
数字信用交易反欺诈研究进展
2023-10-29 04:20刘华玲曹世杰许珺怡陈尚辉
计算机与生活 2023年10期
刘华玲,曹世杰,许珺怡,陈尚辉
上海对外经贸大学 统计与信息学院,上海 201620
互联网信息时代,数字经济成为引领全球经济社会变革、推动我国经济高质量发展的重要引擎,以大数据、人工智能为代表的新一代信息技术在经济社会的不断扩张与渗透,催生出数字金融新业态[1],其中数字信用交易作为伴随消费模式升级与普惠金融的发展而成的新模式,迅速在全国捕获了大量用户,成为数字金融体系的重要组成部分,为我国数字经济的高质量发展铺平了道路。但另一方面,以恶意逾期、冒用他人信用账户为代表的数字信用交易欺诈行为同样变得更为隐蔽,2020 年全球范围内数字信用支付欺诈交易损失较2018年增加了35%[2],目前仍呈上升态势。我国的情况同样不容乐观,信用支付逾期半年未偿信贷总额在2019年略有下降后再次回升[3]。数字信用欺诈交易的存在不仅为用户、银行业在内的个体及金融机构带来大量财物上的损失,更会让消费者丧失对数字支付的信心,严重阻碍我国数字经济的发展。
欺诈交易造成的严重损失与用户对交易安全的硬性需求,使数字化交易安全问题受到社会各界的广泛关注。面对数字交易信息逐步呈现出的海量多源、高维异构等新特点,传统的专家系统与早期的机器学习分类算法难以适应现有数据环境,金融科技革命开始蓬勃发展,蚂蚁金服、Paypal 等互联网科技企业更是引领起反欺诈研究创新的变革新浪潮。
以海量数据为驱动力,融合统计学、数学、机器学习和人工智能算法的数据智能技术成为反欺诈研究中的重要工具。相关算法已在数字信用反欺诈研究领域得到广泛关注与应用,随之涌现出多篇基于不同视角聚焦数字信用交易反欺诈研究的综述性文章。Bansal 和Garg 两位学者[2]从风险来源出发进行综述,详细论述了当前国外数字信用欺诈交易的主要类型及犯罪手段,其文章能够使读者快速了解信用支付反欺诈研究的研究背景,但由于具体业务的开展方式在各国间不尽相同,文章介绍的欺诈交易方式与我国的情况可能有所差异。文献[4-7]从算法的识别性能出发进行综述。Popat 等学者在文献[4]中分析并对比了8 类机器学习分类算法在数字信用欺诈检测中的应用。文献[5]重点分析了当前研究领域受关注最多的6 类有监督模型与4 类无监督模型的性能优劣,但上述文章模型对比均停留在Baseline阶段,缺乏最新的研究进展。文献[6]将目光聚焦于机器学习在反欺诈研究中的应用,但涉及文献较少,涵盖观点不够全面。Ryman、Krause 等学者[7]在真实体量的交易数据集上对最新的欺诈交易识别模型进行实证检验,文章认为与当时的基准测试(2017 年)相比,仅有8 种方法可以应用到实际业务场景中,遗憾的是由于数据集的私密性,无法将其分享出来用作后续研究的对比。文献[8]整合并罗列了领域中常用的公开数据集与获取地址,方便读者进行查找与实验,弥补了文献[7]的不足。Al-Hashedi 等学者[9]聚焦于包含信用交易反欺诈研究在内的金融反欺诈领域,汇总了自2009 年至2019 年由ACM、IEEE、Emerald、Elsevier 出版社出版的相关文章,从模型描述、数据集汇总、算法的横向对比等多角度进行了文献综述,是目前已发表的文章中涉猎时间最广、角度最为全面的综述性文章之一。
综上所述,目前面向信用支付反欺诈研究的综述性文章大多数涵盖内容不够全面,文献[9]虽然涉及内容广泛,但是文章着眼于整体金融欺诈检测领域,就数字信用交易反欺诈研究而言,深度略显不足,目前仍旧缺少对数字信用交易反欺诈研究进行全面、深入梳理与总结的工作。作为最早的数字化非现金交易方式之一,数字信用支付拥有目前最成熟的数据积累和理论基础,其反欺诈算法的研究进展不仅关乎自身业务发展,对整体数字支付环境下的交易风险防范具有更为重要的启示意义。本文在上述文章的基础上进一步对国内外的研究成果进行综述,意图为读者呈现系统、全面的分析与总结。
1 数字信用反欺诈研究简要概述
1.1 数字信用欺诈交易定义及分类
数字信用欺诈交易是指以非法占有为目的,违反信用支付管理法规进行的诈骗行为[10]。根据欺诈者的身份可分为内部信用欺诈交易(internal credit fraud payment)和外部信用欺诈交易(external credit fraud payment)两种模式[11]。内部信用欺诈交易的欺诈者为用户本人,通过伪造身份信息、恶意逾期等行为违法获利;外部信用欺诈交易的欺诈者为非银行、用户本人在内的第三方恶意用户,通过获取信用卡/账户的详细信息及相应个人凭证伪装成持卡者进行违法套利活动。
从实施欺诈交易的方式入手,数字信用欺诈交易主要可分为信用卡丢失/被盗、快捷支付漏洞、使用伪造信用卡、钓鱼网站攻击、电子账户泄露、恶意逾期等类别,如图1所示。

图1 数字信用欺诈交易的主要方式Fig.1 Main methods of digital credit fraud transactions
(1)信用卡丢失/被盗(lost/stolen card):持卡者的信用卡开通免密支付的同时出现丢失或被盗的情况,被不法分子获取后用于非法套利或消费从而产生损失。
(2)快捷支付漏洞(card not present):不法分子获取到持卡者的银行卡卡号、户名、手机号码等信息,并使用伪造的电话卡获取第三方支付平台发送到用户手机的动态口令,从而完成支付。
(3)使用伪造的信用卡(fake credit card):以制作假信用卡或对真实信用卡的信息进行涂改、伪造为代表的违法行为。
(4)钓鱼网站攻击(Phishing):向用户发送虚假购物网站,从而获取用户在该网站上填写的信用账户相关信息,例如客户的账号、登录凭据、信用支付密码等,通过这些信息,不法分子即可完成欺诈交易。
(5)电子账户泄露(account takeover):与钓鱼网站攻击造成损失的原因相似,消费者信用账户的账号及支付密码出现泄露,被不法分子获取,从而造成损失。
(6)恶意逾期(maliciously overdue):持卡者使用信用支付消费后在还款日故意逾期,不偿还贷款的行为。
1.2 欺诈交易识别问题描述及研究难点
数字信用欺诈交易识别问题的定义如下:给定一段时间内的历史交易数据集D={d1,d2,…,dn}及每条交易数据di对应的类别标签li∈{l1,l2},其中di代表一条数字信用交易记录的具体信息,l1、l2分别代表正常交易与欺诈交易。数字信用交易反欺诈研究旨在通过数据挖掘算法提取数据集中欺诈行为模式,进而识别新发生交易中的潜在欺诈交易,输出结果为新发生的交易申请属于正常交易或欺诈交易的概率。因此欺诈交易识别任务本质是一个二分类问题。结合数字经济下具体的应用场景及业务特点,数字信用欺诈交易识别问题当下主要有四个研究难点。
(1)数字支付背景下交易规模激增,传统审核方式难以支撑。
根据央行发布的数据显示,2020 年银行共处理电子支付业务2 352.23 亿笔,其中网上支付业务879.31 亿笔,移动支付业务1 232.20 亿笔,分别同比增长12.46%和21.48%。单日新增数字信用支付记录存储量从2012 年的TB 级向如今的PB 级跃迁,在如此庞大的交易数量下,人工审核或基于规则的算法在检验精度与效率上难以取得令人满意的结果。
(2)公开数据集少,信息敏感度高。
回顾近年来的发展,数据挖掘技术愈加成熟,但是由于交易数据的私密性,银行禁止在未经同意下对客户的消费信息进行任何披露,数字信用反欺诈研究进展缓慢[12]。
(3)数据集样本分布严重失衡,模型分类结果有偏。
基于信用消费记录构成的数据集中,正常用户的交易数据样本数量远多于需要着重关注的欺诈交易样本数。现实业务中,正常用户与欺诈用户的比例甚至能达到1 000∶1以上[13]。数据集类别分布的严重失衡将导致模型对正常交易识别过度,对欺诈交易的样本行为特征识别不足,严重影响模型的检测效果[14-15]。在反欺诈研究中,欺诈交易的错分代价远远高于正常样本的错分代价,欺诈交易才是要重点关注的对象。
(4)部分交易特征高度相似,分类难度大幅提升。
数据集类别分布失衡并非信用支付欺诈识别任务中的主要难题,事实上,只要各类分布可以被该类样本数据完全表达,且不同类别样本之间不存在重叠,以图2中的二维空间为例,如图2(a)所示,即使数据集构成比例严重失衡,传统的分类方法依旧可以取得较好的识别效果。但在信用支付欺诈识别问题中,部分欺诈交易样本表现出来的特征与正常交易的特征具有高度的相似性,将样本映射在特征空间中如图2(b)所示。如何优化重叠区域的分类问题,是领域内研究者解决信用支付欺诈识别问题的主要矛盾,对重叠区域进行量化表达并融入模型也是目前数字信用反欺诈研究领域的最新方向。

图2 样本在特征空间中的映射表示Fig.2 Mapping representation of samples in feature space
1.3 数据描述及特征工程
1.3.1 数据描述
表1罗列了实际业务场景中,新的交易申请发起时会被发卡机构或三方支付机构记录的基本属性,以展示信用支付欺诈交易识别特征表的主要框架。尽管交易特征表的具体结构在不同的发卡机构之间可能略有不同,但表1中涉及的特征在各机构的数据库中应当均有收录且被应用于欺诈交易识别模型的构建中。
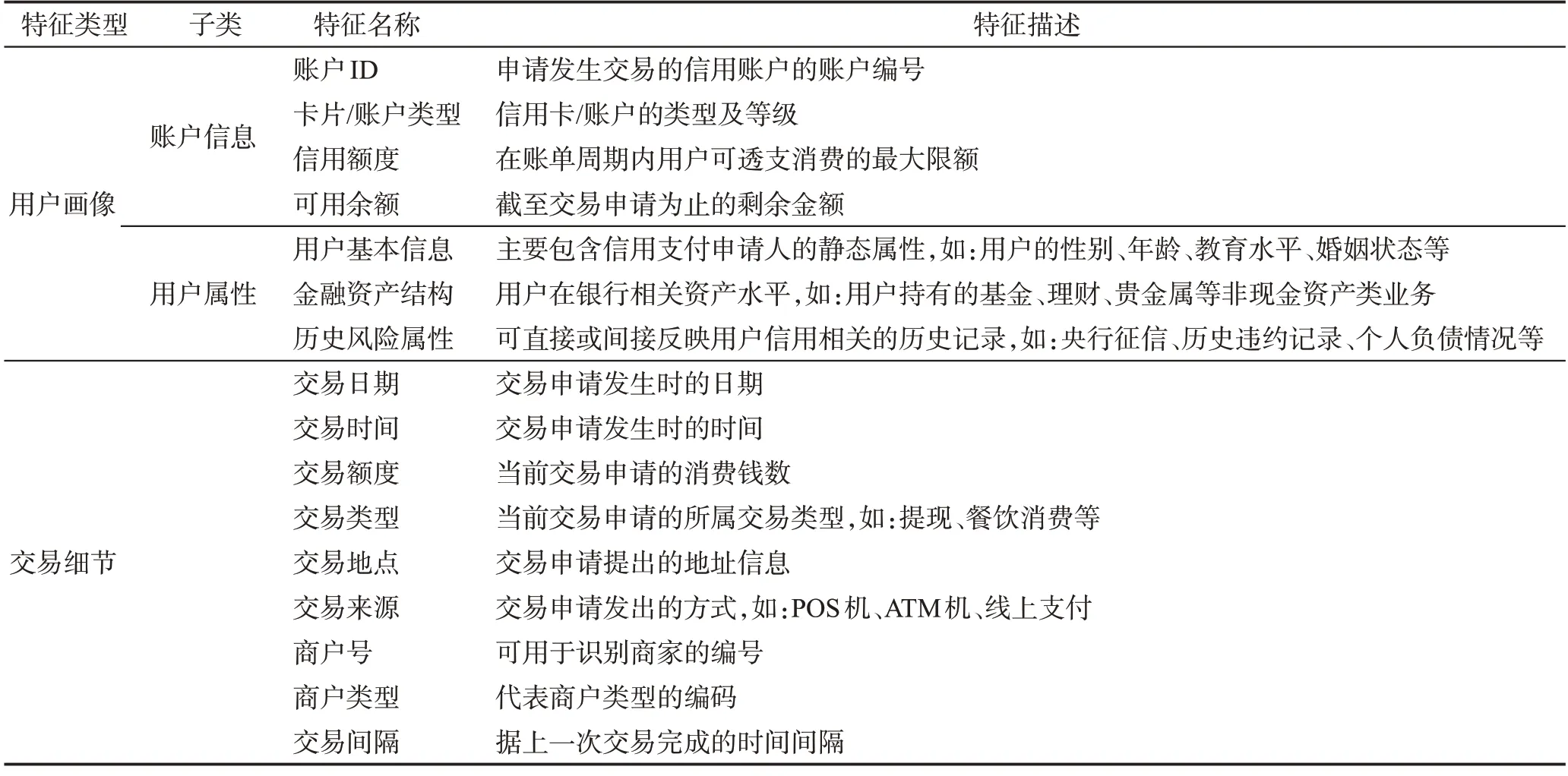
表1 信用支付欺诈交易识别特征Table 1 Features of credit payment fraud transactions
1.3.2 特征工程
在欺诈识别模型搭建中,基于原始数据对交易行为信息进行总结和表示,构建有效特征变量的特征工程是流程内极为关键的一步,特征的质量将直接影响模型的性能,具体来讲,特征越好,灵活性越强,构建的模型也将越简单、性能越出色。
对于信用支付欺诈交易识别问题,数据库由不同用户在相同时间跨度内的历史交易记录构成,但直接使用这些由表1 中初始特征组成的历史信息建模是困难的。如果将单笔交易记录作为建模对象,则忽略了不同用户之间的异质性与同一用户不同交易之间的连续性,造成关联账户历史交易信息的丢失;如果将信用账户作为建模对象,使用每个账户的历史交易记录进行独立建模,虽然解决了上述问题,但仅能用于重点客户分析,在数字经济海量用户的背景下无法大规模实施。因此,除去对现有特征进行筛选与提炼,利用特征工程对用户的历史交易模式进行归纳与总结,作为新的特征补充到交易记录中完善用户画像是保证欺诈识别模型有效性的重要基础。
在现有的研究中,大多数学者结合RFM 框架进行特征工程,其中R(recency)代表客户当前交易距上一次发生交易之间的时间间隔、F(fequency)代表客户的交易频率,M(monetary)代表客户的消费金额,配合不同跨度的时间窗口即可捕获用户长、短期交易行为特征。
Zhang 等学者在研究中认为RFM 框架虽然考虑了不同用户之间的差异,但是忽略了信用支付交易自身的内在异质性,即使是同一用户面对不同的交易类型也具有不同的行为模式,因此在RFM 框架的基础上提出了面向同质性行为分析(homogeneityoriented behavior analysis,HOBA)的特征工程框架[16],配合交易聚合策略从交易类型、聚合周期、交易行为、聚合统计指标四方面完成了更精细的关联账户历史行为特征提取,使用不同的分类器在中国最大的商业银行提供的数据集上进行检验,结果显示经过HOBA框架处理后的数据所构建的模型识别精度有显著的提高。
简单有效是RFM 框架的优势,但数据集在结构化存储方式下,不同用户间的交易样本被默认是相互独立的,用户之间诸如社会关系、交易位置在内的空间联系被完全忽略,无法将此类非结构关系信息提取到行为特征中。直到近年来,以Node2Vec[17]、SDNE(structural deep network embedding)[18]为代表的图嵌入算法的兴起,将交易信息从结构化数据转化为图结构数据,并基于图网络从全局视角挖掘账户之间的空间联系,生成新补充特征应用于风险决策模型成为可能。Vlasselaer 等学者基于RFM 特征框架进行改进,提出了APATE(anomaly prevention using advanced transaction exploration)[19]特征工程方法,一方面使用RFM 框架提取客户消费历史的内在特征,另一方面依据客户与商家的联系构建了消费者-商家信息网络,基于网络为客户建立时间依赖的信用评分,面对新传入的交易申请,网络特征的加入使APATE框架在相同的分类模型上呈现出更好的分类效果。
RFM 框架和基于RFM 框架进行改进的特征工程方法很好地完成了分析用户行为模式、完善用户画像的需求,但是略有不足的是上述方法需要研究者对业务具备深入理解,以手工构造的方式进行开展。随着数字经济的发展,不同机构业务场景下的收录特征与欺诈交易模式不尽相同,基于专家的手动特征构建方法难以满足与日俱增的欺诈识别需求。由此,王成等学者提出面向网络支付的自动化特征工程方法[20],通过定制化转换函数设计在特征集合上自动生成潜在补充特征,依托决策树模型对当前特征重要性进行排序并对数据集进行划分,若当前最佳划分属性为生成特征,则将其保留并更新对应转换函数的权重,随后在子节点中重复上述过程,直至达到结束条件。与随机构造、Cognito 等多种自动化特征工程框架进行对比,效率更快、精度更高。此类自动化特征工程方法也逐渐成为反欺诈研究前期特征挖掘阶段的有利工具。图结构特征构建也同样趋于自动化,文献[19]率先将图表征学习算法Graphsage[21]引入信用支付欺诈研究领域,无需繁琐的手动特征工程即可对消费者-商家交易网络进行特征化处理,从交易网络与结构的视角提取用户行为模式,相较于传统的图特征提取方法,提高了信用支付欺诈识别的效率和准确性,有力展示了图归纳表示学习在信用支付欺诈交易识别问题上自动提取特征的有效性。
1.4 信用支付欺诈交易识别模型主要建模策略
通过1.2 节的分析,信用支付欺诈交易识别本质上是一个面对极度不均衡数据集的二分类问题,现有研究中,对于不平衡数据集的建模思路主要分为两类:(1)从数据层面出发,主要思想在于通过重抽样或者生成伪数据的方法对数据集进行平衡,随后运用传统的分类方法进行研究。(2)从模型层面出发,从模型的理论切入,通过改进分类算法的损失函数或学习策略,提高对少数类样本特征的学习能力。其中代表性的算法为代价敏感分类算法,对少数类样本施加一个较高的错分代价因子以达到提高分类效果的目的[22-24]。在数字信用反欺诈研究业务中,严峻的类别不平衡性与特征空间内重叠区域样本的存在,使得从单一层面进行改进的识别算法难以取得令人满意的效果,因此相关研究者通常将两个改进方向进行融合,虽然模型的复杂度有所提升,但也结合了两者的优点,模型的性能更加稳定。
1.5 评价准则
为了准确评估欺诈识别模型的性能,评价指标的选取至关重要。面对正负类样本分布极度失衡的数据集,以分类准确率(Accuracy)为代表的经典评价指标会侧重评估多数类样本(正常交易)的检测结果。但反欺诈研究中,对少数类样本(欺诈交易)的识别性能才是重点关注的对象,误判欺诈交易所带来的损失要远高于正常交易的错分代价,因此整体的分类准确率并不能迎合真实应用中的业务需求。在目前研究中,通常在精确率(Precision)、召回率(Recall)、F1分数(F1-score)、G-mean、马修斯相关系数(Matthews correlation coefficient,MCC)以及AUROC值或AUPRC值中选取部分作为模型评价指标。
本文将数据集中的欺诈样本定义为正类,将正常样本定义为负类,可得到混淆矩阵如表2所示。
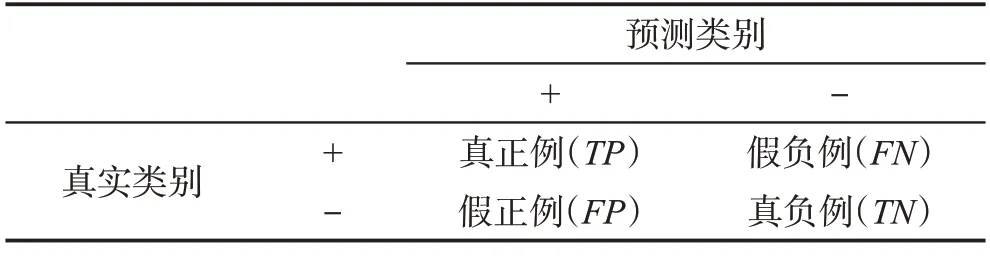
表2 二分类问题的混淆矩阵Table 2 Confusion matrix of binary classification problem
(1)精确率(Precision):又称为查准率,用来表示预测为正类的样本中被正确分类的比重,通常会受到数据集不平衡率的影响,不平衡率越高对其影响越大。
(2)召回率(Recall/Sensitive/TPR(true positive rate)):又称查全率、灵敏度、真阳性率,是模型对正类样本识别全面程度的一个度量。
(3)F1 分数(F1-score):在不平衡分类任务中,精确率和召回率通常是“此消彼长”的关系,F1 分数对精确率与召回率进行了综合,是两者的调和平均值,同时考虑了正类样本检测结果的准确性与全面性。在评价过程中,F1分数的值越高,认为分类器的性能越好。
(4)G-mean:G-mean 同时度量了正类样本和负类样本检测结果的全面性,优点为对数据集中类别分布不敏感,评价过程中,G-mean 值越高,分类器的性能越好。
(5)马修斯相关系数(MCC):马修斯相关系数同时考虑到正类样本与负类样本的识别性能,本质上是样本真实情况与基于分类器得到预测结果之间的相关系数,马修斯相关系数的取值范围为[-1,1],取值为1时,代表模型识别结果与真实情况完全相同,取值为-1时代表模型识别结果与真实情况完全不符。
(6)AUROC值与AUPRC值
ROC 曲线全称为“受试者工作曲线”(receiver operating curve),横坐标为假阳性率(FPR:假正例FP在全部真实负例样本中的占比),纵坐标为真阳性率(TPR)即召回率,对每一个分类阈值,分类器都会给出对应的FPR 与TPR 值(对应坐标系中的一个点),所有坐标点连接而成的平滑曲线即为ROC 曲线。AUC 值(一般特指AUROC)则是ROC 曲线下的面积,能够量化地反映基于ROC 曲线衡量出的模型性能,AUC值越大,模型的分类性能越好。
P-R 曲线全称“精确率-召回率曲线”(precisionrecall curve),横坐标为召回率,纵坐标为精确率,同F1-score 一样是对上述两个指标的综合度量,P-R曲线的绘制方法与ROC 曲线相似,AUPRC 值则是P-R曲线下的面积,AUPRC值越大,模型的分类性能越好。
AUROC 值与AUPRC 值计算方式相似,均通过计算曲线下面积度量模型性能,但在实际应用中存在差异。相比P-R曲线,ROC曲线的形状在正负样本的分布发生变动时能够基本保持不变,但P-R曲线会发生较强烈的变化。这个特点让AUROC 值能够降低不同测试集带来的干扰,更加客观地衡量模型的自身性能,但当研究需要测评模型在某特定数据集上的表现时,AUPRC值更加直观。
2 数字信用反欺诈研究中的数据均衡算法
数据均衡算法的目的在于通过对数据集进行调整,抵消样本分布占比不均衡带来的负面影响,使处理后的数据集能够满足传统分类算法的需求,而在数字信用反欺诈研究中,海量的正常交易样本已经使得正常用户的行为特征得到充分表达,如何通过过采样技术对欺诈交易样本进行补充是领域内的研究重点。本章将重点对欺诈交易识别领域运用到的数据均衡算法进行总结。
目前对数据集进行平衡的方法可分为从重抽样角度出发和从数据分布角度出发两个思路,如表3所示:重抽样角度下的均衡算法提出时间早,理论简单,应用广泛,但过于依赖于已有样本数据的特征表现,没有考虑到数据集的整体分布情况;基于数据分布角度的算法弥补了这一不足,其中生成对抗网络(generative adversarial network,GAN)是近年来深度学习技术在分类问题上的最新成果,采用内部对抗机制对网络进行训练,拟合数据的实际分布,在学术界和工业界均受到广泛关注,是该类方法中最具代表性的前沿算法,缺点是理论较为复杂,时间复杂度有所增加。表4 对各类数据均衡算法的优点与局限性进行了细致的总结与归纳。
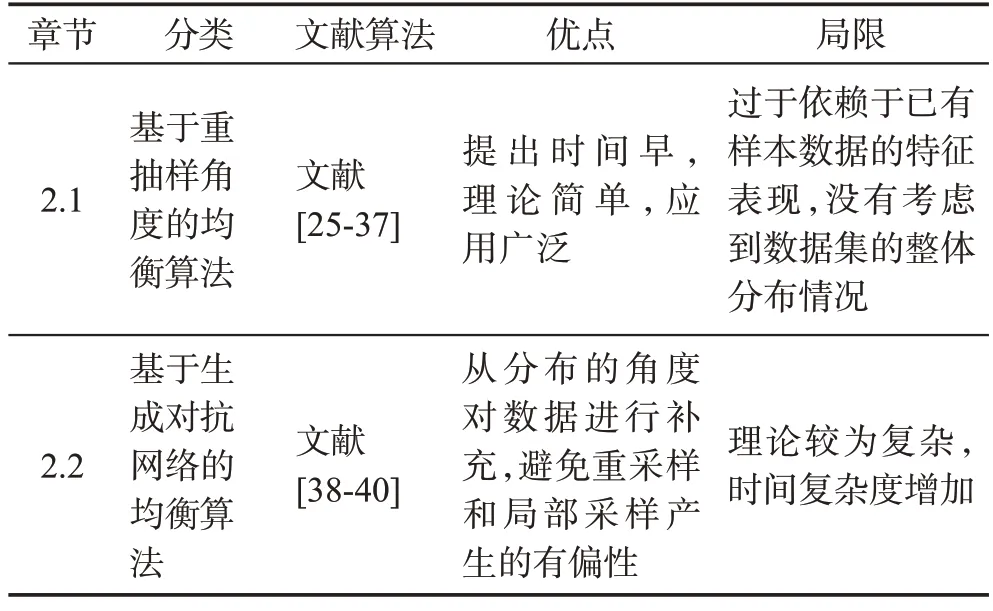
表3 数字信用反欺诈研究中的数据均衡算法Table 3 Data balance algorithms in anti-fraud research of digital credit

表4 各类数据均衡算法的优点与局限性Table 4 Advantages and limitations of various data balance algorithms
2.1 基于重抽样角度的数据均衡算法
基于重抽样技术对数据集进行补充的策略中,最早被提出的算法为随机过采样与随机欠采样技术。随机过采样技术通过对少数类样本进行简单随机的重复抽取,达到平衡数据集的目的,适用于数据集不平衡度较轻的场景,在样本构成差异过大的数据集中,随机过采样方法容易产生过拟合问题。随机欠采样技术旨在通过对多数类样本进行随机的删减,缩小样本量间的差距,但是随机欠采样技术很容易将一些重要的多数类样本删除。
为了解决随机重采样技术的上述缺陷,学者们将重点从样本点本身转向了样本点的局部邻域。Chawla等学者[25]提出了SMOTE(synthetic minority oversampling technique)算法,将少数类中的每个样本点均作为一个种子,寻找其相同类别的K-近邻(K-nearest neighbor,K-NN)样本,按照一定的比例在近邻样本与种子样本之间生成新样本,对少数类样本进行补充。He 等学者[26]进一步提出ADASYN(adaptive synthetic sampling approach for imbalanced learning)方法,分析了每个种子样本K-邻域中多数类样本的分布情况,结合数据不平衡率合成样本,自适应地将决策边界转移到难以学习的样本。上述算法一经提出便受到了学者们的广泛接纳,但是存在以下两方面问题:首先SMOTE 与ADASYN 算法将少数类别中的所有样本均作为种子点生成新样本,忽略了样本中异常点的问题,从而导致生成的样本中存在噪声节点;其次,没有考虑到种子节点与K-近邻节点间多数类样本的特征分布情况,盲目地生成均衡样本会加重数据集在特征空间中的重叠区域的复杂度,使该部分样本更加难以区分[27-28]。
针对上述不足,Batista等学者[29]提出了欠采样与过采样技术相结合的方法,从而减少均衡数据时需要补充的欺诈样本数量。Han等学者[30]对样本点局部邻域的分布情况进行更加深入的研究,提出Borderline-SMOTE 方法,将少数类样本分为安全样本、危险样本与噪音样本,仅使用边界上的样本作为种子生成新样本点,缓解了噪音节点的生成;随后的Safe Level SMOTE[31]、LN-SMOTE(local neighbourhood extension of SMOTE)[32]两种技术在Borderline-SMOTE算法基础上不仅关注种子样本局部子区域的分布,而且对其近邻样本的邻域进行分析,基于邻域分布确定样本合成权重,噪声样本点的问题进一步得以遏制,但仍没有关注均衡样本对重叠区域造成的影响。直到Napierala 与Stefanowski 两位学者[33]从数据集的结构特征出发,将少数类样本划分为安全样本、边界样本、稀有样本和异常值四种情况,通过分析各类初始样本生成的均衡样本对不平衡分类器的影响,为解决均衡样本会加重重叠区域复杂度的问题提供了思路。
在最新的研究中,王芳等学者[34]在Borderline-SMOTE 的基础上提出了邻域自适应SMOTE 算法(neighborhood adaptive SMOTE algorithm,AdaNSMOTE),通过跟踪少数类样本点与其近邻样本构成的超矩形区域内的精度变化,自动为每个少数类样本点确定要合成的少数类样本数量,使过采样后的数据集可以更逼近原始少数类样本的分布。梅大成等学者[35]面对SMOTE算法及其改进算法均比较依赖原始数据集分布的问题,提出了边界与密度自适应的SMOTE 算法(SMOTE algorithm for feature boundary and density adaptation,BDA-SMOTE),一方面对局部的少数类样本进行密度调整,通过非线性映射扩大少数类样本局部密度的差异,减少噪声样本的干扰,另一方面将根据特征边界的特性将数据分为边界与非边界样本,通过设定不同的安全区域扩展数据的原始分布,有效防止边界混淆与过拟合,但性能提升的背后是模型复杂度的大幅增加,可能会成为其应用于大规模数据时的严重阻碍。张忠良等学者[36]将SMOTE算法与Boosting集成学习算法结合起来构建了一种基于高斯过采样的集成学习算法(GSMOTEBoost),增加基分类器多样性的同时,提高分类系统的鲁棒性。
文献[35-36]从种子节点的邻域出发,有意识地关注均衡样本对近邻空间内数据分布的影响,生成的均衡样本更加稳健,但上述研究并不能反映数据集均衡前后全局特征空间内重叠区域的变动情况。如何将重叠度即重叠区域的样本量在数据集中的占比作为监督指标融入到欺诈识别模型中,做到均衡数据集的同时优化样本在特征空间中的分布成为学者们的最新研究方向。Omar等学者[37]基于K-近邻算法定义了用于表征数据集重叠度的新指标Aug-R,并将ADASYN算法与特征选择技术结合起来提出了ROA算法(reduce overlapping with ADASYN)。ADASYN 算法用于对数据集进行均衡,基于弹性网算法构造损失函数对数据集进行特征选择,模型中的超参数则以最小化Aug-R进行确定。实验结果显示,运用ROA算法均衡后的数据集训练出的逻辑回归模型与支持向量机的欺诈识别性能大幅提升,为基于重抽样角度的信用支付欺诈交易识别模型提供了新研究方向。
2.2 基于生成对抗网络的数据均衡算法
生成对抗网络(GAN)[38]是生成式模型最新的、也是目前最为成功的一项技术。模型的构建受到了博弈论中零和博弈思想的启发,由生成器(generator)与判别器(discriminator)两个子网络构成。生成器基于给定的随机噪声合成数据,目的是产生和真实样本相似的伪样本,来混淆判别器使其无法判别;判别器用来判别输入的样本是真实样本还是伪样本。在训练过程中,前者试图产生更接近真实数据的伪样本,后者试图更完美地分辨真实数据与来自生成器的合成数据,两个子网络在对抗中进化,进化后再投入到下一轮的对抗训练中,当生成器学习到真实数据的样本分布时,模型训练达到最终的平衡点,生成对抗网络的流程图如图3所示。
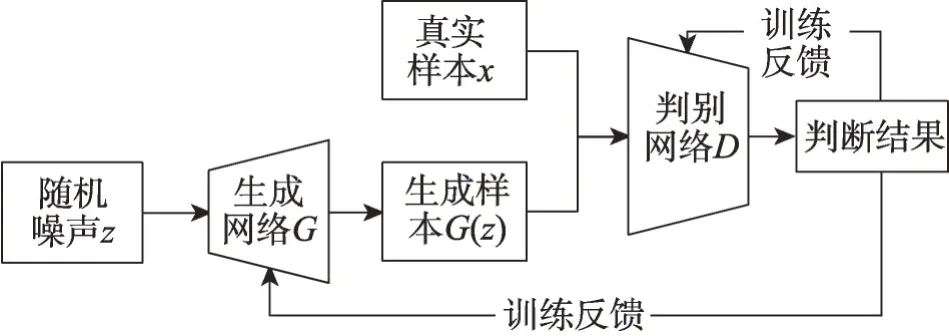
图3 生成对抗网络流程图Fig.3 Flow chart of generative adversarial network
由于生成对抗网络可以模拟真实样本数据的分布,经过生成器生成的伪样本可看作从真实样本的分布中采样得到的,有效避免了重采样和局部采样产生的均衡样本会增加重叠区域复杂度的问题。
Fiore等学者[39]率先将GAN应用到欺诈交易识别领域,通过拟合欺诈交易样本的分布模式,生成伪欺诈交易样本完成对数据集的补充。文章选取了SMOTE 算法作为对比模型,并测试了融入不同数量伪样本的训练数据集对欺诈识别模型性能的影响,当生成的伪样本数量为数据集中原有欺诈样本数量的两倍时,模型性能的提升效果最为显著。
赵海霞等学者同样将最新的重叠度理论引用到基于GAN的欺诈识别模型构建中,提出了RECGAN(re-sampling method based on CGAN)算法[40],文章运用K-NN算法度量样本点周围数据的分布情况,将数据集分为安全样本、边界样本和噪声样本,利用正类样本中边界样本所占的比例表示整体数据集的重叠度。随后用条件生成对抗网络(conditional generative adversarial network,CGAN)和欠采样技术对重叠区间的样本进行均衡,与多个基于重抽样算法的欺诈识别模型相比,算法的识别性能与鲁棒性均得到提升,作为最新的研究思路,该模型未来有很大的提升空间。
3 基于模型层面构建的信用支付欺诈交易识别模型
通过改变分类模型的损失函数或学习策略使模型在训练时对少数类样本即欺诈交易投入更多的精力,抵消数据集类别分布不均衡带来的负面影响是基于模型层面构造欺诈交易识别模型的主要思想。在数字信用交易反欺诈研究中,欺诈交易与正常交易样本量之间的差距过于悬殊,单从模型层面进行优化容易产生过拟合的问题,因此数据科学家普遍从数据与模型层面同时改进,首先对数据集的类别分布进行调整,随后运用改进后的欺诈识别模型进行处理,以增强模型的泛化性。其中数据均衡算法及前沿进展已在第2章进行总结,因此本章主要汇总基于模型层面的反欺诈研究成果。
现有信用支付欺诈交易识别模型根据训练时使用的数据集类型可以分为基于有监督学习算法、无监督异常点检测技术和半监督学习框架的欺诈交易识别模型,如表5所示。
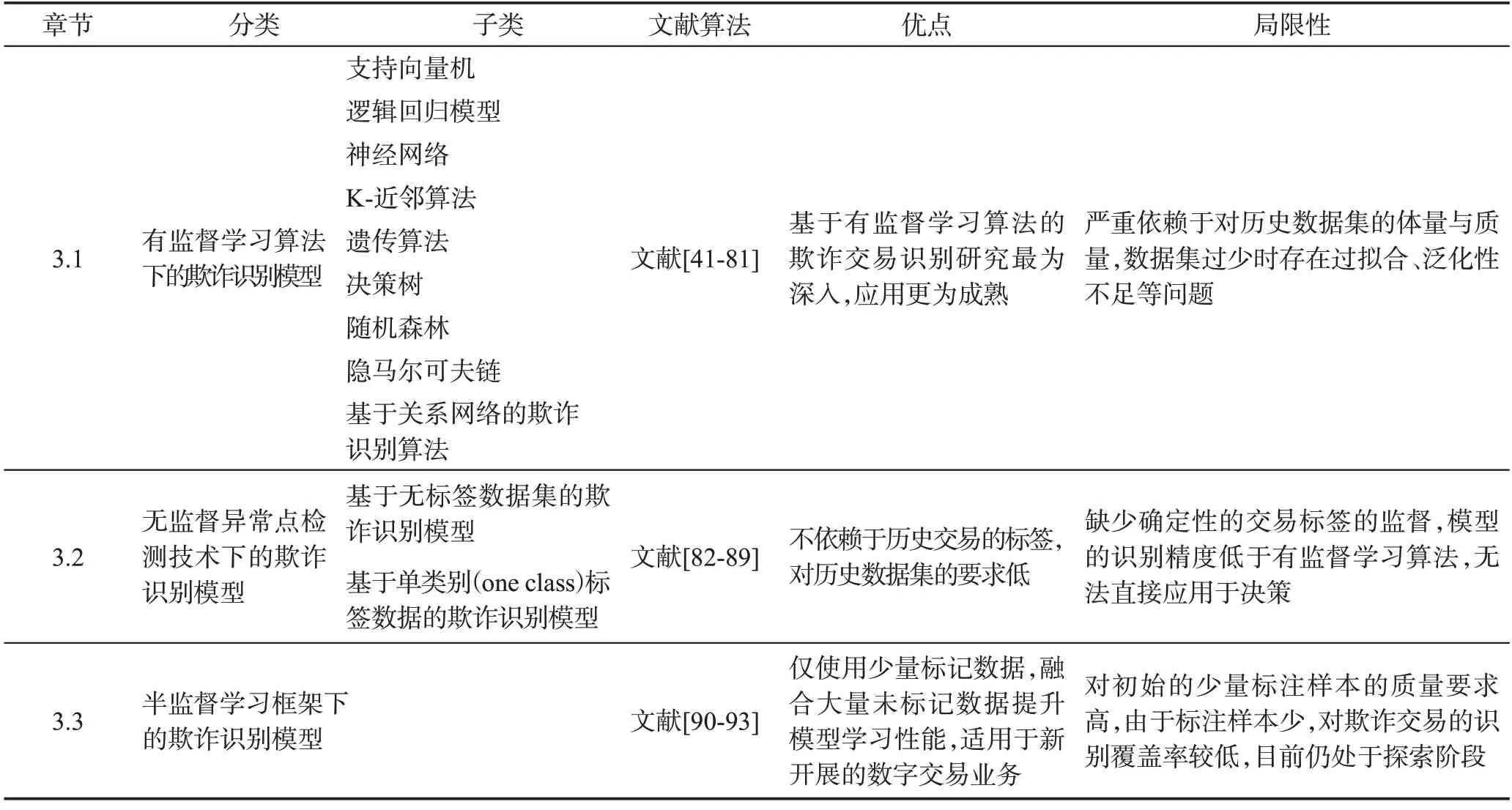
表5 基于模型层面构建的信用支付欺诈交易识别模型Table 5 Credit payment fraud transaction identification model based on model level
3.1 基于有监督学习算法的欺诈识别模型
基于有监督学习的数字交易欺诈识别技术依赖于已知交易结果的历史交易数据集,通过提取历史数据中的欺诈交易与正常交易的行为特征,对新的交易行为进行判断。模型对标注数据集的准确性要求较高,理论基础较为成熟。文献[9]汇总了信用支付欺诈识别领域近10 年内的优秀研究成果,对其中涉及的数据挖掘算法按照出现的频率进行排序,频率越高,代表该类方法越受到学者们的关注。本文参考该关注度排序展开论述,对研究方法与研究进展进行补充。
3.1.1 支持向量机
支持向量机(support vector machine,SVM)是一类二分类学习算法,基本模型是定义在特征空间上的间隔最大线性分类器。面对非线性可分的数据集,核函数与软间隔技术的应用可将输入样本从原始空间映射到更高维的特征空间,在新特征空间中构建超球面作为决策边界完成对数据类别的划分,使SVM成为实质上的非线性分类器适用于更多的业务场景。
面对维度不断增加的交易特征,Xu和Liu两位学者[41]率先将基于高斯核函数优化的SVM 模型用于识别在线信用支付中的欺诈交易,依托核技术解决了原始数据集稀疏性带来的维度诅咒问题,并给出面对不同数据集时的优化方法。效率提升方面,Mareeswari 和Gunasekaran 两位学者[42]将基于高斯核函数的混合支持向量机(hybrid support vector machine,HSVM)分别与社区和尖峰检测技术(spike detection)结合起来构建了一套实时检测系统识别欺诈行为,解决了现有欺诈识别模型在信用支付申请时的身份检测环节泛化性能差、响应时间长等问题,但缺少对实验数据集的详细描述。Spark是专为大规模数据处理而设计的快速通用的计算引擎,Gyamfi 等学者[43]为缓解交易数据集规模不断增长对服务器带来的压力,将Spark 技术与SVM 相结合,提出了专门处理大规模数据的欺诈识别模型,并在特征提取步骤使用了线性回归与逻辑回归技术作为辅助,与后向传播神经网络(back propagation network,BPN)相比,在保证性能的同时有效减少了模型训练所需要的时间。
3.1.2 逻辑回归模型
逻辑回归模型(logistic regression,LR)是信贷风控领域中最基础也最常用的模型,基于特征表现对交易样本的所属类别进行预测。公式由条件概率分布P(Y|X)表示,形式为参数化的logistic分布。
其中,x∈Rn为输入,Y∈{0,1}为输出,w∈Rn,b∈R 为参数,其中w为权值向量,b为偏置。
逻辑回归作为经典的分类模型可以在线性分类问题中取得很好的效果,结果具有可解释性,但在高维大数据集下,识别性能与其他算法相比稍显不足,需要配合强而有效的数据预处理手段一同应用。
在Omar 等学者[37]的研究中,基于原始有偏数据集训练得到的逻辑回归模型无法有效提取欺诈交易的特征,直接导致对欺诈样本识别结果的精确性严重不足,但在以减少重叠样本复杂度为目标对数据集进行特征筛选与数据均衡后,新数据集下的逻辑回归模型性能得到显著提升,同等数据环境下与SVM模型持平。同样在文献[44]中,Itoo等学者基于欧洲数字信用支付交易数据集测试分别由逻辑回归、朴素贝叶斯、K-近邻算法搭建的三类反欺诈算法性能,文章使用随机下采样的方法缓解不均衡数据集对模型的影响,生成了欺诈交易样本量占比分别为50%、34%、25%三类数据集,实验显示,在任一数据集下,逻辑回归在F1-score、AUC 值等评判准则下均发挥了更好的性能。
3.1.3 神经网络与深度学习
神经网络(artificial neural network,ANN)是一类受人脑神经系统工作方式启发而构造的数学模型,通过大量的人工神经元及神经元之间的联结进行计算,能够感知外界信息从而自适应地改变内部结构。在数字信用交易反欺诈研究中,常用来对数据间的复杂关系进行深入挖掘,其网络结构如图4[45]所示。
作为反欺诈研究领域的新晋模型,Randhawa 等学者[46]分别在公开数据集与私有业务数据集上对比了包含神经网络、SVM、LR 在内的12 种Baseline 算法,并基于投票法和Adaboost 技术对分类器进行集成,进一步研究算法间的性能差异。MCC 下的评估结果显示,在单一分类器的对比中,神经网络以0.001的差距位于第二;但在集成算法对比中,以ANN为主体的Adaboost-NN算法与神经网络+朴素贝叶斯的组合算法表现出了最好的识别性能。
为了解决样本分布不均衡导致神经网络对欺诈样本识别精度不足,Ghobadi、Rohani 两位学者[47]将Meta Cost 算法与ANN 结合构造了代价敏感神经网络(cost sensitive neural network,CSNN),通过为标记正确的欺诈交易分配负类错分代价,给予标记错误的正常交易与欺诈交易不同程度的正类错分代价来重构损失函数,有效降低误判率的同时最小化由误判为银行带来的经济损失。杨莲等学者[48]以样本在反向传播网络(backward propagation neural network,BPNN)上的识别结果与真实标签的偏差作为参考,结合焦点损失(focal loss)函数对神经网络中的损失函数进行调整,使模型的训练更加偏向于难以判别的“困难样本”,而此类“困难样本”正对应于特征空间中的重叠区域,该思想有效地提升模型对困难样本的识别能力,改善了欺诈样本检测性能。
另一方面,伴随数据科学的发展与硬件设施的更迭,信息技术的瓶颈逐步从数据获取与计算转向如何面对海量多源异构数据进行信息抽取与知识转换[49]。在此契机下,拥有强大数据抽象化表征能力与端到端学习方式的深度学习技术迅速崛起,基于深度学习的感知认知技术也在金融风险预警中获得广泛应用[50]。
在信用支付欺诈交易识别研究中,以循环神经网络(recurrent neural networks,RNN)为代表的深度序列模型受到了研究者的广泛关注。RNN被设计用于处理具有序列特征的数据,如时间序列数据、文本序列数据等。通过将当前时刻的数据与上一时刻的网络状态一同传入当前时刻的网络进行训练,从而对数据中的时间依赖关系进行建模。但后续研究发现RNN模型在处理长期序列数据时会出现梯度爆炸或梯度消失问题,无法有效学习和利用序列的早期信息,因此进一步提出了长短期记忆模型(long shortterm memory,LSTM)[51]与门控循环单元(gated recurrent unit,GRU)[52]。LSTM 在传统的RNN 网络结构上添加了输入门、遗忘门和输出门,通过门控结构解决长期依赖问题;GRU 模型在保持相近性能的同时对LSTM进行了简化,分别引入重置门与更新门辅助模型捕获序列中的短期与长期依赖关系,LSTM 与GRU 模型的网络结构分别如图5、图6[45]所示。与传统ANN 和深度卷积神经网络相比,基于LSTM 与GRU 算法的反欺诈模型误报率低,准确率与稳健性高,成为反欺诈研究中应用最广泛的RNN 算法[53-54]。在文献[55]中,Benchaji 等学者进一步挖掘数据集中蕴含的序列特征,提出融合注意力(Attention)机制的交易序列欺诈识别模型,与以往的研究相比,Attention机制不仅考虑了交易序列中的顺序性,也具备识别序列中相对重要交易的能力,从而以更高的准确度预测欺诈交易,在保证准确性的同时,显著提升了欺诈交易的识别覆盖率。
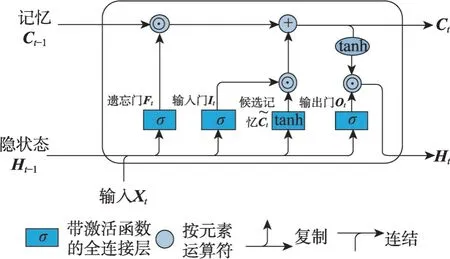
图5 LSTM模型中数据流的图形化演示Fig.5 Graphical demonstration of data flow in LSTM

图6 GRU模型中数据流的图形化演示Fig.6 Graphical demonstration of data flow in GRU
除去被应用于欺诈交易识别模型建模中,强大的抽象表征能力使深度学习在作为集成学习的融合策略时同样受到广泛关注。为解决信用支付交易数据集的严重不均衡问题,刘颖等学者构建了基于深度集成学习的欺诈检测算法[56],将SVM与RF串联形成基分类器,SVM 用于识别训练集中显著的正常交易模式与欺诈交易模式,RF则用于对SVM分类错误的样本进行二次学习,缓解SVM 面对极度不均衡数据易产生的分类超平面偏移问题,最终的模型融合阶段选择深度信念网络(deep belief network,DBN)进行集成,相较于传统的投票机制,欺诈交易的误判率显著降低。Forough 等学者[57]则将LSTM 模型与GRU模型作为基学习器对数据集中的欺诈交易模式进行提取,选择人工神经网络作为新的投票机制对结果进行集成,实验显示,无论哪种深度序列模型作为基学习器,基于人工神经网络集成后得到的识别结果均优于投票机制(voting)下得到的识别结果,且基分类器越少性能提升越明显,对模型的最终成果具有重大贡献。
最后,伴随AlphaGo 及其升级版本的横空出世,强化学习相关概念在业界引起广泛关注,Bouchti 等学者在文献[58]中详细介绍了深度强化学习(deep reinforcement learning,DRL)的理论及其在数字支付环境中进行欺诈检测与风险管理的潜在应用。文章通过讨论有关DRL 的几个有趣案例,揭示了未来研究中DRL方法的竞争力所在。虽然整篇论文偏向理论化,实证检验部分略显不足,但提供了一种处理欺诈检测任务的新视角。
3.1.4 K-近邻算法
K-近邻(K-NN)算法[59]是一类基于实例的分类与回归算法,通过在数据集中寻找与待预测交易样本相似度最高的k条样本,选取其中类别占比最多的标签作为待预测交易的预测结果。
Malini 与Pushpa 两位学者[60]详细介绍了K-近邻算法与异常检测技术的建模思想,从理论的角度论述了算法在欺诈检测任务中的优势,但是文章没有进行实证检验,论据稍显不足。Awoyemi等学者[61]认为欺诈交易识别困难的原因在于交易特征随时间改变的动态性与数据集的严重有偏性,文章将欠采样与过采样技术结合起来对数据进行均衡,构造了两类不同比率的数据集进行对比。随机过采样技术使得欺诈样本的特征更为明显,但也加重了逻辑回归的过拟合问题,实验结果与文献[44]不同,K-近邻算法在两个比率的数据集中均体现出更好的性能。Dighe等学者[62]选取欧洲信用支付交易数据集对文献[61]的结论进行了验证,采用相似的混合采样技术对数据集进行均衡,在多项模型判别准测评估下,K-近邻算法的识别结果更具有稳健性。
K-近邻算法的最大优点在于简单易实施,但这也造成了可扩展性较差,面对特征空间中重叠区域样本时误判率高,作为欺诈识别算法需要提前对数据集进行处理与均衡。但是在最新的研究中,由于K-近邻算法可以度量样本点领域内的分布情况,被学者们广泛应用于对数据集重叠度的测度中,是该模型在欺诈识别问题中的应用新方向。
3.1.5 遗传算法
遗传算法(genetic algorithm,GA)是参考达尔文生物进化论中的自然选择学说和遗传学机理中生物进化过程构建的计算模型,是一种通过模拟自然进化过程搜索最优解的方法。遗传算法可以直接对结构对象进行操作,无需求导和函数连续性的限定,具有内在的隐式并行性和优秀的全局寻优能力,在确定类别惩罚系数与优化反欺诈模型初始参数方面具有突出贡献。
Özçelik等学者[63]认为在欺诈识别检测中应该对透支额度大的信用账户给予更多的权重,因为它们被错分后会带来更加严重的潜在损失,因此提出了具有可变分类错误成本的损失函数并运用遗传算法对各变量对应的参数进行求解,来最小化模型错分损失,改进后的模型增强了对重点客户的关注,识别性能提高了超过200%。效率优化方面,Olabode[64]将遗传算法与反向传播神经网络(counter propagation neural network,CPNN)相结合提出了混合CPNN-GA 算法,遗传算法用来对神经网络的初始参数进行优化,解决由随机设定初始参数带来模型收敛速度慢、精度不足的问题,神经网络对交易进行分类,实验结果显示,改进后的模型训练速度更快且面对不断变化的欺诈策略,识别性能更好。Alotaibi等学者[65]将GA与克隆选择算法(clonal selection algorithm,CLONLG)[66]结合起来以改进CLONLG 算法的克隆选择机制,呈现出的识别结果错分率更低且训练需要的时间更短。
上述研究普遍将遗传算法作为辅助应用于模型的参数更新与训练优化过程,但另一方面,遗传算法通过交叉、变异的方法生成更优子代的思想同样适用于均衡数据的补充。Benchaji等学者[67]运用K-means算法对少数类样本进行聚类,得到的每一个样本簇都具有高度的类内相似性,随后使用GA算法对每一个簇进行新数据生成,补足少数类样本的同时加强了欺诈交易的特征表示,减少了噪声节点的生成,为数据集均衡方法提供了新思路。
3.1.6 决策树与基于集成算法的树模型识别算法
分类决策树(decision tree,DT)是一种描述对实例进行分类的树形结构,由节点和有向边构成。节点有内部节点和叶节点两种类型,其中内部节点表示一个特征或属性,叶节点表示划分后的分类结果。决策树的学习本质是通过训练集归纳出一组显式分类规则,使其能够对实例进行正确的分类。在数字信用反欺诈研究中,其优秀的可解释性搭配便捷的训练方式与不俗的识别性能使其在早期数字风控领域得到广泛应用[68]。
在后续研究中,通过结合多个基学习器以加强模型性能的集成学习思想使决策树算法在数字反欺诈领域焕发了新的活力。根据基学习器之间的关系,可以分为基于Bagging 思想和基于Boosting 思想的树识别算法,前者的代表性算法为随机森林,后者的代表性算法为梯度提升树系列算法。
随机森林(random forest,RF)是Breiman[69]提出的一种由多棵决策树组成的集成学习模型,广泛应用于包含金融、医疗、电子商务在内的多种分类任务场景,运行速度快、稳健性强[70]。作为集成模型,随机森林的整体性能取决于其基分类器的类型与训练效果。Xuan 等[71]在欺诈样本率为0.27%的真实交易数据集上分别测试了基于随机树和C4.5算法的随机森林算法,结果显示基于C4.5 算法的随机森林能够更好地学习欺诈交易的特征,取得了更好的分类效果。
梯度提升树系列算法主要包含梯度提升决策树(gradient boosting decision tree,GBDT)、XGBoost、LightGBM等算法。GBDT算法根据当前模型损失函数的负梯度信息来训练新加入的弱分类器,并将新训练完成的弱分类器以累加的形式结合到现有的模型中;XGBoost算法[72]是GBDT算法的进一步工程实现,通过显式地添加正则项来控制模型的复杂度,有效地防止过拟合问题,并将损失函数进行二阶泰勒展开,同时使用一阶与二阶导数信息进行优化,相较于传统的GBDT 算法,支持更多类别的基分类器,效率更高;LightGBM 算法[73]是Microsoft 开发的GBDT框架,直方图算法的结合、单边梯度采样思想的应用、带深度限制的Leaf-wise建树策略使LightGBM算法具有更快的训练速度、更低的内存消耗以及更准确的识别能力。
陈荣荣等学者[74]基于欧洲信用支付公开数据集对随机森林算法、GBDT与XGBoost算法的性能进行对比,数据集事先经过SMOTE算法处理以达到类别均衡,结果显示,随机森林与GBDT 对于欺诈交易的识别精度相近,XGBoost算法的性能显著优于其余两类集成算法,但模型结构的复杂性使其调参过程更为复杂,时间消耗更久。面对类别不均衡且历史数据集规模较小的信用评估场景,张涛等学者[75]将XGBoost算法与最小风险贝叶斯决策相结合,提出了基于样本依赖代价矩阵的SXG-BMR(SMOTE XGboost-Bayes minimum risk)算法,其代价矩阵不仅与交易类别有关,而且与样本的自身属性相关联,代价的表征更加准确,实验结果显示,结合样本依赖代价矩阵的欺诈交易识别模型检验效果要整体好于传统的类别依赖代价矩阵识别模型,在同样引入样本代价矩阵的情况下,XGBoost 算法相较于逻辑回归、随机森林等分类模型更加准确、稳健。
集成算法与代价损失函数的结合为类别不均衡问题提供了有效的解决方案,但另一方面也加重了数字经济下不断攀升的特征维度对树结构欺诈识别算法训练效率的影响。陈芮等学者[76]针对上述问题将LightGBM 算法与序贯三支决策算法(sequential three-way decisions,S3WD)相结合,提出了基于GANs-LightGBM的序贯三支异常检测模型,根据特征重要性由粗到细地搭建多层次多粒度的特征空间并训练对应的欺诈交易识别模型,持续处理粗特征粒层难以识别的样本,与传统的机器学习算法相比,该方法在提高检测性能的同时具有更低的检测代价。
3.1.7 隐马尔可夫模型
隐马尔可夫模型(hidden Markov model,HMM)是一种双嵌入随机过程,是关于时间序列的概率模型。与经典的马尔可夫模型相比,可以用来拟合更复杂的随机过程。模型由两组变量组成,第一组为状态变量{y1,y2,…,yn},其中yi代表时刻i的系统状态,通常假定该状态是隐藏、不可观测的;第二组是观测变量{x1,x2,…,xn},表示在时刻i的观测值。
基于HMM 构建的欺诈识别模型认为大多数用户在一段时间内会有相对稳定的交易行为,如定期购买相同类型的商品,或与固定对象进行转账交易。交易序列随时间顺序排列,与HMM 模型相对应,由两部分组成,第一部分是可直接在银行数据库中观察的交易金额序列,第二部分是暗示用户交易习惯的交易行为序列,如图7所示。

图7 隐马尔可夫模型下的交易序列Fig.7 Transaction sequence under hidden Markov model
Khan 等学者[77]构建了仿真交易数据,模拟了持卡者在一定支付周期内每笔支出的消费类别及对应的具体消费金额。文章运用K-means 聚类算法将每笔交易按照消费金额分为低、中、高三类,运用HMM算法识别并提取该消费者的支付特征。OOT(out of time)测试显示,HMM对未来短期内的欺诈交易有很好的识别效果。Bhusari 等学者[78]参考文献[77]的思路,做了进一步研究,改进后的模型不再需要获悉每笔支出的消费类别,并提出了K-means 方法中确定类别k的新方式,改进后的模型降低了欺诈交易的误报率。Wang等学者[79]在将量化后每笔交易的消费金额作为观测状态的基础上,融入每笔交易前后固定时间段内的交易频率,因此观测状态从{高消费,中消费,低消费}变成{高消费,中消费,低消费}×{高频交易,中频交易,低频交易}两两结合的九种观测状态。实验结果表示,对于低频交易与中频交易,HMM 算法有较好的识别效果,但高频交易增加了用户交易习惯的提取难度,HMM模型的表现还有待提升。
3.1.8 基于社会关系网络的欺诈交易识别模型
上述欺诈交易识别模型几乎全部聚焦于交易记录本身,利用从历史交易数据集中学习到的特征预测一笔新传入的交易申请为欺诈交易的可能性,完成对欺诈交易的识别与防范。但面对以利用虚假身份信息恶意申请数字支付工具为代表的内部欺诈模式,由于申请者为新用户,缺少历史交易数据,无法进行有效识别,需要从其他的角度进行切入,在申请阶段完成对此类用户的识别。
社会网络(social network)是指以各种连接或相互作用的模式而存在的一组人或群体,例如人与人之间的朋友关系网络、在线社交关系网络、用户间的移动通信网络都属于社会关系网络。社会关系网络不是一个关于个体的简单集合,也不是个体间相互连接关系的总和,而是包含了个体和个体间关系的网络[80],重点关注人们之间的互动和联系,并且假定这种联系会影响人们后续的社会行为。Yang等学者[81]认为用户的移动通信记录可以很好地代表其社交联系,因此作者使用由1 100万用户和超过15亿呼叫日志构成的数据集建立了移动通信网络,在用户已有个人信息的基础上增加了从网络层面提取的局部结构特征指标,运用双任务因子图对新用户是正常用户还是潜在欺诈用户进行预测,有效提高了识别结果的精确率与全面性。
3.1.9 对比与分析
目前,基于有监督学习算法的欺诈交易识别研究最为深入,在实际应用中也比基于其他两种算法的欺诈识别模型更为成熟。本小节对上述欺诈交易识别模型背后的有监督学习算法进行横向对比,表6选取部分算法在欧洲数字信用支付公开数据集进行复现,对当下各类基于不同视角改进的前沿算法性能进行直观展示。表7 进一步总结了各类算法的优缺点及训练数据集的形式,便于研究者在面对特定任务场景中选取最适合的数据分析技术。
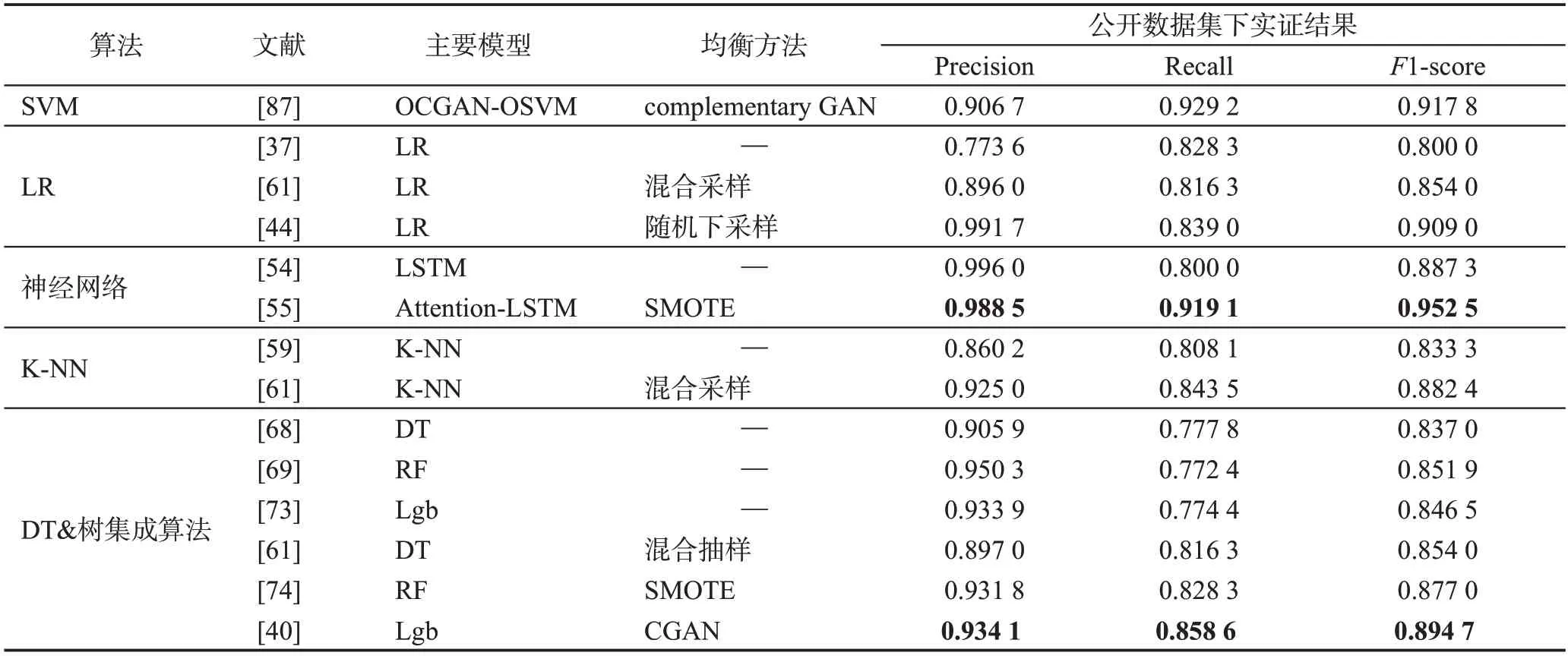
表6 基于欧洲数字信用交易数据集的性能对比Table 6 Performance comparison based on European digital credit transaction dataset

表7 基于有监督学习算法的欺诈交易识别模型对比Table 7 Comparison of fraud transaction identification models based on supervised learning algorithm
3.2 基于无监督异常点检测技术的欺诈识别模型
基于无监督异常点检测技术的欺诈识别模型不依赖于历史交易的标签,该类方法旨在通过表征交易的数据分布,来检测出与正常交易行为特征不符的可疑交易。
3.2.1 基于无标签数据集的欺诈识别模型
从理论角度来看,无监督异常点检测技术可以划分为基于距离(K-means 算法、近邻算法等)、基于密度(DBSCAN(density-based spatial clustering of applications with noise)算法、LOF(local outlier factor)算法等)与基于模型的三类算法。但不断扩大的交易量与特征数量使得前两类算法在训练时的计算量过于庞大,无法满足运算开销的要求[82],因此基于模型的无监督异常点检测技术成为构建信用支付欺诈识别模型的主要理论支撑。
Rai等学者[83]在欧洲信用支付交易数据集上测试了包含基于神经网络、自动编码器、孤立森林在内的五类无监督欺诈识别模型,其中神经网络呈现的检测性能最好,整体数据集分类准确率达到99.7%,对欺诈交易的识别结果也呈现出较高的准确性与全面性,但上述模型仅适用于缺失值较少的数据环境,当交易特征呈现出高度的稀疏性时,包含神经网络、自编码器在内的上述无监督学习算法便难以有效识别交易间的差异。Zheng 等学者[84]设计了一个具有多层非线性函数的无监督深度学习模型来捕获数据集内高维非线性的欺诈结构信息,并结合联合嵌入技术学习双向网络中节点的潜在表示,有效地将不同类型的节点共同嵌入到同一潜在空间中,即使面对稀疏性较高的交易数据集依旧可识别出绝大部分潜在欺诈交易。
基于现有的研究进展,无监督欺诈识别模型已经具备挖掘部分潜在欺诈交易的能力,但作为决策模型加入到欺诈交易识别工作中还有缺陷,这是由模型背后的理论基础导致的。对于重叠区域的大量样本信息,高度的特征相似性大幅限制了无监督欺诈识别模型的分类能力。Pumsirirat等学者[85]曾希望利用无监督学习算法识别有监督学习算法无法处理的新型欺诈交易模式来提高检验性能,提出了基于自动编码器(auto-encoder,AE)和受限玻尔兹曼机(restricted Boltzmann machine,RBM)的深度识别算法,通过重建正常交易样本来发现数据集中异常的交易模式,但实证结果显示,召回率增加的代价是错判了大量正常交易,最终识别的精度不足5%;文献[83]中除了神经网络之外,其他模型均出现了严重的过拟合或欠拟合问题;文献[5]基于公开数据集对常用的有监督与无监督学习算法进行了汇总与对比,实验结果显示,无监督学习算法虽然避免了分布假设问题与前期数据标注的困难,但在相同的召回率下会将更多的正常交易错判为欺诈交易,因此通常作为数据集标注不足时的探索性分析使用。为了解决上述问题,学者们将目光聚焦到了一种特殊的无监督学习算法——单分类欺诈识别模型。
3.2.2 基于单类别标签数据的欺诈识别模型
基于单类别标签数据集的欺诈交易识别模型又称为基于单分类技术(one class classification,OCC)的欺诈交易识别模型。与传统的无监督学习算法不同,此类算法需要事先了解数据集中的标注情况;与有监督学习算法不同,算法仅通过对单一类别样本的学习便可将该类样本与数据集中的其他类别样本进行区分,因此是一类特殊的无监督异常检测算法,适用于数据集分布严重失衡及其他类样本标注可信度不足的情况[86]。在欺诈交易识别任务中,单类别标签数据加强了模型对该类样本特征的学习能力,同时缓解了有监督欺诈识别模型倾向于将历史数据集中未出现过的欺诈交易模式划分为正常交易的问题[83]。
Jeragh、AlSulaimi两位学者[87]针对交易数据集中欺诈样本少、重叠区域样本复杂等问题,将数据集中的欺诈样本单独提取出来,运用自编码器来学习欺诈交易特征的潜在表示,并将训练样本通过自编码器后得到的均方误差作为输入放入单分类支持向量机(one-class SVM,OSVM)中寻找分类超球面,与仅使用自编码器、OSVM 的单一模型和将潜在表示作为输入结合到OSVM的模型[88]相比,模型对欺诈交易识别的覆盖率得到显著提高。
Zheng 等学者[89]提出了改进的单类生成对抗网络(one class GAN,OCGAN)模型,仅需要使用正常交易的样本信息作为训练数据。文章使用LSTMAutoencoder 提取正常用户交易的特征表示,随后使用互补生成对抗网络(complementary GAN)反向学习欺诈交易的分布表示,训练完成后的鉴别器即为最终的判别模型。反欺诈测试中,改进后OCGAN的性能超过了现有的单类别分类算法,检验效果与最新的有监督学习算法Multi-source LSTM相媲美。
3.3 基于半监督学习框架的欺诈识别模型
基于有监督学习的数据挖掘算法在数字欺诈交易识别任务中已经获得了广泛应用,但模型的训练依赖于大量有标注的历史数据集,对于一些新开展的在线支付业务,该需求无法满足。同时,由于数字交易自身的业务特点,交易的发生与对应交易类型即标注的确定之间存在时间差,期间将产生大量的无标注数据。这部分数据无法被基于有监督学习算法的欺诈交易识别模型使用,造成数据浪费。无监督学习技术放宽了对训练数据集的约束,但由于缺少确定性的交易标签的监督,模型的识别性能无法直接应用于决策。因此有学者提出了基于半监督学习框架的欺诈识别模型。
同时使用有标注数据和无标注数据训练模型是半监督学习算法的优势,目前研究理论已经较为成熟。Lebichot 等学者[90]基于时间窗口模拟了一个包含三类业务状态的数据场景,将测试算法当天的交易记录作为待预测的测试集,测试算法日前22天—前7天的交易记录设定为交易类型已确认的有标签数据集,测试算法日前7天内发生的交易记录标记为未出表现期的无标签数据集,文章使用融合半监督框架的APATE 模型作为分类器。经过测试,相较于仅使用有标签数据集的APATE 模型,改进后的算法在测试集上的识别精度更高。
除去可以有效利用数据信息、增加数据价值,半监督学习在训练中标记的欺诈交易样本也成为应对数据集类别不均衡的重要手段。Salazar 等学者[91]与大型金融公司合作,在其提供的私有数据集上进一步对比了半监督学习在不同欺诈交易样本率的数据集上模型的表现差异。欺诈识别结果显示,欺诈样本数量占比越少即数据集构成不平衡度越高,基于半监督学习框架的欺诈交易识别模型提升的效果越好。Xiao等学者进一步将成本敏感学习算法、数据分组处理方法(group method of data handling,GMDH)融合进半监督学习算法框架,提出了一项基于GMDH的成本敏感半监督学习算法(GMDH-based cost-sensitive semi-supervised selective ensemble,GCSSE)[92],与同样作为半监督学习框架的Tri-training、Semi-Bagging、CoBag 等算法相比,GCSSE 算法发挥了最好的识别性能。在最新的研究成果中,半监督学习框架也开始出现在数据均衡技术中,Charitou 等学者[93]将半监督学习框架、稀疏编码器(sparse autoencoder)与GAN相结合提出稀疏自动半监督生成对抗网络(semi supervised GAN,SSGAN),在相同的分类器下,补充的均衡样本具有更好的增益。
3.4 公开数据集汇总
公开数据集的存在能够在一定程度上缓解研究者数据收集工作的压力,将更多的精力投入到欺诈识别研究中。表8 对近年来学者在论文研究中应用频率较高的公开数据集进行罗列,并对数据集中的样本量与特征情况进行描述,当前除UCSD-FICO 数据集停止官方维护,其他数据集均开源在官方网站中供研究者使用。
4 需求视角下数字交易反欺诈研究新方向
通过上述文献的汇总,以信用支付为代表的在线交易欺诈识别模型在近年来已经取得长足的进展,但依旧还有部分难题没有攻克。本章将在已有成果的基础上,从业务需求的角度对目前学者们主要研究的方向进行介绍。
4.1 欺诈识别模型的泛化性
不同国家、不同人群之间欺诈行为往往存在着较高的异质性,意味着基于特定地区数据集训练出的欺诈识别模型难以直接应用于其他环境。考虑到部分地区的数据不足以及大数据驱动下模型训练的高昂成本,将训练好的模型合理地迁移学习到其他环境中对在线交易的欺诈识别问题具有重要意义。在最新的研究中,Lebichot等学者[94]针对该问题展示并对比了15 种迁移学习技术,基于真实的电子商务交易数据,将为欧洲国家开发的欺诈检测模型迁移至其他国家中,并对不同迁移方法下的实证结果进行了比较。研究发现,现有的迁移学习方法都过于依赖目标国家标注样本的数量,文章将自监督与半监督算法的思想相结合,摆脱对海量标记训练样本的依赖性。
除迁移学习之外,提出生成对抗网络的谷歌Goodfellow 团队给出了条件更为宽松的解决方案——对抗学习技术[95]。虽然深度神经网络拥有强大的学习能力,但面对被故意添加细微噪声干扰所形成的对抗样本极为脆弱,通过对噪声进行精心设计,攻击者可以使神经网络模型丧失原有的功能,面对难以察觉其改动的输入样本给出具有高置信度的特定输出。Elsayed、Goodfellow等学者[95]利用深度学习面对对抗性攻击的薄弱性,通过学习融合目标域数据的通用扰动以及任务之间映射的转换函数使得源域中的模型具备执行目标域任务的能力。由于对抗学习对深度神经网络输入施加的加法偏移足以将网络重新用于新任务,训练中无需对源域模型进行微调,理论上比迁移学习效率更高。Chen等学者率先利用对抗学习的思路提出了用于欺诈识别的预训练对抗重编程方法(adversarially reprograms an ImageNet classification neural network for fraud detection task,AdvRFD)[96],选择ImageNet 图像分类数据集的高性能预训练网络作为源模型,将交易样本特征镶嵌到图片特征变动较大的高频区域以构建新的图像数据,并在新的数据集上学习通用扰动项与转换函数,实验结果表明,相较于从头训练的DenseNet-161 网络,AdvRFD-DenseNet-161 不仅训练时间短,对欺诈交易识别的精度也优于DenseNet-161 网络,为对抗学习技术在数字交易欺诈识别领域提供了全新方向。
4.2 欺诈识别模型的可解释性
随着模型复杂性的增加,以深度学习算法为代表的大部分数据挖掘模型均为黑箱模型,无法解释每个特征如何对最终的结果产生影响。而在信用支付欺诈识别业务中,研究者不仅希望识别出异常,还需要了解决策的制定依据,以便于及时更新风险策略。因此,提高模型的可解释性是领域内学者关注的重要研究方向。
在目前研究中,使模型具有可解释性的通用思路是设计一个代理模型[97],在局部数据或全局数据集上对模型进行代理,获得对应样本上的解释。其中局部代理较为成熟的方法是Ribeiro 等学者提出的LIME(local interpretable model-agnostic explanations)模型[98],首先对样本输入添加轻微扰动构建新数据集,再基于扰动后数据集训练可解释模型进行局部建模来获取解释;全局代理则是使用决策树、规则集、教学式方法这种天然易于解释的模型进行代理,以对决策结果进行解释。另外一种思路则是利用深度学习模型的一些自身性质对输出做出解释,如注意力机制(attention)、分层相关性传播技术[99]等。
文献[100]中,Wu、Wang 两位学者针对深度神经网络作为黑箱模型无法为结果提供可解释性建议的缺点,创新性地将基于LIME的解释性模块融入识别模型中,该解释模块由三个白盒解释器构成,分别对应解释模型结构中自编码器、判别器与整个欺诈检测模型三部分。数据均衡方面,作者基于生成对抗网络提出了改进的单类异常检测模型,将自编码器作为模型中的生成器缓解生成对抗网络在生成少数类样本伪数据时不够稳健的问题,解释性模块的加入为特定样本每个特征如何对最终模型输出做出影响提供了清晰视角。董路安、叶鑫两位学者则针对传统教学式解释方法中准确率不足、评价指标测度不够全面两个问题进行改进,选择决策树作为代理模型提出了基于改进教学式方法的信用风险评价模型[101],仅将黑盒模型分类正确且可信度较高的样本用作训练可解释模型的训练样本,并设计了全新的剪枝方法维护可解释模型的准确性、可解释性以及与黑盒模型的一致性,实验结果显示,改进后的教学式方法在大幅提高可解释性能的同时能够准确识别原黑盒模型中93%的结果。
4.3 面对新型欺诈交易模式的敏感性
有监督学习算法下的欺诈交易识别模型是以交易中的欺诈模式能够从历史数据中识别并提取这一假设构造的,因此,面对历史数据未涵盖的新型欺诈模式时,欺诈识别这项任务就变得具有挑战性。不依赖于现有标注的无监督学习技术虽然可以帮助欺诈检测系统发现异常,但由于缺少确定性的交易标签的监督,该类算法对特征空间中的重叠样本无法取得很好的识别效果。最新的研究中,有学者聚焦于这两种模型各自的优势,将两种技术结合以达到同时识别历史、新兴欺诈模式的需求。Carcillo 等学者[102]受到Micenková等学者在文献[103]提到的“bestof-both-worlds”思想的启发,率先将该准则应用到数字欺诈交易识别中,分别从整体数据集、同一用户历史交易数据集两种视角出发,计算交易样本在不同粒度下的异常值分数,并将其作为新特征加入到有监督模型训练中。异常分数越高,代表着该样本的交易特征在当前环境中与其他样本差异越大。改进后的模型在AUPRC 评判准测下的综合性能有所提升,但是基于TopN Precision 测度的头部风险识别能力没有显现显著差异。文章展示、对比了多个方法与粒度下的异常值分数对现有模型的优化效果,对解决目前有监督学习模型无法检测新型欺诈交易模式、无监督学习模型精度不足的难题提供了新的思路,未来还有很大的研究空间。
5 总结与展望
近年来数据挖掘技术的发展,硬件设备的更迭,数字支付方式盛行带来的交易记录激增为欺诈交易识别研究奠定了坚实的基础。本文聚焦这一领域,首先介绍了信用支付欺诈交易识别问题的相关概念、研究难点及评判标准,随后根据构建模型的理论基础,从数据均衡算法与模型优化策略两方面分别对欺诈交易识别模型进行了详细阐述,重点介绍了各类欺诈交易识别模型的理论基础、适用场景及前沿进展,并结合业务场景对同类算法进行对比与总结。最后,文章结合现有的研究成果,从需求的角度出发对眼下最新的研究方向进行论述。
从目前的研究成果来看,现有欺诈交易识别模型已经可以准确地抽取历史数据集中的欺诈交易模式,结合用户的个人信息、行为模式对新发生的交易申请进行准确推断。对于部分没有或标注数据集不足的新型业务,也有相应的无监督和半监督欺诈识别算法作为辅助应用在决策过程中,整体研究进展顺利、未来可期。但在蓬勃发展的数字经济时代,欺诈交易识别模型作为保护用户财产的最后一道“守护卡”,尚不能驻足于此,本章基于已有的研究成果和不足,结合在线欺诈交易识别任务在新时代暴露的新需求,总结了以下未来最值得关注的问题和研究方向。
5.1 打破数据孤岛,及时互联互通
从数据分析的角度来说,信息的来源越丰富,对客户的刻画越细腻,分析的结果就越准确。数字支付方式的普及使得银行、第三方支付平台手中快速累积了巨量的交易数据,但交易信息的敏感性、用户身份信息的私密性成为数据共享时的难题,大量的多源异构数据无法相互传递,造成了信息浪费。联邦学习(federated learning)[104]是谷歌率先提出用于解决“数据孤岛问题”的新方案,能够使各终端在不泄露隐私数据的条件下实现协同训练,目前已有研究[105]将其与决策树算法相结合用于反欺诈中,实现了联邦学习的初步应用,这种新型的人工智能技术有望成为未来分布式学习和企业间联合建模的曙光。
另外,“数据孤岛”现象不仅存在于企业与企业中,还存在于企业与学者中。目前的公开数据集稀少,学者们缺少将理论快速进行验证的通道,拖慢了反欺诈研究的进程。处理好“数据孤岛”问题势在必行。
5.2 聚焦重叠样本,关注主要矛盾
从技术角度看,映射在特征空间中的重叠区域样本具有高度的特征相似性,难以被模型准确捕捉与识别;从业务上看,重叠样本代表着当前数字金融环境中隐匿性最强的欺诈行为,是欺诈损失的主要来源。因此,增强算法对重叠样本的分类精度是研究者在迭代优化模型时的主要目标,也是未来数字信用反欺诈研究的重要方向。在最新的研究成果中,文献[34-35]从定性的角度对欺诈交易样本的邻域分布进行深入挖掘,避免生成噪声节点的同时优化均衡样本的稳健性;文献[37,40]从特征空间出发量化数据集均衡前后重叠区域的变动情况,并将样本重叠系数融入欺诈识别模型的损失函数中,加强对该区域样本识别能力;文献[48,75]为各交易样本添加样本粒度下的错分代价,使模型在训练中能够主动关注难以识别的重叠样本。上述文章打开了聚焦重叠样本的新思路,但性能提升的背后是模型参数量与复杂度的大幅提升。目前针对重叠样本的优化工作正在如火如荼地进行,同时也是未来数字信用交易反欺诈研究的重要方向。
5.3 提升模型的解释能力,辅助智能决策
面对海量多源的高维数字信用交易数据,以Lgb、深度学习为代表的欺诈交易识别模型参数量与复杂度不断增加,精度提升的背后是可解释性能的大幅下降,研究者难以解释每个特征如何对最终的决策产生影响。在数字信用反欺诈研究中,银行或第三方支付机构需要的不仅仅是模型在测试集上的准确率,更需要了解模型从历史交易数据集中学习到的风险点或具体的欺诈行为模式,进而有针对性地进行策略调整,加强风险防范,在根本上杜绝欺诈损失的发生。回顾现有研究成果,主要的突破是代理模型的运用[97-101],通过添加外部的可解释器为当前欺诈识别模型的决策提供局部或全局解释。目前仍存在以下两方面不足:代理模型无法完全替代决策模型,两者间存在信息损失;决策模型自身的可解释性没有得到优化,依旧不具备相应的可解释性能。在未来的研究中,如何提高模型的可解释能力并用到决策过程值得进一步研究。
5.4 善用数据资源,防范新型欺诈交易
运用数据挖掘或深度学习算法提取历史数据集中的欺诈行为特征,进而对新发生的交易展开预测是当前数字信用交易反欺诈研究的主要思路。但实际业务场景中,从欺诈交易发生到相关案例库形成之间存在间隔,时间上的滞后性使欺诈交易识别模型面对历史数据未涵盖的新型欺诈模式时,无法对其进行正确识别。目前,有关新型欺诈交易的防范还处于理论探索阶段,如何利用手中海量、多源的交易信息在学习已有欺诈模式的同时加强对新型欺诈模式的敏感度是未来亟需攻克的问题。
猜你喜欢
眼科新进展(2022年12期)2022-12-29
公民与法治(2020年20期)2020-11-27
中国外汇(2019年16期)2019-11-16
中国外汇(2019年10期)2019-08-27
中国外汇(2019年9期)2019-07-13
中国设备工程(2017年7期)2017-04-10
股市动态分析(2016年23期)2016-12-27
瞭望东方周刊(2016年45期)2016-12-07
公民与法治(2016年24期)2016-05-17
上海国资(2015年8期)2015-12-23
