
基于交互注意力机制的多模态情感分析模型
2023-11-09 12:39周柏男,李旭,范丰龙,姚春龙
大连工业大学学报 2023年5期
周 柏 男, 李 旭, 范 丰 龙, 姚 春 龙
( 1.大连工业大学 信息科学与工程学院, 辽宁 大连 116034;2.大连工业大学 工程训练中心, 辽宁 大连 116034 )
0 引 言
随着社交媒体的迅速发展,数据种类与形式的多元化,产生了多模态数据。传统的文本情感分析仅仅利用文本数据分析情感信息[1]具有局限性,使得多模态情感分析成为研究热点。
多模态数据通常包含文本、视频和音频。多模态数据表示以及多模态特征融合是多模态情感分析中两类重要工作[2]。针对多模态数据表示,通常利用神经网络分别对不同模态的数据进行表示,Poria等[3]提出了一种基于多核学习的模型,利用深度卷积神经网络提取文本特征,并将其与其他模态以拼接的形式进行融合。Cambria等[4]提出了一个通用的多模态情感分析框架,该框架由模态内的特征学习和多模态的特征拼接组成,并为之后的研究奠定了基础。Zadeh等[5]引入了多模态词典,以便更好地理解在表达情感时面部、手势和音频之间的交互作用,并提出MOSI多模态情感分析数据集。之后Zadeh等[6]提出张量融合网络学习模态内和模态间的特征,并在MOSI数据集上提高了多模态情感分析的精度。为了能够考虑更多的上下文信息,Poria等[7]提出了一个基于LSTM的框架,利用上下文信息来捕获模态之间的依赖关系。Zadeh等[8]利用多注意力块来获取3种模态之间的信息,并在不同的数据集上有良好的表现。在Transformer出现之后[9],Tsai等[10]提出了跨模态Transformer模型,通过跨模态注意力机制来强化目标模态的特征学习。然而上述的多模态数据表示研究没有考虑在多模态数据表示中不同模态数据之间相互的关联,仅仅侧重于分别对不同模态数据进行表示。
多模态特征融合通常采用早期融合的融合方式。Poria和Cambria等[3-4]将多模态数据利用神经网络表示后,用简单的拼接方式进行特征融合。Liu等[11]提出低秩多模态融合方式,利用低秩向量表示多模态数据,再用笛卡尔积的方式实现特征融合。该融合方式没有考虑不同模态数据对情感分析结果的贡献程度,并且通常的多模态情感分析任务通常为单任务的训练方式,未考虑多模态情感分析和各个模态情感分析任务之间存在的关联和约束关系。
本研究提出一种基于注意力机制的多任务情感分析模型[12],利用单模态与多模态的情感分析任务相关性来实现情感分析任务。由于在自然语言任务中,语境信息对整体的识别性能有很大影响[13],所以在单模态情感分类任务中,采用自注意力机制来考虑单模态自身的语义信息,并利用模态间的交互注意力机制实现更充分的多模态特征融合。
1 方 法
1.1 问题定义
在多模态情感分析任务中,主要任务是确定视频段的情感极性或者情感强度,所以通常情况下多模态情感分析既可以视为分类任务,也可以被视为回归任务。在本研究中将多模态情感分析视为回归任务判断视频片段的情感强度。
模型输入为单模态原始序列Xm∈lm×dm,其中Xm为输入的原始序列,lm为序列的长度,dm为输入序列向量表示的维度。m∈{a,v,t},其中a为音频序列,v为图像序列,t为文本序列。输出为多模态情感强度在训练阶段该模型的输出其中n∈{a,v,t},使用作为最终的预测结果。
1.2 模型的整体结构
模型的整体结构如图1所示,该模型主要分为两个部分:多模态情感分析和3个独立的单模态情感分析。采用多任务的学习模式,多模态情感分析作为多任务学习中的主任务,3个独立的单模态情感分析作为多任务学习中的辅助任务,在不同任务之间采取共享底层表示的学习方式。

图1 整体模型结构Fig.1 Overall model structure
1.3 多模态数据表示
从视频段中提取出文本、视频、音频的数据信息,分别将这3种模态的输入序列Xm编码成向量表示hm,其中m∈{a,v,t}。对于文本类数据使用BERT[13]对输入序列进行编码表示,取最后一层的[CLS]标志位的向量表示作为整个句子的向量表示。对于音频数据和图像数据根据文献[14]、[15]使用双向LSTM[16]编码非文本数据特征,具体表示如式(1)、式(2)。
(1)
(2)
式中:ht为文本数据表示,hm为非文本数据表示。3类数据表示作为多任务学习共享的底层表示。
1.4 单模态自注意力机制
单模态注意力机制应用于多任务学习的辅助任务部分,主要利用单模态的上下文信息,只考虑单模态内部对情感分类的重要程度,无须考虑模态间的相互关系。输入的原始单模态数据表示hn∈ln×dn(hn包括ht文本数据表示和hm非文本数据表示),其中ln表示序列的长度,dn表示输入序列数据表示向量的维度。利用其自身的语义相关性,通过与自身单模态数据表示转置的点积,计算语义相关性矩阵M,对语义相关性较大的部分赋予更高的权重,之后对语义相关性矩阵做归一化处理得到单模态自注意力权重矩阵A。
M=hn·hnT
(3)
A=softmax(M)
(4)
将包含语义相关性的注意力权重矩阵A与原始单模态数据表示hn的点积,获得包含语境信息的新的单模态数据表示Hn。
Hn=A·hn
(5)
将得到的新的数据表示用于辅助任务部分。
1.5 模态间注意力机制
在得到文本数据表示ht之后,利用模态间语义相关性分别计算文本对应于音频和视频的相关程度(用语义相关性矩阵M1、M2表示,对应于音频或视频相关程度大的部分赋予高的权重)并对两个语义相关性矩阵进行归一化处理,得到文本对应于视频和音频的注意力权重矩阵A1、A2。
M1=ht·haT
(6)
M2=ht·hvT
(7)
A1=softmax(M1)
(8)
A2=softmax(M2)
(9)
将注意力权重矩阵A1、A2与原始单模态文本数据表示做点积,使新的数据表示包含文本数据与音频和视频数据的语义相关性权重信息,得到文本对应于视频和音频的2种数据表示如式(10)、式(11)所示。
HTV=A1·ht
(10)
HTA=A2·ht
(11)
为了使文本数据表示能够包含更多的模态间信息将两种数据表示以拼接的方式进行融合处理,得到的新的文本数据表示Ht。
Ht=HTV+HTA
(12)
同理对于音频数据以及视频数据与文本数据处理方式相同,分别通过计算语义相关性矩阵和注意力权重矩阵,从而分别得到新的数据表示Ha和Hv,最后将新的数据表示用于主任务部分。
1.6 多任务联合训练
多任务联合训练是将多模态情感分析作为主任务,单模态情感分析作为辅助任务并且辅助任务只存在于训练阶段,主任务与辅助任务共享底层的数据表示部分,将主任务的损失与辅助任务的损失作为模型的总损失一同进行优化。
对于主任务在得到单模态数据表示hn之后,由于多模态数据提取的特征向量维度不同,将3个多模态特征向量通过全连接层,避免向量的空间特征对计算的影响。再利用模态间的语义相关性分别对3种模态数据做模态间的注意力机制,得到3种模态新的数据表示Hn,其中n∈{a,v,t},并将新的单模态数据表示与原始数据表示相连实现多模态特征融合得到F。
F=Ha+Ht+Hv+ht+ha+hv
(13)
特征向量F相比之前的融合方式能够包含更多信息,并且能减少噪声。
由于ReLU激活函数具有稀疏性,使稀疏后的模型能够更好地挖掘相关特征,拟合训练数据,所以选取ReLU作为激活函数,将融合之后的数据表示F通过ReLU激活函数得到F*。
(14)
式中:W1∈Rln×2(da+dv+dt)。
将F*用于情感强度的预测。
(15)
式中:W2∈R2(da+dv+dt)×1。
为了减少单模态数据内部的噪声,利用单模态自注意力机制得到新的单模态数据表示Hn,使用ReLU激活函数,使单模态的数据表示具有非线性的特点。并利用激活函数输出进行情感预测。
(16)
式中:W1∈Rln×dn,W2∈Rdn×1,n∈{a,v,t}。
最后根据文献[15],利用其自生成标签方法实现单模态标签的生成。
yn=ULGM(ym,F*,Hn)
(17)
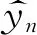
1.7 权重损失分配

(18)
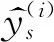
主任务多模态情感分析的损失采取用总损失的平均值计算,其中N表示训练样本的总数。
(19)
各个任务的损失本文的损失权重w_Ls如式(20)所示,其中s∈{a,v,t,m},并分别赋予各个任务。
(20)
对损失较大的部分赋予更大的权重损失,加速模型的收敛加快训练进程。模型总损失如式(21)所示。
(21)
2 实 验
2.1 数据集
使用MOSI和MOSEI数据集,两个数据集的基本信息见表1。

表1 数据集基本信息Tab.1 Basic information of dataset
CMU-MOSI数据集是多模态情感分析常用的基准数据集,是Zadeh等[5]收集的YouTube上关于电影评论视频为主的视频博客。总共随机收集了93个视频包含2 199条视频片段,这些视频的标注由来自亚马孙众包平台的5个标注者进行标注并取平均值,标注为从-3(消极)到+3(积极)的7类情感倾向。
CMU-MOSEI[17]数据集扩展了数据的内容,该数据集包含了3 228个视频,23 453个句子,1 000个讲述者,250个话题,总时长达到65 h,总计22 856条视频段。该数据集提供了2、5、7类情感分类的数据标注并且同样对情感强度进行了标注,标注为从-3(消极)到+3(积极)的七类情感倾向。
2.2 对比模型
为了充分验证模型的性能,使用近年来的多模态情感分析基准模型(TFN[6]、LMF[11]、MFN[18]:MISA[14]、REVEN[19]、MULT[8]、MAG-BERT[20])在相同数据集下与本文提出的模型进行比较。
2.3 超参数和评价指标
使用Adam作为优化器,BERT的初始学习率为5×10-5、dropout值为0.1,双向LSTM的dropout值为0,其他参数的学习率见表2。对于MOSI数据集和MOSEI数据集均采用相同的batch_size(batch_size=32)。

表2 MOSI和MOSEI数据集相关学习率Tab.2 Relevant learning rates of MOSI and MOSEI datasets ×10-3
根据文献[6]、[14],以分类和回归两种方式计算七分类任务的准确率(Acc7)、二分类准确度(Acc2)和F1评分:负/非负(不排除零)(Zadeh等[6])和负/正(排除零)(Tsai等[14])。对于回归任务本文采用平均绝对误差以及相关系数作为评价指标。
3 结果分析
具体的实验结果如表3、表4所示,除本模型数据,其他来源于文献[21]。其中对于二分类准确率(Acc2)和F1评分左边为负/非负的实验结果,右边是负/正的实验结果(排除零)。
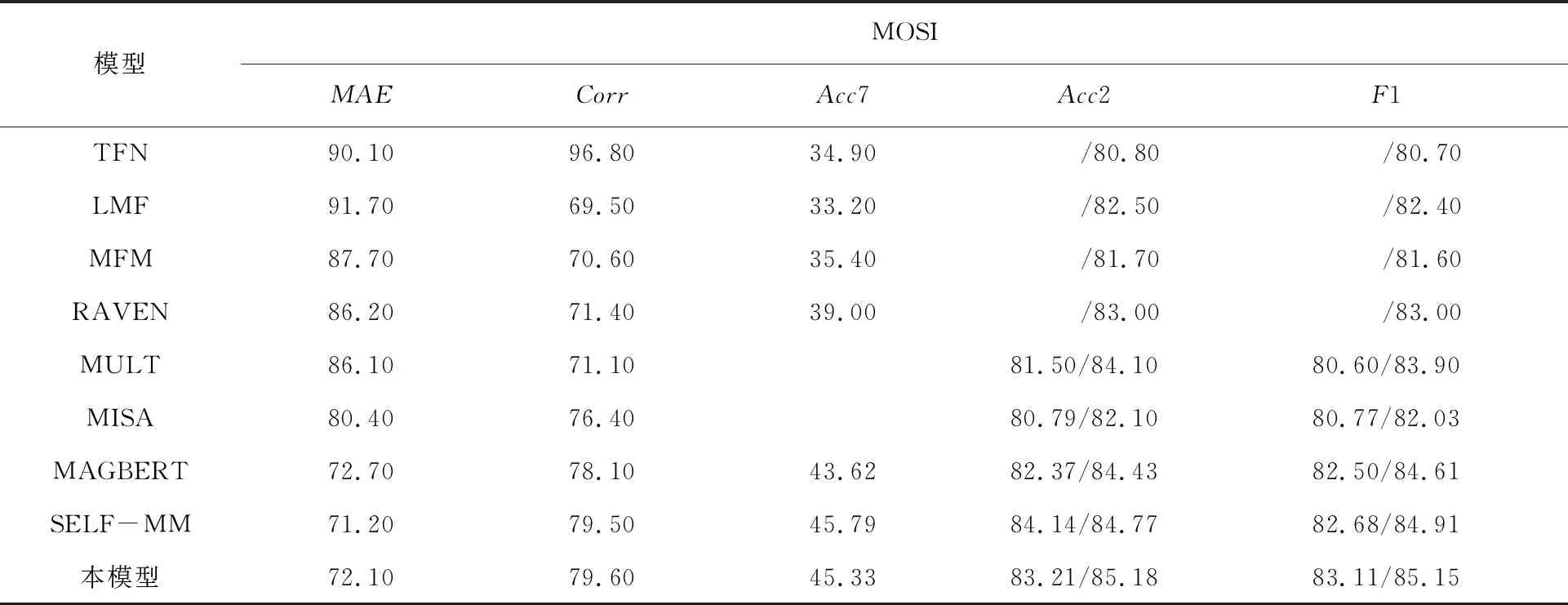
表3 MOSI数据集实验Tab.3 Experimental results of MOSI dataset %
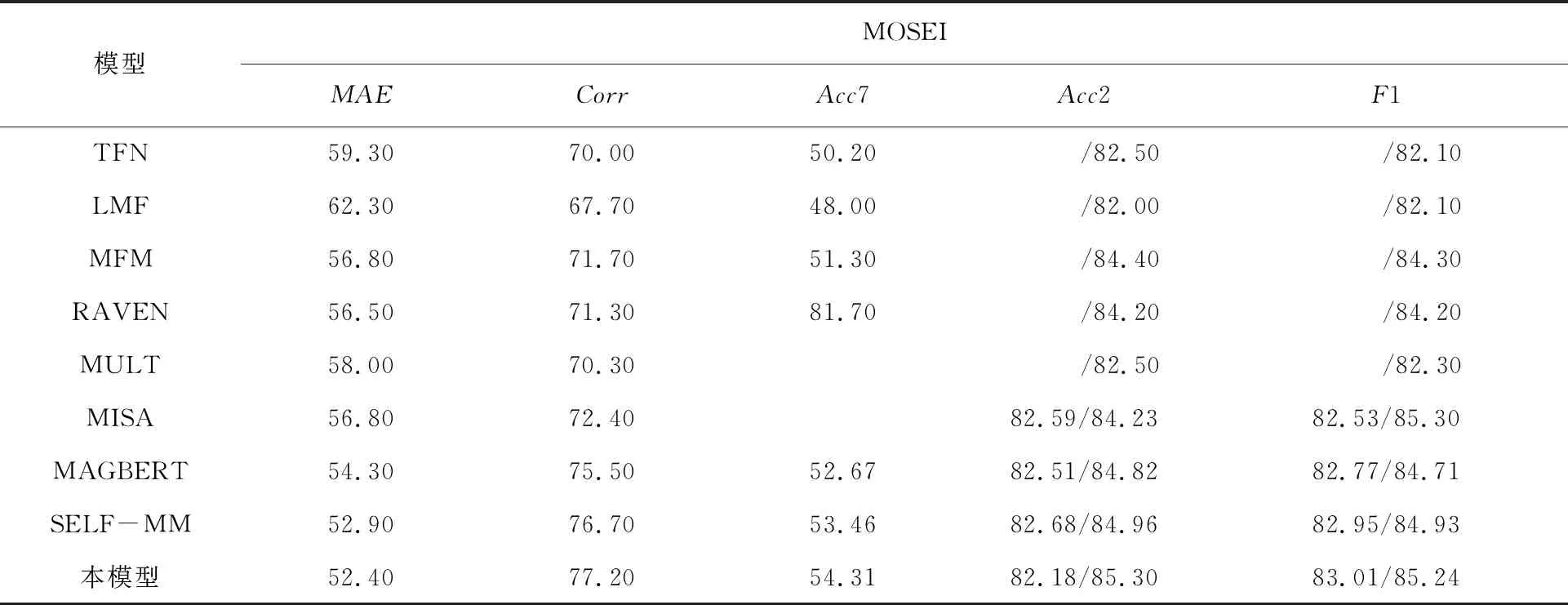
表4 MOSEI数据集实验Tab.4 Experimental results of MOSEI dataset %
实验数据证明,对于分类任务本文提出的模型相比早期的TFN、LFN等基准模型,在准确率和F1评分两方面有3%~5%的提升,相比于同样使用BERT作为文本数据特征提取的基准模型仍有提高。对于回归任务本文提出的模型在平均绝对误差MAE以及相关性Corr两方面也优于基准模型。就两个公共多模态情感分析数据集而言,由于MOSEI数据集的数据量远大于MOSI数据集,实验结果证明本文提出的模型在MOSI数据集上相关性,准确度以及F1评分上相比之前有所提升,然而在平均绝对误差上效果一般,说明数据量太小会影响数据的整体拟合效果,会导致整体的误差偏大,这说明数据是影响模型效果的重要因素之一。
3.3 消融实验
根据实验的结果可以发现,通过引入模态间的自注意力机制、单模态的自注意力机制以及损失权重分配,模型的性能有了提高。针对这3个方面做了消融实验,实验结果如表5、表6所示。

表5 MOSI数据集消融实验Tab.5 Ablation experimental results of MOSI dataset %

表6 MOSEI数据集消融实验Tab.6 Ablation experimental results of MOSEI dataset %
实验结果表明,分类任务在规模相对较小的MOSI数据集上,仅使用注意力机制可以更好地提高分类的准确性;规模较大的MOSEI数据集,注意力机制以及权重损失机制共同使用效果提升明显。对于分类任务,七分类任务的准确率、二分类任务准确率以及F1评分提升1%~4%,在回归任务中注意力机制以及权重损失机制共同使用,平均绝对误差MAE以及相关性也优于二者单独使用。本文提出的注意力机制以及权重损失机制在数据规模较大的MOSEI上表现明显,当去掉注意力机制时整体的分类效果在二分类的准确度下降1.2%~4.4%。充分说明注意力机制在自然语言任务中的重要程度,可以有效地帮助模型理解语义、语境信息。
4 总结与展望
提出了一种基于注意力机制的多任务多模态情感分析模型,该注意力机制主要分为两种:基于模态间的注意力机制以及单模态的自注意力机制。利用模态间交互注意力机制或单模态自注意力机制实现减少噪声,充分利用模态间信息增益,实现提高模型性能。但本文提出的模型仅能处理多模态的情感分任务,对单模态以及双模态情感分析任务没有自适应能力,并且多任务权重损失是一个没有参数学习的部分,仍需加以改进。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
文苑(2018年21期)2018-11-09
传媒评论(2017年3期)2017-06-13
第二课堂(课外活动版)(2016年2期)2016-10-21
湖北经济学院学报·人文社科版(2015年8期)2015-12-29
中国卫生(2015年9期)2015-11-10
上海电机学院学报(2015年4期)2015-02-28
中国卫生(2014年3期)2014-11-12
中国火炬(2014年4期)2014-07-24
计算物理(2014年2期)2014-03-11
