
不确定域特征表示的鲁棒性情感分析模型
2023-12-08 11:49张燕平
计算机与生活 2023年12期
陈 洁,李 帅,赵 姝,张燕平
安徽大学 计算机科学与技术学院,合肥 230601
文本情感分析又称为情感倾向性分析或意见挖掘,旨在提取文本数据中所包含的情感信息[1],通过对文本进行分析以获取人们的观点、看法、态度和情感等。文本情感分析作为自然语言处理的研究热点,在舆情分析、用户画像和推荐系统中具有很大的研究意义[2]。随着自然语言处理技术的快速发展,研究其中的鲁棒性问题变得日益重要。对自然语言处理(natural language processing,NLP)鲁棒性的研究有利于学术界更加顺利地理解机器学习模型的运行原理。近年来,针对NLP 领域的鲁棒性研究不断涌现,研究者从数据集[3]、表示[4]、模型[5]和评估[6]等不同的角度,对模型的鲁棒性问题开展了一些研究。
模糊数据因其不确定性在模型训练出的原始特征空间中较难被正确分类,且影响模型的鲁棒性。在实际应用中,由于高维数据中存在着大量无效信息[7],处理海量数据时,这些无效信息会降低模型性能,同时增加时间成本,因此需要通过特征降维来去除无效信息。特征选择是特征降维的一个主要的方法,其本质是从原始特征空间中删除一些不确定信息从而获得一个较为鲁棒的特征表示。
三支决策(three-way decisions,3WD)作为处理不确定性的有效方法,一直是人们研究的热点。论域被划分为三个不相交的区域,即确定域(正域和负域)和不确定域,对不同的区域“分而治之”执行不同的策略。确定域样本可以直接训练下游任务分类模型,而分布在不确定域中的模糊数据存在着冗余属性,因此需先选取合适的特征表示以便下游任务。本文基于三支决策理论研究情感分析模型的鲁棒性,通过对模糊数据进行属性挑选,构建多粒度特征表示,降低模糊数据的不确定性,最终融合出适用于不确定域的鲁棒性特征表示,增强模型的鲁棒性。本文的主要贡献包括以下三方面:
(1)提出一个不确定域特征表示的鲁棒性情感分析模型(robust sentiment analysis model based on feature representation of three-way decision uncertainty domains,UFR-SA),对于较难分类的模糊数据,模型利用异类样本间的差异性,进行属性挑选,构建层次化多粒度特征表示,降低模糊数据的不确定性。多粒度特征表示通过多特征融合网络,融合适用于不确定域模糊数据的鲁棒性特征表示,实现对模糊数据的划分。
(2)提出一种多特征融合的方法,该方法由一个三层的感知网络实现,多粒度特征表示进入网络后,输出维度不变的融合后的新特征表示,将该特征表示与原始标签信息融合,优化感知网络参数,实现多粒度特征表示的融合,增强模型鲁棒性。
(3)UFR-SA 模型在SST-2 数据集上取得92.70%的准确率,在SST-5 数据集上取得54.58%的准确率,在CR数据集上取得94.12%的准确率,均优于目前最好的模型性能。
1 相关工作
1.1 情感分析研究
情感分析是自然语言处理的一个主要研究内容,用于用户情感信息的获取、舆情监测、产品推荐等方面,国内外现阶段关于情感分析的研究主要集中在基于预训练的方法上。预训练模型是指事先用数据集训练好模型,在遇到类似情况的时候,可以调整参数后直接使用[8],达到节约再训练时间的同时也能得到较好结果的目的。最新的预训练模型有BERT(bidirectional encoder representations from transformers)、XLNET、ALBERT(a lite version of BERT)、Transformer等。胡任远等[9]提出一种多层协同卷积神经网络模型MCNN(multi-level convolutional neural networks),和BERT 模型结合,提出BERT-MCNN 模型,和Word2vec-MCNN、Glove-MCNN、ELMO-MCNN 3 个模型进行对比实验,基于BERT 的表面情感分类的能力有明显提升。Devlin 等[10]提出基于BERT 的新方法,评分提高到80.5%(提高7.7 个百分点)。Xu 等[11]把ELMo和BERT 结合起来提出了DomBERT(domain oriented language model based on BERT)模型,在基于方面的情感分析中,显示了良好的效果并和BERTLinear model、BERT-DK(BERT on domains knowledge)模型进行了性能比较,DomBERT 模型取得了优良的性能。
1.2 面向特征的模型鲁棒性
实际应用中由于高维的原始特征中存在着大量的冗余属性,导致部分样本被误分类。这些冗余的属性使得数据的样本分布存在着不合理的噪声点。现阶段关于鲁棒性特征表示的提取方法有着丰富的研究。Li 等[12]通过保留图结构来保留全局相关性和动态局部相关性,进而筛选冗余的属性,提高模型的鲁棒性。Li 等[13]提出了一种归一化的鲁棒特征提取器,通过将数据嵌入正交空间,保证多个数据的独立提取。Guney 等[14]提出了一种基于最小权重阈值法的高维数据集鲁棒集成特征选择技术,解决异常值问题。该方法采用支持向量分类器为特征分配权重方法,在创建集成列表时处理排名特征列表中的异常值。此外本文利用样本集进行属性挑选,再进行特征融合的方法,也可大大降低冗余属性的干扰,提升模型的鲁棒性。
1.3 三支决策模型
三支决策是姚一豫教授提出的一种分析和解决复杂决策问题的理论[15]。其主要思想是“三分而治”和“化繁为简”,将整体分为确定域(正域、负域)和不确定域3个独立的部分,根据收集到的信息对不同的部分采用不同的处理策略[16]。Chen 等[17]针对评论文本存在情感极性不确定的文本以及评论文本转换成特征向量时存在维度较高、冗余属性、忽略不同类别中的特征差异性等一系列问题,提出基于三支决策和类别特征表示的情感分析模型。将文本划分为三部分,利用最优特征表示和原始特征在3个域上分别进行二分类情感分析,得到模型二分类情感分析的效果。然而,此方法只考虑了确定域的信息,对不确定域的样本信息缺少利用。模型对于不确定域样本的处理并不能取得较好的分类结果。针对此问题,本文提出一种不确定域特征表示的鲁棒性情感分析,利用不确定域异类样本间的差异性进行属性冗余的去除和多粒度特征表示的构建,进而融合出适用于不确定域样本的鲁棒性特征表示。
2 模型介绍
2.1 不确定域
Pawlak 粗糙集对于接受和拒绝的条件都过于严厉,只有完全被正确分类的元素才归于正域里,或只有完全错误的元素才归于负域里。这样的定义结果使得不确定域达到最大,没有考虑分类过程中的错误和模型的容错率,在实际应用中往往难以实现。针对此问题,概率粗糙集概念被人们提出,对于给定一对阈值,概率粗糙集上下近似集[18]可被定义为:
根据三支决策的定义,可构造出如下基于概率粗糙集的三支决策,确定域N和不确定域U的定义如下:
利用两个参数来划分三个边界,确定域样本用原始特征表示,不确定域中的样本根据异类样本的差异性,去除冗余属性,构造鲁棒性特征表示,增强模型鲁棒性。
2.2 UFR-SA模型
针对文本情感分类时出现模糊数据影响模型鲁棒性的问题,本文提出一种不确定域特征表示的鲁棒性情感分析模型(UFR-SA)。模型对不确定域中的模糊数据进行处理,降低其不确定性对模型的干扰,增强模型鲁棒性。UFR-SA 的模型架构主要包括文本嵌入模块、不确定域多粒度特征表示构建模块以及多粒度特征表示融合模块三部分。图1 为UFRSA 模型的示意图,本节详细介绍了该模型的具体步骤和优化细节。
2.2.1 文本嵌入模块
本文采用预训练BERT 模型对数据进行嵌入表示。对于输入的样本集S={s1,s2,…,sn}包含文本信息X={x1,x2,…,xn}以及标签信息Y={y1,y2,…,yn}。模型训练引入标签信息,将类别相同的样本视为正样本,类别不同的样本视为负样本,进行对比学习,输出为文本特征表示,以及一个标签感知的特征表示。损失函数采用Chen 等[19]改进的对比损失函数LDual。该损失函数由标签感知特征表示的损失函数Ly和文本特征表示的损失函数Lf两部分组成。其中Ly损失函数的形式化定义如下:
在本文中,将标签信息作为增强文本送入BERT中,用以获得异类样本之间的类别差异性信息。输入样本经过文本嵌入模块后,得到文本特征表示和标签感知特征表示,样本分布得到初步划分。
2.2.2 不确定域多粒度特征表示构建模块
对于给定的样本集S被概率阈值α划分为确定域N和不确定域U。对于不确定域样本,原始的高维特征存在着影响分类的冗余属性。本文选取不确定域中异类样本点对,利用异类样本之间的差异性,消除不确定性影响,进而增强模型鲁棒性,点对的选取如图2所示。
针对误分类率较高的不确定域,有异类样本点si,sj∈U,异类样本点对PAP(i,j)的形式化定义如下:
式(8)中d为样本xi、xj之间的距离,min{}为不确定域中距离最近的样本点对。
基于异类样本点对PAP(i,j),考虑异类样本之间的差异性,进行属性的挑选,进而实现多粒度特征的构造。因不确定域样本的模糊性,利用不确定域样本点对构造的多粒度特征表示,消除了原始特征的不确定性,达到了增强模型鲁棒性的目的。下面是不确定域样本多粒度特征表示构造的具体流程:
对于给定不确定域样本集U⊆S,属性集A:
(1)取不确定域样本集U,属性集A;
(2)将样本集U投影到属性集A所构成的特征空间;
(3)寻找样本点si最近的异类样本点sj构成点对PAP(i,j);
(4)计算点对PAP(i,j)内各属性的差值的绝对值,即属性偏差值集合
(5)取属性偏差值集合中,差值较小的前k个属性保留,剩余属性值均置零,构成粒度1 的属性集A1=A(i,j);
(6)退回步骤(1),继续构造粒度的属性集A2,A3,…,An;
(7)不确定域样本集U内的所有样本均已遍历完成,多粒度特征表示构造结束。
根据异类样本点对的定义,原始特征空间被分割成不同的特征子空间,即多粒度特征表示A1,A2,…,An。多粒度特征表示代表着不确定域样本各个点对之间的差异性,在各自点对内可较好地区分异类样本之间的差异性。
2.2.3 多粒度特征表示融合模块
不确定域多粒度特征表示构建模块生成的多粒度特征表示A1,A2,…,Ak,对不确定域单个异类样本点对具有良好的特征表示,但由于测试样本数据未可知,单个粒度缺乏对未知数据的适用性,模型泛化性能不佳。针对此问题,本文提出多粒度特征表示融合模块,融合各粒度优势,增强模型的鲁棒性。预训练BERT模型对数据进行嵌入,得到原始特征表示A,其中特征表示A中包含i个属性,即A={a1,a2,…,ai-1,ai},多粒度特征表示A1,A2,…,Ak是从同一个文本特征中挑选出的不同的属性集合,具体形式如下:
A表示粒度特征,a表示该特征内的属性值,在多粒度特征表示A1,A2,…,Ak中0 表示此属性未被保留,ai表示第i个属性被保留,各粒度特征之间的差异性即为属性组合的不同。本文的文本嵌入模块输出特征维度为768维,即i=768。多粒度特征表示融合网络可形式化定义为函数F,具体如下:
式(9)中A表示多粒度特征表示,WT为多粒度特征表示融合网络的参数矩阵,b为偏置值。多粒度特征表示融合网络由一个输入层为768 维、隐藏层为512维、输出层为768维的多层感知网络构成,层与层之间的激活函数采用sigmoid函数。粒度经过特征融合网络本质为将不同粒度的属性值做函数F的输入。例如粒度A1,经过函数F后输出一个768 维的新特征,形式化如下:
式(11)为将文本特征Z与标签特征融合后得到的预测标签Y。将预测标签与真实标签进行对比得到不确定域样本损失LU,LU的计算方式与LDual损失相同,形式化表示如式(12)所示:
UFR-SA 通过反向传播来优化模型,通过最小化LU,更新模型参数优化嵌入结果。
2.3 算法流程
UFR-SA模型采用BERT模型分别对文本信息和标签信息进行特征表示,将标签作为文本信息增强,以扩大类别间差异性。使用SGD 优化器来优化多层感知网络。UFR-SA 模型的损失采用的是改进的对比学习损失函数LDual。该模型的算法流程如下:
算法1UFR-SA模型流程
3 实验结果及分析
3.1 数据集介绍
本文的实验在斯坦福情感树库(The Stanford Sentiment Treebank)SST-2、SST-5 以及CR 数据集上进行。SST-2 是一个单句子分类任务的数据集[20],包含电影评论中的句子和它们情感的人类注释。SST-5是一个用于情感分析任务的流行数据集[20]。它包含了11 855 部电影评论,根据其情感将其标记为以下5个类别之一:非常负面、负面、中立、积极、非常积极。CR 是一个客户产品评论数据集[21],类别分为两类正面(positive,样本标签对应为1)和负面(negative,样本标签对应为0),表1总结了数据集的统计数据。
3.2 参数设置及评价标准
本文采用的实验参数如表2所示,在不确定域构建多粒度特征表示时,本文分别进行保留特征数为[128,256,512,640]的实验,在保留特征数为512 时取得最好的实验结果。激活函数为Sigmoid 函数,学习率lr为1.5E-10,Batch size 设置为16,Epoch 设置为100,衰减率decay 为0.01,temp 设置为0.1,不确定域样本选取阈值α为0.95。
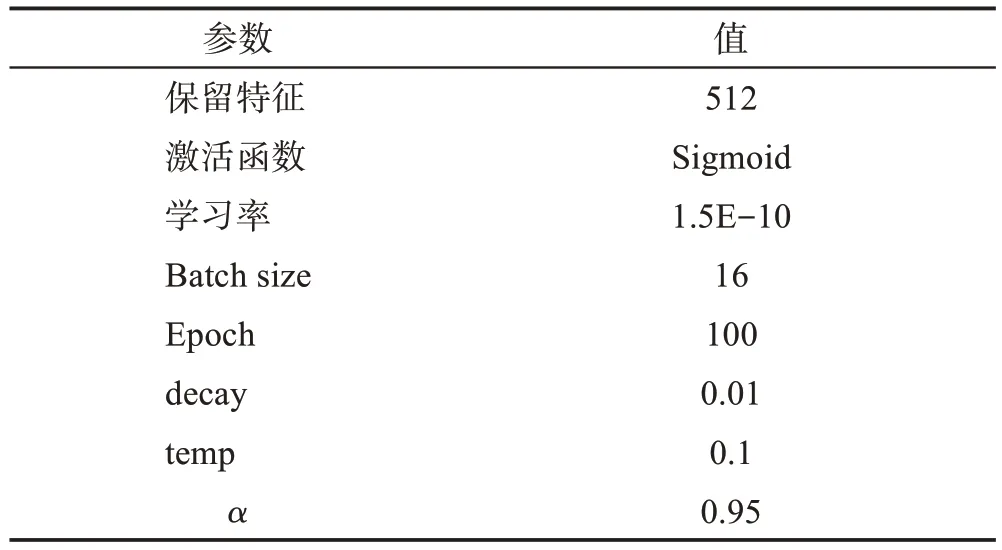
表2 参数设置Table 2 Parameter setting
为了证明该方法在情感分析中的有效性,本文使用平均分类精度Acc来衡量评价度量。Acc的计算公式如下:
其中,Tp为预测为积极类别的积极样本数;Fp为预测为积极类别的消极样本数;Tn为预测为消极类别的消极样本数;Fn为预测为消极类别的积极样本数。
3.3 对比算法
PAR transformer(pay attention when required transformer)模型[22]:利用具有线性复杂度的差分神经结构搜索算法来改进Transformer 模型。实验表明,该模型在保持测试精度的同时,能减少63%的自注意力模块,同时也节省了时间。
RCDA(reinforced counterfactual data augmentation)模型[23]:用一个双分类器去联合原始样本和对应的反事实样本,引入一个强化学习框架去联合生成任务和分类任务。
CE+SCL[24]:多分类任务中传统的交叉熵损失函数导致泛化性能较差,对有噪声的标签或对抗样本缺乏鲁棒性。CE+SCL 模型提出监督对比学习的思路额外添加了一个loss,目的是使同一类样本尽可能离得近,异类样本尽可能离得远。使得模型对微调训练数据中的不同程度的噪声具有更强的鲁棒性,并且可以更好地推广到具有有限标签数据的相关任务。
DualCL[19]:一个对偶对比学习框架,在同一空间内同时学习输入样本的特征和分类器的参数。具体来说,DualCL 将分类器的参数视为关联到不同标签的增强样本,然后利用其进行输入样本和增强样本之间的对比学习。
3.4 结果分析
为进一步评估本文提出的不确定域特征表示的鲁棒性情感分析模型的性能,在3 个数据集SST-2、SST-5 以及CR 上进行平均分类精度对比,实验结果如表3 所示。UFR-SA 模型在平均分类精度Acc上均取得了最优结果。
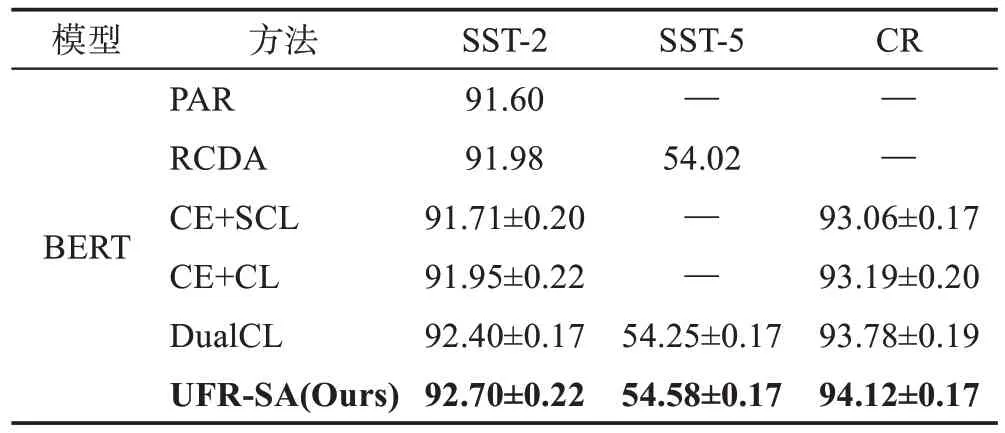
表3 与流行算法比较(Acc)Table 3 Comparison with state-ofthe-art models(Acc) 单位:%
在文本词嵌入同为BERT 模型的基础上,UFRSA 模型在SST-2 数据集上取得92.70%的准确率,在SST-5数据集上取得54.58%的准确率,在客户产品评论CR数据集上取得94.12%的准确率,结果均优于目前最好的模型。证明了本文提出的UFR-SA 模型可以有效地消除模糊数据不确定性的影响。
3.5 消融实验及参数分析
为了进一步验证不确定域特征处理的有效性,本文在不同的特征维度下进行消融实验。结果如表4所示。

表4 不同特征维度下的消融实验(Acc)Table 4 Ablation experiments under different characteristic dimensions(Acc) 单位:%
在表4中,特征维度为不确定域样本特征保留的长度,UFR-SA 为本文提出的不确定域特征表示的鲁棒性情感分析模型,UFR-SA/wo net 为不进行多粒度特征表示融合的结果。从表4 的消融实验结果可以看出,去除多粒度特征表示融合模块后,相关结果都有所下降,但是结合表3 和其他算法对比结果来看,下降的幅度并不大,用UFR-SA/wo net就足以超过现有的对比算法,这是由于虽然本文并未采取特征表示融合模块,但是在消融实验中仍然采用了不确定域多粒度构建模块,UFR-SA/wo net 的实验结果为利用粒度特征处理不确定样本后的实验结果,这进一步证明了多粒度构建模块构建出的多粒度特征的有效性。UFR-SA 实验表明模型的分类均值Avg 优于不进行多粒度特征表示融合的实验,证明了不确定域特征表示的鲁棒性情感分析模型的有效性。图3为在不同特征维度下SST-2 和CR 数据集上UFR-SA的实验结果。
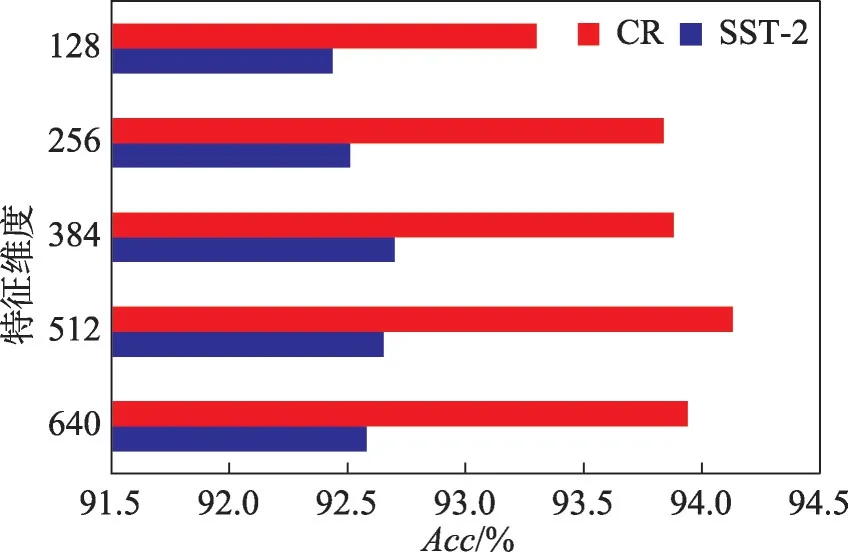
图3 UFR-SA在不同特征维度下的实验结果Fig.3 Experimental results of UFR-SA under different characteristic dimensions
如图3 所示,UFR-SA 在SST-2 数据集上,当特征为384 维时取得最好的分类结果;在CR 数据集上,当特征为512 维时取得最好的分类结果。这是因为特征中冗余属性在开始时去除较少,不足以改善模糊数据不确定性对模型的影响。当属性去除达到临界点之后,继续去除特征中的属性,将会造成样本特征包含的信息过少,影响模型的分类效果。图4 为在不同特征维度下SST-5 数据集上UFR-SA 的实验结果。
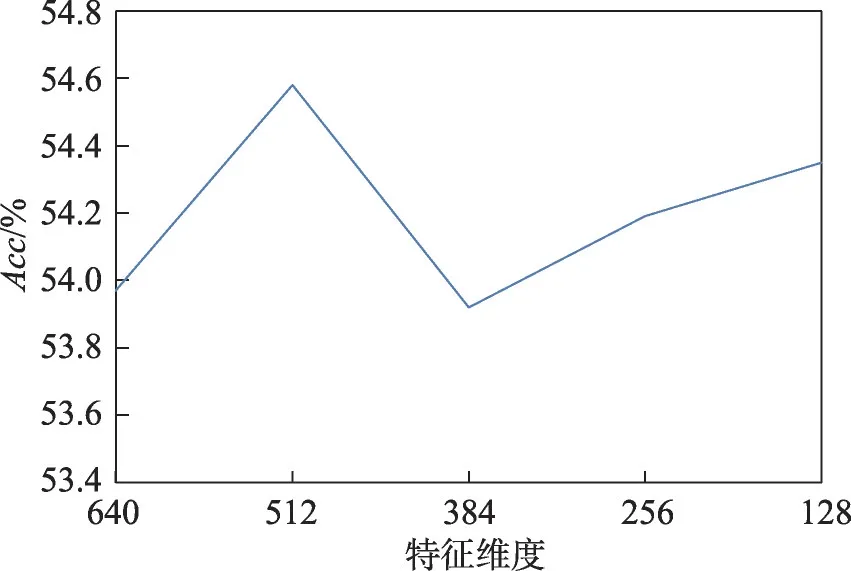
图4 UFR-SA在SST-5数据集上不同特征维度下的实验结果Fig.4 Experimental results of UFR-SA under different characteristic dimensions on SST-5 dataset
如图4 所示,UFR-SA 在SST-5 数据集上,当特征为512维时取得最好的分类结果。3个评论数据集上的结果均优于目前最好的模型性能,证明了UFR-SA模型的有效性。
4 结束语
针对文本情感分析存在较难分类的模糊数据,常常会因其不确定性对模型的鲁棒性产生较大影响的问题,本文提出一种不确定域特征表示的鲁棒性情感分析模型。模型采用三支决策“分而治之”的思想,对于不易处理的不确定域中的模糊样本,根据异类样本间的差异性,去除属性冗余,构建多粒度特征表示,融合出适用于不确定域样本的鲁棒性特征表示。在多个情感分析数据集上UFR-SA 模型均取得较好的分类性能。
虽然本文提出的UFR-SA 模型提升了对不确定域样本的处理性能,增强了模型的鲁棒性,但是对于不确定域样本的特征挑选,还存在着忽略特征之间关联性的问题,特征挑选的合理性存在缺陷。因此在未来工作中还将针对以上问题继续改进。
猜你喜欢
粉末冶金技术(2021年3期)2021-07-28
南京大学学报(自然科学版)(2021年1期)2021-01-30
数学年刊A辑(中文版)(2020年2期)2020-07-25
农业机械学报(2020年2期)2020-03-09
数学物理学报(2019年6期)2020-01-13
中华建设(2019年7期)2019-08-27
数学物理学报(2017年5期)2017-11-23
系统工程与电子技术(2016年12期)2016-12-24
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
