
基于强化学习算法的水下滑翔机路径跟踪研究
2023-11-28 09:40:12石晴晴张润锋张连洪兰世泉
中国机械工程 2023年9期
石晴晴 张润锋 张连洪 兰世泉

摘要:针对洋流影响下水下滑翔机实际路径与预定路径偏差较大的问题,在传统的长短期记忆网络模型的基础上引入注意力机制,建立了具有长短期记忆与注意力机制的神经网络洋流预测模型;利用深度神经网络生成水下滑翔机运动的动态Q表,并通过强化学习算法选择最优运动姿态,同时考虑洋流的影响,构造了基于深度强化学习的水下滑翔机路径跟踪算法。结果表明,基于注意力机制的长短期记忆网络相较于传统的整合移动平均自回归模型与长短期记忆网络,其洋流预测具有更小的均方误差与均方根误差,具有良好的预测能力;相较于传统的PID控制,深度强化学习模型可使水下滑翔机轨迹均方根误差降低50.9%,显著提高了路径跟踪精度。
关键词:水下滑翔机;路径跟踪;注意力机制;强化学习
中图分类号:U665
DOI:10.3969/j.issn.1004-132X.2023.09.011
Research on Underwater Gliders Path Tracking Based on Reinforcement Learning Algorithm
SHI Qingqing ZHANG Runfeng ZHANG LianhongLAN Shiquan1,2
Abstract: Aiming at the large deviations between the actual paths and the predetermined ones of underwater gliders affected by ocean current, a neural network ocean current prediction model with long-term and short-term memory and attention mechanism was established based on the traditional long-term and short-term memory network model.The dynamic Q-table of underwater glider motions was generated by depth neural network, and the optimal motion attitude was selected by reinforcement learning algorithm. Considering the influences of ocean current, an underwater glider path tracking algorithm was constructed based on depth reinforcement learning. The results show that the long-term and short-term memory network based on attention mechanism has less mean square errors and root mean square errors in ocean current prediction than that of the traditional integrated moving average autoregressive model and long-term and short-term memory network.Compared with the traditional PID control, the deep reinforcement learning model may reduce the root mean square errors of the underwater glider trajectory by 50.9%, and significantly improve the path tracking accuracy.
Key words: underwater glider; path tracking; attention mechanism; reinforcement learning
0 引言
水下滑翔機具有能耗低、成本低、效率高、续航长、隐身能力强、可重复使用等优点,在海洋环境观测、军事侦察等领域具有广泛的应用前景[1]。相较于其他自主式水下航行器(autonomous underwater vehicle, AUV),水下滑翔机单纯使用浮力驱动方式,其航迹控制和定位精度较低、航速慢,对海洋环境具有极大的依赖性,海洋中复杂洋流和极端气象环境等都会使其偏离预定航线,从而降低路径追踪的精度[2]。
路径规划问题一直是水下滑翔机研究的重点问题之一,合适的路径规划方式可以降低能耗,减小路径偏差,精确到达采样点,完成预定任务。水下滑翔机路径规划可分为全局路径规划与局部路径规划,其中全局路径规划旨在制定出最优预设路线,局部路径规划旨在通过控制水下滑翔机的实时动作从而完成实际航行轨迹和预设路径的拟合工作[3]。国内外学者对机器人局部路径规划中的路径跟踪问题进行了研究。传统的路径跟踪方法主要有自适应积分视线法、纯跟踪法、比例积分微分控制法及滑模控制技术等。LI等[4]将自适应积分视线与非线性迭代相结合,同时研究了子路径切换算法以解决欠驱动自主水下航行器的复合曲线路径跟踪问题。YAO等[5]研究了欠驱动自主水下航行器的三维直线路径跟踪问题,硬件层面采用滑模控制技术改进了动态控制器,软件层面采用基于模型预测控制的改进方法,不仅提高了水下航行器的跟踪质量,而且有效地降低了方向舵角的均方误差和饱和率,使整个系统更稳定更节能。田宇等[6]利用Serret-Frenet坐标系描述路径跟踪误差,以PID控制器作为水下滑翔机路径跟踪控制器,设计出一种改进的三维路径跟踪制导函数以解决欠驱动自主水下机器人三维路径跟踪问题,提高了水下机器人的路径跟踪精度。王宏建等[7]采用滤波反步法设计路径跟踪控制器,以解决欠驱动水下航行器的三维路径跟踪问题,主要通过二阶滤波过程获得虚拟控制量的导数,可避免直接对虚拟控制量解析求导,同时滤除了高频测量噪声,增加了系统对噪声的鲁棒性。ISERN-GONZLEZ等[8]利用迭代优化方法对水下滑翔机的路径跟踪问题进行了研究,将水下滑翔机实际路径与预定路径之间的面积总和作为损失函数,通过不断迭代优化降低损失函数值,使实际路径逐渐收敛于预定路径。HUANG等[9]提出了“广义洋流”的概念,将水下滑翔机自身的缺陷问题及洋流对水下滑翔机航向的影响问题全部归结于“广义洋流”对水下滑翔机的影响,将“广义洋流”应用于水下滑翔机的动力学公式并利用迭代算法得出最优航向角以实现水下滑翔机路径跟踪控制,该方法计算成本低且没有增加额外的传感器。HUO等[10-11]根据不同流量条件与平均流量的相对强度,将洋流分为以潮汐流为主和以瞬时流为主,采取流量抵消策略计算滑翔机的转向角使其遵循预定路径,在此基础上对路径跟踪误差进行进一步分析,发现在空间变化的流量相对较高的情况下,使用时间平均流场进行路径跟踪控制可使水下滑翔机路径跟踪误差更小。
近年来国内外学者针对水下滑翔机路径跟踪问题的研究包括从简单的迭代优化控制算法与PID控制算法逐步扩展到相对复杂的视线导航算法、滑模控制算法以及多种算法融合,从水下滑翔机二维路径跟踪算法扩展到水下的三维路径跟踪算法,这些研究主要体现在对控制器的优化及其与水下滑翔机动力学的结合方面。目前传统的路径跟踪方法主要存在以下弊端:①大多数学者将环境视为已知变量或可观测变量,然而海洋洋流受海面风应力、大气运动、热盐效应及地球自转等多种因素综合影响,在时间上和空间上一直处于不断变化的状态,此外多数水下滑翔机在执行任务时并不携带测流装置,故无法将海洋洋流变量视为已知变量或可观测变量。②水下滑翔机动力学模型具有非线性和强耦合的特点,部分动力学模型参数无法准确获得。此外,洋流的速度与水下滑翔机速度处于同一数量级,可使水下滑翔机在水面时产生随洋流漂浮的现象。③传统的PID控制器、滑模控制器及模糊控制等算法的参数设定多取决于人工经验,设定的参数在某一环境下表现良好,面对复杂的动态海洋环境需要人工不断调整参数,精度较低。故传统的路径跟踪算法应用于水下滑翔机领域可能会产生相对较大的路径跟踪误差。
随着人工智能技术的飞速发展,机器学习、强化学习与神经网络等被广泛应用于各类机器人的运动控制中,取得了令人满意的效果。其中,在强化学习中,智能体通过与环境的交互和学习来不断调整自身的行为策略并使之达到最优,并不依赖于精确的环境模型,适用于复杂多变的海洋环境。如潘昕等[12]将长短时记忆网络(LSTM)引入Soft Actor Critic框架中以解决二维路径跟踪问题,以较少的状态变量训练网络,能够在满足路径跟踪精度的情况下具有更好的鲁棒性和更快的收敛速度。李泽宇等[13]采用Q-Learning方法,根据无人潜航器的航速、跟踪误差及其变化率等参数,对滑模控制参数进行离线训练优化,同时通过搭建径向基函数(RBF)网络加快训练过程,避免Q表指数增加导致的维数灾难现象,将训练得到的RBF-Q学习网络应用于在线控制,从而提高路径的跟踪性能。邵俊恺等针对无人驾驶铰接式运输车辆无人驾驶智能控制问题,提出了一种强化学习自适应PID路径跟踪控制算法,通过强化学习算法对PID参数进行在线自适应整定,能够有效减小超调和震荡,实现精确跟踪参考路径[14]。相比传统路径跟踪控制方法,深度强化学习算法具有以下优势:①深度强化学习可将深度学习的感知能力与强化学习的决策能力相结合,通过端对端的学习方式实现从原始输入到输出的直接控制;②神经网络可通过梯度下降方式进行神经网络参数更新,实现控制器参数快速自整定,满足不同环境下水下滑翔机航向控制问题;③利用深度学习神经网络不需要精确求解水下滑翔机非线性的动力学问题,仅靠运动学即可解决路径跟踪问题的优势,可避免动力学模型及其求解误差对路径跟踪精度的影响。综上,深度强化学习算法具有较高的可行性与优越性。
针对水下滑翔机驱动力小以及洋流变化形式复杂多样等问题,本文利用差分整合移动平均自回归模型、长短期记忆网络及基于注意力机制的长短期记忆网络三种方法,基于历史洋流数据对未来洋流数据进行预测。同时采用传统PID控制、强化学习方法及深度强化学习方法对水下滑翔机的航向进行控制,最终得到最优路径跟踪方法,使水下滑翔机能够按照预定路径航行,减小路径偏差,最后进行了仿真实验以验证算法的有效性。
1 流场建模與流场预测
1.1 深度平均流流场建模
水下滑翔机一个运行周期可分为水面悬浮等待指令阶段及水下航行执行任务阶段两个阶段。水下滑翔机在水面时可通过GPS获取其真实位置信息,然而当水下滑翔机在水面以下时处于失联状态,无法获得其位置与姿态等信息,只能通过航位推算获取位置信息。由于海洋洋流的影响,推算的出水点位置信息与实际出水点位置信息存在一定的偏差,将该偏差完全视为由海洋洋流导致(图1),由此可得出:
式中,yt为当前值;μ为常数;γi为自相关系数;βi为移动平均项系数;εt为残差序列。
本文选用 (175°E,56.5°N) 到 (176.5°E,56.5°N) 海域内300组深度平均流数据作为一个数据集用来进行海洋洋流数值预测,将数据集以70%为界限分为训练数据集及测试数据集。进行预测前需要进行数据平稳性检验,否则可能会产生数据伪回归现象从而导致预测失效。由图2可以看出自相关系数q阶震荡衰减最终趋于零,证明了选用ARIMA模型进行时间序列预测的合理性,通过自相关图可选择合理的p、q参数值。其次需要进行模型验证,主要对残差进行分析,确保所选模型的残差为白噪声,由图3、图4可以看出,洋流数据的残差值在0附近摆动,均值接近于0,并且残差密度满足正态性,说明残差序列为典型的白噪声序列,由上可判断预测模型选择的正确性。最后将深度平均流数据集应用于ARIMA模型,图5、图6所示为实际预测结果。
1.3 长短期记忆网络模型洋流预测
长短期记忆人工神经网络 (long short-term memory, LSTM)是一种时间循环递归神经网络(recurrent neural network,RNN)的改进算法,可用于解决长距离依赖以及梯度消失等问题,广泛应用于时间序列预测、语音识别及自然语言处理等方面[18-19]。LSTM网络相较于RNN网络,增加了一个可用于判断信息的记忆单元(cell)以解决RNN网络中存在的梯度爆炸及梯度消失的问题。LSTM网络中最关键的是记忆单元的状态,为了保护和控制记忆单元的状态,将输入门、遗忘门和输出门三个控制门放置于一个记忆单元中[19]。
在LSTM网络结构单元中,F表示遗忘门,I表示输入门,C表示细胞状态,O表示输出门。其中,Ct表示当前时刻t的细胞状态,Xt表示时刻t的输入,ht表示当前时刻t的输出以及下一个细胞状态的输入。Ft、It和Ot分别表示遗忘门、输入门和输出门的输出状态[19]。
在LSTM预测过程中,首先在遗忘门读取出上一时刻的输出ht-1及当前输入Xt,然后采用Sigmod函数作为判断函数以实现在细胞状态中丢弃信息的功能。即
式中,Wo为输出层权重矩阵;bo为输出层偏置矩阵。
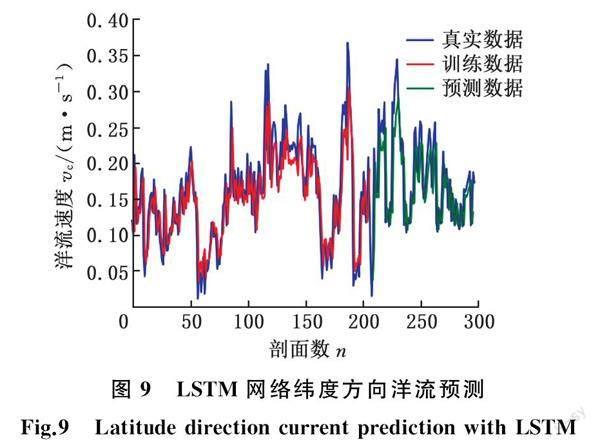
式(6)~式(10)表示LSTM网络的前向传播过程,反向传播过程与传统的前馈神经网络类似。LSTM网络通过利用输出层的误差反向求解出各层权重值,并通过梯度下降的方式完成权重系数的更新。在相同条件下利用LSTM网络对局部区域海洋洋流数据进行预测,结果见图8和图9。
1.4 基于注意力机制的LSTM模型洋流预测
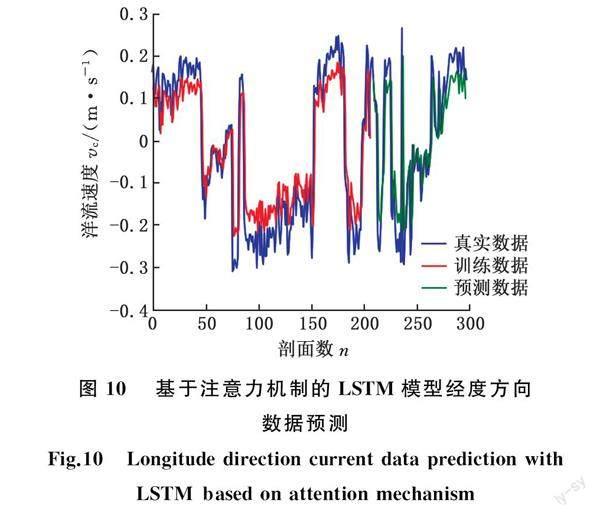
注意力(attention)机制即从大量信息中快速筛选出高价值重点信息进行处理而忽略其他非重点信息,当神经网络处理多输入信息时, 可以借鉴人脑的注意力机制概念,快速选择高价值重点信息进行处理[20-21]。将注意力机制引入LSTM 预测模型中,能对高价值的历史时间节点特征赋予更高的权重值,从而改善预测效果。建模时将中间输出结果与对应的输出序列值联系起来,并通过训练模型学习选择性地关注对输出结果影响较大的输入数据,为相关性更高的输入向量赋予更高的权重[22]。注意力机制的输入是当前状态以及侧重关注的特征,通常以softmax函数作为激活函数,输出是对特征的softmax函数打分,在后续处理中,使用该打分功能进行过滤[23]。LSTM网络能学习到序列的深度特征,并对序列的隐藏状态和记忆状态进行同层及跨层的传递,引入注意力机制,将输入层的不同时刻对预测结果的影响力做出了区分,将对输出结果影响较大的序列赋予更高的权重并进行深入学习,从而提高模型学习的效率,在一定程度上解决长依赖问题[24]。与ARIMA模型一样在相同的条件下进行海洋洋流模型预测,LSTM模型的预测结果见图10和图11。
1.5 预测结果及分析
本文选用ARIMA、LSTM及基于注意力机制的LSTM三种方法对相同时间相同地域的洋流数据在同一条件下进行预测并得出预测结果。为了更加准确地衡量不同方法的预测效果,本文采用了平均绝对误差 (mean absolute error, MAE)、均方误差(mean square error, MSE)和均方根误差 (root mean square error, RMSE)三种评价方法作为评价模型预测性能的指标,其计算公式如下:
式中,yi、y′i分别为洋流数据的真实值和预测值。
在预测过程中LSTM与基于注意力机制的LSTM所采用的优化函数均为MSE函数,将ARIMA、LSTM以及基于注意力机制的LSTM三种方法所得海洋洋流时间序列预测结果进行对比。由表1可得,LSTM在经度及纬度方向的平均绝对误差分别为0.0450 m/s和0.0316 m/s,基于注意力机制的平均绝对误差在经度及纬度方向分别为0.0464 m/s和0.0327 m/s,略低于LSTM方法的相应值。然而在均方误差及均方根误差方面,基于注意力机制的LSTM预测方法在经度以及纬度两个方向均优于其他两种预测方法。在经度方向,基于注意力机制的均方误差和均方根误差分别为0.0124 m/s和0.1123 m/s,相较于ARIMA分别降低了7.25%、3.5%,相较于LSTM分别降低了1.44%、0.72%。在纬度方向,基于注意力机制的均方误差和均方根误差分别为0.0020 m/s和0.0447 m/s,相较于ARIMA分别降低了15%、8.3%,相较于LSTM分别降低了10%、3.8%。综上,基于注意力机制的LSTM预测方法相较于其他两种方法预测能力具有显著优势,预测结果与实际数据更加吻合。
2 水下滑翔机路径跟踪
2.1 水下滑翔机运动特征
相较于其他水下无人潜水器,水下滑翔机不依靠螺旋桨产生的动力向前滑翔,而是通过改变排油量以改变自身的体积,从而产生相应的净浮力进行上浮或下潜运动,并在机翼上产生升力,机翼升力水平分量推动水下滑翔机水平向前运动,垂直潜浮和水平向前运动合成滑翔运动[25-27]。在海洋中可将水下滑翔机看作一个六自由度设备,利用滑翔速度及对应的水平(u)和竖直(v)速度分量等参数来描述水下滑翔机的速度,利用滑翔速度与水平面夹角(滑翔角τ)、滑翔机轴线与水平面夹角(俯仰角θ)及滑翔速度与水下滑翔机轴线夹角(攻角α)等参数来描述水下滑翔机的角度。
水下滑翔机可通过调整自身质量块的移动量来改变俯仰角与滑翔角等参数,从而改变水下滑翔机的运动姿态。在水下滑翔机上浮时,需要改变水下滑翔机的排油量同时移动内部质量块,使浮力大于重力同时浮力位于重力前方,所产生的扶正力矩使水下滑翔机仰头,直至重力、浮力作用线重合。同理,当机身需要向左横滚时,将机翼位于浮心之后,机翼升力的水平分量对浮心产生偏转力矩,使机艏向右偏转,同时提供向左的向心力。水下滑翔机的运动特性使它只能以“锯齿”型轨迹在海洋中进行观测探测。
2.2 基于PID的路径跟踪
PID控制算法是一种传统的机器人运动控制算法,PID控制算法将比例、积分及微分三种环节融于一体,实质上是根据水下滑翔机实际出水点与推算的出水点之间的偏差值,按照比例、积分、微分的函数关系进行运算,将运算结果用以控制水下滑翔机的航向。PID控制算法应用广泛,具有原理简单、易于实现以及参数选定简单等优点[24]。连续控制系统的理想PID算法控制规律为
(14)
式中,KP为比例增益;Tt为积分时间常数;TD为微分时间常数;u(t)为PID控制器的输出信号;e(t)为输入信号r(t)与输出信号y(t)之差[28]。
水下滑翔机利用PID控制器的控制原理如图12所示。
水下滑翔机在海洋中执行任务过程中会受到多种环境因素影响而偏离预定航线,本文只考虑海洋洋流这一因素对水下滑翔机偏离航线的影响并利用PID控制器對水下滑翔机航向进行不断调节,使路径跟踪误差降至最低。依据深度平均流的概念将海洋洋流分为南北方向与东西方向,由于海洋洋流的大小和方向等参量与位置、时间和表面风等因素有关,故在洋流的影响下,水下滑翔机的实际出水点与预定航线会出现一定的偏差。在PID控制中可将偏差经过比例环节、积分环节和微分环节的同步作用对水下滑翔机的航向进行调节,不断缩小偏差,最终使水下滑翔机从起始点到达目标点。
2.3 基于强化学习路径跟踪
强化学习(reinforcement learning, RL)是机器学习领域的方法之一,主要用于解决智能体如何在与环境的交互过程中通过学习行为策略采取不同的行动,以最大限度地提高奖励值或实现特定目标的问题[29]。本文主要利用强化学习模型解决水下滑翔机路径跟踪问题,使水下滑翔机路径跟踪误差降至最低。本文将水下滑翔机路径跟踪问题建模为一个马尔科夫决策过程 (Markov decision processes, MDP),通过不断学习与训练以实现跟踪误差最小的目标[29]。利用一个四元元组(S、A、P、R)对MDP模型进行表示,其中S、A、R分别表示状态集、动作集和奖励集,P为状态转移概率。在MDP模型中,假设Rt和St为具有离散的概率分布的随机变量,且仅依赖于状态St-1和动作At-1的作用。对于所有的S′,s∈S,r∈R,a∈A(s),Pr指这些值从时间t-1到时间t出现的概率[30],则有
2.4 基于强化学习路径跟踪
传统的强化学习算法相对比较简单,不存在收敛性问题。但是随着所需考虑因素的增加,状态空间S和动作空间A随之增大,Q表会呈指数增长,从而导致维数灾难。针对维数灾难问题,可将深度卷积神经网络和与强化学习相结合,通过卷积神经网络生成动态Q表,减少Q表爆炸增长以解决复杂空间的维数灾难问题,与此同时可在一定程度上解决非线性函数近似表示值函数的不稳定问题。
强化学习与深度强化学习目标都是通过利用智能体与环境交互学习来找到最优的行为策略,使长期奖励最大化,两者之间的根本不同在于增加了深度神经网络。深度强化学习算法定义了两个结构完全相同且两者之间相对独立的网络,网络包含一层隐藏层,两层全连接层,分别将其称为训练网络和目标网络。其中,训练网络主要用于拟合值函数Q,其表达式为
Q(s(t),a(t),w)≈Q*(s(t),a(t))(23)
目标网络用于获得目标Q值,目标网络Q值定义为
Q=r(s(t),a(t))+λmax Q(s(t+1),a(t+1);ω-)(24)
式中,ω为评估Q网络的权重参数;ω-为目标Q网络的权重参数。
在学习的过程中,智能体通过与环境进行交互获得对应的奖励值,以奖励值为目标函数,通过目标函数最大化以实现训练网络的学习。首先智能体将与环境交互得到的奖励与状态更新情况存放于经验池中,当经验池中存储的样本量大于随机抽样的样本量时开始训练,经过设定步数的训练后,最终将训练网络中得到的参数全部赋值给目标网络。在训练阶段,从经验池中随机抽取小批样本作为目标网络的输入。在每一步训练中,深度强化学习算法通过最大化目标函数最小化损失函数以更新神经网络隐藏层参数,将损失函数定义为
Loss=E[(Q-Q(si,ai,ω))2](25)
首先根据当前从经验池中抽取的样本来计算评估网络参数ω的梯度△ω, 其次使用自适应估计算法更新评估Q网络的参数ω,目标网络的参数ω-是在一段时间后将评估Q网络的参数ω直接赋值更新,即
ωt+1=ωt+E[Q-Q(s(t),a(t),ω)]△Q(s(t),a(t),ω)(26)
为了减少训练样本之间的相关性,可设置经验回放单元,同时还可改善神经网络逼近强化学习的动作值函数不稳定的问题。在每次训练的过程中,从经验库中随机均匀选取一批样本与训练样本混合在一起,破坏相邻训练样本的相关性,从而提高样本利用率。
2.5 仿真与分析
本文利用Python平台及其TensorFlow、Keras等工具包构造洋流模型,搭建出水下滑翔机航行环境,模拟水下滑翔机在不同海洋环境下的运动,并利用三种控制模型实现水下滑翔机直线路径跟踪的研究目标。在利用Python进行水下滑翔机路径跟踪仿真的过程中,选择任务的起始点为(10 km, 110 km),目标点为(190 km, 110 km),定义水下滑翔机的航行深度为800 m,俯仰角为23°,由水下滑翔机运动特性可得单剖面航行距离约为3.77 km,取洋流在东西方向与南北方向的最大速度均为0.15 m/s。三种控制模型的仿真结果如图13和表2所示。
由图12和表2可以看出,在仿真环境相同的条件下,强化学习算法相较于传统的PID控制算法在最小误差、最大误差、平均绝对误差及均方根误差等方面均具有明显的优势,利用强化学习算法所得路径平均绝对误差为PID控制算法的51.6%,均方根误差仅为PID控制算法的50.9%,证明利用强化学习算法所产生的水下滑翔机路径与预定路径的吻合性更好,精确度更好。深度强化学习在强化学习的基础上引入深度神经网络的同时引用了另外一个相同的目标网络,利用双向网络对路径跟踪进行仿真来提高精度和减小误差。深度强化学习相较于强化学习在平均绝对误差方面提高了16.76%,在均方根误差方面提高了16.29%。以上均表明利用深度强化学习算法所产生的水下滑翔机路径更平滑,波动性更小,更有助于节约水下滑翔机航行能耗。
3 水下滑翔机路径跟踪海试实验
3.1 海试实验概述
本文以天津大学自主研发的“海燕-L”号长航程水下滑翔机为海试实验平台,对本文算法的适用性与有效性进行验证评估,如图14、图15所示。
“海燕-L”水下滑翔机于2022年7月于南海某海域进行海试任务,其试验水深为800 m,本文选取20个剖面用于深度强化学习路徑跟踪算法的评估验证海试实验,其中10个剖面用于验证深度强化学习算法路径跟踪能力,另外10个剖面采用水下滑翔机传统路径跟踪方法用于对比实验。
3.2 海试实验步骤
(1)对水下滑翔机进行硬件检查、配平工作及初始化参数设置等工作。
(2)到达指定海域后,水下滑翔机上电与岸基控制中心通信进行相关参数更改工作。
(3)将水下滑翔机进行布放,观察其入水姿态,通过上位机控制面板设置初始剖面深度。
(4)不断更改水下滑翔机剖面深度直至到达指定深度。
(5)当水下滑翔机正常运行后,选定水下滑翔机实验验证与评估的初始剖面,将初始剖面位置纬度作为水下滑翔机预定直线航线,在该实验中水下滑翔机的运行方向为从西向东。
(6)调整水下滑翔机的排油量及俯仰角等为固定参数,调节其航向角并发送下潜指令。
(7)水下滑翔机完成该剖面上浮至水面后记录其位置信息,获得该剖面深度平均流数值,利用基于注意力机制的LSTM算法对下一剖面洋流数据进行预测。
(8)根据水下滑翔机实际出水点位置信息获取瞬时奖励,同时考虑洋流干扰,利用深度强化学习算法得出最优航向角。
(9)在上位机中更改水下滑翔机目标航向角为最优航向角,发送下潜指令开始执行下一剖面观测任务。
(10)重复步骤(7)~(9),直至完成10个剖面任务。
(11)选择对比实验初始剖面,将水下滑翔机的初始剖面位置纬度作为其预定直线航线,在该实验中水下滑翔机的运行方向为从西向东。
(12)水下滑翔机按照传统比例控制完成连续10个剖面的路径跟踪任务。
3.3 海试实验结果分析
将水下滑翔机传统控制算法路径跟踪与利用深度强化学习水下滑翔机轨迹跟踪所得的结果进行整理,结果如图16所示。
由图16可知根据深度强化学习算法对水下滑翔机进行航向控制解决路径跟踪问题的效果优于传统控制算法。利用传统的控制算法对水下滑翔机进行航向控制,其实际出水点位置与预定路径之間存在较大的偏差,海试实验中10个剖面产生的误差均值为1511 m。而利用深度强化学习算法对水下滑翔机进行航向控制相对于传统比例控制实际出水点与预定路径之间的距离差值较小,海试实验中10个剖面产生的误差均值为806.6 m,仅为传统控制算法误差均值的53.38%。以上结果证明利用深度强化学习解决路径跟踪问题误差较小,可有效减小航向调节幅度,降低能耗,同时也验证了仿真实验结果的准确性。
4 结语
本文模型不仅提高了海洋洋流预测模型的精度,而且减小了预测误差。在此基础上,针对水下滑翔机路径跟踪问题,在一定程度上改善了非线性函数近似表示值函数不稳定问题,相较于传统的控制方法以及传统强化学习模型提高了精度,更有助于节约能耗。“海燕-L”号长航程水下滑翔机海洋观测与探测海试实验结果验证了深度强化学习算法的有效性及仿真实验的真实性。
今后将把所提的深度强化学习算法扩展到漩涡、黑潮等更复杂的航行条件,同时将所提算法应用到水下滑翔机更为复杂的曲线航线及三维路径跟踪任务中。此外,还需要开发更有效的深度强化学习算法来处理连续状态和动作空间以及不同航行任务和条件之间的迁移学习问题。
参考文献:
[1]夏城城.水下滑翔机系统设计与优化[D].杭州:浙江大学, 2018.
XIA Chengcheng. Design and Optimization of Underwater Glider System[D]. Hangzhou:Zhejiang University, 2018.
[2]李沛伦.水下滑翔机路径规划研究[D].上海:上海交通大学,2019.
LI Peilun. Research on Path Planning of Underwater Glider[D]. Shanghai:Shanghai Jiaotong University, 2019.
[3]牛作硕,宫金良,张彦斐. 基于多路线追踪的机器人局部路径规划与实验[J]. 计算机应用与软件,2020, 39(1):60-64.
NIU Zuoshuo, GONG Jinliang, ZHANG Yanfei. Robot Local Path Planning and Experiment Based on Multi Route Tracking[J]. Computer Applications and Software, 2020, 39(1):60-64.
[4]LI Ben, XU Guohua, XIA Yingkai, et al. Composite Curve Path Following an Underactuated AUV[J].Mathematical Problems in Engineering,2021,2021(16):6624893.1- 6624893.18.
[5]YAO Xuliang, WANG Xiaowei, WANG Feng, et al. Path Following Based on Waypoints and Real-time Obstacle Avoidance Control of an Autonomous Underwater Vehicle[J]. Sensors, 2020, 20(3):795.
[6]田宇, 张艾群, 李伟. 欠驱动自主水下机器人三维路径跟踪控制[C]∥第30届中国控制会议. 烟台,2011:3456-3461.
TIAN Yu, ZHANG Aiqun, LI Wei. Three Dimensional Path Tracking Control of Underactuated Autonomous Underwater Vehicle[C]∥30th Chinese Control Conference. Yantai, 2011:3456-3461.
[7]王宏建, 陈子印, 贾鹤鸣,等. 基于滤波反步法的欠驱动AUV三维路径跟踪控制[J]. 自动化学报,2015, 41(3):631-645.
WANG Hongjian, CHEN Ziyin, JIA Heming, et al. Three Dimensional Path Tracking Control of Underactuated AUV Based on Filter Backstepping Method[J]. Journal of Automation,2015, 41(3):631-645.
[8]ISERN-GONZLEZ J, HERNANDEZ-SOSA D, FERNANDEZ-PERDOMO E, et al. Application of Iterative-optimization Techniques to Solve Hold Track Problem in Glider Navigation[C]∥OCEANS 2011 MTS/IEEE.Waikoloa,2011:12470493.
[9]HUANG Yan, YU Jiancheng, ZHAO Wentao, et al. A Practical Path Tracking Method for Autonomous Underwater Gilders Using Iterative Algorithm[C]∥OCEANS 2015 - MTS/IEEE. Washington D C,2015:15798877.
[10]HUO Mengxue, LIU Shijie, ZHANG Fumin, et al. A Combined Path Planning and Path Following Method for Underwater Glider Navigation in a Strong, Dynamic Flow Field [C]∥OCEANS-MTS/IEEE Kobe Techno-Oceans Conference. Kobe,2018:697-704.
[11]HUO Mengxue, LIU Shijie, ZHANG Fumin, et al. Path Tracking Error Analysis for Underwater Glider Navigation in a Spatially and Temporally Varying Flow Field[C]∥OCEANS 2018 MTS/IEEE. Charleston, 2018:18374498.
[12]潘昕, 馮国利, 侯新国. 基于分层学习的AUV路径跟踪技术研究[J]. 海军工程大学学报,2021, 33(3):106-112.
PAN Xin, FENG Guoli, HOU Xinguo. Research on AUV Path Tracking Technology Based on Hierarchical Learning[J]. Journal of Naval Engineering University, 2021, 33(3):106-112.
[13]李泽宇, 刘卫东, 李乐, 等. 基于FBR网络Q学习的AUV路径跟踪控制方法[J]. 西北工业大学学报,2021, 39(3):477-483.
LI Zeyu, LIU Weidong, LI Le, et al. AUV Path Tracking Control Method Based on FBR Network Q-learning[J]. Journal of Northwest University of Technology,2021, 39(3):477-483.
[14]邵俊恺, 杨钰, 张文明,等. 无人驾驶铰接式车辆强化学习路径跟踪控制算法[J]. 农业机械学报,2017, 48(3):376-382.
SHAO Junkai, YANG Yu, ZHANG Wenming, et al. Reinforcement Learning Path Tracking Control Algorithm for Unmanned Articulated Vehicle[J]. Journal of Agricultural Machinery,2017, 48(3):376-382.
[15]ZHOU Yaojian, YU Jiancheng, WANG Xiaohui. Time Series Prediction Methods for Depth-averaged Current Velocities of Underwater Gliders[J]. IEEE Access, 2017, 5:5773-5784.
[16]曹慧, 秦江涛. 基于ARIMA-BP组合模型的货运量预测研究[J].软件导刊,2022, 21(2):32-36.
CAO Hui, QIN Jiangtao. Research on Freight Volume Prediction Based on ARIMA-BP Combination Model[J]. Software Guide,2022, 21(2):32-36.
[17]王源昊. 基于ARIMA模型和LSTM神经网络的全球气温预测分析[J]. 科学技术创新,2021, 35:166-170.
WANG Yuanhao. The Software Guides the Prediction and Analysis of Global Temperature Based on ARIMA Model and LSTM Neural Network[J]. Scientific and Technological Innovation,2021, 35:166-170.
[18]张忠林, 张艳. 改进FA优化LSTM的时序预测模型[J]. 计算机工程与应用,2022,58(11):125-132.
ZHANG Zhonglin, ZHANG Yan. Improved FA Optimized LSTM Time Series Prediction Model[J]. Computer Engineering and Application,2022,58(11):125-132.
[19]刘炽.基于LSTM和TNC的室内定位系统研究与实现[D].济南:山东大学,2019.
LIU Chi. Research and Implementation of Indoor Positioning System Based on LSTM and TNC[D]. Jinnan:Shandong University,2019.
[20]邵必林, 史洋博, 趙煜. 融合注意力机制与LSTM的建筑能耗预测模型研究[J]. 软件导航,2021,20(10):61-67.
SHAO Bilin, SHI Yangbo, ZHAO Yu. Research on Building Energy Consumption Prediction Model Integrating Attention Mechanism and LSTM[J]. Software Navigation,2021, 20(10):61-67.
[21]李亚峰, 王洪波, 李晨,等. 融合注意力机制的LSTM期货投资策略[J].计算机系统应用,2021,30(8):22-30.
LI Yafeng, WANG Hongbo, LI Chen, et al. LSTM Futures Investment Strategy Integrating Attention Mechanism[J]. Computer System Application,2021, 30(8):22-30.
[22]龚飘怡, 罗云峰, 窦帆.基于Attention-BiLSTM-LSTM神经网络的短期电力负荷预测方法[J].计算机应用, 2021,41(增1):81-86.
GONG Piaoyi, LUO Yunfeng, DOU Fan. Short Term Power Load Forecasting Method Based on Attention BiLSTM LSTM Neural Network[J]. Computer Application, 2021,41(S1):81-86.
[23]于涛, 张文煊. 基于注意力机制的 LSTM 液体管道非稳态工况检测[J]. 油气与新能源,2021, 33(4):58-63.
YU Tao, ZHANG Wenxuan. Detection of Unsteady State Conditions of LSTM Liquid Pipeline Based on Attention Mechanism[J]. Oil and Gas and New Energy, 2021, 33(4):58-63.
[24]刘翀, 杜军平. 一种基于深度LSTM和注意力机制的金融数据预测方法[J]. 计算机科学,2020, 47(12):125-130.
LIU Chong, DU Junping. A Financial Data Prediction Method Based on Depth LSTM and Attention Mechanism[J]. Computer Science,2020,47(12):125-130.
[25]桑宏强, 于佩元, 孙秀军. 基于航向补偿的水下滑翔机路径跟踪控制方法[J].水下无人系统学报,2019, 28(5):71-77.
SANG Hongqiang, YU Peiyuan, SUN Xiujun. Path Tracking Control Method of Underwater Glider Based on Heading Compensation[J]. Journal of Underwater Unmanned Systems,2019, 28(5):71-77.
[26]李永成, 马峥, 王小庆.水下滑翔机高效滑翔水动力性能研究[J].中国造船,2020, 61 (4):57-64.
LI Yongcheng, MA Zheng, WANG Xiaoqing. Study on Hydrodynamic Performance of Efficient Glide of Underwater Glider[J]. China Shipbuilding,2020, 61(4):57-64.
[27]方尔正, 周子凌, 桂晨阳. 水下滑翔机原理与应用[J]. 国防科技工业,2020(8):66-68.
FANG Erzheng, ZHOU Ziling, GUI Chenyang. Principle and Application of Underwater Glider[J]. National Defense Science and Technology Industry,2020(8):66-68.
[28]陈奕煿, 张润锋, 杨绍琼. 基于参数自整定PID的水下滑翔机航向控制方法[J].重庆大学学报,2022,45(8):26-33.
CHENG Yibo, ZHANG Runfeng, YANG Shaoqiong, et al. Course Control Method of Underwater Glider Based on Parameter Self-tuning PID[J]. Journal of Chongqing University,2022,45(8):26-33.
[29]QI Xuwei, LUO Yadan, WU Guoyuan, et al. Deep Reinforcement Learning Enabled Self-learning Control for Energy Effcient Driving[J]. Transportation Research Part C,2019, 99:67-81.
[30]LI Junxiang, YAO Liang, XU Xin, et al. Deep Reinforcement Learning for Pedestrian Collision Avoidance and Human-machine Cooperative Driving[J]. Information Science,2020, 532:110-124.
(编辑 陈 勇)
作者简介:
石晴晴,女,1997 年生,硕士研究生。研究方向为复杂环境下的无人设备路径规划与智能决策。
兰世泉(通信作者),男,1988年生,高级工程师。研究方向为无人水下航行器产业化及应用推广。E-mail:yxlx2010@163.com。
收稿日期:2022-06-06
基金项目:天津市新一代人工智能科技重大专项(19ZXZNGX00050)
猜你喜欢
电子技术与软件工程(2019年5期)2019-06-20 10:31:23
软件导刊(2019年1期)2019-06-07 15:08:13
数字技术与应用(2019年2期)2019-05-14 08:25:10
现代电子技术(2018年8期)2018-04-13 06:36:32
软件工程(2017年11期)2018-01-05 08:06:09
智能计算机与应用(2017年5期)2017-11-08 12:11:51
软件导刊(2017年10期)2017-11-02 11:22:44
现代电子技术(2017年15期)2017-09-04 15:47:05
上海海事大学学报(2017年2期)2017-07-14 22:19:44
中学课程辅导·教学研究(2017年13期)2017-07-01 14:50:34
