
个性化新闻推荐方法研究综述
2023-12-08 11:48孟祥福霍红锦张霄雁王琬淳朱金侠
计算机与生活 2023年12期
孟祥福,霍红锦,张霄雁,王琬淳,朱金侠
辽宁工程技术大学电子与信息工程学院,辽宁 葫芦岛 125105
由于在线新闻服务的便利性和及时性,很多用户的新闻阅读习惯已经从传统报纸转向了数字新闻内容。然而每天都有大量新闻文章被创建和发布,用户不可能通过浏览所有新闻来查找其感兴趣的新闻。因此,个性化新闻推荐(personalized news recommendation,PNR)技术旨在根据用户兴趣偏好及其位置为用户推荐新闻,是新闻平台帮助用户减轻信息过载、改善新闻阅读体验的关键技术[1]。
个性化新闻推荐系统通过分析和处理原始新闻数据和用户行为数据,结合不同的新闻推荐方法对新闻和用户建模,充分提取新闻内容特征,挖掘用户偏好以生成新闻和用户嵌入表示,其架构如图1 所示。当用户进入个性化新闻推荐系统时,推荐引擎会根据用户的阅读历史、位置、偏好等因素,从候选新闻集中选取满足用户需求和偏好的新闻并根据预测模型对候选新闻进行排序,生成推荐列表并展示给用户。例如,如果用户之前阅读过足球新闻,那么推荐系统可能向用户推荐最新的世界杯赛事新闻;如果用户位置在北京,那么推荐系统可能推荐北京地区的周边新闻。此外,用户界面还将为每个用户显示不同主题的新闻,收集用户反馈并以此更新推荐结果,从而实现个性化的新闻推荐。
尽管PNR 技术已经取得了显著的进展,但仍需进一步提高个性化推荐水平,包括更全面地挖掘新闻语义,更细粒度地提取用户偏好和构建更高效的个性化新闻推荐模型。随着移动互联网技术的蓬勃发展,基于移动端的个性化新闻推荐已成为主流趋势。个性化移动新闻推荐系统能够随时随地向用户提供新闻信息,具有良好的交互性,为用户实时获取新闻资讯带来更加便捷舒适的体验。然而,移动设备的屏幕尺寸较小、网络质量不稳定和使用场景的多变性可能会影响个性化新闻推荐系统的效果和效率,这仍是未来个性化移动新闻推荐研究亟待解决的重要问题。
传统的新闻推荐方法主要分为三类:基于协同过滤(collaborative filtering,CF)、基于内容和混合推荐方法。其中,基于协同过滤的推荐算法旨在通过分析用户行为来发现新闻或用户之间的相关性并相应地向用户推荐新闻。Dong 等人[2]采用协同过滤算法来预测用户评分并在计算用户相似性时添加新闻热点参数来改进相关系数公式,缓解了用户评分矩阵数据的稀疏性。Wang 等人[3]结合协同过滤和概率主题模型的特点,为用户和新闻提供一个可解释的潜在结构。然而,早期的协同过滤算法通常只使用描述性特征(如ID 和属性)构建用户和新闻嵌入,未考虑用户与新闻交互之间丰富的语义信息,存在数据稀疏和冷启动问题。因此,基于内容的推荐算法通过提取新闻文章中的语义及上下文特征来缓解上述问题,其核心在于对推荐对象的内容特征的挖掘以及基于内容特征和用户行为的兴趣模型的构建。Okura 等人[4]基于新闻间的相似性来学习新闻嵌入表示,并引入主题信息来丰富新闻建模。Liu 等人[5]提出一种基于用户点击行为的新闻推荐方法,采用贝叶斯模型根据用户对不同新闻主题的文章的点击分布来学习用户的兴趣表示。混合推荐算法是指上述两种或两种以上推荐算法的组合。Bansal等人[6]将主题模型、贝叶斯模型及协同过滤方法整合为统一框架来推荐用户可能会评论的文章。Lu 等人[7]将基于内容和协同过滤技术相结合,根据新闻文本丰富的上下文信息向用户进行推荐并采用协同过滤技术分析长尾用户的稀缺反馈。然而,混合推荐算法仍存在数据异构性、数据稀疏性和冷启动问题等缺点。
深度学习(deep learning,DL)已成为人工智能时代的新热潮并在推荐系统中得到广泛应用[8]。目前已有多篇相关综述性论文介绍个性化新闻推荐领域技术,如:黄立威等人[9]和余力等人[10]分别从深度学习和强化学习角度提及了个性化新闻推荐技术;田萱等人[11]从深度学习角度剖析了个性化新闻推荐算法;王绍卿等人[12]和孟祥武等人[13]分别从个性化推荐框架和移动推荐角度介绍了新闻推荐算法等。为了更系统地、全面地分析个性化新闻推荐技术,本文从深度学习技术角度进一步论述个性化新闻推荐技术的研究进展,着重总结了基于图结构学习的个性化新闻推荐方法并从新闻推荐的核心对象(即用户和新闻)角度全面分析深度学习技术对于个性化新闻推荐的特点和优势。
1 个性化新闻推荐概述
与电影、商品、旅游、音乐等领域的推荐方法不同,个性化新闻推荐具有高度的时间敏感性,并且受上下文因素和社交因素的影响较大。由于新闻内容通常与当前事件和话题相关,个性化新闻推荐系统需及时捕捉用户偏好并据此动态地更新和调整推荐的新闻内容。相比之下,其他领域推荐通常具有相对较长的内容生命周期。一旦发布,它们可能在一段时间内保持相对稳定的特性和信息,因此更新频率相对较低。此外,由于新闻数据增长迅速,对个性化新闻推荐系统的可扩展性也提出了更高要求。表1 给出了个性化新闻推荐与其他领域推荐方法受上下文因素、社交因素、时间因素和可扩展性方面影响程度的对比结果。
1.1 个性化新闻推荐
1.1.1 基于时间的新闻推荐
基于时间的新闻推荐包含时效性和实时性两个方面。时效性是新闻推荐区别于其他推荐的本质特征,发布时间较久的新闻往往会失去它作为新闻的价值。实时性是根据用户当前行为(如下拉、滑动等),个性化新闻推荐系统实时更新推荐结果,快速反映用户的兴趣变化,给用户视觉上的冲击与强感知。Liu等人[14]设计一个时间模块来强调新闻新鲜度对推荐结果的影响,通过预测用户在每篇新闻文章上花费的“活跃时间”来模拟及时性对新闻推荐结果的影响。实验表明,该方法提高了新闻推荐的时效性并促进了最新发布新闻的传播,但在一定程度上削弱了用户兴趣的主导地位。因此,个性化新闻推荐需要考虑新闻时效性和用户偏好之间的平衡。
1.1.2 基于位置的新闻推荐
移动用户阅读新闻的地理位置并不固定,考虑用户阅读新闻的位置能更加准确地获取用户当前的阅读偏好,也更符合用户的实际需求。袁仁进等人[15]将新闻事件的地理位置引入新闻推荐模型中,提出一种顾及事件地理位置的个性化新闻推荐方法(news recommendation algorithm considering geographical position,NCGP)。该方法通过设计一个提取新闻事件发生地的算法并采用向量空间模型表示新闻特征向量并分别对有地理位置和无地理位置的新闻集构建用户兴趣模型。Chen等人[16]提出一种显式语义分析方法(location-aware personalized news recommendation with explicit semantic analysis,LP-ESA),利用用户的个人兴趣和地理上下文信息进行新闻推荐。然而,LP-ESA 中基于维基百科的主题空间存在高维性、稀疏性和冗余性等问题,为此进行改进提出具有深度语义分析的位置感知推荐方法,采用深度神经网络为用户、新闻和位置提取密集、抽象、低维和有效的特征表示。Xu 等人[17]提出一个专为移动用户设计的个性化新闻推荐框架(MobiFeed),将路径预测引入基于位置的个性化新闻推荐中并根据用户的移动轨迹,实时向用户推荐位置相关的新闻。基于位置的个性化新闻推荐有利于用户发现其附近的新闻,捕捉当下周围环境中所发生的事情,但该方面研究趋向于提高位置匹配精确度而往往忽略了位置感知的用户偏好。
1.1.3 基于社交网络的新闻推荐
社交网络是一个由个体节点以及反映个体之间特定关系的边所组成的图,能够向用户提供一个交友、分享资讯的平台,在一定程度上起到了信息传播和流通的作用。社交信息通常包含用户及其朋友活动的最新信息,反映了用户兴趣的动态性和多样性。Saravanapriya 等人[18]提出一种多标签卷积神经网络,通过挖掘社交媒体来预测用户的多标签兴趣并根据用户感兴趣的标签来确定最受欢迎的新闻文章。Ashraf 等人[19]将用户的社交媒体偏好和新闻类别间的关系进行建模并通过从社交媒体中获取的用户兴趣来进行新闻排名。Yang 等人[20]将知识图谱和社交网络集成到新闻推荐中,采用改进的抽样机制对社交网络结构进行量化并采用随机游走抽样策略来获取社交网络中的邻居。实验表明,融合社交因素的新闻推荐能够动态捕捉用户兴趣变化,进而提升新闻推荐效果。
1.1.4 基于会话的新闻推荐
基于会话的新闻推荐旨在通过在短时间内基于用户偏好对序列信息进行建模,根据用户的短期会话为用户提供个性化的阅读建议。Moreira 等人[21]提出一种基于会话的新闻推荐深度学习元架构,将新闻内容和上下文特征相结合并采用循环神经网络(recurrent neural network,RNN)建模用户时序兴趣。Meng等人[22]将环境、突发新闻及新闻内容相结合,提出一个基于会话的上下文感知兴趣漂移网络(context-aware interest drift network,CaIDN),采用双向注意力循环网络有效地从各方面捕捉用户阅读兴趣的漂移,提高用户兴趣的动态性和多样性。然而,现有的基于会话的新闻推荐方法集中从新闻文章和交互序列中提取特征,通常忽略了新闻文章间的语义结构信息。Sheu 等人[23]提出一种基于会话的新闻推荐上下文感知图嵌入框架,利用知识图谱来丰富文章中的实体语义并采用图卷积网络(graph convolution network,GCN)进一步细化文章嵌入。
1.1.5 基于多模态的新闻推荐
大多数现有的新闻表征方法通常只从新闻文本中学习新闻表示,而忽略了新闻中的视觉信息(如图片、动画等)。事实上,用户点击新闻不仅是由于对新闻标题感兴趣,也有可能被多模态特征(如图像、音频和视频等)所吸引。因此,融合视觉和文本信息来学习多模态特征对于新闻建模和预测新闻点击率尤为重要。Guo 等人[24]融合多模态特征来学习新闻表征并将用户兴趣表示为多模态信息,提出一种基于深度强化学习的新闻推荐方法。Wu等人[25]采用预训练视觉语言模型对新闻文本和从新闻图像中提取的感兴趣的区域图像进行编码,提出一种多模态新闻推荐方法。Xun 等人[26]采用视觉语义建模的方法来捕获用户浏览新闻时所感知的视觉印象信息,从而更加深入地理解用户阅读新闻的过程。实验表明,融入多模态特征的新闻推荐能够更全面地描述新闻内容,提高新闻推荐的效果和准确性。
1.2 个性化新闻推荐与传统新闻推荐的区别
与单纯基于新闻热度、新闻新鲜度等非个性化因素来推荐新闻的方法不同,个性化新闻推荐需要深入考虑每个用户的兴趣偏好,并根据新闻内容、位置、类型等与用户偏好的匹配程度来提供个性化新闻推荐服务。与传统新闻推荐系统相比,PNR 在满足用户个性化需求基础上,还有以下几方面特点:
(1)多样性:推荐结果多元化长期影响用户体验及参与度,是提供高质量个性化新闻推荐的重要因素。然而,现有大多数新闻推荐方法只追求提高推荐精度,往往忽略了新闻推荐的多样性。因此,Wu等人[27]提出一种多样性感知的新闻推荐方法,以端到端的方式生成具有多样性的新闻推荐列表并采用多样性感知正则化方法来鼓励模型进行可控的多样性感知推荐,在新闻推荐的准确性和多样性之间实现良好的平衡。由于新闻中通常带有某种类型的情感倾向,Wu 等人[28]提出一种情感多样性感知新闻推荐方法,将情感信息通过感知情感的新闻编码器融入新闻建模中并基于候选新闻的情感取向建模用户兴趣,有效地向用户推荐具有不同情感的新闻以提高新闻推荐的多样性。
(2)时效性:新闻时效性是新闻的“生命”,以最快的速度将新闻传递给读者是新闻发布和传播的核心。但现有新闻推荐算法往往缺少对新闻时效性的掌控,Liu等人[14]设计一个双任务深度神经网络模型,采用一个扩展的时间模块来细化新闻表示并通过预测用户在每篇新闻上的活跃时间(即从用户点击打开新闻文章页面到用户点击关闭页面的时间间隔)来学习用户向量表示。同步进行新闻推荐和活跃时间预测的多任务学习框架明确模拟了及时性对新闻推荐的影响。考虑到用户兴趣与时间变化的相关性,Qin 等人[29]利用艾宾浩斯遗忘曲线构造基于时间的函数并将其集成到用户兴趣建模中进行时间加权更新,从而实现用户兴趣建模的实时更新以提高新闻推荐的时效性。
(3)流行性:现有方法通常利用新闻标题、摘要、实体等信息或将一些辅助任务添加到多任务学习框架中来预测点击率(click-through rate,CTR)。然而,很少有方法将预测新闻的流行程度和用户对流行新闻的关注程度综合考虑到预测结果中。Wang等人[30]提出一种流行度增强的新闻推荐方法(popularityenhanced news recommendation,PENR),将预测新闻流行度的得分添加到最终的点击率预测中,利用新闻流行度来模拟用户关注热点新闻的倾向程度。由于新闻流行度受许多不同因素影响(如新闻内容和新鲜度),Qi等人[31]提出一种将新闻内容、新闻新鲜度和实时性点击率相结合的方法来预测候选新闻的流行程度,以更全面的时间感知方式预测新闻推荐的流行性。此外,流行度感知用户编码器根据点击新闻的内容和流行度生成用户兴趣嵌入,消除用户行为中的流行度偏差,学习更精确的用户兴趣表示以捕捉流行新闻中不同用户的个性化偏好。
2 个性化新闻推荐系统关键技术
2.1 个性化新闻推荐总体框架
个性化新闻推荐是一种向人们提供满足其个性化阅读兴趣的新闻的重要技术,通常包含三个重要部分。首先,利用新闻编码器从新闻内容或其他特征中学习新闻表示。其次,利用用户编码器从用户的历史点击新闻中准确地学习用户表示。最后,根据候选新闻与用户兴趣之间的相关性对候选新闻进行排序。高质量的新闻推荐在很大程度上依赖于对新闻文章和用户兴趣的准确和及时表示。因此,新闻推荐方法通常采用新闻-用户表示学习框架来学习不同的新闻和用户嵌入向量表示(如图2所示)。
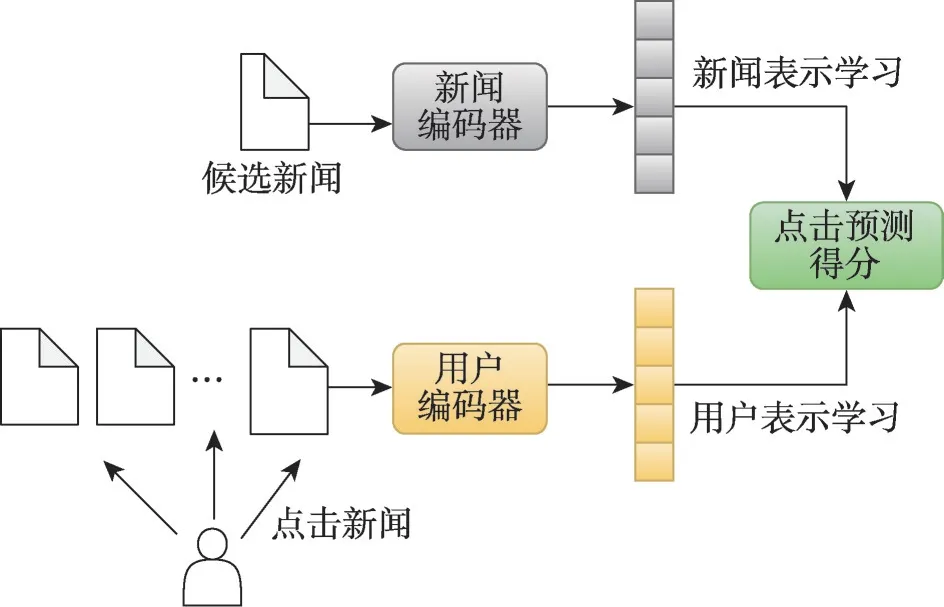
图2 新闻-用户表示学习框架Fig.2 News-user presentation learning framework
新闻-用户表示学习框架的核心在于如何准确地匹配用户兴趣和候选新闻。首先,新闻编码器和用户编码器对新闻文章和用户兴趣进行特征提取和向量化,并采用深度学习或传统机器学习方法习得新闻-用户的嵌入向量表示。其次,通过计算新闻-用户向量之间的相似度,得到新闻语义信息与用户偏好信息的匹配程度并对候选新闻进行排序。最后,点击预测得分越高,用户点击候选新闻的概率就越大。新闻-用户表示学习框架能够整合多源信息(如用户浏览记录、阅读时间及位置、社交媒体信息等),自动从大量数据中学习新闻和用户特征,为用户提供个性化、准确和高效的新闻推荐服务。
2.2 基于深度学习的新闻推荐
基于深度学习的个性化新闻推荐技术是指通过学习多个非线性网络结构来描述用户和新闻表示,从复杂的内容中自动学习高级有效的特征,解决了传统推荐算法过于依赖人工提取特征的问题。常见的深度学习模型包括自编码器(auto-encoder,AE)[4]、卷积神经网络(convolutional neural network,CNN)[21,32]、循环神经网络[33-34]、注意力机制(attention mechanism,AM)[35-39]等,这些模型在不同的新闻建模和用户建模上展示出优越的性能。
2.2.1 新闻建模
新闻建模能够捕捉新闻文章的特征并理解其丰富的文本内容,是个性化新闻推荐方法中的关键步骤。基于深度学习的新闻建模方法旨在从原始输入中自动学习新闻嵌入表示。例如,Okura 等人[4]使用去噪自编码器从新闻文本中学习新闻表示。Moreira等人[21]采用CNN 网络对新闻内容进行卷积以生成新闻嵌入表示。Zhu 等人[32]采用两个最大池化并行CNN 网络从新闻标题中学习新闻的隐藏特征表示。CNN网络在新闻建模中被广泛应用,但难以捕捉长距离的文字交互,不适合长序列新闻推荐任务。因此,一些研究采用AM 扩展神经网络,通过选择重要信息来构建新闻表示,提高文本特征提取的准确性[35-39]。Wu 等人[35-37]提出基于多头自注意力机制的新闻推荐方法,通过捕捉远距离词之间的相互作用以增强新闻特征的表征能力。此外,还提出利用个性化注意力网络学习新闻标题的语义表示和利用自注意力机制来学习新闻标题和正文中的词语语义表示并采用交互式注意力网络来建模标题和正文间的关系。近年来,BERT(bidirectional encoder representations from transformers)[40]、Transformer[41]等大型预训练语言模型(pre-trained language models,PLMs)在对新闻文本中复杂的上下文信息方面具有更强的建模能力,其在个性化新闻推荐中得到广泛应用[42-46]。例如,Zhang 等人[44]将新闻文本串联起来纳入BERT 模型中,同时捕获词级和新闻级多粒度用户-新闻匹配信号以增强文本表达。Huang 等人[45]提出一种自适应Transformer 模型来学习用户和候选新闻之间的深度交互,有效地将历史点击新闻和候选新闻集成到其中以捕获它们固有的相关性。然而,大型预训练模型在输入多领域信息时可能会产生压缩类别和实体信息的浅层特征编码与深度BERT 编码不兼容的问题。因此,Bi 等人[46]提出一个多任务学习框架,将多领域信息整合到BERT 中以提高新闻编码的能力。表2 总结了近年来基于深度学习方法的新闻信息表示和个性化新闻建模技术。虽然上述基于深度学习的方法可以自动学习新闻表示,但未充分利用相关实体及实体间的关系信息。因此,一些研究尝试构造图数据结构来挖掘新闻的潜在知识级联系,本文将在2.3节详细介绍。
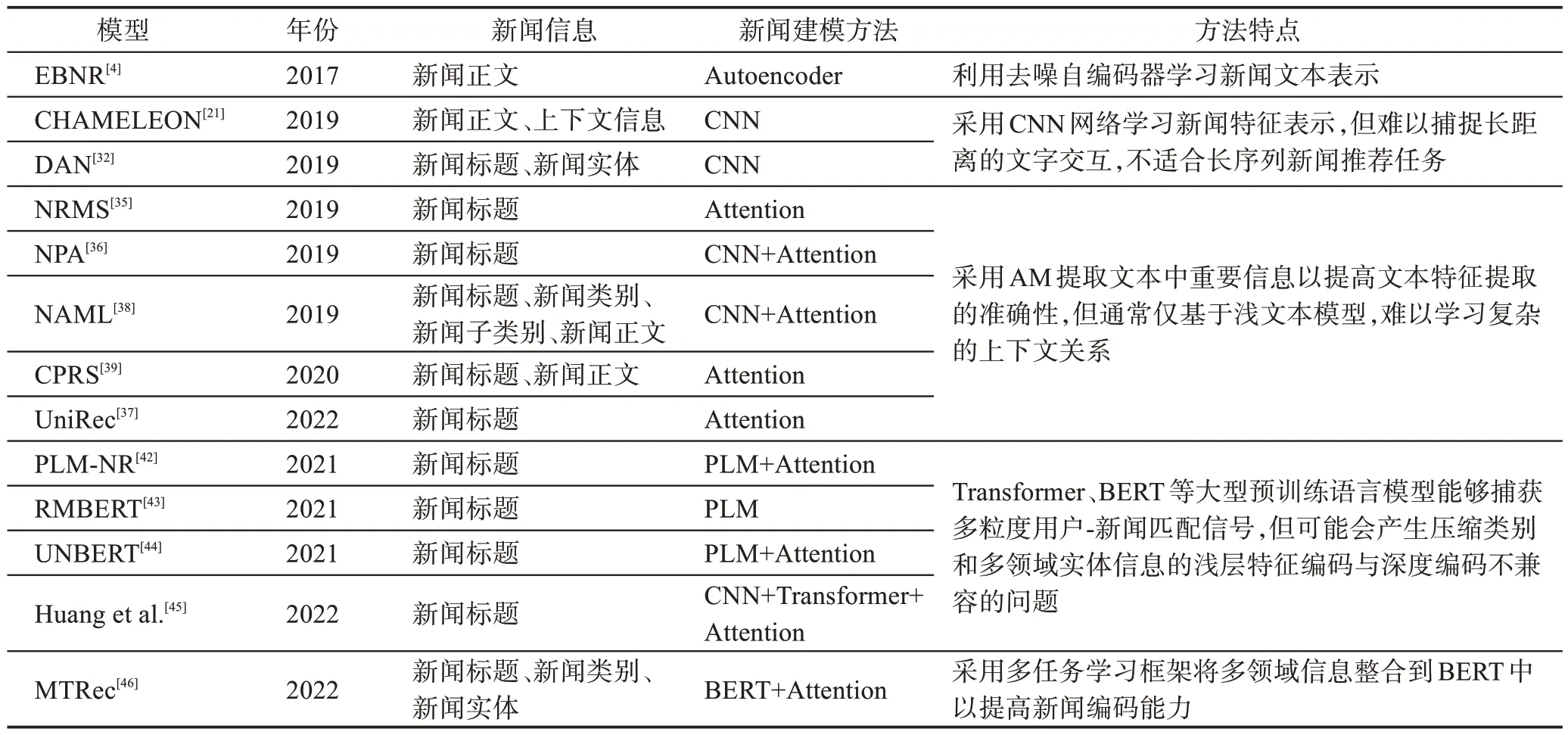
表2 基于深度学习技术的不同新闻建模方法比较Table 2 Comparison of different news modeling methods based on deep learning
2.2.2 用户建模
用户建模旨在推断用户对新闻文章的偏好,是个性化新闻推荐系统中的关键步骤。用户建模通常从用户历史点击行为中推断用户的兴趣和偏好。例如,Wu 等人[38]采用注意力网络从点击新闻的表示中学习用户兴趣表示。Zhang等人[47]利用AM 聚合点击新闻和候选新闻的不同信息以建模用户。然而,上述方法未充分考虑用户历史阅读的顺序信息的影响,其能够更好地反映一段时间内用户兴趣的变化和多样性。为进一步考虑用户的点击顺序,一些研究采用RNN来建模点击序列中的依赖关系以更好地模拟用户兴趣[32-33,48-49]。Okura 等人[4]采用门控循环单元(gated recurrent unit,GRU)网络从用户浏览的新闻表示中学习用户嵌入表示。Zhu等人[32]采用长短期记忆(long short-term memory,LSTM)网络来捕获用户点击历史中更丰富的隐藏序列特征。然而,上述方法虽然增强了用户兴趣的动态表示,但在捕获用户全局兴趣方面仍较薄弱。因此,An等人[33]提出长短期兴趣结合的混合新闻推荐方法(neural news recommendation with long-and short-term user representation,LSTUR),通过GRU 网络学习用户短期兴趣嵌入并通过用户ID嵌入建模用户长期兴趣。
上述方法主要依赖用户点击行为信息来建模用户,通常用户的点击行为比较杂乱,仅从点击反馈中很难全面准确地推断用户兴趣。因此,一些研究将其他类型的用户信息纳入其中以增强用户兴趣建模能力[21,34,39,50]。一种方法是通过添加上下文信息来建模用户偏好。例如,Moreira 等人[21]引入时间、设备、位置等上下文信息,采用UGRNN(update gate RNN)网络来学习用户偏好表示。另一种方法是考虑多种类型的用户行为。例如,Wu等人[50]考虑了新闻点击、搜索查询和浏览网页等多种用户行为并分别从每种行为中学习用户嵌入以作为用户的不同兴趣特征。Wu 等人[39]在用户建模中考虑了用户点击和阅读行为,从被点击新闻的标题中模拟用户的点击偏好并从被点击新闻的主体中模拟用户的阅读满意度。
此外,一些研究结合多种显隐式反馈来推断积极和消极的用户兴趣以增强用户兴趣建模能力[51-54]。Wu等人[51]利用强反馈表示从隐式弱反馈中提取积极和消极的用户兴趣以实现准确的用户兴趣建模。Wu等人[52]提出一种隐式负反馈新闻推荐方法,根据新闻点击的阅读停留时间来区分正、负新闻点击并通过附加注意力网络分别从中学习用户表示。然而,现有方法通常将用户点击的新闻独立编码后将其聚合到用户嵌入中,忽略了来自同一用户的不同点击新闻之间的词级交互。Qi 等人[55]提出一种细粒度的快速用户建模框架,从细粒度的行为交互中建模用户兴趣,利用交互行为中所包含的详细线索来推断用户的兴趣。表3 总结了近年来基于深度学习方法的用户信息表示和用户建模技术。虽然上述基于深度学习的方法可以自动学习新闻表示,但未充分考虑用户与新闻之间的高阶关系。因此,一些研究尝试构造图数据结构来挖掘更深层的用户兴趣特征,本文将在2.3节详细介绍。
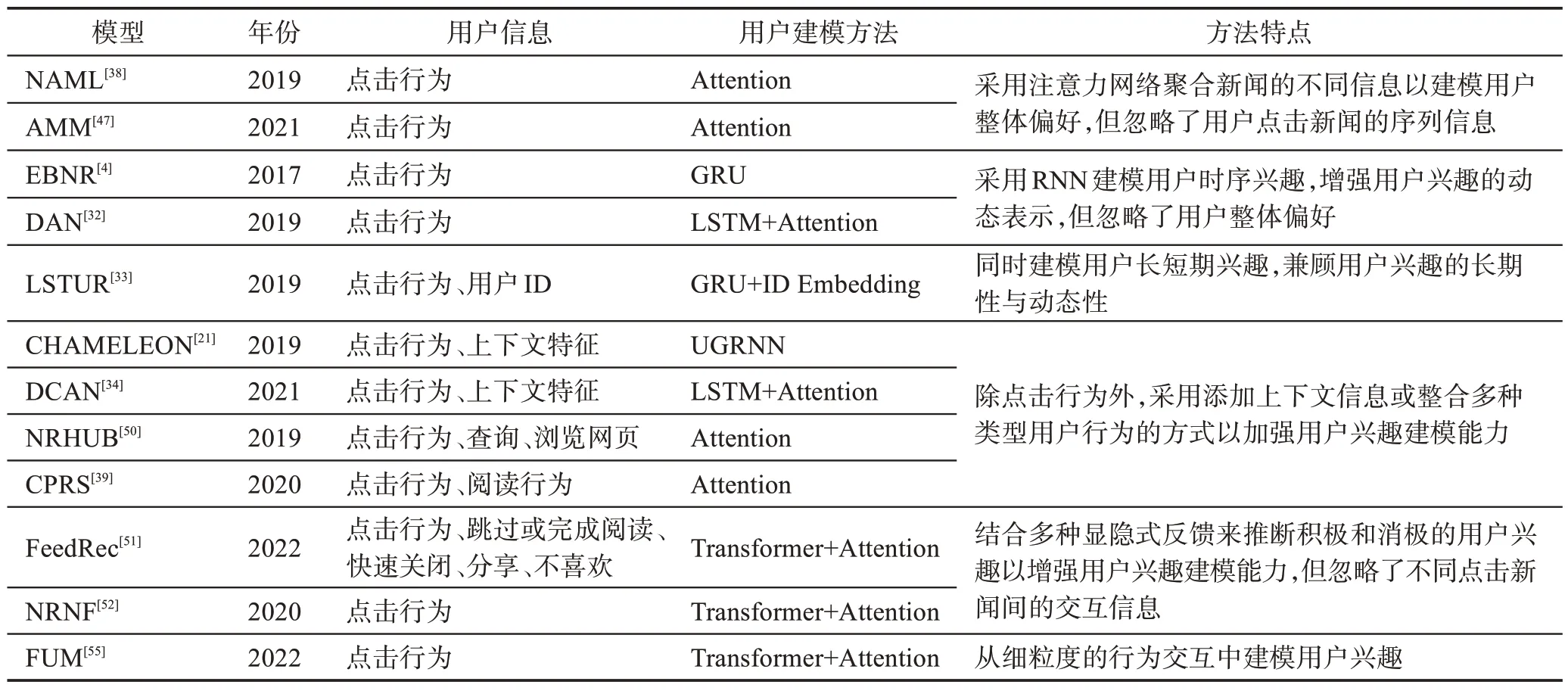
表3 基于深度学习技术的不同用户建模方法比较Table 3 Comparison of different user modeling methods based on deep learning
2.3 基于图结构学习的新闻推荐
图结构是一种非线性的复杂数据结构。在基于深度学习的个性化新闻推荐领域中,图结构通常被用来建立多个用户与多个新闻之间的交互关系,其中所反映的用户与新闻之间的高阶连接性蕴含着丰富的特征信息。近年来,图神经网络(graph neural network,GNN)在图结构上的学习能力逐渐凸显,因其基于节点特征和图结构数据的强大特征表达能力受到广泛关注[56-59]。在基于深度学习的个性化新闻推荐中,图神经网络在建模用户与新闻之间的高阶连接性上具有强大表征能力。本节主要介绍基于图结构学习的个性化新闻推荐模型,包含用户-新闻交互图、知识图谱及社交关系图,其分类标准如图3所示。
2.3.1 基于用户-新闻交互图的新闻推荐
用户-新闻交互图是一种描述不同用户与新闻之间交互行为的图结构。基于用户-新闻交互图的新闻推荐将用户与新闻交互数据作为主要信息源,通过分析交互信息来捕获用户和新闻的特征及高阶的、复杂的关系以进行个性化的新闻推荐。Ge 等人[56]将用户与新闻间的交互信息建模为图结构并设计二跳图学习模块,采用图注意力网络(graph attention network,GAT)聚合新闻和用户的邻居嵌入,增强对应特征的表达能力。Hu 等人[57]在用户-新闻二分图的基础上,通过邻域路由机制对用户的潜在偏好因素解离合,提高了表示的表达性和可解释性。事实上,图结构能够融合个性化新闻推荐系统中的多源异构数据。因此,一些研究将用户和新闻信息描述为异构图(heterogeneous graph,HG),并采用先进的图学习方法进一步丰富用户和新闻图表示[58-59]。Hu等人[58]构造了一个用户-新闻-主题异构图来显式建模用户、新闻和潜在主题之间的交互,合并的潜在主题信息可以有效缓解数据的稀疏性,丰富新闻的语义表示。在此基础上,Ji等人[59]将用户在页面上的活跃时间纳入新闻表示中,提出一种时间敏感异构图神经网络(temporal sensitive heterogeneous graph neural network,TSHGNN),模型结构如图4所示。TSHGNN由两个子网络组成,一个子网采用卷积神经网络和改进的LSTM 网络来学习用户在页面上的停留时间并将点击序列特征作为时间维度特征;另一个子网利用图神经网络将用户-新闻-主题异构图的结构特征作为空间维度特征来编码高阶结构信息。通过利用用户与新闻间交互的动态时间特征,充分建模用户兴趣的动态变化,提高推荐的准确性和时效性。然而,在上述基于用户-新闻交互图的方法中每个用户通常只由全局用户-新闻图中的一个节点表示。
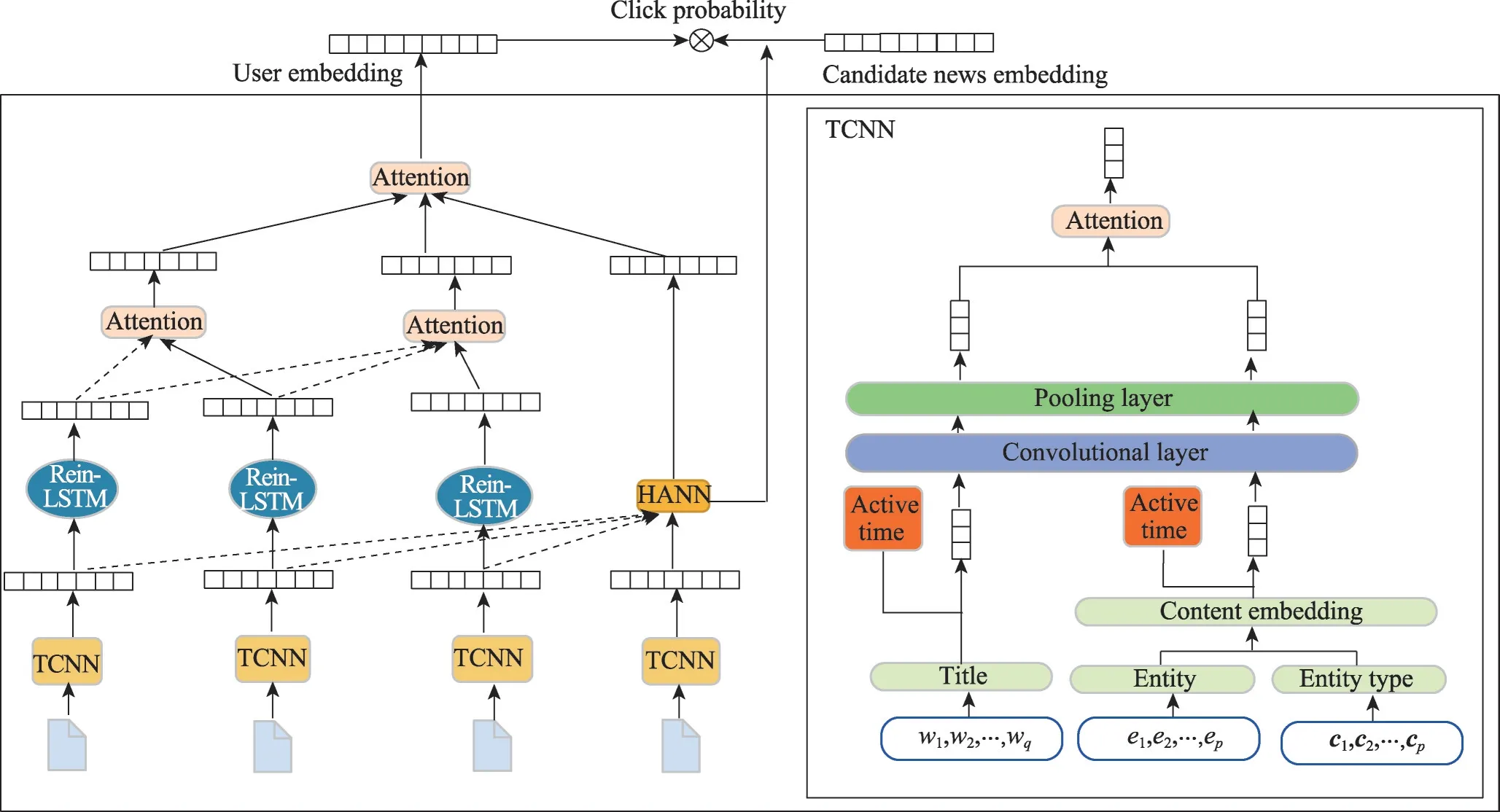
图4 TSHGNN结构Fig.4 Structure of TSHGNN
为了更丰富地建模用户兴趣,Wu 等人[60]提出一种用于新闻推荐的用户建模方法(User-as-Graph),将每个用户建模为一个由用户行为信息构建的个性化异构图并采用异构图池化(heterogeneous graph pooling)方法从中学习用户兴趣嵌入,充分建模用户行为间的相关性,为推断用户兴趣提供更细粒度的信息。异构图池化方法不仅总结了异构图中的节点特征和图拓扑信息,还能了解不同类型节点之间的差异,以更高效、灵活、细粒度的方式学习异构图中用户兴趣表示。不足的是,上述研究侧重于如何从用户图中提取细粒度信息,未充分考虑候选新闻和用户之间必要的特征交互。因此,Mao等人[61]提出由新闻图和用户图组成的双交互式图注意力网络(dual-interactive graph attention networks,DIGAT),模型结构如图5所示。在新闻图示中,利用语义增强图(semantic-augmented graph,SAG)融合相关语义信息丰富单个候选新闻的语义表示。在用户图示中,利用新闻-主题图建模用户历史信息来表示多层次的用户兴趣。同时设计了一个双图交互过程以便在新闻图和用户图之间执行有效的特征交互,更精确地学习新闻-用户匹配表示。
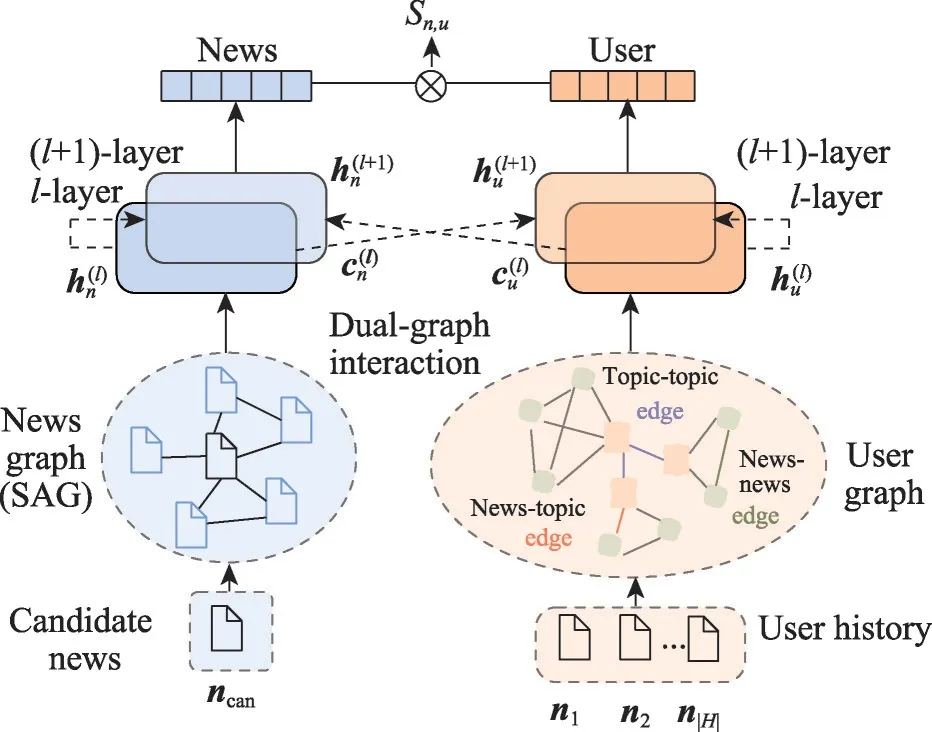
图5 DIGAT结构Fig.5 Structure of DIGAT
现有研究在建模用户表示时往往仅考虑用户的点击行为。为了丰富用户兴趣特征,Ma 等人[62]利用六种不同类型的用户行为(未点击、点击、点赞、关注、评论、分享)信息构建多行为用户新闻交互图,提出了一个基于图的行为感知交互式新闻推荐方法(graph-based behavior-aware network,GBAN)。该方法通过构造一个加权多行为交互异质图,充分利用了用户与新闻之间的多样化关系并在行为图中引入核心特征,衡量用户兴趣的集中程度,合理地权衡了个性化新闻推荐系统的准确性和多样性。
2.3.2 基于知识图谱的新闻推荐
知识图谱(knowledge graph,KG)具有强大的关系能力和丰富的语义特征。若能够通过其引入外部知识来丰富语义,充分挖掘新闻的潜在知识层联系,将会获得更细粒度的信息表示。因此,融入KG 的个性化新闻推荐系统可以进一步提高新闻推荐的准确性、多样性和可解释性。Wang 等人[63]利用知识感知卷积神经网络(knowledge-aware convolutional neural network,KCNN)从新闻标题及标题的实体中学习新闻表示,融合了新闻的语义层和知识层表示。KCNN将单词和实体视为多个通道,并在卷积过程中保持其对齐关系,其模型结构如图6所示。多通道对齐机制消除了单词、实体、实体上下文嵌入空间的异质性,更加全面地捕捉新闻之间潜在知识级关系,获取更丰富的新闻内容。与此类似,Ren 等人[64]利用上述KCNN 组件提取新闻特征,结合KG 构建了一个双重注意力网络,综合考虑了词级注意力机制和整合单词、实体及实体上下文的项目级注意机制并采用多头注意力机制将两者进行特征融合,更好地表征了用户兴趣的多样性。
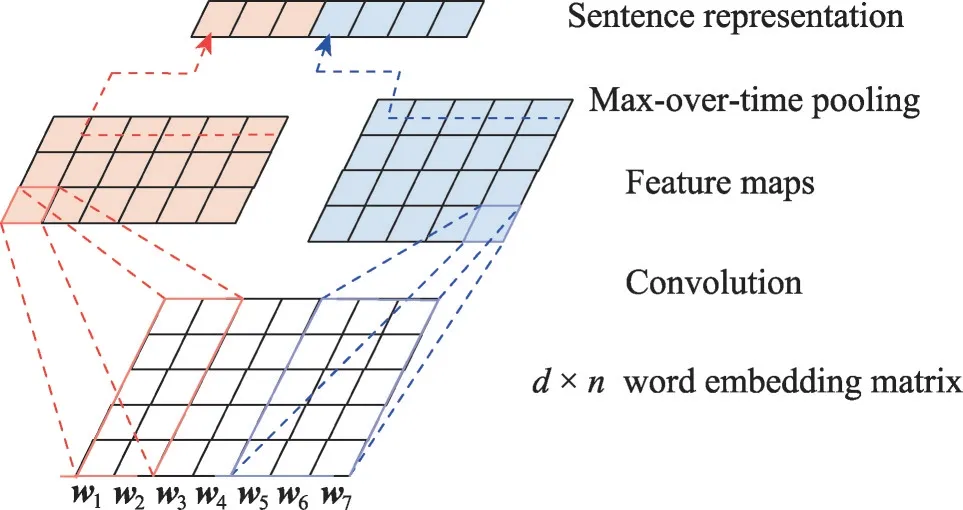
图6 KCNN结构Fig.6 Structure of KCNN
为了充分考虑高阶邻居信息的重要性,Sheu 等人[23]提出一种上下文感知图嵌入框架(context-aware graph embedding,CAGE),利用实体的一跳邻居构造子图生成新闻语义级嵌入,并采用图神经网络结合文章之间的邻域结构信息进一步细化新闻文章级嵌入。然而,这些嵌入主要浓缩了实体之间的低级交互,无法识别两个实体是否出现在同一个新闻中。Lee等人[65]通过引入主题关系提出了主题丰富的知识图谱新闻推荐方法(topic-enriched knowledge graph recommendation,TEKGR),采用知识图谱级新闻编码器,通过添加实体间的两跳邻居从新闻标题中构建一个主题丰富的子图,并利用图神经网络学习新闻知识级表示,其模型结构如图7 所示。TEKGR 采用增加二跳邻居的方法充分挖掘了实体之间的主题关系,丰富实体相关性的建模。除了新闻标题之外,此方法也适用于文本内容或新闻摘要等任何类型的文本信息。然而,这些模型仅利用新闻标题等单一数据,没有充分利用可以为标题实体提供上下文信息的新闻主体、新闻摘要、新闻类别等内容,新闻语义空间不够丰富。
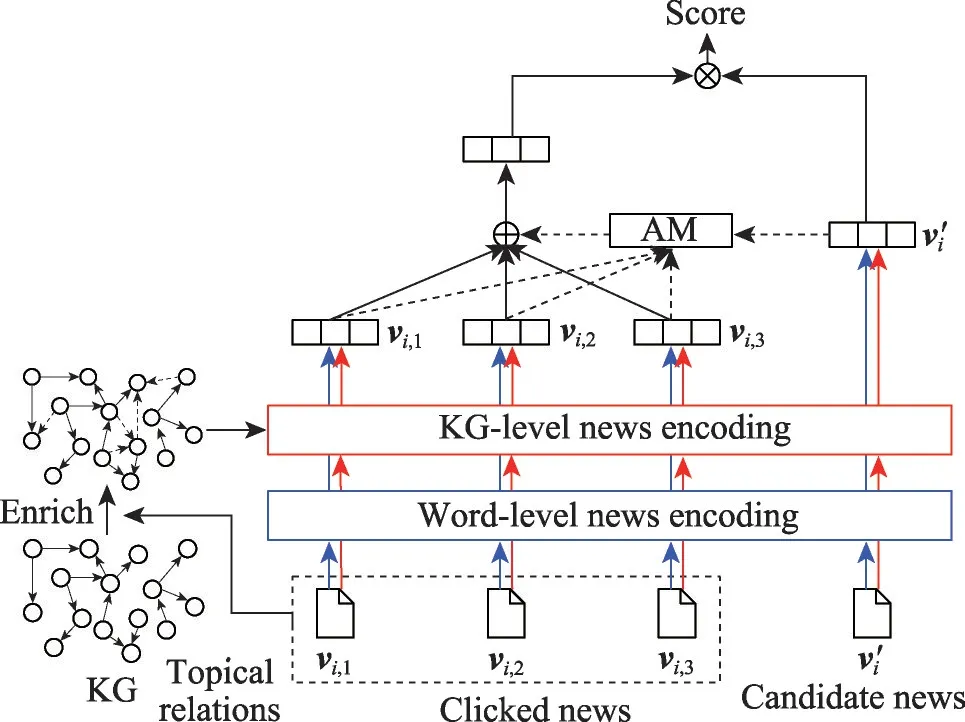
图7 TEKGR模型的结构Fig.7 Structure of TEKGR model
因此,一些研究通过构建多特征学习框架或采用多视角的方式组合学习新闻表示,丰富了知识图谱中新闻语义特征。Sun 等人[66]提出一种结合知识图谱的多特征注意力模型,利用多种新闻特征(标题、摘要、类别、子类别)与链接的外部实体相结合来学习新闻表示,并采用词级和特征级注意力网络选择出重要的单词和特征,丰富了新闻特征表达能力,提高新闻推荐的准确性。Xu 等人[67]引入多种新闻信息构建多视图新闻框架,提出了基于知识图谱的多视图学习新闻推荐方法(news recommendation based on knowledge graph with multi-view learning,NRKM)。该模型利用新闻标题、摘要、类别和知识图谱特征,采用图交互式注意力网络(knowledge graph interaction network,KGIN)和多头注意力机制学习新闻表示,捕获实体与其邻居之间的关系,其结构如图8 所示。由于新闻文章中可能涉及多个方面实体并且用户通常具有不同类型的兴趣,候选新闻和用户兴趣的独立建模可能无法满足新闻和用户之间的精确匹配。Qi 等人[68]提出一种知识感知交互式新闻匹配方法(knowledge-aware interactive matching,KIM),采用图注意力网络对新闻的实体与其邻居之间的关系进行建模,其结构如图9 所示。KIM 设计两个编码器,其中知识感知新闻编码器从语义和知识层面捕获用户点击新闻和候选新闻的相关度,以交互方式学习新闻的知识感知表示;用户-新闻联合编码器交互式地学习候选新闻感知的用户表示和用户感知的候选新闻表示,更好地捕捉用户兴趣和新闻间的相关性。

图8 NRKM实体编码器和KGIN结构Fig.8 Entity encoder of NRKM and structure of KGIN
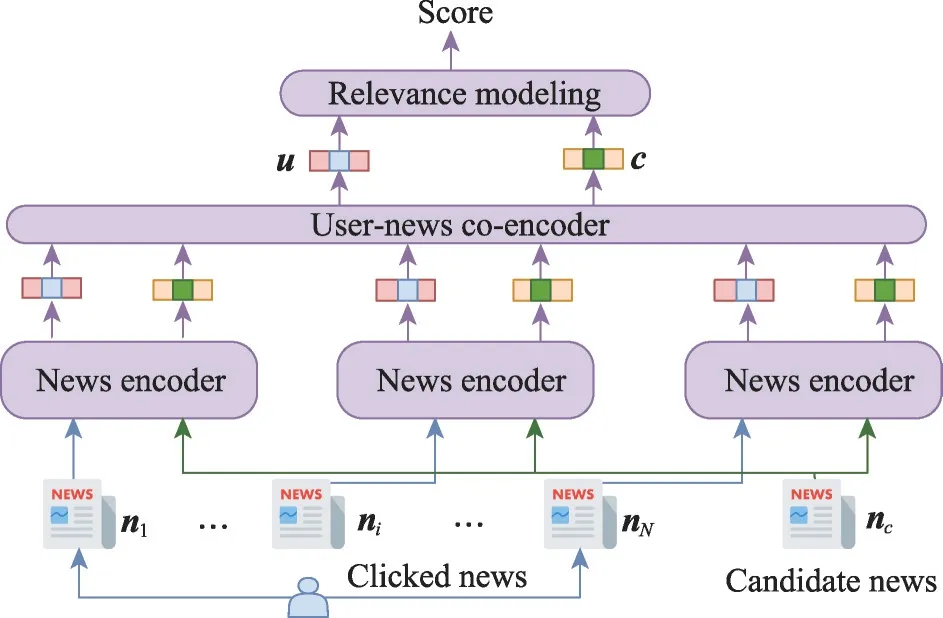
图9 KIM模型的结构Fig.9 Structure of KIM model
此外,现有个性化新闻推荐方法通常从历史点击新闻文章中学习用户表示来反映其现有兴趣,忽略了用户的潜在兴趣,也很少关注用户未来可能感兴趣的新闻。因此,Qiu 等人[69]利用KG 提出一种具有用户现有和潜在兴趣相结合的图神经新闻推荐方法(graph neural news recommendation with user existing and potential interest modeling,GREP)。该方法首先挖掘用户历史点击新闻的标题来编码用户现有兴趣,然后通过找出KG 中与历史点击新闻中的实体相关的实体探索用户的潜在兴趣,丰富用户的兴趣表示。实验表明,利用KG 学习新闻文章及用户表示,在一定程度上提高了新闻语义及用户兴趣特征的表达能力。此外,不同的用户对同一篇新闻文章会有不同的兴趣,若能直接识别与用户兴趣相关的实体并生成用户表示,将能够提高新闻推荐的效率和可解释性。因此,Tian等人[70]提出一种基于知识剪枝的循环图卷积网络的新闻推荐方法。该方法没有建模新闻文章表示,而是直接利用新闻文章中的相关实体建模用户兴趣表示。此外,并非KG 中提供的所有知识辅助信息都与用户的兴趣有关,该模型直接通过修剪大量的不相关知识图谱信息来直接识别与用户兴趣相关的实体以建模用户兴趣。
2.3.3 基于社交信息的新闻推荐
社交信息通常包含用户及其朋友活动的最新信息,自然地反映了用户兴趣的动态性和多样性[20,71]。Zhu等人[71]提出融合社交信息的图卷积网络新闻推荐方法(integrating social information for news recommendation,SI-News),其结构如图10 所示。它主要包含四种编码器,即新闻编码器、社交信息编码器、点击新闻序列编码器和用户编码器。其中,新闻编码器从新闻标题和内容中提取新闻语义特征来学习新闻表示;社交信息编码器首先提取出用户兴趣和用户间朋友关系的隐藏特征,然后构建社交关系图并将其输入到图卷积网络中,学习用户节点信息和朋友关系边信息的嵌入以生成用户的兴趣表示;点击新闻序列编码器采用LSTM 网络从用户历史点击新闻中提取序列相关性特征来学习新闻序列表示;用户编码器融合用户兴趣表示、新闻表示及新闻序列表示以生成所有用户的整体表示。此外,SI-News 还考虑了大众用户点击的常见新闻,有效地缓解了常见推荐模型所面临的冷启动问题。实验证明,融入社交信息的个性化新闻推荐模型能够获取更加丰富的用户信息,进一步反映用户兴趣的动态性和多样性。本小节主要介绍了基于图结构学习的个性化新闻推荐相关研究。表4 总结了基于图结构学习的不同模型的关键技术。
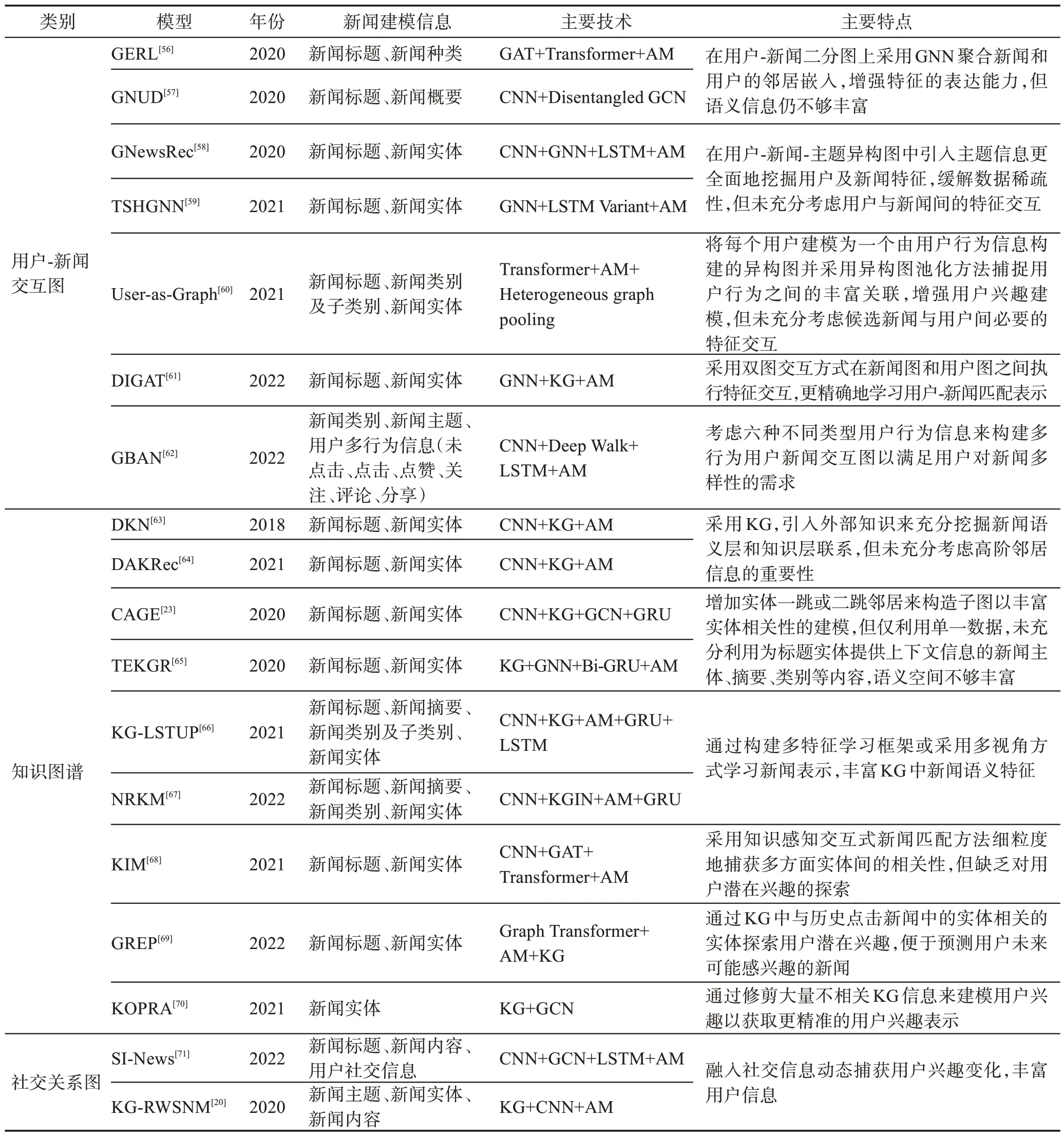
表4 基于图结构学习的不同建模方法比较Table 4 Comparison of different modeling methods based on graph structure learning

图10 SI-News模型的结构Fig.10 Structure of SI-News model
2.4 个性化新闻推荐技术的分析与总结
基于传统学习和深度学习的PNR 技术在模型结构和模型解释性等方面存在差异。在模型结构方面,传统学习模型通常依赖手工提取特征(如用户及新闻的属性等),难以挖掘用户与新闻文章间的深层交互信息;而深度学习模型采用不同的神经网络直接从原始数据中自动学习复杂的特征表示,能够更好地处理高维稀疏数据以提高模型的泛化能力。在模型可解释方面,传统学习模型通常具有简单的线性或非线性结构(如逻辑回归、支持向量机等),通过对特征的选择、转换等方式及对参数的解释来理解模型的预测结果,具有简单、可解释性强的优势;深度学习模型通常具有复杂的非线性结构,参数数量庞大,使得模型的预测结果难以直接被解释。因此,将传统学习与深度学习相结合,进一步提高新闻推荐系统性能是值得探索的研究方向。
深度学习模型可应用于序列数据、图结构数据、欧氏空间数据等数据类型上,其中基于图结构数据的深度学习(图结构学习)的个性化新闻推荐在建模复杂数据结构及解决冷启动问题等方面具有优势。在模型结构方面,图结构学习能够将用户与新闻的多源信息融合并有效地处理复杂的图结构数据,如知识图谱和社交网络等。其中,用户-新闻交互图将用户与新闻间的交互行为建模为图结构以更好地挖掘用户与新闻之间复杂的高阶交互信息,但交互信息通常通过图结构中多跳邻居节点进行传播,需要更多的计算资源和更长的训练时间;知识图谱作为一种更丰富的结构化表示形式,其包含多种类型实体和关系,通过挖掘实体之间的语义关系使其为用户提供更多维度的新闻推荐服务,但对于非结构化的新闻文本,需要进行知识抽取和实体链接等预处理工作,增加了推荐算法的计算复杂度;社交网络图能够捕捉用户之间的社交关系,为用户提供更具有社交性的PNR 服务。因此,相比传统学习方法,图结构学习能够充分利用图结构中的节点和边信息,学习节点之间的关系和信息传递规律以增强模型的表征能力。此外,图结构学习还可以处理多模态数据(如图像和文本等),更好地满足复杂新闻推荐场景的需求。在冷启动问题方面,图结构学习利用其节点属性信息来预测新用户偏好,而深度学习技术则需要更多的用户行为数据来挖掘用户兴趣。虽然图结构学习在处理图结构数据和挖掘深层次交互信息方面表现更为优异,但传统学习模型在特征可解释性方面更具优势。此外,图结构学习对大规模图数据的处理效率相对较低,需要更多的计算资源和更长的训练时间。因此,未来应综合考虑不同模型的特点,根据不同场景和需求来选择更合适的模型,进而提高新闻推荐的效率和准确性。表5 总结了基于传统学习、深度学习及图结构学习的区别与优劣。
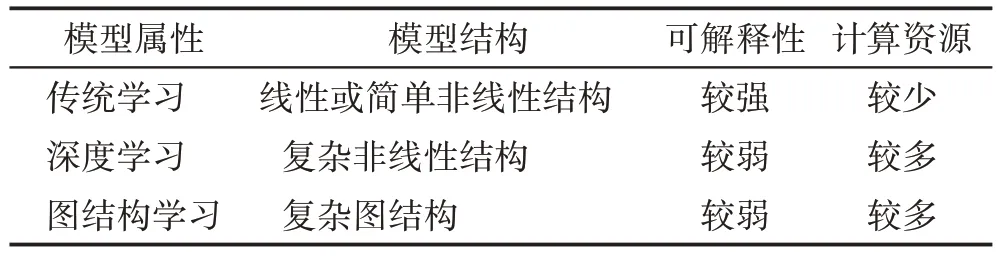
表5 基于传统学习、深度学习及图结构学习的比较Table 5 Comparison on traditional learning,deep learning and graph structure learning
3 数据集及评估指标
3.1 新闻数据集
PNR中常用数据集的统计信息如表6所示。
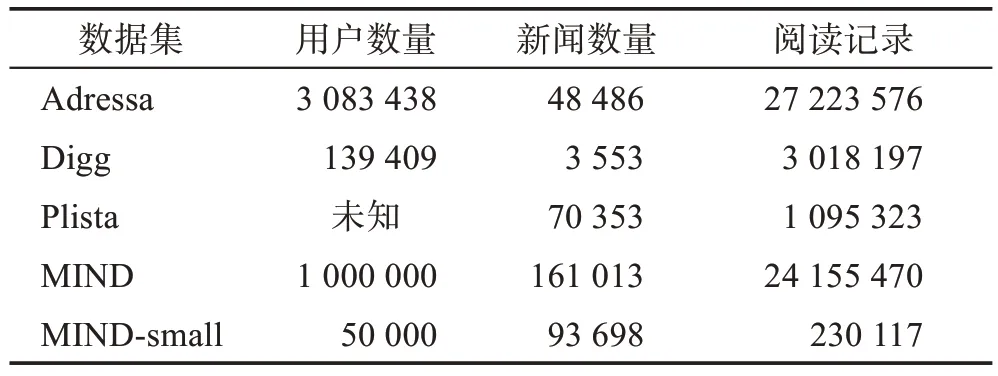
表6 个性化新闻推荐中常用数据集的统计信息Table 6 Statistics of common datasets of personalized news recommendation
(1)Adressa 数据集[72]:由3 个月内Adresseavisen网站收集的新闻日志构成,包括完整版和小数据集两个版本。其中,完整版本包含10 周内的3 083 438名用户、48 486 篇文章与27 223 576 次点击;小版本包含1 周内的561 733 名用户、11 207 篇文章以及2 286 835次点击。
(2)Digg 数据集[73]:由美国南加州大学信息科学研究所于2009 年6 月份在Digg 网站收集的3 553 条新闻构成,包含digg_votes 表和digg_friends 表。其中,digg_votes 表包含139 409 个用户以及3 018 197个投票;digg_friends 表包含71 367 个用户之间的1 731 658个链接关系。
(3)Plista数据集[74]:发布于RecSys2013新闻推荐比赛,由德国13 个新闻网站6 月份收集的1 095 323篇文章、14 897 978 个用户和84 210 795 条阅读记录构建而成。
(4)MIND数据集[75]:由微软新闻网站6周内采集的100 万用户的真实新闻日志构成,包括MIND 和MIND-small 两个版本。其中,MIND 包含161 031 篇新闻、1 000 000 个用户和24 155 470 条行为日志;MIND-small 则包含93 698 篇新闻、50 000 个用户和230 117条行为日志。
3.2 新闻评估指标
个性化新闻推荐的性能主要从推荐结果准确性、多样性和响应时间等多个方面来体现。经典评价指标包括:准确率(precision)、召回率(recall)、准确率和召回率调和平均值F1-score、ROC(receiver operating characteristic curve)、AUC(area under curve)等。现阶段使用较多的F1-score 和AUC 指标具体计算公式如下所示:
其中,Precision为准确率,表示用户对推荐结果的点击概率;Recall为召回率,表示用户感兴趣的新闻被推荐的概率。
其中,Np和Nn表示正负样本的数量。pi表示第i个正样本的预测得分,nj表示第j个负样本的得分。
由于新闻数量庞大,用户通常更加注重排在推荐列表中较前的新闻,一些研究方法按照排名列表对推荐结果进行加权评估。常用基于排名度量评价指标包括MAP(mean average precision)、MRR(mean reciprocal rank)和NDCG(normalized discounted cumulative gain)等,具体计算公式如下所示:
其中,U表示所有用户集。式(4)的含义是将所有用户AP得分取平均。MAP值越大,推荐列表中相关的新闻数量越多且相关新闻的排名越靠前。
其中,u∈U表示遍历所有用户,ranku表示用户u推荐列表中第一个真正例所在的位置。
其中,ri是第i级新闻的相关性得分,若点击新闻ri值为1,否则值为0。
为了获得更高的用户满意度,还需考虑其他方面的新闻评估指标,例如主题多样性、新颖性、公平性和流行度等。Gabrilovich 等人[76]将推荐结果通过新颖性来评估,新颖性是指向用户推荐非热门新闻的能力,衡量新颖性最直接的方法是根据新闻间的相似度,即推荐列表中的新闻与用户已点击的新闻相似度越小,新颖度越高。Zheng 等人[77]采用列表内相似度(intra-list similarity,ILS)函数来衡量推荐结果的多样性。Wu等人[28]使用一组情绪多样性度量标准来衡量历史点击新闻和候选新闻之间的情绪差异。Wu等人[78]使用敏感属性(如性别)预测的准确度作为公平性度量来衡量一个新闻推荐系统是否对不同的用户群体或新闻发布者保持公平。此外,一些研究方法通常采用两种或两种以上的评估指标全面评估新闻推荐系统的性能并进一步改善用户体验,例如将AUC、NDCG和MRR组合评估[61,66]等。
4 挑战与展望
综合回顾现有PNR 技术,可以看到基于深度学习的个性化新闻推荐技术在近几年取得了实质性进展。然而,仍然存在许多问题和挑战亟待解决。本章将讨论个性化新闻推荐领域面临的挑战及其未来研究方向。
4.1 面临的挑战
4.1.1 数据稀疏性和冷启动
在PNR 领域,数据稀疏性和冷启动问题一直是十分重要的研究热点。一方面,用户对于海量在线新闻的阅读、收集、评论等行为数据非常有限,导致用户与新闻之间的交互数据极其稀疏,进而难以准确地进行新闻推荐;另一方面,新闻更新速度很快,容易出现冷启动问题,需要及时为新用户和新闻建模来进行合理化推荐。为此,研究者们利用辅助信息,通过引入新节点和边来扩展图网络结构以增强对用户兴趣的建模能力。例如,Hu 等人[58]将主题元数据与用户点击历史相结合以缓解用户与新闻文章间交互的稀疏性问题。由于用户的点击行为数量通常非常有限,Wu等人[50]提出一种多视图学习框架,从用户的搜索查询、点击新闻和浏览网页等异构多行为中学习统一的用户表示。Yang 等人[20]引入知识图谱,采用随机游走抽样策略来获取社交网络中目标对象的邻居信息以丰富用户兴趣建模。除了将KG与新闻推荐系统相结合,现实应用中仍有许多其他外部结构信息可以帮助提高推荐系统性能,例如社交关系信息、多模态信息和跨领域信息等。因此,如何充分挖掘并整合多种信息来解决PNR 中的数据稀疏性和冷启动问题值得进一步研究和探索。
4.1.2 模型可解释性
新闻推荐可解释性旨在向用户提供清晰、合理的推荐结果解释,增加推荐系统的透明度和可信度,进而提高用户对系统的满意度。现有PNR 模型通常具有大量的参数和复杂的网络结构,难以直接对推荐结果作出合理解释。因此,一些研究采用AM 对模型的每个输入向量进行权重分配并根据权重作出解释,以便更好地理解深度学习模型的内部机理和决策过程。例如,Wu 等人[36]采用词级和新闻级注意力机制对新闻不同内容进行高亮可视化展示,提高推荐的可解释性。此外,KG 中包含的大量实体及实体之间丰富的语义关系,能够帮助用户更直观地了解推荐结果的生成过程和推荐依据。Wang 等人[79]将KG 集成到推荐系统中并通过寻找用户和项目的路径来提供相应的解释。然而,在PNR 领域中,关联的KG 通常包含数千种关系类型,现有新闻推荐模型通常只应用于关系类型非常有限的小知识图谱上。因此,如何在大规模数据上进行可解释性分析与呈现是当前PNR所面临的挑战。
4.1.3 推荐结果多样性
推荐结果的多样性对于提高用户体验至关重要。在个性化新闻推荐系统中,可以从三个角度来理解多样化的推荐结果。第一种是具有时空多样性的新闻推荐,即推荐与用户最近点击的新闻主题或内容不同的新闻以满足用户的多样化偏好。第二种是细粒度多样性的新闻推荐,即通过为每个用户分层提取多个兴趣向量,细化用户嵌入以有效地捕获多粒度的用户兴趣[80]。第三种是上下文信息多样性的新闻推荐,不仅使新闻内容和主题多样化,还整合了用户阅读新闻的时间、地点及新闻的新颖性、流行度等各种上下文因素,提供更高质量的多样化新闻推荐[21,34]。因此,具有多样性感知的个性化新闻推荐可以帮助用户扩展和发现新的兴趣,提高用户满意度并缓解新闻推荐系统中的过滤气泡问题。然而,增加推荐结果的多样性往往会造成准确性的损失,因此如何平衡PNR 系统的准确性和多样性已成为一个关键挑战。
4.1.4 用户隐私保护
现有PNR 方法通常依赖于用户行为数据的集中存储来进行模型训练。由于用户行为具有隐私敏感性,集中存储用户数据可能会增加隐私泄露的风险。联邦学习是一种隐私保护框架,允许多个客户端在不共享其私有数据的情况下协作训练模型。Qi 等人[81]提出一种统一的隐私保护新闻推荐框架,利用本地存储在用户客户端中的用户数据来训练模型并以一种隐私保护的方式为用户提供服务。然而,以联邦方式直接学习现有新闻推荐模型的计算成本对于用户客户端而言较高。Yi 等人[82]提出一种更高效的基于联邦学习框架的隐私保护新闻推荐方法,没有对整个模型进行训练,而是将新闻推荐模型分解为在服务器中维护的大型新闻模型以及在服务器和客户端上共享的轻量级用户模型。尽管联邦学习技术在一定程度上降低了数据被攻击或泄露的风险,但开发保护隐私的新闻推荐系统仍面临挑战。现有推荐模型通常采取数据加密、数据匿名化等技术来增强对用户隐私的保护。然而,PNR 模型通常会尽可能地挖掘不同用户的各类信息以准确地刻画用户个性化偏好并生成更准确的推荐列表。因此,当隐私保护技术和PNR 技术相结合时,用户信息被获取的概率将会减少,从而降低新闻推荐任务的准确性。因此,如何合理地优化PNR 系统的隐私和安全性能仍是一个亟待解决的问题。
4.2 未来研究方向
4.2.1 缓解数据稀疏性和冷启动问题
数据稀疏性和冷启动问题一直是PNR 领域的关键问题,可以从以下几个方面进行改进:
(1)融合多源异构数据
PNR 技术在不同程度上会受到不同类型上下文信息的影响,如用户阅读时间、位置、情绪、社交网络和新闻生命周期等,这些信息对挖掘用户兴趣和建模用户偏好具有重要意义[28,34]。Wu 等人[28]将提取的情感特征与新闻内容特征相结合,探讨情感信息在用户建模中的影响。Meng等人[34]提出一种深度共注意力网络,将用户偏好和新闻生命周期的注意力相结合以模拟对用户点击新闻的双重影响。然而,新闻推荐具有时效性和动态性,尤其在移动新闻推荐中,移动设备的可携带性和使用场景的多变性增加了PNR 中上下文感知的难度。此外,上下文信息的获取与处理也是一个挑战。例如,用户的位置信息通常使用GPS 获取,而GPS 的准确性可能受到许多因素的影响,例如天气、建筑物和地形等。因此,未来应尝试设计一个统一的框架来收集并整合各种上下文信息并有效地动态建模不同信息之间的相关性以获得更准确的个性化新闻推荐结果。
此外,社交网络和媒体在新闻分享和传播中也发挥着重要作用[18-20]。一方面,用户在不同的社交媒体(如微博、头条等)通过留言、回复和分享等多种行为与其他用户进行社交互动,进而反映出用户对该新闻的偏好和满意度,为用户建模提供丰富的补充信息。另一方面,用户的讨论和传播行为便于及时了解新闻的内容并在短时间内迅速形成热门信息,有助于全面挖掘用户的潜在多样化兴趣。因此,利用社交网络中丰富的可挖掘信息(如社会化关系)和多种媒体资源来及时补足文本内容的不足十分必要。然而,近年来针对社交网络在PNR 领域的研究仍较有限。因此,构建一个多源异质社交网络,充分整合不同用户的信息并进行在线社交互动,是未来极具潜力的研究方向。
(2)融合多模态信息
多模态信息整合可以缓解PNR 系统的数据稀疏性和冷启动问题。除了文本内容,新闻通常还包含丰富的图片、音频及视频等多模态信息。这些多模态新闻内容可以为新闻建模提供补充信息,从而提高新闻理解的全面性。因此,采用多模态信息建模技术可以更全面、准确地获取新闻内容并进行用户行为感知与新闻推荐预测。如本文第1.1.5 小节所述,目前已有少量PNR 研究融入了图像信息并取得了显著的效果[24-26]。然而,除图像数据外,其他类型的数据也能够提升新闻推荐的整体效果,例如音频信息,可以获取用户的语速、语调和情感等信息以便对新闻内容进行情感分析,有助于推荐更符合用户当前兴趣的新闻。未来应进一步考虑将多模态信息进行整合,综合分析不同类型数据的特征以便更充分地理解新闻内容,从而得到更准确、更全面的新闻推荐结果。目前,基于多模态信息的PNR 研究尚少且缺少大规模的多模态新闻数据集。因此,引入多模态特征,建模候选新闻与点击行为之间的多模态关系是当前值得探索的研究方向。
(3)跨域新闻推荐
跨领域融合可以缓解PNR 任务中常见的数据稀疏性和冷启动问题。一方面,跨域新闻推荐系统可以从多个不同的新闻网站中收集数据信息,并在这些网站之间进行新闻推荐,帮助用户更好地了解不同新闻网站的内容,从而提供更丰富、更多样化的新闻推荐服务。此外,利用多领域数据也能够帮助不同的新闻网站扩展其用户群,提高系统的知名度和推广力。另一方面,用户对来自不同领域的项目选择通常是相关的。例如,当用户看完电影《传奇梅西》后,可能会更加关注关于梅西的新闻报道,因此可以将用户对电影的交互信息传输到新闻推荐交互信息中以缓解PNR 任务中数据稀疏性和冷启动问题。然而,现有跨域新闻推荐的研究尚少且很难将用户在各个领域中的交互信息收集在一起,同时跨领域信息间的交互关系往往比单个领域的信息之间的关系更为复杂。因此,如何开发更通用的迁移学习模型以有效捕获不同域之间复杂和异构的依赖关系以实现准确和多样化的新闻推荐值得进一步研究和探索。
4.2.2 新闻推荐的可解释性
尽管现有工作在利用KG 提高新闻推荐的准确性和可解释性方面取得了一些进展,但仍存在一些局限性。首先,PNR 领域涉及的知识图谱通常包含数千种关系,难以枚举每个关系对所对应的所有路径。此外,一篇新闻文章通常包含多个实体,仅仅构建单一路径可能无法完全揭示实体之间的关系,从而导致新闻文本内容未得到充分利用。其次,因果推理能够提供因果解释并处理潜在的混淆因素,是一种用于揭示事物之间因果关系的重要技术,但其在新闻推荐领域的可解释性方面研究尚少。因此,将因果推理技术应用于新闻推荐领域以构建可解释的PNR 系统,是一个值得研究的方向。此外,强化学习能够提供明确的奖励信号和可解释的决策过程,即根据用户的需求与反馈进行学习和优化,有助于用户理解推荐系统中的因果关系。因此,未来应尝试将KG与强化学习结合,进一步探索PNR的知识推理,并将其扩展到其他领域推荐,如商品、音乐推荐等,以构建更统一、更具可解释性的推荐系统。
4.2.3 多样性新闻推荐
现有研究在探索多样性新闻推荐方面通常只注重推荐内容的多样性,往往忽略了多样性与准确性之间的平衡,容易导致推荐的新闻与用户的实际偏好相差较大,从而降低用户对推荐系统的满意度,甚至导致用户信息流失。因此,设计一种更综合的多样性新闻推荐模型对于提高在线新闻服务质量具有重要意义。首先,可以采用一些多目标优化方法来设计多样性损失函数,如带权重的多目标优化、多目标自适应平衡策略和演化算法等,以平衡新闻推荐的准确性和多样性。其次,将生成对抗网络(generative adversarial network,GAN)与双目标平衡相结合也是一种十分巧妙的解决思路。GAN 模型由一个生成器和一个判别器组成,生成器采用不同的生成策略,如贪心搜索、随机采样等来控制生成结果的多样性。判别器则负责评估生成器产生的新闻并对生成的推荐列表进行打分。两者采用对抗式交替训练的方式来相互协作,进而得到更加准确且多样化的新闻推荐结果。此外,引入一些多样性评价指标也是十分必要的,如覆盖率、流行度和新颖度等,并将这些指标纳入损失函数中进行训练以综合考量个性化新闻推荐结果的准确性和多样性。
4.2.4 新闻推荐系统的安全性
保护用户隐私是PNR 领域发展的重要前提和基础。因此,开发一种更合理有效的隐私保护新闻推荐方法是值得探索的方向。首先,尝试设计一种更加灵活的联邦学习框架,以便更好地利用上下文特征。例如,可以使用联邦迁移学习方法将不同客户端的上下文信息合并,并将整合的结果应用于推荐系统中。联邦元学习方法能够自适应地选择模型结构和参数,便于在不同的联邦学习任务中动态调整数据交换和模型学习策略,实现充分利用上下文特征的效果。此外,对抗学习通过合成噪声数据来去除用户的敏感属性信息,从而针对性地保护用户隐私。因此,采用多种技术相结合的方法来提高PNR系统的隐私保护性能是一个值得尝试的研究方向。
4.2.5 更精准的用户建模
如何实现更精准的用户建模一直是PNR 领域的研究热点。首先,用户兴趣通常是多样的,不同用户具有不同偏好,同一用户在不同情况下也会有不同偏好。现有PNR 方法通常只从用户历史行为中学习单个用户嵌入以表示其阅读兴趣,而单个用户嵌入并不足以充分建模多样化、多粒度的用户兴趣。未来应尝试采用更复杂的结构(如图结构)来细化用户嵌入以提高对用户兴趣的理解。其次,用户兴趣是动态的。现有方法通常分别学习用户的长期和短期兴趣,并推荐与最近点击新闻相关的候选新闻。由于用户兴趣通常随时间而变化,了解不同时期的用户兴趣并进一步建模其内在关系十分重要。强化学习模型能够根据用户与新闻的交互反馈捕获用户当前偏好并据此调整下一步动作,基本思想是根据当前状态(State)决定采取的动作(Action),再根据采取动作后获得的奖励(Award)调整下一次动作。未来应尝试采用强化学习方法及更多的序列建模技术以改进PNR 中的用户动态兴趣建模,更充分地探索用户兴趣的转移过程。最后,用户的点击行为往往受各种噪声的影响。一方面,用户容易误点击其不感兴趣的新闻;另一方面,系统可能会推荐多种用户感兴趣的新闻,但其只点击其中一条,容易产生负隐式反馈噪声。因此,需要综合考虑用户的多种行为和反馈(如分享、不喜欢等)以提供丰富的补充信息并将其整合到统一的框架中以更好地支持用户建模。未来需进一步综合考虑用户的各种行为和反馈,以便更合理地探索用户的潜在兴趣。
4.2.6 提高新闻推荐效率
随着PNR 领域中用户和新闻数量的爆炸式增长,PNR 算法亦面临越来越大的数据处理压力。现有研究往往忽略了算法或技术的效率问题,因此,如何设计更高效的新闻推荐方法已成为个性化新闻推荐技术的研究热点。未来应兼顾推荐效率和预期结果的准确性,评估每种技术在一个或多个不同数据集上的效率,获得可接受的响应时间。此外,也可以采用快速聚类、降低特征维度及知识蒸馏等方法来压缩大规模新闻推荐模型以提高新闻推荐效率。
5 总结
本文系统性综述和总结了近年来主要的基于深度学习的个性化新闻推荐方法。首先,介绍了个性化新闻推荐系统的特点,描述了个性化新闻推荐系统的总体框架和关键技术。根据个性化新闻推荐的特点和主流深度学习技术方法,重点阐述了基于图结构学习的个性化新闻推荐技术。其次,介绍了个性化新闻推荐系统的数据集和评价指标。最后,提出了当前研究所面临的挑战,并对未来研究方向进行展望。
本文具有两个主要贡献:首先,本文在综述了基于深度学习的个性化新闻推荐方法的基础上,着重总结了基于不同类型的图结构数据的个性化新闻推荐方法,并分析了基于图结构学习的个性化新闻推荐在建模复杂数据结构及解决冷启动问题等方面的优势,突出了图结构数据在个性化新闻推荐中的重要性和潜在应用前景。其次,本文详细地分析了当前个性化新闻推荐领域所面临的挑战和未来研究方向。当前,个性化新闻推荐领域仍存在个性化推荐效果评价、模型优化和隐私保护等难题。因此,未来应尝试结合更多技术(如知识图谱、图神经网络和强化学习等)并探索更丰富的上下文信息(如点击时间、位置、社交关系等)以促进个性化新闻推荐系统更深入的研究和发展。
猜你喜欢
中学生数理化(高中版.高考理化)(2020年11期)2020-12-14
文苑(2020年4期)2020-05-30
电子制作(2018年17期)2018-09-28
新闻传播(2018年12期)2018-09-19
通信电源技术(2018年5期)2018-08-23
汽车与新动力(2016年6期)2017-01-04
商用汽车(2016年11期)2016-12-19
商用汽车(2016年6期)2016-06-29
商用汽车(2016年4期)2016-05-09
创业家(2015年5期)2015-02-27
