
基于图神经网络的实体对齐表示学习方法比较研究
2023-10-29 04:20曾维新唐九阳
计算机与生活 2023年10期
彭 鐄,曾维新,周 杰,唐九阳,赵 翔
国防科技大学 大数据与决策实验室,长沙 410073
知识图谱(knowledge graphs,KG)是以三元组的形式(头实体、关系、尾实体)存储和表示知识的一种图数据库,其中每个节点都代表真实世界中的某个唯一的对象,而边则表示这些对象之间的关系。知识图谱已被广泛用于改进各种下游任务,例如语义搜索[1]、推荐系统[2-3]和自然语言问答[4-5]。在实际应用中,不同的知识图谱通常是从不同数据来源独立构建而得,因此难以覆盖某一领域的全部知识[6]。为提高知识图谱的完备性,一种常用的做法是将其他知识图谱融合进来,因为这些知识图谱可能包含额外的或者互补的信息[7]。在这一过程中,一个关键的步骤是识别出两个不同知识图谱(分别被称为源知识图谱和目标知识图谱)中的等价实体,即指向真实世界中相同对象的实体[8]。这一任务被称为实体对齐(entity alignment,EA)。
当前的实体对齐方法大都假设不同知识图谱中的相同实体具有相似的邻接结构信息,然后通过表示学习和对齐推理两个步骤完成实体对齐任务[9]。其中,表示学习旨在将知识图谱表示为低维向量,根据向量之间的关联建立不同知识图谱中实体的关联。表示学习的效果对最终对齐的结果有着较大影响,因此当前的大多数研究都致力于提升表示学习的准确性。实体对齐中表示学习的早期代表方法为TransE[10],该方法假设每个三元组(h,r,t)满足近似等式h+r≈t,并根据该假设学习三元组的表示。后续提出的改进方法TransH[11]、BootEA[12]、MTransE[13]等也都是对该假设的变换。而近期的实体对齐工作,大多都采用图神经网络(graph neural network,GNN)[14]来学习知识图谱的表示,主要通过建模实体的邻居特征来生成实体的向量表示。具体地,基于图神经网络的方法通过消息的传递与聚合,使得每个实体的表示都融合了其邻居实体、关系或其他类型的特征信息,从而生成准确的实体表示[15]。目前基于图神经网络的方法已从初始的一跳邻居实体特征的学习,发展到了对更大范围的多种特征的学习,并且附加了辅助增强学习效果的模块[16-19]。
图神经网络由于模型结构与知识图谱的相容性和强大的图结构信息的学习能力,在实体对齐的表示学习中得到了广泛的应用,发展出了结构纷杂多样的各种方法。为了以一个统一的便于理解的框架描述这些方法,剖析其内部结构和工作原理,并为未来方法的优化改进提供参考,本文对这些模型进行了归纳与比较研究。本文的主要工作可以总结为以下三点:
(1)提出了一种描述这类表示学习方法的通用框架,并选取了近期具有代表性的工作进行总结和对比,根据该通用框架对这些工作中的表示学习模型的各个部分进行了解构和归纳。
(2)进行了这些模型之间的对比实验和表示学习模型内部结构的消融和替换实验,揭示了当前方法的优缺点,为后续的研究提供参考。
(3)针对当下兴起的语言大模型与知识图谱结合的研究方向,通过初步的实验指出了该场景下现有表示学习方法的问题以及下一步需要研究的方向。
1 模型概述
1.1 通用框架
为更好地理解当前基于图神经网络的表示学习方法,本文提出一个通用框架来描述这些方法,如图1所示。该框架包括六部分:预处理模块、消息传递模块、注意力模块、聚合模块、后处理模块和损失函数。
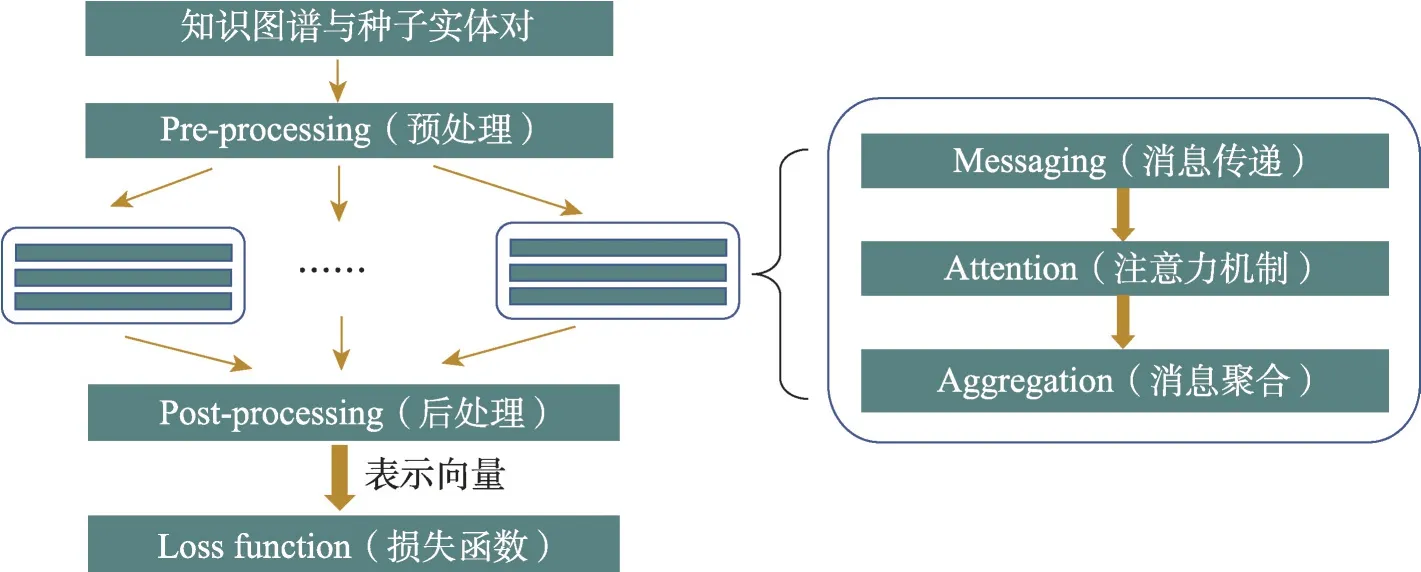
图1 表示学习通用框架Fig.1 Universal framework of representation learning
首先是预处理阶段,旨在对原始知识图谱的三元组信息进行处理,以生成初始的实体或关系向量表示;然后通过一个或若干基于图神经网络的模型获得更好的表示。一个图神经网络通常包含三个步骤,即消息传递、注意力和聚合。消息传递过程基于图谱的结构、属性和语义等信息,提取邻居实体或关系的特征,用于后续的特征整合与更新;注意力模块旨在计算不同特征的权重来进而优化邻接信息的整合过程[20-21];聚合模块则基于前述所提取的邻接特征以及注意力机制计算出的权重来聚合特征,并得到更新后的向量表示[22-23]。一些方法还通过后处理操作,增强得到的最终表示。在训练阶段,损失函数决定了表示学习模型训练的方向。
1.2 结构比较
按照上述通用框架,本文选取了十种近期实体对齐工作中的表示学习模型,并总结如表1所示。下面分别阐述这六部分的现状:
(1)预处理模块。部分方法未进行预处理操作,直接采用随机的初始化方法。其他方法主要分为两类:一类是使用预训练模型,输入名称或文本描述来生成初始表示;另一类则是使用较为简单的GNN 学习结构信息来生成初始表示。
(2)消息传递模块。从表1中可以看出大部分模型采用了线性变换的方法,即用一个可学习的参数矩阵乘以邻居特征。其他消息传递的方法则包括多头邻居消息的拼接,直接使用邻居特征等。
(3)注意力模块。根据计算公式中相似度的计算方式,可对这些模型进行分类。其中大部分模型采用了拼接乘积的形式计算中心实体和邻居的相似度。具体而言,便是将中心实体与邻居的特征进行拼接,然后乘以一个可学习的参数向量。还有部分模型采用了内积的形式,通过计算中心实体与邻居特征的内积来得到两者的相似度。
(4)聚合模块。按照计算公式中聚合的对象对这些模型进行了分类。从表1 中可以看到几乎所有模型都聚合了1跳邻居实体或者关系的信息,同时也有个别模型结合了多跳邻居的信息。
(5)后处理模块。大多数模型采用了拼接GNN中各隐藏层的中间结果来强化最终的表示,还有一些模型使用了如门控机制[34]的自适应策略来结合不同特征,获得最终的表示。
(6)损失函数。当前绝大多数模型均在训练时使用基于边缘的损失函数,使表示学习模型生成的正例样本对距离尽可能近,且负例样本对距离尽可能远。有的模型在此基础上加上了TransE损失函数,有的则利用归一化和LogSumExp操作[35]进行改进。
2 模型详述
为了更详细地解析当前表示学习模型的结构,本文将对表1 中十种模型的各个部分进行阐述。其中图神经网络中的各个步骤可概括为如下公式:
2.1 基于门控多跳邻接聚合的对齐模型AliNet
AliNet利用了多跳邻居实体来进行实体表示[24],其方法如下。
在聚合模块,使用了多跳的聚合策略。对于两跳的聚合,公式为:
其中N2表示两跳邻居。之后将多跳的聚合结果合成实体表示,一跳和两跳信息聚合如下:
对于注意力部分,该模型使用中心实体与邻居实体表示的内积来计算不同邻居的注意力权重:
在消息传递模块,该模型中邻居实体特征的提取是通过一个简单的线性变换实现的,即Messaging(i,j)=,其中Wq表示第q跳邻居的变换矩阵。
后处理部分,最终的实体表示由GNN 中所有层的输出拼接而成:
其中⊕表示拼接操作,norm(⋅)为L2归一化函数。其损失函数定义为:
其中A-是随机采样的负样本的集合,||⋅||表示L2范数,[⋅]+=max(0,⋅)。
2.2 面向跨语言知识图谱的实体对齐方法MRAEA
该工作提出利用关系信息促进实体表示学习过程的模型MRAEA(meta relation aware entity alignment)[25]。对于预处理模块,首先为每个关系生成一个反向关系,得到扩充的关系集合R,然后通过平均和拼接邻居实体和邻居关系的嵌入得到初始的实体特征:
其中实体和关系的嵌入均为随机初始化得到。
其中Mi,j表示由ei指向ej的关系,σ为LeakyReLU激活函数。值得注意的是,该方法同样也可以用于多头注意力机制。
对于消息传递,这一过程中的邻居实体特征即为预处理阶段对应的特征。后处理部分,最终实体表示由不同层的输出拼接而成:
损失函数定义为:
2.3 基于关系镜像变换的实体对齐RREA
该工作提出了使用关系镜像变换聚合特征来学习实体表示的模型RREA(relational reflection entity alignment)[26]。
在聚合模块,实体表示计算公式如下:
对于消息传递,这一过程中的邻居实体特征即为预处理阶段对应的特征,即Msg(i,j,k)=。
后处理阶段,与前述方法类似,网络中不同层的输出被拼接在一起形成表示,然后将实体表示与其邻居关系的嵌入拼接在一起得到最终的实体表示:
损失函数定义为:
2.4 基于可靠路径推理和关系感知异构图转换的实体对齐RPR-RHGT
RPR-RHGT(reliable path reasoning-relation aware heterogeneous graph transformer)引入了基于元路径的相似度计算框架,将预对齐的种子实体的邻居当作可靠的路径。关于可靠路径的生成参考文献[27]第3.3节。
对于预处理模块,该模型首先通过聚合邻居实体的表示来生成关系嵌入:
其中Hr和Tr分别为关系r连接的所有头实体和尾实体集合,bh和bt分别是头尾实体的权重系数,||表示拼接操作,初始的实体表示e0由实体名称经过一个预训练的文本嵌入得到。
在聚合模块,实体h的表示由邻居实体传递的消息经过注意力系数加权后得到:
其中⊕表示覆盖操作。
注意力部分,多头注意力计算方式如下:
消息传递部分,多头消息传递计算方式如下:
其中V_Lineari是尾实体的线性投影,与实体对应关系的表示拼接后得到第i头的消息。
后处理阶段,该模型通过残差连接[37]将结构特征与名称特征结合在一起。基于关系结构Trel和路径结构Tpath,可以分别生成基于关系的实体表示Erel和基于路径的实体表示Epath。
最终的总损失函数为基于边缘的排序损失函数:
其中L 为种子实体对,L′为负样本实体对,λ1是边缘超参数,||⋅||1为L1 范数,Lpath的定义与Lrel类似。θ是控制两种损失权重的超参数。
2.5 面向实体对齐的邻居匹配网络NMN
NMN(neighborhood matching network)同时利用实体的拓扑结构和邻居的差异信息来获得更好的实体表示[28]。
在预处理阶段,该工作使用了谷歌翻译将实体名称统一翻译为英语[38],然后使用预训练好的向量[39]作为输入。接着用一个简单的带有highway 网络[34]的图卷积神经网络(graph convolutional network,GCN)对实体表示进行预训练,详细设置可参见文献[28]第3.2 节,得到的实体i的表示记为hi。利用预训练得到的实体表示,NMN 提出一种对实体的邻居进行采样的方法,形式化地,该方法给出了实体i的第j个邻居被采样的概率分布,之后还为每个实体挑选了若干候选对齐实体,E2为目标知识图谱的实体集合,细节描述参见文献[28]第3.3节和第3.4节。
聚合模块,NMN 对跨图谱的邻居信息进行了传递和聚合。给定实体对(ei,cik),p和q分别是ei和cik的邻居,计算公式为:
消息传递部分,NMN 通过邻居之间的差异传递特征,即Msg(p,q)=hp-hq。因此mp实际衡量了中心实体的邻居p与对应候选实体的邻居的差异程度。
注意力部分,NMN采用内积来计算注意力权重,公式为:
后处理阶段,首先将聚合得到的向量与实体表示拼接得到邻居的增强表示,β为超参数。然后将邻居的增强表示累加[40]:
其中αip即为实体i的邻居p被采样的概率,σ()为sigmoid函数,Wg和WN均为可学习参数。最终实体表示为
损失函数为基于边缘的损失,与式(12)类似,不再赘述。
2.6 面向全局实体对齐的关系感知图注意力网络RAGA
RAGA(relation-aware graph attention network)利用自注意力机制将实体信息传递给关系,之后再把关系信息传递回实体,以此增强实体表示的质量[29]。
在预处理阶段,使用预训练好的向量[39]作为输入,并通过一个两层的带有highway 网络的GCN 编码结构信息。详细实现可参见文献[29]第4.2节。
对于聚合模块,在RAGA 模型中有三个主要的GNN网络。记由预处理部分得到的实体ei的初始表示为hi。第一个GNN 通过聚合所有与其相连的头实体和尾实体来得到关系的表示。对于关系rk,其所有头实体的聚合计算过程与式(10)类似,其聚合对象为关系rk的所有头实体,以及与这些头实体对应的所有尾实体。对于尾实体的聚合通过一个类似的过程得到。关系的表示则为
之后,第二个GNN 通过把关系信息聚合回实体获得关系感知的实体表示。对于实体ei,所有其向外的关系嵌入的聚合过程如下:
最后,第三个GNN 将关系感知的实体表示作为输入,再对一跳邻居实体进行聚合得到输出
注意力部分,对应三个GNN网络,RAGA模型中有三个注意力权重的计算。在第一个GNN 中,头尾实体分别进行线性变换后拼接得到注意力中的相似度,其中a1是可学习的注意力向量,σ为LeakyReLU 函数。在第二个GNN 中,实体的表示与其邻居关系被直接拼接在一起,没有进行线性变换。第三个GNN 中注意力的计算方式,即Att3(i,j),与上述类似,只是将邻居关系替换为邻居实体,不再赘述。
消息传递部分,该模型中只有第一个GNN 使用了线性变换作为消息传递的方式,即Msg1(i)=Whi,其中W在聚合头实体时为Wh,聚合尾实体时为Wt。
后处理阶段,最终增强的实体表示是第二个和第三个GNN输出的拼接
损失函数定义类似公式(12)。
2.7 基于结构、属性和值的实体对齐AttrGNN
该工作提出一种属性值编码器和将知识图谱划分成子图来对不同类型的属性三元组进行有效的建模[30]。
在预处理阶段,根据属性类型的不同,知识图谱被划分为四个子图:第一个子图包含所有“名称”属性的三元组,第二个和第三个子图分别包含属性值为文本和数值类型的三元组,第四个子图则包含关系三元组。在跨语言数据集上,知识图谱中所有文本都通过谷歌翻译转换为英语。文中使用了预训练的BERT(bidirectional encoder representations from transformers)模型[41]生成每个属性三元组中属性值的向量表示。第一个子图中实体的初始表示为其名称的嵌入向量,而其他三个子图中的实体和属性均被随机初始化为相同固定长度的向量。
每个子图的实体表示均由两层有残差连接[37]的图神经网络生成。对于聚合模块,AttrGNN在图神经网络的第二层使用简单的平均值操作聚合实体与其邻居的特征[42]:
其中W2为可学习参数,mean(⋅)为取均值操作,σ为ReLU激活函数。
而在第一层中,实体的表示由实体的属性与属性值聚合生成:
在消息传递部分,AttrGNN将实体的所有属性和属性值进行拼接,并通过线性变换提取特征:
其中W1为可学习权重参数,aj和vj分别是该实体的第j个属性和对应的属性值的向量。
注意力部分,计算公式与式(4)类似,其中相似度部分由实体的初始表示与属性向量拼接计算得到,即,其中u为可学习的注意力向量,为预处理阶段得到的实体的初始表示。
对于损失函数,AttrGNN为每个子图分别计算损失,公式与式(9)类似,其中使用的距离函数为余弦距离dis(⋅,⋅)=1-cos(⋅,⋅)。
2.8 无负采样的实体对齐方法PSR
PSR(high performance,scalability and robustness)利用镜像变换对知识图谱进行表示学习,并提出一种无需负采样的损失函数和半监督的训练方法[31]。
在聚合模块,受RREA 启发,PSR 将关系镜像变换运用于消息传递和注意力计算中。具体地,定义变换函数如下:
受BYOL(bootstrap your own latent)[44]和SimSiam[45]的启发,PSR 没有进行负采样,而是采用冻结部分反向传播计算的方式进行训练,其损失函数定义如下:
2.9 基于归一化硬样本挖掘的双注意力匹配网络Dual-AMN
Dual-AMN(dual attention matching network)提出利用图谱内和跨图谱的信息来学习实体表示[32]。该工作通过构造一组虚拟节点,即代理向量,在图谱之间进行消息传递和聚合。
注意力部分,对于图谱内信息的学习,注意力权重通过关系rk的表示hrk乘以可学习参数计算而来,该表示由He_initializer[46]随机初始化。对于跨图谱信息的学习,通过计算实体与代理向量之间的相似性来计算注意力权重:
消息传递部分,对于第一个GNN,消息传递的过程与RREA相同,即用一个关系镜像变换矩阵来传递邻居特征。对于第二个GNN,邻居实体的特征被表示为实体与代理向量之间的差:
受批归一化能够减小数据协方差偏移的启发[47],该模型提出使用归一化操作,将样本损失的均值和方差进行修正并减小对超参数数值大小的依赖,得到新的损失最后,总损失定义如下:
其中P为正样本的集合,E1和E2分别是两个图谱的实体集。
2.10 语义驱动嵌入学习的高效实体对齐SDEA
SDEA(semantic driven entity embedding method for entity alignment)使用双向门控循环单元(bidirectional gated recurrent unit,BiGRU)来捕获邻居间的相关性和生成实体表示[33]。
在预处理阶段,该方法用属性嵌入模块来捕获实体的关联。具体地,给定实体ei,首先将其属性的名称和描述拼接起来,记为S(ei)。然后将S(ei)送入BERT[41]模型生成属性嵌入Ha(ei)。
在聚合模块,该模型在聚合邻居信息中使用了注意力机制:
由于SDEA将邻居当成一个序列处理,t实际表示ei的第t个邻居实体,而Messaging()是一个BiGRU[48]。
该模型通过简单的内积来计算注意力:
而在消息传递部分,与其他模型不同,SDEA 捕获了邻居之间的相关性,而实体ei的所有邻居被当成一个序列作为BiGRU 的输入。给定实体ei,记xt为第t个输入嵌入(即ei的第t个邻居的属性嵌入,由预处理部分得到),而ht表示第t个隐藏单元的输出。将这些嵌入输入BiGRU,得到两个方向的输出,而消息传递部分的输出,是两个方向之和:
后处理阶段,在获得了属性嵌入Ha(ei)和关系嵌入Hr(ei)后,两者被拼接起来并送入一个MLP层中,得到Hm(ei)=MLP([Ha(ei)||Hr(ei)])。最终,Ha(ei)、Hr(ei)和Hm(ei)被拼接在一起得到Hent(ei)=[Hr(ei)||Ha(ei)‖Hm(ei)],而该表示被用于对齐阶段。
该模型使用如下基于边缘的排序函数作为损失函数来训练属性嵌入模块:
其中D是训练集,Ha和分别是源图谱和目标图谱的属性嵌入,β>0 是用于分离正负样本对的边缘超参数。关系嵌入模块的训练使用了类似式(38)的损失函数,Ha(ei)被替换为[Hr(ei)||Hm(ei)]。
2.11 小结
本文详细介绍了十种近期实体对齐的表示学习方法的结构,可以看出不同方法的差异主要表现在利用信息的种类和方式上。
利用信息的种类方面,大多数方法都是利用两种信息进行实体表示的学习。AliNet、MRAEA、AttrGNN分别是较早期利用多跳邻居信息、关系信息和属性信息的代表;NMN 则发掘了跨图谱的实体差异信息;而Dual-AMN 和RPR-RHGT 则是利用了三种信息进行学习,其中RPR-RHGT 提出了利用路径信息,其本质上是增强的关系和结构信息。
利用信息的方式方面,较早期的方法AliNet、AttrGNN 均只使用一个GNN 进行实体表示的学习。MRAEA 和NMN 则在预处理阶段使用了额外的GNN 辅助学习。RREA 虽然其他部分没有太大亮点,但在消息传递过程中对邻居信息提取方式进行了简洁而有效的改进,也影响了后续的一些工作。PSR则是对损失函数进行了创新性的改进,简化了模型训练。RAGA 使用了三个GNN,对结构和关系信息进行了更充分的利用。SDEA 则另辟蹊径,使用BiGRU取代GNN进行消息传递,提升对邻居信息的利用率。
3 实验
本章首先进行模型之间的总体比较实验来展示当前表示学习方法的效果,之后对表示学习中的六部分分别进行实验,比较采用不同方法和结构的效果。
3.1 实验设置
实验中使用最为常用的DBP15K 数据集[38]来评估模型。该模型分为中英数据集(ZH-EN)、日英数据集(JA-EN)和法英数据集(FR-EN),并按照较为常见的设置,将30%的种子实体对用作训练集[8]。
实验在Intel Core i7-12700F CPU 和NVIDIA GeForce RTX 3090 GPU 上进行,内存大小为32 GB,显存为24 GB。在模型的总体比较实验中,在相同的设置下使用十种模型的公开源代码复现了结果。特别地,为了比较的公平性,实验中修改和统一了这些模型的对齐部分,强制这些模型使用L1距离和贪婪算法进行对齐推理。由于不同的模型有各种不同的超参数,实验中只对一些共同的参数进行了统一,例如边缘损失函数中的边缘λ=3,负采样数量k=5。对于其他参数,实验中保持原论文的默认设置。在进一步的消融和替换实验中,选择了RAGA 模型作为基底模型。
根据现有研究,使用Hits@k(k=1,10)和平均倒数排序(mean reciprocal rank,MRR)作为评估指标。Hits@k和MRR 越高,效果越好。在实验中,将三次独立运行结果的平均值作为记录的结果。
3.2 总体比较结果与分析
首先比较了十种现有模型的效果,如表2 所示,其中最好的结果用粗体标出,次优的结果用下划线标出。从结果可以得出以下结论:
(1)没有模型在三个数据集上都达到最好的效果。这表明当前方法在不同情况下均有各自的优势和缺陷。
(2)SDEA在中英数据集和法英数据集上取得了最好的效果,而RPR-RHGT 在日英数据集上效果最好。考虑到这两种模型均使用了预训练模型来生成输出嵌入,并提出了独特的方法来提取邻居特征,能够得出使用预训练模型有益于表示学习,并且有效的消息传递对总体的结果很重要的初步结论。
(3)在法英数据集上NMN取得了第二的Hits@1指标,RAGA则在Hits@10和MRR指标上达到了第二的效果。RAGA 在日英数据集上是第二优,而Dual-AMN 在中英数据集上是第二优。注意到RAGA 和NMN 也都用了预训练模型,这进一步验证了使用预训练模型进行初始化的有效性。Dual-AMN 使用代理向量帮助捕获跨图谱信息,以此提高了表示学习的能力。
(4)AliNet在三个数据集上的效果都最差。因为AliNet是唯一聚合了两跳邻居实体的模型,结合一些已有研究的结论[49-50],这可能表示聚合两跳邻居信息难以带来性能的提升,而这一点在后续对聚合部分的实验中也有印证。
3.3 进一步的实验
为了比较表示学习各部分的不同方法,接下来以RAGA模型为基础进行了进一步的实验。
3.3.1 预处理部分
RAGA以预训练向量为输入,并通过一个两层带highway结构的GCN网络生成初始表示。为了检验预训练向量与结构嵌入的效果,将这两部分分别移除,并进行比较。表3展示了结果,其中“w/o Pretrained”表示移除了预训练向量,“w/o GNN”表示移除了GNN,“w/o Both”表示移除了整个预处理部分。从结果可以看到,移除结构特征和预训练向量后模型的表现明显下降,而移除了整个预处理部分的模型达到了最差的效果。由此可以得出结论,在初始化嵌入时提取有用的特征是十分重要的。更进一步地,可以看到预训练模型中提供的语义特征要比结构向量更有用,这验证了预训练向量中蕴含的先验知识的有效性。使用结构向量来初始化的效果相对不太明显,主要是因为表示学习中接下来的步骤同样也可以提取结构特征来生成有用的表示。

表3 使用RAGA对预处理部分的分析Table 3 Analysis of pre-processing module using RAGA
3.3.2 消息传递部分
在消息传递部分,线性变换是使用最为广泛的方法。RAGA 仅在第一个GNN 中使用了线性变换,因此该部分设计了两种变体,一种是将线性变换完全去除,另一种则是给剩下的GNN 加上额外参数。表4 展示了实验结果,后缀“+Linear Transform”表示在消息传递部分使用了更多线性变换的RAGA,而“-Linear Transform”表示完全不使用线性变换。此外,还比较了这些变体的收敛速度并绘制了图2。从表中可以明显看到线性变换能够提升RAGA 的性能,特别是在日英和法英数据集上,Hits@1分别提升了1.1个百分点和1.2个百分点。

表4 使用RAGA对消息传递部分的分析Table 4 Analysis of messaging module using RAGA
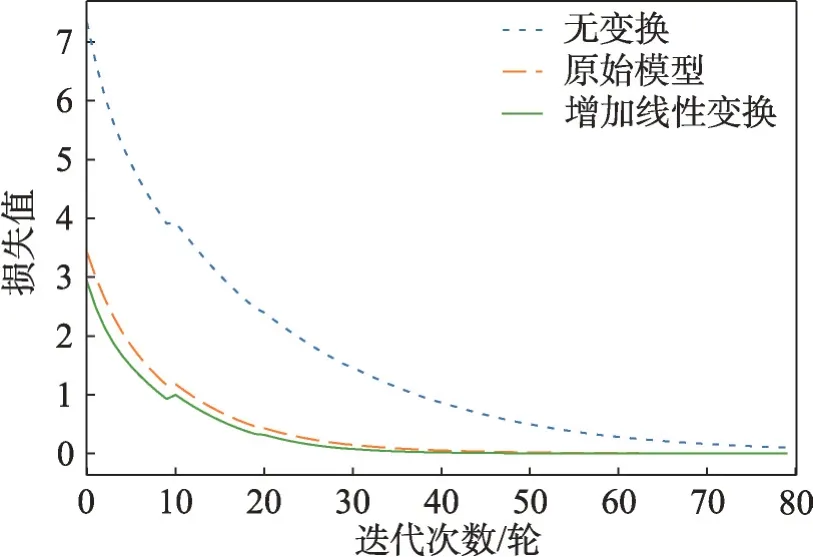
图2 不同变体收敛速度比较Fig.2 Comparison of convergences of different variants
此外,没有使用变换的RAGA 性能下降很明显。这证明了消息传递的改进能够提升表示学习的能力。图2 进一步表明线性变换还能加快模型收敛速度,可能是因为引入了额外的参数。
3.3.3 注意力部分
对于注意力模块,当前有两种主要的实现方式,即内积和拼接。为了比较这两种方式,实验中将RAGA 中的拼接计算改成了内积计算,变体后缀为“-Inner product”,将vT[ei||ej]改成(M1ei)T(M2ej),其中M1、M2是可学习矩阵。实验还设计了移除注意力机制的变体,后缀名为“w/o Attention”,用取均值操作代替注意力系数的计算。如表5前三行所示,两种变体模型与原始模型表现几乎相同。考虑到预处理部分生成的初始表示的影响,实验移除了预处理部分的预训练向量并进行了相同的比较。
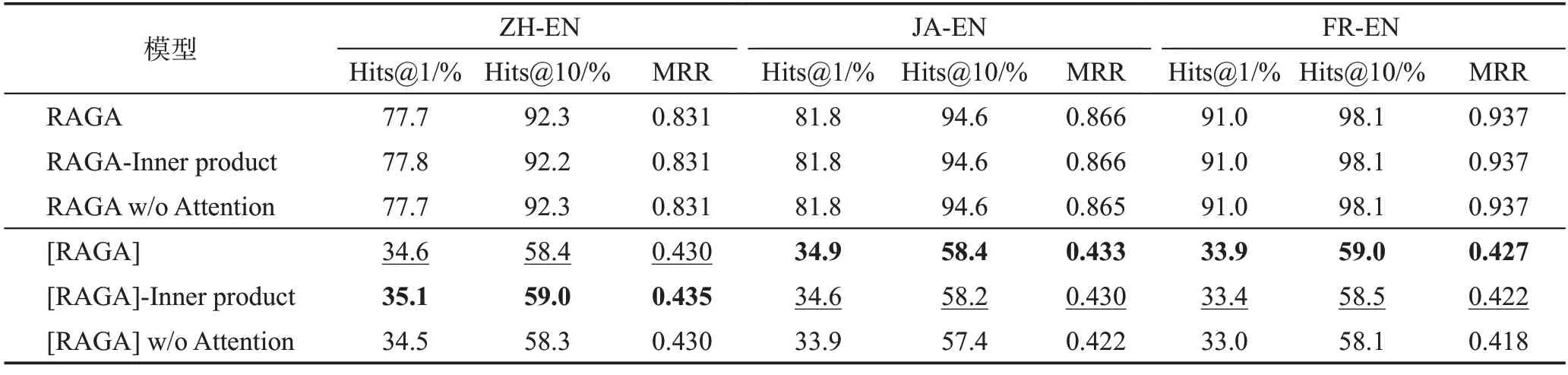
表5 使用RAGA对注意力部分的分析Table 5 Analysis of attention module using RAGA
如表5后三行所示,移除了注意力机制后模型表现有所下降,因此得出初步结论,注意力机制可能在缺乏先验知识的情况下能够发挥更好的作用。至于注意力计算的两种方式,内积计算比拼接计算在中英数据集上表现更好,但在日英和法英数据集上表现更差,表明这两种方式在不同数据集上作用不同。
3.3.4 聚合部分
对于聚合部分,因为RAGA 同时结合了一跳邻居实体和关系信息来更新实体表示,实验测试了两种变体,其中一种增加了两跳邻居实体信息(“-2hop”),一种移除了关系表示(“w/o rel.”)。结果如表6 所示。可以看到移除关系表示学习后的模型表现明显下降,这表明集成关系表示能够确实增强模型的学习能力。此外,在加入两跳邻居实体后,模型的表现稍有下降,说明并不是所有实体都是有用的,两跳邻居信息会引入噪声影响模型学习效果。
3.3.5 后处理部分
RAGA 通过将关系感知的实体表示和一跳邻居聚合来得到最终实体表示。实验测试了两种变体,“-highway”是将拼接操作替换成highway 网络,“w/o post-processing”是将关系感知的实体表示去除,即不进行后处理。
从表7 的实验结果中可以看到移除了后处理部分的模型表现下降,表明后处理操作能够增强最终表示并提升对齐效果。在把拼接操作替换成highway网络后,模型在日英数据集上表现下降,而在法英数据集上表现上升,说明两种后处理方式并无明显的绝对优劣之分。

表7 使用RAGA对后处理部分的分析Table 7 Analysis of post-processing module using RAGA
3.3.6 损失函数部分
RAGA 在训练中使用了基于边缘的损失函数。实验考虑了另外两种较典型的方法,即基于TransE的损失和边缘损失+TransE 损失。具体地,基于TransE 的损失公式为,其中(hk,rk,tk)是随机采样的三元组。
从表8所示的结果可以看出,模型在使用或添加了TransE 损失后表现下降,这主要是因为TransE 假设并不通用。例如,在本次实验使用的RAGA中,关系的表示实际上是由头实体和尾实体相加得到的,这与TransE的假设存在冲突。

表8 使用RAGA对损失函数部分的分析Table 8 Analysis of loss function module using RAGA
3.4 实验总结
本章进行了十个表示学习模型的总体比较实验,之后为了比较每个模块的不同方法,选取RAGA作为基底模型,分别对六个模块进行了消融和替换实验。实验结果表明:
(1)预训练模型生成的初始向量在提升模型性能上能够发挥重要作用。在模型的整体比较实验中,表现最好的两个模型均使用了预训练模型来生成实体的初始表示。在预处理部分的消融实验中,移除了初始预训练向量的模型性能显著下降。这些都表明预训练模型中包含的先验知识对模型的学习有非常大的帮助。
(2)消息传递方法的改进能够增强模型表示学习的能力。在总体比较实验中,两个表现最好的模型都使用了独特的消息传递方式;在消息传递部分的实验中,使用更多线性变换的模型比更少的模型性能有所提升。这表示未来的研究可以聚焦于改进消息传递的方式。
(3)当前注意力部分和后处理部分的方法较少,但它们是必要的。后处理部分能够增强实体的最终表示,而注意力机制能够在缺乏先验知识的情况下帮助优化聚合过程。另外,这两部分都有两种不同的方法,但是它们都有自己的优势,其效果依赖于具体情况和数据。
(4)在聚合部分和损失函数部分,有些方法并不通用。在聚合部分的实验中增加了两跳邻居信息的变体和在后处理部分实验中增加了TransE损失的变体都出现了性能下降。这证明了这两部分并不是越复杂的结构越好,甚至可能会造成更差的结果。
4 大模型方向探究
近年来预训练语言大模型(pretrained language models,PLM)因其强大的通用能力,被广泛用于各种下游任务中。而在一些文本生成类任务中,预训练语言模型表现出了具有真实世界的知识的特征。于是将预训练语言模型当作一种参数化的知识库,并通过各种方式将其中的知识提取出来成为近期新兴的研究方向[51]。
如何将预训练语言模型中提取的知识与现有知识图谱进行融合,现有表示学习在这些知识上的效果如何,本文对这些问题进行了初步实验探究。本章设计了一个简单的实验,首先用LAMA 数据集[52]中的三元组构建了一个简单的知识图谱作为现有知识图谱,然后选择其中的一些头实体和关系,利用OptiPrompt[53]构造提示词,其中包含了头实体和关系的内容,以及一个需要由大模型填补的空白,将提示词输入预训练的BERT 模型,使BERT 输出后续内容,即为尾实体的名称。例如,三元组

表9 预测练语言大模型输出知识对齐结果Table 9 Alignment of knowledge from pretrained language models
根据实验中大模型输出的内容以及对齐的结果,有以下发现:
(1)词汇表决定了大模型的知识上限和粒度。语言模型不能输出词汇表中不存在的内容,因此词汇表中包含的概念、实体等数量决定了大模型知识的上限,当其遇到的问题的答案在词汇表中不存在时,大模型不能输出正确答案。此外,词汇表还决定了大模型知识的粒度。本实验使用的大模型为预训练的BERT,从其输出可以发现BERT 掌握了相当的真实世界中的常识知识,例如国家与国民的关系,但对于一些具体领域的知识,则显得较为无力。
(2)现有表示学习模型不能很好地学到语言模型输出知识的表示。最主要的原因在于语言模型输出的知识较为碎片化,且其中存在错误的事实。在人工构建的知识图谱中,大多数实体都有许多不同的邻居,也具有许多不同的关系,现有表示学习模型正是建立在对这种邻居和关系的学习上。而本实验中大模型一次仅能输出一个头实体与关系对应的尾实体,且并不能保证该尾实体的正确性。
(3)语言大模型输出结果的正确性较难评估。本实验使用的LAMA 数据集中有许多测试数据,可以对语言大模型输出的结果进行评估,但在真实应用情景下,例如使用语言大模型对现有知识图谱进行补充,则难以判断输出的正确性。此外,对于一些答案不唯一的问题,即一个头实体和关系可能存在多个尾实体,如何辨别语言大模型输出的结果哪些是正确的哪些是错误的,也是有待进一步研究解决的问题。
基于以上发现和问题,本文认为对于语言大模型和知识图谱方向的未来工作,可以从以下方面开展:
(1)从更大的语言模型中提取知识。BERT系列的语言模型存储的知识有限,且大多为粗粒度的常识知识,将这种知识与现有知识图谱融合的意义不大。若要用语言大模型对现有知识图谱进行补充,应当选择较大参数量的大模型。
(2)利用文本信息辅助知识融合。利用结构和邻居关系来学习的实体对齐方法难以学习语言大模型输出的内容,因此对齐效果较差。但语言模型输出的形式均为文本,因此可以考虑利用文本信息,使用基于规则或者文本嵌入的方法辅助实体对齐。
(3)使用知识图谱纠正语言大模型的错误。相较于语言大模型,知识图谱具有可靠、可控、可解释的特点,可以用高质量的知识图谱辅助语言大模型推理,或者利用知识图谱对语言大模型进行微调,从而产生更准确可靠的结果。
5 结束语
实体对齐是知识融合的重要步骤,主要分为表示学习和对齐推理两个阶段。本文提出了一种表示学习的框架,将表示学习分为六部分,并按该框架总结和剖析了十种现有对齐工作中表示学习的组成。之后,进行了不同表示学习方法的对比实验和表示学习方法中每部分不同策略的对比实验,总结并指出了表示学习的各个模块不同策略的优劣差异。最后,探讨了语言大模型与知识融合相结合的新兴任务,通过初步的实验提出了目前存在的问题和下一步研究的方向。
猜你喜欢
小雪花·成长指南(2022年1期)2022-04-09
少先队活动(2020年12期)2021-01-14
中国外汇(2019年18期)2019-11-25
哲学评论(2017年1期)2017-07-31
传媒评论(2017年3期)2017-06-13
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
第二课堂(课外活动版)(2016年2期)2016-10-21
领导科学论坛(2016年9期)2016-06-05
