
数据预处理和统计方法对核桃叶片氮、磷、钾含量光谱反演精度的影响
2023-11-27 15:08胡珍珠裴宝磊王广龙吴欣欣陈辉
天津农业科学 2023年10期
胡珍珠,裴宝磊,王广龙,吴欣欣,陈辉
(淮阴工学院生命科学与食品工程学院,江苏 淮安 223003)
氮(N)、磷(P)、钾(K)养分的盈亏,都会作用到植物的形态特征从而影响光谱反射率[1-2]。随着光谱技术在农业领域的深入研究,建立作物养分光谱反演快速监测技术体系,可为田间施肥管理提供科学依据。目前的光谱传感器对作物表型性状非常敏感,可以通过光谱反射率显著反映[3-5],但光谱传感器不能直接测量作物的表型性状,光谱反射率与这些表型性状之间的关系需要建模[6-8],可以使用经验方法或物理方法建立模型,也可以将二者结合使用[9-10]。目前来看,建立作物养分模型多采用经验方法,也称为“回归”,是仅通过统计方法直接将输入与输出联系起来的模型。现实研究中,作物养分和光谱反射率间的对应关系由于其生理结构、理化性质、周围环境扰动及其他低频噪声的差异而难以准确建立。这就需要基于大量可靠光谱数据积累的基础上,采用不同数理统计方法逐步探寻这些内在的对应关系,将估测值与实测进行综合分析来解释对应关系的作用原理。有研究表明,利用多元线性回归(MLR)和反向传播神经网络(BPNN)算法建立的定量模型可估计冬小麦4 个生育期的叶片N 含量[11]。采用比值光谱指数RVI(660,815)构建的光谱反演模型估测小麦(Triticum aestivum)N 含量具有较高精度[12];采用最小二乘回归方法预测菠菜(Spinacia oleracea)的N含量具有较高的精度[13];采用665 nm 和680 nm 波段处光谱反射力构建的芦苇(Phragmites australis)N元素含量估算模型的决定系数为0.774 6,均方根误差为0.292 5[14];采用植被指数(R760~850)/(R350~400)和(R760~850-R350~400)/(R760~850+R350~400)估算巨杉(Sequoiadenron giganteum)叶片N、P、K 含量精度达95.8%以上[15];扁桃(Amygdalus communisL.)坐果期叶片N、P、K 含量光谱反演研究结果表明,二次函数可以较好地预测坐果期N 含量,三次函数预测坐果期P、K 含量具有较高精度[16];利用最小二乘法对所得数据进行回归分析,可以实现对荔枝树(Litchi chinensisSonn.)叶片N、P、K 元素含量的快速检测[17]。这些研究结果均表明,光谱反演可以较好地估测作物N、P、K 含量。然而,这些研究方法选择的敏感波段并不完全一致,这就造成了作物养分监测波段选择会影响估算精度、一般适用性和可解释性。因此,为了提高光谱数据的利用水平,进一步提高反演模型的适用性和客观性,有必要采用不同统计方法构建不同的反演模型。
K1+160—K1+310边坡总长150 m,由于是开挖阶段故以施工便道通行的工程车辆为主,平均车速约为Vv=20 km/h,日通过车次约Nv=360辆/日。计算得到人员时空概率PS∶T=0.1125。
从表1可以看出五个译本的标准类符/形符比存在一定的差异。蓝译本最高,这说明她的译文词汇变化性最大,用词最丰富,其次是斯译本和杨译本,第四是莱译本,王译本的标准类符/形符比最小,说明王译本的用词最不丰富,缺乏变化。另一方面,五个译文的形符告诉我们莱译本的译文最长,蓝译本的译文最短,蓝译本最接近原文的形符数。因此,蓝译本用词丰富且译文的长度接近原文。莱译本的长度是杨译本1.48倍,蓝译本的1.57倍,说明莱译本的译文将原文中的一些隐性表达进行了显化处理,显化现象明显。
核桃(Juglans regiaL.)是世界上主要的坚果之一。中国是世界上最大的核桃生产国,截至2020 年,我国核桃产量占全球核桃产量的一半[18]。采用光谱技术进行快速、无损的养分监测可为核桃田间施肥管理提供科学依据。核桃叶片光谱反射率受叶片生理和结构等因素的干扰,采用原始测量光谱数据直接构建作物养分反演模型精度将受到影响。本研究以核桃叶片为研究对象,对叶片光谱反射率进行平滑去噪预处理,分别采用一次函数、二次函数、三次函数、幂函数、指数函数和半对数函数建立果实不同生育期核桃叶片N、P、K 含量光谱反演模型,通过对比不同回归模型预测值与实测值的一致性,研究数据预处理和统计方法对核桃叶片N、P、K 含量反演精度的影响,以期为数据预处理方法和回归模型的类型选择提供科学参考。
1 材料和方法
1.1 试验材料
淮安市(32°43′00″N~34°06′00″N,118°12′00″E~119°36′30″E)地处黄淮平原和江淮平原,无崇山峻岭,地势平坦,地形地貌以平原为主,属温带季风气候,四季分明,年均气温为14.1~14.8 ℃;年无霜期为240 d 左右,年平均降水量约940 mm,年平均日照时数为2 130~2 430 h,气候及土壤条件较好。以12 年树龄核桃树体为研究对象,随机选取树体生长健康、树体大小一致的核桃树体90 株,其中50 株用以构建核桃叶片N、P、K 含量光谱反演模型,另40 株用以验证模型精度。
1.2 光谱数据采集
用两倍稀释法将铁皮石斛匀浆液稀释成质量分数分别为1.25%、2.5%、5%、10%和20%的系列溶液。向制备好的培养基中分别加入不同浓度的稀释液1 mL,涂布均匀后置于培养箱中20 min。取出后,再分别加200 uL菌液于培养基表面,涂布均匀,倒置于培养箱中,37℃培养24 h。每个浓度重复3次,以不长菌的最低浓度作为最小抑菌浓度。
1.3 叶片N、P、K 含量测定
其菜系在中餐菜系中独树一帜,融贯中西口味,其常用调味汁有黑椒胆、辣椒酱、葡汁、芒果酱、西柠汁、糖醋汁、糖醋西柠汁、煲仔汁、马拉盏、日本烧鳝汁、XO酱、豉油皇、牛柳汁、献汁、沙律酱、千岛汁、脆皮水、葱油、脆皮水葱油、农家酸椒、美极葱姜汁、蒜茸辣酱等几十种之多。
柴达木盆地是青藏高原的一部分,具有干燥、多风、寒冷的特点。年平均气温大多数高于2℃;最热的七月份平均温度仅11.5~18.0℃;一月平均温度多在-10~-15℃之间,极端最低温度一般在-30℃以下。以西风为主,最大风速为20~22 m/s。年日照时数可达3200~3600h。盆地东部降水量约160~180mm,中部降至40~50mm,西部的冷湖一带更少,不足20mm,然而,年蒸发量1973.62~3183.04mm[12]。
试验分别于果实坐果期、速生生长期、脂化期、近成熟期进行核桃叶片光谱数据采集。采用美国ASD 公司生产的FieldSpecFR 光谱仪进行野外田间叶片光谱反射率测定,波段范围为350~2 500 nm。为消除叶片表面弯曲等因素造成光谱波动及叶片内部变异造成的影响,进行光谱反射率测定时,避开叶脉位置,将叶夹夹紧叶片,并确保叶片水平且被探测面积与叶室面积相同。光谱数据测定选择在晴朗无风天气的11:00—14:00,此时太阳直射叶面,可减少太阳高度角的变化对光谱反射率的影响,同时每隔15 min 用白板进行优化。为保证精度,每个样株选取东、南、西、北4 个方向叶片20 片,每个叶片6 次重复测定,取其平均值作为样株原始光谱反射率。
2.2.1 不同回归方法对核桃叶片N 含量光谱反演精度的影响 由图4 可见,采用不同回归统计方法构建核桃叶片N 含量光谱反演模型的精度差异较大。但4 个生育时期均以采用三次函数建立的叶片N 含量回归估测模型精度最高,其均方根误差(RMSE)在1 g·kg-1内,相对误差(RE)在1%内。而采用二次函数构建的叶片N 素含量回归估测模型精度次之,其精度较三次函数反演模型略低。另外4种回归反演模型精度由高到底依次为:一次函数>半对数函数>指数函数>幂函数,其估算值和实测值的方程决定系数(R2)相对较低,均方根误差(RMSE)和相对误差(RE)相对较大,且半对数函数、指数函数、幂函数光谱反演模型未通过置信椭圆F检验。
1.4 数据分析
1.4.1 数据预处理 为消除仪器噪声和环境背景干扰,利用Savitaky-Golay 方法对数据进行平滑去噪预处理,本研究中使用的预处理数据即为滤波后的光谱值,即前后9 个原始波段的平均值,其函数表达式为:R'i=(Ri-4+Ri-3+Ri-2+Ri-1+Ri+Ri+1+Ri+2+Ri+3+Ri+4)/9。
1.4.2 模型构建及精度评价 应用回归分析建立叶片N、P、K 含量光谱特征参量反演模型,采用的函数式共6 种,即:一次函数(y=ax+b)、二次函数(y=ax2-bx+c)、三次函数(y=ax3+bx2+cx+d)、幂函数(y=axb)、指数函数(y=aebx)和半对数函数(y=alnx+b)。
为评价模型的可靠性和适应性,从大田生产园中随机抽取40 个样株作为独立样本来检验不同生育期叶片N、P、K 含量光谱反演模型的精度。反演模型估测值和实测值间的决定系数(R2)、均方根误差(RMSE)和相对误差(RE)[19]、置信椭圆F检验法[20]综合评价模型的估算精度,计算公式如下:
从已有文献来看,学者们多从结构学派出发对纷繁复杂的内创类型及主体按照一定的原则进行合理归并,并且视角大多落在组织层面的内创业。Burgelman(1983)从内创业产生来源的角度,把内创业活动分为引致性内创业和自发性内创业。Covin & Miles(1999)强调公司内创业在创新或者再造方面实际结果不同,并把内创业分为持续创新、组织再造、战略更新和领域重构四种类型。Antoncic & Hisrich (2003)把内创业的具体类型细分为以下几种:(1)建立自主或半自主的新企业;(2)在现有市场和产品的基础上开拓新业务;(3)产品和服务的创新;(4)生产工艺方面的创新。
式中,yi为真实值为平均值;fi为估计值。
建模数据集中叶片N 含量最小值为15.87g·kg-1,最大值为40.63g·kg-1,平均值为(28.95±3.02)g·kg-1;叶片P含量最小值为1.57g·kg-1,最大值为8.32g·kg-1,平均值为(5.23±1.56)g·kg-1;叶片K 含量最小值为1.53g·kg-1,最大值为16.74g·kg-1,平均值为(9.28±3.38)g·kg-1。
式中,yi为实际测定值为估测集样本的估测值。下同。
2.1.1 数据预处理对核桃叶片N 含量光谱反演模型精度影响 由图1 可见,光谱数据预处理对提高叶片N 含量光谱反演模型精度起到重要作用。果实坐果期和脂化期,采用预处理光谱数据构建的叶片N 含量光谱反演模型估算值与实测值的回归方程决定系数(R2)分别为0.826 2、0.886 1,且均方根误差(RMSE)均在1 g·kg-1内,相对误差(RE)在1%内,并通过置信椭圆F检验。而以原始光谱数据构建的叶片N含量光谱反演模型估算值与实测值的回归方程决定系数(R2)仅分别为0.5614、0.6855,且均方根误差(RMSE)和相对误差(RE)均较大,未通过置信椭圆F检验。
2 结果与分析
2.1 数据预处理对核桃叶片N、P、K 含量光谱反演模型精度影响
式中,n为预测集样本数;xi为预测集样本的估算值;a为估算值与实测值拟合的回归直线截距;b为估算值与实测值拟合的回归直线斜率。

图1 原始光谱数据与预处理光谱数据构建的核桃果实不同生育期叶片N 含量光谱反演模型精度比较
果实速生生长期和近成熟期,采用预处理光谱数据构建的叶片N 含量光谱反演模型估算值与实测值的回归方程决定系数(R2)高达0.961 2、0.889 9,且具有较低的均方根误差(RMSE)和相对误差(RE)。以原始光谱数据构建的叶片N 含量光谱反演模型虽通过置信椭圆F检验,但均方根误差(RMSE)在6 g·kg-1以上,相对误差(RE)在5.4%以上,表明原始光谱数据构建的核桃叶片N 含量光谱反演模型精度较低。
同步采集每一样株上已进行光谱数据测定的叶片作为一个样品,将清洁、吸水、杀青、烘干后的核桃叶片粉碎并于消煮炉中进行消化处理,用水将消煮液定容至100 mL 后过滤,供N、P、K 元素的测定。叶片N 含量采用钒钼黄比色法测定,叶片P 含量采用钒钼黄比色法测定,叶片K 含量采用火焰光度计法测定。
2.1.2 数据预处理对核桃叶片P 含量光谱反演模型精度影响 由图2 可见,采用平滑去噪预处理光谱数据构建的果实坐果期、速生生长期、脂化期和近成熟期核桃叶片P 含量光谱反演模型的估算值和实测值间的决定系数(R2)分别为0.730 2、0.731 7、0.727 8、0.698 4,且均方根误差(RMSE)均在6 g·kg-1内,相对误差(RE)均在5.3%内。而采用原始光谱数据构建的核桃叶片P 含量光谱反演模型的估算值和实测值间的决定系数(R2)分别为0.633 4、0.607 5、0.667 6、0.571 9,均方根误差(RMSE)和相对误差(RE)分别在6.4 g·kg-1、7.3%以上。由此可见,采用预处理光谱数据对核桃叶片P 含量光谱反演模型的精度有较大程度地提高。
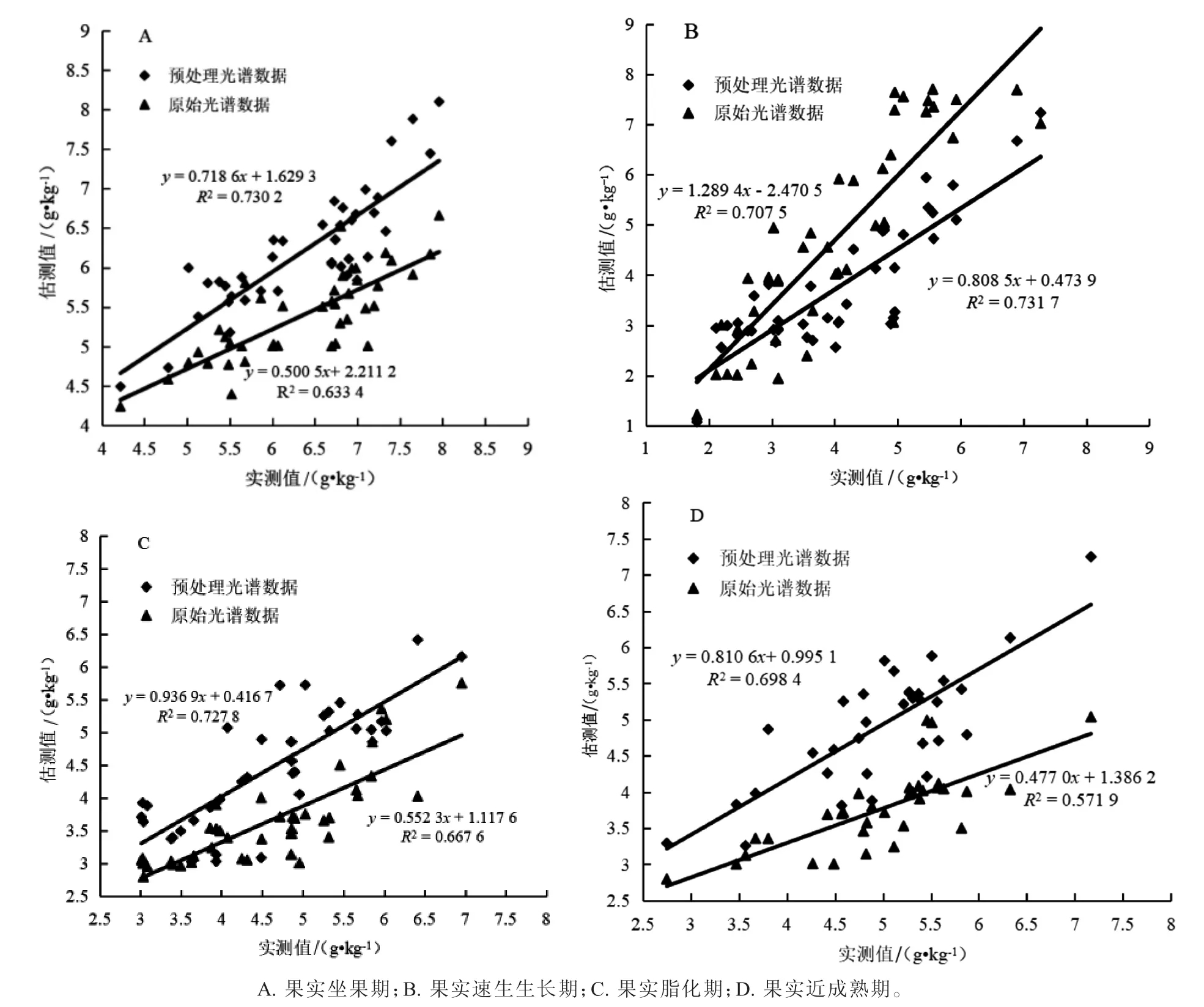
图2 原始光谱数据与预处理光谱数据构建核桃果实不同生育期叶片P 含量光谱反演模型精度比较
2.1.3 数据预处理对核桃叶片K 含量光谱反演模型精度影响 核桃叶片K 含量光谱反演模型精度表现出了相同的规律(图3),果实4 个生育时期均以预处理光谱数据构建的叶片K 含量光谱反演模型精度最高。果实速生生长期,原始光谱数据构建的叶片K 含量光谱反演模型估算值较实测值大,其他3 个生育时期则比实测值偏小,但其均方根误差(RMSE)和相对误差(RE)均较大,且未通过置信椭圆检验。结果表明,预处理光谱数据较大程度地提高了核桃叶片K 含量光谱反演模型的精度。

图3 原始光谱数据与预处理光谱数据构建的核桃果实不同生育期叶片K 含量光谱反演模型精度比较
2.2 不同统计方法对核桃叶片N、P、K 含量光谱反演精度的影响
检验数据集中叶片N 含量最小值为17.79 g·kg-1,最大值为38.95 g·kg-1,平均值为(29.71±2.95)g·kg-1;叶片P 含量最小值为1.82g·kg-1,最大值为7.96g·kg-1,平均值为(4.99±1.38)g·kg-1;叶片K 含量最小值为1.75 g·kg-1,最大值为14.44g·kg-1,平均值为(8.50±3.04)g·kg-1。
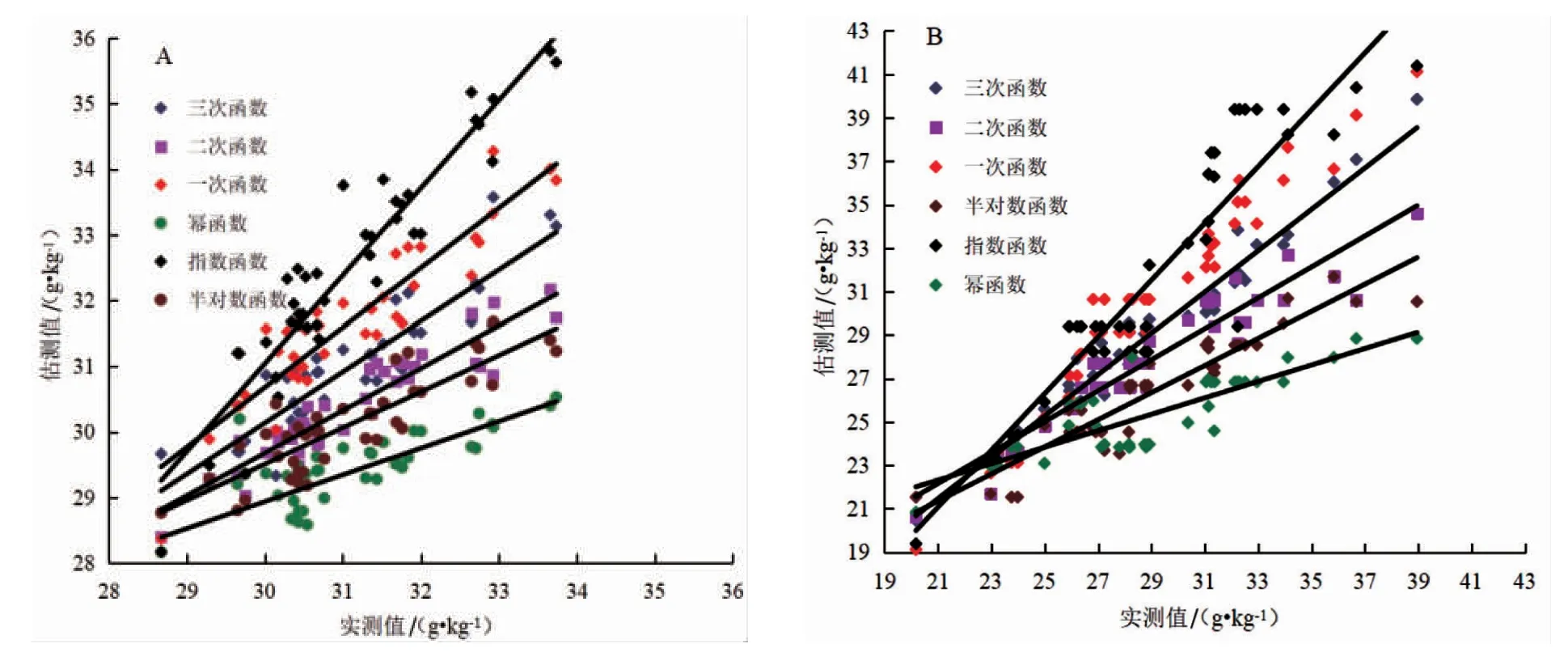
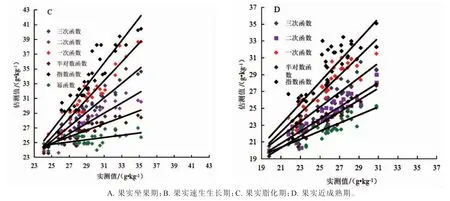
图4 不同回归方法构建的核桃果实不同生育时期叶片N 含量光谱反演模型精度比较

图5 不同回归方法构建的核桃果实不同生育期叶片P 含量光谱反演模型精度比较

图6 不同回归方法对核桃果实不同生育期叶片K 含量光谱反演模型精度影响
2.2.2 不同回归方法对核桃叶片P 含量光谱反演精度的影响 6 种回归方法构建的果实坐果期、速生生长期、脂化期、近成熟期核桃叶片P 含量光谱反演模型表现出相同的规律,即:叶片P 含量回归估测模型精度最高的均为三次函数,其模型的估算值和实测值回归方程的决定系数0.698 4≤R2≤0.753 6,均方根误差(RMSE)在6 g·kg-1内,相对误差(RE)在3%内。采用二次函数构建的叶片P 含量回归估算模型精度稍低,其次为一次函数、半对数函数、指数函数构建的叶片P 含量回归估算模型,幂函数构建的叶片P 含量回归估算模型精度最差,且未通过置信椭圆F检验。
2.2.3 不同回归方法对核桃叶片K 含量光谱反演精度的影响 果实坐果期,6 种核桃叶片K 含量光谱反演模型的精度差异总体最小,果实速生生长期、脂化期、近成熟则差异较大,但4 个生育时期均以采用三次函数建立的叶片K 含量回归估测模型精度最高,二次函数构建的叶片K 含量回归估测模型精度次之。
3 讨论与结论
3.1 讨论
研究结果表明,进行平滑去噪预处理的光谱数据比原始数据构建的核桃果实不同生育期叶片N、P、K 含量反演模型精度更高。由于光谱具有高度的敏感性,作物光谱数据的获取受光照条件、大气气溶胶、附着凋落物背景等环境因素和其他低频噪声[21-23]等外界因素的影响,为有效减少光照环境引起的可乘性因素影响,增强可见光区的光谱差异,本研究将原始数据进行平滑去噪预处理,以去除噪音、样本不均匀、基线漂移、光散射等因素的影响[24]。这在一定程度上能够削弱因光照环境等条件变化造成的光谱反射率测量误差对估测精度的影响。其次,平滑去噪处理是将原始反射率进行转换,通过转换可以放大或者缩小特征峰的反射率值,提升光谱识别的概率,增强有价值波段信息[23]。在建立光谱数据与理化成分间的回归模型时,采用多种回归方法综合验证可以更精确地分析光谱数据和理化成分的内在对应关系[25],以达到提高建模精度的作用[22]。
研究结果还表明,采用一次函数、二次函数、三次函数、幂函数、指数函数和半对数函数分别构建的核桃叶片N、P、K 含量反演模型精度各不相同,均以三次函数建立的各生育期叶片养分含量回归估测模型精度最高。这是因为经验方法(如非参数线性回归、机器学习回归)的优势在于可以充分利用全光谱[26],还可以部分克服多重共线性问题,获得比基于可视化的方法更精确的结果。缺点是训练时计算量大,模型和参数设置复杂,需要现场样本。对扁桃(Amygdalus communisL.)N、P、K 含量光谱反演研究结果也表明二次函数可较好预测坐果期N 含量,三次函数预测坐果期P、K 含量具有较高精度[16]。Darvishzadeh 等[27]利用逐步线性回归和偏最小二乘回归方法对原始高光谱维数进行降维,估算出非均质草地的叶面积指数和叶绿素密度。贾芳芳等[28]采用多元线性回归(MLR)和BP 神经网络方法预测烤烟叶片的N 含量。由此可见,构建不同的反演模型,可以提高光谱数据的利用水平,进一步提高反演模型的适用性和客观性。
3.2 结论
(1)平滑去噪预处理的光谱数据构建的反演模型比原始数据的决定系数(R2)更高、均方根误差(RMSE)和相对误差(RE)更小,即采用预处理数据构建的反演模型具有更高精度。
在实际生活中寻找创作灵感,就是指在进行作文教学的时候老师要合理的引导学生观察身边的一些事物,在生活的点滴中不断积累自己的写作素材,把写作灵感激发出来,把写作融入进实际生活中。
(2)将6 种统计方法构建的N、P、K 含量模型的预测值和实测值绘制1∶1 关系图,以直观展示模型估算值与实测值的一致性程度,三次函数构建的各生育期叶片N、P、K 含量光谱反演模型具有最高的决定系数(R2)、最小的均方根误差(RMSE)和相对误差(RE),并通过置信椭圆F检验,故三次函数构建的各生育期叶片N、P、K 含量光谱反演模型精度最高。
猜你喜欢
中等数学(2022年5期)2022-08-29
今日农业(2021年19期)2021-11-27
环境保护与循环经济(2021年7期)2021-11-02
哈尔滨轴承(2020年1期)2020-11-03
中国奶牛(2019年10期)2019-10-28
电子制作(2018年23期)2018-12-26
基层中医药(2018年2期)2018-05-31
石油地球物理勘探(2017年4期)2017-12-18
石油地球物理勘探(2017年2期)2017-11-23
陕西画报(2016年1期)2016-12-01
