
基于动态差分扩展的强鲁棒数据库水印算法研究
2023-11-28 02:56汪天琦张迎周邸云龙李鼎文朱林林
网络与信息安全学报 2023年5期
汪天琦,张迎周,邸云龙,李鼎文,朱林林
基于动态差分扩展的强鲁棒数据库水印算法研究
汪天琦1,2,3,张迎周1,2,3,邸云龙1,2,3,李鼎文1,2,3,朱林林1,2,3
(1. 南京邮电大学计算机学院,江苏 南京 210023;2. 南京邮电大学软件学院,江苏 南京 210023;3. 南京邮电大学网络空间安全学院,江苏 南京 210023)
科技行业的快速发展带来信息量的暴增,各行各业都需要收集和应用大量的数据,海量数据在发挥价值的同时,给数据安全领域带来了史无前例的挑战。关系型数据库作为数据的底层存储载体之一,其存储的数据规模大、数据内容丰富、数据隐私度高。数据库的数据一旦泄露将会造成巨大的损失,保护数据库的所有权,确认数据的归属刻不容缓。对于现有的数据库水印技术来说,提高水印嵌入容量和减小数据失真之间存在固有矛盾问题,为了缓解此问题且进一步提高水印的鲁棒性,提出了一种基于动态差分扩展的强鲁棒数据库水印算法。该算法选取QR码作为水印,利用经过Haar小波变换的图像低频部分进行奇异值分解(SVD,singular value decomposition),提取部分特征值,用取余后的特征值作为待嵌入的水印序列,使得相同长度的水印序列包含更多信息,缩短了嵌入水印的长度。该算法结合自适应差分进化算法和最小差值算法选择最佳嵌入属性位,以缓解传统差分扩展技术在嵌入水印时计算效率低、数据失真大、鲁棒性差的问题,提高水印嵌入容量的同时减少了数据的失真。实验结果表明,该算法保证高水印嵌入率的同时数据失真较低,能够抵御多种攻击,具有良好的鲁棒性,追踪溯源的能力强,且与现有的算法对比优势明显,在数据安全领域具有广阔的应用前景。
数据库水印;差分进化;差分扩展;SVD;Haar小波变换;QR码
0 引言
科技行业的快速发展带来的是信息量的暴增,各行各业都需要收集和应用大量的数据,累积的数据规模正以惊人的速度增长。海量数据蕴含的商业价值巨大,但其发挥价值的同时,也为数据安全领域带来了史无前例的挑战。数据库作为最常用的底层存储工具之一,其信息安全问题不容小觑。国内外学者大多是通过数据库水印技术来保护数据库的数据安全,解决信息泄露、源头难以追踪的困扰。在数据库背后利益的驱使下,攻击者在数据库所有者不知情的情况下对其加以复制、分发和篡改。数据库的数据一旦泄露将会造成巨大损失,保护数据库的所有权,确认数据的归属刻不容缓。
数字水印技术[1]可以有效解决很多信息安全问题,作为一种安全有效的保护数字版权的技术手段,数字水印技术广泛应用于多媒体领域[2-3]。但是,针对数据库的数字水印研究相对较少。目前,数字水印技术主要关注其不可见性、鲁棒性、安全性和嵌入容量等特性[4]。
可逆水印技术是数字水印技术的一个重要分支,Zhang等[5]提出了经典的可逆水印算法,该算法利用直方图平移拓展出的冗余空间按照指定的运算公式来嵌入水印,经过逆运算即可恢复出原始数据和水印信息,但是该算法的鲁棒性较差,在面对不法分子的恶意攻击时提取出的水印信息不完整。针对Zhang等提出算法的不足,Hu等[6]引入了遗传算法训练出最佳的水印嵌入位置,结合分组密钥和平移直方图设计了一种基于遗传算法的直方图平移可逆水印技术。
对于数据库水印来说,水印隐藏在关系数据库中,数据值变化较大,严重破坏原始数据的质量,水印的鲁棒性低,攻击者很容易破坏水印信息。Gupta等[7]吸取了数字水印技术的经验,提出了基于差分扩展的可逆数据库盲水印,选取元组中的任意两个属性值,通过差分扩展计算将水印嵌入数值中,对两个属性值进行计算嵌入一位水印,导致数值改动大于水印的嵌入,影响了数据库的可用性和鲁棒性。差分扩展技术中增加了水印嵌入容量,但不可避免地增大了数据的失真,于是研究者想到利用优化算法改进差分扩展数据库水印方法。Jawad等[8]利用遗传算法改进了基于差分扩展的可逆数据库盲水印,提出基于遗传算法的差分扩展可逆数据库水印,提高数据库水印算法的鲁棒性同时减少数据失真。但是,经过遗传算法优化的水印嵌入率并不尽如人意。邱升红[9]设计了一种基于差分扩展和人工蜂群算法的数据库可逆水印方法,使用人工蜂群算法代替遗传算法进行优化,增大了水印的嵌入容量并减少了数据的失真,进一步提高了水印算法的鲁棒性。宋岩等[10]利用改进的布谷鸟算法启发式地搜索水印嵌入属性位,通过差分扩展嵌入水印,对于大规模的数据库算法的水印嵌入率较高,对抗攻击的能力较强。孔嘉琪等[11]基于模拟退火改进的粒子群算法寻找更好的水印嵌入位置,提出了基于属性重要度的带权损失函数,解决了现有方案在抗属性维度攻击时鲁棒性较差的问题。由于数据库存储的是纯数据,其数值的改变对原载体的影响远大于多媒体水印,所以数据库水印技术很难在水印容量和数据失真方面保持平衡。Shi等[12]试图通过恢复原始数据和嵌入式水印信息来克服数据失真的问题。可逆水印技术能够在提取水印的同时恢复数据,然而目前的可逆数据库水印技术在嵌入水印后,数据质量和水印鲁棒性方面存在缺陷,基于此,Ge等[13]对水印容量和数据失真做了研究和改进,在一定的数据失真范围内提高了水印嵌入容量。现有的技术主要通过增加水印长度或提取水印特征压缩数据两种方法来达到提高水印嵌入容量的目的。陈青等[14]提出了一种新的基于旋转稳定区域和两级奇异值分解(SVD,singular value decomposition)的水印算法,保证水印的嵌入容量,且具有良好的不可见性和较高的鲁棒性。关虎等[15]将大容量、高容错的二维码理论应用于变换域图像水印算法,在保证水印不可见性和算法安全性的基础上,显著提高了水印容量和鲁棒性。在学者不断研究改进的过程中,数据库水印的鲁棒性和嵌入容量逐渐提高,数据的失真能够控制在合理的范围内。
1 本文算法
1.1 算法框架
大多数据库水印技术是单纯地嵌入一串数字序列或一副图像,包含的信息量较少且容易被攻击者破坏。当数据库发生泄露被恶意攻击时常常会导致水印被破坏,无法根据提取的信息锁定攻击者,因此水印的鲁棒性和溯源度较差。为了解决这一问题,需要增加水印的嵌入容量,但是嵌入容量过多会造成数据严重失真,影响数据库正常使用。针对数据库冗余性小、水印嵌入容量和数据失真之间存在固有矛盾等问题,本文提出了一种基于自适应差分进化(ADE,adaptive differential evolution)和动态差分扩展(DDE,dynamic difference expansion)的强鲁棒数据库水印算法,以下简称ADE-DDEW。所提算法首先对经过Haar离散小波变换的图像低频部分进行SVD,提取非0特征值,然后对特征值进行取余,对取余后的特征值进行动态压缩作为待嵌入的水印序列。结合自适应差分进化算法和最小差值算法选择最佳的水印嵌入属性位,最后通过动态地选取传统的或改进的差分扩展技术进行水印的嵌入。算法的总体框架如图1所示,主要包括水印预处理、水印嵌入和水印提取3个部分。
1.2 数据库水印预处理


图1 算法的总体框架
Figure 1 General framework of the algorithm
基于Haar小波变换的图像压缩算法的核心思想是通过计算平均值和差值得到细节系数(分为低频和高频),将图像分解成若干个高频图像和一个低频图像,可以在不影响主要信息的情况下初步对原始图像进行压缩,达到减小图像信息量的目的。Haar能够完全无失真地还原出原始图像,进而提高水印的可溯源性。本文采用Haar小波变换对QR码图像进行频域分解,由于低频部分包含图像大多数的有用信息,并且低频信号对于图像压缩、高斯噪声等多种图像处理操作有很强的抵御能力,所以本文提取分解后的低频图像作为处理完成的水印图像。假设水印图像的4个相邻像素值是[],基于Haar小波变换的QR码频域分解的具体步骤如下。
步骤1 将4个像素值两两分组,得到[]和[]。




SVD[16]主要应用在数据降维和数据压缩领域,是很多机器学习算法的基石,其核心思想是将图像矩阵分解出特征值和特征向量。矩阵的运算可以描述为线性空间中的变换,当一个矩阵进行运算时,本质上就是在矩阵空间下进行的一次线性变换(拉伸或者旋转),线性变化无法直观地通过图像来展示,但是经过奇异值分解得到的部分特征向量代表了该矩阵的主要变化方向。在这些方向上进行变换,就可以模拟矩阵的运算。基于上述性质,SVD可以做到无失真的压缩,不对图像造成损坏的同时通过逆运算还原出原始图像。
目前,图像作为水印嵌入数据库的场景基本是需要分割图像,然后将分割后的子图像分别嵌入分组后的子数据表。这种传统的方法不仅对图像的尺寸有一定的要求,而且由于数据库的分组不是无限的,所以嵌入的图像也有一定的限制。为了将二维的图片水印压缩成一维的水印序列,使用SVD技术对频域分解后提取出的低频图像进一步压缩,提取部分特征值生成水印序列。SVD不要求图像的尺寸并且有很强的数据降维能力,提高了水印信息的压缩率,使得相同长度的水印序列中包含更多的数据信息。
假设QR码图像是一个×的矩阵,经过SVD可以变成如式(3)的形式。


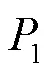

图2 水印SVD流程
Figure 2 Watermark singular value decomposition flow
1.3 算法设计
(1)数据库分组


定义2 水印嵌入容量(WEC,watermark embedding capacity):把嵌入水印的元组数和总元组数的比值定义为水印嵌入容量。


定义3 数据失真量(AoDD,amount of data distortion):定义嵌入水印前后属性值的改变率为数据失真量。即对于任意属性列来说,是嵌入水印造成的整体数据差值和该属性列极差之间的比值。
数据的变化量受原始数值的影响较大。具体来说,一位数的数据变化量只能在区间[0,9],而两位数则可以达到[0,99],以此类推,可以得出原始数值越高,可能导致数据变化量越大,如果只是单纯地累加数值变化量,对于有失真统计来说有失公平。本文数据失真量的计算方法如式(6)所示。


将上述WEC和AoDD两个指标作为目标函数的主体得到最终的目标函数,如式(7)所示。

(2)最佳嵌入属性位选取
本文利用自适应差分进化算法[15]进行水印最佳嵌入位置的选择,在提高嵌入容量的同时数据失真也会比较大。因此,通常选择每一个元组差值最小的两个属性进行嵌入,但是该算法难以抵御最小差值攻击。于是,在嵌入水印之前增加一次属性失真的判断,将超过属性失真范围的属性位置用最小差值计算的属性位置来代替,具体步骤如下。


步骤2 根据式(9)~式(11)对初始基因种群进行变异处理得到变异后的基因个体数组。
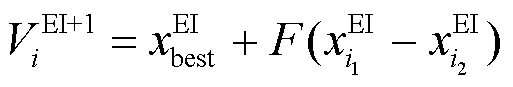



步骤4 分别计算和的适应度函数,适应度函数越小,说明越符合收敛目标。
步骤5 根据步骤1重新随机产生一个新的初始种群,分别计算和的适应度函数。
步骤6 重复执行步骤2到步骤5,直到获得最优决策向量或者达到最大的进化迭代次数,计算得到的最优值即当前数据库子组的最佳待嵌入水印属性位,与元组主键一起构成水印嵌入位置表adet。
步骤7 提取每个参与水印运算的元组取余后属性差值最小的两个属性,从而记录最小差值的水印嵌入位置表mdt。对adet进行属性失真判断,如果元组嵌入水印后的值超过了有失真范围,则将其水印嵌入位的下标记为−1,然后把下标为−1的位置用mdt的下标来代替,生成最终的嵌入水印的属性位置表ademdt。
(3)水印嵌入算法
差分扩展技术[18]的核心思想是利用数值间的平均值和差值计算将水印嵌入数据载体中。基于这一特性,差分扩展的水印嵌入率很高,但同时如果数据之间的差值过大,刚经过计算后得到的新数据的改变量也很大,数据的失真降低了数据水印的可用性。因此本文对要嵌入水印的数据进行有条件的取余,尽量将数据之间的差值控制在一定范围内,优化差分扩展特性导致的数据失真过大的弊端,增大水印的嵌入容量。

取余后属性值间的均值avg和差值计算如式(14)所示。





传统差分扩展技术和改进差分扩展技术对数值的改变量受到原始数据差值的影响,根据图3可以看出,在原始数据差值小于10时,传统的差分扩展的数据改变量普遍小于改进的差分扩展,而在原始数据差值大于10时,改进的差分扩展的数据改变量明显小于传统的差分扩展。因此,选取嵌入水印的属性位置后,先判断该位置上的属性差值,如果<10,则选择传统的差分扩展算法,反之选择改进的差分扩展算法。

图3 传统的差分扩展和改进的差分扩展算法应嵌入水印后的数据改变量对比
Figure 3 Comparison of the amount of data change between the traditional differential extension algorithm and the improved differential extension algorithm after embedding the watermark
基于自适应差分进化和动态差分扩展的水印嵌入算法如算法1所示。首先对数据库进行聚类分为个子组;其次对所有子组使用自适应差分进化算法初步选择出水印嵌入位,通过有失真分析结合最小差值算法确定最佳的水印嵌入位;最后判断嵌入水印数值间的差值,根据差值的范围动态选择传统的或改进的差分扩展算法,依次对子组进行水印的嵌入。特别地,每个子组冗余地嵌入同一水印比特位。
算法1 ADE-DDEW水印嵌入算法
输入 数据库DB,数据库分组数,嵌入水印属性列数,待嵌入水印序列,取余值Valmod
输出 嵌有水印的数据库DB,最终的嵌入水印位置表ade_mdt
1) ade_mdt=[][] //初始化最终的嵌入水印位置表ade_mdt
2) adet=[][] //初始化根据自适应差分进化计算的水印最佳嵌入属性位置表adet
3) mdt=[][] //初始化根据最小差值计算的水印最佳嵌入属性位置表mdt
4) DB←kmeans(DB,) //利用-means 算法进行数据库分组,得到个子组
5) For=0 to−1 do //遍历每个子组嵌入水印,得到嵌有水印的数据库DB
6) adet←ADE(DB,,) //自适应差分进化算法计算出最佳属性下标存放在adet数组中
7) mdt←MD(DB,,) //最小差值函数计算出差值最小的属性下标存放在数组 mdt 中
9) adet[1][2]=−1 //如果超过有失真范围,将有失真属性位置下标置为−1
10) End if
11) ade_mdt← 将adet数组中下标为−1的部分用mdt的下标代替
12) For=0 to ade_mdt.GetLength(0)−1 do //遍历当前子组嵌入水印位置表ade_mdt 的嵌入位置
13) For=1 to ade_mdt[0].length−1 do
14) If ade_mdt [][]!=−1 then
15) If<10 then…//嵌入水印数值的差值小于 10
16) 利用传统的差分扩展技术嵌入水印W
17) Else
18) 利用改进的差分扩展技术嵌入水印W
19) End if
20) DB←根据式(17)还原嵌入水印的属性值
21) End if
22) End for
23) End for
25) Return DB, ade_mdt
26) End for
(4)水印提取算法
在水印提取阶段,同样通过聚类算法进行分组。对每个子组提取水印比特位,由于是冗余嵌入,利用大数表决的方法确定提取的水印数值,将提取出的水印比特位按照分组顺序组合在一起得到最终的水印序列,同时能恢复出原始的数据库。





ADE-DDEW水印提取算法在利用改进的差分扩展算法进行水印提取时,通过嵌入水印时的除数和取余值恢复数据,数据可以复原,即使数据库遭到一定破坏,提取的水印可能不完整,但数据库可以复原如初,有效保障了数据库的可用性。针对提取出的水印序列,根据数据压缩恢复一维水印序列,根据SVD逆运算还原出低频图片,最后通过Haar小波逆变换还原出QR码。根据扫描出的QR码信息,可以确定泄密者的身份,识别攻击者。特别地,即使还原的QR码有失真,只要在一定范围内也可以扫描出身份信息,提高了水印的鲁棒性,如算法2所示。
算法2 ADE-DDEW 水印提取算法
输入 数据库DB,嵌入水印位置表ade_ mat,数据库分组数,取余值Valmod
输出 恢复的原始数据库DB,提取的数字水印序列,还原出的 QR 码图像
1) DB←kmeans(DB,) //利用-means算法进行数据库分组,得到个子组
2) For=0 to−1 do //迭代每个子组
3)0=0,1=0 //初始化记录提取的 0、1 个数的变量,用于大数表决
4) For=0 to ade_mdt.GetLength(0)−1 do //迭代每个子组的所有元组
5)1=ade_mdt[][0],2=ade_mdt[][1] //根据 ade_mdt 选择出嵌入水印的属性
6) 根据式(18)对1、2进行取余操作
7) 根据式(20)提取水印的比特值W,根据式(21)和式(22)恢复属性数值1、2
8) IfW== 0 then
9)0++ //统计提取的水印比特值为 0的个数
10) Else
11)1++ //统计提取的水印比特值为 1 的个数
12) End if
13) End for
14) If0>1then //大数表决
15)W=0 //如果提取的水印0的个数大于1的个数,则该子组的水印比特为0
16) Else
17)W=1 //否则该子组的水印比特为 1
18) End if
19)append(W) /依次组合每个子组提取的水印比特值
23) End for
24) Return DB,,QR
2 实验与结果分析
2.1 实验指标
本文的仿真实验采用UCI机器学习资源库提供的Appliances energy prediction Data Set作为数据样本,该数据库包含19 735个元组和29个属性。由于ADE-DDEW水印算法是对整数型的数值属性进行计算,所以对于浮点型属性值进行预处理,将其扩大成整数型数据然后通过差分扩展嵌入水印,最后等比例还原成浮点型。将ADE-DDEW算法与已有的GADEW[10]、GAHSW[8]、RF-GADEW[14]和RF-GAHSW[14]等可逆数据库水印算法进行对比实验分析。
本文通过对比原始水印比特位和提取的水印比特位的方法来衡量数据库水印算法的鲁棒性,即水印的误码率(BER,bit error rate)[8]。鲁棒性评价指标BER的计算如式(23)所示。

其中,为数据库的分组数,即水印序列的长度,W和分别是嵌入水印和提取水印的第位比特值。由式(23)可知,算法的鲁棒性和BER成反比,较低的误码率值意味着较高的水印鲁棒性。
对于数据库水印算法的嵌入容量,通过水印嵌入容量(WEC)来衡量,即计算嵌入水印的数据库元组占数据库元组的比例。对于数据失真,即嵌入水印后造成数据库数据的改变量。本文通过水印嵌入前后属性的平均值(Mean)、标准差(Std)的变化以及平均绝对误差(MAE)来量化其统计失真,MAE的计算如式(24)所示。

2.2 相关参数分析
在将水印嵌入数据库之前,需要对QR码和数据库进行预处理,使得嵌入的水印序列包含更多信息,提高嵌入容量。为了在相同长度下得到更多信息,经常采用数据压缩技术,这其中Haar小波变换效果最好,嵌入数字QR码和嵌入文本QR码的小波变换对比分别如表1和表2所示。

表1 嵌入数字QR码的小波变换对比

表2 嵌入文本QR码的小波变换对比
压缩率和绝对最大差异是衡量小波变换压缩效果的指标。压缩率越高,表示数据压缩的能力越好,信息密度越高;绝对最大差异越大,表示数据信息的多样性越好,过滤信号的能力越强。本文对不同像素的QR码进行了小波变换实验,从表1和表2可以看出,Haar小波变换的压缩率和绝对最大差异综合强于另外3种小波变换(Daubechies、Coiflet、Symlet)算法,这也是文本选用Haar小波变换压缩QR码的理由。
ADE-DDEW水印算法采用自适应差分进化算法计算最佳属性位,不同的种群规模对算法最优解的计算有一定的影响,种群规模过大导致算法的收敛速度下降,搜索时间增加;种群规模过小容易过早收敛,全局搜索能力差,影响算法的鲁棒性。对区间[10,120]的种群规模进行测试,不同种群规模下适应度值对比如图5所示,结果显示,当种群规模为90时,目标函数适应度值最小。

图4 取余值Valmod与数值改变量的关系
Figure 4 The residual value Valmodis plotted against the amount of change in value

图5 不同种群规模下适应度值对比
Figure 5 Comparison of the adaptation of different population sizes
除此之外,本文评估了迭代次数对于自适应差分进化算法的影响,分别进行了25、50、75、125、150、175和200次迭代。每迭代一次,ADE-DDEW算法给数据库随机产生一个新的初始种群参与族外竞争,避免差分进化陷入局部最优,适应度值和迭代次数的关系如图6所示。可以看出,当迭代次数为200时,ADE-DDEW算法达到最低的适应度值。

图6 适应度值和迭代次数的关系
Figure 6 Plot of the relationship between fitness value and number of iterations

图7 权重系数与目标函数关系
Figure 7 Graph of weight coefficients versus objective function
不同的嵌入属性列数可能会导致容量和数据失真不同,本文对10~29列的情况分别做实验,具体结果如图8所示。

图8 不同嵌入属性列数下水印嵌入容量和数据失真对比
Figure 8 Comparison of watermark embedding capacity and data distortion with different number of embedding columns
实验结果表明,选取28列属性嵌入水印,其嵌入容量较高、数据失真最小。因此,后面的实验都将选取28列属性进行水印的嵌入。
2.3 实验过程
(1)嵌入容量和数据失真对比实验
将本文提出的ADE-DDEW算法与已有的GADEW、RF-GADEW、GAHSW和RF-GAHSW算法进行水印嵌入容量和数据失真的对比。对于数据库水印算法来说,嵌入容量越大,数据失真越大。各水印算法嵌入容量和数据失真对比如图9所示。

图9 各水印算法嵌入容量和数据失真对比
Figure 9 Comparison of embedding capacity and data distortion by watermarking algorithm
从图9中可以看出,本文提出的ADE-DDEW算法在嵌入容量高的算法中数据失真最低,在数据失真低的算法中嵌入容量最高,有效缓解了水印嵌入容量和数据失真之间存在的矛盾。ADE-DDEW算法对数据进行了取余操作,限制了数据的变化范围,同时浮点型化为整型计算有效降低了数值改变量,因此水印不会造成过大的数据失真,采用差分扩展算法嵌入水印同时结合最小差值和差分进化算法确定水印嵌入位置提高了水印的嵌入容量。

表3 水印嵌入前后不同数据库水印算法的平均值和标准差统计结果
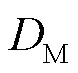


其中,Mean和Std分别代表原始数据库的平均值和标准偏差值,Mean和Std分别代表嵌入水印后数据库的平均值和标准偏差值。

表4 水印嵌入前后不同数据库水印算法的平均值、标准差变化和平均绝对误差统计结果
由表3和表4可知,ADE-DDEW算法的各个属性在平均值和标准差方面的变化非常小,其造成的最大变化是0.015,这与GADEW、RF-GADEW、GAHSW和RF-GAHSW算法相比可以忽略不计。另外,表中有一些变化值为0,表示该属性列没有嵌入水印。一般来说,水印算法对数据质量的影响越小越好,对于量化属性分布有失真的MAE来说也是如此。表中GADEW、RF-GADEW、GAHSW和RF-GAHSW算法的MAE值并不理想,分别为2.914、1.315、0.852和0.516,这意味着嵌入水印后会造成巨大的数据失真,影响数据库的可用性,而ADE-DDEW算法的MAE值为0.019,远远低于其他算法。实验结果验证了所提ADE-DDEW算法的有效性。综上所述,ADE-DDEW算法在统计失真方面的表现明显优于其他算法,保障了数据库的可用性。
(2)鲁棒性实验
本文通过检测水印的误码率(水印检测失败的比率)来判断在多种元组攻击下各数据库水印算法的鲁棒性,其中误码率越低,说明水印鲁棒性越好,当误码率接近零时,水印被正确地从数据库中检测出来。实验分析和对比了本文提出的ADE-DDEW算法与GADEW、RF-GADEW、GAHSW和RF-GAHSW算法在删除攻击、修改攻击和插入攻击下水印的误码率,分别完成0、10%、20%、30%至90%的攻击比例,取误码率的平均值作为最终结果。实验结果如图10~图12所示。
1)元组删除攻击
攻击者会随机删除元组以破坏水印,被删除的元组中可能嵌有水印,如果删除过多,会导致无法提取出正确的水印,影响版权的保护。删除攻击下各算法提取水印的误码率对比如图10所示。

图10 删除攻击下各算法提取水印的误码率对比
Figure 10 Comparison of BER of watermark extraction by algorithms under removal attack
从图10可以看出,当数据库受到严重删除攻击时,如数据库中被删除的元组达到90%,GADEW、RF-GADEW、GAHSW和RF-GAHSW算法提取水印的BER值分别为0.93、0.74、0.47和0.42,而ADE-DDEW算法的BER值为0.37。如果删除的元组中含有大量的水印信息,会影响到水印的完整提取。因此,删除攻击对数据库水印的影响最为严重。实验还表明,随着删除元组数量的增加,水印提取时的误码率随之增加,相较其他方法,ADE-DDEW算法的误码率曲线增长较为平缓且最大的误码率不超过0.4,在删除攻击下有更好的鲁棒性。
2) 元组修改攻击
攻击者会随机修改元组中的任意属性值以破坏水印,被修改的属性值中可能嵌有水印,如果修改过多,会导致无法提取出正确的水印,同时还原数据库过程也会受到影响。修改攻击比例下各算法提取水印的误码率对比如图11所示。

图11 修改攻击下各算法提取水印的误码率对比
Figure 11 Comparison of BER of watermark extraction by each algorithm under modified attack
从图11可以看出,修改攻击的强度和水印的误码率成正比,ADE-DDEW算法的整体误码率明显低于其他水印算法,即使修改了90%的元组属性值,ADE-DDEW算法的误码率也只有0.25,也能恢复大部分的水印信息和原始数据,是高度稳健的水印算法,有利于溯源攻击者。
3) 元组插入攻击
元组插入攻击是随机创建元组并插入数据库以破坏水印的一种攻击。元组插入攻击下提取水印的误码率对比如图12所示。
实验结果表明,对于利用差分扩展进行水印嵌入的数据库水印算法来说,向数据库添加元组这种攻击方式不会对水印信息完整正确地提取造成影响,也就是说,无论插入多少元组,在插入攻击下的误码率始终为0。因此,ADE-DDEW算法对插入攻击具有极强的鲁棒性。

图12 元组插入攻击下提取水印的误码率对比
Figure 12 Comparison of BER of extracted watermark under tuple insertion attack
综上所述,ADE-DDEW算法在删除攻击、修改攻击和插入攻击下水印误码率增长缓慢,特别是对于插入攻击,可以完全提取出正确的水印。可见ADE-DDEW算法可以抵御常见的数据库攻击,具有良好的鲁棒性。
(3)溯源效果展示
ADE-DDEW算法嵌入的水印是经过压缩的QR码,其中文本QR码带有“njupt”的身份信息,数字QR码带有“20211216”的身份信息。提取出的水印序列通过一系列的逆运算还原出QR码,扫描QR码就可以得到唯一标识攻击者的身份信息,以达到追踪溯源的目的。本文提取攻击实验后的水印序列,将其还原成对应的QR码与嵌入的QR码进行对比,检测算法的追踪溯源能力。待嵌入QR码图像如图13所示。

图13 待嵌入QR码图像
Figure 13 QR code image to be embedded
各攻击下提取的QR码图像如表5所示。QR码有极强的容错率,即使提取的水印存在一定的无码率,还原的QR码也能够扫描出身份信息。由上述图表可知,即使在攻击比例高(90%)的情况下,扫描QR码仍然可以准确无误地扫描出“njupt”和“20211216”这两个身份信息,能够准确地追踪到攻击者。

表5 各攻击下提取的QR码图像
(4)数据库还原实验


图14 不同攻击比例下ADE-DDEW算法的数据改变情况
Figure 14 Data alteration of ADE-DDEW algorithm for different attack ratios
由图14可知,即使大部分数据被攻击,ADE-DDEW算法也可以恢复原始数据,即使大量数据被破环,也可以恢复将近一半的数据,说明ADE-DDEW算法具有良好的还原性。
3 结束语
考虑到提高水印嵌入容量和减小数据失真存在的固有矛盾问题,本文提出了一种基于动态差分扩展的强鲁棒数据库水印算法。用QR码作为水印载体,利用Haar小波变换进行数据压缩并且通过SVD提取QR码的特征值,作为待嵌入的水印序列,增大了相同水印序列长度下水印包含的信息量。同时过滤多种信号攻击,提高图像抵御攻击的能力。该算法结合自适应差分进化算法和最小差值算法选择最佳嵌入属性位,通过动态地选取传统差分扩展算法或改进的差分扩展技术进行水印的嵌入,以缓解传统差分扩展算法在嵌入水印时计算效率低、数据失真大、鲁棒性差的问题,提高水印嵌入容量的同时减少数据失真。本文通过实验验证了数据库水印算法的可行性,该算法在一定的数据失真范围内能有效地提高水印的嵌入容量,在数据库遭受攻击时表现出良好的鲁棒性,能够有效地溯源泄密者,且与现有的算法对比优势明显。
[1] HOLT L, MAUFE B G, WIENER A. Encoded marking of a recording signal[P]. U L Patent GB2196167A, 1988.
[2] HIMANSHU A, FAROOQ H. Development of payload capacity enhanced robust video watermarking scheme based on symmetry of circle using lifting wavelet transform and SURF[J]. Journal of Information Security and Applications, 2021, 59.
[3] SHOHIDULISLAM M, NAQVI N, ABBASI A T, et al. Robust dual domain twofold encrypted image-in-audio watermarking based on SVD[J]. Circuits, Systems, and Signal Processing, 2021 (prepublish).
[4] 赵春雨. 提高嵌入容量的水印算法研究[D]. 郑州: 郑州大学, 2011.
ZHAO C Y. Research on algorithm for improving the capacity of digital watermarking[D]. Zhengzhou: Zhengzhou University, 2011.
[5] ZHANG Y, YANG B, NIU X M. Reversible watermarking for relational database authentication[J]. Journal of Computers, 2006, 17(2): 59-66.
[6] HU D, ZHAO D, ZHENG S. A new robust approach for reversible database watermarking with distortion control[J]. IEEE Transactions on Knowledge and Data Engineering, 2018, 31(6): 1024-1037.
[7] GUPTA G, PIEPRZYK J. Reversible and blind database watermarking using difference expansion[J]. International Journal of Digital Crime and Forensics, 2009, 1(2): 42-54.
[8] JAWAD K, KHAN A. Genetic algorithm and difference expansion based reversible watermarking for relational databases [J]. Journal of Systems and Software, 2013, 86(11): 2742-2753.
[9] 邱升红. 面向关系数据库的可逆水印方法研究[D]. 西安: 西安电子科技大学, 2018.
QIU S H. Research on reversible watermarking methods for relational databases[D]. Xi'an: Xi'an University of Electronic Science and Technology, 2018.
[10] 宋岩, 沈泉江, 杨洪山. 基于布谷鸟算法的可逆数据库水印方案[J]. 计算机应用与软件, 2021, 38(12): 304-313.
SONG Y, SHEN Q H, YANG H S. A reversible database watermarking scheme based on cuckoo algorithm[J]. Computer Application and Software, 2021, 38(12): 304-313.
[11] 孔嘉琪, 王利明, 葛晓雪. 基于模拟退火和粒子群混合改进算法的数据库水印技术[J]. 信息网络安全, 2022, 22(5): 37-45.
KONG J Q, WANG L M, GE X X. Database watermarking technique based on simulated annealing and particle swarm hybrid improvement algorithm[J]. Information Network Security, 2022, 22(5): 37-45.
[12] SHI Y, LI X, ZHANG X, et al. Reversible data hiding: advances in the past two decades[J]. IEEE Access, 2016, 4(10): 3210-3237.
[13] GE C, SUN J, SUN Y, et al. Reversible database watermarking based on random forest and genetic algorithm[C]//2020 International Conference on Cyber-Enabled Distributed Computing and Knowledge Discovery (CyberC). 2020.
[14] 陈青, 夏兰婷, 卜莹. 基于两级奇异值分解的鲁棒水印算法[J]. 应用科学学报, 2020, 38(6): 966-975.
CHEN Q, XIA L T, BU Y. Robust watermarking algorithm based on two-level singular value decomposition[J]. Journal of Applied Sciences, 2020, 38(6): 966-975.
[15] 关虎, 张桂煊, 张树武, 等. 基于二维码的鲁棒图像水印技术及应用研究[J]. 有线电视技术, 2018(10): 20-26.
GUAN H, ZHANG G X, ZHANG S W, et al. Research on robust image watermarking technology and application based on QR code[J]. Cable TV Technology, 2018(10): 20-26.
[16] KLEMA V, LAUB A. The singular value decomposition: its computation and some applications[J]. Automatic Control IEEE Transactions on, 1980, 25(2): 164-176.
[17] STORNR P K.Differential evolution: a simple and efficient adaptive scheme for global optimization over continuous spaces[R]. 1995.
[18] TIAN J. Reversible data embedding using a difference expansion[J]. IEEE Transactions on Circuits & Systems for Video Technology, 2003, 13(8): 890-896.
Research on strong robustness watermarking algorithm based on dynamic difference expansion
WANG Tianqi1,2,3, ZHANG Yingzhou1,2,3, DI Yunlong1,2,3, LI Dingwen1,2,3, ZHU Linlin1,2,3
1. Department of Computer Science, Nanjing University of Posts and Telecommunications, Nanjing 210023, China 2. Department of Software, Nanjing University of Posts and Telecommunications, Nanjing 210023, China 3. Department of Cyberspace Security, Nanjing University of Posts and Telecommunications, Nanjing 210023, China
A surge in the amount of information comes with the rapid development of the technology industry. Across all industries, there is a need to collect and utilize vast amounts of data. While this big data holds immense value, it also poses unprecedented challenges to the field of data security. As relational databases serve as a fundamental storage medium for data, they often contain large-scale data rich in content and privacy. In the event of a data leak, significant losses may occur, highlighting the pressing need to safeguard database ownership and verify data ownership. However, existing database watermarking technologies face an inherent tradeoff between improving watermark embedding capacity and reducing data distortion. To address this issue and enhance watermark robustness, a novel robust database watermarking algorithm based on dynamic difference expansion was introduced. The QR code was employed as the watermark, the SVD decomposition of the low frequency part of the image was utilized after Haar wavelet transform. By extracting specific feature values and using residual feature values as the watermark sequence, it was ensured that the same-length watermark sequence contains more information and the embedded watermark length can be reduced. Furthermore, by combining the adaptive differential evolution algorithm and the minimum difference algorithm, the optimal embedding attribute bits were selected to alleviate the problems of low computational efficiency, high data distortion and poor robustness of traditional difference expansion techniques in embedding watermarks, and to improve the embedding capacity of watermarks while reducing the distortion of data. Experimental results demonstrate that the proposed algorithm achieves a high watermark embedding rate with low data distortion. It is resilient against multiple attacks, exhibiting excellent robustness and strong traceability. Compared to existing algorithms, it offers distinct advantages and holds great potential for broad application in the field of data security.
database watermarking, differential evolution, difference expansion, singular value decomposition, Haar wavelet transform, quick response code
TP393
A
10.11959/j.issn.2096−109x.2023065

汪天琦(1997−),女,安徽合肥人,南京邮电大学硕士生,主要研究方向为数字水印技术。
张迎周(1978−),男,安徽庐江人,博士,南京邮电大学教授,主要研究方向为软件与信息安全。

邸云龙(1996−),男,安徽滁州人,博士,南京邮电大学硕士生,主要研究方向为数字水印技术。
李鼎文(1998− ),男,江苏南京人,南京邮电大学硕士生,主要研究方向为数字水印技术。

朱林林(1997−),女,山东德州人,南京邮电大学硕士生,主要研究方向为数字水印技术。
2022−04−02;
2022−11−21
张迎周,zhangyz@njupt.edu.cn
汪天琦, 张迎周, 邸云龙, 等. 基于动态差分扩展的强鲁棒数据库水印算法研究[J]. 网络与信息安全学报, 2023, 9(5): 150-165.
WANG T Q, ZHANG Y Z, DI Y L, et al. Research on strong robustness watermarking algorithm based on dynamic difference expansion [J]. Chinese Journal of Network and Information Security, 2023, 9(5): 150-165.
猜你喜欢
新世纪智能(数学备考)(2021年5期)2021-07-28
电脑报(2021年14期)2021-06-28
农业机械学报(2020年2期)2020-03-09
中华建设(2019年7期)2019-08-27
计算机与生活(2019年5期)2019-07-18
吉林大学学报(理学版)(2018年2期)2018-03-29
项目管理技术(2016年12期)2016-06-15
西南交通大学学报(2016年6期)2016-05-04
信息安全研究(2015年3期)2015-02-28
太空探索(2014年1期)2014-07-10
