
3分支多层次Transformer特征交互的RGB-D显著性目标检测
2023-11-28 01:50孟令兵袁梦雅时雪涵刘晴晴黎玲利何术锋
工程科学与技术 2023年6期
孟令兵,袁梦雅,2,时雪涵,刘晴晴,程 菲,3,黎玲利,何术锋
(1.安徽信息工程学院 计算机与软件工程学院,安徽 芜湖 241199;2.安徽信息工程学院 电气与电子工程学院,安徽 芜湖 241199;3.杭州电子科技大学 管理学院,浙江 杭州 310018;4.黑龙江大学 计算机科学与技术学院,黑龙江 哈尔滨 150006;5.南京水利科学研究院 生态环境研究所,江苏 南京 210017)
显著性目标检测(SOD)[1-3]旨在定位图像中最引人注目的对象,目前已经被广泛应用到计算机视觉的各种领域,如目标检测[4]、图像渲染[5]、图像认证[6]等。近年来,随着微软Kinect深度传感器和华为手机的广泛使用,深度图的采集也更加容易。深度图像相对于RGB图像具有更好的几何结构、内部一致性和光照不变性,推动了RGB深度图像(RGB-D)显著性目标检测的研究。该项研究最常用的模型是单流检测和双流检测,例如:Fu等[7]提出一种联合学习与密集协同融合的检测方法,联合学习模块提供强大的显著性特征学习能力,密集协同融合模块合理组合不同模态学习的特征信息。Chen等[8]在编码阶段的预融合和在解码阶段的深度融合中使用3维卷积神经网络,更加有效地促进RGB特征信息和深度特征信息的充分融合。Zhao等[9]直接使用深度图引导RGB特征与深度特征之间的早期融合和中间融合,从而节省深度图的特征编码,实现模型的轻量化和实时性。但是,上述的单流检测模型无法有效地探索不同模态的特征信息,于是,越来越多的双流检测模型被提出,例如:Sun等[10]提出一种深度敏感注意和自动多模态融合的深度RGB-D显著性检测方法,利用深度几何先验知识构建深度敏感注意力模块,并且利用自动结构搜索方法促进多模态特征的融合。Li等[11]提出一种分层交替交互网络,在该网络中,深度图和RGB图像以分层方式进行交互,逐步将局部和全局上下文集成到单特征尺度中,有效增强RGB和深度特征之间的跨模态交互。Jin等[12]设计两阶段的跨模态融合策略,将高级深度特征和低级深度特征分别与RGB特征融合,进一步提高了模型的性能。Zhang等[13]提出一种有效的深度质量启发特征操作,在跨模态融合之间调控和增强深度图特征,以避免引入嘈杂的深度特征,从而提高模型的检测精度。Zhang等[14]设计RGB 诱导细节增强模块和深度诱导语义增强模块,更好地融合了RGB图像和深度图的跨模态特征。Wen等[15]设计一个动态选择模块来挖掘RGB图像和深度图之间的跨模态互补信息,并通过门控机制和池化选择机制进一步优化多层次和多尺度信息。Zhou等[16]提出一种交叉流和跨尺度自适应融合模型去检测图像中的显著性目标。Wu等[17]在解码阶段设计了一个“一致性-差异性”聚合模块整合跨模态和跨级别的信息。Wang等[18]采用跨模态方式分别计算模型提取的RGB图像和深度图中每个像素对的相关性,从而学习到有判别力的特征。Liang等[19]提出多模态交互注意单元,联合注意引导跨模态解码模块和多级特征渐进解码模块组成的一种端到端模型,全面充分地组合跨模态跨层次特征信息。尽管上述的检测方法取得了很大的成功,但是基于卷积神经网络(CNN)的方法通常表现出对目标远距离关系建模的局限性,这些模型在复杂场景中检测性能仍然较弱。最近,Transformer结构在计算机视觉领域的应用取得了显著的成效。Liu等[20]提出的VST(visual saliency transformer)模型第一次将Transformer结构应用于显著性目标检测,结果表明检测性能有明显提升,验证了Transformer结构能够较好地适用于该任务。
受到之前方法的启发,本文结合U-Net与Transformer的优点,提出一种3分支多层级Transformer特征交互的RGB-D显著性检测模型(three-branch multilevel Transformer feature interaction for RGB-D salient object detection,TMTFI)。首先,采用坐标注意力模块抑制RGB模态与深度图模态的噪声信息,从而使模型提取出更有效的显著特征流向下一阶段。其次,利用Transformer编码高层特征用于获取图像的全局信息。然后,为了增强显著性区域特征,提出一个多层次特征交互模块。最后,提出一个密集扩张特征细化模块,该模块通过聚合多个扩张卷积的特征获得丰富的上下文特征信息,能避免出现显著性目标的丢失和模糊。
1 本文方法
本文提出的RGB-D显著性目标检测模型如图1所示,首先,采用两组相同的特征提取模块分别提取RGB图像和深度图的特征,采用跨模态坐标注意力模块来抑制RGB图像和深度图的噪声特征。其次,通过特征融合模块得到3个相同分辨率的特征图,特征图经过Transformer层进行特征向量编码,重塑的特征图被送入多层次特征交互模块和密集扩张特征细化模块。最后,累加3种分支的特征图得到预测显著图。接下来详细介绍模型的5个部分,包括特征提取、跨模态坐标注意力模块、特征融合模块、多层次Transformer特征交互模块和密集扩张特征细化模块。
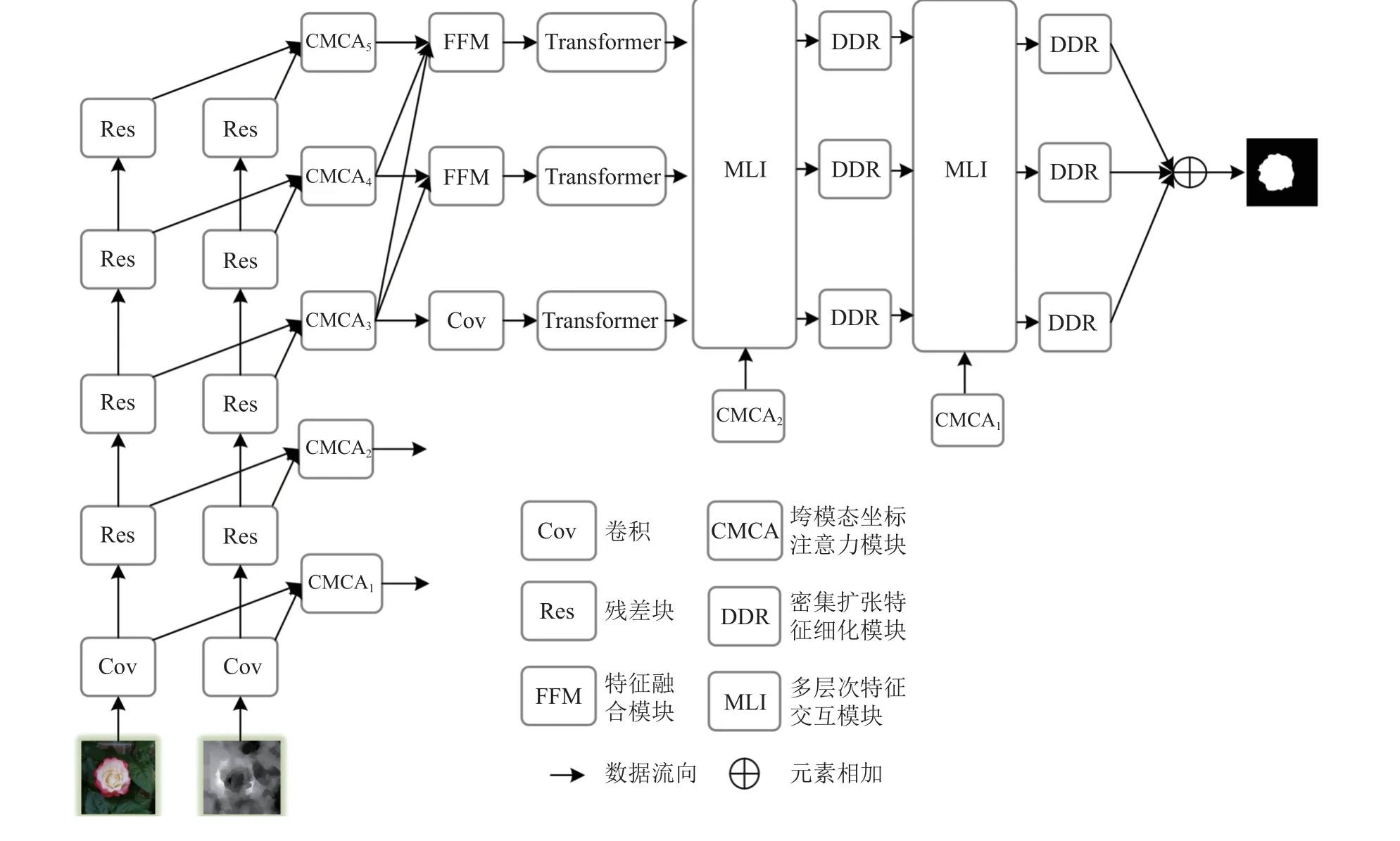
图1 3分支多层次Transformer特征交互的RGB-D显著性目标检测模型Fig.1 Three-branch multi-level Transformer feature interaction for RGB-D salient object detection
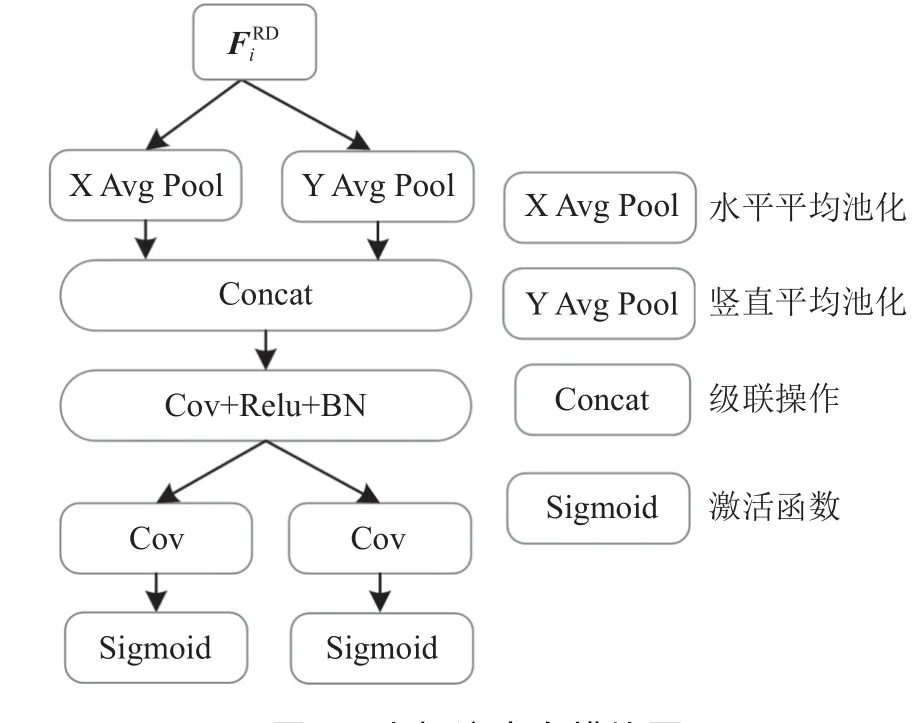
图2 坐标注意力模块图Fig.2 Coordinate attention module
1.1 特征提取
在特征提取阶段,将输入的图像经过1次普通卷积层(Cov)和4次残差卷积层(Res),其中,残差卷积层采用是Resnet50架构的前4层,提取的RGB特征和深度图特征分别记为和,i表示特征图的层数,i∈{1,2,3,4,5},5个特征图的大小(RGB特征图和深度图特征相同)依次为64×64×64、64×64×256、32×32×512、16×16×1 024、8×8×2 048。
1.2 跨模态坐标注意力模块
RGB-D显著性目标检测具有RGB图像模态和深度图模态。RGB模态提供显著性目标丰富的颜色信息和语义信息,深度模态提供显著性目标的几何结构。在RGB图像中,复杂的背景会对检测目标产生严重的干扰,此外,采集的深度图也存在质量较低的情况。两种模态提供显著性目标不同的特征信息和噪声,如果仅仅对这两种模态进行简单连接,则它们各自的噪声都会被引入模型,降低检测的性能。因此,本文提出一个跨模态坐标注意力模块(CMCA),该模块利用坐标注意力抑制深度图中的噪声,同时在很大程度上也能抑制RGB图像中非显著性区域,从而使得模型能够提取出更显著性的特征信息。
跨模态坐标注意力模块具体运行步骤如下:首先,将提取的5层RGB特征和深度图特征进行拼接;然后,使用大小为3×3的卷积层调整特征图通道数;最后,将结果输入坐标注意力模块,可表示为:式(2)~(3)中,H、W和C分别为特征图的长度、宽度和通道数,p和q为像素值坐标,Zm和Zn分别为水平和竖直方向的平均池化结果。

上述操作是沿着两个空间方向进行特征聚合,该操作允许注意力模块捕捉某空间方向的长程依赖,同时保存另一个空间方向的精确位置信息。
其次,利用坐标向量产生具有全局感受野并拥有精确位置的显著性特征信息生成坐标注意力图,生成注意力图。具体操作如下:首先,拼接上述步骤生成的两个坐标向量,然后,使用一个核大小为1×1的卷积对进行特征图变换,接下来,沿空间维度将拼接的特征图Z切分为两个单独的特征图ZH和ZW,再利用两个大小为1×1 卷积运算和Sigmoid函数生成一对方向感知和位置敏感的注意力图GH和GW,公式如下所示:

跨模态坐标注意力模块不仅可以充分捕获到显著性目标的空间位置信息,还能够有效地捕捉通道之间的关系,抑制噪声的同时实现跨模态特征之间有效的信息交互,增强显著性目标的特征表示能力。
1.3 特征融合模块
为了减少模型的参数量,本文采用具有共享权重的Transformer结构来编码特征图信息。由于Transformer层要求输入的特征图分辨率相同,因此,需要调整来自跨模态坐标注意力融合后的特征图。
首先,使用一个核大小为3×3卷积层和ReLU激活函数将跨模态特征融合的后3层特征图通道数调整为64;然后,利用特征融合模块来逐层调整不同分辨率的特征图,通过渐进式上采样方式使得被融合的特征图大小保持相同,融合过程可描述为:

1.4 多层次Transformer特征交互
由于具有很强的特征提取能力,CNN已经被广泛应用于计算机视觉的各个任务,并且取得了较好的效果。但是,CNN操作计算仍有局限性,特别是处理复杂场景时模型预测的显著图与真值图存在较大的差异。因此,有效克服CNN计算的局限性可以提高模型检测的性能。Transformer是一种序列到序列的自注意力模型结构,由于其具有长距离的远程依赖关系,在自然语言处理领域中应用较为广泛。因此,本文在检测模型中引入Transformer结构,将CNN特征映射中的标记化图像块编码为1维特征信息,该信息可用于对全局上下文的序列特征信息的建模。
首先,将输入的特征图x∈RH×W×C分为N个小图像块(patch),标记为∈RP2×C,其中,每个小图像块的大小为P×P,N=H×W/P2,j=1,2,···,N。然后,将得到的N个小图像块通过线性操作,化为D维映射空间特征,通过将学习特定的位置映射特征添加到图像块映射特征来编码空间信息。整个过程如下所示:
式中:E为patch映射操作矩阵,E∈RP2×C×D;Epos为位置编码矩阵,Epos∈RN×D;W0为添加位置映射特征后的空间信息矩阵。
Transformer结构如图3所示,Transformer结构由L层多头注意力(MHSA)块和多层感知机(MLP)块组成,第l层的输出可以写成:
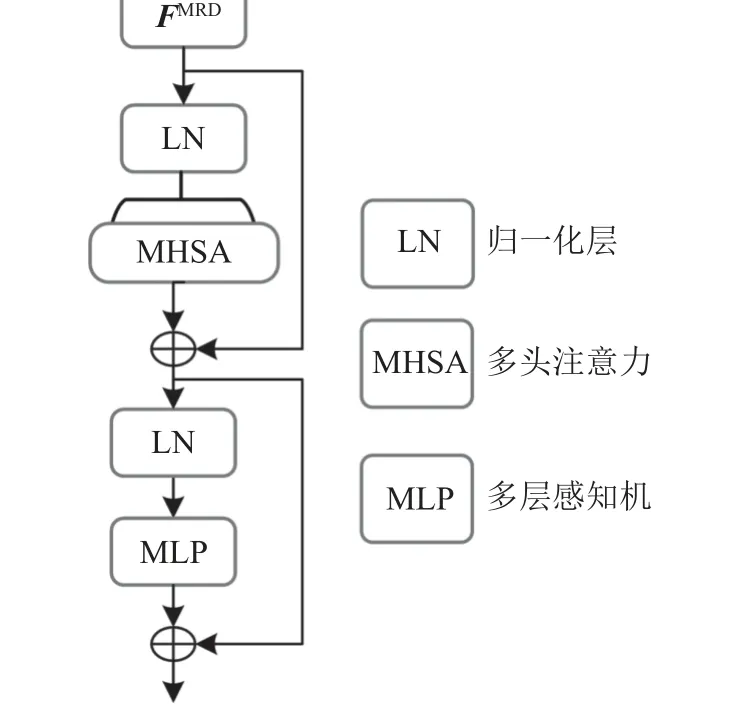
图3 Transformer层Fig.3 Transformer Layer(TL)
式(13)~(14)中,fMSA、fLN和fMLP分别为多头注意力、归一化操作和多层感知机,Pl为中间计算结果,Ql为Transformer层的输出结果。
在CNN中,不同层次的特征图表现出显著性目标不同维度的信息,低层特征具有较为清晰的边界轮廓信息,高层特征具有丰富的上下文语义信息,而上下文语义信息对于定位显著性目标位置至关重要,因此,在高层特征之间引入特征交互可以进行跨层次上下文信息的互补,这有助于模型精细化目标的位置信息,可以有效增强显著性特征的表达能力。基于此目的,本文提出一个多层次特征交互模块(MLI),模块结构如图4所示,图4中,为经过Transformer层编码后的特征图,i=3,4,5。通过交互策略聚合高层次特征,更有效地加强相邻特征图彼此之间的显著性特征信息,实现精准的目标定位;同时,引入低层特征细化目标的边界信息,达到多层次特征信息之间的有效整合,使得解码器更加准确地预测显著图。

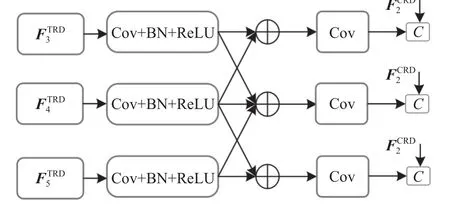
图4 多层次特征交互模块Fig.4 Multi-level feature interaction module(MLI)
式(15)~(20)中,fCBR为核大小为3×3的卷积操作、ReLU激活函数和BN层处理的组合。该过程与图1第2个MLI模块中FC1RD与3个高层次特征融合方法相同。
1.5 密集扩张特征细化模块
显著性目标的数量和尺寸变化会影响检测的性能,例如,当图像中存在多个对象和小对象时,级联结构不利于捕获多尺度信息。因此,如果CNN的感受野不是大到足以覆盖整个显著区域,则无法捕获足够的显著区域特征信息,从而导致检测结果不完整。为了解决这个问题,本文设计了一个串联的密集扩张特征细化模块(DDR),该模块将不同的扩张率应用于相邻的两个卷积层,将当前提取的特征和原始特征融合输出到下一个层,由后续的卷积层进行下一步处理,模块具体细节如图5所示。

图5 密集扩张特征细化模块Fig.5 Dense dilated feature refinement module(DDR)
该模块包括3个扩张卷积层和特征细化层,前3层中的每一层用来接收上一过程所有特征层的信息(即特征图累加的策略),每一层的输出作为下一层的输入。其中第1层卷积的扩张率为 2,第2层卷积的扩张率为4,第3层卷积的扩张率为6,扩张卷积能够扩大目标的感受野,全面捕捉丰富的多尺度特征信息。过程如下:
考虑到不同层次的特征融合会带来冗余特征,本文利用乘法和加法进一步细化和增强特征图。本文首先采用核大小为1×1的卷积层将输入特征图通道数转换为256,然后,将其输入到两个卷积层以获得用于乘法和加法运算的权重M和偏置b:

密集扩张特征细化模块可以获得丰富的上下文特征信息,可以很好地适应显著性物体形状、大小和数量的变化,提高模型的检测性能。
1.6 3分支解码
显著性目标的3个高层特征经过Transformer层编码后,经过多层次特征交互模块后与低层特征相结合,再经过密集扩张特征细化模块,实现解码的过程,上述整个3分支的解码过程表示如下:
式(26)~(29)中,fTL、fMLI和fDDR分别为Transformer层、多层次特征交互模块和密集扩张特征细化模块操作,fAdd为相加操作,fCov1为输出通道数为1的卷积操作,FFFM为最终预测的显著图。
相比较采用U-Net架构进行单分支解码,本文提出的3分支多层次模型具有以下特点:1)采用3分支结构;2)多层次特征交互。模型通过利用高层次特征的3个分支进行解码,避免了高层语义信息向下解码传递的丢失;同时,3个分支的显著性信息都被保留进行层次解码,可以有效增强显著性特征的表达能力。多层次特征交互有效地聚合高层特征和低层特征,通过高层特征交互实现目标的精准定位,通过低层特征细化目标的边界信息,从而利用多层次特征实现更精准地解码。
2 实验与结果
2.1 数据集
本文在5个具有挑战性的 RGB-D SOD基准数据集上进行了实验,分别是DES[21]、NLPR[22]、NJU2K[23]、SSD[24]和SIP[25]数据集。其中,DES是一个包含135张分辨率为640像素×480像素的图像的小规模RGB-D数据集;NLPR由1 000张分辨率为640×480的图像对组成,部分图像中存在多个显著物体,深度图通过微软 Kinect传感器在不同的光照条件下获得;NJU2K是最大的RGB-D数据集,包含1 985 张图像;SSD是从室内和室外场景的3部立体电影中挑选的80张图像组成的测试集,每张图像的分辨率高达960像素×1 080像素;SIP是使用华为Meta10双摄像头的智能手机捕获的1 000张图像,图像的分辨率为992像素×744像素,图像包含了来自各种视角、姿势、遮挡、低光照和复杂背景的真实场景。
2.2 训练参数与评价指标
为了保证不同检测方法的公平性,本文参照文献[10,12]的训练策略:在NJU2K 数据集中选取1 485幅图像作为训练集,剩余的图像作为测试集;在NLPR数据集中选取700 幅图像作为训练集,剩余的图像作为测试集;DES、SSD和SIP全部图像用于测试。在训练时,设置输入图片的分辨率为256像素×256像素。本文采用Adam作为优化器,数据批量大小设置为3,初始学习率为1×10-5,每60轮减小10倍,训练机器型号为NVIDIA GTX 3090 GPU。本文采用平均F-measure和自适应 F-measure[26]、平均E-measure和自适应E-measure[27]、平均绝对误差[28]和P-R(precision-recall)曲线作为评价指标。其中,平均F-measure和自适应 F-measure记为Fm和Fa,平均E-measure和自适应 E-measure记为Em和Ea,平均绝对误差记为M。
2.3 对比实验
将本文提出的方法与19种主流的显著性检测方法进行了比较,包括SSP[7]、EENet[17]、LDCM[18]、MIAD[19]、DSAM[10]、 DCF[29]、3DCNN[8]、HAIN[11]、CDNet[12]、DQFM[13]、CDIN[14]、CCAF[16]、BiANet[30]、VST[20]、JLDCF[7]、CMW[31]、HDFN[32]、ICNet[33]、D3Net[25]。表1为本文和其他显著性检测方法在5个测试集上进行训练的结果,其中,M值越小检测效果越好,其他4个指标数值越大则检测效果越好。3DCNN、CMDI和VST分别是典型的单流模型、双流模型和Transformer模型,从表1可以看出,本文的评价指标在5个数据集上远远高于3DCNN模型,也高于其他模型的检测结果,这说明使用单流检测模型无法获得较好的检测性能。与CMDI模型相比,在NJU2K数据集上本文方法的Fm、Fa、Em和M这4个评价指标均优于其检测结果,比如,本文方法的Fm和Fa较其分别提升了0.002和0.005,M值下降了0.005,在NLPR数据集上,本文方法的Fm、Fa、Em和Ea较其分别提升了0.007、0.021、0.009和0.008,M值下降了0.004。本文方法在NJU2K、NLPR、SSD这3个数据集上的检测结果高于VST模型,比如,在NJU2K和NLPR数据集上,本文方法的Em较VST分别提升了0.012和0.008,M值分别下降了0.005和0.004。上述实验结果验证了本文方法的有效性。但是在DES和 SIP这2个数据集上,本文方法并未取得较好的检测结果,如在DES数据集上,本文方法的Ea较VST低0.010,在SIP数据集上,Em和Ea较VST方法分别降低了0.009和0.016,M值下降了0.007。这可能是由于VST模型提出了多层级tokens融合方法以及图像块注意力模块,实现了显著性检测与边界检测的同步进行,利用边界信息减少低光照图像对模型带来的影响。SIP数据集包含多个低光照图像对,而 VST模型能够更好地检测低光照场景,但综合5个数据集的检测结果来看,本文提出的模型与其他模型相比取得了一定的改进效果,并在特定复杂场景中达到了很好的检测效果。
19个模型在5个数据集上的P-R 曲线和F-measure 曲线如图6和7所示。由图6可知,本文方法在5个数据集的曲线很短,表明本文方法检测的结果具有较高的召回率。由图7可知:在不同的阈值下,本文方法在NLPR、DES和NJU2K数据集的F-measure曲线处于较高的位置;在SSD和SIP数据集上,本文方法的曲线也高于很多模型。通过以上定量比较可以看出本文方法具有较好的泛化能力,能够很好地适用真实场景的检测。
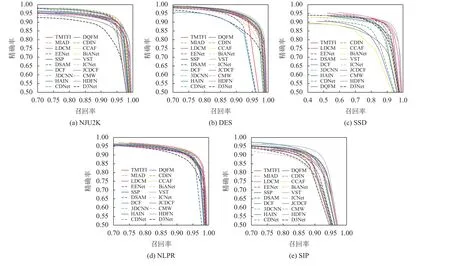
图6 不同模型在5个数据集的P-R曲线Fig.6 P-R curves of different models on five datasets

图7 不同模型在5个数据集的F-measure曲线Fig.7 F-measure curves of different models on five datasets
图8为本文方法和其他10种方法显著图的视觉对比,其中DM和GT分别表示深度图和真值图。在前3行中,RGB原始图像的前景显著区域颜色与背景颜色高度相近,很多方法都不能完整地预测出目标,部分显著性区域被背景吞噬,但是本文方法受益于跨模态坐标注意力模块,不受低质量深度图以及RGB背景色彩的影响,能够过滤两种模态的噪声信息,从而保留更多有效的特征信息。最后3行展示包含多个物体的图像。很多方法检测出的目标存在缺失或者模糊的情况,本文方法由于采用了密集扩张特征细化模块,不仅能够检测出图像中所有的目标,还能够将它们分割开,并且检测结果更完整,细节更突出。从展示的图片可以看出本文方法在多目标、背景复杂、目标与背景色彩相似等场景下检测的显著图效果更好,比其他方法更接近真值图。

图8 不同方法可视化的显著图Fig.8 Visualizing saliency maps of RGB-D SOD methods
2.4 消融实验
为了验证每个模块的有效性,本文在数据集DES、NLPR和NJU2K上进行了消融实验,结果见表2,其中,BL表示基础的U-Net模型(保留3分支结构)。从实验数据可以看出,在使用CACM模块后,由于噪声能够有效被抑制,相比较单独使用BL模型,Fm在3个数据集上分别提升了0.006、0.003和0.013。加入DDR模块后,M值降低较为显著性,在数据集NJU2K和NLPR都降低了0.002,其他的4个指标也有不同程度的提升。采用TL层建模图像远距离依赖关系后,检测结果提升较为显著,Fm在3个数据集上分别提升了0.006、0.002和0.003,M值分别下降0.002、0.002和0.001。从3个数据集的各项指标定量分析结果可以得出,每个模块对检测性能都有一定的提升效果,同时使用这些模块达到最好的检测结果。

表2 在3个数据集上的消融实验Tab.2 Ablation experiments on three datasets
2.5 失败案例分析
上述的评价指标和可视化显著图都证明了本文方法的优越性和有效性。然而,本文方法在特定的场景下仍然存在局限性,图9为本文方法检测失败的显著图,从展现的图片可以看出,RGB图像的光照非常低,显著性目标与背景的对比度也非常低,这表明,本文模型不能有效检测低光照场景下的目标。对于低光照环境下的图像,认为可以通过图像增强的方法提高RGB图像的质量,进而提高模型检测的性能。

图9 本文方法预测失败的显著图Fig.9 Some failure examples of our proposed method
3 结 论
本文提出一个新颖的3分支多层级Transformer特征交互RGB-D显著性目标检测模型。 首先,本文设计一个跨模态坐标注意力模块,过滤多模态中的噪声信息,从而保留有效的显著性特征信息,实现跨模态特征信息的有效融合。然后,利用Transformer层将特征图编码为特征向量,Transformer结构可以有效地学习显著性目标的长距离依赖关系和全局特征信息。最后,提出密集扩张特征细化模块,充分挖掘显著物的细节信息和丰富的多尺度特征信息。实验结果表明,本文提出的方法具有较好的检测效果和较强的鲁棒性,可视化显著图中的目标边界轮廓更突出,细节更准确,相比其他模型的显著图更接近真值图。此外,本文也通过消融实验证明了各个模块的有效性。在未来工作中,将重点探究如何更有效地提高模型在低光照场景下的检测效果。
猜你喜欢
北京航空航天大学学报(2021年9期)2021-11-02
计算机应用(2019年3期)2019-07-31
电子制作(2019年11期)2019-07-04
北京航空航天大学学报(2018年1期)2018-04-20
软件导刊(2016年9期)2016-11-07
科技视界(2016年2期)2016-03-30
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
上海电机学院学报(2015年4期)2015-02-28
计算物理(2014年2期)2014-03-11
电视技术(2014年19期)2014-03-11
