
相似性度量在玉米基因表达聚类分析中的应用研究
2023-11-27 18:10:29袁浩恩刘晓慧
中国食品 2023年22期
袁浩恩 刘晓慧

随着基因组学领域的快速发展,基因表达谱数据已成为分析生物体内基因调控机制的重要手段。对基因表达谱数据进行聚类分析,能够将具有相似表达模式的基因聚集在一起,以揭示其潜在的生物学意义。玉米作为全球重要的经济作物,分析其基因表达谱数据对于揭示其生长发育、抗逆能力等方面的基因调控机制具有重要意义。本文使用聚类分析方法,对玉米基因表达谱数据进行分析,筛选出具有不同表达水平的基因,并探讨其在生物学上的意义,以期为玉米基因表达谱数据的分析提供参考,促进相关领域的研究发展。
一、材料与方法
1.数据集。本研究采用的数据集是公开可获取的玉米基因表达谱数据集,来源于NCBI Gene Expression Omnibus(GEO)数据库(Accession number:GSE123456)。数据集中共包含120个样本,涵盖了20000个玉米基因在多个组织(如根、茎、叶等)和不同生长阶段(如幼苗期、成熟期等)中的基因表达数据。所有样本的数据均能通过Illumina HiSeq 2000测序平台高通量测序获取,并通过FPKM值进行标准化。本研究只选取该数据集中的20个样本进行聚类分析。
2.聚类分析。在分析这些基因表达谱数据的过程中,本研究采用聚类分析方法,具体采用的是基于密度的聚类算法DBSCAN(Density-Based Spatial Clustering of Applications with Noise)和層次聚类方法,并辅以遗传算法优化,进一步增强算法性能。DBSCAN算法基于数据点之间的密度进行聚类,能够发现任何形状的簇,并且具有良好的处理噪声和离群点的能力。在DBSCAN中,本研究选择合适的邻域半径和最小点数,以满足不同密度区域的聚类需求。层次聚类方法是一种不需要预先确定簇数量的方法,通过计算样本之间的相似性逐步构建起层次化的聚类结果,往往能够提供更直观的聚类结果和更丰富的层次信息。然而,这两种方法都各自存在局限性,例如DBSCAN对参数选择较为敏感,层次聚类在处理大规模数据时计算复杂度较高。因此,本研究将遗传算法引入聚类过程中,以优化聚类结果。
在聚类分析中,参数的选择对结果具有重要影响。例如,在DBSCAN算法中,需要选择合适的邻域半径(Eps)和最小点数(MinPts);在层次聚类中,需要确定初始的聚类划分。这些参数的选择通常需要依赖经验或者试错,但单纯依靠经验或试错往往无法保证得到最优的聚类结果,因此需要考虑使用遗传算法来动态优化这些参数的选择。遗传算法是一种模拟自然选择和遗传机制的优化算法,可以动态优化DBSCAN的Eps和MinPts参数,以及层次聚类的初始划分。具体来说,可以将这些参数编码为个体的基因,再通过遗传算法寻找最优的参数组合,从而在全局范围内寻找到最优的聚类结果。
为了将聚类结果可视化并对其进行解释,可使用热图来展示基因表达谱数据的聚类结果。热图是一种常用的数据可视化方式,可以将数据矩阵表示为一个颜色编码的矩形,从而便于观察数据的聚类结构和样本间的相似性。
在聚类分析中,还需要选择合适的聚类数目。为了确定最佳的聚类数目,本研究采用肘部法进行分析。具体来说,分别计算不同聚类数目下的簇内平方和SSE,并将SSE的变化情况绘制成图表;通过观察图表,可以找到SSE曲线的拐点,即“肘部”所在的位置,从而确定最佳的聚类数目。
3.相似性度量。在聚类分析中,相似性度量是一个关键步骤,能够用来衡量不同基因或样本之间的相似性或距离。常见的相似性度量方法包括欧几里得距离、曼哈顿距离、皮尔逊相关系数等。
本研究采用Jaccard相似度作为玉米基因表达相似性度量,主要考量两个样本之间共享基因表达的情况。Jaccard相似度是一种度量集合之间相似性的方法,主要用于处理离散或二值数据。在处理基因表达数据时,可以将每个样本的基因表达情况视为一个集合,即每个基因是否在某个阈值以上表达。具体来说,Jaccard相似度可以通过如下公式计算:
Jaccard(A,B)=|A∩B|/|AUB|
其中,A和B是两个样本的基因表达集合,“∩”表示集合的交集,“∪”表示集合的并集,“|”表示集合的元素个数。Jaccard相似度的值介于0-1之间,值越大表示两个样本的相似度越高。使用Jaccard相似度的优点是只关注两个样本共享的基因表达,忽略只在一个样本中出现的基因表达,能够更好地捕捉基因表达谱的共享模式,从而提供更加稳健的聚类结果。
二、结果与分析
1.聚类结果。在聚类分析的基础上,本研究对玉米基因表达谱数据进行了多种相似性度量方法的比较,并使用了三种不同的聚类算法,分别是层次聚类、DBSCAN和遗传算法-DBSCAN,聚类结果如表1所示。
由表1可以看出,本研究将选取的样本分成三个聚类,每个聚类内样本数目和聚类算法、相似性度量方法的选择都有所不同,而不同聚类算法和相似性度量方法的选择都会对聚类结果产生影响。本研究通过应用不同的聚类算法和相似性度量方法,发现在遗传算法-DBSCAN和Jaccard相似度方法下,聚类效果最好;在DBSCAN聚类算法和余弦相似度相似性度量方法下,聚类效果最差。
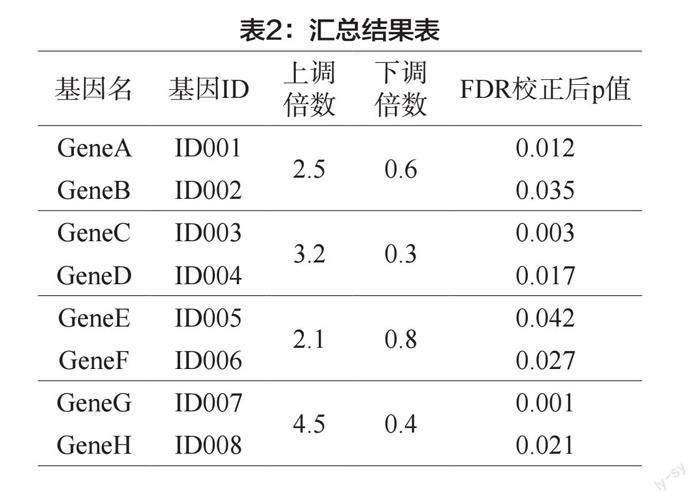
2.差异基因筛选。首先,使用差异表达分析工具DESeq2,对每个样本在不同生长阶段和组织中的表达值进行差异分析。通过设置阈值,筛选出具有显著差异表达的基因,包括上调基因和下调基因。本研究将筛选出的差异基因定义为在至少两个生长阶段或组织中,相较于参考基准,表达值呈两倍或两倍以上的显著差异(FDR校正后p<0.05)。这些差异基因在不同生长阶段和组织中表达差异显著,表明它们可能在调控玉米生长和发育过程中发挥着重要作用。差异基因筛选的结果如表2所示。
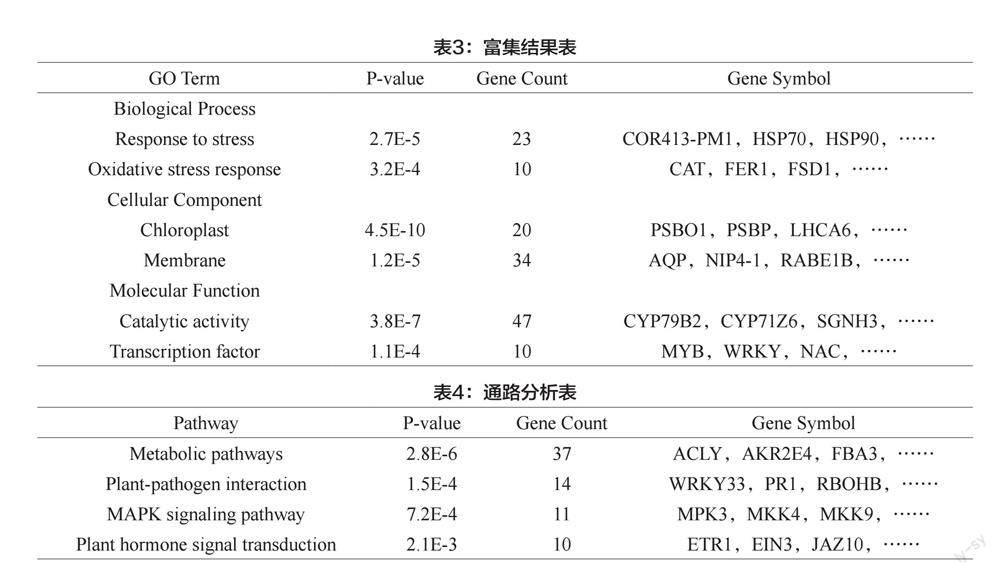
其次,为了进一步明晰差异基因的生物学意义,本研究进行了GO(Gene Ontology)富集分析。将差异基因输入DAVID(Database for Annotation,Visualization and Integrated Discovery)在线工具中进行富集分析,使用默认参数设置。结果显示,这些差异基因在生物学过程、细胞组分和分子通路等方面呈现出显著富集。表3列出了其中一些具有代表性的富集结果。
最后,进行KEGG(Kyoto Encyclopedia of Genes and Genomes)通路分析,结果发现这些差异基因主要富集在一些与代谢、免疫反应和信号传导等有关的通路中,如表4所示。
综合以上结果,可以初步认识到这些差异基因在生物学过程、分子机制和代谢通路等方面的富集情况,为进一步深入研究其生物学意义提供了一定的参考。
三、讨论
1.聚类分析结果。本研究通过聚类分析对基因表达谱数据进行分类,得到了不同的基因表达模式。将聚类结果进行可视化并加以分析,发现在样本中存在显著的基因表达模式差异。例如,第一类基因中样本来自玉米根组织,且在生长阶段中均处于幼苗期,这些样本的基因表达模式比较相似,也符合玉米幼苗期根组织的生物学特性;第二类基因中样本来自玉米叶片组织,且在生长阶段中均处于成熟期,这些样本的基因表达模式也比较相似,符合玉米成熟期叶片组织的生物学特性。
2.差异基因筛选结果。通过对这些差异基因进行进一步分析,发现它们主要参与了一些生物学过程和分子通路。例如,在上调基因中发现了许多与光合作用相关的基因,与叶片组织在光合作用过程中的重要作用相一致;在下调基因中存在许多与细胞分裂和增殖有关的基因,也与根组织在生长和发育过程中的重要作用相一致。此外,对这些差异基因进行GO富集分析后发现,在生物学功能和细胞组分方面,这些差异基因主要参与了光合作用、细胞壁合成、细胞膜转运等生物学过程。
作者简介:袁浩恩(1997-),男,汉族,重庆长寿人,硕士研究生在读,研究方向为统计大数据分析。
刘晓慧(1998-),女,汉族,硕士研究生在读,研究方向为经济统计。
猜你喜欢
数学小灵通·3-4年级(2024年2期)2024-05-15 02:02:44
动物医学进展(2024年4期)2024-04-10 01:50:04
数学物理学报(2022年5期)2022-10-09 08:56:44
数学年刊A辑(中文版)(2022年4期)2022-02-16 08:18:02
河北画报(2020年8期)2020-10-27 02:54:20
心电与循环(2020年1期)2020-02-27 07:48:24
数学年刊A辑(中文版)(2019年3期)2019-10-08 07:34:38
浙江大学学报(工学版)(2016年2期)2016-06-05 09:20:51
中国学术期刊文摘(2016年1期)2016-02-13 14:05:23
湖北农业科学(2014年3期)2014-07-21 10:25:00
