
基于词序扰动的神经机器翻译模型鲁棒性研究
2023-11-28 02:47赵彧然薛傥刘功申
网络与信息安全学报 2023年5期
赵彧然,薛傥,刘功申
基于词序扰动的神经机器翻译模型鲁棒性研究
赵彧然,薛傥,刘功申
(上海交通大学网络空间安全学院,上海 200240)
预训练语言模型是自然语言处理领域一类十分重要的模型,预训练−微调成为许多下游任务的标准范式。先前的研究表明,将BERT等预训练语言模型融合至神经机器翻译模型能改善其性能。但目前仍不清楚这部分性能提升的来源是更强的语义建模能力还是句法建模能力。此外,预训练语言模型的知识是否以及如何影响神经机器翻译模型的鲁棒性仍不得而知。为此,使用探针方法对两类神经翻译模型编码器的句法建模能力进行测试,发现融合预训模型的翻译模型能够更好地建模句子的词序。在此基础上,提出了基于词序扰动的攻击方法,检验神经机器翻译模型的鲁棒性。多个语言对上的测试结果表明,即使受到词序扰动攻击,融合BERT的神经机器翻译模型的表现基本上优于传统的神经机器翻译模型,证明预训练模型能够提升翻译模型的鲁棒性。但在英语−德语翻译任务中,融合预训练模型的翻译模型生成的译文质量反而更差,表明英语BERT将损害翻译模型的鲁棒性。进一步分析显示,融合英语BERT的翻译模型难以应对句子受到词序扰动攻击前后的语义差距,导致模型出现更多错误的复制行为以及低频词翻译错误。因此,预训练并不总能为下游任务带来提高,研究者应该根据任务特性考虑是否使用预训练模型。
神经机器翻译;预训练模型;鲁棒性;词序
0 引言
将预训练语言模型(PLM,pre-trained language model),如BERT[1]等,融入神经机器翻译模型中是自然语言处理领域十分热门的研究方向[2-5]。融合之后,机器翻译模型能够利用PLM学习到丰富语义和句法知识[6-15],进而提升翻译模型的鲁棒性和翻译效果[16]。但之前的研究更关注改进模型的效果,忽略了对这些提升的来源进行解释,并且缺乏预训练语言模型如何影响翻译模型鲁棒性的考量。
本文首先检验了BERT能否改进机器翻译模型的句法能力。使用一些探针对传统的神经机器翻译模型Transformer[17](记作NMT模型)的编码器和融合了BERT的Transformer模型(记作BERT-NMT模型)的编码器进行测试[10,18],检验它们分别编码了哪些句法相关的信息。实验结果表明,融合BERT后,机器翻译模型编码器在词序建模以及重建依存句法树相关任务上的表现更好。为了验证这些提升确实是由BERT带来的,实验过程中使用掩码操作分别遮掩了自注意力模块和BERT-编码器(BERT-Enc,BERT-encoder)注意力模块。结果证明,BERT的确能够帮助提高翻译模型对词序进行建模的能力,特别是显著提高模型在双词调换(BShift,bi-gram shift)任务上的表现。
直觉上来讲,这种特性能够帮助机器翻译模型更好地处理源语言句子中的词序扰动攻击。为了检验这一猜想,本文提出了一种以概率交换两个相邻词以改变词序的攻击方法,并使用双语替换评测[19](BLEU,bilingual evaluation understudy)和BERTScore[20]对攻击后模型的翻译结果进行评价。在机器翻译工坊(WMT,workshop on machine translation)提供的多个语言翻译任务上进行实验表明,虽然词序扰动的概率不同,BERT-NMT模型生成的译文质量几乎优于NMT模型生成的译文,但在英德翻译任务中,随着扰动概率的增加,使用英文BERT反而会给模型生成的译文质量带来消极影响,说明英文BERT将破坏翻译模型的鲁棒性。
为了找到使用英文BERT训练得到的BERT-NMT模型翻译质量下降的原因,比较攻击前后源语言端和目标语言端句子的语义变化。使用WMT14英德数据集分别训练得到英德翻译模型和德英翻译模型并进行对比。对比发现,英语句子在受到攻击之后语义变化更为明显,这可能是德语具有比英语更为灵活的词序。而源语言端和目标语言端的语义差别则说明:英语BERT难以缩小词序扰动攻击前后源语言端的语义变化。为了细致了解翻译质量下降的具体表现,对比NMT模型和BERT-NMT模型分别受到攻击之后输出的译文。随着攻击时扰动概率的增加,BERT-NMT模型倾向于错误地从源语言端直接复制单词作为译文。此外,对比两个模型在翻译低频词时的正确率。统计结果表明,当扰动概率增加时,BERT-NMT模型翻译低频词的效果甚至不如普通的NMT模型。可见预训练并不总能为下游任务带来性能上的提升,在使用过程中应该更为小心。
1 研究现状
1.1 NMT模型中的PLM
神经机器翻译与预训练的交叉领域主要包含以下两条研究线路:①将PLM融合至神经机器翻译模型;②预训练跨语言的语言模型。
1.1.1 将PLM融合至神经机器翻译模型
在BERT[1]被提出之后,出现了许多将BERT融入机器翻译模型的简单尝试,包括使用PLM的输出替代机器翻译模型的嵌入层[21],以及使用PLM的参数对NMT模型的编码器进行初始化[22]。Zhu等[2]设计了BERT-Enc和BERT-解码器(BERT-Dec,BERT-decoder)注意力模块,并且混合了不同模块输出的表示。类似地,APT框架使用基于层的注意力机制对BERT的各层输出进行动态混合[13]。Guo 等[23]使用两个BERT分别作为编码器和解码器,在BERT不同层之间添加适配器,以同时利用编码器端和解码器端BERT包含的信息。Guo 等[24]进一步提出冻结BERT参数并添加适配器的方法来加速机器翻译模型的训练过程。Shavarani等[15]提出更加充分地利用BERT包含的语言学信息,而非简单地将其作为词嵌入的替代品。Xu 等[25]使用145 GB德语文本训练了一个特制的双语语言模型BiBERT,来提高模型的翻译效果。
1.1.2 跨语言的语言模型预训练
由于BERT在训练过程中仅使用单语语料,并不适合执行机器翻译任务,Conneau等[26]设计了一个新的翻译语言模型(TLM,translation language model)任务,并使用双语平行语料训练得到XLM模型。此外,以BERT为代表的单语语言模型往往仅包含编码器,与翻译模型常采用的编码器−解码器架构并不匹配,为此,Song 等[27]提出预训练一个序列到序列架构的模型MASS。此后,Liu 等[28]设计了更为复杂的预训练任务,并使用25种语言训练得到mBART,使得在翻译任务上进行微调成为可能。Lin 等[29]使用随机对齐替换任务训练了一个普适性更强的多语言翻译模型mRASP。Pan等[30]在mRASP的基础上引入对比学习和基于对齐的数据增强以提高模型效果。Li等[31]的研究表明,对序列到序列模型进行预训练的过程中使用双向解码器能显著提高模型的翻译效果。
1.2 NMT模型的鲁棒性
尽管相比先前的统计机器翻译模型,神经机器翻译模型生成的译文质量有了显著提高,但其仍存在一些不足之处。Belinkov等[32]发现基于字符的神经机器翻译模型的翻译效果很容易受到文本中噪声的影响。Cheng 等[33]指出同义词替换同样能够降低神经机器翻译模型的翻译效果。为了检验神经机器翻译模型的鲁棒性,之前的研究还尝试在输入中加入笔误,对输入中的字符或单词执行交换、重复以及删除操作,并对模型的相应输出进行评价[34~35]。
为了提高NMT模型的鲁棒性,主流的方法为基于对抗学习[32],即使用人工添加噪声的数据训练NMT模型。Sato 等[36]提出向输入添加使得损失增大最多的噪声以增强模型的鲁棒性。Cheng 等[37]设计了一个基于梯度的方法来生成对抗样本。此外,Sennrich 等[38]以及Michel和Neubig[39]说明使用子词表示句子能够帮助机器翻译模型更好地处理扰动。Cheng 等[33]提出了一个新的训练目标,最大化原始输入和扰动过的样本之间的相似性。UniDrop[40]在特征、结构和数据3 个维度使用丢弃法来提高机器翻译模型的效果。此外,Cheng等[41]将有监督训练和自监督训练相结合来提高神经机器翻译模型应对代码转换类型干扰的鲁棒性。
本文使用融合BERT的神经机器翻译模型来探究BERT为神经机器翻译模型带来了哪些影响。之前的研究表明,BERT能够提高文本分类模型的鲁棒性[16]。但BERT是否会影响神经机器翻译模型的鲁棒性还不得而知,这是本文要探究的问题。
2 BERT改善句法能力
本节通过实验来分析BERT如何影响神经机器翻译模型的建模能力,具体来说,使用5种不同的探针任务来检测NMT模型的编码器和BERT-NMT模型的编码器中分别编码了哪些句法相关的信息。
2.1 实验设置
2.1.1 探针任务
本文实验共使用以下5种探针任务。Distance任务中探针需要依据任意两个单词的向量表示预测它们在依存句法树中之间的距离。Depth任务则需要探针根据每个单词的向量表示预测其在依存句法树中的深度,即单词和根节点之间的距离。BShift任务则需要探针根据句子的向量表示判断句中是否存在两个相邻单词的位置被调换了。TreeDepth任务要求探针预测句子的短语结构树的最大深度。TopConst任务要求探针对句子的短语结构树最顶层类型进行分类。表1提供了每种句法探针任务的示例。

表1 句法探针任务的示例

探针B的训练目标为
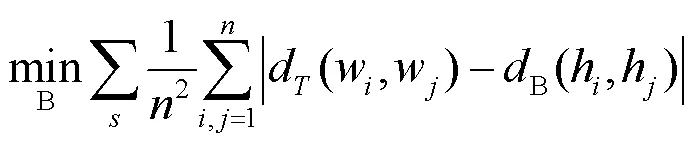
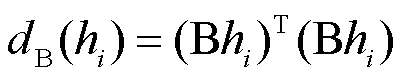
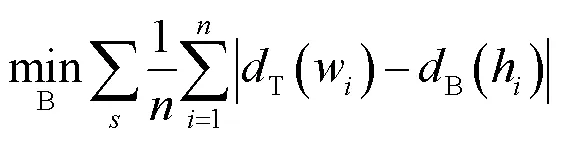
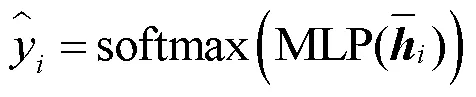
训练目标为


2.1.2 数据
对于Distance和Depth任务,使用STS 12-16[42-46]的数据,并且使用开源工具Stanza[47]生成每个句子对应的依存句法树以计算单词之间的距离和每个单词的深度。对全部数据按照7:2:1划分为训练集、验证集和测试集,分别包含36 000、10 000、5 000条句子。
对于其他探针任务,使用SentEval[48]提供的数据集。每个任务的训练集包含100 000条句子,验证集和测试集的大小均为10 000。
使用WMT14英德数据集训练神经机器翻译模型。在训练之前,首先使用40 000次合并操作的字节对编码[38](BPE,byte-pair encoding)算法对句子进行编码。验证集为newstest2013,测试集为newstest2014。
2.1.3 模型
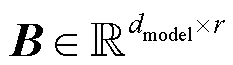
用于生成单词表示的基础模型包括BERT、NMT编码器以及BERT-NMT编码器。
NMT模型的整体架构如图1所示,包含编码器和解码器。其中,编码器主要包含自注意力和前馈网络模块,解码器则包括掩码自注意力、交叉注意力以及前馈网络3个模块。每个模块之后都会进行残差连接和层标准化操作。
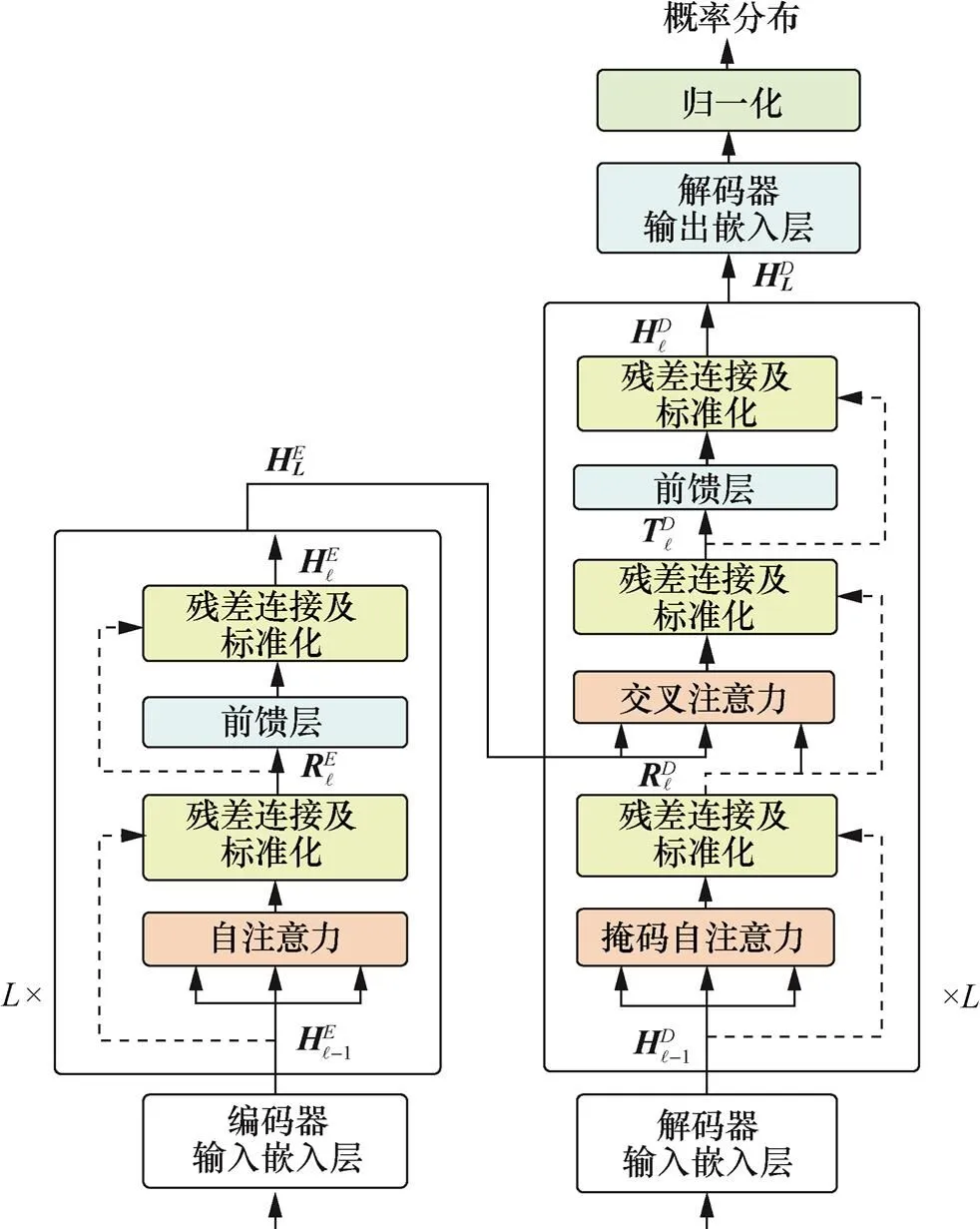
图1 NMT模型的整体结构
Figure 1 The whole structure of the NMT model
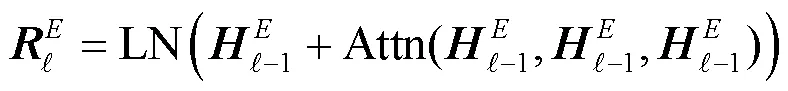
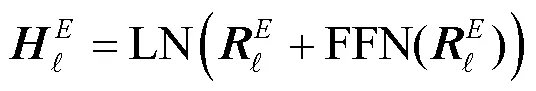
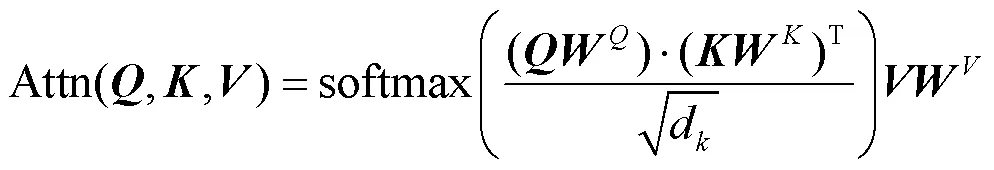
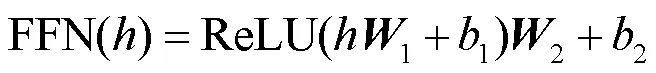
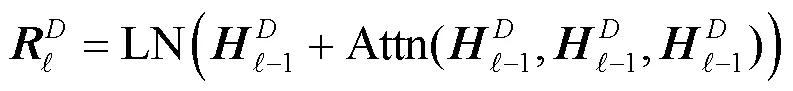
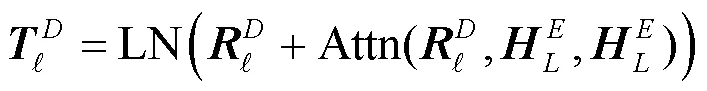
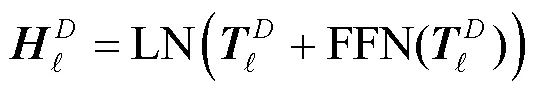

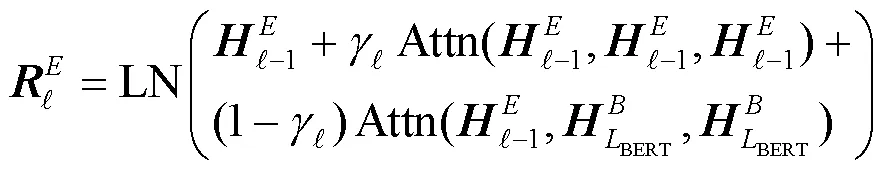
对于BERT,使用HuggingFace[49]提供的bert-base-uncased模型作为基准。NMT模型和BERT-NMT模型的实现与训练均基于Fairseq[50],其中BERT-NMT模型在训练时同样采用bert-base-uncased作为BERT模块。
对于每个基础模型,使用其最后一层的输出作为单词的表示,并且使用单词表示的均值作为句子的嵌入。
此外,为了能够了解自注意力模块和BERT-Enc模块的作用,使用控制变量法,在训练结束后生成单词表示时分别对两者进行掩码操作,这样最终得到的向量表示仅由一部分模块计算得到。对自注意力模块进行掩码操作如图2(b)所示,对BERT-Enc模块进行掩码操作图2(c)所示。
2.1.4 训练设置

图2 BERT-fused编码器结构和掩码操作示意
Figure 2 Overview of the structure of BERT-fused encoder and masking methods
2.1.5 翻译模型结果
2.2 BERT的影响
句法相关的探针任务实验结果如表2所示,在BERT的帮助下,BERT-NMT编码器在Distance、Depth、BShift、TreeDepth、TopConst任务上都获得了比NMT编码器更高的准确率。
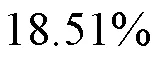
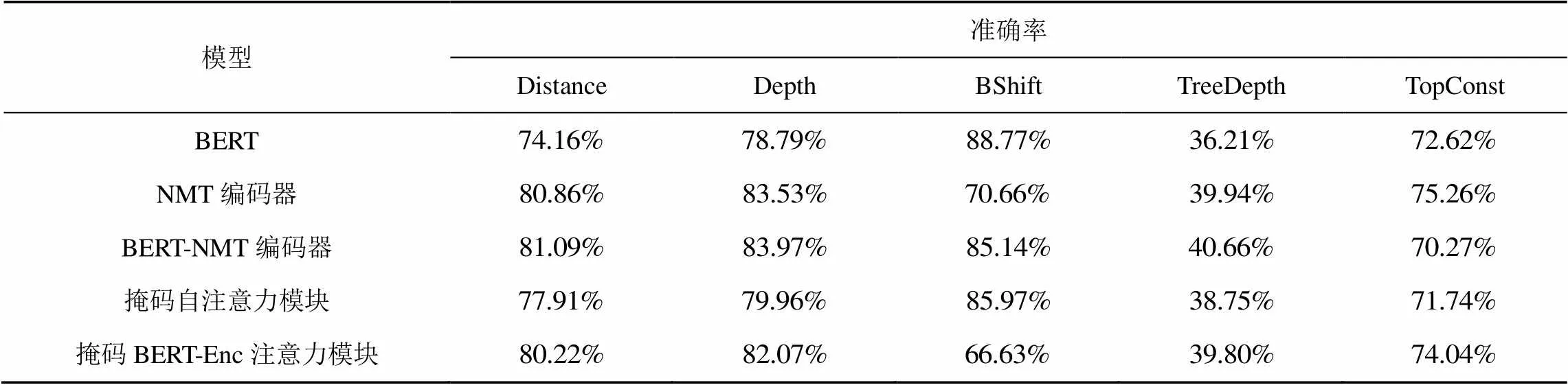
表2 句法相关的探针任务实验结果
3 使用语序扰动攻击NMT模型
即使相邻的两个单词位置调换,BERT也能够识别出句子的语义信息,这种特性可以帮助神经机器翻译模型更好地应对源语言句子中的扰动。本节探究BERT是否能够提升机器翻译模型的鲁棒性。
3.1 实验设置
3.1.1 攻击方法
为了探究BERT能否提高机器翻译模型的鲁棒性,本节仿照BShift任务设计了一种扰乱词序的攻击方法。简单来说,打乱翻译任务测试集中句子的原有词序,并以一定概率交换两个相邻单词,之后以扰动后的句子作为输入,评估模型翻译出的译文效果。表3展示了使用攻击方法按照不同概率生成的样例。值得注意的是,句首第一个单词和结尾标点的位置在攻击时不会被改变。

表3 使用攻击方法按照不同概率生成的样例
攻击之后,分别观察NMT和BERT-NMT模型输出的翻译结果。如果BERT能够提高机器翻译模型的鲁棒性,那么BERT-NMT的译文分数(BLEUScore或BERTScore)将会更高。反之,如果BERT-NMT模型的分数更低,则说明BERT可能对机器翻译模型的鲁棒性有负面影响。
3.1.2 数据
为了囊括尽可能多的语言,本文选择了5种来自不同语系的语言对,包括WMT14德语−英语数据集(De-En,包括4 500 000条平行语料)、WMT14英语−德语数据集(En-De)、WMT17芬兰语−英语数据集(Fi-En,包括2 600 000条平行语料)、WMT17土耳其语−英语数据集(Tr-En,包括207 000条平行语料)以及WMT17中文−英语数据集(Zh-En,包括20 800 000条平行语料)。对于WMT14 英德数据集,借助Moses提供的脚本进行分词,之后使用40 000次BPE合并操作进行编码,并生成一个共享字典。对于WMT17 Fi-En和Tr-En,使用WMT17官方提供的预处理后的版本,同样使用源语言和目标语言的共享字典。至于WMT17 Zh-En数据集,首先使用jieba对中文文本进行分词处理,之后对中文和英文数据集分别使用32 000次BPE合并操作构建字典。
对于WMT14数据集,使用newstest2013作为验证集,newstest2014作为测试集。WMT17的翻译任务在newstest2016上进行验证,在newstest2017上进行评测。

表4 NMT和BERT-NMT在相应测试集上的BLEUScore和BERTScore
3.1.3 模型
本节使用的NMT模型和BERT-NMT模型的架构与超参数与2.1节中介绍的相同。
3.1.4 评价指标
3.2 攻击结果
3.2.1 BLEUScore和BERTScore的变化
3.2.2 源语言端和目标语言端语义的变化
为了找出融合英文BERT后,BERT-NMT模型翻译质量下降这一现象背后的原因,比较源语言端句子和目标语言端译文的语义变化。

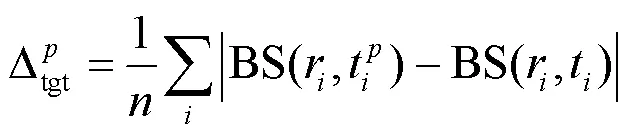
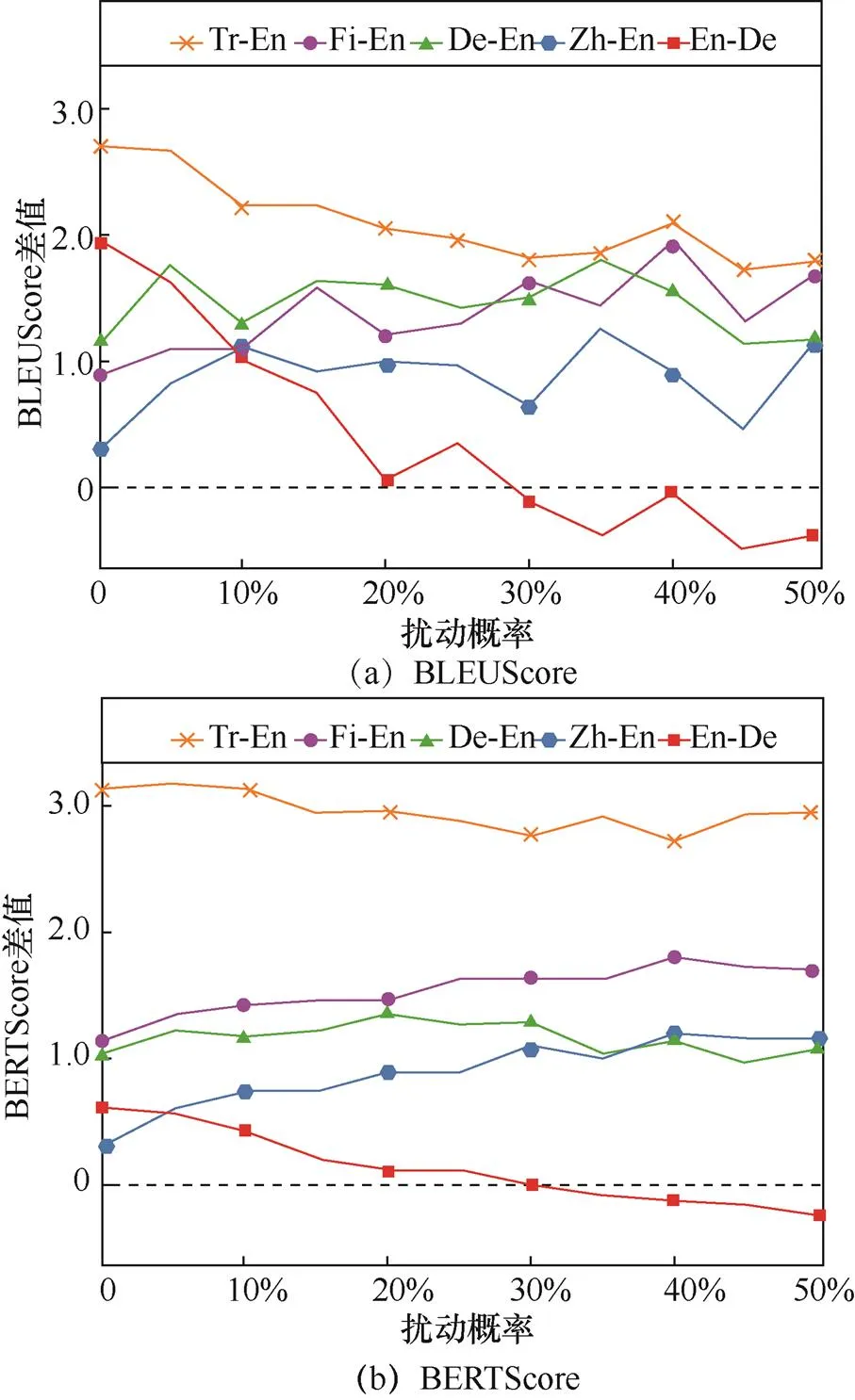
图3 BERT-NMT和NMT在BLEUScore和BERTScore上的差值
Figure 3 Plots of differences between BERT-NMT and NMT in terms of BLEUScore and BERTScore

源语言和目标语言端语义变化如图4所示,En-De在源语言端的语义变化明显大于De-En中源语言端的语义变化,说明不同语言对于词序扰动具有不同的反应。对于英语文本来说,受到干扰之后句子的语义发生了一定改变,而德语的句子仍保留了原始的意义。一种可能的解释是德语的语法允许较为灵活的词序。
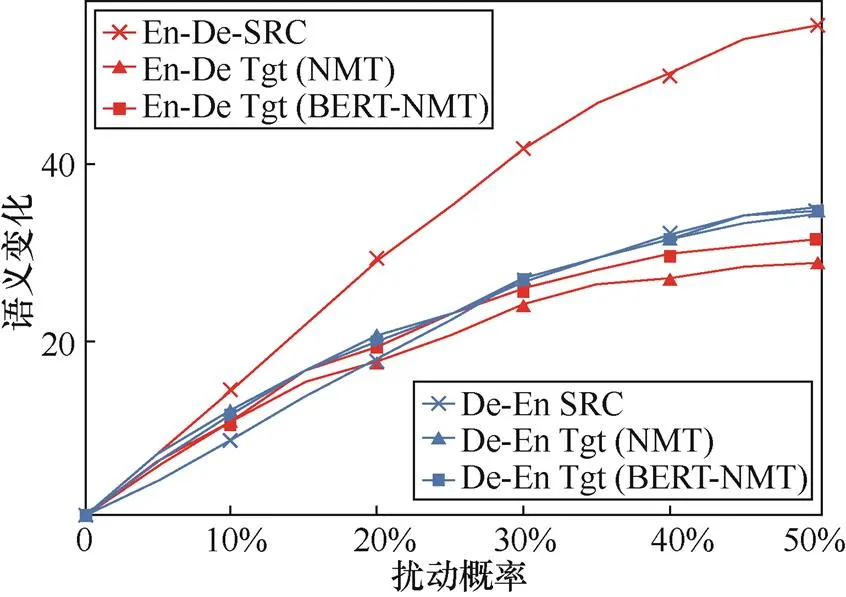
图4 源语言和目标语言端语义变化
Figure 4 Changes of semantics in the source side and target side
但是在En-De任务中,NMT和BERT-NMT模型在目标语言端上的变化趋势和源语言端并不相同。而它们在De-En任务中的变化趋势和源语言端的变化更为类似。这说明在En-De任务中,不论NMT还是BERT-NMT模型,都没能很好地应对攻击带来的变化。
3.2.3 源语言端和目标语言端语义的差值
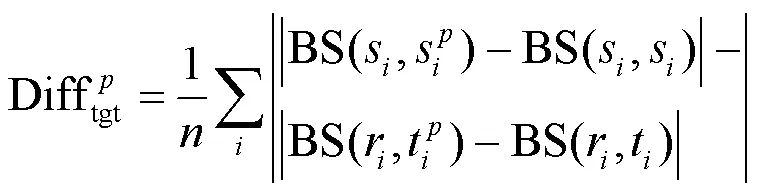
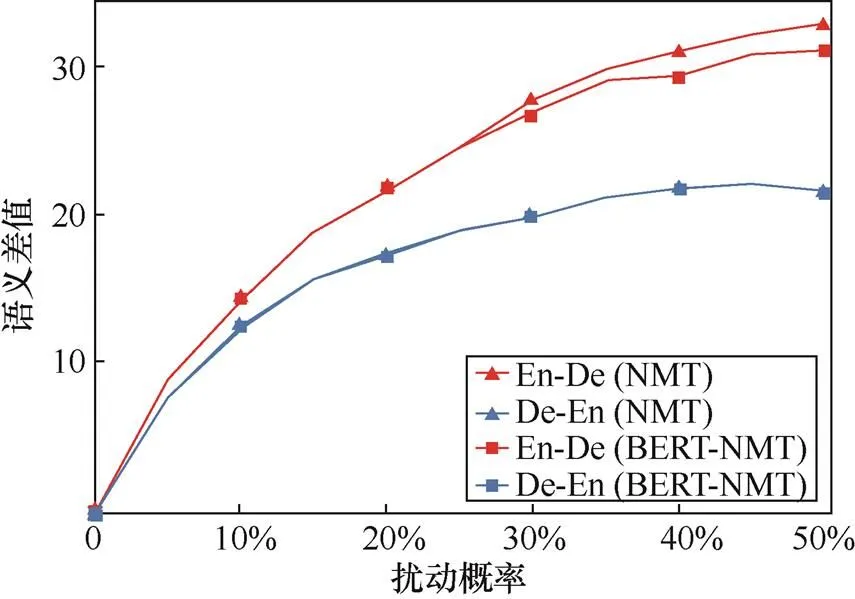
图5 源语言和目标语言端间的语义差值
Figure 5 Semantic difference between the source side and target side
3.3 分析
3.3.1 复制行为
为了更加细致地了解翻译质量下降的表现,本文比较了NMT模型和BERT-NMT模型在输入未受扰动和受扰动情况下生成的译文。当输入分别为未受攻击的句子和扰动后的句子时NMT和BERT-NMT生成的翻译样例如表5所示,当源语言句子未被攻击时,BERT-NMT模型能够产生高质量的翻译。但当输入受到扰动后,BERT-NMT模型倾向于简单地直接从源语言句子中复制单词。而NMT模型仍能生成较为合理的译文。统计结果显示,BERT-NMT模型从源语言端错误地复制了48个句子,而NMT模型仅复制了33个句子。这一对比结果说明,随着攻击概率的增加,融合BERT将会放大神经机器翻译模型由于数据不确定性引发的复制错误[5,53]。
3.3.2 低频词翻译不足
考虑到翻译低频词时往往需要依赖上下文信息,而前文提出的攻击方式会破坏上下文信息,因此En-De任务中BERT-NMT模型翻译效果下降的一个可能解释是模型难以很好地处理低频词的翻译。compare-mt[54]能够用于评价单词级别的翻译表现。根据单词在训练集中出现的频率将其划分为3类:低频词(小于10)、中频词(10到100)和高频词(大于100)。对于每一类,compare-mt报告预测结果相对真实结果的1值。Tr-En和En-De中不同频率单词NMT和BERT-NMT的翻译1值如表6和表7所示。不论词频和攻击概率如何变化,使用Tr-En数据集训练得到的BERT-NMT模型的1值始终高于NMT模型。

表5 当输入分别为未受攻击的句子和扰动后的句子时NMT和BERT-NMT生成的翻译样例

表6 Tr-En中不同频率单词NMT和BERT-NMT的翻译F1值
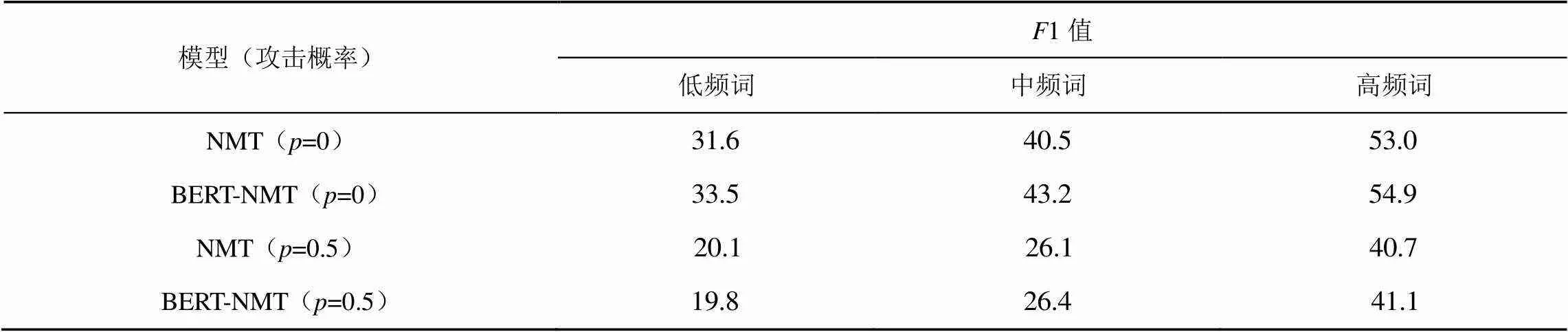
表7 En-De中不同频率单词NMT和BERT-NMT的翻译F1值
4 结束语
本文说明了BERT能够提高神经机器翻译模型句法相关的能力,特别是对词序进行建模的能力;设计了一种基于词序扰动的攻击方法,来检测翻译模型的鲁棒性。在多种不同语言对上的实验结果表明,融合英语BERT会给神经机器翻译模型的翻译质量带来消极影响。英语BERT无法缩小原始句子和受扰动句子之间的语义差别。进一步分析显示,BERT导致了更多翻译时的复制行为,以及低频词翻译不足的后果。因此,研究者应该根据下游任务和具体情境决定是否使用预训练语言模型。未来,将继续探究跨语言预训练方法对神经机器翻译模型语义、句法能力以及鲁棒性的影响。
[1] DEVLIN J, CHANG M W, LEE K, et al. BERT: pre-training of deep bidirectional transformers for language understanding[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019: 4171-4186.
[2] ZHU J, XIA Y, WU L, et al. Incorporating BERT into neural machine translation[C]// 8th International Conference on Learning Representations. 2020: 1-16.
[3] BAZIOTIS C, HADDOW B, BIRCH A. Language model prior for low-resource neural machine translation[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 7622-7634.
[4] AN T, SONG J, LIU W. Incorporating pre-trained model into neural machine translation[C]//2021 4th International Conference on Artificial Intelligence and Big Data (ICAIBD). 2021: 212-216.
[5] LIU X, WANG L, WONG D F, et al. On the complementarity between pre-training and back-translation for neural machine translation[C]//Findings of the Association for Computational Linguistics: EMNLP 2021. 2021: 2900-2907.
[6] PETERS M E, NEUMANN M, ZETTLEMOYER L, et al. Dissecting contextual word embeddings: architecture and representation[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 1499-1509.
[7] JAWAHAR G, SAGOT B, SEDDAH D. What does BERT learn about the structure of language[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 3651-3657.
[8] TENNEY I, DAS D, PAVLICK E. BERT rediscovers the classical NLP pipeline[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 4593-4601.
[9] TENNEY I, XIA P, CHEN B, et al. What do you learn from context? Probing for sentence structure in contextualized word representations[C]//7th International Conference on Learning Representations. 2019: 1-17.
[10] HEWITT J, MANNING C D. A structural probe for finding syntax in word representations[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019: 4129-4138.
[11] GOLDBERG Y. Assessing BERT's syntactic abilities[J]. arXiv preprint arXiv:1901.05287, 2019.
[12] SUNDARARAMAN D, SUBRAMANIAN V, WANG G, et al. Syntax-infused transformer and bert models for machine translation and natural language understanding[J]. arXiv preprint arXiv:1911.06156, 2019.
[13] WENG R, YU H, HUANG S, et al. Acquiring knowledge from pre-trained model to neural machine translation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020: 9266-9273.
[14] YANG J, WANG M, ZHOU H, et al. Towards making the most of bert in neural machine translation[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2020: 9378-9385.
[15] SHAVARANI H S, SARKAR A. Better neural machine translation by extracting linguistic information from BERT[C]//Proceedings of the 16th Conference of the European Chapter of the Association for Computational Linguistics. 2021: 2772-2783.
[16] HAUSER J, MENG Z, PASCUAL D, et al. BERT is robust! a case against synonym-based adversarial examples in text classification[J]. arXiv preprint arXiv: 2109.07403, 2021.
[17] VASWANI A, SHAZEER N, PARMAR N, et al. Attention is all you need[C]//Proceedings of the 31st International Conference on Neural Information Processing Systems. 2017: 6000-6010.
[18] CONNEAU A, KRUSZEWSKI G, LAMPLE G, et al. What you can cram into a single $ &!#* vector: probing sentence embeddings for linguistic properties[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers). 2018: 2126-2136.
[19] PAPINENI K, ROUKOS S, WARD T, et al. Bleu: a method for automatic evaluation of machine translation[C]//Proceedings of the 40th annual Meeting of the Association for Computational Linguistics. 2002: 311-318.
[20] ZHANG T, KISHORE V, WU F, et al. BERTScore: evaluating text generation with BERT[C]//8th International Conference on Learning Representations. 2020: 1-43.
[21] CLINCHANT S, JUNG K W, NIKOULINA V. On the use of BERT for neural machine translation[C]//Proceedings of the 3rd Workshop on Neural Generation and Translation. 2019: 108-117.
[22] ROTHE S, NARAYAN S, SEVERYN A. Leveraging pre-trained checkpoints for sequence generation tasks[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 264-280.
[23] GUO J, ZHANG Z, XU L, et al. Incorporating bert into parallel sequence decoding with adapters[J]. Advances in Neural Information Processing Systems. 2020, 33: 10843-10854.
[24] GUO J, ZHANG Z, XU L, et al. Adaptive adapters: an efficient way to incorporate BERT into neural machine translation[J]. IEEE/ACM Transactions on Audio, Speech, and Language Processing, 2021, 29: 1740-1751.
[25] XU H, VAN DURME B, MURRAY K. BERT, mBERT, or BiBERT? a study on Contextualized Embeddings for Neural Machine Translation[C]//Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing. 2021: 6663-6675.
[26] CONNEAU A, LAMPLE G. Cross-lingual language model pretraining[C]//Proceedings of the 33rd International Conference on Neural Information Processing Systems. 2019: 7059-7069.
[27] SONG K, TAN X, QIN T, et al. MASS: masked sequence to sequence pre-training for language generation[C]//International Conference on Machine Learning. 2019: 5926-5936.
[28] LIU Y, GU J, GOYAL N, et al. Multilingual denoising pre-training for neural machine translation[J]. Transactions of the Association for Computational Linguistics, 2020, 8: 726-742.
[29] LIN Z, PAN X, WANG M, et al. Pre-training multilingual neural machine translation by leveraging alignment information[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP). 2020: 2649-2663.
[30] PAN X, WANG M, WU L, et al. Contrastive learning for many-to-many multilingual neural machine translation[C]//Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing. 2021: 244-258.
[31] LI P, LI L, ZHANG M, et al. Universal conditional masked language pre-training for neural machine translation[C]//Proceedings of the 60th Annual Meeting of the Association for Computational Linguistics. 2022: 6379-6391.
[32] BELINKOV Y, BISK Y. Synthetic and natural noise both break neural machine translation[C]//6th International Conference on Learning Representations. 2018: 1-13.
[33] CHENG Y, TU Z, MENG F, et al. Towards robust neural machine translation[C]//Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics. 2018: 1756-1766.
[34] VAIBHAV V, SINGH S, STEWART C, et al. Improving robustness of machine translation with synthetic noise[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019: 1916-1920.
[35] MICHEL P, LI X, NEUBIG G, et al. On evaluation of adversarial perturbations for sequence-to-sequence models[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2019: 3103-3114.
[36] SATO M, SUZUKI J, KIYONO S. Effective adversarial regularization for neural machine translation[C]//Proceedings of the 57th Annual Meeting of the Association for Computational Linguistics. 2019: 204-210.
[37] CHENG Y, JIANG L, MACHEREY W, et al. AdvAug: robust adversarial augmentation for neural machine translation[C]//Proceed- ings of the 58th Annual Meeting of the Association for Computational Linguistics. 2020: 5961-5970.
[38] SENNRICH R, HADDOW B, BIRCH A. Neural machine translation of rare words with subword units[C]//Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics. 2016: 1715-1725.
[39] MICHEL P, NEUBIG G. MTNT: a testbed for machine translation of noisy text[C]//Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing. 2018: 543-553.
[40] WU Z, WU L, MENG Q, et al. UniDrop: a simple yet effective technique to improve transformer without extra cost[C]//Proceed- ings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies. 2021: 3865-3878.
[41] CHENG Y, WANG W, JIANG L, et al. Self-supervised and supervised joint training for resource-rich machine translation[C]//International Conference on Machine Learning. 2021: 1825-1835.
[42] AGIRRE E, CER D, DIAB M, et al. SemEval-2012 task 6: A pilot on semantic textual similarity[C]//Proceedings of the Main Conference and the Shared Task, and Volume 2: Proceedings of the Sixth International Workshop on Semantic Evaluation (SemEval 2012). 2012: 385-393.
[43] AGIRRE E, CER D, DIAB M, et al. * SEM 2013 shared task: semantic textual similarity[C]//Proceedings of the Main Conference and the shared task: Semantic Textual Similarity. 2013: 32-43.
[44] AGIRRE E, BANEA C, CARDIE C, et al. Multilingual semantic Textual Similarity[C]//Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014). 2014: 81-91.
[45] AGIRRE E, BANEA C, CARDIE C, et al. Semantic textual similarity, english, spanish and pilot on interpretability[C]//Proceedings of the 9th International Workshop on Semantic Evaluation (SemEval 2015). 2015: 252-263.
[46] AGIRRE E, BANEA C, CER D, et al. Semantic Textual Similarity, Monolingual and Cross-Lingual Evaluation[C]//Proceedings of the 10th International Workshop on Semantic Evaluation (SemEval-2016). 2016: 497-511.
[47] QI P, ZHANG Y, ZHANG Y, et al. Stanza: a python natural language processing toolkit for many human languages[C]//Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics: System Demonstrations. 2020: 101-108.
[48] CONNEAU A, KIELA D. SentEval: an evaluation toolkit for universal sentence representations[C]//Proceedings of the Eleventh International Conference on Language Resources and Evaluation (LREC 2018). 2018: 1699-1704.
[49] WOLF T, DEBUT L, SANH V, et al. Transformers: state-of-the-art natural language processing[C]//Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing: System Demonstrations. 2020: 38-45.
[50] OTT M, EDUNOV S, BAEVSKI A, et al. Fairseq: a fast, extensible toolkit for sequence modeling[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). 2019: 48-53.
[51] KINGMA D P, BA J. Adam: a method for stochastic optimization[C]// 3rd International Conference on Learning Representations. 2015: 1-15.
[52] POST M. A call for clarity in reporting BLEU scores[C]//Proceed- ings of the Third Conference on Machine Translation: Research Papers. 2018: 186-191.
[53] OTT M, AULI M, GRANGIER D, et al. Analyzing uncertainty in neural machine translation[C]//International Conference on Machine Learning. 2018: 3956-3965.
[54] NEUBIG G, DOU Z Y, HU J, et al. compare-mt: a tool for holistic comparison of language generation systems[C]//Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics (Demonstrations). 2019: 35-41.
Research on the robustness of neural machine translation systems in word order perturbation
ZHAO Yuran, XUE Tang, LIU Gongshen
School of Cyber Science and Engineering, Shanghai Jiao Tong University, Shanghai 200240, China
Pre-trained language model is one of the most important models in the natural language processing field, as pre-train-finetune has become the paradigm in various NLP downstream tasks. Previous studies have proved integrating pre-trained language models (e.g., BERT) into neural machine translation (NMT) models can improve translation performance. However, it is still unclear whether these improvements stem from enhanced semantic or syntactic modeling capabilities, as well as how pre-trained knowledge impacts the robustness of the models. To address these questions, a systematic study was conducted to examine the syntactic ability of BERT-enhanced NMT models using probing tasks. The study revealed that the enhanced models showed proficiency in modeling word order, highlighting their syntactic modeling capabilities. In addition, an attacking method was proposed to evaluate the robustness of NMT models in handling word order. BERT-enhanced NMT models yielded better translation performance in most of the tasks, indicating that BERT can improve the robustness of NMT models. It was observed that BERT-enhanced NMT model generated poorer translations than vanilla NMT model after attacking in the English-German translation task, which meant that English BERT worsened model robustness in such a scenario. Further analyses revealed that English BERT failed to bridge the semantic gap between the original and perturbed sources, leading to more copying errors and errors in translating low-frequency words. These findings suggest that the benefits of pre-training may not always be consistent in downstream tasks, and careful consideration should be given to its usage.
neural machine translation, pre-training model, robustness, word order
TP393
A

赵彧然(1998−),男,河南安阳人,上海交通大学硕士生,主要研究方向为自然语言处理。
薛傥(1999−),男,山西运城人,上海交通大学硕士生,主要研究方向为自然语言处理。

刘功申(1974−),男,山东聊城人,上海交通大学教授、博士生导师,主要研究方向为人工智能安全、自然语言处理、信息安全。
2022−09−27;
2023−03−02
刘功申,lgshen@sjtu.edu.cn
国家自然科学基金(U21B2020);上海市科技计划项目(22511104400)
赵彧然, 薛傥, 刘功申. 基于词序扰动的神经机器翻译模型鲁棒性研究[J]. 网络与信息安全学报, 2023, 9(5): 138-149.
10.11959/j.issn.2096−109x.2023078
The National Natural Science Foundation of China (U21B2020), Shanghai Science and Technology Plan (22511104400)
ZHAO Y R, XUE T, LIU G S. Research on the robustness of neural machine translation systems in word order perturbation[J]. Chinese Journal of Network and Information Security, 2023, 9(5): 138-149.
猜你喜欢
农业机械学报(2020年2期)2020-03-09
孩子(2019年12期)2019-12-27
中华建设(2019年7期)2019-08-27
河南教育·高教(2019年3期)2019-04-11
北方文学(2018年18期)2018-09-14
心理与行为研究(2016年4期)2016-12-16
北方文学·中旬(2016年6期)2016-08-01
速读·下旬(2016年7期)2016-07-20
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
