
烟叶总还原糖近红外光谱稳健模型的建立及其在多台仪器的长期应用
2023-11-29 01:43束茹欣吴圣超倪力军王文俊栾绍嵘张立国
分析测试学报 2023年11期
束茹欣,居 雷,吴圣超,倪力军,王文俊,栾绍嵘*,张立国
(1.上海烟草集团有限责任公司 卷烟烟气重点实验室,上海 201315;2.华东理工大学化学与分子工程学院,上海 200237)
近红外光谱(NIRS)技术作为一种绿色、无损、快速的检测方法,在各行各业得到了广泛应用[1],基于NIRS技术对产品进行质量检测的行业标准、国家标准也不断完善和推出[2]。该技术以样品的近红外光谱信号为自变量,样品待测组分的定量及定性性质为因变量,利用多元统计或化学计量学方法建立定量或定性的NIRS模型,应用模型对未知样品进行预测[3-4]。测试环境、样品形态、仪器的工作状态及样品采收期等因素均会对光谱质量产生影响,并可能导致模型在后续时段及其他仪器上应用时的预测误差增大[5-7],需要更新模型或采用传递方法使模型能适应新的仪器或样品[5,8-9]。而对于烟叶这类按年份或季节采收的农产品,通常期望建立的NIRS模型不仅能在不同仪器间直接共享,还能有较长的使用寿命。
研究表明[10-12],建立一个性能良好的NIRS模型未必需要所有的光谱信息。本课题组[11]前期基于图像处理的尺度不变特征变换(SIFT)算法,根据若干主机代表性样品的光谱信息筛选特征波长建立了烟叶总植物碱NIRS模型,该模型对主机及3台从机样品的预测误差均能满足企业内控要求。并进一步在SIFT 筛选波长的基础上,通过剔除光谱信号间相关性高的波长及信号不稳定波长,建立了黄芩苷的NIRS 模型[12],该模型直接传递到从机后的预测误差满足测定要求。Ni 等[13]的工作表明,基于SIFT 筛选的重要且独立性强的波长点建立的NIRS 模型,可直接传递到多台从机实现对从机玉米样品中蛋白质、油脂含量及烟叶总植物碱含量的准确预测。上述工作表明基于主机样品光谱,采用合适的多步波长筛选可建立稳健的近红外光谱模型,从而实现模型的无标样传递。
迄今有关NIRS 模型传递的报道多为模型在多台仪器上转移的研究,而NIRS 模型在同一仪器不同年份下的长期应用以及在不同仪器上的长期应用属于NIRS模型传递的更广泛的应用场景。这些场景在农产品NIRS模型的应用中十分常见,但关于这类场景的研究和应用探索尚不多见[6-7]。
本文以烟叶总还原糖(TRS)NIRS 光谱模型在多台仪器传递及在多台仪器的长期应用为背景,探究了基于SIFT的多步波长筛选方法实现该目标的可行性,以改进模型的传递性能及使用寿命,减少模型传递及维护的工作量。
1 实验部分
1.1 样品及光谱采集
本文采用3 个烟叶样本集建立模型并进行验证。样本集 A 为2011~2013 年间采收的292 个烟叶样本,在傅里叶变换近红外光谱仪A2(Thermo Fisher 公司,型号:ANTARIS Ⅱ NIR)上采集其光谱信息;样本集 B由2011~2013年另外收集的77个烟叶样本构成,分别在主机及6台代号为C1、C2、J、N、P2和S 的从机(Thermo Fisher 公司,型号:ANTARIS Ⅱ NIR)上采集其光谱,用以检验模型的预测和传递性能。样本集C 由2014~2020 年积累的180 个按采收年份分成7 个组别的烟叶样本组成,分别在主机A2及上述6台从机上采集其光谱,用以检验模型在多台仪器的长期使用寿命。
所有烟叶样品粉碎后,过40~60 目筛。置于可旋转石英杯中,在(22±4) ℃、30%~80%湿度下采集其光谱:分辨率为8 cm-1,波长范围为10 000~4 000 cm-1,扫描64 次,增益取2。各样品的TRS 含量采用连续流动法[14]测定。3个样本集中TRS的分布范围、均值及方差等信息如表1所示。
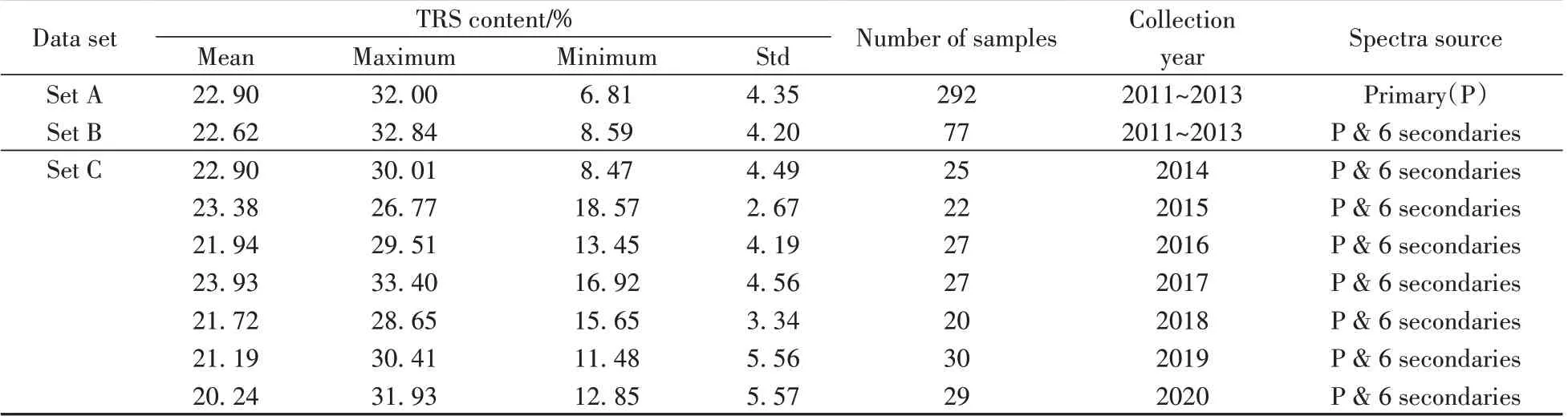
表1 烟叶样本集A、B及C中总还原糖含量信息Table 1 The information of TRS in tobacco samples of Set A,Set B and Set C
Set A中2011~2013年的292个烟叶样品在主机A2上的近红外光谱如图1A所示,Set B中2011~2013年的77个样品在主机A2及各从机上所测光谱的平均谱图如图1B所示。其中,Set A中的样本用于波长筛选、建立和验证烟叶总还原糖的NIRS 模型,Set B 中的样本用于验证模型的传递性能,Set C 用于检验模型在后续年度下在多台仪器上的长期应用性能。
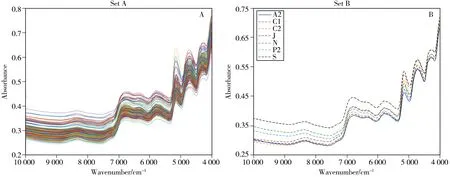
图1 主机(A2)上采集的Set A中2011~2013年292个烟叶样品的原始光谱(A)和Set B中77个样本在7台仪器上的平均红外光谱(B)Fig.1 Spectra of the 292 samples in Set A collected in 2011-2013 tested on the primary(A2)(A) and average spectra of the 77 samples in Set B tested on the primary spectrometer(A2) and six secondary spectrometers(C1,C2,J,N,P2 and S)(B)
1.2 研究思路
从图像分析角度而言,SIFT 算法[15-16]所筛选的特征波长集合Uc中各波长下的光谱信号与其相邻信号存在明显区别,被视为具有高度区分特征的波长点。SIFT 算法用于光谱特征点抽提及其参数的优化在文献[11-12]中已有介绍,本文不再赘述。
SIFT 算法中采用2~10 个代表性主机样品光谱即可满足特征波长筛选的需要,故本文首先采用SPXY(Sample portioning method based on X and Y)方法[17]从Set A 中筛选10 个代表性样品,根据这10 个样品的光谱筛选特征波长集合Uc。考虑到SIFT算法的端部效应,需要结合其他波长筛选方法剔除冗余的、信息量少且不稳定的波长点。众所周知,不同样品在同一波长下的光谱响应不同且这些光谱响应的差异程度随波长的不同而改变。若不同样品在某一波长下的光谱响应差异很大,那么该波长对于建立一个好的NIRS 模型非常重要;反之,如果各样品在某波长下光谱响应的变化很小,则建立NIRS 模型时可以不必采用该波长的光谱信息。
基于上述考量,本课题组基于样品光谱标准方差(SDSS)的大小来剔除Uc中信息量少、冗余的波长[13],SDSS的计算公式如下:
其中,Mij是第i个样本在波长j下的光谱响应值,m是Set A 中的样本个数,是第j个波长下各样本光谱响应的均值。SDSS(j)越大,则波长j下各样品光谱响应的差异越大。由此可见,高SDSS值的光谱点可以很好地体现不同样品间的光谱差异,是多元统计模型中的重要变量。
因此,本文在第二步波长筛选时,将SDSS值小于某一阈值b的波长从Uc中剔除,得到重要特征波长集合Uic,该法简称为SIFT-SDSS。众所周知,水分及湿度对样品近红外光谱的稳定性有很大影响,即使样品的待测组分浓度相同,水分含量不同也将导致近红外光谱形状的改变[18],如Gaines 与Windham 发现小麦的漫反射吸光度全光谱会随着水分含量的增大而增大[19-21]。为提高所筛选波长下光谱响应的稳定性,本文在SIFT-SDSS 筛选的重要特征波长集合Uic的基础上进一步去除水分吸收系数大于8 000 的波段(分别位于4 000~4 058 cm-1与5 012~5 278 cm-1)[22],挑选出重要、稳定的特征波长集合Uisc,该波长筛选方法简称为SIFT-SDSS-MUS(moisture-unsensitive)。
分别基于Uc、Uic、Uisc与全波长光谱信息,选取Set A 中部分代表性样本作为建模集,其余样本作为验证集,建立烟叶总还原糖的偏最小二乘(PLS)校正模型M-SIFT、M-SIFT-SDSS、M-SIFT-SDSSMUS与M-WW。采用Set B、Set C对各模型传递性能及长期应用性能进行检验。
1.3 烟叶总还原糖NIRS模型的建立与评价
根据课题组前期研究结果[23],采用一阶导数与二次多项式S-G 卷积平滑(光滑点数为9~15)对烟叶近红外光谱数据进行预处理时,烟叶总植物碱NIRS模型的传递性能优于采用其他预处理光谱所建的模型。故本文采用该方法对光谱进行预处理,光滑点数取15。在Set A 中的292个样本中按照浓度区间挑选80%的样本(234 个)作为校正集,剩余20%样品(58 个)作为内部验证集,以保障建模集和验证集样品个数沿浓度的分布相似。采用偏最小二乘回归(PLSR)方法建立烟叶总还原糖的NIRS 模型。预测均方根误差(RMSEP)及交叉验证均方根误差(RMSECV)通常用来评估近红外光谱模型的预测性能。但是,均方根误差的水平会随样本数据而改变,其阈值很难确定。烟草企业通常以NIRS模型预测值与实测值相对误差绝对值的平均值(MARE)是否小于6%来判断模型预测结果的准确度,当MARE小于6%时,则认为该模型可以接受。MARE的计算公式如下:
式中,m表示样品数,yi,actual和yi,predicted分别表示第i个样品的实际含量和预测含量。本文根据MARE小于6%的内控要求来评价烟叶总还原糖NIRS模型的传递及长期应用效果。
PLSR算法中的潜变量个数(nLVs)对模型结果有重要影响,通常采用留一交叉验证确定。但本课题组在研究黄芩、玉米与烟叶中主要成分NIRS 模型传递过程中[12-13,22]发现,采用留一交叉验证确定的nLVs个数偏大,易造成过拟合,导致模型传递性能变差。根据前若干个潜变量累积贡献率大于或等于99.9%或者验证集预测误差最小确定nLVs时,模型的稳健性及传递性能较好。故本文采用主机内部验证集样品的均方根残差(RMSEV)最小来确定nLVs。
本文所有算法在Matlab2020a上完成。
2 结果与讨论
2.1 烟叶光谱中重要且稳定特征波长的筛选
SIFT算法所筛选的光谱点与算法中的参数O(组数)、S(层数)及初始高斯变换参数σ0密切相关。文献[11-13]的研究表明,初始高斯变换参数σ0对筛选结果的影响最大,而O、S则无显著性影响,建议S取值4~5,O取值3~5。本文参照课题组对烟叶总植物碱NIRS 模型的研究结果,选定SIFT 算法筛选烟叶特征波长点的参数O=S=5,σ0=3.0[13]。
基于“1.2”所述波长筛选流程及上述SIFT参数,本文在1.0×10-4~1.5×10-4范围、间隔1.0×10-4选取不同的SDSS 阈值b,可得到不同的重要且稳定特征波长集Uisc,基于各Uisc所建立的M-SIFT-SDSS-MUS 模型在不同nLVs 下的主机验证集的RMSEV如图2所示。
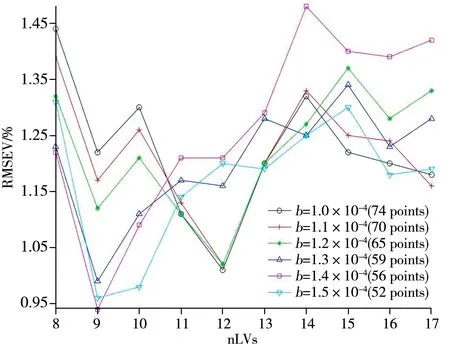
图2 不同阈值b下模型M-SIFT-SDSS-MUS的RMSEV随nLVs的变化Fig.2 The RMSEV predicted by different PLS models,which were built on Uisc obtained at different threshold of b along with nLVs
由图2 可知,b=1.4×10-4时,基于波长集合Uisc所建的TRS模型在nLVs为9时,RMSEV最小。故SDSS 的阈值b设为1.4×10-4,此时Uisc中有56个波长,该阈值下SIFT-SDSS 方法所筛选的波长集合Uic中有72个波长。
由图3可知,SIFT 所选的367个特征波长(以○表示)中很多位于10 000~7 200 cm-1区间,而6 800~5 300 cm-1、10 000~7 200 cm-1区间的SDSS 小于阈值1.4×10-4,说明这两个区间的光谱信号波动非常小、其对NIRS 模型的影响可以忽略不计。SIFT-SDSS 方法剔除这些波长后得到的重要特征波长集合Uic有72 个点(用▲表示)。使用SIFT-SDSS-MUS 方法进一步从Uic中去除区间4 058~4 000 cm-1与 5 278~5 012 cm-1的水吸收系数大于8 000 的波长,最终获得位于4 800~4 066 cm-1、7 200~6 800 cm-1及5 300~5 278 cm-1区间的56个重要、稳定的烟叶近红外光谱特征波长点(用*表示)。
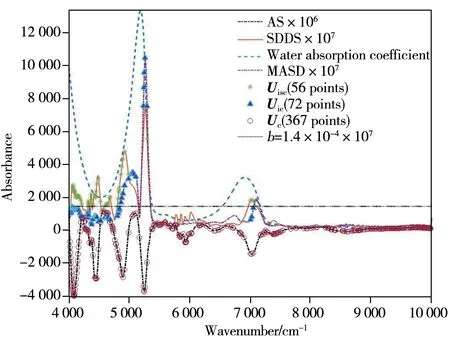
图3 校正集样品的平均光谱(AS)、样本标准方差谱(SDSS)和水的吸收系数谱、主机与从机样品光谱绝对值差谱的平均谱(MASD)以及Uisc、Uic、Uc三个波长集合点Fig.3 Average spectrum(AS) and standard deviation of samples spectra(SDSS) of calibration samples,absorption coefficient spectrum of water,mean absolute difference spectrum(MASD) between primary and secondary spectra,and the wavelengths of Uisc,Uic,Uc
2.2 烟叶总还原糖NIRS 定量模型预测2011~2013年样品的结果
表2 给出了基于不同波长集合所建各烟叶总还原糖NIRS 模型在不同仪器上测得的Set B 中77个样品光谱预测TRS 的MARE。由表可知,全波长模型M-WW 和M-SIFT-SDSS-MUS 直接预测C1、C2、N、J、P2 5 台从机样品TRS 含量的MARE 均小于6%,仅对从机S 上样品TRS 的预测误差(分别为10.46%与6.07%)不满足企业内控要求;而M-SIFT模型预测两台从机(C1、N)TRS的MARE大于6%,只有M-SIFT-SDSS模型直接传递到6台从机的MARE 均小于6%,且其在7 台仪器上的MARE 均值最小(4.02%),M-WW、M-SIFT 与M-SIFTSDSS-MUS 预测7 台仪器测试样品TRS 的MARE 均值分别为5.06%、4.56%与4.26%。总体而言,当各模型预测与建模集样品同一时间段采集的Set B 中的77个样品时,M-SIFT-SDSS 的传递性能最佳,MSIFT-SDSS-MUS次之,M-SIFT最差。

表2 不同模型预测Set B中77个样品的MARE(%)Table 2 MARE(%) of TRS content in the 77 tobacco samples of Set B predicted by different models
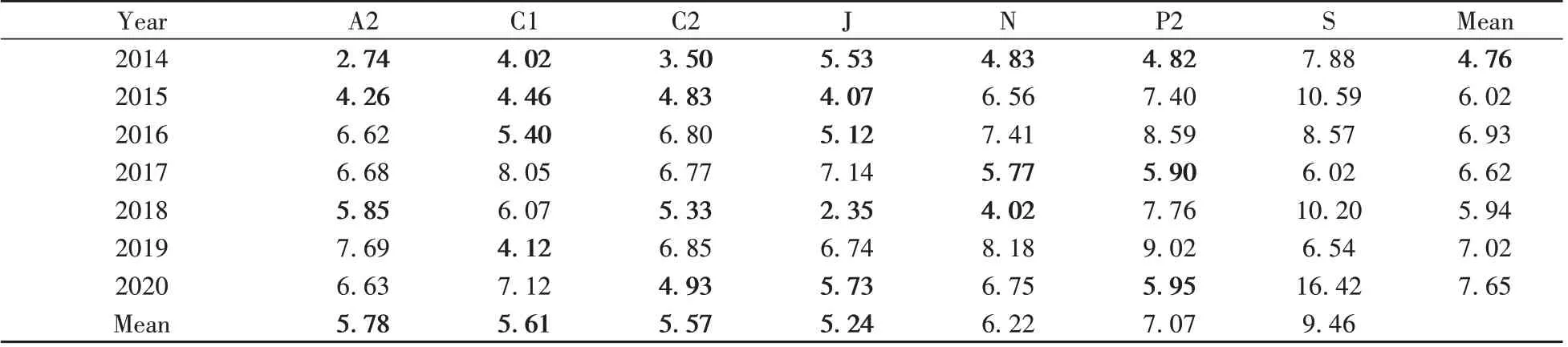
表3 全波长模型(M-WW)预测Set C中各年度样品中总还原糖的MARE(%)Table 3 MARE(%) of TRS content in the samples of Set C predicted by the M-WW model according to the sample collection year

表4 M-SIFT模型预测Set C中各年度样品中总还原糖的MARE(%)Table 4 MARE(%)of TRS content in the samples of Set C predicted by the M-SIFT model according to the sample collection year

表5 M-SIFT-SDSS模型预测Set C中各年度样品中总还原糖的MARE(%)Table 5 MARE(%)of TRS content in the samples of Set C predicted by the M-SIFT-SDSS model according to the sample collection year
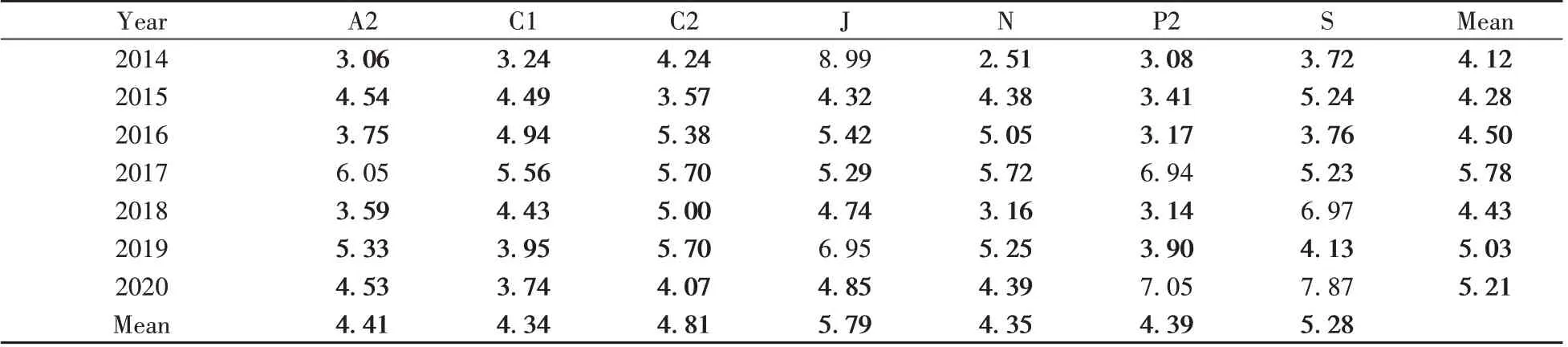
表6 M-SIFT-SDSS-MUS模型预测Set C中各年度样品中总还原糖的MARE(%)Table 6 MARE(%)of TRS content in the samples of Set C predicted by the M-SIFT-SDSS-MUS model according to the sample collection year
2.3 烟叶总还原糖NIRS定量模型预测2014~2020年Set C样品的结果
表3~表6 分别给出了各模型根据2014~2020 年间样品在7 台仪器上测定的近红外光谱所预测TRS含量的MARE以及按照仪器、年度得到的各MARE的均值。下面分几个方面对结果进行讨论。
2.3.1 烟叶总还原糖NIRS 定量模型在7台仪器长期应用能力的考察由表3可知,根据NIRS模型预测TRS 的MARE 应小于6%的企业内控标准,全波长M-WW 模型在C1 和J 仪器上可以应用到2016 年;在A2、C2仪器可以应用到2015年;而在N、P2仪器该模型2015年就必须更新维护。M-WW 预测仪器S 上各年份样品TRS 的MARE 为6.02%~16.42%,均大于6%。因此,对于在2014~2020 年间分年度收集的Set C中的样品而言,其样品采收期和测试时间不同于建模集样品,M-WW 在7台仪器上多年份应用的性能不佳,远不及表2中该模型对Set B中2011~2013年样品的预测性能。
由表4 可知,M-SIFT 模型在仪器S、N、C1、A2、P2、C2 上的使用寿命分别为7 年(2014~2020)、5 年(2014~2018)、3 年(2014~2016)、2 年(2014~2015)、2 年(2014~2015)和1 年(2014 年),模型在仪器J 上的长期应用性能最差:对2014 年J 仪器测试样品TRS 的预测MARE 为8.93%、超过了6%。总体而言,M-SIFT 模型在7 台仪器上的长期应用性能优于M-WW 模型,表明基于SIFT 算法筛选特征波长点建立的模型较全波长模型更稳健。
表5中,仅J仪器2014年样品及P2仪器2020年样品的MARE 大于6%(分别为7.43%和6.79%),其余MARE 均小于6%。说明M-SIFT-SDSS 模型在A2、C1、C2、N 和S 5 台仪器上可以从2014 应用到2020 年,在P2 仪器可从2014 应用到2019 年。该模型在7 台仪器的长期应用性能大大优于M-SIFT 模型。表明在SIFT算法筛选的特征波长基础上进一步挑选可良好区分样品差异的重要波长点集合Uis,所建立的M-SIFT-SDSS模型的稳健性及长期应用能力较M-SIFT模型有明显改进。
表6 结果表明,M-SIFT-SDSS-MUS 模型可在C1、C2 与N 仪器上应用7 年(2014~2020)、在仪器S上应用4 年(2014~2017)、仪器A2 及P2 应用3 年(2014~2016),而在仪器J 上应用时,2014 年就必须更新模型。该模型在7台仪器上的长期应用能力不及M-SIDT-SDSS模型,但优于M-SIFT和M-WW 模型。结合表2 结果可知,在Uic重要特征波长集合基础上,剔除对水分敏感的波长点,并不能改进烟叶总还原糖近红外光谱模型M-SIFT-SDSS 的传递性能及其在多台仪器的长期应用性能。造成这一结果的可能原因是,总还原糖中含有多个羟基,其在近红外光谱区的特征吸收与水的强吸收区域重合度较高,剔除这些波长点反而会降低TRS 模型的准确度,并削弱模型的传递性能和长期应用能力。一般在一个模型的预测性能及传递性能优良的情况下,进一步的波长筛选或者是采用标样校正从机预测结果(光谱),得到的结果往往不如原模型。
2.3.2 验证集样本数及分布对烟叶总还原糖NIRS 定量模型预测结果的影响若不按年度区分,以Set C 中2014~2020 年所有180 个样本为验证集,则表3~表6 的最后一行Mean 即为各模型根据这180 个样本在不同仪器上测试的光谱所预测TRS 的MARE。由表3 可知,应用全波长模型M-WW 预测这180个样品TRS 时,A2、C1、C2 和J 4 台仪器上的MARE(即Mean)值均小于6%,这意味着不区分2014~2020 年间180 个样本的采收年份而将其视为整体时,采用2011~2013 年样品建立的全波长TRS 模型可在主机及C1、C2 和J 3 台从机上应用,但仪器N、P2 和S 应用该模型预测Set C 中180 个样品TRS 含量的MARE在6.22%~9.46%之间,不满足企业内控要求。
由表4最后一行可知,M-SIFT 模型除在A2和J仪器上预测180个样品中TRS含量的MARE 大于6%外,在其他5 台仪器的MARE 均小于6%。表5 和表6 的最后一行表明,7 台仪器应用M-SIFT-SDSS 和M-SIFT-SDSS-MUS 两个模型预测Set C 中不按年度划分的180 个样品的TRS 含量时,各仪器的MARE均小于6%。
经考察建模集、Set B、Set C 样品数目随浓度区间的分布,发现建模集样品、Set B 的77 个样品及不按年度划分时Set C 中所有180个样品的分布图接近正态分布,这3个图非常相似。而Set C 中各年度样品数目在20~30 之间,每个年度样品随浓度区间的分布与建模集差异很大。从统计学角度而言,对于20~30范围的样本空间,如果有个别样本的相对误差绝对值较大,会导致MARE显著增大。而在77~180 个样本中有若干相对误差大的样本出现时,这一风险会小很多。由此不难理解为何表3、表4 中,M-WW 和M-SIFT 模型预测各仪器多年份样品的TRS 误差均很大,但模型用于总体预测180 个样品时,在多台仪器的MARE 均小于6%。故增加2014~2020 各年度烟叶样品数目并使各年度样品数随TRS 浓度分布图与建模集尽可能相似,有望降低各模型预测2014~2020 年各年度样品TRS 的误差,提高模型在多台仪器上长期应用的能力。
3 结 论
本文采用多步波长筛选方法,综合光谱特征、对样本的区分度以及对水分的敏感度等因素进行建模,发现基于从若干代表性主机样品光谱中挑选重要(或重要且稳定)特征波长的两步与三步波长筛选方法所建的M-SIFT-SDSS 及M-SIFT-SDSS-MUS 模型的传递能力及服役年限均显著优于全波长模型,且优于一步波长筛选法所建的M-SIFT 模型。其中M-SIFT-SDSS 模型的传递能力及在多台仪器上的长期应用能力最佳,其模型变量个数仅为全波长模型的4.9%。该模型用于预测2011~2013 年样品时,可在6 台从机上直接共享;用于预测2014~2020 年各年度样品时,可在5 台仪器的考察年度内长期应用7年、在一台仪器上应用6年(2014~2019)。本文提出的基于SIFT算法的多步波长筛选方法可实现TRS近红外光谱模型在6 台从机上的无标样传递,并延长模型在各仪器上的使用寿命。本方法对其他数据集的适应性有待进一步研究。
猜你喜欢
特产研究(2022年6期)2023-01-17
北京航空航天大学学报(2022年8期)2022-08-31
活力(2019年15期)2019-09-25
现代园艺(2017年23期)2018-01-18
实用口腔医学杂志(2017年6期)2017-09-19
中国照明(2016年4期)2016-05-17
中国光学(2015年5期)2015-12-09
物理实验(2015年9期)2015-02-28
天津造纸(2015年2期)2015-01-04
食品工业科技(2014年23期)2014-03-11
