
深度学习的二维动画视觉领域修复综述
2023-12-08 11:48李雨航谢良彬
计算机与生活 2023年12期
李雨航,谢良彬,2,董 超,3+
1.中国科学院 深圳先进技术研究院 机器视觉与模式识别重点实验室,广东 深圳 518000
2.澳门大学 科技学院,澳门 999078
3.上海人工智能实验室,上海 200000
二维动画是一种风格独特的影像作品,其制作方式、画面特征和表现内容与记录真实场景的影像存在明显差异。传统二维动画在制作方式上具有独特的特点。在动画制作的前期阶段,通常设定具有超脱于真实世界的表达,具有高度的假设性和象征性。在动画制作的中期阶段,动画师根据设定绘制关键帧,并根据相邻关键帧的动作幅度、轨迹和形变状态合理补充流畅的中间帧。在这个过程中,动画师通常使用纸张或借助软件逐步绘制草图和清晰的线稿,最后进行上色。通常情况下,背景和角色是分开绘制的,因此可以在画面风格和播放速度等方面分别处理前景和背景。最后,将背景和角色合成,并添加后期效果,使用摄影设备或剪辑软件通常以每秒24 帧的速度制作成动画影片,以确保观感上没有卡顿的现象。
制作完成后的二维动画的画面通常由清晰的边缘线条和平滑的色彩区域组成,并带有一些手绘笔触或艺术风格。二维动画中不存在真实的光源,对于光影的处理通常是模仿现实场景或根据画面风格进行艺术加工。画面背景与前景人物往往具有明显的虚实关系。因此,动画中常常出现明确的明暗交界线和独特的细节纹理,以及明显的虚实关系。在修复过程中,如何更好地保留动画的风格特点和虚实关系成为二维动画修复的难点和关键所在。
现有的动画影像受到多种因素的影响,从制作、保存到传输过程,可能会出现画质退化的现象,如噪声、模糊、压缩损失和色彩失真等。随着放映设备的更新换代,一些早期动画作品在高清屏幕上的效果并不理想。目前,日本的动画作品通常以720P 的分辨率制作,而观众在视频网站上看到的1080P甚至更高分辨率的作品通常是通过算法进行插值拉伸得到的。这是因为目前动画制作仍未完全数字化,直接制作高分辨率动画成本高昂,并且原始数据过大不便于传输和保存。此外,动画播放过程中可能出现画面卡顿和不流畅的问题。因此,对于旧动画影像的修复工作以及对新动画影像的超分辨率处理是非常必要的,研究者需要从实际应用的角度进行分析和探索。
在传统工业界中针对动画画质问题(例如噪声、模糊、压缩损失、色彩失真等)会使用一些传统算法。针对噪点问题,常使用滤波方法,包括中值滤波、均值滤波、高斯滤波等。然而,这些去噪方法只适用于特定类型的噪声,并且参数调整较为困难。对于画面模糊问题,常使用逆滤波方法、模拟模糊函数方法以及基于稀疏表示的去模糊方法。逆滤波方法通过傅里叶变换将模糊的图像转换到频域,再通过对频域图像进行滤波和反变换,恢复出清晰的图像。模拟模糊函数方法需要模拟多种模糊核及相关参数,以找到最佳的去模糊效果。而基于稀疏表示的去模糊方法则将模糊后的图像分解为稀疏表示和低通部分,从而得到清晰的图像。总体来说,传统的去模糊方法具有较强的局限性,无法应对复杂情况。针对压缩损失问题,工业界通常在动画传输之前进行预处理操作,如去噪、降低分辨率等,以减少图像数据量,从而降低传输过程中的压缩损失。另外,还可以选择更适合的压缩算法,如JPEG、H.264、H.265,或采用自适应压缩技术,在网络带宽等条件下自动选择合适的压缩比例和算法。在传输过程中,可以使用异常检测技术来检测传输错误、丢包、带宽不足等问题,并对已经损失的数据进行修复。对于已经受到压缩损失的动画数据恢复,常常使用降噪、去模糊、边缘增强等方法来恢复原始数据的细节和信息。然而,在数据损失较大的情况下,传统的降噪和去模糊方法可能会损失大量有效信息,从而影响观感。对于颜色失真问题,工业界也经常使用诸如色彩平衡、色调、饱和度、曲线等工具来调整图像或视频的颜色、亮度和对比度等参数。然而,传统的色彩校正方法通常只能对整个图像或视频进行调整,无法进行精细的局部调整。通过上述对传统工业界处理方法的分析可以看出,在面对不同的质量问题时,通常需要分成多个步骤来解决,并且需要调整和控制大量的参数,操作繁琐,解决问题的能力有限。
对于插帧任务,在传统工业界中有两种处理路线:第一种是根据前后帧图像进行线性插值;第二种是进行光流估计,即通过估计相邻帧之间的运动矢量生成新的中间帧。线性插值方法是通过对两个已知帧之间的像素值进行加权平均来计算新的像素值,这种传统方法存在明显的模糊和失真。光流估计方法则需要进行像素间的匹配,通过对图像中某些特征的比较来匹配关键点,并计算出这些点之间的位移向量。相比传统的帧间线性插值,光流估计方法的效果更好。然而,在处理复杂场景时,目前仍存在一些挑战,效果不尽如人意。
近年来,深度学习方法在视频超分辨率、去噪、去模糊、光流估计以及视频插帧等领域快速发展,为动画影像修复工作提供了更多选择。
对于动画画质修复问题,既可以将画质问题拆分开来解决,也可以将动画影像修复理解为一种盲修复任务。因为画质受损的动画往往具有复杂的退化情况,很难拆解成明确的子问题。在有监督的深度学习中,根据动画作品真实的退化状况准备数据集,同时结合动画的特点进行模型构建,在模型学习的过程中要利用好蕴含在动画影像中的空间信息与时序信息。此外,尽可能端到端地解决动画画质问题,避免在传统工业界中多步骤处理影像。并且从真实的低质量动画场景中学习,能够增强深度学习网络的处理能力。在动画影像修复中,要在保留画面原有风格的基础上提高画面质量,达到更好、更自然的效果。
基于深度学习的动画画质修复方法,往往需要大量高质量和低质量的动画影像数据对。使用传统的下采样插值方法(例如双线性插值、双三次插值等)、模糊核(例如各向同性或各向异性高斯模糊)和随机噪声(例如椒盐噪声、高斯噪声、泊松噪音)等经典的退化方法,很难近似拟合出逼近真实场景的低质量动画,使得数据集的构建变得困难。
对于动画插帧任务,传统的光流估计算法通常依赖于人为设计的特征和约束,在复杂场景中处理困难。随着深度学习的发展,可以通过神经网络学习出更丰富、更准确的特征表示,从而改善光流估计的性能。基于深度学习的光流估计算法有更灵活的优化策略,可通过定义不同的损失函数来引入不同的约束条件。通常包括亮度约束项和平滑性约束项,用于保持光流的一致性和平滑性。这样可以提高算法的鲁棒性,更好地处理复杂场景,并获得更准确的光流估计结果。
但是二维动画数据缺乏精确的光流信息,在制作过程中很难进行矢量标定,从而阻碍了一些利用光流信息进行插帧的方法在动画领域的应用。
综上所述,二维动画影像具有独特的制作方法与画面特征,因此其明显区别于现实场景的影像。传统工业界常使用一些传统算法来修复动画作品,但这些方法存在很大的局限性。随着深度学习的引入,动画影像修复方法得到了显著改进。然而,深度学习方法常受到数据集的限制,且针对动画自身特点的画质修复、插帧等算法以及有效的评价指标仍需要研究者们进行挖掘和探索。
本文将从数据集、动画画质修复、动画时序修复、各算法结果以及评价指标的有效性这几个方面进行介绍和分析,全面总结深度学习方法在动画影像修复领域的应用情况,并最终指出动画影像修复领域的现存问题和发展前景。
1 二维动画相关数据集
根据动画数据的制作方式,本文将动画数据集划分为真实二维动画影像数据集和利用三维软件构建的二维动画数据集。真实二维动画影像通常由画师逐帧绘制,不包含光流、深度等矢量信息。真实二维动画影像数据集主要由从真实动画影片中截取的动画图片和从插画网站收集的插画图片组成。而利用三维软件构建的二维动画数据集可以利用三维软件进行批量渲染生成,能够准确标定每一帧画面中各个物体的矢量信息。
1.1 真实二维动画影像数据集
在动画画质修复任务中,通常需要使用从真实动画影片中收集的数据进行学习。有监督的深度学习方法需要大量成对的数据集,为了生成高质量的动画数据,可以通过特定的退化方式生成相应的低质量动画数据。其中AVC(animation video clip)[1]是一个大规模高质量的真实动画影片剪辑数据集,每个剪辑片段包含100 张连续的动画图片。使用AVCRealLQ(从网络上下载的44 个真实低质量动画片段),通过视频超分辨率网络选择出高质量修复图片,从而形成数据对,再利用经典的退化模块和卷积层组成的退化网络进行训练。这种可学习的降质策略有助于缩小合成数据与真实数据之间的分布差距。
在动画影片的插帧任务中,ATD-12K[2]提供了一个在网络上收集的大型动画数据集,从30 部不同风格的动画电影中挑选出了12 000 个三联组。这些三联组的中间帧可作为算法插帧结果的监督图像。此外,ATD-12K 的测试集根据运动幅度和遮挡面积划分了插帧难度级别,并提供了感兴趣区域(region of interest,RoI)和运动类别的标签。
除了针对动画超分和插帧的真实动画影片数据集,还有一些在插画网站上整理得到的插画数据集。Danbooru[3]是一个持续更新动画人物插画的网站,拥有百万级的插画数据和大量粗糙标签,但可以通过标签筛选来获取所需的相关数据,进而整理出可用的数据集。DanbooRegion[4]包含大量的动画插图与其对应的区域分割图,可以应用于动画区域追踪、线稿上色、动画图像内容分解等方向。nico-illst[5]包含50万张插图,注释标签包括作者、主题和图像的风格(水彩、铅笔、丙烯酸等)等信息。
对于动画角色的脸部识别,DAF:re[6]基于DanbooruAnimeFaces(DAF)动画人脸数据集,保留角色名称的标签,并标注出头部边界框,主要用于动画角色识别的相关研究。iCartoonFace[7]是目前规模最大的动画人物识别数据集,由40 万张以上高质量图片组成,包含5 013个动画人物。LSASRD[8]是一个大规模的动画风格识别数据集,包含了190部动画作品,每个作品包含10个以上的角色。不同人物的头像会被裁剪出来,并标记好年份、性别、地区、种族等信息。
1.2 利用三维软件构建的二维动画数据集
Blender[9]作为一款开源的三维图形图像软件,被广泛应用于动画制作和数据生成。它可以解决传统二维动画逐帧绘制繁琐及无法进行矢量标定的问题。通过“三渲二”技术来建立动画数据集,即模拟二维动画的风格和光源将三维模型渲染成具有二维动画风格的图片。但目前“三渲二”技术尚不成熟,与逐帧绘制的动画影片具有一定差距。因此利用三维软件构建的二维动画数据集不常用于动画画质修复任务,而更常用于动画插帧这类需要矢量信息辅助的任务。
Creative Flow+Dataset[10]使用Blender 软件,在三维动画场景中获取每个物体在每个时刻的真实准确位置坐标,并创建了一个多样化的多风格艺术视频数据集。该数据集包含每个像素的光流、遮挡、分割标签、法线和深度的准确信息。数据集包括3 000 个动画序列,使用了40 个纹理线样式和38 个阴影样式随机选择进行渲染。然而,每个样本都是由简单的预定义运动驱动单一模型生成的,因此无法模拟真实的二维动画所需的运动和模型的复杂度。
AnimeRun[11]选择了三部Blender 开源的三维动画影片,将其渲染成二维动画风格,同时生成相应的光流及深度信息。二维动画风格画面由明晰的边缘线条和纯色色块组成,尚未添加阴影部分以及复杂光源和特效,与真实二维动画仍存在差距。但相较于Creative Flow+Dataset,AnimeRun包含能够移动的背景、多个模型间丰富的交互以及更复杂的运动。
AnimeCeleb[12]提供了240 万张图片,并标注了相应的详细姿态信息。该数据集首先在网站上收集三维动画模型,通过改变模型的三维属性获得更多的表情与姿态,然后在Blender 软件上渲染成二维动画风格的人物图像,再使用注释系统进行标注。
2 动画修复的相关算法
2.1 动画画质修复相关算法
在单张动画图片的修复方面,Anime4K[13]是一个开源的高质量实时动画超分去噪方法,早期的v1.0版本没有使用深度学习方法,而是考虑清晰的边缘对动画视觉效果的重要性。该方法首先使用双三次插值将图像放大到目标大小,然后根据周围像素的亮度和梯度信息对每个像素点进行优化。后面更新的版本中尝试使用深度学习方法,其官方提供了一个基于Tensorflow 框架,参数量仅为2 548 的卷积神经网络模型。Anime4K 的重心倾向于实时优化动画画质,更注重模型大小和运行时间,并有多种模式可以相互组合使用,以达到更好的结果。
目前有许多方法通过学习大量动画数据来提高修复效果。Waifu2x[14]最初基于SRCNN(super-resolution convolutional network)[15]网络,并应用于动画图像的超分和去噪工作。其提供了一个7层卷积神经网络模型,并通过反卷积的方法对图像进行上采样;随后更新了一个由两个U-Net结构[16]组成的UpCunet2X 模型。目前最新版本的Waifu2x尝试使用Transformer结构,引入了5个SwinTransformer-Block[17],构建了UpSwin-UNet 网络。以上Waifu2x 的所有方法均提供了无降噪版与降噪版。
Real-CUGAN(real cascade U-Nets generative adversarial network)[18]在Waifu2x 的UpCunet2X 模型版本的基础上,利用生成对抗方法在百万级未公开的动画数据上进行训练。
Real-ESRGAN(Anime6B)[19]是Real-ESRGAN(realworld enhanced super-resolution generative adversarial network)的动画修复版本,是在原模型的基础上将残差稠密块(residual in residual dense block,RRDB)的数量减少至6 个,并输入大量动画数据集进行训练,使其更好地应用于动画图像的修复。单张动画图片修复网络的发展路线如图1所示。

图1 单张动画图片修复网络发展路线Fig.1 Single animation image restoration method development line
在动画视频超分辨率方面,Real-ESRGAN 提供了一个名为AnimeVideo-v3[20]的动画视频模型,该模型结构如图2 所示。该方法以单帧作为输入,由17个串联的卷积模块组成,未利用帧间的时序信息。而AnimeSR[1]是专为动画设计的深度学习网络,考虑了动画影像的特征。该方法使用单向循环网络和基于滑动窗口的结构,可以将多帧图像作为输入,并充分利用连续帧中蕴藏的时序信息。循环块内部采用多尺度设计,充分融合不同尺度下的特征,帮助网络理解画面内容,优化修复,该模型结构如图3 所示。在第3.2 节中,通过测试和比较这两种动画视频超分辨率网络,来验证AnimeSR结构设计的有效性。

图2 AnimeVideo-v3模型结构Fig.2 AnimeVideo-v3 model structure
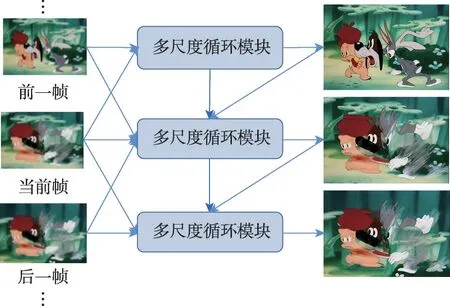
图3 AnimeSR模型结构Fig.3 AnimeSR model structure
2.2 动画时序修复相关算法
2.2.1 动画插帧算法
AnimeInterp[2]首次正式地定义和研究了专门针对动画的插帧问题,其具体结构如图4所示。针对经典的二维动画具有清晰线条和单一颜色填充的封闭区域的特点,该方法首先利用相邻帧中色块对应匹配生成粗糙的光流(segment-guided matching);然后使用经过训练的循环结构光流细化模块(recurrent flow refinement)进一步优化粗糙的光流,以弥补二维动画中光流信息的缺失;最后采用多尺度的卷积神经网络进行扭曲变换合成中间帧。当时,AnimeInterp没有可用的二维动画光流数据进行学习,因此可以巧妙地利用二维动画中色块平坦和线条清晰的特点来模拟光流信息以进行插帧。然而,在第3.3 节的测试中,发现这种不精确的光流会导致插帧结果出现画面模糊和边界不清的问题。
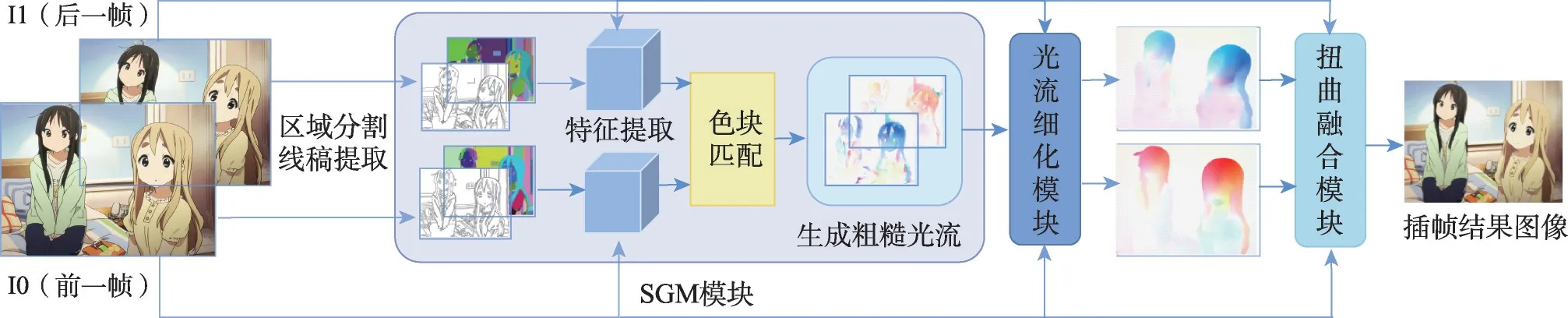
图4 AnimeInterp流程图Fig.4 AnimeInterp pipeline
在AnimeInterp 之后,Chen 等人[21]为进一步提升动画插帧的画面质量,提出了SSL 模块(Softsplat-Lite)。该模块采用前向扭曲结构进行特征提取、光流预测和图像融合。为了更好地利用二维动画的线条信息以获得更清晰的色块区域,作者设计了DTM模块(distance transform module)。该模块首先通过边缘检测提取图像的二值化线稿;然后利用欧几里德距离变换(normalized Euclidean distance transform,NEDT)处理前后参考帧与SSL 输出结果的线稿,并通过训练来估计中间输出帧的NEDT;最后将估计得到的中间输出帧的NEDT 与SSL 模块的结果进行融合,通过训练得到优化后的中间输出帧。以上训练涉及的两部分分别进行处理,整体流程图如图5所示。

图5 Chen方法流程图Fig.5 Chen's method pipeline
经过对这两种插帧网络进行测试,可以发现插帧结果存在画面模糊、重影等问题,因此需要更好的动画插帧算法。这种算法不仅要能够解决视频插帧中常见的物体突然出现或遮挡消失的问题。还要能够准确估计二维动画中的光流信息,并有效处理动画画面中出现的特殊插帧问题,例如大面积纯色色块的运动,同色不同物体帧间对应等。
2.2.2 与帧间一致性有关的动画算法
为了解决动画影片超分辨率和动画插帧任务中出现的色块晕染和边缘线条模糊问题,通常需要引入确保画面帧间一致性的模块。在这方面,可以借鉴一些动画视频上色和动画追踪算法。这些算法通常涉及人物抠像、运动估计、边缘线条提取、色块分割、区域匹配、光流估计等领域。本小节重点介绍这些算法中为保证帧间一致性所采取的方法。
Sykora 等人[22]提出一种无监督的黑白动画视频上色算法。首先屏蔽背景层,只保留运动的人物,再利用基于特征点匹配的KLT(Kanade-Lucas-Tomasi)[23]追踪算法,在第一帧中提取出高曲率点与交界点,然后在第二帧中寻找这些特征点的对应点,并计算它们之间的位移向量来得到光流场。根据这些匹配好的关键点,将每一帧的人物拆解成图像块,使用归一化差异平方和(L2-norm)估计参考图像与目标图像块间的结构相似程度。经过旋转和运动估计的处理后,对匹配好的图像块进行粘贴后再进行颜色统计并上色。如果出现相似结构但颜色不同导致匹配错误,可以通过建立一种图像块间归属关系图(attributed relational graphs,ARG)来表示共用边界线的图像切片。最后通过概率松弛方法排列该目标图像切片各种颜色的可能性,并选择可能性最大的颜色作为最终结果。
Zhu等人[24]提出一种识别手绘动画中连续帧间的物体或区域的对应关系的动画追踪算法,使用一种漫画的区域提取方法(stereoscopizing cel animations)[25]对序列中的每一帧进行区域标记。对于遮挡和后续区域发生分割的问题,该追踪算法考虑了序列中所有帧各区域间的关系,并且建立一个无环连通图,将区域间的外观匹配程度作为路径的损失,从而将跨帧区域匹配问题转化成一个最小路径问题。
目前许多动画视频上色算法使用深度学习方法,通常依靠相邻帧作为上色参考。Thasarathan 等人[26]使用生成对抗网络进行训练,将线稿、灰度图以及参考帧的彩色图作为输入,结合条件损失、内容损失、风格损失共同训练。Shi 等人[27]设计出一个由颜色转换网络和细化网络组成的模型。颜色转换网络的输入包括目标图像与参考图像的线稿、参考图像的彩色原图,以及目标图像与彩色图像线稿经过二值化处理后的欧几里德距离变换图。为了学习参考图像与目标线稿图像相似的空间特征,作者提出了一个距离注意力机制,利用非局部相似性将颜色信息从参考图像转换到目标图像。为保证上色的帧间一致性和统一的画面风格,颜色转换网络中还包含8个以自适应实例标准化(adaptive instance normalization,AdaIN)[28]作为归一化层的残差块。Li 等人[29]提出了一种算法,用于完成关键帧之间的多帧上色。该算法使用两个关键帧和一张中间帧线稿草图作为指引。在第一步中,通过输入的两个关键帧获取颜色信息,学习中间帧草图简化后的线稿与彩色参考图之间的联系。然后,使用PWC-Net(pyramid,warping,and cost volume net)[30]生成光流估计结果,并进行光流一致性检查,得到遮挡处理的掩膜。最后,隐式地结合掩膜信息、线稿信息和光流信息,生成上色后的中间帧。为了减少由于线稿过细导致的画面模糊,还提出了一种基于倒角匹配的线条损失参与训练。在第二步中,假定根据光流估计结果按任意帧率生成其他中间帧的光流。然后,通过光流细化模块和光流一致性检查,混合生成上色后的结果。最后,将所有生成的中间帧作为输入,使用可变形卷积细化结果。Zhang 等人[31]提出了一个相关匹配特征转移模块(correlation matching feature transfer model,CMFT)来保证时间一致性。作者认为相邻帧的线稿是风格相似但内容不同的图片,而同一帧的线稿与彩色图是内容相同但风格不同的图片。因此,可以先将参考图像的线稿和目标图像的线稿输入一个编码器,并将两个结果输入CMFT 模块进行特征匹配,然后将彩色参考图经过编码器后的特征图输入CMFT模块,进行特征转移。Yu等人[32]提出了一个两阶段光流着色网络来解决动画序列帧的着色问题。第一阶段,网络从给定的参考帧和下一帧线条之间的纹理变化中找到颜色像素流向,然后完成初始着色。第二阶段,网络对第一阶段的输出进行颜色校正,以此来增强帧间一致性。
综上所述,研究者们在图像块或色块层面进行匹配;引入注意力机制、AdaIN、对相邻帧进行特征提取等深度学习方法;利用线稿或光流信息等方式来保证动画的帧间一致性。
2.3 工业界常用的二维动画修复软件
对于二维动画修复问题,学术界与工业界有不同的侧重目标和解决方案。学术界更重视算法的效果和创新性,通常致力于将前沿模型应用于动画领域,或设计出更符合动画特点的创新模型。而工业界更注重算法的实现、效率、可扩展性以及用户友好性,旨在实时、综合地解决动画修复问题。
例如,Topaz Labs[33]的“Topaz Photo AI”和“Topaz Video AI”利用深度学习方法,可以对图像和视频进行超分辨率、画质修复、运动插帧以及稳定抖动等多种处理。用户可以通过选择不同的模型和参数来修复低质量视频。
为解决各类影像问题,Topaz Labs 使用了多种模型和训练策略。例如,在画质修复方面,使用Dione 模型处理隔行扫描视频,并针对不同类型的数字视频格式和分辨率进行数据收集和训练,以得到相应的模型变体。他们还使用Proteus Fine Tune 和Artemis 模型作为通用模型,根据不同质量的数据进行训练,并获得各自的变体。此外,使用Gaia 模型来优化高质量影像和计算机生成影像,以及使用Theia模型进行锐化和增强细节。对于运动插帧问题,使用Apollo 模型处理非线性运动和稍微模糊的输入,以及使用Chronos 模型处理帧之间变化较大的快速运动。
目前,Topaz Labs 并未公开上述模型的具体结构和所使用的训练集。然而,Topaz Labs需要使用用户本地的硬件进行图片和视频处理,因此对用户的硬件有一定要求。例如要求用户的显卡至少为Nvidia GTX 900 或更高版本,且具有4 GB 以上的显存。显卡要求通常与模型的大小和复杂度相关联。可见,工业界为了确保用户能够正常使用,需要对模型的大小和复杂度进行限制。为了更好地处理复合问题,他们采用多种训练模型和训练策略,并联合使用多个模型来解决复杂的问题。
除了使用深度学习的Topaz Labs 之外,Adobe After Effects[34]、TVPaint Animation[35]等视频编辑和二维动画制作的专业软件也可用于动画影像的修复和增强。
3 结果分析与方法评估
3.1 动画单张图片画质修复测试
本文对第2.1节中提到的基于深度学习网络的动画单张图片的超分方法进行了测试。方法包括Anime4K 官方的Tensorflow 版本、Waifu2x_7Conv(无降噪版、降噪版)、Waifu2x_CUNet(无降噪版、降噪版)、Waifu2x_Swin(无降噪版、降噪版)、Real-CUGAN(无降噪版、降噪版)、Real-ESRGAN(Anime6B_4X)。所有方法均使用官方提供的权重将原图像放大到两倍,并与其他方法进行对比。其中Real-ESRGAN(Anime6B_4X)版本上采样至四倍后再使用双三次插值方法下采样至两倍。
为了进行测试,从网络上选择了169 张真实的低质量动画图片。后续会公开这169 张真实低质量图片,它们包含多个国家不同风格、不同内容的动画作品,并且所有低质量图片存在不同程度的模糊、压缩、噪点等未知的复合退化情况。因此,这些低质量动画修复问题属于盲复原问题。
目前的网络均是利用拟合出的数据对进行训练,并没有学习过真实的低质量动画图片。同时,这些测试图片没有对应的高质量动画图片,因此需要使用无参考的评价方法来评估修复结果。在图像质量评价方面,选择了NIQE(natural image quality evaluator)[36]、BRISQUE(blind/referenceless image spatial quality evaluator)[37]、NRQM(non-reference quality metric)[38]、感知指数(perceptual index,PI)[39]这些传统方法,它们不使用机器学习方法。另外,还采用了使用深度学习的方法,包括GIQA(generated image quality)[40]、HyperIQA[41]、MANIQA(multi-dimension attention network image quality assessment)[42]。其中GIQA 可以分为KNN(Knearest neighbor)版本、GMM(Gaussian mixture model)版本。然而,以上无参考的评价指标是否能有效评价动画图片仍需要进一步分析。
本文中所有实验均是在Nvidia GeForce GTX TITAN X上进行测试。
3.1.1 动画单张图片修复结果
首先,对网络的无降噪版与降噪版进行了比较,具体包括Waifu2x_7Conv、Waifu2x_CUNet、Waifu2x_Swin、Real-CUGAN。其中Waifu2x的三种网络参数量逐渐递增。人们通常认为深度学习网络参数量越多,修复效果会更好,但三种Waifu2x 网络面对真实的低质量图片的处理结果并未展示出明显区别。Real-CUGAN的表现明显优于三种Waifu2x网络。
真实的动画测试图片通常会存在噪声与压缩。如表1所示Waifu2x的三种无降噪版并没有学习到这类退化,因此无法处理这些问题,并且会产生伪影。而降噪版虽然只接触过拟合的低质量动画数据,但仍能在一定程度上去除噪声和压缩,从而取得更好的效果。并且在面对较为严重复合的噪声与压缩时,处理效果并不理想。Waifu2x 降噪版能使图像更平滑,但无法生成自然的纹理细节。在高模糊图片中Waifu2x 的降噪版抹平了原本动画人物眼睛的高光,影响观感。相比之下,Real-CUGAN 的修复效果明显优于Waifu2x 的三种网络,修复结果的边缘更加清晰,线条更加锐化。另外,Real-CUGAN 的无降噪版对图片中的噪声与压缩也有明显的效果,而Real-CUGAN降噪版的平滑效果更明显。
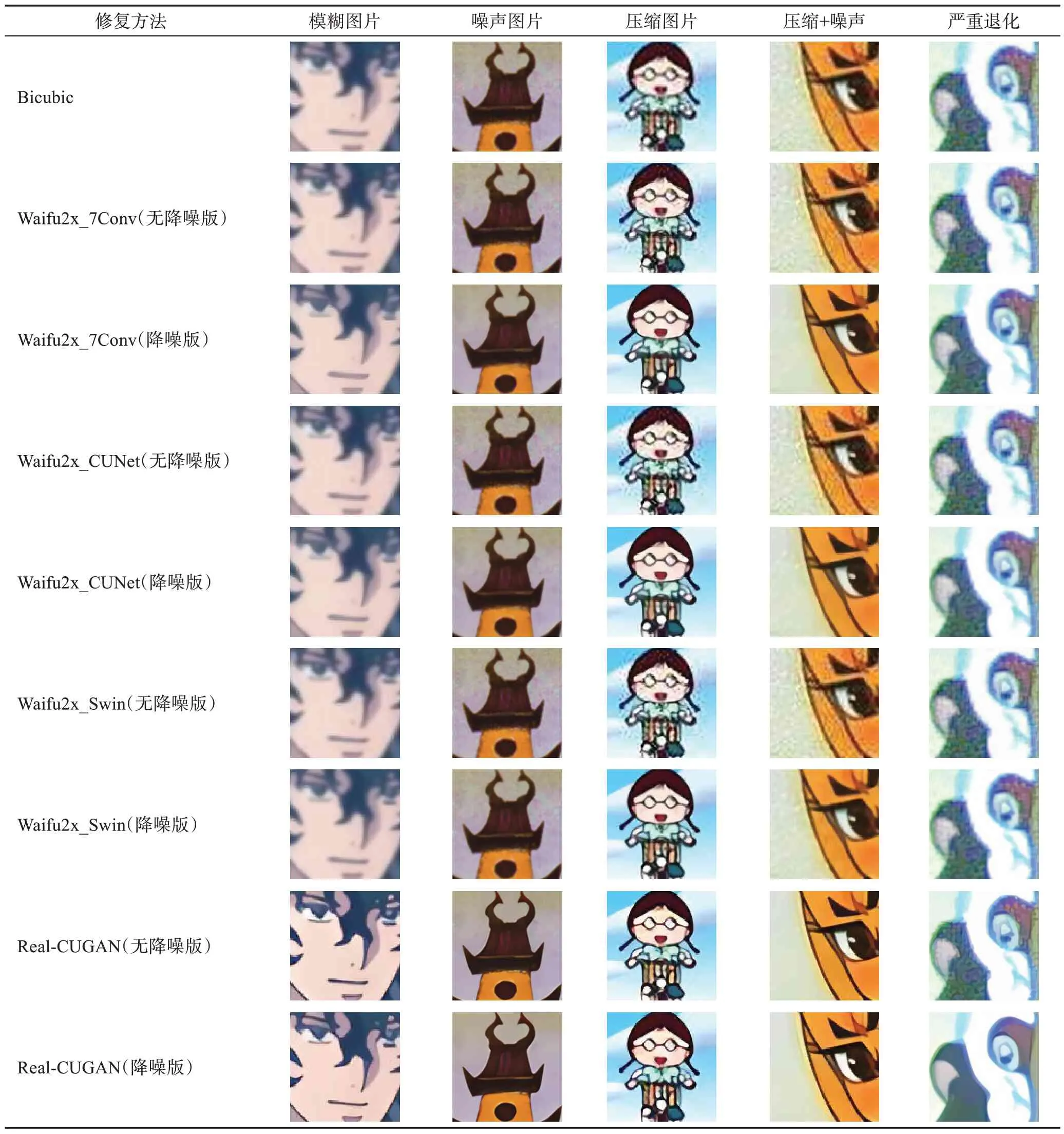
表1 网络的无降噪版与降噪版修复结果对比Table 1 Comparison of restoration results between no denoise models and denoise models
总体来说,与各自的无降噪版相比,各网络的降噪版修复结果的色块更加平坦,颜色过渡更加平滑,但也会损失部分细节。
在二维动画的修复中,针对动画人物的处理效果对观众的感受至关重要。为了比较分析各方法对人物细节的修复效果,本文选择了Anime4K、上一组实验中表现较好的Real-CUGAN无降噪版和降噪版,以及Real-ESRGAN(Anime6B_4X)方法。如表2 所示,Anime4K 对动画图像的修复效果不太理想。而Real-CUGAN 与Real-ESRGAN 不仅能处理画面中模糊、噪点与压缩,还可以生成符合二维动画人物的眼睛、毛发、手部细节。特别是Real-ESRGAN生成的纹理最精细和清晰,对人物的处理效果最佳。

表2 对动画人物细节的修复结果对比Table 2 Comparison of restoration results for details of animation characters
二维动画经常对画面中的某些部分进行虚化处理,通常需要通过网络保持画面原始的虚实关系,并在前景进行锐化,在背景进行虚化。为了实现这一目标,选择了在降噪去压缩和人脸修复方面表现最佳的方法Real-CUGAN 和Real-ESRGAN。如表3 所示,Real-ESRGAN 缺乏对画面内容的理解,难以准确区分图片的前景和背景,这可能导致背景过度锐化,产生伪影,影响观感。相比之下,Real-CUGAN 相较于Real-ESRGAN 对虚化区域保留更好。此外,Real-ESRGAN 在处理模糊的粗边缘线时容易产生中空现象或高亮白边,这是其过度锐化的特点。然而,Real-CUGAN 相对而言在这些情况下表现不太明显。在二维动画中常常具有一些特有的笔触和风格,但目前的网络对于笔触处理和风格的保留均不理想,经常出现涂抹感强的现象。

表3 动画修复中的特殊情况Table 3 Special cases in animation restoration
总体来说,Real-CUGAN 与Real-ESRGAN 的处理效果明显优于其他方法。这两种方法均倾向于锐化线条边缘并使色块更加平坦均匀,这符合二维动画的特征。其中Real-CUGAN 的修复结果对虚化区域的保留更好,而Real-ESRGAN更加善于构造纹理,尤其是人物的细节部分,但过锐的特点可能会产生边缘线中空、白边或生成伪影。因此希望未来的方法能够进一步理解画面内容,从而更好地保留画面中的虚实关系、笔触与风格。
3.1.2 无参考图像质量评价结果
传统无参考图像质量评价指标不需要进行训练,通常是比较目标图片与真实的自然场景图片在空间域上分布的差异。如NIQE、BRISQUE引入归一化亮度系数MSCN(mean-subtracted contrast normalization)比较目标图像MSCN 分布与广义高斯分布的偏离情况;NRQM 提取了自然图像在多个色彩空间的特征;PI则结合了NRQM 与NIQE的结果。然而二维动画图像与自然图像在空间域上存在明显差异,因此传统的无参考图像质量评价指标不能很好地评估动画图像。
深度学习的图像质量评价指标通常通过网络提取图片特征。如GIQA 原本是为生成图片设计的评价指标,具有参数化模型(GMM-GIQA)和非参数化模型(KNN-GIQA)两种。GIQA 首先对真实数据在特征层面建模,从AVC数据集中选择了909张1 920×1 080 的真实高质量动画数据,并对其进行多尺度处理,采用0.75、0.50、0.375 作为下采样参数,从而获得四种不同尺寸的真实图片进行特征提取。然后对待测图片进行特征提取,比较真实数据与待测图像分布,通过得分的排名来判断图片质量的高低。而HyperIQA通过多尺度模块加强对图片语义特征的理解,MANIQA 使用多尺度注意力机制,通过ViT(vision transformer)[43]提取特征,加强全局和局部图像不同区域之间的交互作用。HyperIQA 与MANIQA 都通过增强对图片的语义理解来提高评估的准确性,并且两种IQA网络目前没有使用动画数据进行训练。
首先,需要验证各图像质量评价指标是否符合基本的视觉规律。根据第3.1.1 小节中169 张真实低质量动画图片修复结果,可以发现Bicubic 修复效果明显不如Waifu2x_CUNet(降噪版),而Real-CUGAN(无降噪版)与Real-ESRGAN的结果明显优于其他所有方法,更符合人类视觉感知。此外,两种方法各有特点,Real-CUGAN(无降噪版)对虚化区域保留得更好,而Real-ESRGAN对人物细节处理得更好,画面更锐利清晰。
因此一个成功的动画图片质量评价指标必须要正确地区分各方法的结果,需要使Waifu2x_CUNet(降噪版)的得分明显优于Bicubic,而Real-CUGAN(无降噪版)与Real-ESRGAN 的打分可以相近,但得分要明显优于其他方法。
由表4 所示,从169 张低质量动画数据修复后的平均得分来看,NIQE、BRISQUE、NRQM、PI、KNNGIQA 的结果与视觉感知不符;GMM-GIQA 对四种方法得分的排序基本正确,但Waifu2x_CUNet(降噪版)与Real-CUGAN(无降噪版)区分并不明显,只算是大致符合;HyperIQA 与MANIQA 在未经过动画数据集微调的情况下已经取得了基本符合人类视觉感知的结果。从得分平均值来看GIQA、HyperIQA 与MANIQA均更偏爱Real-ESRGAN的修复。
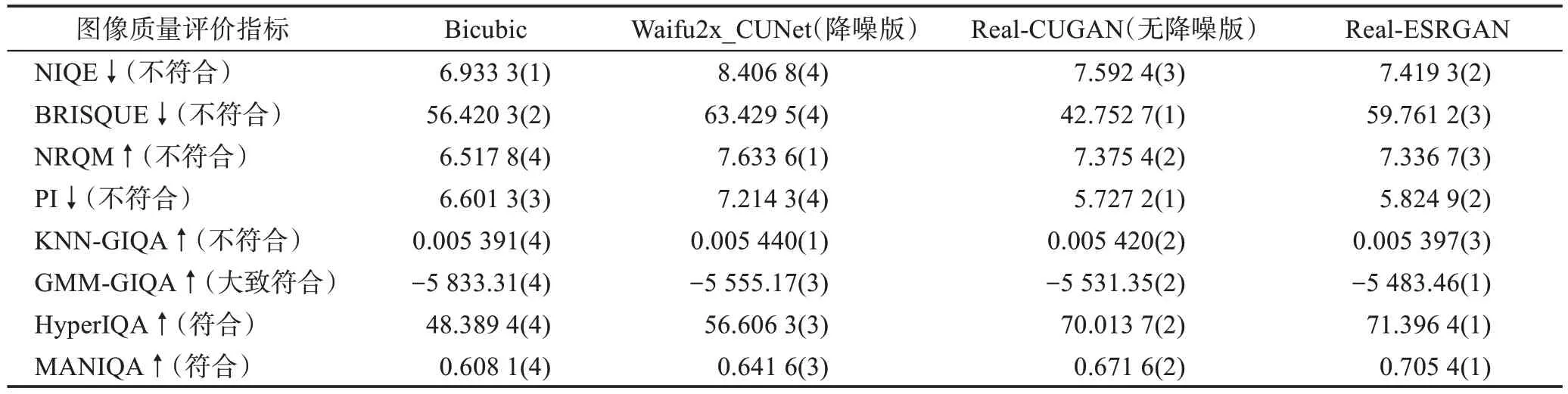
表4 低质量数据修复结果的各图像质量评价指标平均得分Table 4 Average score of image quality assessment methods for low-quality data restoration results
然而,从表5 中两个具体的单张图像结果可见,第一幅“民族服饰女孩”图片中Real-CUGAN(无降噪版)清晰且无明显伪影,Real-ESRGAN 在装饰处有伪影,因此对于这张图像,评价指标Real-CUGAN(无降噪版)的修复结果应该获得最高分。对于下面的动画群像图像,Real-ESRGAN 清晰且对人物面部处理最好,因此对于这张图像,评价指标应该是Real-ESRGAN的处理结果得分更高。然而,GMM-GIQA、HyperIQA、MANIQA 在Real-CUGAN(无降噪版)与Real-ESRGAN 结果有明显的优劣时,打分情况没有完全符合人类感知。

表5 单张图片修复结果在各图像质量评价指标下得分Table 5 Score of single image after restoration evaluated by image quality assessment methods
除了满足基本的视觉规律,本文也验证了评价指标对动画图片中的压缩与噪声的敏感度。从169张真实动画图片中筛选出了80 张有明显压缩、噪声的图片,使用Waifu2x_7Conv、Waifu2x_CUNet、Real-CUGAN 这三种网络的无降噪版与降噪版进行比较。在处理噪声和压缩图片方面,Waifu2x 两种网络的降噪版在噪声、压缩图片处理上均明显优于无降噪版;Real-CUGAN 的两种版本都能有效地降噪去压缩,只是降噪版的结果更趋于平滑。总体而言,Real-CUGAN 网络的结果比Waifu2x的两种网络的结果更加清晰。
因此,在评价各指标对噪声和压缩敏感度的时候需要明显区分Waifu2x 网络的降噪版和无降噪版。Real-CUGAN的降噪版和无降噪版的得分可以接近,但总体而言,Real-CUGAN 的结果应优于Waifu2x 的两种网络的结果。
如表6所示,NIQE、BRIEQUE、NRQM、PI无法区分噪声压缩图像与正常图像;KNN-GIQA 可以正确区分两种Waifu2x 网络的降噪版与非降噪版,但是Waifu2x 的两种网络与Real-CUGAN 的分数接近;GMM-IQA 大致符合,但Waifu2x_CUNet(降噪版)与Real-CUGAN 两种版本的得分较为接近;HyperIQA的打分完全符合;MANIQA 的评分与预期不符。具体单张图像结果可见于表7 和表8,MANIQA 对图片中的噪声敏感,给出了正确的评分,但对压缩不敏感,导致处理压缩图片失败的结果得到较高的分数。这可能与MANIQA的训练数据有关。

表6 压缩与噪声明显数据的各图像质量评价指标平均得分Table 6 Average score of image quality assessment methods for significant compression and noise data

表7 单张压缩图片修复结果在各图像质量评价指标下得分Table 7 Score of single compressed image after restoration evaluated by image quality assessment methods

表8 单张噪声图片修复结果在各图像质量评价指标下得分Table 8 Score of single noise image after restoration evaluated by image quality assessment methods
另外,本文还测试了目前表现最好的三种评价指标,即GMM-GIQA、HyperIQA、MANIQA来评估它们对于画面中特殊情况的准确性,例如虚化区域的保留程度和边缘问题的出现等。
如表9 所示,对于背景虚化图片,Real-ESRGAN过度锐化了虚化区域,导致产生伪影。然而,这三种评价指标仍将其评为最佳,这与视觉规律不符。当经过Real-ESRGAN 处理后,图片边缘出现白边时,HyperIQA 和MANIQA 仍将其选为最佳,也不符合视觉规律。

表9 修复图片特殊情况在各图像质量评价指标下得分Table 9 Score of special image case after restoration evaluated by image quality assessment methods
综上所述,目前传统的无监督图像质量评价方法不适用于动画图像。而利用深度学习网络的这三种评价指标,即GMM-GIQA、HyperIQA和MANIQA,对于动画图像的评价结果基本符合视觉规律。目前,MANIQA 对于图像中的压缩问题不敏感。这三种方法在背景虚化问题上失效,而HyperIQA 和MANIQA在过度锐化的边缘问题上的评价也失效。如果HyperIQA 和MANIQA 能够学习更多种类的退化动画图片,也许它们的表现会更好。
3.1.3 动画单图修复算法效率比较
本小节对上述基于Pytorch 框架[44]的深度学习网络的二倍超分辨率模型进行了算法效率的比较(其中Real-ESRGAN针对动画训练的权重是四倍超分辨率模型)。本文针对几个关键指标进行分析,分别是模型参数量、每秒浮点运算数(FLOPs)、激活次数(activation)、平均运行时间。
首先,比较了模型复杂度方面的指标。模型参数量是衡量模型大小的指标,它表示了模型中需要学习的参数的数量。每秒浮点运算数是衡量模型计算量的指标,它表示模型在每秒内执行的浮点运算的数量。这两个指标都对模型的效率和计算资源的需求有重要影响。其次,考虑了激活次数这一指标。激活次数表示模型中激活函数的执行次数,它直接关系到模型的计算速度和内存使用情况。最后,对平均运行时间进行了分析。平均运行时间是指在给定输入条件下,模型完成一次前向传播的平均时间。这个指标反映了模型的实时性能和计算效率。
表10 所示的所有关键指标结果均是使用256×256 的图片在Nvidia GeForce GTX TITAN X 上进行测试得到的。需要注意的是,网络参数量越大复杂度越高,则运行时间越长。其中Waifu2x_Swin仅有4层卷积层,每秒浮点运算数和激活次数较小,但它仍然需要处理大量的自注意力操作和窗口划分操作,反而增加了计算时间。而Waifu2x_CUNet 和Real-CUGAN 网络模型参数量相同,但用户可以设置不同的参数。此外,两个官方网络的代码实现细节、计算精度和编译器优化也存在差异。
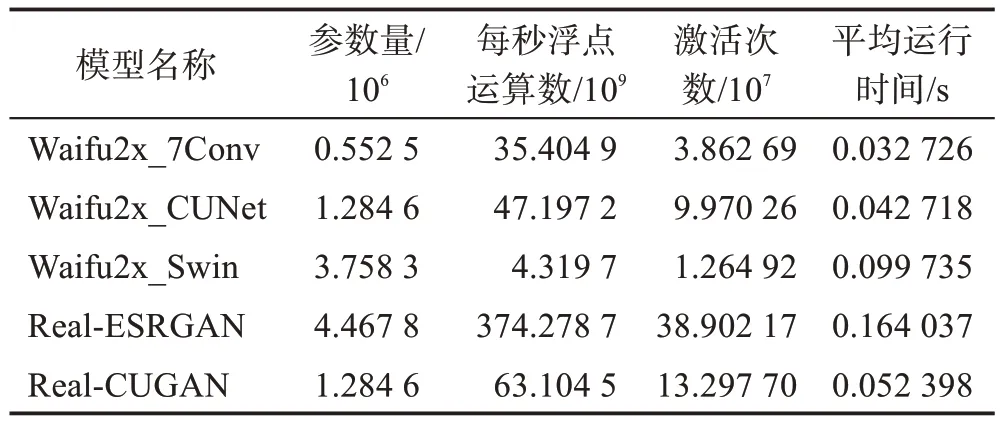
表10 动画单图修复算法效率比较Table 10 Comparison of effectiveness of single image animation restoration algorithms
通过对以上指标的比较和分析,可以评估模型的算法效率,并选择最适合实际应用场景的模型。同时,也可以根据这些指标来进一步优化模型,以提高算法效率并减少资源消耗。
3.2 动画视频画质修复测试结果
接下来对第2.1 节中提到的动画视频超分方法AnimeVideo-v3 与AnimeSR 进行了测试。测试数据选取了真实的低质量动画序列,包括一些AVCRealLQ 序列与网络下载的动画视频剪辑。为了评估它们的性能,使用了第3.1.2小节介绍的评价指标,即GMM-GIQA、HyperIQA和MANIQA。
由表11 可见,在“pig_13”画面中,动画的笔触明显,形变剧烈,并带有马赛克状色块断层。Anime-Video-v3 与AnimeSR 在平滑画面的同时,也导致了严重的涂抹感。马赛克断层现象得到了平滑,但尚未完全解决。总体上,AnimeSR 的处理结果在画面边缘清晰,色块平滑方面表现更好,相比之下,AnimeSR的结果更加锐利。

表11 pig_13部分片段处理结果Table 11 Restoration results of pig_13 sequence
由表12 可见,GMM-GIQA 在9 组动画序列中认为有5 组中AnimeSR 的表现更佳,而HyperIQA 和MANIQA则基本认为AnimeSR的结果更好。因为它采用了多尺度结构,增强了对画面内容的理解,并且输入了多帧图片,从而能够挖掘蕴藏在动画序列中的时序信息,更好地保证帧间的一致性。然而,目前的评价指标只能对单张图像的结果进行评估,无法评估视频帧间的一致性。
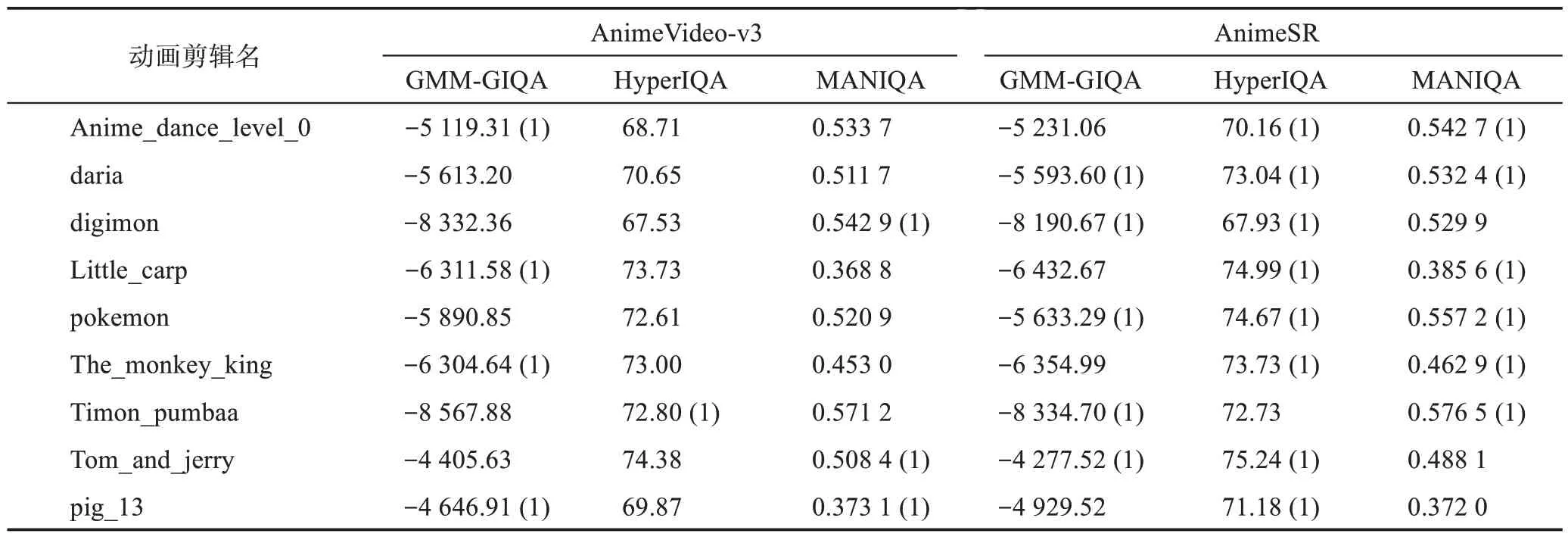
表12 视频超分算法结果的各图像质量评价指标平均得分Table 12 Average score of image quality assessment methods for restoration results of animation video algorithm
3.3 动画插帧算法测试
本文对第3.2 节中提到的动画插帧算法进行了测试,方法包括AnimeInterp[2]与Chen 方法[21]。测试数据选取了ATD-12K 中2 000 组测试集三联组。由于三联组的中间帧是插帧的真实值,评价指标可以选择全参考的峰值信噪比(peak signal-to-noise ratio,PSNR)、结构相似性指数(structural similarity,SSIM)[45]、学习感知图像切片相似度(learned perceptual image patch similarity,LPIPS)[46]。
从表13 中可以看出,针对三种评价指标,Chen方法表现更好。然而,目前的图像质量评价方法无法从时序角度分析插帧的合理性和一致性。

表13 ATD-12KTest插帧后平均得分Table 13 Average score of ATD-12KTest after interpolation
复杂运动与物体间遮挡是当前插帧算法的难点。此外,动画影像通常具有大面积平滑色块,缺乏纹理特征,并且经常出现非现实的夸张运动,使得动画插帧变得更加困难。AnimeInterp 与Chen 的插帧方法均依赖光流,在结构中使用了能进行光流预测的RAFT/RFR[47]模块。
如表14所示,当新物体突然在画面中出现时,如果前一帧没有像素点可以映射到新物体的区域,使用前向扭曲(forward warping)方法会导致空洞的产生。而使用后向扭曲(backward warping)方法时,新物体的部分区域在前一帧中没有可以映射到的位置,因此插帧效果差。反之,若原本画面中的物体在下一帧中被遮挡或消失,插帧效果也不理想,正如表14中的前两组示例所示。
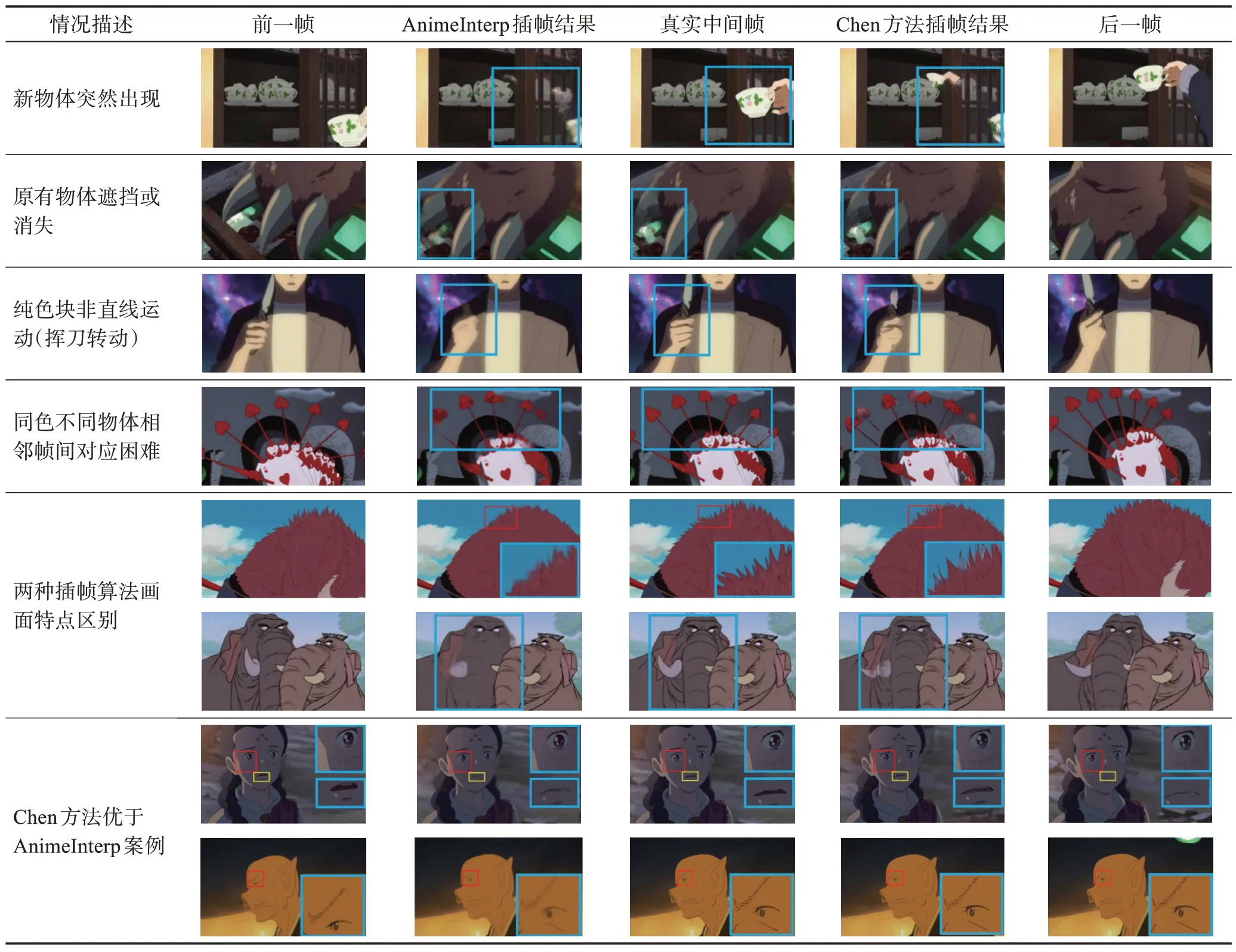
表14 插帧方法修复情况Table 14 Animation interpolation restoration results
对动画由大量纯色色块组成的特点进行分析,表14 第3 组示例中的挥刀转动属于纯色物体的非直线运动,该实例中“刀”由纯色组成,缺乏纹理特征,造成光流方向估计错误。同理,第4 组中的“红桃队列”具有相同颜色,但每个“红桃”均是独立的物体,它们在动画中的运动方向不同,插帧算法很难分辨出不同帧间每个“红桃”的对应关系,因此两种插帧方法在保证帧间一致性上表现不佳。
在AnimeInterp 与Chen 方法的对比中,发现AnimeInterp 的插帧结果边缘模糊,涂抹感强,插帧不佳的部分呈现模糊态。Chen 方法使用了含有边缘信息的欧几里德变换,因此边缘特征更明显,插帧不佳的部分呈现重影态而非模糊。由于Chen更重视边缘的做法更符合动画作品的特点,其插帧结果也常有优于AnimeIntrep 的表现。如表14 中最后两组示例所示,Chen插帧结果在对人物毛发、五官等细节部分边缘清晰,更接近真实中间帧结果,而AnimeInterp模糊不清。
综上所述,动画插帧面临的难点包括新物体进入画面与原有物体被遮挡或消失的情况。除此以外,大面积纯色缺乏纹理、不同物体相同颜色等动画特点也会增大光流估计的难度。AnimeInterp 插帧常会造成画面模糊,边缘不清;而Chen方法插帧常会造成重影,但边缘相比AnimeInterp结果更加清晰。
4 动画修复问题的瓶颈与方向
4.1 动画数据集
在画质修复方面,缺乏成对的真实动画数据。因此只能使用降质方法生成对应的低质量图像,或者利用画质修复方法得到高质量图像。然而,这种拟合的数据必须尽可能接近真实数据集的分布,这是收集动画画质相关数据时的难点。虽然Real-ESRGAN 与AnimeSR 均有自己的降质策略,但表11“pig_13”动画中的马赛克颜色断层问题仍未得到完全解决,因此需要找到更适合动画的降质策略。
在时序方面,二维动画数据缺乏矢量标记。在AnimeInterp 算法中,通过色块匹配的方式来弥补光流数据的缺失。Chen 方法注重线条的提取,取得了更好的效果。然而,当面临大面积纯色或不同物体具有相同颜色的情况时,这两种方法都可能由于光流预测错误而导致插帧失败。
AnimeRun 与AnimeCeleb 利用三维软件建模,模拟二维动画特征进行渲染,得到具有矢量标记的二维动画数据。但是三维软件建模的成本较高,模拟二维动画的光效较为单一,难以得到逼真的二维动画风格。因此,结合二维动画画面特征与三维软件辅助是动画矢量标记的重要方向。
4.2 动画画质修复相关方法
在单张动画图片画质修复方面,目前Real-CUGAN与Real-ESRGAN 的处理效果最优。然而,这两种方法并没有针对动画画面特点进行模型的改进。其中Real-CUGAN 对人物处理粗糙,细节不佳。Real-ESRGAN 过锐的特点会产生边缘线中空、白边和伪影,尤其在虚化的背景区域。两种方法对笔触和动画风格的保留均不足,涂抹感强。
要解决以上问题,今后的网络设计需要结合动画画面特点,更好地理解画面内容,从而更好地保留画面中的虚实关系、笔触与风格。在网络结构上可以加入对边缘特征的提取,通过在数据集上进行降质方法改进、蒙版处理、特殊情况筛选等步骤,来进一步保留画面原本风格。
多帧输入的AnimeSR 在表现上优于单张输入的AnimeVideo-v3,这提示了动画序列间的时序信息的重要性。AnimeSR 采用了多尺度的循环模块,增强了网络对画面内容的理解和对时序信息的利用,为未来模型的探索提供了参考。
4.3 动画插帧算法
AnimeInterp 和Chen 的插帧方法都没有利用具有矢量标注的数据集进行学习。除了视频插帧中常见的问题,如物体突然出现或原有物体遮挡消失,还存在纯色或相似色块光流估计不准的问题。例如,人物的两只眼睛通常具有相似的形状和颜色,如果在相邻帧之间无法正确对应眼睛,对画面的影响将非常明显。
而AnimeRun 则具有真实的矢量标注,尽管其模拟的二维动画与真实二维动画之间存在差距,但光流信息是准确的,并且同色但不同物体之间的帧间匹配也是准确的。因此,利用类似AnimeRun 这样使用三维软件制作的光流数据集参与动画插帧网络训练是一个方向。同时AnimeInterp 与Chen 方法对动画特征的利用也值得学习和借鉴。
4.4 评价指标
目前,传统的无参考图像质量评价方法,如NIQE、BRISQUE、NRQM 和PI,其设计初衷是针对自然图像,因此在动画评估中全部失效。然而,它们在自然图像中的特征提取方法可以提供借鉴的思路。在利用深度学习的无参考图像质量评价方法中,GIQA 使用大量真实的动画图像作为参考,通过筛选和收集这些真实图像可以提高GIQA 的效果。HyperIQA 和MANIQA 表现最佳,但它们偏向于过锐化的效果。建立一个动画质量评价数据集,并对HyperIQA 和MANIQA 进行重新训练,将使这两种方法在动画中更加适用。
对于全参考的图像质量评价方法,如PSNR、SSIM 和LPIPS,它们可以用于对单张图像进行评价,但在动画作品中,“观感”比“精确度”更为重要。与超分辨率或插帧后的图像与参考图像之间的误差相比,画面中线条、人物等细节的纹理对观感的影响更为明显。例如人物面部占画面的比例很小,但往往能最直观地体现修复效果的好坏。因此,在动画修复相关工作中,应更加注重观感和细节。除了单张画面的细节和画质外,动画中帧间的一致性也非常重要。色块匹配错误会导致边缘模糊、色块晕染和画面不流畅等问题。然而,目前尚缺乏用于评估帧间一致性的指标。
4.5 对工业界发展的展望
Topaz Labs 的成功商业化验证了深度学习方法在实际应用中的可行性。然而,利用用户本地资源进行计算需要对模型的复杂度进行限制。因此,工业界需要采用模型压缩技术,如剪枝、量化和分解等,以减少模型的存储需求和计算复杂度。同时,优化训练策略和数据集,提升网络的能力,使网络更高效。此外,网络设计需要尽可能地端到端,以优化用户的使用体验。
随着计算能力的提升和云计算的普及,实时动画修复技术和云服务将成为重要的发展方向。云服务能够提供高性能的计算资源,使动画修复工作能够利用更复杂的模型,从而获得更好的修复效果。
为了进一步提升用户体验,便捷的交互方式和多模态技术具有广阔的发展前景。用户可以通过文字或其他交互方法智能而优雅地修改和完善动画画面,从而进一步提升其质量和可操作性。
综上所述,工业界的发展方向包括使用更高效的网络模型为用户提供优质的效果,以及探索深度学习方法和云平台的结合,将科研界前沿的方法实际应用于工业领域。这将推动深度学习技术在动画修复领域的应用,并为用户提供更优质的服务体验。
5 结束语
目前动画的修复任务已取得一定的进展,但仍存在一些亟待解决的关键问题。本文展示了这些方法的实际效果,对关键问题与难点进行了总结归纳,并提出了一些潜在的研究方向。未来希望能够出现更多的动画相关数据集、修复算法以及评价指标。同时,这些方法需要应用到真实的动画场景中,例如动画相关的超分算法可以使过去的动画作品在2K、4K的屏幕上重现光彩。动画插帧算法可以极大地减少动画工作者的劳动时间。希望研究者能更加注重观感与实际,并进一步优化和改进动画相关修复工作。
猜你喜欢
黑龙江大学自然科学学报(2022年4期)2022-11-17
导航定位学报(2022年5期)2022-10-13
小哥白尼(趣味科学)(2021年12期)2021-03-16
小学科学(学生版)(2020年10期)2020-10-28
作文小学中年级(2020年6期)2020-07-24
文苑(2019年22期)2019-12-07
电光与控制(2018年10期)2018-10-13
学生天地(2016年9期)2016-05-17
中国铁道科学(2014年6期)2014-06-21
自然资源遥感(2014年3期)2014-02-27
