
面向学术检索系统的摘要语步识别效果测评与应用策略研究*
2023-11-23 13:11:16孟旭阳白海燕
情报杂志 2023年11期
孟旭阳 白海燕
(中国科学技术信息研究所 北京 100038)
0 引 言
语步是语言学概念,指实现完整交流功能的一个修辞单位[1]。在科技论文的摘要中,作者一般会说明研究的目的、方法、结果以及结论等要素,这些要素被称为科技论文摘要的语步。近年来,国内外在语步自动识别领域的相关研究中取得了较多的研究成果。
以科技论文为例,摘要语步自动识别研究的终极目标在于更好的对论文中主要意图和科学知识进行揭示,使科研人员阅读文献摘要时能够快速、准确了解论文的主要内容,提升阅读效率,同时更好地支撑基于科技论文的情报分析与知识发现。
然而,在各大学术检索系统,如WOS、PubMed、Wiley、CNKI、百度学术和万方等平台目前都未发现提供语步成果的相关应用功能服务。是学术研究成果成熟度不够还是在工程化应用中面临着应用难点?目前较为先进成熟的摘要语步识别研究成果是否能够投入实际应用,如何进行应用,在加速推动知识化服务建设上具有重要的意义。
本文重点关注面向学术检索系统的应用测评和应用策略研究,以国家科技图书文献中心(以下简称NSTL)为例,针对在NSTL实际应用中需要考虑的应用条件、场景、数据特点等,制定多维度的测评方案,对目前较为先进的基于BERT深度学习模型的语步识别效果进行多维度测评和结果分析,评估目前语步识别成果在实际应用中的可行性及存在问题,并以NSTL为例,制定相应的优化策略和应用方案,解决应用问题,促进语步识别研究成果的落地应用。
1 相关研究
摘要语步识别已有相关研究主要分为基于规则的方法、机器学习方法和深度学习方法三大类。
基于规则的方法主要通过一些启发式定义的函数或组合特征,基于词频、位置等信息构建特征模板。Milward等[2]对医学领域文献的摘要进行了分析,提出了基于本体的科学文献交互信息提取模型。Cross等[3]从语义组织和主题结构两个方面分析原生动物学领域的文献摘要,探索了摘要中各语步内容的语义特点。杜圣梅等[4]对医学领域的科技文献摘要内容特征进行分析,使用PIBOSO模型给出了摘要中一些语步特征的抽取方法。郑梦悦等[5]基于知识元本体理论,对各个语步功能句中的线索词、句型和位置,建立相关规则库,设计了非结构化摘要语步信息的抽取算法。一般来说,基于规则的方法识别准确度较高,但往往针对特定语言、特定领域等,具有一定的局限性,可移植性低,且规则特征模板的设计繁琐耗时,代价较高。
基于机器学习的方法大致可以分为两类:一类是将语步自动识别看作文本自动分类任务,即对论文摘要中的句子语步功能类别进行划分,利用文本分类算法模型实现语步的自动识别。另一类是把语步识别问题转化为序列标注问题,根据各类别在文本中出现的位置顺序规律来识别文本片段所属的类。Wu等[6]提出了隐马尔可夫模型对摘要中的语步进行识别。McKnight等[7-8]构建了支持向量机模型,对文献摘要句子进行分类。Hirohata等[9]利用条件随机场构建语步识别模型,取得了良好的识别效果。机器学习的方法识别性能良好,但大多为特征工程,依赖精心设计的词汇、语义、结构、统计等特征。
近年来,随着深度学习技术的发展,越来越多的研究者将深度学习方法应用到语步识别中。沈思等[10]提出了基于Bi-LSTM-CRF模型的全字语义摘要结构功能自动识别方法,实现了字粒度上的摘要语步内容自动识别。张智雄[11]等对不同深度学习模型的科技论文摘要语步识别效果进行了对比研究,认为深度学习方法在语步识别中具有较大的优越性。特别是2018年10月,谷歌的Devlin等[12]发布的BERT受到了广泛关注,一些学者基于BERT开展了语步识别工作[13]。王末等[14]结合句子文中位置改进BERT模型输入,同时在句子表征输出单元之上增加多层感知机分类器,实现了语步分类,语步识别效果较好。Gaihong Yu等[15]提出的一种基于BERT的掩藏句子模型 (masked sentence model, MSM),对文摘中的语步开展自动识别,该模型能够充分学习摘要句子的上下文特征,提高整体识别性能,在PubMed 20k RCT 数据集上与其他基于BERT的方法进行了对比实验,结果表明具有更好的标注效果。基于深度学习的方法避免了繁琐的“特征工程”,能够实现精准自动识别并提高语步识别的效果。
在应用研究上,国内外已有不少学者在学术论文论证结构上的相关研究证明,基于论文结构的论证知识提取对于知识组织、语义检索、知识发现等有重要的应用价值和较好的知识服务能力[16]。黄永等[17]探讨了学术文本全文层面的结构功能在学术搜索中的作用,证明了学术文本的结构功能在学术搜索中具有应用价值。孟旭阳等[18]分析了学术文献摘要中目的、方法、结论等结构功能代表的语义特征对关键词抽取效果的提升有良好的作用。但是目前还没有相关研究面向学术检索系统中的知识服务对论文摘要语步识别研究成果进行应用测评和应用探索,也并未发现相关的工程化实际应用。因此,本文将选择较为先进语步识别模型开展面向实际学术检索系统的应用测评和应用方案研究,给出面向应用的策略和建议,以期促进语步识别研究成果在学术检索系统知识服务中的落地应用。
2 研究设计
为了促进科技论文语步识别研究成果在实际系统中的应用,以NSTL为例,深度分析和梳理面向应用条件、应用场景、数据特点等应用问题,制定面向应用的多维度测评方案,开展大样本量的科技论文数据测评和结果分析,最终面向NSTL应用给出具体的应用策略和建议。本文研究设计框架如图1所示。

图1 研究设计框架图
如图1所示,本文的研究过程共包括6个部分。
a.面向NSTL的工程化集成应用,梳理应用问题。本文从应用条件、应用场景、数据特点等三个方面分析梳理投入NSTL实际应用应考虑的问题。具体主要包括:在应用条件上,需要通过准确率等测评指标评估上线服务的可行性和实用性,切实保证服务质量。在应用场景上,应结合不同场景的应用方式和应用内容,评估语步要素数量的适宜性。在数据特点上,一方面,针对NSTL数据资源涵盖理工农医四大领域的特点,应评测语步识别在各领域学科上的通用性;另一方面,科技论文的摘要存在自有结构化要素文摘和非结构化文摘两种类型,有必要面向不同文摘类型数据开展语步识别效果测评以支撑应用策略研究。
b.制定多维度的测评方案。根据上述分析和梳理的具体应用问题,制定有针对性的测评方案,包括准确性与实用性测评、语步要素类型适宜性测评、学科领域通用性、不同文摘类型对比测评等多维度测评内容,为后续的应用策略和应用方案提供切实参考依据。为保证测评质量,通过自动化测评和人工测评相结合的方式,实现更加高效、精准的测评。
c.测评数据构建。以NSTL实际英文科技论文数据为对象,根据测评方案涉及的要点,构建大体量的、学科领域涵盖全面的、囊括多样化文摘类型的测评数据,充分支撑测评分析内容。
d.基于BERT深度学习模型的语步识别效果测评。通过相关研究的调研和分析,本文选取Yu等[15]文章中基于BERT的掩藏句子模型 (masked sentence model, MSM)的语步自动识别方法,该模型能够充分学习摘要句子的上下文特征,提高整体识别性能,在现有研究中具有一定的代表性和先进性。因此,本文选取该模型作为测评模型,开展面向应用的语步识别效果测评。
e.测评结果分析。对测评实验结果进行统计,开展不同维度以及横向纵向的对比分析,并针对测评内容和面向实际应用的具体问题进行讨论分析。
f.应用策略及建议。根据测评结果分析,梳理存在的应用问题和应用难点,从NSTL的实际应用角度出发,给出具体的应用策略和建议。
3 语步识别效果测评
3.1 测评过程
语步识别效果测评过程主要包括:测评数据构建、结构化摘要语步要素类型分析与语步提取、基于BERT模型的语步识别、结果测评等4个部分,如图2所示。
如图2所示,首先开展测评数据的构建、语步识别模型的准备;然后,对结构化摘要数据中包含的语步要素类型进行梳理总结,进而对结构化摘要进行语步要素内容的提取。一方面,将梳理总结的语步要素类型与语步识别模型支持的语步要素类型进行对比分析;另一方面,结构化摘要的语步提取为每个句子添加语步要素标签,支撑自动化测评。其次,通过基于BERT的掩藏句子模型[15]对测评数据进行语步识别;最后,开展语步识别结果测评。在测评方法上,针对不同摘要类型数据特点采取不同的测评方法,具体包括:①对于结构化摘要数据,以原文摘结构化要素为正确依据,开展大规模的自动化测评。②对于非结构化摘要数据,因为无测评的正确依据,只能依靠人工判读,考虑人力和时间成本,开展随机抽样的人工判读测评方法。
3.2 测评数据构建
面向NSTL实际文献数据开展测评数据的构建,为确保测评的充分性、真实性、客观性、准确性,本文构建较大规模的数据进行测评。
首先,从NSTL数据仓储中抽取数据,并对语种、文献类型、发表年份、摘要长度、数据量等进行了设置,如表1所示。依据抽取条件设置开展数据抽取。

表1 数据抽取条件设置
数据抽取完成后,根据模型标注结果的机器自动化效果评估筛选(依据语步出现的异常顺序等条件自动过滤),经统计,保留的数据量为3 089 610篇,其中,结构化摘要论文数1 487 038篇,非结构化摘要论文数1 602 572篇。因此,本文以保留的3 089 610篇数据作为测评数据集开展测评分析。
3.3 结构化摘要语步提取
在具有结构化摘要的英文科技论文中,每篇论文使用的结构化语步要素类型在数量和表达用词上并不统一。为了全面了解实际数据中语步要素类型概况,以支撑实际应用中语步要素类型的选择。本文对实际英文科技论文数据中的结构化语步要素进行分析总结,如表2所示。

表2 结构化语步要素梳理
通过梳理总结了英文科技论文存在的较为常见的结构化语步要素共18个,共计45种不同的表达用词。如“Objective”语步要素,其他表达用词有“Aim”、“Purpose”等,因表达含义相同,均归为或者映射为“Objective”语步要素内容。
本文基于结构化要素关键词及表达用词,利用正则表达式完成结构化摘要语步要素对应内容的自动提取,则每个句子有了正确的语步要素标签,作为判断模型识别正确的依据,支撑结构化摘要数据的自动化测评。
然而,目前语步识别研究成果中,大多数研究成果包括本文测评模型[15]采用的语步要素均为常见且使用较多的5个语步要素:“背景”、“目的”、“方法”、“结果”、“结论”,这与实际数据中存在18种语步要素的现状不相符。这就需要讨论两个问题:①面向学术研究使用的5个语步要素是否能够满足和支撑面向工程化应用的实际需求;②在测评工作开展中,如何对实际数据中的18个语步要素与模型支持的5个语步要素进行合理的映射,以判断模型识别结果正确与否,进而开展测评分析。
为初步讨论问题①,对测评数据集中的结构化摘要语步分布情况进行统计,如图3所示。
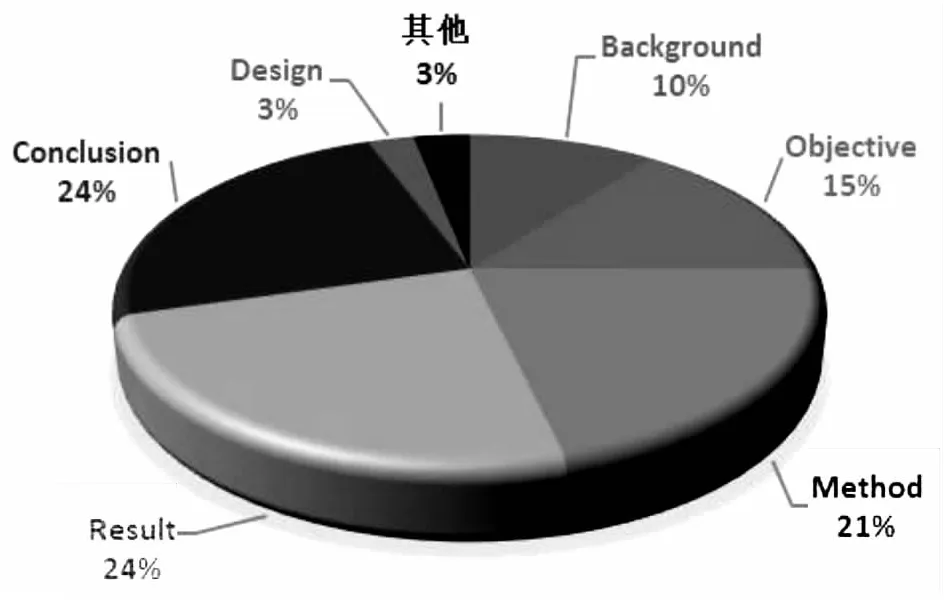
图3 测评数据集中结构化摘要语步分布情况
如图3所示,可看出在实际数据中当前学术研究常使用的5个语步要素占比均较高,“背景”占比10%、“目的”占比15%、“方法”占比21%、 “结果”占比24%、“结论”占比24%,一共占比所有语步要素的94%。从一定程度上侧面反映了这5个语步要素在面向应用中具备良好的适宜性。后面小节也将从准确性等其他维度进一步深度分析5个语步要素的适宜性。
为讨论问题②,需要对结构化摘要数据分为两类分别进行讨论,类别A:原始结构化摘要中的语步要素仅包括上述5个语步要素或为这5个语步要素中的几个;类别B:原始结构化摘要中包括上述5个语步要素外的其他语步要素(即表2中的序号为6-18的语步要素)。对于类别A,无需进行其他处理,可直接与模型识别结果开展对照测评;对于类别B,则需要对其他语步要素与5个语步要素之间进行对照映射,如结构化摘要中存在“局限”语步,不在语步识别模型支持的5个语步要素之内,如何判断“局限”句子在模型中识别的正确与否,依据具体的含义,普遍认为模型将“局限”句子内容识别为“结论”的话是可以被接受的,反之,若识别为“目的”、“方法”等其他语步则普遍认为是不可以被接受的,即认为识别错误。因此,本文依据语步要素的具体含义和学术研究成果使用的映射方式对照进行映射,具体对照映射关系为:将表2中序号为6、11、12、17的语步要素映射到“结论”语步,序号为7-10,13-16,18的语步要素映射到“方法”语步。依据映射后的语步,与测评模型的语步识别结果开展测评分析。
3.4 测评效果指标
本文语步识别效果的测评,对于每篇文献的每个语步要素,统计准确率P(Precision)、召回率 R(Recall)、 F1值(F1-Score),如公式(1)-公式(3)所示。使用F1值指标的算术平均值评价各语步的识别效果。同时,对每篇文献统计Accuracy,如公式(4)所示。通过Accuracy指标的算术平均值评价整体标注的准确率。
(1)
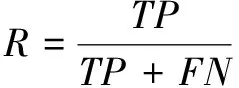
(2)
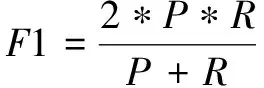
(3)
(4)
对于每个语步要素类型i来说, TP(True posit- ives)表示将实际为语步i且被预测为语步i的句子数。FP(False positives)表示将实际为其他语步类型但被预测为语步i的句子数。FN(False negatives)表示将实际为语步i但被预测为其他语步类型的句子数。
3.5 测评结果与分析
自动化测评:对结构化摘要数据,采用本文选取的基于BERT的掩藏句子模型开展语步识别。
测评一:语步识别效果的准确性与实用性、当前研究使用的5个语步要素的适宜性。结构化摘要语步识别效果统计如表3所示。其中,结构化摘要类别A、类别B的含义已在3.3节中说明。

表3 结构化摘要语步识别效果统计
从表3的结果中可看出:a.整体的语步识别准确率Accuracy平均值达70.88%,在NSTL的大体量科技论文数据中平均识别效果良好,准确率有进一步提升的空间。b.从各语步识别的平均F1值来看,“结论”语步识别效果最好,平均F1值86.27%,其次“方法”语步识别效果较好,平均F1值83.06%,“背景”语步识别效果最差,平均F1值31.36%。由此可看出,模型在不同的语步要素识别准确率上存在较大差异,普遍在“结论”“方法”语步上表现较好,其他语步识别效果较差,因此,模型后续可着力针对效果较差的这几个语步优化提升。c.在结构化摘要论文中,结构化摘要类别A的论文有1303763篇,占全部结构化摘要数据的87.68%,说明仅包含当前研究成果采用的5个语步要素内的论文量占比较多,5个语步要素的设置具有一定的合理性,能够涵盖大多结构化摘要数据。d.通过其他语步要素的合理映射,采用统一的5个语步要素,模型的识别效果在类别B与类别A数据上的统计效果基本一致,也一定程度上反映了映射方式较为合理。
测评二:语步识别在不同学科领域文献数据上的适用性和通用性测评。
将测评数据按照论文的分类号:理O、工T、农S、医R,分别统计理工农医4个学科领域语步识别效果,如表4所示。

表4 理工农医4个学科领域语步识别效果统计
从表4的统计结果可看出,(1)统计数据中理工农医文献数据量共约82万篇。其中,医学类的文献占比最多,约80.56万篇,占比为98.30%。且从Accuracy指标来看,医学论文的语步识别准确率最高,达73.17%。通过分析发现,本文选择的测评模型是基于PubMed(核心主题为医学)数据集训练得到的,因此在医学领域数据上表现效果最佳。(2)各学科间语步识别的效果存在一定的差异,医学、工学文献的语步识别平均准确率较好,Accuracy值均在73%左右,理学文献的语步识别平均准确率略低,农学文献的语步识别平均准确率最低,Accuracy仅为62.70%。(3)从语步要素角度来看,整体上 “结论”语步识别效果最好,且医学的“结论”语步标注效果最佳,达89.15%。其次是“方法”语步识别效果好,且医学的“方法”语步标注效果最佳,达83.80%。“背景”语步识别效果最差,平均F1值仅为34.16%。
人工测评:对非结构化摘要数据,采用随机抽样人工判读方式进行效果评估。
随机抽样的数据对象为英文期刊科技论文,按中图分类号对理(O)、工(T)、农(S)、医(R)4个学科领域的文献进行了随机抽样,每个领域各10篇论文,共40篇论文,对其语步识别结果进行判读,根据判读结果统计得出准确率Accuracy,结果如图4所示。
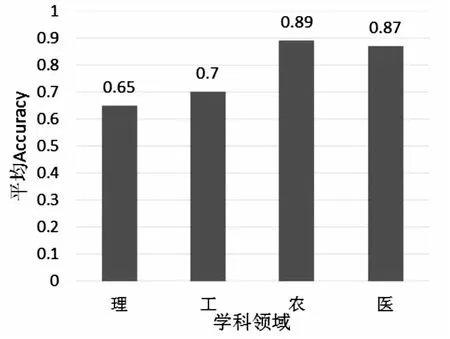
图4 非结构化摘要数据语步识别人工评测结果
如图4所示,对于随机抽样的非结构化摘要样例数据,在医学和农学领域数据中语步标注的准确率近90%,准确率和实用程度较好,但在理学和工学上的标注准确率较低,有优化的空间。从40个随机样例的语步识别结果判读来看,选取5个语步元素整体上具有一定的适宜性,仅有1个样例数据不适用该5个语步元素,具体分析后发现该文主要阐述了主题为建筑业未来及新冠影响的研讨会内容,摘要主要论述了研讨会概况和一些专家的观点,因此不适用。
4 语步识别成果在面向学术检索系统知识服务应用上的策略和建议
基于以上对摘要语步识别效果的测评结果与分析,对面向学术检索系统知识发现服务应用上的语步识别成果应用策略提出以下3点建议:
a.语步识别模型的准确率与学科领域的通用性有待进一步提升。在准确率上,模型在方法和结论语步上识别效果较优,可着力针对效果较差的背景、目的和结果三个语步优化提升。在学科领域上,当前语步识别研究成果多是基于单一领域的数据集开展研究,主要专注于模型算法的优化,提升识别准确性。然而在实际系统中面临的数据往往是多学科多领域的,在模型的准确性要求上同时关注模型的通用性和可扩展性,因此建议开展支持多学科领域协同的建模研究,进一步优化模型算法,增强模型成熟度和通用性,以满足实际应用需求。
b.可提供多层次的深度服务。学术检索系统可结合数据特点,服务场景、用户需求等,基于语步要素和语步内容为用户提供多层次的深度服务。服务的场景、内容,应用的深度、维度,功能的可操作性、便利性与实用性等都直接影响着用户体验。摘要语步识别研究成果在应用中可充分考虑不同场景的数据特点和不同用户的功能需求,以此获取用户青睐。如,检索场景下可扩展基于语步要素的检索功能,深化学术研究要素的细粒度检索,提升知识发现能力;浏览场景下可提供基于语步要素的分面筛选功能,通过限定语步精炼检索结果,实现检索结果的快速过滤;详情查看场景下可提供结构化要素的可视化展示功能,辅助用户快速掌握论文要点,提高阅读效率;统计分析场景下可提供基于语步要素的统计分析功能,为用户提供知识化的深度分析服务。
c.面向不同应用场景与数据特点采取不同的应用策略。从数据特点来看,摘要类型分为结构化摘要和非结构化摘要两类,这两类数据的应用上可采取不同的应用策略。如,对于结构化摘要论文,在论文详情查看场景下的结构化语步要素展示功能,可采用结构化摘要本身的语步要素进行展示,不受限于研究成果的固定语步要素,因为作者的结构化标识是对论文摘要内容最准确的阐述,与作者保持一致不论是对阅读用户还是作者本身来说都是最合适的方式;对于非结构化摘要论文,可采用研究成果得到的常用语步要素进行展示。而在其他场景下,如基于要素的扩展检索中,可采用固定的、常见的、用户较关注的结构化要素进行检索,以满足不同数据类型上应用的统一性。
5 结束语
本文为探究语步识别研究成果的成熟度,加速推动该成果的落地应用,面向NSTL实际的各种应用问题,制定了多维度的测评方案,包括准确性、实用性、语步要素类型适宜性、学科领域通用性等,测评内容较为全面,测评维度广,测评模型对象具有先进性,测评数据具有大体量和真实性,并通过自动化测评和人工测评主客观相结合的方式开展测评和结果分析。测评结果分析发现模型在识别的准确率和学科领域通用性上有待进一步优化提升,同时给出了面向应用的一些具体策略和建议,如多层次的深度应用服务,不同场景下可采用不同的应用策略,希望可以为该学术研究成果的工程化应用提供有益的参考。
猜你喜欢
健康之家(2021年19期)2021-05-23 11:17:39
医学食疗与健康(2021年27期)2021-05-13 18:46:23
河北理科教学研究(2021年4期)2021-04-19 13:34:44
农业科技与信息(2021年2期)2021-03-27 07:27:38
开封文化艺术职业学院学报(2021年1期)2021-01-02 22:02:23
计算机教育(2020年5期)2020-07-24 08:53:00
中国交通信息化(2018年5期)2018-08-21 03:37:40
厦门理工学院学报(2016年6期)2016-02-06 08:57:34
黑龙江工业学院学报(综合版)(2015年10期)2015-12-13 13:08:38
计算机工程(2015年8期)2015-07-03 12:20:35
