoder Representation from Transformers)[8]是GOOGLE 在2018 年提出的深度学习模型,传统的Word2Vec[9]模型是基于静态词嵌入,无法学习到词在不同语境的文本特征,为了解决这个问题,ELMO,BERT 等预训练模型相继被提出。BERT 使用如图1 所示的双向多层Transformer作为编码器来捕捉词的上下文信息,通过对大规模语料进行训练从而得到一个通用的语言模型,之后对预训练BERT 模型进行微调,即可满足下游的各种任务。
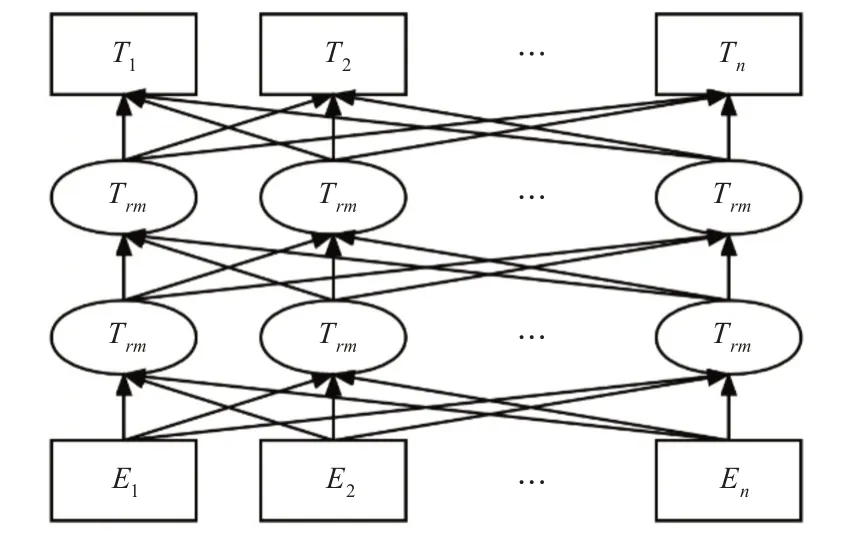
图1 BERT模型结构
2.2 输入表示
Transformer[10]模型接收的输入是一个词向量序列x=(x1,x2,…,xn),其中xi表示单个词的向量,因此在使用Transformer训练前,需要将原始语料转换成模型能够识别的向量序列,为了使BERT 能够处理多种NLP 任务,并且更好地提取语义特征,BERT 在提取特征向量前使用三层Embedding 层对语料进行不同维度的编码,最终的输入表示由三层Embedding求和得到。
此外,BERT 还会在原始语料中插入一些特殊字符,其中,[CLS]和[SEP]为特殊符号,[CLS]用以标识语料的开头,用于学习整条语料的语义特征,可以用于分类任务,对于其他类型任务可以忽略,[SEP]用以区分语料中的不同句子。Token Embeddings 表示的是字向量或词向量,可通过查表获得,用以表征词本身,本文使用字向量;Segment Embeddings 用于区分字所属的句子,E0表示字来自于句0;Position Embedding表示字的位置信息。
2.2.1 预训练(Pre Training)
在得到语料的输入表示后,BERT 使用掩码语言模型(Masked Language Model,MLM)和下一句预测(Next Sentence Prediction,NSP)两个无监督任务进行训练。
传统语言模型如N-gram 是根据上文预测当前词,为方便计算概率,其假设第n个词只与前n-1个词有关,而BERT 是双向的Transformer 模型,为了能够同时学习到上下文的双向语义特征,BERT 提出了MLM 模型,在训练时,模型会随机掩盖掉15%的字,即将真实的字以[mask]替代,之后用其对应的上下文来预测真实的字。
此外,BERT作为预训练模型,需要适用于下游的多种NLP任务,除了文本分类,阅读理解,序列标注等任务外,还需要满足问答等任务,这就需要BERT 不仅能够学习到字词间的关系,还需要学习到句子之间的关系,因此,BERT 提出了NSP 任务,将每条句子的语义特征作为分类特征,从而判断两句话是否存在问答关系。
2.2.2 微调(Fine Tuning)
BERT通过在超大规模语料进行训练得到了上游的预训练模型,谷歌官方提供了不同版本的BERT模型,主要分为Base版和Large版,使用者可以根据自身情况选择对应的预训练模型,之后在微调阶段,针对不同类型的下游任务,只需要在预训练模型基础上增加相应的处理,如分类任务,可以使用句首[CLS]的语义特征作为句向量,后接Softmax或者LSTM等作为分类器。
2.3 LDA模型
LDA 主题模型是由Blei,David M.等于2003 年提出的,本质上是一个包含文档-主题-词汇的三层贝叶斯模型,可用来分析文档的隐含主题,从而得到文档的主题分布以及主题的词汇分布,LDA模型的概率图如图2所示。
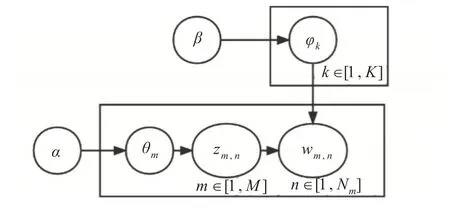
图2 LDA模型概率图
其中,M代表语料中文档的个数,K代表语料中主题的个数,实际训练中K值可作为超参数进行调整,θm是第m篇文档的主题分布,为多项式分布,α是文档-主题分布的Dirichlet 先验分布,φk是第k个主题的词汇分布,也为多项式分布,β是主题-词汇分布的Dirichlet 先验分布,Zm,n代表第m篇文档的第n个词汇所属的主题,wm,n代表第m篇文档的第n个词汇,此外,文档与文档之间,主题与主题之间相互独立。
从图2 可知,LDA 模型的生成过程主要由两个子过程组成,具体生成过程如下所示。
LDA模型:
1)首先生成主题-词汇分布,根据第k个主题的Dirichlet 先验分布生成第k个主题的词汇分布φk。
2)生成文档-主题分布,根据第m篇文档的Dirichlet先验分布生成第m篇文档的主题分布θm。
3)根据2)中得到的主题分布θm得到一个主题编号k,再根据主题k的词汇分布φk生成词wm,n。
2.4 BERT-LDA模型
在对短文本进行主题分析时,由于短文本中词汇稀疏,包含的语义特征不明显,使得LDA 模型在生成主题分布时效果很差。本文提出了适用于短文本主题挖掘的BERT-LDA 模型,BERT-LDA 模型由语义特征提取、特征聚类和主题挖掘三个部分组成。
2.4.1 语义特征提取
BERT 模型第一步会对原始数据进行三层Embedding,插入[CLS]和[SEP]标识,Token Embedding 层为字向量,Segment Embedding标识所属句子,其值为当前字所在句子在语料中的序号,取{0,1,2,…},Position Embedding 为位置向量Si=i,将三层Embedding 值累加即可得到编码层输出,之后输入BERT 模型进行词向量提取,得到最终的特征向量,根据BERT原理,使用作为整条文本的语义特征进行聚类。
2.4.2 特征聚类
使用K-means[11]算法进行文本聚类,先随机选择K条样本作为初始聚类中心,计算每条样本xj到每个聚类中心的距离,该距离使用余弦相似度来衡量,计算公式如下:
计算完距离后,对每个聚类簇重新计算聚类中心,重复上面操作,直到达到最小误差或者最大迭代次数。
最后,将每个聚类簇中的文本合并成一条长文本,对每条文本作分词处理,形成语料,使用LDA模型对语料进行主题建模,求解LDA 模型,就是求解联合分布,由于词分布是已知数据,因此我们需要求出的是条件概率分布。
2.4.3 主题挖掘
本文采用Gibbs 采样算法[12]进行采样求解,获取最终的主题分布。将语料中任意一个词的位置记为i,i代表坐标(m,n),对应第m篇文档的第n个词,代表去除位置为i的词,根据贝叶斯理论,我们可以得到对应的Dirchlet 后验分布为
其中为文档-主题和主题-词汇的多项式分布,根据Gibbs采样算法,我们有
根据Dirchlet分布的数学期望公式可得到
2.5 评价指标
困惑度[13]是评价语言模型好坏的一个重要指标,它的基本思想是给测试集句子赋予更高概率值的语言模型更好,即当语言模型训练好后,对测试集进行测试,句子出现概率越大,则证明模型效果越好,困惑度越低,其具体计算公式如式(7)所示。
其中,Dt为测试集数据,p(wmt)为模型在第m篇文档中产生词wmt的概率,Nm为第m篇文档中词汇的个数。
3 实验设计
3.1 数据集
本文采用的数据集为真实微博数据,使用Python爬取体育、游戏、时政、科技、财经、娱乐等多个类别话题的微博博文,同时,为了验证BERT-LDA模型在短文本主题挖掘上的效果,从爬取的博文中筛选长度在200 字符以下的博文,构成最终实验所用的数据集,共155724条博文。
3.2 数据预处理
由于LDA 模型进行主题建模时使用的是词袋模型,停用词没有意义,无法将其归属到任何主题中,因此将文本进行分词[14]并将停用词去除,所用停用词[15]为哈工大、川大、百度等开源的停用词表。
3.3 实验结果分析
训练BERT_LDA 模型时,设置BERT 识别句子最大长度为200,聚类簇数K为5000,随机划分15%数据作为测试集,以LDA 模型,BTM 模型作为对比,同时,为了观测主题数对模型效果的影响,设置主题数分别为10、20、30、40、50 进行实验,实验结果如图3所示。
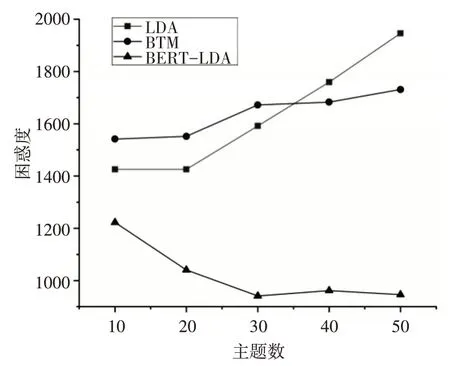
图3 主题数对困惑度的影响
由图3 可知,LDA、BTM 和BERT-LDA 这三种模型在不同主题数下困惑度均不同,总体来看,LDA 模型的困惑度高于BTM 和BERT-LDA 模型,这证明LDA 模型在短文本建模上的效果确实不好,BTM 模型的困惑度虽然低于LDA,但是总体仍是高于BERT-LDA 模型,证明BERT-LDA 模型能够取得更低的困惑度,效果要好于LDA 和BTM 模型。
4 结语
本文提出了一种基于BERT 和LDA 的短文本主题挖掘模型,针对LDA 模型在短文本建模上存在的词汇稀疏问题,提出采用BERT 预训练模型对短文本进行语义特征提取,通过聚类的方法将短文本聚合成长文本,最后输入到LDA 模型中进行主题建模。通过对短文本数据的实验分析,验证了本文所提算法的有效性,相比传统的主题模型具有更低的困惑度。
同时本文方法仍存在不足,例如,Bert 提取特征向量和K-means聚类这个过程耗时较长,如何优化算法,降低算法运行时间这是本文后续的研究方向。
猜你喜欢
客联(2022年3期)2022-05-31
中国新闻周刊(2021年26期)2021-07-27
时代英语·高二(2018年7期)2018-12-03
时代英语·高二(2018年3期)2018-06-06
海外华文教育(2016年1期)2017-01-20
信息安全研究(2016年4期)2016-12-01
当代教育理论与实践(2015年9期)2015-12-16
民族古籍研究(2014年0期)2014-10-27
外语教学理论与实践(2014年2期)2014-06-21
