
基于7 nm NPU 预布局的布图优化设计
2023-11-08 17:58陈力颖
天津工业大学学报 2023年5期
陈力颖,高 祥,李 勇,徐 微
(1.天津工业大学电子与信息工程学院,天津 300387;2.天津工业大学天津市光电检测技术与系统重点实验室,天津 300387;3.台州国晶智芯科技有限公司,浙江台州 318014)
随着芯片制造工艺的不断进步,每块芯片上集成的晶体管数已经从几亿增加到几十亿,对于知识产权(IP)核和宏单元(macro cells)的使用也越来越多。对于先进工艺而言,特别是14 nm 及以下的工艺,芯片物理设计人员要花费更多的时间来摆放宏单元,进行平面布图规划(floorplan)[1-2]。布图规划的好坏决定着后续设计工作能否顺利进行,在一定程度上决定了芯片性能优劣[3]。当工艺到达7 nm 以后,线宽及线间距进一步缩小,受光刻分辨率的影响,需要采用双重图技术并对宏单元摆放的位置和距离做出更多限制才能达到光刻精度[4-5],这不仅加大了芯片的成本,而且增加了设计的复杂度[6]。
在采用先进工艺的芯片设计中,通常因为设计规模大,一般采用层次化的设计方法[7]。在层次化时,会根据功能将原本正方形的芯片区域,切割为多个四边形甚至多边形,其中高宽比相差较大的四边形和多边形在进行布图规划时的难度较大。
基于以上问题,本文以一款采用TSMC N7 工艺、高宽比接近3 ∶1 的子模块布图设计为例,在布图阶段预布局直通(feedthrough)寄存器,避开直通寄存器密集的位置,将宏单元放置在模块上下两端来优化布图,并根据N7 工艺对宏单元的约束编写TCL 脚本,修复违例,以期为解决直通寄存器不能在自动布局时均匀分布的问题和高宽比相差较大、纵向绕线较多的7 nm 布图设计提供参考。子模块中包含248 个宏单元,3 个静电保护单元及3 个定位单元。规模约为3 550 万门,面积为1 250 μm×3 532 μm,采用最新布局布线工具Innovus。
1 布图规划流程
芯片的物理设计流程可以分为展平式设计和层次化设计。其中,层次化设计是将整个设计分割成多个模块,对每个模块进行展平化处理,每个模块单独进行布图规划、布局布线,经过时序优化达到时序收敛,最终将满足要求的数据提供给顶层进行组装[8-11]。在超大规模的集成电路设计中,层次化设计方法可以减小设计复杂性,将问题集中于个别模块进行重点解决,同时还能缩短设计周期,加快时序收敛[12-13]。与多数布图设计时的宏单元摆放规则相同[14],层次化设计的布图规划流程是先将逻辑模块(module)细分,把与输入输出端口(I/O port)相关的宏单元摆在I/O port 附近[15],然后把处于同一个module 下的宏单元尽可能摆放在一起并均匀地分布在布图区域四周,宏单元之间留下足够的通道进行绕线与缓冲单元的插入[16]。布图规划完成后进行电源规划、布局、时钟树综合,通过内外部时序、早期布线拥塞和设计规则检查(design rule check,DRC)违例数量对布图规划进行评估,如果合理将继续进行后续步骤,若不合理将重新调整布图[17-18]。
2 传统四周摆放布图方法
采用布图规划流程中将宏单元摆放在四周的布图方法,在Innovus 中对module 进行Ungroup 操作,将宏单元所属的module 进行细分后,摆入布图区域。在遇到I/O port 时留出约100 μm 的间距,用于后续顶层拼接之后缓冲单元的插入,摆放完成的情况如图1 所示。

图1 四周摆放的布图结果Fig.1 Results of placed around floorplan
进行电源规划、布局以及时钟树综合,对各项性能指标进行评估,发现该布图存在较多时序违例,时序难以收敛,布线拥塞严重,纵向溢出(overflow)为9%。由此表明,使用四周摆放的布图方法不合理。不合理的原因主要有2 点:
(1)子模块的高宽比相差较大,为“瘦高”类型模块,宏单元数量较多,纵向走线多,但纵向的绕线资源较少,在中部摆放的宏单元造成了大量的纵向拥塞,导致时序恶化。
(2)为了避免输入到输出端口距离过长而插入直通寄存器进行打拍,如图1 中a、b 两组路径共插入了4 级寄存器,每组一级有2 048 个寄存器。但由于距离过长,工具在自动布局时不能使寄存器均匀分布,导致出现图2 中的情况。图2 中蓝色高亮部分为第3 级直通寄存器,而第4 级寄存器在输出端口附近,框内的第3 级寄存器到第4 级的距离超过了2 000 μm,过长的数据路径导致时序违例较大。

图2 第3 级直通寄存器分布Fig.2 Distribution of the third level feedthrough register
3 预布局布图优化方法
本文在布图阶段不再将宏单元均匀摆放在模块四周,并针对所遇到的问题提出以下方法:
(1)在布图阶段预先布局直通寄存器,将第1、4级直通寄存器固定在I/O port 附近,第2、3 级寄存器均匀分布在输入输出端口之间,减少路径过长引起的时序违例;在摆放宏单元时避开直通寄存器集中的地方,避免直通寄存器引起的拥塞;摆放时使用以下约束条件进行摆放,设置利用率为10%的区域型约束(region),避免工具优化时将这些寄存器位置挪动太多。具体命令为:
(2)摆放宏单元时将宏单元采取上下分布的摆放方法,将模块中间的部分空出来,留出更多的纵向走线资源,同时也避开直通寄存器密集的位置,避免造成拥塞,最后在摆放时给输入输出端口附近留出60 ~100 μm,以便在顶层优化时插入缓冲单元。
图3 为直通寄存器第二、三级预布局之后的情况与布图优化后宏单元摆放结果,红色为a 组端口之间的直通寄存器,蓝色为b 组端口之间的寄存器。

图3 布图优化结果Fig.3 Optimization results of floorplan
4 布图约束检查的修复
在7 nm 工艺中,因为特征尺寸、互连线的缩小,对光刻制造工艺也产生了较大的挑战,所以晶圆厂商为了提高精度以及成品率,添加了许多新的设计规则检查[19-20],在布图阶段进行的统一布图约束(unified floorplan constraint,UFC)检查就是其中的一种。对于不同的宏单元到芯片边界有着不同的距离要求,即宏单元加上晕环(halo)到布图上下边界的距离满足2.4+0.48n(n 为整数)或0.96+0.48n 的约束,约束条件为:


所以在宏单元摆放完成后还要进行UFC 的检查,检查之后出现了296 条UFC 违例,如图4 所示。

图4 UFC 检查违例Fig.4 UFC check violation
若提前计算好距离再去摆放宏单元和添加halo将是非常复杂繁琐的。根据规则的定义,关注宏单元切掉行(Row)之后,Row 边缘到Row 边缘的距离如图5 中黄色所框选的部分,而不是另外2 条halo 到halo或宏单元到宏单元的距离。

图5 间距要求示意图Fig.5 Schematic diagram of spacing requirements
所以通过脚本调整halo 的宽度,改变切割Row 的范围,可以修复大部分UFC 产生的违例。脚本计算主体如下:


通过foreach 循环完成计算每个宏单元到边界的距离是否满足约束,若不满足则需要重新添加满足约束的halo,在运行脚本之前还需要先进行如下设置:
以上设置将所有Macro 移动到鳍式场效应晶体管(FinFET)的格点(grid)上,只有在grid 上才能将芯片正确的制造出来。最后通过运行脚本对UFC 进行修复,修复后的结果如图6 所示,脚本运行前后的对比如图7 所示。
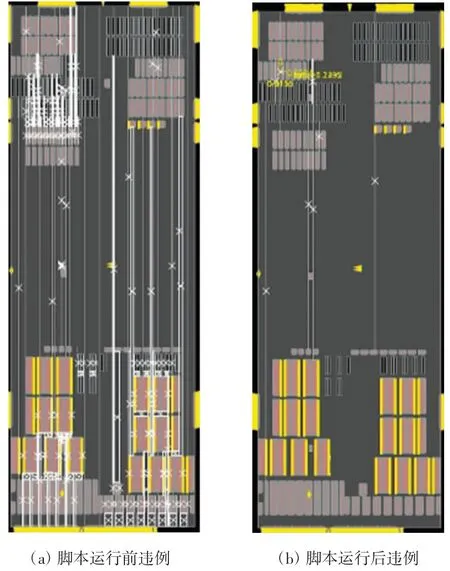
图7 脚本修复前后宏单元违例对比Fig.7 Comparison of macro cells violations before and after script fix
由图7 可知,由UFC 检查产生的违例由296 条降到了8 条,剩余的8 条为宏单元左右边界未对齐所引起的,可以通过手动调整宏单元左右位置,修复剩余UFC 违例。如果296 条违例都人工解决则至少需要花费2 h 以上的时间,而通过脚本修复之后,违例只需要8 min 以内便可修复,极大地提升了工作效率,缩短了约90%以上的时间。
5 布图结果对比
在预布局直通寄存器并对宏单元进行调整之后,进行相同的电源规划、布局优化,该模块的时序和拥塞都有了很大的改善。布局优化前后建立时间的最差负违例(worst negative slack,WNS)、负违例总和(total negative slack,TNS)和拥塞结果对比如表1 所示。

表1 布局优化前后结果对比Tab.1 Comparison of results before and after placement optimization
结合表1 可以看出,通过优化后的布图,WNS 和TNS 都有了明显的改善。在布局优化后WNS 由-0.364 ns 下降到了-0.233 ns,TNS 也从-16 731.7 ns下降-3511.57 ns,下降了约80%,纵向拥塞也从9.23%降到了0.98%。由此说明,布局优化后时序和拥塞有了明显的改善,可以大大减少后续时序收敛难度、绕线难度以及绕线后的线上违例,减少后续工作量。
在优化布图缩短数据路径并改善拥塞之后,功耗对比结果如表2 所示,可以看出,功耗也降低了约500 mW。

表2 功耗结果对比Tab.2 Comparison of power consumption results mW
6 结 论
针对直通寄存器在自动布局时不能均匀分布和高宽比相差较大、纵向绕线较多的布图设计,本文提出了在布图阶段提前布局直通寄存器,摆放宏单元时避开直通寄存器密集的位置,并将宏单元放置在两端的方法,结果表明:
(1)纵向拥塞从9.23%降到0.98%,WNS 减少了0.131 ns,TNS 减少了约80%,功耗下降约500 mW。
(2)针对TSMC N7 工艺中,为了正确制造而对宏单元提出的统一布图约束,在布图阶段通过编写脚本修复宏单元造成的大部分违例,相较人工修复工作效率提高了90%以上。
猜你喜欢
体育教学(2022年12期)2023-01-09
西藏艺术研究(2021年4期)2021-06-02
今日农业(2020年20期)2020-12-15
看世界·学术下半月(2020年4期)2020-09-10
计算机应用(2020年5期)2020-06-07
单片机与嵌入式系统应用(2017年7期)2017-07-31
体育科技(2016年2期)2016-02-28
创业家(2015年1期)2015-02-27
网络安全与数据管理(2011年24期)2011-08-08
通信技术(2010年8期)2010-08-06
