
自适应阈值约束的密度簇主干聚类算法
2023-12-08 11:48张锦宏
计算机与生活 2023年12期
张锦宏,陈 梅,张 弛
兰州交通大学 电子与信息工程学院,兰州 730070
如何自动化地分析、理解和总结数据是当前面临的一个主要问题,数据聚类分析是一种解决该问题的有效技术[1]。聚类分析是一种无监督机器学习方法,其根据数据点间的相似性将数据点划分到不同的簇中,从而识别出数据的内在模式并提取有用的知识[2]。然而,现有的部分聚类算法在处理多种类型的复杂数据集时存在聚类精度不理想的情况[3],因此,提出更优秀的聚类算法是非常必要的。
目前相关研究人员已经提出很多聚类算法[3],且被广泛应用于生物[4]、交通[5]、大数据[6]、电力[7]等领域。经典的基于划分的聚类算法包括k-means[8]和k-Medoids[9]等。该类算法的簇个数通常依赖于用户设定,簇的数量对聚类结果有决定性影响。此外划分聚类算法对非球状簇的识别效果较差。基于密度的经典聚类算法之一DBSCAN(density-based spatial clustering of application with noise)[10]通过高密度区域的连通性发现簇,利用低密度区域对高密度区域的隔断性标识不同的簇,对簇的形状和大小不敏感,但聚类质量随着簇内点密度变化剧烈程度的增加而降低,且算法阈值参数难以直接确定[11]。OPTICS(ordering points to identify the clustering structure)[12]是DBSCAN 的改进版本,该算法不显式地生成聚类结果,而是生成一个数据点的有序序列,通过调整邻域半径参数从而在该序列中得到相对应的聚类结果,但该算法对簇内数据点密度变化的敏感度依然较高。Chameleon[13]是层次聚类算法的典型代表,该算法通过动态考虑初始小簇间的相对互连性和相对近似性将小簇归并得到最终簇。尽管该算法可以识别任意形状的簇,但算法运行时间成本较高。基于网格的聚类方法也是一种有效的基本聚类方法,其中STING(statistical information grid)[14]将数据空间按层次顺序分割为不同分辨率的单元格,基于每个单元中的数据统计信息对单元格进行聚类。虽然网格化数据空间有助于提高算法执行速度,但其导致的数据空间分辨率下降在聚类任意密度数据集时会影响结果的精度。
上述现有聚类算法中存在难以识别多中心点任意簇、对簇内点密度变化敏感[15]及阈值取值难以确定等问题。近年来,为了应对检测任意形状、任意密度簇的聚类问题,学者们又提出了一些新颖的聚类算法。CFDP(clustering by fast search and find of density peaks)[16]结合了密度聚类和划分聚类的特点,基于密度和距离识别出每个簇的聚类中心,然后基于划分的方法完成非聚类中心点的分配,得到聚类结果。虽然该算法可以准确地识别出聚类中心点,但CFDP 认为每个聚类中心点仅代表一个簇,因此会分割多中心点的复杂簇,且非中心点的分配策略具有层次依赖性,若先分配的数据点出现错误会影响后续所有分配。SCC(sub-cluster component algorithm)[17]是可扩展的层次聚类算法,该算法使用一系列递增的距离阈值来确定在特定轮次中合并哪些子簇。该算法在不牺牲质量换取速度的前提下实现了很好的可伸缩性。MulSim(a novel similar-to-multiple-point clustering algorithm)[18]采用多点相似聚类策略,在综合考虑节点间以及节点与对方近邻间相似关系的情况下进行聚类,从而可以发现任意形状、大小和密度的簇。基于上述分析,可以看出基于密度进行聚类是识别任意簇的一种有效思路,因此本文将基于密度聚类算法进行进一步研究。
为了更精确地识别出复杂数据集中的任意分布簇,本文提出自适应阈值约束的密度簇主干聚类算法(density backbone clustering algorithm based on adaptive threshold,DCBAT)。根据密度可达阈值,DCBAT 算法首先将可达核心点识别为簇主干,接着将非聚类核心点分配到密度较大的最近邻所在簇中得到初始簇,最后根据密度差阈值对初始簇进行拆分得到最终簇。该算法考虑到数据点间的密度可达性往往与数据点的整体分布有关,因此基于数据分布自适应地计算密度可达阈值,克服了DBSCAN 等以密度可达思想进行聚类时密度阈值难以直接确定的问题。同时,复杂分布数据集中各簇的密度不均匀给聚类带来了一定的困难,但单个簇内由核心到边界方向的数据点密度由大到小的变化趋势是相对稳定的,因此该算法基于各簇内点的密度差值自适应地计算密度差阈值,根据簇内数据点间的密度差值与对应阈值的大小关系分割错误合并的初始簇,克服了任意密度影响聚类结果的问题,提高了算法识别精度,降低了异常点对结果的影响。该算法时间复杂度较低,在参数不变的情况下聚类结果唯一,具有稳定性,可以识别任意簇。
1 相关工作
传统的密度聚类算法虽然具备识别任意簇的能力,但依然存在阈值取值不好确定、对变密度簇敏感等问题[15]。
对于阈值取值问题,自适应DBSCAN 算法(selfadaptive density-based spatial clustering of applications with noise,SA-DBSCAN)[19]在DBSCAN 的基础上利用数据集的统计特性自动确定邻域半径Eps和邻域内对象数Minpts参数,避免了阈值取值的人工干预。自适应基于广度优先搜索邻居的聚类算法(selfadaptive broad first search neighbors,SA-BFSN)[20-21]改进了基于广度优先搜索邻居的聚类算法(broad first search neighbors,BFSN)中距离参数r和参数λ的确定方式,在Dk曲线上进行逆高斯分布拟合确定参数r,接着分析噪声点数量的分布特征选择合适的参数λ。自适应密度峰值聚类(adaptive density peak clustering,ADPC)[22]对CFDP 算法进行了改进,使用基尼系数对CFDP 的dc参数进行约束,从而实现自适应选择截断距离dc的目的。
对于变密度簇敏感问题,VDBSCAN(varied density based spatial clustering of applications with noise)[23]首先利用k-dist图识别密度层次,对每层选择一组邻域半径Eps和邻域内对象数Minpts参数,分别调用DBSCAN算法实现不同密度簇的聚类。基于边界点检测的变密度聚类算法(varied density clustering algorithm based on border point detection,VDCBD)[24]通过识别簇边界点发现簇核心结构,依据高密度近邻分配原则划分边界点到相应的簇核心结构中,以这种方式聚类变密度簇。融合网格划分与FDBSCAN 的改进聚类算法(fusion of grid partition and FDBSCAN clustering algorithm,G_FDBSCAN)[25]利用网格划分技术将数据集分为稀疏区域和密集区域并分而治之,合并相邻的密集区域形成子类,根据稀疏网格的邻居子类中是否存在核心点判断是否将稀疏网格识别为噪声,达到识别变密度簇的目的。
受上述工作启发,本文发现可以利用数据自身的统计特性和分布特征自适应地确定合适的阈值,同时可以利用簇内及簇间点密度变化特点克服变密度簇聚类问题。本文提出一种自适应阈值约束的密度簇主干聚类算法,它基于数据自身特点自适应地确定算法阈值识别簇主干,并利用簇内和簇间数据点密度变化的特征获取最终聚类结果。
2 相关定义与说明
定义1(k近邻)对于∀xi∈D,D中与xi距离最近的前k个数据点定义为xi的k近邻,记作Nk(xi)。
定义2(点的局部密度)对于∀xi∈D,点xi与其近邻点间的距离关系反映了xi的局部密度。点的局部密度与其近邻数量成正比,与邻居和该点之间的距离之和成反比。本文采用式(1)计算数据点的局部密度:
其中,ρi为点xi的局部密度,k为点xi的近邻数量,disij为点xi与其近邻xj之间的距离。
定义3(点的相对距离)对于∀xi∈D,其相对距离δi定义为点xi与点xj之间的距离,其中xj的局部密度大于xi的局部密度,且距离xi最近的数据点,称xj为xi的归属点。点xi的相对距离δi的计算公式如下:
特殊情况下,若点xi具有全局最大局部密度,则:
定义4(聚类核心点)潜在的聚类核心点应该具备局部密度较大和相对距离较大两个特征,定义为:
其中,Ω是聚类核心点集合。ρT是局部密度阈值,其取值为所有数据点密度的中位数。δT是相对距离阈值,其取值为所有数据点相对距离的上四分位数。
定义5(基于数据分布的数据点密度可达自适应阈值)一组数据的偏度系数表征着数据分布的偏态程度,且密度可达阈值与数据集中点的密度分布情况息息相关。基于偏度系数调整密度均值的数据点密度可达自适应阈值的计算公式如下:
其中,RT表示密度可达阈值,表示数据集D中点的密度均值,λ为D中数据点密度的偏度系数,λ的计算公式如下:
其中,Q3表示D中数据点密度的上四分位数,Q2表示数据点密度的中位数,Q1表示数据点密度的下四分位数。
定义6(数据点可达)对于∀xi,xj∈D,若存在一组数据点序列x1,x2,…,xm,…,xT∈D,其中x1=xi,xT=xj,该序列满足xm的局部密度ρm大于密度可达阈值RT且xm+1∈Nk(xm),则称xi到xj数据点可达。
定义7(基于密度分布的密度差自适应阈值)本文新定义密度差阈值的计算公式如下:
其中,ρm_T表示单个簇的密度差阈值;ρm_ave表示一个簇中所有密度差值的均值;μ为比例系数,用于放大密度差均值。
密度差值反映一个簇中数据点密度变化趋势的缓急程度,均值体现了一组数据的统计学特征,因此可以利用ρm_ave判断簇内密度差值的变化情况。为避免均值取值过小导致算法对密度变化过于敏感,将经比例系数μ适当放大后的密度差均值作为密度差阈值。用该阈值评判密度差值可以为是否拆分初始簇提供可靠的信息参考。
为了便于后文中描述算法,将本文中用到的定义符号整理如表1所示。

表1 DCBAT算法中常用符号定义Table 1 Definition of commonly used symbols in DCBAT algorithm
3 自适应阈值约束的密度簇主干聚类算法
3.1 算法思想
簇核心点具有较高的局部密度,且与其他簇核心点之间的距离相对较远。同一个簇中的核心点之间是密度可达的,且簇内高密度区域到低密度区域的数据点密度变化趋势相对平滑,跨簇时数据点密度会出现剧烈变化。本文立足于数据点的分布情况和簇内数据点的密度变化趋势提出DCBAT 算法,定义了基于数据点分布的密度可达自适应阈值作为核心点间的可达性度量,以簇内数据点密度变化趋势作为依据决定是否对簇进行拆分。
本文以Flame 数据集为例直观地展示算法聚类思想,如图1所示。第一阶段基于局部密度度量和相对距离度量准则,筛选出全部数据点中的聚类核心点,核心点分布如图1(b)所示。根据数据点密度可达自适应阈值检测核心点间的可达性,将聚类核心点划分为若干集合,每个集合代表一个初始簇的簇主干,图1(c)展示了簇主干。第二阶段将剩余数据点合并到其密度较大的最近邻所在簇中,得到初始簇,结果如图1(d)所示。第三阶段基于每个初始簇中数据点的密度差自适应阈值对初始簇进行拆分。图1(e)绘制了图1(d)中上方初始簇内数据点密度由高到低的变化趋势,可以看到数据点密度在红框处出现了骤降,断层处的两数据点密度差值远大于密度差阈值,因此断层上下的数据点应属于不同的簇。以断层处为界将上方初始簇拆分,得到最终簇结构,结果如图1(f)所示。对比聚类结果和图1(a)所示的数据集真实分布,DCBAT 可以准确识别Flame 中包括左上角两个异常点在内的每个点。
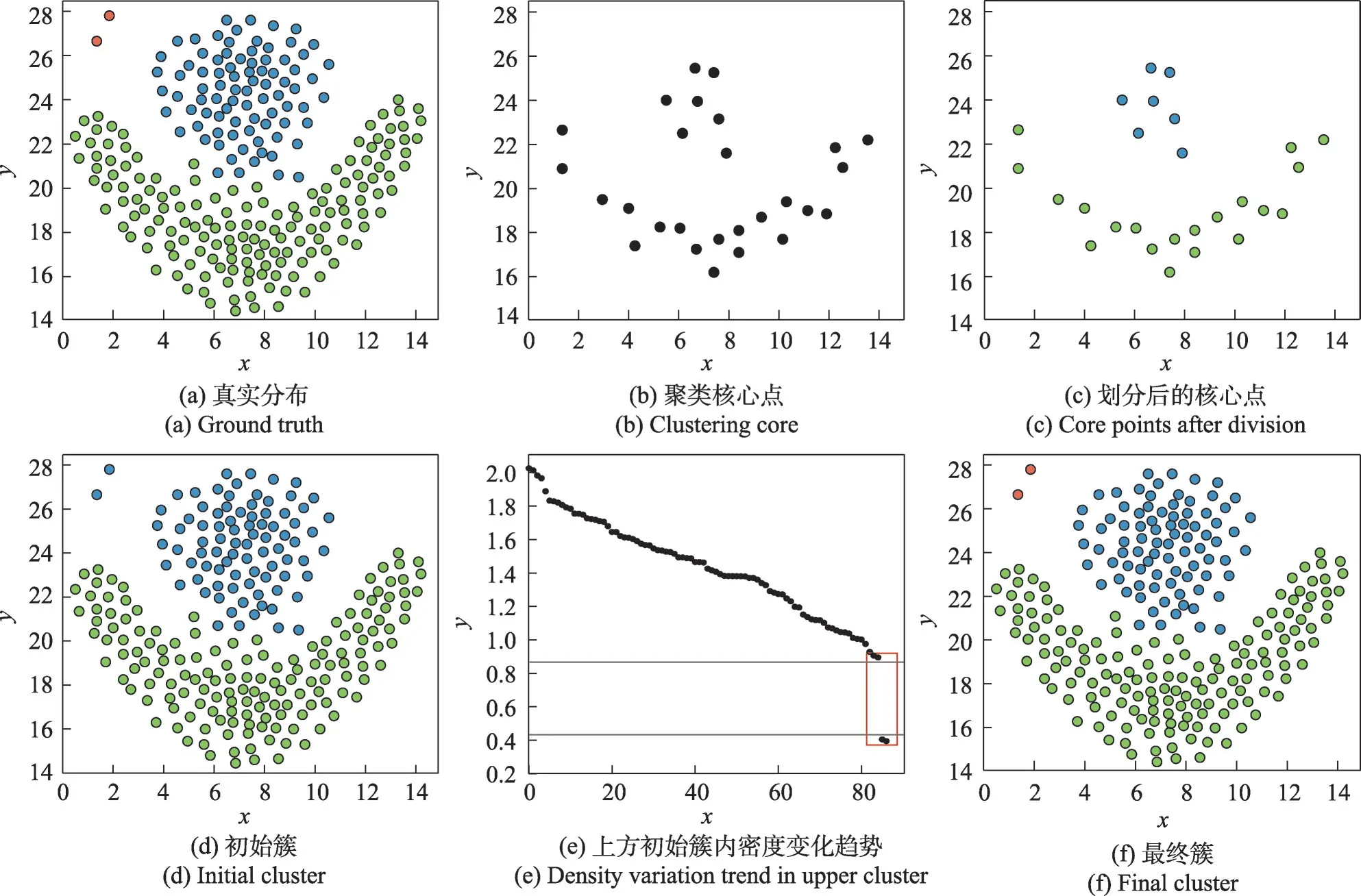
图1 DCBAT算法思想示例Fig.1 Example of DCBAT algorithm idea
DCBAT算法基于密度可达阈值正确判定了聚类核心点的所属簇,准确识别了非核心点分配策略中顶层数据点的所属簇,有效降低了该策略的层次依赖性对聚类结果的影响,提高了算法识别簇的容错率。DCBAT算法通过簇内数据点间的密度差值与对应阈值的大小关系判断初始簇划分的合理性,以大于阈值的密度差所对应的数据点为界将初始簇拆分,大大提高了最终簇的识别精度,同时还可以对异常点进行有效识别。
3.2 算法聚类过程
DCBAT 算法使用点的近邻数量k作为算法参数,通过3 个阶段完成簇识别。DCBAT 的总执行过程如算法1所示。
算法1DCBAT执行总过程
在算法1 中,第2~3 行计算每个点的局部密度和相对距离,第5 行根据定义4 筛选出潜在的聚类核心点,第7 行根据第6 行计算出的密度可达阈值RT判断这些核心点之间的可达性,形成初始簇主干;接着第8 行对非聚类核心点进行分配,得到初始簇结构;最后在第9~13 行检测初始簇的合理性,对错误合并的簇进行拆分,得到最终的簇结构。
3.2.1 获取簇主干
算法1.1 识别可达核心点,获取簇主干
本算法第一阶段如算法1.1所示。第2~3行首先使用式(1)基于每个点的k近邻计算点的局部密度ρi,所有ρi组成局部密度集合ρ。第4~12 行识别每个点的归属点。对于点xi,根据定义3 在其k近邻范围内寻找其归属点xj,得到xi的相对距离δi;若k近邻范围内不存在满足条件的点,则在全局范围内进行检索。所有δi构成相对距离集合δ,所有的归属点xj构成归属点集合B。第14行取ρ的中位数和δ的上四分位数分别作为局部密度度量阈值ρT和相对距离度量阈值δT,第15 行判断数据集中的每个点xi是否满足定义4的要求,若满足则将该点标记为聚类核心点,否则标记为非核心点。接着第16 行利用式(4)基于数据集中点的密度分布情况计算密度可达阈值RT。在第17~28 行中算法随机选择一个聚类核心点xi,根据定义6 找到xi的全部密度可达核心点,将xi与其密度可达的聚类核心点划分到一个簇中,生成一个初始簇的主干。然后随机选择一个未访问的聚类核心点重复上述过程,直到访问完全部聚类核心点,得到全部初始簇主干。
3.2.2 生成初始簇
算法1.2分配非核心点,生成初始簇
本算法第二阶段如算法1.2 所示。DCBAT 按密度降序依次遍历所有非核心点,将每个点归并到其归属点所在簇,得到初始簇结构。
3.2.3 拆分初始簇得到最终簇
算法1.3拆分初始簇,获取最终簇
本算法第三阶段如算法1.3 所示。为了判断初始簇的合理性,DCBAT 以单个初始簇为单位,在第6~7 行对每个簇中的点按密度降序排序,并计算降序序列中相邻两个点之间的密度差值。在8~12行中使用式(6)计算出的密度差阈值找到每个簇中密度差值的异常值。第13~14 行以异常值对应的数据点为界,将降序序列划分为若干个子序列,即将初始簇划分为若干新簇,得到最终的簇结构。
根据所得密度差阈值,簇内密度变化异常的初始簇在密度变化波动较大的位置被分割为若干个子簇,即最终簇。最终簇的簇内密度变化趋势平稳,且簇内数据点密度分布的均匀性与密度变化趋势相对独立,不会影响初始簇的分割过程。
3.3 时间复杂度分析
设数据集D的大小为n,近邻数量参数为k。
第一阶段采用k-d树[26]作为数据结构来获取每个数据点的k近邻,所需时间复杂度为O(n×lbn)。在k近邻的基础上计算每个点的局部密度ρi花费O(k×n)。计算每个点的相对距离并生成归属点集合B时需要遍历k近邻矩阵,时间复杂度为O(k×n);若k近邻中不存在密度较大的点,则需在全局范围内进行检索。对数据集D中的点按局部密度降序排序,这样检索时只需要遍历降序序列中该点之前的数据点即可,单个数据点检索的平均时间复杂度为O(0.5×n),实验中发现在k近邻中检索到密度较大点的概率超过90%,因此计算相对距离的总时间复杂度约为O(0.9×k×n+0.1×0.5×n)。筛选聚类核心点前要计算局部密度度量阈值ρT和相对距离度量阈值δT,需要对局部密度集合ρ和相对距离集合δ进行排序,所花费时间复杂度为O(2×n×lbn),接着遍历数据集D对每个数据点进行判断,时间复杂度为O(n)。最后确定核心点之间的可达性,在最差的情况下需要访问全部数据点,时间复杂度为O(n)。本阶段的总时间复杂度为O(n×lbn)。
第二阶段分配非核心点需要遍历全部数据点,阶段总时间复杂度为O(n)。
第三阶段需要遍历每个初始簇。首先需要将单个簇中的数据点按密度降序排序,然后计算每个簇中相邻两点之间的密度差值并找出差值中的异常值。总的排序时间复杂度为O(n×lbn);计算密度差花费时间O(n-cl),其中cl为初始簇的个数,且cl≪n;寻找异常密度差值时间复杂度为O(n)。本阶段的总时间复杂度为O(n×lbn)。
综上所述,算法的总时间复杂度为O(n×lbn)。
3.4 基于密度可达性判定核心点所属簇
对于单个簇而言,核心点构成的簇主干蕴含着簇的内部结构信息,因此准确识别簇主干可以保证聚类的准确性。簇内部区域的局部密度相对较高,而边缘区域和簇间区域的局部密度一般较低。构成簇主干的核心点一般位于远离簇边缘的内部区域,由于簇内部区域的密度高,同一簇中的核心点间具有更好的密度可达性;不同簇间存在低密度区域,导致不同簇中核心点间的密度可达性较差。综上,核心点间是否密度可达是判断其是否属于同一个簇的重要依据,密度可达的核心点同属于一个簇。算法第一阶段借助能够体现数据分布特点的偏度系数和体现数据统计特征的密度均值计算出合适的密度可达阈值,使用该阈值识别彼此之间密度可达的核心点,基于此可以有效地判断每个核心点的所属簇,为后续步骤打下良好基础。
3.5 基于簇主干发现簇
经典聚类算法如k-means 根据数据点与簇心之间的距离关系识别簇;DBSCAN 算法从单个数据点出发,基于密度可达性自底向上地发现整个簇;CFDP算法通过识别每个簇的聚类中心进而发现簇。以上经典算法聚类时仅考虑了单个数据点,缺乏对数据内部整体结构的考量。DCBAT充分考虑了数据的内部结构,通过识别簇主干完成聚类。簇主干是一个簇的骨架,体现了簇内数据点的分布特征,基于簇主干聚类不仅考虑了数据点间的关联关系,还考虑了数据的内部结构特征,利用数据点与簇主干间的关系去识别簇。点间联系与数据结构特征的综合考量保证了聚类结果的可靠性,有助于准确识别簇。
4 实验与结果分析
为了验证算法在任意形状、任意密度数据集上的性能,将本文提出的算法与5 种对比算法分别在8个数据集上进行测试。对比算法包括3 种经典算法和两种新算法。
4.1 实验数据集
本次实验共采用8 个数据集,其中包括5 个二维数据集(Aggregation、Compound、Spiral、Flame 和T4)和3 个多维数据集(Column_3C、Ecoli和Seeds),其中二维数据集和多维数据集分别获取自东芬兰大学(http://cs.joensuu.fi/sipu/datasets/)和UCI 网站(https://archive.ics.uci.edu/ml/datasets.php)。8 个数据集囊括了任意形状、任意密度、含噪声点、不同维度以及不同规模簇的数据分布情况。各数据集的详细信息如表2所示。
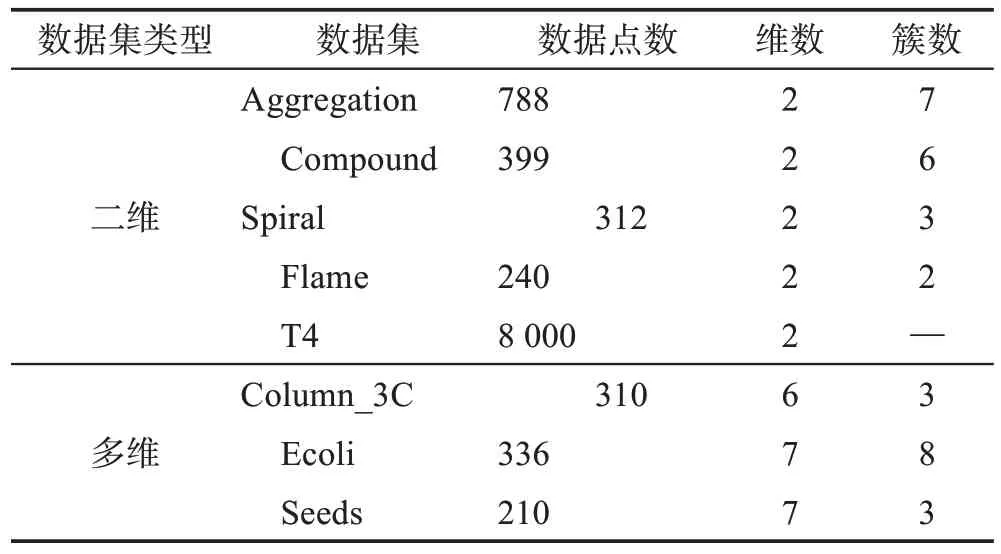
表2 数据集信息Table 2 Information of datasets
4.2 对比算法说明
为对比本文算法与现有算法之间的性能差异,本节使用5个算法与本文算法进行对比实验,其中包括3种经典算法(k-means、DBSCAN 和OPTICS)和两种新算法(CFDP 和MulSim)。其中k-means 是划分聚类算法的典型代表,DBSCAN和OPTICS是基于密度的聚类算法,CFDP 将基于密度与基于划分两种聚类算法思想相结合通过寻找聚类中心从而得到聚类结果,MulSim基于单点和多点间的相似原则识别簇。3种经典算法均来自Python 的“scikit-learn”库,其余算法代码均由其作者提供。
4.3 聚类评价指标
为了更直观地比较各算法间的性能差异,本文使用精度(accuracy,Acc)、调整兰德系数(adjusted Rand index,ARI)和归一化互信息(normalized mutual information,NMI)对算法的性能进行量化评价。
Acc 是数据集中正确划分的数据点数N1与数据点总数N的比值,其计算公式为:
NMI 是一个基于信息论的聚类结果评价标准,其计算公式为:
其中,I(Ω,C)表示聚类结果和数据真实分布的互信息,H(Ω)和H(C)分别表示聚类结果和数据真实分布的熵。
ARI是兰德系数的调整形式,其衡量的是两个数据分布的吻合程度,计算公式如下:
其中,RI表示兰德系数,E(RI)表示兰德系数的期望值。
3 个指标的取值越大说明聚类结果越接近数据的真实分布。对于二维数据集的实验结果还以散点图的形式进行了可视化展示。
4.4 DCBAT算法及对比算法的参数
引言部分已经介绍了对比算法,DCBAT 算法和各对比算法的具体参数如表3 所示。实验中各算法的参数取值通过多次实验寻优确定,各算法在不同数据集下的最优参数如表4所示。通过实验发现,本文算法的密度差自适应阈值中的比例系数μ取值为25左右时可以在各数据集得到较好的聚类结果。

表3 DCBAT算法及各对比算法参数Table 3 Parameters description of DCBAT and compared algorithms
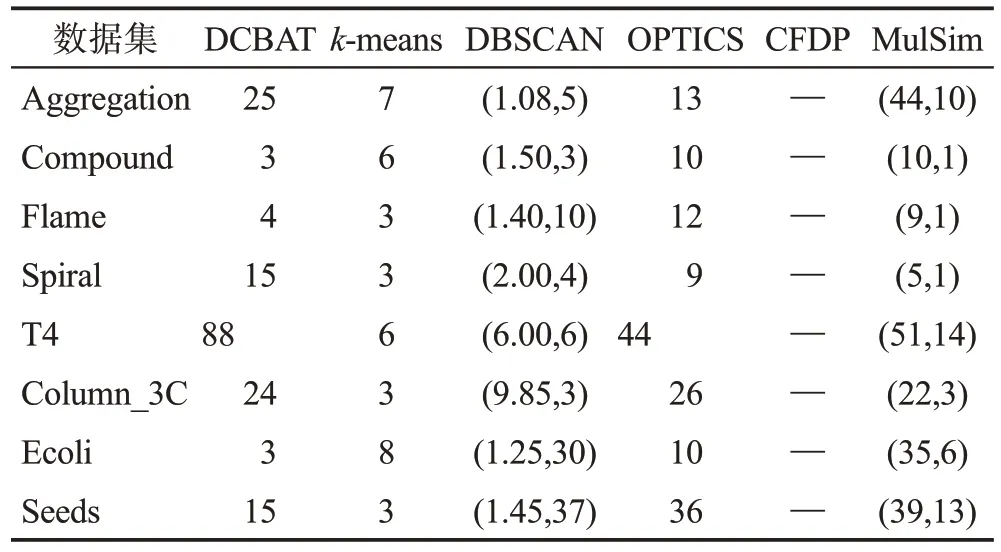
表4 DCBAT及对比算法在数据集上的参数取值Table 4 Parameter value of DCBAT and compared algorithms on datasets
4.5 实验结果及分析
4.5.1 二维数据集
图2~图6 分别展示了DCBAT 及对比算法在5 个二维数据集上的聚类结果,表5 统计了相应的Acc、ARI 和NMI,由于T4 数据集没有真实类标,表5 中无对应数据。
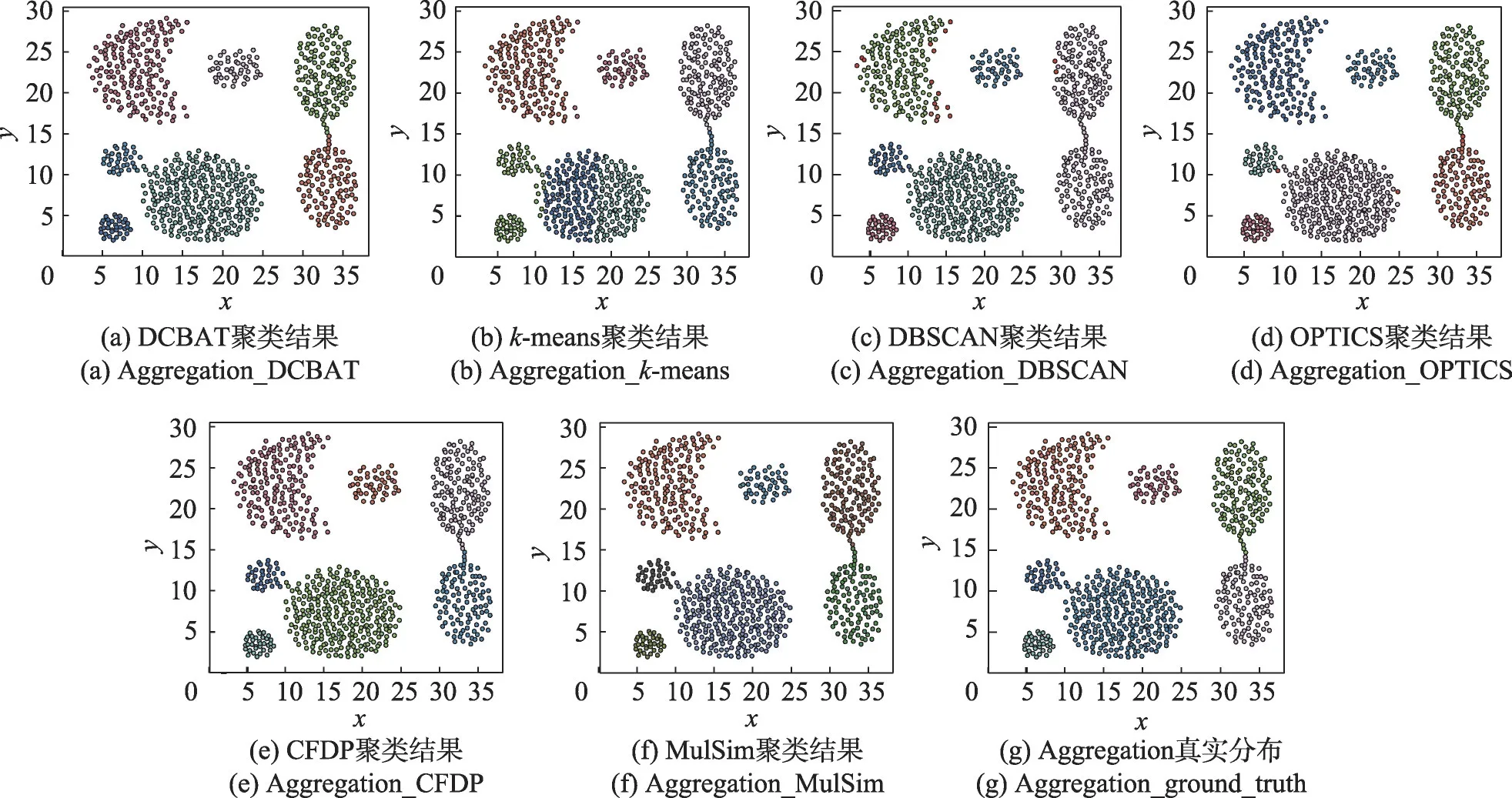
图2 DCBAT与对比算法在Aggregation数据集上的聚类结果Fig.2 Clustering results of DCBAT and compared algorithms on Aggregation dataset

表5 DCBAT及对比算法的聚类指标量化结果Table 5 Quantitative results of DCBAT and compared algorithms
(1)Aggregation数据集
Aggregation 数据集中包含典型的凸状簇,簇内密度均匀,每个簇的密度大小相对统一,但不同簇中包含的数据点数量差异较大,且存在通过若干数据点相连在一起的两对簇,这也是该数据集的聚类难点所在。图2展示了DCBAT 与对比算法在该数据集上的聚类结果,其中图2(g)为Aggregation 的真实簇分布情况,图2(a)~(f)分别为DCBAT 及对比算法在该数据集上的聚类结果。
通过图2 和表5 可以看出,DCBAT 仅错误识别一个点,取得了最佳的Acc、ARI 和NMI。本文算法基于合理的数据点密度可达阈值,通过判断数据点间的可达性对隶属于不同簇的核心点正确地进行了划分,在初始阶段就确定了每个簇的簇主干,避免了簇间连通部分对聚类结果的影响,解决了聚类难点。CFDP 的Acc、ARI 和NMI 与DCBAT 并列第一,MulSim 排名第二,二者除簇间连接区域外均可以准确地识别出数据点的所属簇。DBSCAN算法的Acc、ARI 和NMI 排名第四,由于其采用固定的数据点密度可达阈值,对左上角密度较小的簇边缘区域数据点未能正确识别,且受到簇间衔接部分的影响,没有划分开右侧的相连簇。OPTICS 算法在DBSCAN的基础上进行了优化,但仍不能准确识别簇边缘区域的部分数据点,其Acc、ARI 和NMI 排名第三。k-means 算法受到相距较近的两个簇的尺寸影响,错误地选取了簇心,导致未能识别出左下角的两个相连簇。
(2)Compound数据集
Compound 数据集中包含3 类簇,其中左上角的两个簇距离较近且具有不均匀的簇内密度;右侧两个簇拥有不同的簇内密度。左下角外圈的簇中不存在显著的簇中心点。数据集的聚类难点在于数据点分布情况错综复杂,同时存在多中心点簇和变密度簇。图3展示了DCBAT 与对比算法在该数据集上的聚类结果,其中图3(g)为Aggregation 的真实簇分布情况,图3(a)~(f)分别为DCBAT 及对比算法在该数据集上的聚类结果。
从图3和表5可以看出,DCBAT算法的Acc、ARI和NMI排名第一,对Compound数据集的识别最为准确,仅识别错误一个点,且基于初始簇内的密度变化趋势正确地分割了右侧的两个簇。MulSim算法聚类结果排名第二,其在识别右侧两个相邻簇的边界区域时遇到了困难。DBSCAN 和OPTICS 的聚类结果指标依次排名第三和第四,两个算法受限于固定的密度阈值参数,不能准确识别右侧不同密度的簇。由于算法思想的制约,CFDP 没能识别出左下角的多中心点簇。k-means对于右侧的不同密度簇和左下角的无清晰中心点簇的聚类效果较差。
(3)Spiral数据集
Spiral 数据集中包含3 个螺旋状的簇,每个簇内的数据点密度随着螺旋向外延伸而递减。图4 展示了DCBAT 与对比算法在该数据集上的聚类结果,其中图4(g)为Spiral的真实簇分布,图4(a)~(f)分别为DCBAT以及对比算法的聚类结果。
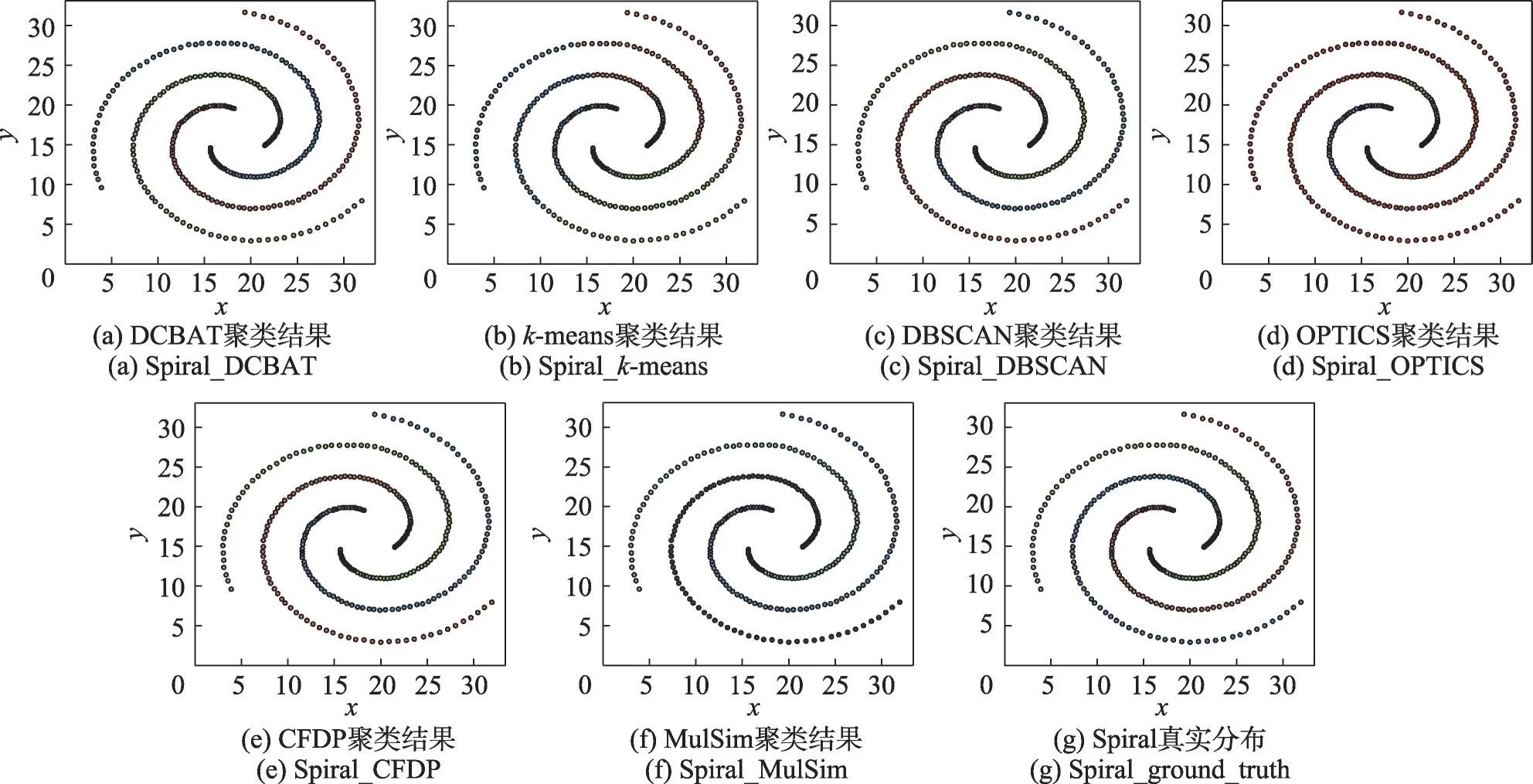
图4 DCBAT与对比算法在Spiral数据集上的聚类结果Fig.4 Clustering results of DCBAT and compared algorithms on Spiral dataset
从图4和表5可以看出,DCBAT、DBSCAN、CFDP和MulSim 算法获得了完美的划分结果,聚类指标均达到了1.000 0。k-means将数据集划分成了3个球状簇。OPTICS 未能正确识别螺旋尾部密度较小的数据点,将其划分为了异常点。
(4)Flame数据集
Flame 数据集中包含两个簇,两个簇中的数据点分布比较稀疏,且簇内密度与两簇相连区域处的密度差异较小。图5展示了DCBAT 与对比算法在该数据集上的聚类结果,其中图5(g)为Flame的真实簇分布情况,图5(a)~(f)分别为DCBAT 以及对比算法的聚类结果。
从图5和表5可以清晰地看出,DCBAT完美地识别出了真实的簇结构,取得了最好的聚类结果,其聚类指标达到了1.000 0。k-means 将数据集强行分为3个簇,未能识别左上角的两个异常点,还将下方的簇一分为二。由于上、下簇之间的数据点分布较为稀疏,且异常点距离簇较远,DBSCAN 和OPTICS 的聚类结果较为理想,只有簇相连处的部分数据点识别错误。CFDP 基于数据点的分配策略错误地将下方簇的右侧部分划分给了上方簇,导致聚类效果不佳。MulSim 的聚类结果与DBSCAN 的结果相似,效果也比较理想。
(5)T4数据集
T4 数据集中的数据不包含真实类标签,但数据集中包含异常点,且通过散点图可以容易地看出簇的数量、形状以及周围的异常点。T4 数据集中包含任意形状的簇。图6展示了DCBAT 与对比算法在该数据集上的聚类结果,图6(a)~(f)分别为DCBAT 以及对比算法的聚类结果。
很明显,DCBAT 和DBSCAN 都可以正确检测出簇结构,并且将周围的稀疏点判定为异常点,更能凸显簇结构。k-means 算法无法识别任意形状簇,因此未能识别出簇结构和异常点。CFDP 算法无法识别出异常点,且错误识别了部分簇。OPTICS 将所有数据点划分为两个簇。MulSim算法正确识别出了部分异常点,但由于右侧存在一条较为密集的数据点带连接两个簇,该算法错误地将两个簇进行了合并。
图2~图6以可视化的形式直观地展示了DCBAT和对比算法在二维数据集上的聚类结果。为了更清晰地量化对比DCBAT 与对比算法的性能差异,图7(a)~(c)绘制了二维数据集上3 种聚类评价指标的条形图。

图7 DCBAT与对比算法在二维数据集上的指标条形图Fig.7 Measurement bar diagram of DCBAT and compared algorithms on two-dimensional datasets
从图7可以看出,DCBAT算法在4个二维数据集上的聚类评价指标均高于对比算法,该算法不但能识别出正确的簇结构,且相较于对比算法具有最佳的聚类性能。
4.5.2 多维数据集
表5 中后半部分罗列了DCBAT 与各对比算法在多维数据集Column_3C、Ecoli和Seeds上的聚类结果评价指标,由于高维数据集无法以散点图的形式直观地展示聚类结果,采用聚类评价指标条形图的形式来展示和对比算法性能。
图8(a)~(c)所示为DCBAT及对比算法在3个多维数据集上的Acc、ARI和NMI指标的结果。从图中可以看到,DCBAT 算法的聚类结果评价指标整体高于对比算法,说明其具有较强的识别数据真实分布的能力。

图8 DCBAT与对比算法在多维数据集上的指标条形图Fig.8 Measurement bar diagram of DCBAT and compared algorithms on multi-dimensional datasets
最后,为对比算法的综合性能,将DCBAT 及对比算法在全部数据集上的聚类评价指标通过箱线图的形式进行展示,结果如图9 所示。在盒图中,每个盒体的上下边界表示对应数据的上下四分位数,盒体中的实线表示对应数据的中位数,自盒体延伸出的上下方的短线代表数据中的最大值和最小值,“×”表示异常值。通过图9 中的盒图可知,DCBAT 算法对应的盒图中各特征数据(中位数、上下四分位数和最值等)所处位置整体高于对比算法,盒体的高度整体低于对比算法,且不存在异常值,说明该算法的聚类评价指标取值较大且波动较小,算法聚类性能相较于对比算法更优。

图9 DCBAT及对比算法的评价指标盒图Fig.9 Measurement box diagram of DCBAT and compared algorithms
综上所述,DCBAT算法基于核心点可达的思想,利用簇内数据点密度变化趋势平稳的特点实现了任意簇的高效识别,算法整体具有鲁棒性。
4.6 变密度簇敏感性分析
变密度簇识别一直是聚类分析的难点所在,给识别数据分布带来了一定的阻碍。虽然变密度簇拥有非均匀的簇内密度,但簇内核心区域的局部密度总是相对较高,且簇内密度变化趋势相对稳定。本文算法使用高密度区域的核心点生成簇主干,核心区域的高密度特性和自适应的密度可达阈值使得簇主干的识别受簇密度变化的影响很小,降低了该过程对变密度簇的敏感性。簇主干可以体现一个簇的主体结构,有效地反映了簇的内部结构信息,其余的低密度点本质上都依托于簇主干来判定其归属簇,因此理论上本文算法对变密度簇不敏感。
为了验证本文算法对变密度簇的敏感性,本文在调整的Compound 数据集上进行了实验。针对数据集左上角的变密度簇(如图10(a)中红圈所示),本文以10%为步长,按80%~150%的比例缩放簇内数据点间的距离来模拟簇密度变化的情景,不同缩放比例下的聚类结果如图10 所示,聚类指标如表6 所示。可以看出,在多个比例的缩放下,本文算法均能有效识别簇,评价指标均高于0.95。当缩放比例达到140%及以上时,由于缩放比例过大导致变密度簇下方边缘区域的点距离整个簇过远,且更靠近左下方高密度簇,因此未能正确识别该区域的少部分点,但仍可以识别变密度簇中的大部分点。实验结果表明DCBAT 在调整后的Compound 数据集上的聚类性能良好,对变密度簇不敏感,可以保证聚类精度。
5 结束语
为了解决聚类中任意簇识别困难、对簇内密度变化敏感以及阈值确定困难等问题,本文提出了DCBAT 算法。DCBAT 将具备高局部密度和高相对距离且彼此相互可达的数据点识别为簇主干,并以此为基准划分剩余数据点得到初始簇,接着对初始簇进行拆分处理得到最终聚类结果。新定义的两种阈值基于数据分布计算得到,具有良好的自适应性。同时,利用簇内密度变化趋势来决定是否拆分初始簇,更好地考虑了数据的内部结构,有效降低了算法对变密度簇的敏感性,提高了聚类精度。为了验证DCBAT 算法的有效性,本文选择了五种先进算法在八个不同维度和各具特点的数据集上与本文算法进行了对比实验。结果表明DCBAT 算法相较于对比算法具有良好的性能,能更精确地识别任意簇,对异常点不敏感,算法结果稳定。在将来的研究中,拟基于簇内密度变化趋势进行纵向研究,提出更多高效的聚类算法。
猜你喜欢
军事文摘(2024年2期)2024-01-10
广东教育·高中(2022年1期)2022-03-16
数学年刊A辑(中文版)(2020年2期)2020-07-25
数学物理学报(2019年6期)2020-01-13
电子测试(2017年15期)2017-12-18
数学物理学报(2017年5期)2017-11-23
雷达学报(2017年6期)2017-03-26
新课程研究(2016年21期)2016-02-28
中国交通信息化(2015年2期)2015-06-05
电子设计工程(2015年6期)2015-02-27
