
适用于稀疏图的基于关键点标记的可达性算法
2023-10-29 04:20苗伟华
计算机与生活 2023年10期
苗伟华,危 辉
复旦大学 计算机科学技术学院/软件学院 认知算法模型实验室,上海 200438
对于一张有向图G=(V,E),其中u,v∈V。可达性查询是询问是否存在一条路径使得u点可以到达v点。可达性查询是图论中的基础操作,广泛应用于多种场景[1-3],如XML数据库、社交网络分析、物流运输、生物信息学等。比如检测两种蛋白质之间是否存在生物学通路等。但随着人类社会的发展以及大数据时代的来临,图的规模越来越大。传统算法如传递闭包、深度优先搜索等因为具有极高的时间复杂度或空间复杂度而变得不再适用。
一种有效的策略是针对有向图的不同结构特点,设计不同种类的算法[4-7]。GRKPL(graph reachability indexing via key points labeling)算法的提出是为了解决稀疏图上的可达性问题。现实生活中很多网络都是稀疏的,如电力网络、生物网络等。稀疏图通常具有的特点是边集规模和点集规模同阶。因此可以将稀疏图看作由若干有向生成树与少量非树边共同组成的。那么稀疏图上的可达性问题就可以被拆分为两部分:第一部分是生成树上的可达性问题;第二部分是引入非树边后增加了哪些新的连通点对。对于第一部分,已经有区间标记法[8]可以在线性时间内构建标记,并在常数时间内回答询问,该算法会在2.1节详细介绍。为了能够高效解决第二部分带来的可达性问题,提出了GRKPL算法,即基于关键点标记的图上可达性查询算法。GRKPL构建了一个规模与原图中非树边数量同阶的关键点集,通过将原图中的可达性查询转化为关键点集中点对的可达性的查询,从而解决了第二部分带来的问题。为了快速回答关键点集中任意两点之间是否可达,需要预处理关键点集的闭包。为了加速这一过程,构建了新图G′=(V′,E′),其中V′为关键点集。并从数学上证明了V′与E′的规模都是与非树边数量同阶的。设t为原图G中非树边的数量,,di表示i点的入度。则关键点集闭包传递的时间复杂度可以表示为O(|V′||E′|)=O(t2)。通过使用位压缩技术,将标记预处理的时间复杂度降至O(n+m+t2/w),其中n=|V|,m=|E|,w表示处理机字长。标记存储的空间复杂度降至O(n+t2/b),其中b为存储标记类型的比特数。查询回答的时间复杂度为O(1)。最后在14 个现实数据集[9]上进行了对比实验。GRKPL算法在中小规模数据集上表现优异,在查询处理方面,所用时间相对于其他算法平均减少49.8%,空间占用方面平均减少65.1%。预处理方面虽然表现不如搜索类算法,但相比标记类算法中表现较好的TOL(total order labeling)算法用时减少了17.4%。
1 相关工作
目前常见的可达性算法大致可以分为两类:标记法与搜索法。标记法会预先对图进行处理,构建并存储与可达性相关的标记。在回答查询时,便可以直接通过标记快速回答。如Floyd[10]直接预处理图中任意两点间的可达性。链剖分[11]将有向图分割成若干互不相交的链,预处理每个点能够达到每条链中的最小编号。树剖分[8]首先会找到有向图的一棵生成树,然后对其进行区间标记。因为有非树边的存在,每个点可能会有多个区间标记,那么在回答询问时就需要遍历每一个标记。Dual-Labeling[7]将可达性询问转化为二维平面上线段数量的查询。Path-Tree[12]将图划分为多条互不相交的路径,并将每条路径抽象成一个点,从而得到新图,最后通过深度优先搜索的方式对新图进行标记并处理相关标记。相关算法还有很多[13-19]。标记类方法的特点是预处理的过程通常需要花费大量的时间与空间,但查询的复杂度通常较低,大多数情况下均为常数级别。
搜索法则是另一种极端,通常具有较低的预处理时间复杂度与空间复杂度,但查询的时间复杂度会相对较高。大部分的搜索类算法都会结合一些标记以达到剪枝的目的,从而加快搜索过程。如GRAIL(graph reachability indexing via randomized interval labeling)[20]通过对图进行多次随机遍历,使得每个点都拥有多个区间标记。以此实现在搜索过程中快速处理不可达询问的目的。GRIPP(graph indexing based on pre-and post-order numbering)[21]在遍历图的同时维护了一张实例表,借助实例表可以在搜索过程中完成对查询的转换。IP(independent permutation)[22]首次引入了随机性,使用k-min-wise独立排列处理可达性查询。BFL(Bloom filter labeling)[23]提出了基于Bloom filter的一种新型标记方式,并证明了其误报率是有界的。相关算法还有很多[24-27]。由此可见,不同种类的算法本质上都是对空间复杂度与时间复杂度的一种权衡与取舍。表1 展示了一些可达性算法的时间与空间复杂度[22-23],其中n表示图中顶点数量,m表示边数。

表1 可达性算法复杂度Table 1 Reachability algorithm complexity
为了方便说明,之后所提到的有向图都默认为有向无环图,因为所有的有向图都可以通过Tarjan算法[28]进行强连通分量缩点后变为有向无环图。
2 GRKPL算法
GRKPL 即基于关键点标记的可达性算法,通过构建关键点集,将原图中的查询变换成关键点集上的查询,从而降低算法的时间和空间复杂度。设图G=(V,E)为有向无环图,其中n=|V|,m=|E|。T=(VT,ET)为图G的一棵有向生成树。对于图G来说,若存在多个入度为0的顶点,那么一棵树无法完全覆盖图G中所有的顶点,但是可以通过建立一个虚拟的根节点vroot,使得vroot向图G中所有入度为0 的点建边。这样以vroot为根的生成树就可以完全覆盖图G中的所有节点。对于有向边e,如果e∈E∧e∈ET,则称有向边e为树边,否则称为非树边。设t为图G中非树边的数量,则有式(1):
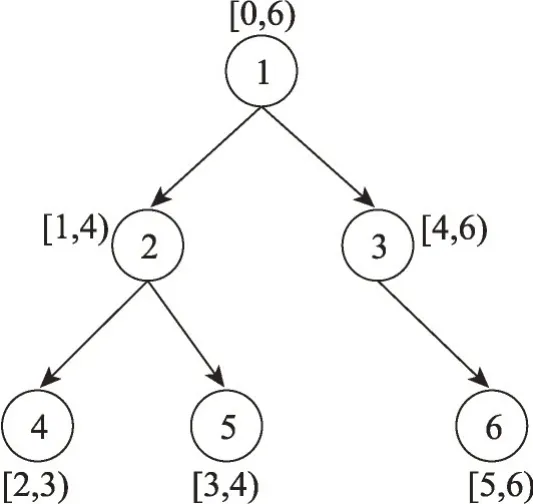
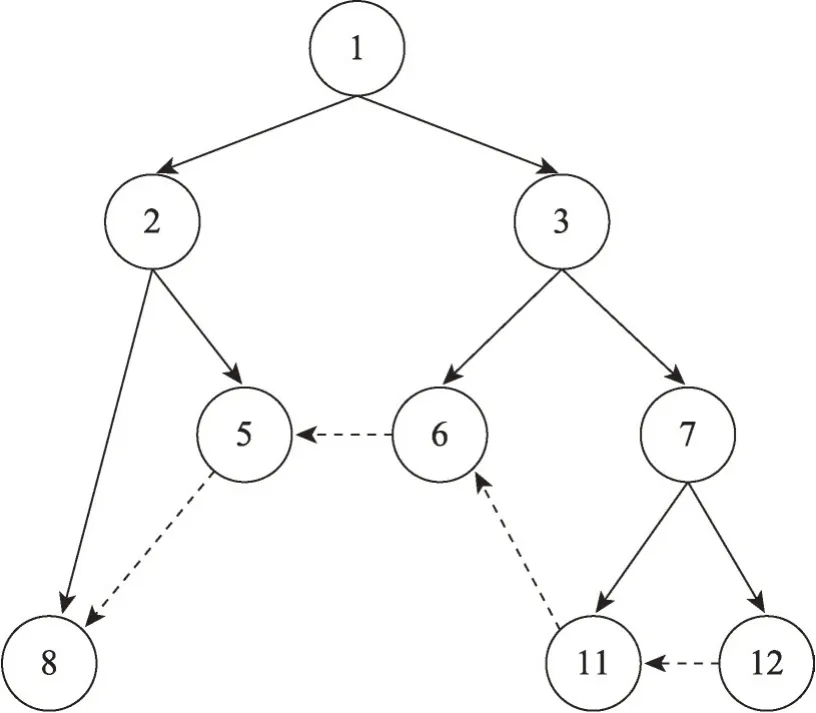
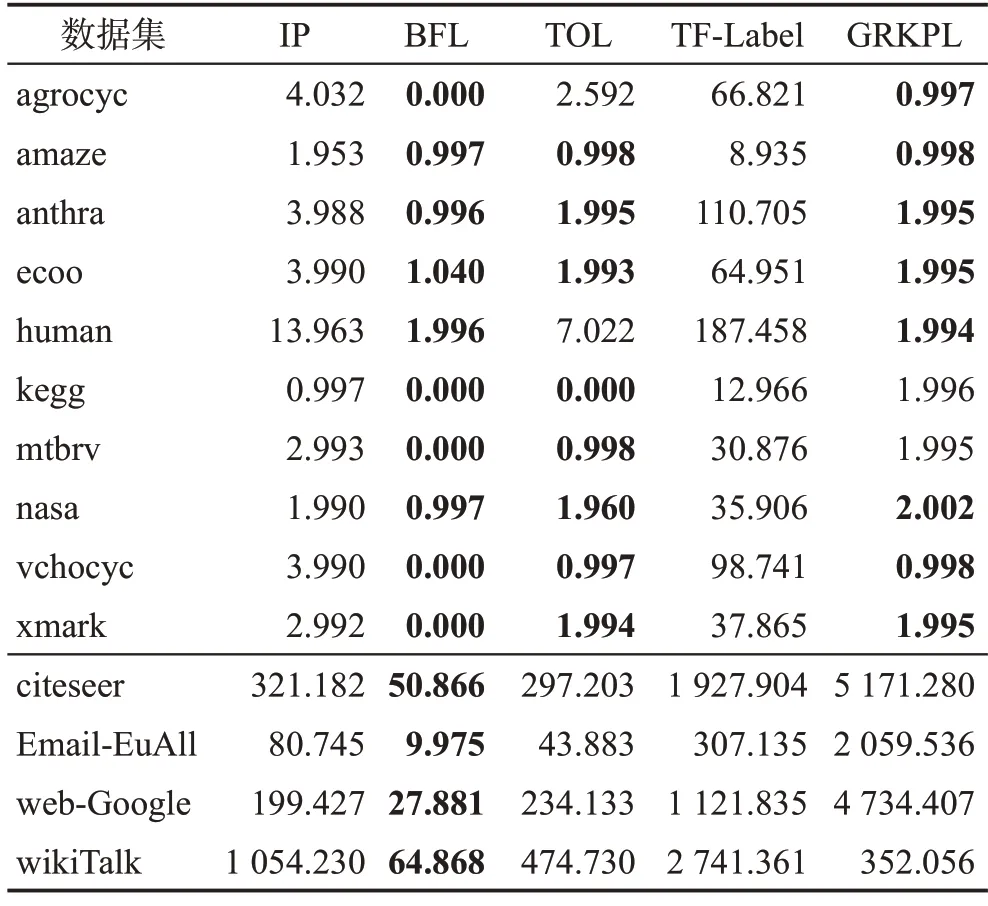
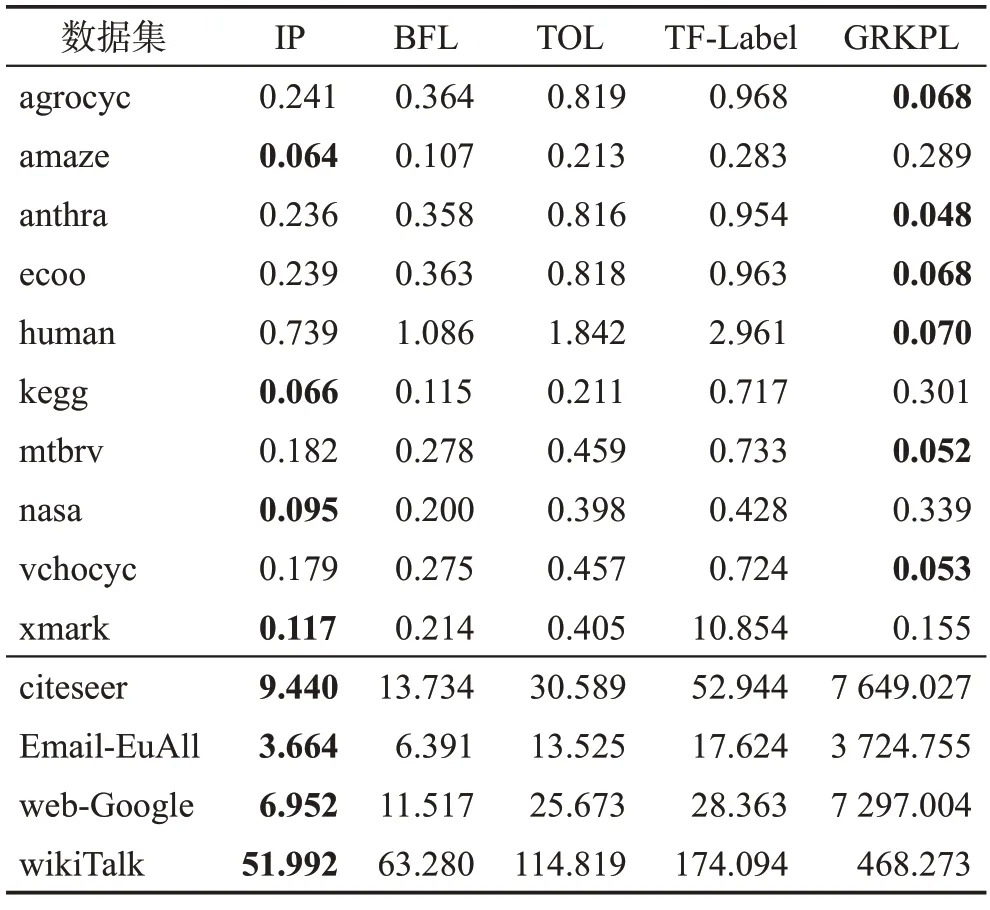
其中,di表示i点的入度,其思想是树上每个节点的入度至多为1,多余的入边则为非树边。对于稀疏图而言,往往有t< 树是有向无环图的一种特殊情况,对于树上任意两点的可达性查询有一个非常简单且高效的算法,称为区间标记法[8]。只需要对树进行深度优先搜索(前序遍历),在第一次进入节点u时记录当前的时间戳lu,在遍历完u点的子树后准备回溯时,记录当前的时间戳ru。这样对于树中每一个节点u都有标记[lu,ru)。在查询两点之间的可达性时,便可通过查询两点的区间标记是否是包含关系来判断,具体形式由式(2)给出: 如图1所示,若要判断v1是否能达到v5,只需查看进入v5的时间是否在v1的区间标记之中,即l5∈[l1,r1) 。又因为3 ∈[0,6),所以v1点可以到达v5点。通过此算法便可在O(n+m)的时间复杂度下预处理标记,其中n为树的节点数,m为树的边数。在O(1)的时间复杂度内回答询问。 图1 区间标记后的树Fig.1 Tree after interval labeling 因为稀疏图可以看作以vroot为根的有向生成树与少量非树边的组合,所以可以先找出稀疏图的有向生成树,然后对该生成树进行区间标记。虽然稀疏图中以vroot为根的生成树并不唯一,但生成树的形态对于算法复杂度的影响微乎其微。因为影响算法复杂度的是图中非树边的数量,而这个值与生成树的形态无关。算法1 提供了一种在选取生成树的同时进行区间标记的方法。 算法1寻找生成树并进行区间标记 输入:vroot表示虚根。 输出:图中所有节点的区间标记(l,r)与生成树。 参数说明:dfn表示时间戳,G表示邻接表,用于存图。 图2 展示了对图G进行区间标记后的结果。其中实线表示树边,虚线表示非树边。假设查询(u,v),即查询u点是否可以到达v点。如果v点在u点的子树内,那么u点便可以仅通过树边到达v点。不然u点必须要经过若干树边和非树边才可以到达v点,或者是不可达。定义u点为覆盖点,当且仅当u点的入边或出边中包含非树边。图2 中的覆盖点集合CG={v5,v6,v8,v11,v12}。若u点要经过若干树边和非树边才可以到达v点,那么u点必然会先走到其子树中的某个覆盖点x,再从x出发经过若干非树边和树边到达某个覆盖点y,最后从y点沿树边走到v点。这样便可以把原始查询(u,v)变为新查询(x,y)。但并不是所有的查询都可以转化为覆盖点之间的查询。假如u点的子树内不包含覆盖点,那么u点到v点的所有路径中必然不会经过任何一条非树边。同理,若v点的祖先内不包含覆盖点,那么同样u点到v点的所有路径中也不会经过任何一条非树边。因此需要对这种情况进行特殊判断。 图2 区间标记后的图GFig.2 Graph G after interval labeling 设Su表示u点子树中的覆盖点集,Pv表示v点祖先中的覆盖点集。对于查询(u,v),如果v点不在u点的子树中,那么需要枚举Su中的点,检查其是否能到达Pv中的任意一点。因为|Su|和|Pv|的数量级都是O(t) 的,所以这种做法的时间复杂度会退化到O(t2)。但事实上可以通过两步优化,将查询的复杂度降到O(1)。 优化1设根节点的深度为0。Pv中深度较小的节点一定能够沿树边达到深度大于或等于自身的节点。因此对于查询(u,v)来说,只需要检查Su中是否存在一个节点,能够到达Pv中深度最大的节点即可。这样时间复杂度就可以降至O(t)。 优化2当|Su|>1 时,希望可以找到一个点x,满足点x可以到达Su中任意一点。这个点x实际上就是Su中所有节点的公共祖先。不妨取x点为u点子树内所有覆盖点的公共祖先中深度最大的祖先,即最近公共祖先(lowest common ancestor,LCA)[29]。那么原查询(u,v)就可以转化为新查询(x,y),其中y为Pv中深度最大的节点。因此只要预处理T中每个节点子树内所有覆盖点的最近公共祖先,再结合优化1,就可以做到在O(1)时间复杂度内回答查询。 设T中的覆盖点集合为CT={a1,a2,…,am},T中每个节点子树内所有覆盖点的最近公共祖先为LT={lca(Sv)|v∈[1,n]}。定义图G的关键点集KG=CT⋃LT。综上可知,除2.2 节中讨论的特殊情况外,原图中任意点对之间可达性的查询均可转化为关键点集中点对可达性的查询。定理1与定理2将证明|KG|的数量级为O(t)。 由定理1 可知,设CT={a1,a2,…,am}表示T中所有覆盖点,则有式(3)成立。因此不需要对T中每个节点都计算出其子树内所有覆盖点的最近公共祖先,只需把所有覆盖点两两之间的最近公共祖先求出即可。 证明定理2 等价于:对于i∈[2,r],有∀j∈[1,i),成立。当r=2 时,有lca(a1,a2)=lca(b1,b2),定理显然成立。假设r=k时定理成立,当r=k+1时,不妨假设存在u=lca(bt,bk+1),t∈[1,k),且设dep(u)表示u点在生成树中的深度,因为bj是按照前序遍历的顺序排序后得到的,所以当j 由定理2 可知,LT=Qvroot=Rvroot,因为|Rvroot|的数量级为O(t),所以LT的数量级也为O(t) 。又因为KG=CT⋃LT,所以关键点集|KG|的数量级也为O(t)。图3展示了G中的关键点集,其中CT={v5,v6,v8,v11,v12},用斜线填充的节点表示。LT={v1,v2,v3,v7},用实心节点表示。由于有向图的生成树并不唯一,对于不同形态的生成树,其得到的关键点集也是不同的。但由定理2可知,|LT| 图3 图G 中的关键点集Fig.3 Set of key points in graph G GRKPL 算法的标记由两部分组成:第一部分是点u祖先中深度最大的关键点,记为pidu;第二部分是点u子树中深度最小的关键点,记为sidu。因为关键点中已经包含了所有覆盖点两两之间的最近公共祖先,所以sidu必然是u点子树内所有覆盖点的最近公共祖先。需要对图G中所有节点都求出这两部分标记。对于第一部分标记,可以用栈在深度优先搜索的时候保留路径上的关键点,对于当前点来说,若栈为空,则表示其祖先中不存在关键点,否则栈顶即为所求。在回溯的时候,如果当前点是关键点,那么从栈中把它弹出。对于第二部分标记,可以在深度优先搜索的时候检查当前点u是否为关键点,如果是则从当前点开始沿着父亲边(树边)往回跳,一直跳到点v已经被打上第二部分标记或者跳到根为止。这回跳的过程中经过的所有点的第二部分标记都是点u。最终标记效果由图3 给出。算法伪代码由算法2给出。 算法2构建GRKPL标记 输入:vroot表示虚根。 输出:图中所有节点的(sid,pid)。 参数说明:vis[u]表示点u是否访问过;stk表示栈;par[u]用来记录点u在树中的父亲;G表示邻接表,用于存图;K(G)表示图G中的关键点集。 为了加速关键点集中闭包的传递,需要将关键点集从原图G中分离出来。图4 展示了分离之后得到的新图G′。为了防止G′中边的规模退化到O(t2),需要维持原本的树形结构。具体做法为在深度优先搜索的过程中处理出每个点其祖先中深度最大的关键点,然后只需要连接这两个点即可。这样既不会破坏闭包,同时也将新图中边集的大小控制在了O(t)级别,因为去除非树边后,每个点的入度都是1。因此边集的数量级和点集的数量级是相同的。 图4 分离后的新图G′Fig.4 New graph G′ after separation 传统Floyd-Warshal[10]算法传递闭包的时间复杂度是O(n3),空间复杂度为O(n2)。但对于有向无环图来说,可以通过动态规划的方法进行加速,使时间复杂度变为O(nm)。具体做法是:首先设dp[u][v]这个二维数组存储图G中任意两点之间的可达性,取值0或1。然后将图G按逆拓扑序进行排序后顺序遍历,若当前节点为u,那么u点可以通过它的出边到达它所有的后继节点,即可以用所有后继节点的状态来更新当前节点的状态。又因为遍历的顺序是逆拓扑序,这样就保证了访问u点之前,u点所有可能可达的点已经都访问过,从而保证了算法的正确性。具体更新规则由式(4)给出: 由于所要求解的答案只有两种状态,即0和1,分别表示可达与不可达,可以用1 bit 来表示这个信息。计算机在进行一次运算时是以字为单位的,设计算机字长为wbit。那么将信息位压缩后,时间复杂度变为O(nm/w),因为计算机一次可以对wbit同时操作。空间复杂度也会相应地降低。若以C++中语言的int 类型来存储信息,因为一个int 类型有32 bit,那么压缩后的空间复杂度会变为O(n2/32)。 对于查询(u,v),如果u=v,那么一定可达。设dep[u]表示点u的深度,根的深度为0。点u的区间标记为[lu,ru),点v的区间标记为[lv,rv)。如果点v在点u的子树内,即满足dep[u] 算法3查询处理 输入:(u,v)查询u是否能到达v。 输出:true or false。 参数说明:dep[u]表示u点深度,map[u]表示关键点u在新图G′中的编号。 实验环境:操作系统Windows 11,CPU Intel i5-9300HF,内存16 GB,编译指令g++-std=c++17-O3。程序语言为C++,编译器版本为gcc 8.1.0,boost 库版本为1.80。实验共用到14 个数据集[9],包含了10 个中小规模数据集与4 个大规模数据集,表2 展示了数据集的规模。参与比较的算法可以分为两部分,搜索类的算法有IP[22]和BFL[23],标记类的算法有TOL[16]、TF-Label[17]和GRKPL。程序代码均由原作者提供。 表2 数据集规模Table 2 Scale of datasets 算法参数配置:GRKPL 算法包含两个可变参数。计算机字长w由CPU架构决定,实验采用64位机器,因此w=64。存储标记类型的比特数b由程序语言与编译器决定,实验采用int 类型存储标记,因此b=32 。其余算法均采用原论文中使用的默认参数。 实验内容:对于每一个数据集,随机生成1 000万个查询,测试并分析不同算法在查询时间、预处理时间与标记的空间占用三方面的表现。 表3 展示了五种算法在处理查询时所耗费的时间。可以发现在14个数据集的测试中,GRKPL算法在其中8个数据集上都有更好的表现,但是也有一些表现不佳的情况,这是由于稀疏图中大部分的随机查询都是不可达的。虽然GRKPL 回答查询的复杂度是O(1),但并没有对不可达的查询进行优化,因此程序运行时所执行的语句会相对更多,时间就会相对较慢。GRKPL 算法在10 个中小规模数据集上查询共用时663.145 ms,优于其他四种对比算法,查询平均用时减少49.8%。 表3 查询处理时间Table 3 Query processing time 单位:ms 表4 展示了五种算法在不同数据集上的预处理时间。可以看出搜索类算法(IP、BFL)的表现整体优于标记类算法(TOL、TF-Label、GRKPL)。这是由于算法类型的不同,搜索类构建的标记更多是用于对搜索过程的剪枝,而标记类算法则是需要依靠标记来回答询问。因此这注定了搜索类算法在预处理时间以及标记存储空间两方面都会优于标记类算法,表5 展示的标记的空间占用情况也证实了这一点。尽管如此,GRKPL 算法在许多数据集上的表现也会优于搜索类算法,并在绝大多数情况下都会优于其他两种标记类算法或表现相当。GRKPL 在10 个中小规模数据集上的预处理时间总计为16.965 ms,仅次于搜索类算法BFL 的6.026 ms。相比同属标记类算法中表现较好的TOL(20.549 ms),预处理时间减少17.4%。GRKPL在10个中小规模数据集上的空间占用总计为1.443 MB,优于其他四种对比算法,空间占用平均减少65.1%。但是在大规模数据集上,GRKPL算法的预处理时间与空间占用都非常大。这是由于图中存在大量的入度为0的节点,导致非树边的数量较高,影响了性能表现。 表4 预处理时间Table 4 Preprocessing time 单位:ms 表5 标记的空间占用Table 5 Space occupied by labels 单位:MB 测试所用的数据集分别对应了若干个不同的现实领域。如agrocvc、amaze、anthra 等对应于生化领域,包括蛋白质相互作用、基因表达等。基因、化合物、蛋白质等可以抽象为节点,它们之间已知的关联作用可以抽象为有向边。GRKPL算法可用于快速回答两个节点是否存在直接或间接的联系,如查询一个基因是否受到另一个基因的调控。nasa 与xmark为XML 文档,其结构化的特征使其能够被抽象为一张有向图。GRKPL算法能够快速回答元素之间的从属关系。GRKPL算法的特点在于其影响复杂度的主要因素为图中非树边的数量,这使得其在一些规模较小的现实网络如生化网络、XML 文档等中优势较大,不仅查询速度快,标记占用空间与预处理时间也很少。但在一些规模较大的网络如邮件网络(Email-EuAll)、网站引用网络(web-Google)中,因为非树边的数量较大,导致标记占用空间与预处理时间增加。 本文提出了一种针对有向稀疏图可达性算法GRKPL。通过对图进行拆分,将原图中的查询转换到另一个规模更小的点集中的查询,该点集也称为关键点集。并证明了关键点集的规模与原图中非树边的数量同阶。这使得在处理稀疏图中可达性问题时,预处理标记的时间与标记的空间占用都进一步缩小。最后在14个现实数据集中进行测试,GRKPL算法在大部分的数据集中都表现优异。GRKPL算法局限性在于:其预处理时间复杂度与标记占用空间复杂度的级别都是非树边数量的平方。因此当作用于一些规模较大或较为稠密的网络时,算法的性能表现会下降。 后续研究方向主要包含两部分:第一部分是如何优化不可达查询的处理速度。在稀疏图中有大量不可达查询,而GRKPL 算法的逻辑是优先判断可达。因此在面对不可达查询时,所要执行的步骤较多,会影响查询速度。第二部分是如何将GRKPL算法扩展到动态图中,即在面对节点或边的动态增加或删除时,如何快速更新标记,保证查询效率等。2.1 区间标记法
2.2 查询转化

2.3 构建关键点集

2.4 标记预处理
2.5 闭包传递
2.6 查询处理
3 实验
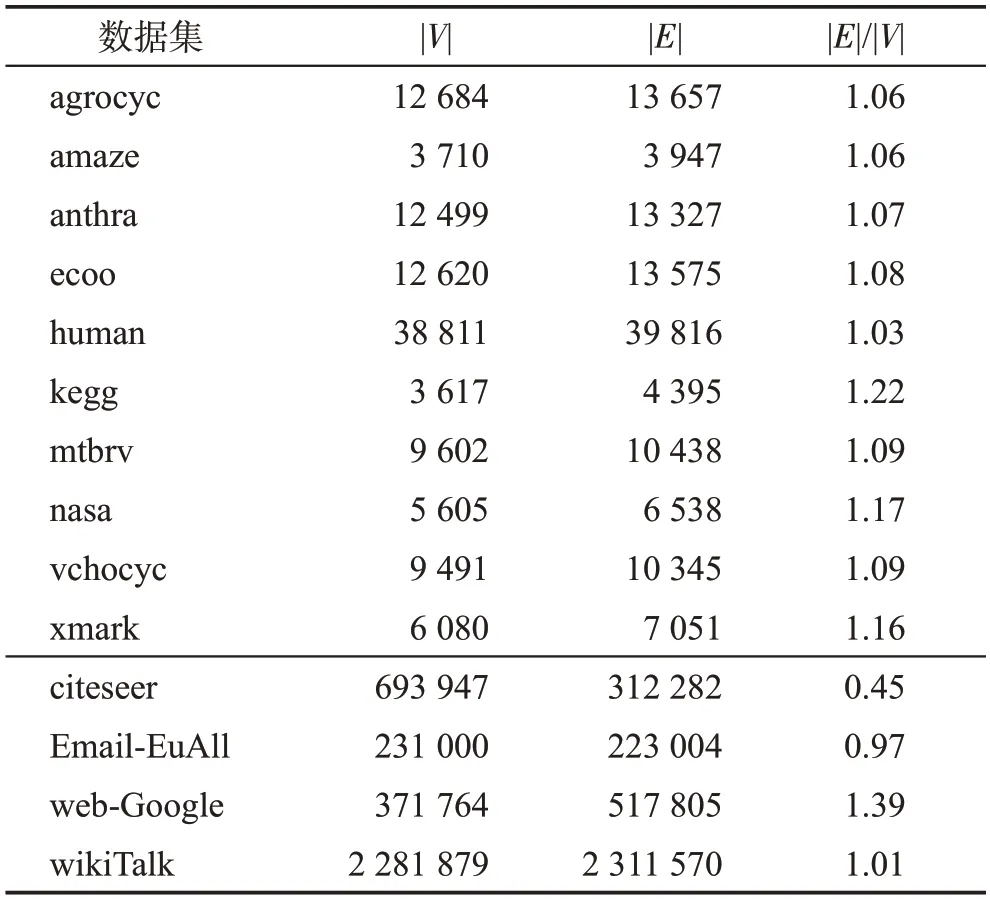
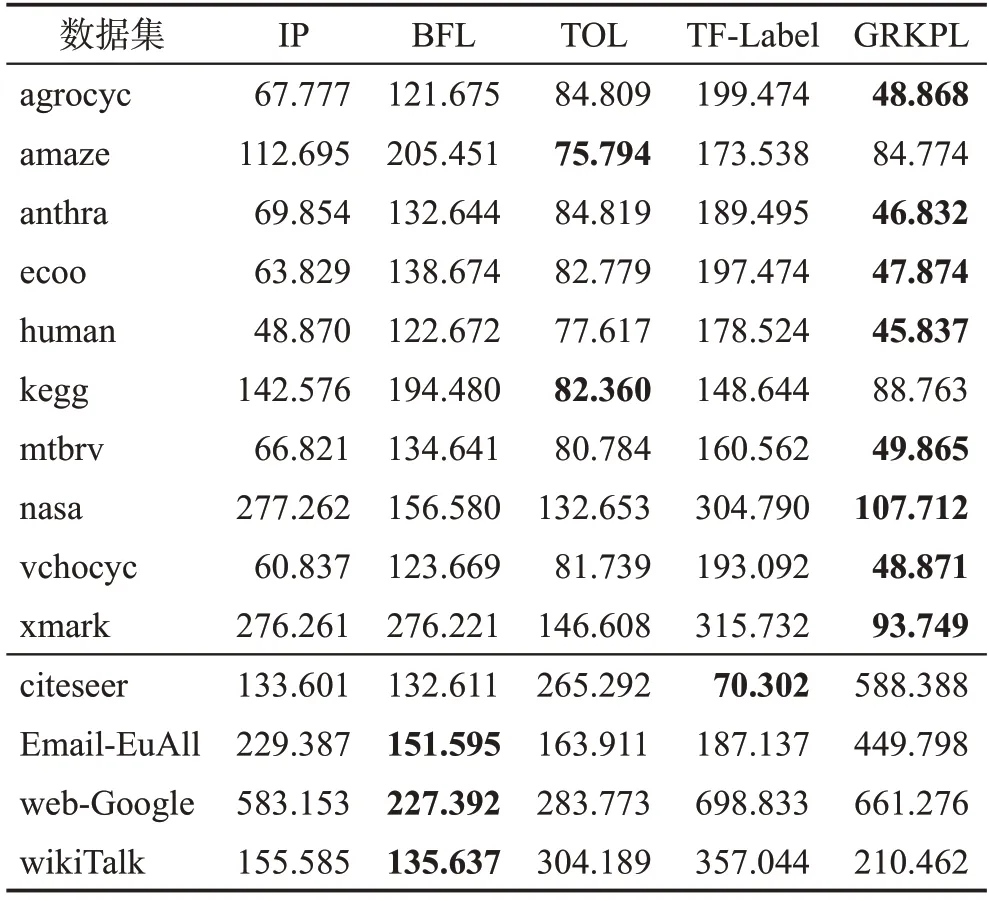
4 结束语
猜你喜欢
中学生数理化·中考版(2022年12期)2022-02-16科学大众(2021年21期)2022-01-18今日农业(2021年8期)2021-11-28中国惯性技术学报(2019年6期)2019-03-04小哥白尼(趣味科学)(2018年10期)2019-01-16红领巾·探索(2018年10期)2018-11-14中央民族大学学报(自然科学版)(2017年2期)2017-06-11火控雷达技术(2016年3期)2016-02-06课堂内外(初中版)(2015年12期)2015-09-10浙江理工大学学报(自然科学版)(2015年10期)2015-03-01
