
结合高光谱特征与语义分割的水稻产量分类*
2023-12-09 08:50李邦昱
计算机与数字工程 2023年9期
卢 柱 齐 亮 李邦昱,2
(1.江苏科技大学电子信息学院 镇江 212003)
(2.中国科学院自动化研究所 北京 100190)
1 引言
水稻育种是一个极其复杂的过程,在常规育种的选择过程中,准确估算农作物的生物量十分重要,目前估算农作物的生物量的工作主要依靠人工测量。然而,人工测量农作物生物量是主观的,缺乏鲁棒性或可重复性,并且对于较大面积的农田来说非常耗时[1]。随着无人机技术和光谱成像技术的发展,基于无人机的高光谱相机在农作物生物量测量的高通量表型领域的应用越来越广泛[2]。
目前,基于高光谱数据预测出高产的水稻品种通常是通过预测回归模型来实现的[3~5],如最大似然分类方法、最小错误概率的贝叶斯分类器[6]、SVM[7]等。
近年来,深度学习的发展给利用农作物高光谱图像进行分类预测带来了新的机遇。2015 年,Hu等[8]将卷积神经网络(CNN)引入高光谱分类中,该方法利用了光谱信息作为分类依据。闫苗等[9]通过分析不同CNN 模型对高光谱图像的分类效果,证实了CNN 模型在高光谱遥感地物分类中具有较高的识别率。2019 年,魏祥坡等[10]结合残差网络和密集网络设计了残差密集网络模型(ResDen-Net),该模型充分利用了所有分层特征,增强了分类方法的稳定性。
本文的研究中,我们结合了高光谱数据和深度学习语义分割算法来分类预测出高产水稻品种。高光谱数据的分类器通过deeplabv3+算法训练获得。我们先分析水稻高光谱中各波段的相关性,然后提取高光谱的通道特征向量以构成伪RGB 图,最后将伪RGB 训练集和标签导入搭建的deeplabv3+网络中进行训练并保存模型,利用模型对目标数据进行有效分类。
2 研究方法
本节介绍了本文所提出的稻田产量分类方法:deeplabv3+。该算法包括两个部分:编码器架构和解码器架构。
2.1 编码器架构
deeplabv3+算法将deeplabv3 网络作为编码模块来提取特征,然后通过解码模块来实现语义分割。在deeplabv3 网络中,deeplabv3 使用深度残差网络(ResNet_101)[11]提取语义信息,同时采用空洞卷积(Atrous Convolution)来控制输出特征图的分辨率并扩大卷积核的感受野。以二维特征图为例,假设卷积核为W,当空洞卷积作用于输入特征图x,对于输出特征图y中的每个位置i,有:
其中:r表示膨胀率。对应于我们采样信号的步长(stride),这等效于在每个空间维度上,将输入x与两个连续的卷积核之间插入r-1 个零而产生的上采样卷积核进行卷积。如图2 所示,在卷积核中插入0,相当于对卷积核进行了上采样,其中,标准卷积r=1。空洞卷积允许我们通过膨胀率来控制感受野的大小。
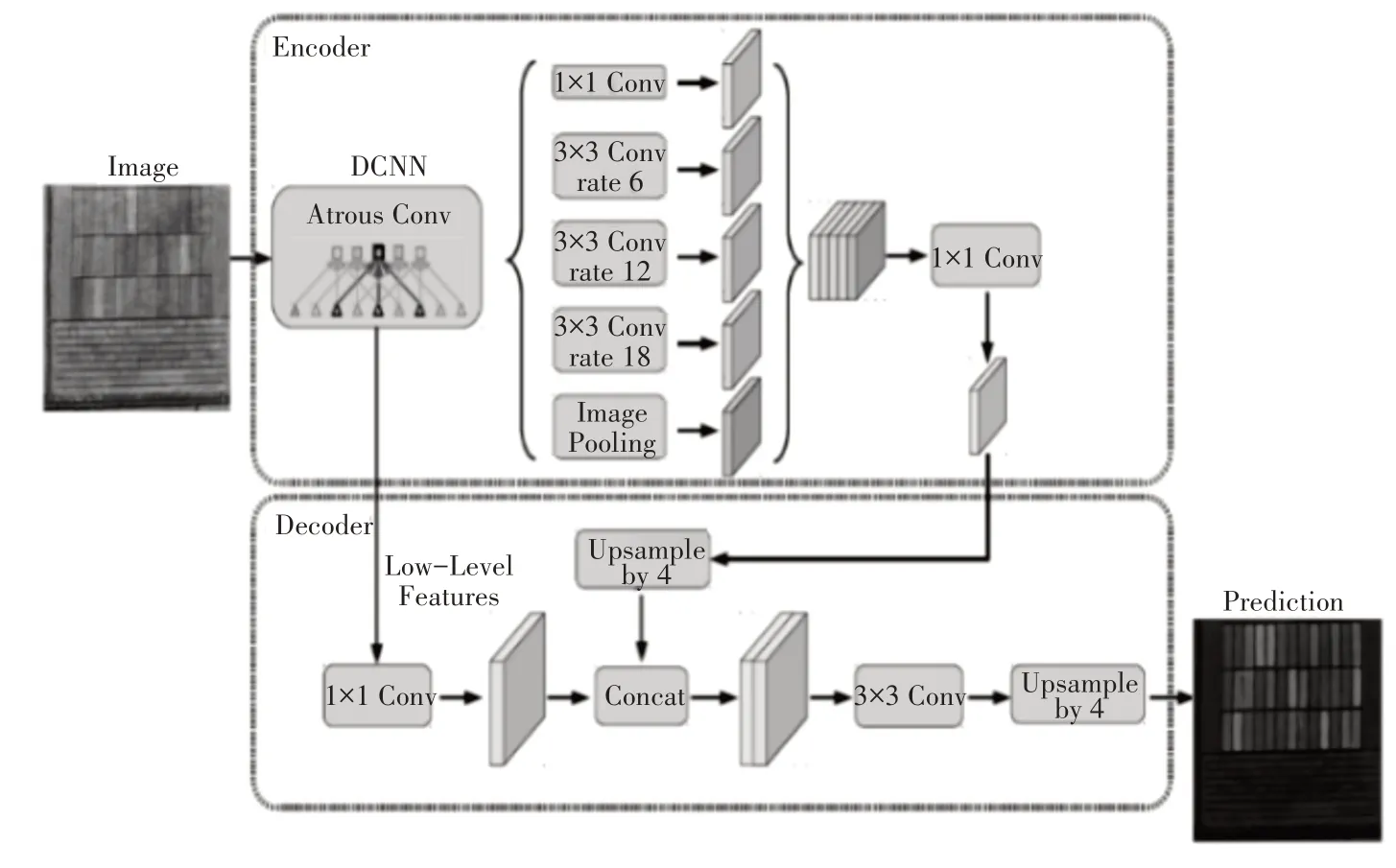
图1 deeplabv3+网络结构图

图2 高光谱数据采集地
2.2 解码器架构
deeplabv3+网络中非常巧妙地使用了一个虽然简单但很有效的解码方式:在deeplabv3+网络对目标图像进行分割时,首先对编码器特征进行双线性插值4 倍上采样,然后将计算后的编码器特征与来自网络主干的具有相同空间分辨率的低级特征连接起来。然后,采用3×3 的卷积核和因子为4的双线性插值上采样来将输出特征图的大小转化成与输入一样的形状,最终经Softmax 分类层得到对应的分割结果。
整个网络采用逐像素的交叉熵误差函数作为损失函数,对于每个像素x,Softmax 分类器的输出为
其中:x为二维平面上的像素位置;k为总类别数;αk(x)表示Softmax输出的像素x对应的第k个通道的值;Pk(x)表示像素x属于第k类的概率。于是整个网络的损失函数可表示为
其中:tx为像素x的正确解监督数据;Pl(x)为像素x属于真实类别l的概率。
3 水稻高光谱数据的获取和预处理
3.1 水稻高光谱数据的获取
3.1.1 高光谱数据采集地点
在中国宁夏永宁县宁夏农业科学院进行了水稻栽培和高光谱图像数据采集(图2)。宁夏6月至9月的平均月降雨量为34.3mm,此期间的平均温度在15.9℃~23.4℃之间。水稻幼苗于2018 年6 月1日移栽,并于2018 年9 月9 日收获。水稻种植地点和种植情况如图2所示。
3.1.2 根据人工测量产量对水稻品种进行分类
本研究中所使用的数据集来自13 个晚熟早粳稻品系,每个品系有3 组,共39 个样本单元。根据每亩人工测量的平均粮食产量对不同样本单元中的水稻品系进行标记。据中国国家标准(编号:20000011),拥有产量超过750kg/亩,750kg/亩和700kg/亩之间,以及小于700kg/亩分别为high 类、mid类和low类。分类情况如表1所示。
将13 个水稻品种按人工测量的产量分为高产、中产、低产三个类别,其中红色标签代表中产,绿色标签代表低产、黄色标签代表高产。具体标记情况如图3所示。
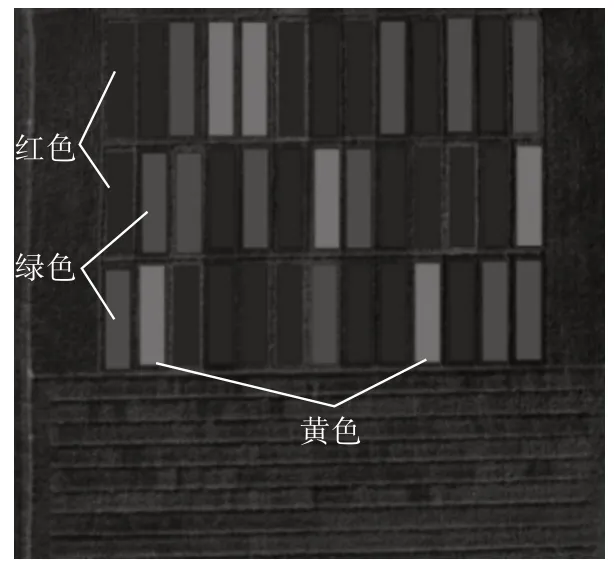
图3 数据分类和标记
3.2 高光谱特征波段选择和数据集的制作
3.2.1 特征波段选择在高光谱图像分类中的作用
高光谱数据有上百个波段,波段间距窄,提供了丰富的地物光谱信息,但波段越多,波段间的相关性就越大,数据的冗余度也越大,同时也带来了海量数据存储和处理的技术难题。合适的光谱特征波段选择方法可使高光谱图像数据的维数降低、运算复杂度减小,分类算法的训练和测试时间也随之降低[12]。
3.2.2 分步选择法提取特征波段
实现最佳波段组合,需要考虑波段信息量丰富、波段间相关性小、波段组合对目标地物的光谱反映差异大三个因素。波段相关性和波段信息量的提取有组法和分步法,组合法要求在一个评价准则或公式里求得最小相关性和最大信息量,如最优索引因子(Optimal Index Factor,OIF)的波段选择法和自适应波段选择法(Adaptive Band Selection,ABS)的两种组合波段选择方法。
有研究指出OIF 和ABS 法选取的特征波段难以兼顾信息量和相关性的问题[13],本研究采用分步选择法提取水稻高光谱图的特征波段。分步法采取分别考虑波段信息量和波段间相关性的方法来寻找最优波段组合,其流程图如图4所示。
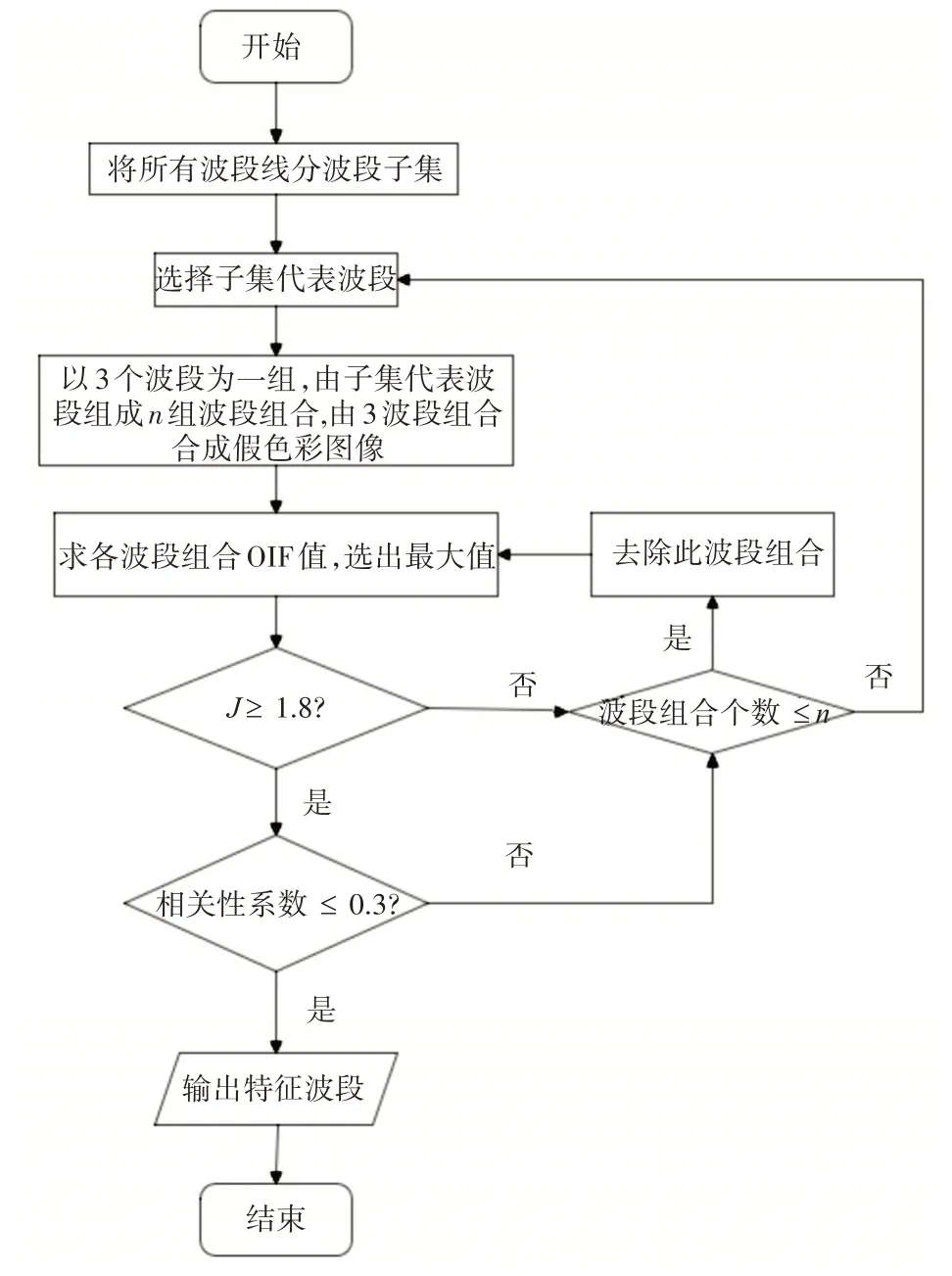
图4 分步选择法提取特征波段的流程图
通过无人机采集的水稻高光谱数据集的高光谱波段有176 个,其灵敏度高于分析要求。首先,通过对高光谱的各波段进行相关性分析,可以得出使该高光谱数据的相关性系数最大的连续波段数为8。因此,本文使用8 个相邻频段的平均值作为中心频段将176 个波段按照植被光谱的特征分为相关性较弱的22 个子集,然后在各个子集内寻找信息量最大的波段作为子集的代表波段。
其次,在选出的几个代表波段中,以任意3 个波段为一组,计算所有波段组合的最优索引因子OIF。将这些波段组合用3 波段分别合成假彩色图像,并通过JM距离计算假彩色图像中各类水稻特征的可分性M,其计算公式如式(4)所示。
式中,JM代表JM距离;X代表像元;ωi,ωj代表类别号;p(X/ωi)代表类条件概率密度,即第i个像元属于第ωi个类别的几率。JM的值在0~2 之间时,其大小代表样本间的可分离程度。当JM位于0.0~1.0 之间时,认为样本间不可分;JM位于1.0~1.8 之间时,样本间具有一定的可分性,但存在错分现象;位于1.8~2.0 之间时,样本间具有较好的可分性[14]。
最后,最佳特征波段组合通过选择OIF 最大且JM 距离大于1.8、相关性系数小于0.3 的一组波段确定[15]。
通过这样的三步来获取最优波段组合,虽然分步选择法比OIF 法过程稍显繁琐,但只计算波段子集内两两波段的相关系数,计算量并不大,更重要的是该方法确保了所选波段相关性小、信息量大,因而更合理。
通过分布选择法,我们从水稻田数据集的176个高光谱波段中提取有效的特征组合,获取了1291 张可供深度学习网络训练的伪RGB 图。如图5所示。

图5 各波段组合生成的伪RGB数据集
3.2.3 训练数据集的制作
我们的水稻田数据集包含1291 张伪RGB 图片。为了使用深度学习网络对其进行有效训练,我们对该数据集进行了相应的划分,其中训练集有833张图,验证集有358张图,测试集有100张图。
最后,我们使用语义分割专用的标记工具labelme对预处理好的数据集进行人工标记。每张图片中的水稻田块有3组,每一组有13块地。我们先对水稻成熟后的产量进行人工统计,再根据各田块产量的统计数据,将39 块稻田划分成高、中、低三类,分别用黄、红、绿三种颜色标记,标签名分别为mid,low,high,其余无关背景的标签名为backgroud。
4 实验和评估
4.1 实验的实施
实验软件环境为Windows10-64 位系统,采用目前流行的tensorflow 深度学习开源框架。计算机内存为16GB,搭载AMD R7-4800H CPU,GPU 采用英伟达的GTX1650 对深度学习模型进行加速。试验中训练数据和测试数据的批次大小都设置为1。训练模型时采用了momentum 优化器来实现网络参数的快速更新。为防止过拟合,采用了常用的权值衰减(weight decay)方法,权值衰减系数设置为0.00004,初始学习率设置为0.0001,每迭代100 次学习率减小为原来的10%。。训练过程中的损失函数值的变化与评估结果分别如图6、图7所示。
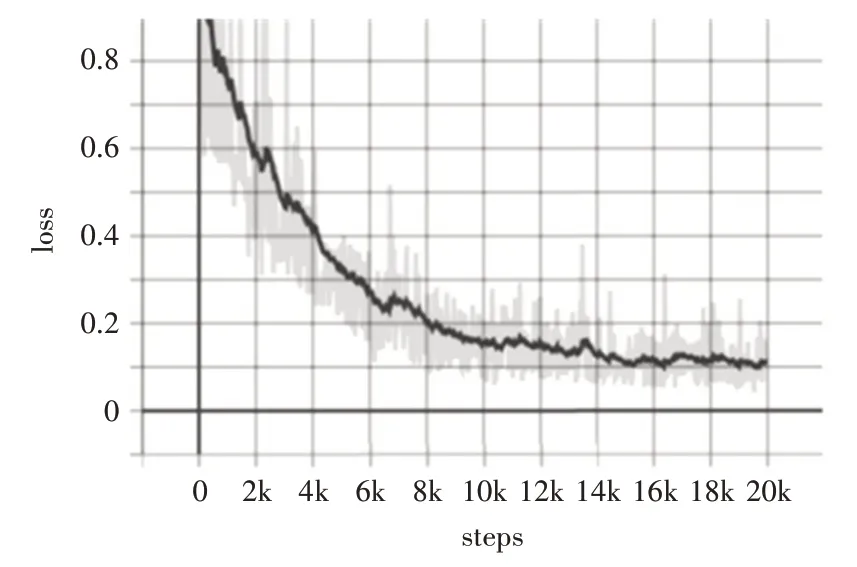
图6 损失函数的变化曲线
图7 评估结果
4.2 评估
在水稻高光谱数据测试集上,我们评估了deeplabv3+分类的性能,并与其他传统的用于图像分类的语义分割方法进行了比较。具体的deeplabv3+网络以及其他网络对测试集图片的分割效果分别由图11 所示以及由表1 给出。在图8 中,(a)是用于预测的原始图像;(b)是用于验证的标签图;(c)是deeplabv3+分割结果图;其中,低中高三种产量的水稻地块分布用绿、红、黄三种颜色标记。
实验中,我们比较了不同的深度学习网络对水稻的数据集的分类效果。我们使用IOU>0.6 作为评估是否正确区分出水稻类别的依据。使用MIOU来评价所使用的深度学习网络的优劣。它们的定义如下:
其中,A表示标签中的像素,它由人工标记时进行定义,B表示网络的预测结果。
其中nc为总类别数,nji表示实际类别为i、被预测类别为j的像素数量,为类i的像素总数,MIOU为真实值与预测值的交集比并集,通常为语义分割最终的评价标准。
其他两个指标是precision和recall,它们的定义如下:
其中,TP表示真正样本,FP表示假正样本,FN表示假负样本。
在水稻产量实验中,我们将目标水稻田像素作为正类,以背景像素为负类,真正样本表示网络正确推断出各自的产量类别像素,真负样本表示网络推断背景像素正确,假正样本是指网络错误地推断出水稻或将背景像素推断为水稻,最后一个假负样本表示网络错误地推断了水稻像素为背景。最后,表2 给出了评价指标,它由MIOU、Recall、F1-measure组成。
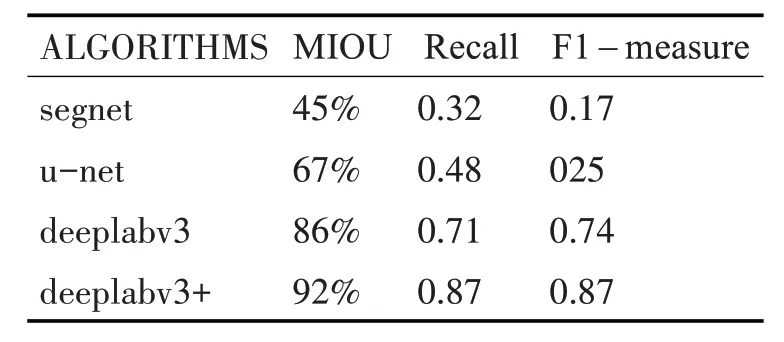
表2 不同水稻产量预测算法的比较
5 结语
在本文中,我们对水稻的高光谱数据采用了当前最流行的语义分割算法deeplabv3+,以实现分类出高产产量水稻。此外,我们还比较了几种不同的语义分割方法对水稻高光谱图片分类的效果。deeplabv3+算法的总体精度高于其他分类算法。相比于原有的deeplabv3 架构的分类算法,它保持了较高的分类精度,同时,也明显提升了稻田边缘的细节信息。实验结果表明,对于水稻高光谱数据集,deeplabv3+可以实现非常好的分类效果。为提高农业生产中的产量估算和育种等工作的速度和效果提供了更为准确有效的技术支持。
猜你喜欢
艺术家(2023年8期)2023-11-02
北京航空航天大学学报(2022年8期)2022-08-31
小哥白尼(军事科学)(2022年2期)2022-05-25
红领巾·萌芽(2019年8期)2019-08-27
高师理科学刊(2016年8期)2016-06-15
CHIP新电脑(2016年3期)2016-03-10
中国光学(2015年5期)2015-12-09
西藏科技(2015年4期)2015-09-26
河北北方学院学报(自然科学版)(2014年2期)2014-05-30
食品工业科技(2014年23期)2014-03-11
