
基于随机森林算法的烟草提取物类别识别模型研究
2023-11-29 01:42:32申涛榕张艳飞杜欢哲邹小勇
分析测试学报 2023年11期
丁 莎,申涛榕,张艳飞,杜欢哲,吴 榆,邹小勇*
(1.湖南中烟工业有限责任公司技术中心,湖南 长沙 410007;2.中山大学 化学学院,广东 广州 510006)
目前烟草行业使用的同类不同来源的烟草提取物包括不同产地、不同生产工艺的提取物、精油、浸膏、净油、精制物等,常用的分析检测手段为气相色谱-质谱联用技术,包括气相色谱-四极杆质谱(GC-Q MS)、气相色谱-四极杆飞行时间质谱(GC-QTOF MS)[1]、气相色谱-离子阱质谱(GC-IT MS)[2-3]和气相色谱-三重四极杆串联质谱(GC-QQQ MS)[4-5]等。其中GC-QTOF MS 的优势在于:一方面高分辨飞行时间质谱具有分辨率高、扫描速度快等优势,可通过与其他质谱串联实现多级质谱分析的要求;另一方面GC-QTOF MS 结合了气相色谱的高分离能力,极大地拓展了高分辨质谱在化合物定性分析上的应用范围,非常适用于烟草提取物等复杂体系中目标化合物的提取与鉴定[6-8]。
随机森林(Random forest,RF)[9-10]是一种基于多个决策树的集成学习方法,具有高效、鲁棒性好、易于实现等优点,已被应用于烟草中化学成分的测量和分析,为烟草的品质评价、加工工艺优化、香气调控等提供了新的思路和方法。该方法可利用烟草易获得的特征数据,建立烟草化学成分与特征数据之间的非线性关系模型,实现对烟草中化学成分的快速识别。郭东锋等[11]使用随机森林分类算法分析影响烤烟香型的关键因素,有效地对烤烟香型进行分类。赖燕华等[12]利用近红外光谱技术和随机森林算法,建立了一种烟叶霉变快速识别模型,对不同霉变程度的复烤片烟进行了有效判别。杨睿等[13]利用随机森林方法对不同品种的鲜烟叶成熟度进行了判别。陈颐等[14]利用热裂解/气相色谱-质谱法和随机森林方法,对加热卷烟烟叶原料的化学成分和感官评价进行了分析,建立了烟叶原料适用性的预测模型,并筛选出影响适用性的重要化学成分。
本文采用GC-QTOF MS 技术和RF算法,获取20种烟草提取物相关信息,对其进行了各成分分析,获得二进制表征数据集。基于RF 模型,构建了提取物、油类物质和浸膏物质3 类物质,以及6 个地域产地烟草提取物的识别方法,相关研究未见报道。
1 实验部分
1.1 仪器、材料与试剂
20种烟草提取物,按种类分为8种提取物、10种油类物质、2种浸膏物质;按地域分为7种(只对6地域产地分析),分别为2种A 烟草、3种B 烟草、5种C 烟草、2种D 烟草、3种E 烟草、3种F烟草、1种G烟草提取物和1种未知产地的油类提取物,具体如表1所示。

表1 20种烟草提取物信息Table 1 Informations of the 20 kinds of tobacco extract
1.2 实验方法
用分析天平称取0.100 0 g 单一烟草提取物样品,分别加入10 mL 乙酸乙酯-甲醇(体积比1∶1)有机溶剂,振荡,超声提取15 min,用0.22 μm滤膜过滤,进样1 μL上机分析。
色谱条件:在气相色谱(Agilent 7890 A)分析仪上进行,色谱柱为DB-5MS(30 m × 0.25 mm × 0.25 μm)弹性石英毛细管柱;进样口温度为280 ℃;柱初始温度为50 ℃(保持4 min),以8 ℃/min 升至180 ℃,再以20 ℃/min 升至250 ℃,保持3 min,最后以30 ℃/min 升至280 ℃,保持5 min;进样量为1.0 μL;分流比5∶1;载气为He;柱前压力为22.44 kPa,流速为1.5 mL/min。
质谱条件:Xevo G2-XS QTOF MS 系统,采用大气压气相色谱电离源(APGC+)模式;源温度:120 ℃;锥孔气:150 L/h;辅助气:200 L/h;采集模式:MSE;高碰撞能量:5~30 V;采集质量范围:50~800 Da。
1.3 随机森林模型构建
RF 是一种属于集成学习方法的机器学习算法。它通过组合多个分类树,最终通过投票或取平均值,使得整体模型结果具有高的准确度和泛化性能。该算法不仅支持大数据集,而且可应对高维特征向量。基于Matlab 软件中的“TreeBagger”函数执行RF 算法。按照[100∶100∶1 000]和2^[1∶1∶11],以及算法的默认参数,优化RF参数:森林中包含树的数目和每一棵树的叶节点选择参数的数目。样本随机平均分成2 份,其中1 份用作测试集,剩余1 份用作训练集。重复2 次,使2 份中的每一份均被作为测试集。最后,整合2 次重复的结果,评估模型性能。具体步骤如下:①利用Matlab 的xlsread函数读取并装载样本对应的二进制特种向量;②将样本随机分为2 等份;③根据设置的随机森林参数和Matlab 的“TreeBagger”函数,运行RF 算法;④基于2-折交叉验证,采用预测精度(Accuracy)优化模型参数,并评估模型性能;⑤基于最优的参数组合,构建RF 模型;⑥根据构建的RF 模型,输出识别结果。其中Accuracy 定义为:Accuracy=ni/Ni,其中Ni为第i类的样本数目,ni为正确识别第i类的样本数目。
利用Xevo G2-XS QTOF MS 系统,对20 种烟草提取物样品进行GC-QTOF MS 分析,并获取各烟草提取物成分,构建二进制表征数据集。由于G产地只有1种,采用RF模型,只对3种类(提取物、油类和浸膏类)和6地域产地(2种A、3种B、5种C、2种D、3种E、3种F)烟草提取物进行区分和识别。
2 结果与讨论
2.1 成分分析及特征表征
对3 种类和6 地域产地的20 种烟草提取物进行了成分分析,涉及1-羟基-2-丙酮、2-甲基四氢呋喃-3-酮和法尼基丙酮等110个成分。以B 产地为例(其他类同),共有烟草提取物(B)、B 浸膏和烟草提取物(B精油)3种物质,烟草提取物(B)和B浸膏含有吡啶,对应二进制向量中的元素值为1,烟草提取物(B 精油)元素值为0;B 浸膏含有茄酮,元素值为1,其他2 个元素值为0;烟草提取物(B 精油)含有十八酸,元素值为1,其他2个元素值为0;烟草提取物(B)、B 浸膏和烟草提取物(B 精油)含有乙酸甲酯,元素值均为1;3种物质不含有乙酸异丁酯,元素值均为0。因此,构建了110 × 3维二进制向量数据集表(如表2)。

表2 产地B烟草提取物的二进制表征表Table 2 Binary characterization of tobacco extract from origin B
2.2 RF三类模式识别
将20种烟草提取物按照8种提取物、10种油类和2种浸膏划分为3类。8种提取物标记为“1”,10种油类和2种浸膏分别标记为“2”和“3”,构建RF模型对香烟提取物进行三类模式识别研究。
构建了8 种提取物、10 种油类和2 种浸膏二进制向量数据集,维数分别为:110 × 8、110 ×10、110 ×2。采用构建的数据集,基于Matlab数学建模软件中的“TreeBagger”命令进行判别分析。采用2-折交叉验证方法评估模型的预测精度,并优化参数。
RF 参数(树的数目和选择特征的数目)优化结果如图1 所示,混淆矩阵如图2 所示,结果列于表3~表5。由图2 可以看出,建立的RF 模型100%准确识别8 种提取物、10 种油类和2 种浸膏。由表3 可以看出,无论森林中树的数目和每个节点选择的特征数目如何改变,构建的模型始终能够正确识别8 种提取物。对于10 种油类物质,当树的数目为100,且选择的特征数目为2 时,预测精度较低,但仍达到90%的正确识别率。对于2 种浸膏,由于样本数目较少,只有当森林中树的数目较大,且选择的特征数目大于4时,构建的模型才能准确识别。结果表明,基于识别的特征成分,选择优化参数,RF 模型能够有效识别20种烟草提取物中8种提取物、10种油类和2种浸膏。
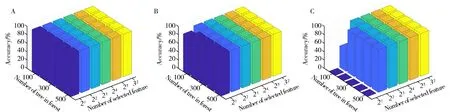
图1 RF模型参数优化对8种烟草提取物(A)、10种油类提取物(B)和2种浸膏提取物(C)的预测结果Fig.1 Optimization of RF model parameters for prediction results of 8 tobacco extracts(A),10 oil extracts(B) and 2 extractums(C)
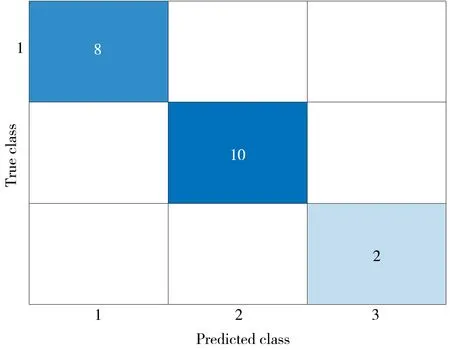
图2 RF模型混淆矩阵Fig.2 Confusion matrix of RF model
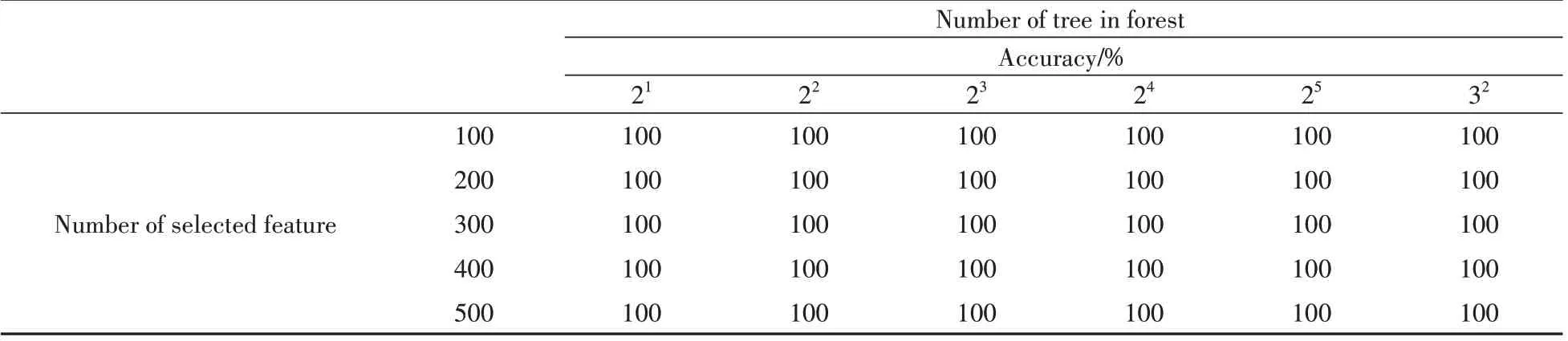
表3 RF模型参数对8种烟草提取物的识别结果Table 3 Recognition results of 8 tobacco extracts using RF model from different parameter combination

表4 RF模型参数对10种油类提取物的识别结果Table 4 Recognition results of 10 oil extracts using RF model from different parameter combination

表5 RF模型参数对2种浸膏提取物的识别结果Table 5 Recognition results of 2 extractum using RF model from different parameter combination
2.3 RF六类模型
将20 种烟草提取物按照产地A、B、C、D、E和F 分别标记为“1”、“2”、“3”、“4”、“5”和“6”。构建RF 模型对烟草提取物进行六类模式识别研究。
构建的6 个地域产地(2 种A、3 种B、5 种C、2种D、3种E、3种F)二进制向量数据集,维数分别为:A:110×2、B:110×3、C:110×5、D:110×2、E:110×3、F:110×3。采用构建的数据集,基于Matlab 数学建模软件中的“TreeBagger”命令进行判别分析。采用2-折交叉验证方法评估模型的预测精度,并优化参数。
采用RF 算法构建模型开展识别研究,预测结果示意图和混淆矩阵如图3 所示。在图3A 中,每个点表示样本在三维空间中的分布,点的颜色与三维坐标数值相关,即坐标值越大颜色越浅。结果表明,RF 构建的模型能够准确识别6 种烟草在高维空间的分布边界;图3B 纵坐标A、B、C、D、E 和F分别表示样本的真实类别,横坐标表示样本的预测类别,方格中的数字表示样本数目,颜色与样本数目大小相关,即样本数目越多颜色越深。结果表明,每一类样本均被构建的RF模型准确识别,模型能够100%识别每一地域产地的烟草。因此,RF 模型准确识别了2 种A 烟草、3 种B 烟草、5 种C 烟草、2种D烟草、3种E烟草、3种F烟草。
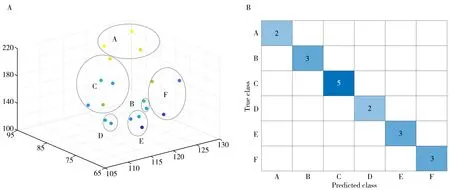
图3 随机森林最优模型对6种烟草提取物的预测结果示意图(A)与混淆矩阵(B)Fig.3 Schematic diagram(A) and confusion matrix(B) of prediction results of six types of tobacco extracts based on RF optimized model
3 结 论
本文以不同产地的20 种烟草提取物为研究对象,采用GC-QTOF MS 作为样本的高分辨表征手段,对同类不同来源的烟草提取物进行深入的成分剖析及其关键成分的定量研究等,有望获得它们更多的化学信息。研究结果可为烟草提取物的质量标准制定奠定基础,也为同类不同来源的天然香原料(包括烟草提取物)品控和分析提供科学依据,并为功能性香基模块中天然香原料的溯源可行性提供理论依据。
猜你喜欢
中学化学(2024年4期)2024-04-29 22:54:35
现代盐化工(2022年2期)2022-06-10 01:35:30
河北渔业(2021年9期)2021-09-22 02:03:28
天然产物研究与开发(2019年1期)2019-03-01 05:41:26
中成药(2017年5期)2017-06-13 13:01:12
河北渔业(2016年8期)2016-09-23 12:46:44
中国民族医药杂志(2016年5期)2016-05-09 07:43:50
作文大王·低年级(2016年3期)2016-03-11 00:48:53
中国药业(2014年21期)2014-05-26 08:56:32
中国药业(2014年4期)2014-05-09 08:48:22
