
面向知识图谱和大语言模型的因果关系推断综述
2023-10-29 04:20马新宇杨国利赵会群
计算机与生活 2023年10期
李 源,马新宇,杨国利,赵会群,宋 威
1.北方工业大学 信息学院,北京 100144
2.北京大数据先进技术研究院,北京 100195
“因果关系”[1]是指存在于事件之间的一种关系,即“原因”与“结果”之间的对应关系,是一种重要的关系类型。一般来讲,一个事件是很多原因综合产生的结果,且原因都发生在较早时间点,而该事件又可成为其他事件的原因。与描述性或预测性任务不同,因果关系推断旨在理解干预一个变量如何影响另一个变量[2]。
因果关系推断作为一项重要的研究课题,在许多领域中有极高的应用价值。一旦做到真正理解因果关系背后的逻辑,即可在计算机上进行模拟,进而创造出一个“因果关系推断专家系统”。这个系统将可能为解释或发现未知的现象或规律,解决久而未解的科学问题,开发和设计新的实验,并不断地从环境中获取更多的因果知识,进而为社会和民众带来福祉。例如:在数据库领域,从文本数据中提取出事件的因果信息可以填充事件数据库,为事件数据库提供有价值的事件数据[3];在事件预测领域,因果关系推断可应用于重大事件或突发事件的预测,有助于政府迅速做出反应和决策[4];在生物制药领域,因果关系推断可以用来识别药物分子之间的相互作用或药物分子对某疾病的治疗效果及作用,以了解其性质和疾病的发病机制[5]。现如今,随着越来越多的深度学习模型的诞生,模型的可解释性也成为研究人员越来越关注的问题,因此研究模型输入与输出之间的因果关系可以增强模型的可解释性[6]。总之,许多领域在未来都可以从因果关系推断技术或系统中获益。
传统的因果关系推断方法分为两种:一是面向样本数据的因果关系推断。以随机对照实验为例,为了研究发现药物的疗效,患者将被随机地分为治疗组和对照组,通过比较两组患者的平均结果来衡量药物对某疾病的康复效果的影响[7]。二是面向文本语义分析进行因果关系发现。具体过程是首先通过自然语言处理技术,将文本数据转换成可计算的形式,例如提取文本中的实体、关系等信息;然后利用机器学习、深度学习等技术对获得的信息进行建模,得到变量之间的因果关系。
知识图谱是一种用于表示实体关系的图形结构,其中蕴含丰富的实体间的关系信息(例如因果关系信息)。大语言模型拥有海量参数,可以从上下文信息和对语义理解进行因果推断。但在目前众多有关因果关系推断的文献中[8],尚未涌现对知识图谱和大模型因果关系推断的总结性文献。鉴于此,经过深入的调查研究(见表1),本文对面向知识图谱和大模型的相关因果关系推断方法进行总结,将传统因果关系推断方法进行了分类详述,并对未来因果关系推断的发展趋势(如图1)进行了详细总结和对比。

表1 因果关系推断相关文献Table 1 Related literature on causality inference
本文对因果关系推断的方法和模型进行了深入的分类讨论。从多个关键方面出发,包括面向样本数据、文本语料、知识图谱以及大模型等,从而更加准确和详尽地对因果关系推断方法进行讨论。(1)传统的因果关系推断方法:这一类方法主要分为面向样本观测数据和文本语料两类。面向样本数据的方法基于统计学原理,挖掘数据变量之间的因果关系;而面向文本语料的因果关系发现方法通过分析文本中的逻辑关系、因果信号和主题词等,可以从大规模文本语料中挖掘出潜在的因果关系。(2)面向知识图谱的因果关系推断方法:知识图谱是一种用于表示实体关系的图状结构,其中蕴含丰富的因果关系信息。基于知识图谱的方法可以通过对图谱中的实体和关系进行推理,揭示出潜在的因果联系。这类方法有助于将外部领域知识融入因果关系推断过程。(3)面向大语言模型的因果关系推断方法:大模型可以从多源数据中学习因果关系的模式,利用上下文信息和语义理解进行推断,从而提高因果关系的准确性和普适性。(4)知识图谱与大模型相结合的因果关系推断方法:旨在利用知识图谱的结构信息和大型语言模型的文本理解能力来深入理解和推断因果关系。
通过从以上几个方面进行分类,能够更全面地理解不同因果关系推断方法的优势和局限性。本文旨在为读者提供一个系统性的视角,帮助研究此方向的学者以及对此方向感兴趣的读者能够更好地把握因果关系推断领域的发展趋势和前沿动态。通过综合考虑统计学、文本语料、知识图谱和大语言模型等多个方面,本文希望能够为因果关系推断方法的讨论提供更加深入和全面的内容,促进该领域的研究和发展。
1 因果关系推断概述
早期因果关系推断是在没有实验设计或者随机分配的情况下,通过观察变量之间的关系来推断因果关系的方法。这种方法可以追溯到18世纪的哲学家大卫·休谋,他提出了“常见的连续性”(常见的联系)的概念,即通常只能通过经验观察到两个事件的关系,而无法知道其中一个事件是因果于另一个事件。
随着统计学等学科的发展,一些早期的因果关系推断方法逐渐得到了发展和完善,例如卡方检验[9]、Pearson相关系数[10]、多元回归分析[11]等方法。这些方法都可以用于检验两个或多个变量之间的关系(因果效应),并推断其中的因果关系。但是,由于没有实验设计,这些方法并不能完全消除混淆变量的影响。因此,现代的因果推断方法则更加严格,例如随机化对照实验、自然实验和文本数据统计分析等。通过这些方法通常更能保证因果关系推断的准确性。
本文从多个关键方面出发,包括面向样本数据文本语料、知识图谱以及大模型等,从而更加准确和详尽地对因果关系推断方法展开讨论。
2 传统因果关系推断方法
传统的因果关系推断方法根据其面向的对象可以分为两大类:面向样本观测数据和面向文本语料的方法。面向样本观测数据的因果关系推断方法主要依赖于统计学相关技术来推断因果关系[12]。这些方法建立在统计学的基础上,基于假设,即如果两个变量之间存在因果关系,那么它们之间必定存在一定的统计联系。因此,通过分析这两个变量之间的统计关系,可以得出它们之间可能存在因果关系的结论。而面向文本数据的因果关系推断方法则侧重于从文本中提取因果关系,通常需要进行一系列文本处理步骤,如分词、词性标注、实体识别等。接着,借助自然语言处理技术来分析文本中的语义信息,以发现其中隐藏的因果关系。这类方法通常需要倚赖领域知识和语言模型的支持,以更准确地提取和理解文本中的因果关系信息。
2.1 面向样本观测数据的因果关系推断方法
在统计学领域,许多优秀学者为因果关系推断的研究与发展做出了卓越贡献,Fisher[13]及Neyman等[14]各自从统计学家的立场出发,分别提出了从潜在结果和随机的视角来讨论因果关系。Fisher提出了“随机对照实验”的概念,而Neyman 提出“潜在结果”并将其应用于随机对照实验。Rubin在文献[15]中进一步结合了“潜在结果”和“随机对照实验”这两个概念,系统性地提出了潜在结果模型的理论假设、核心内容和推理方法。Neyman 利用数学语言描述了潜在结果框架下的因果效应,Rubin将这一数学定义推广到观察性研究中。
随机对照实验是推断因果关系的最高效的方式,将对象随机分成两组,并且控制两组只有待验证的变量不同,其他变量相同,观察结果。在科学研究中,使用随机分配机制将子对象分配给不同的治疗组的随机对照实验作为建立因果关系的黄金标准有着悠久的历史。然而,在许多情况下,随机实验在实践中既不可行,也不符合伦理,因此研究人员需要依靠观察数据来推断因果关系,进而将随机对照实验方法进行了推广。
推广随机对照实验的一种常见方法是通过倾向评分。Rosenbaum 和Rubin 在文献[16]中表明,如果治疗分配没有根据随机变量的情况确定,那么它同样没有根据倾向评分确定,这表明根据倾向评分进行调整可以消除观察性研究中的混淆。一旦估计了倾向得分,即可进一步应用匹配、分层和逆概率加权等方法进行因果关系推断。
但是观察性研究仅针对观测数据进行观察,以推断变量间的因果效应,但这种方法不能由研究者决定是否针对某些研究对象采取干预或对照操作,并且如果忽略了协变量的作用,仅使用随机对照实验进行因果关系推断就会产生偏差,这种偏差又称为“混淆因素”。文献[17]在相关关系的基础上定义混淆因素为:假如两个变量之间的相关关系受到第三个变量的影响,则称第三个变量为混淆因素。文献[2]则从潜在结果的角度出发对混淆因素进行了定义:p(Y1|X=1)=p(Y1|X=0)且p(Y0|X=1)=p(Y0|X=0),即若潜在结果Y0和Y1的分布情况与对照总体的潜在结果分布情况相同,则说明干预组与对照组之间无混淆因素干扰。因此观察性研究不再满足随机对照实验的条件。为了表述因果关系,Rubin 在文献[18]中提出了一种潜在结果框架,其中一个重要概念为“因果效应”。因果效应是指在给定一些特定的干预措施(例如药物或教育方案)下,响应变量(例如治愈率或考试成绩)发生的变化。为了衡量这种效应,Rubin提出了一个符号体系来表述潜在结果框架:
其中,τ表示因果效应,E表示期望值,Y(i),i=0,1 表示潜在结果下的响应变量。
在实际应用中,由于无法同时观察到Y(0) 和Y(1),需要利用统计学的方法来估计因果效应,从而进行因果关系推断。然而潜在结果框架只能观察和实现其中一个潜在结果,因此存在缺失数据的问题。并且当涉及到识别因果路径或可视化因果网络时,潜在结果框架具有自身的局限性。
因此,Munch等在文献[19]中提出了一种交互式方法,从已知边图表示的任何给定相关领域建立概率关系模型。结合本体论和专家知识,定义了一组转化为关系模式的约束。通过此关系模式可以学习概率关系模型,并可以应用因果关系推断。此方法的主要思想是在给定因果约束下的学习概率模型,从学习到的模型中,提取因果知识。Yuan等在文献[20]提出结构方程模型(structural equation model,SEM),研究可观测变量与潜在变量,以及潜在变量之间关系。SEM是一种能够把样本数据间复杂的因果联系用相应的模型方程表现出来并加以测量、进行分析的模型方法。结构方程模型针对一些数据本身不能直接询问或测量得到,即所谓以潜在变量的形式,对数据模型进行估计的分析方法。结构方程模型包括两个基本模型,分别为测量模型和结构模型,测量模型由潜在变量、观测变量以及测量误差项组成,主要分析潜在变量对观测变量的影响效果。Awang等在文献[21]中引入了非参数结构方程模型(non-parametric structural equation model,NPSEM),对结构方程模型和松弛的线性假设进行了调整。对于NPSEM,它允许研究人员更自由地探索变量之间的关系,而不受事先设定的参数假设的束缚。这有助于发现潜在的非线性关系、交互作用和因果关系,从而提供更准确和全面的分析结果。
面向图模型的结构因果模型(structure causal model,SCM)是传统因果推断中最常用的模型之一。在文献[22]中,Pearl详细阐述了潜在结果模型与结构因果模型之间的等价性。相比之下,潜在结果模型更加精确地代表观察数据,从而有助于推断因果关系模型,而结构因果模型更加直观。Pearl 在贝叶斯网络领域提出了外部干预的概念,并为面向外部干预提供了一种形式化表达方法,这一概念开创了一种从数据中挖掘因果关系和理解数据生成机制的方法。因此,本节总结了因果图模型方法以及面向知识图谱的因果关系推断相关的概念和方法。这些方法为人们更深入地理解因果关系提供了强大工具。
图论是一种广泛被应用的数学语言,它能够直观地描述事物之间的相互影响关系,并且可以通过简单的计算解决因果问题。在数学中,有向图[23]中节点X和Y之间的路径是指从X开始到Y结束的一系列由边连接的节点。路径上的第一个节点称为该路径上所有节点的祖先节点,而其他节点则是祖先节点的后代节点[24]。如果路径沿着箭头方向追踪,那么这条路径就称为有向路径。当图中存在一个节点存在回到自身的有向路径时,这个图被称为有环图,而没有环的有向图则称为有向无环图(directed acyclic graph,DAG)[25]。
结构因果模型是一种图形表示的因果关系模型,可以描述一个或者多个变量之间的因果关系的图形表示。形式上,SCM 可以表示为一个四元组
面向有向无环图的结构因果模型[26]因果关系的推断依赖于有向无环图的三种基本路径结构,即因果链条、共同原因和共同结果三种结构。因果链条结构可以表示为X→Y→Z,表示信息尽可以单向传递;共同原因结构X←Y→Z表示信息可以从中间节点传递给两端节点;共同结果结构X→Y←Z表示中间节点同时接收两端节点的消息。通过这三种结构(如图2)可以将结构因果模型中任意路径进行拆分,以至于考虑到结构因果模型中全部的因果路径,从而可以准确推断出因果关系。
Richardson和Robins等在文献[27]中引入单一世界干预图,该图统一了图形理论和潜在结果框架。具体来说,对于在系统中设置的XA=xA的任何干预,表示为G[X(XA=xA)]的单一世界干预图可以从DAG中构造而来,从而进行因果关系推断。该模型利用DAG表示随机变量之间的因果关系,并引入干预变量的概念来描述针对某些变量进行的干预操作。SWIG(single world intervention graph)模型通过对DAG 上的治疗节点进行“分裂”操作,形成新的图形,该图形上的节点对应于对治疗变量进行干预后的反事实变量,即对于干预前原始的变量取值的替代值。Pearl[22]通过将结构方程和有向图结合进行因果结构建模,并以此推断因果关系。
传统的面向图模型的因果关系推断方法可以分为两类:第一类方法是面向条件独立性关系,其代表性算法为(Peter Clark,PC)算法[28]、FCI(fast causal inference)算法[28]和GES(greedy equivalence search)算法[29]。这类方法通过判断变量之间的条件独立性来构建无向图,然后通过一系列的步骤来判断图中边的方向。第二类方法是面向结构方程模型的方法,其代表性模型为非时序线性非高斯(linear non-Gaussian acyclic model,LINGAM)模型、非线性加性噪声(additive noise model,ANM)模型和后非线性因果模型(post-nonlinear causal model,PNL)。
PC算法的核心思想是面向条件独立性关系来推断DAG 的结构,并通过删边和方向传播等操作来确定DAG 中边的方向。PC 算法详细步骤如下所示:(1)PC 算法从一个完整的无向图G开始。(2)对于每一对变量i和j,算法逐个检查当n=0,1,…,d-2 时,是否存在一些其他n个变量的条件使得i和j之间独立。如果满足条件,移除i和j之间的无向边,并更新条件变量到分离集。算法继续执行,得到修建后的骨架。(3)算法确定V-结构,从而获得CPDAG(completed partially directed acyclic graph),并根据其他规则确定剩余的无向边。PC算法在提取非时间数据中的因果关系时具有高效、可扩展性强等优点。同时在处理大规模数据时也能够得到比较准确的结果。
同时,FCI算法是PC算法的一种改进,可以处理存在未知混淆变量的情况,能够更加准确地推断DAG 结构。FCI 算法的开始步骤类似于PC 算法,构建包含无向边的完整图,然后进行迭代条件独立性测试来移除边缘。FCI 算法利用Prossible-Dsep 和Sepsets 进行条件化时,首先移除独立的边缘。对剩下的边应用10 个方向规则进行递归定向,构建适当的有向无环图。详细的步骤可以在文献[30]中找到,此文的作者详细阐述了此算法的正确性和完备性。GES(optimal structure identification with greedy search)算法首先从一个完全无向图出发,采用贪心的方式不断地向模型中添加边(依赖关系),从而得到打分函数局部最大的结构图。其次利用贪心算法逐步删除有向边,直到得分函数不再变化,得到最后的因果结构图。GES 算法结合了PC 算法的优点,在准确性和计算效率之间取得了良好的平衡,尤其适用于中等规模的数据集。PC算法与FCI算法均基于一种称为D-分离(D-Separation)[31]的方法。D-分离是图形模型中的一个基本概念,用于确定在DAG中,给定一个第三个节点集合Z,两个节点集合X和Y是否在条件下相互独立,其中这三个集合是不相交的。如果X和Y之间的所有路径都被条件集合Z所阻断,那么称X和Y在Z的条件下是通过D-分离的。
非时序线性非高斯(LINGAM)模型[32]也是一种用于因果关系推断的方法,基于LINGAM 的因果关系推断需要满足3个假设:(1)因果顺序假设,观测变量按照一定的因果顺序进行排序。在这个排序中,原因变量必须位于结果变量之前,换言之,各种观测变量的因果图模型必须是有向无环图。这是应用此方法进行因果发现最基本的假设,它指示了变量之间的因果关系的方向。(2)因果充分性假设,在模型中,变量集合中的任意两个变量的直接原因都存在于已观测的变量集合中。(3)数据生成方式假设,数据生成的过程是线性的,原因变量和结果变量之间的函数关系服从线性关系(式(2))。
其中,ei为噪声项,ci为偏置常数项。噪声项ei之间相互独立。噪声项ei服从高斯分布。
传统的面向得分的因果推断方法[33]依赖于各种局部启发式方法,根据预定义的得分函数搜索DAG。虽然这些方法在样本无限且符合某些模型假设时可能具有显著的效果,但在实验过程中由于数据有限且可能存在假设违规的情况,其表现是不令人满意的。因此,Zhu 等在文献[34]中提出使用强化学习(reinforcement learning,RL)来搜索得分最高的DAG。其将编码器-解码器模型以可观测数据作为输入,并生成用于计算奖励的图邻接矩阵。奖励预先定义的得分函数和强制保持无环性而引入的两个惩罚项。与典型的RL 应用不同,其目标是学习一种策略,并将RL用作搜索策略,最终得到的输出是在训练过程中生成的所有图中获得最佳奖励的图。其在合成数据集和真实数据集进行了实验,结果显示所提出的方法不仅具有改进的搜索能力,而且在满足无环性约束的情况下可以使用更灵活的得分函数。
面向统计学的方法利用数据分析,它试图从观察到的数据中推断出两个变量之间的相关性。然而相关性并不意味着因果关系。因此,这种方法假设通过对数据进行统计分析,可以确定变量之间的因果关系。Heckerman在文献[35]中引入了一种面向约束的贝叶斯网络的因果关系推断方法。该方法通过建立节点之间的概率依赖关系从而推断因果关系。由于面向约束的方法容易受到数据集中可能出现的错误分类决策的影响,在之后的研究中Heckerman在文献[36]中引入了面向贝叶斯的方法用于因果关系推断。将先验分布和似然函数结合起来计算后验分布,从而得到模型参数的估计值,通过参数的估计值进行因果关系推断。完全依赖于统计学的方法通常会带来误导性、偏见性和泛化性差的结果,在解决特性领域的问题时可能需要更广泛的领域知识。
2.2 面向文本语料的因果关系抽取
Morgan 在文献[37]中介绍了使用传统(非文本)数据集进行有效因果推断的技术,但将这些技术应用于自然语言数据会带来新的挑战。面向文本语料的因果关系抽取主要分为两种方法,一种是基于模式匹配的方法,一种是基于自然语言处理(natural language processing,NLP)技术和机器学习算法来从文本数据中抽取出因果关系。
2.2.1 基于模式匹配的方法
文献[38]分析了法语中具有因果含义的动词,并实现了一个名为COATIS的系统,用于抽取带有标记的显示因果关系的句子,其中句子具有“CauseVerb Effect”的结构。这意味着COATIS 系统可以识别并标记出表达因果关系的句子,其中动词在句子中起到因果关系的作用。但COATIS 系统只考虑动词作为因果连接词。因此,文献[39]在考虑动词的基础上,同时考虑一些介词(如“for”和“from”等)、状语连接词(如“so”“hence”和“therefore”等)以及子句(如“that's why”和“the result is”等)也可以表达因果关系。为了抽取带标记的因果关系,采用了模式匹配的方法,并从人工标注的华尔街日报的语料中提取带有标记的因果关系。
2.2.2 基于机器学习的方法
当今基于机器学习或深度学习模型对因果关系抽取主要从三方面进行研究。
(1)对文本进行分类。根据句子是否包含因果关系进行分类。通过文献[40]的提出,有两种方法可供选择:一种是面向知识特征的分类模型;另一种是面向深度学习的方法,通过卷积神经网络(convolutional neural network,CNN)对句子中的因果关系进行分类。这个模型能够识别明显的因果关系和隐含的因果关系,并确定因果关系的方向。而根据文献[41]的研究,通过使用平行的维基百科语料库,可以识别新的标记,这些标记是已知因果短语的变体。通过远程监督创建训练集,并利用开放类标记的特征和上下文信息的语义特征来训练因果关系分类器。
(2)对文本中包含的关系进行抽取。根据文献[42]的研究,他们将SemEval 数据集中的单词扩展为短语,并将一对一的因果关系扩展为多对多的因果关系。他们提出了一种新的约束隐藏朴素贝叶斯模型,用于提取文本中的显式因果关系。但此模型需要事先知道先验概率,因此增加了特征工程的繁琐度。而根据文献[43]的研究,他们利用生成式对抗网络(generative adversarial networks,GANs)的对抗学习特性,将带有注意力机制的双向门控循环单元网络(bidirectional gated recurrent unit,BiGRU)与对抗学习相融合,提出了一种融合对抗学习的因果关系抽取方法,从而避免了繁琐的特征工程。另外,根据文献[44]的研究,他们采用多列卷积神经网络来抽取因果关系,利用从网络文本中提取的背景知识以及从原始句子中提取的因果关系候选信息,但需要进行大量的自然语言处理(NLP)预处理工作。
(3)进行序列标注。根据文献[45]的研究,他们采用层叠条件随机场来抽取事件间的因果关系,并将因果关系扩展到跨句、跨段、多因多果等多种类型。在这个过程中,进行了大量的特征工程构建。而根据文献[46]的研究,他们利用单词级别的词向量和语义特征,通过双向长短期记忆网络(bi-directional long-short term memory,BiLSTM)标注句子中的原因、结果和因果连接词,并将标记扩展到短语,包括虚词“of”等。另外,根据文献[47]的研究,他们利用因果关系的时间特性,重新定义因果抽取为一种特殊的时间提取方法,并通过引入多层条件随机场模型将任务转化为序列标注的过程。此外,王朱君等在文献[3]中引入了面向流水线的因果关系发现方法:在流水线方式的因果关系抽取中,关系分类任务利用事件检测阶段标注出的语料。这一任务是对已标记事件的语料进行因果关系的判别。因果关系抽取是目前研究较少的领域之一。虽然因果关系分类是特殊的关系分类任务,但其主要目标是抽取出语料中实体对之间存在的关系。因此,它与抽取事件间的关系的任务类似。
此外,Blei 等在文献[48]中提出了潜在狄利克雷分配(latent Dirichlet allocation,LDA)模型,该模型是一种面向概率图的主题模型。它假设每个文档包含多个主题,每个主题又由一组词项构成。LDA 通过对文档中的词项分布和主题分布进行推断,从而得到文本的主题结构。LDA具有更好的灵活性和可解释性,能够更准确地捕捉到文本中的主题关系。Devlin等在文献[49]中提出了从文本上下文嵌入,为从文本中提取出有效信息以估计因果效应提供了有效的方法,以估计因果效应。Veitch 等在文献[50]中使用文本嵌入的方式进行因果关系推断。由于文本的维度非常高,作者在这篇文章中提出了一种对文本的因果嵌入的方式。这种方式结合了两个思路:第一是在有监督的前提下对文本进行降维;第二是进行高效的语言建模,将语言上不相关(这些信息因果上也不相关)的文本剔除,有效提高了利用文本嵌入方式进行因果推断的准确度。
在面向文本语料的因果关系发现中,存在一些混淆的因素,这些混淆因素会对因果发现的结果产生影响,因此需要在因果关系发现中加以考虑。一些学者应用面向自然语言处理(NLP)的方法发现混淆因素:一组方法应用无监督的降维方法,将高维文本数据降维为低维变量集。这些方法包括潜在变量模型,如主题模型、嵌入方法和自动编码器。Roberts等[51]以及Sridhar 和Getoor[52]应用主题模型从文本数据中提取混淆因素。Mozer 等[53]在单词袋表示上使用距离度量来匹配文本。
3 面向知识图谱的因果关系推断
知识图谱(knowledge graphs,KGs)是一种用于表示现实世界知识的图形化结构,在2012年,由谷歌正式提出[54]。其将结构化数据存储为三元组KG={(ο,γ,τ)⊆E ×R×E },其中E和R 分别代表实体和关系。目前,知识图谱可以分为四类(如图3)[55]:(1)百科全书式知识图谱;(2)常识性知识图谱;(3)领域特定知识图谱;(4)多模态知识图谱。KGs通过将实体、关系和属性等元素组织成图谱的形式,提供了对知识的丰富而精准的表达和查询[56]。而因果关系推断则是在对知识图谱中的实体和关系进行分析和推理的基础上,通过识别和分析不同实体之间的因果关系,进一步深化了对知识图谱所代表的现实世界的理解和认识。因此,知识图谱与因果关系推断密切相关,相互促进,为因果关系推断领域的发展提供了重要的支持和应用基础。
因果关系推断是针对知识图谱中已有的事实或关系的不完备性,是在现存知识的基础上推断出未知的或者新知识的过程[57],是对头尾实体之间关系的推断[58]。现有的KGs从文本中提取因果关系,面向名词短语的语言模式来表示原因和结果,例如ConceptNet[59]和WordNet[60]。KGs 表示因果关系为“原因”和“效应”实体之间的“有因果关系”“归因于”和“中介”关系。KGs 应该面向实体而不仅仅是名词短语来对因果关系进行建模,例如Wikidata 和DBpedia。面向实体的表示模型通过将因果实体与KGs中相关的效果实体或概念进行关联,从而扩大搜索空间。因果关系是一种复杂的关系,不能像现有的KGs 中表示的那样用单个链接来表示原因和效果之间的关系。现有KGs中因果关系的表示方法使得支持反事实推理变得具有挑战性。因此,需要在面向KGs 的方法中更丰富地表示和建模因果关系。
Jaimini 等在文献[61]中提出了一种因果知识图框架(CausalKG,如图4),该框架首先创建一个因果贝叶斯网络和特定领域的观测数据集,之后创建一个因果本体并用因果关系丰富领域本体,并在给定上下文中估计治疗、中介和结果变量的因果效应。其目的是将因果知识集成到知识图谱中,以改善某领域的可解释性,促进干预、反事实推理和因果推断在下游任务中的应用。其提供了对知识图谱进行因果关系推断的可能性,但是并未考虑到元数据类包含和重叠以及完整性约束等问题。因此,Huang在文献[62]中引入了CareKG 方法。CareKG 是一种新的形式化方法,用于在知识图谱中表达概念(类和关系)之间的因果关系,以及使用元数据语义实现知识图谱中的因果查询。其主要原理是通过将因果结构嵌入到元数据语义中,扩展了现有的知识表示方法,使得知识图谱中的实体和关系能够表示因果关系,并允许进行因果推断。
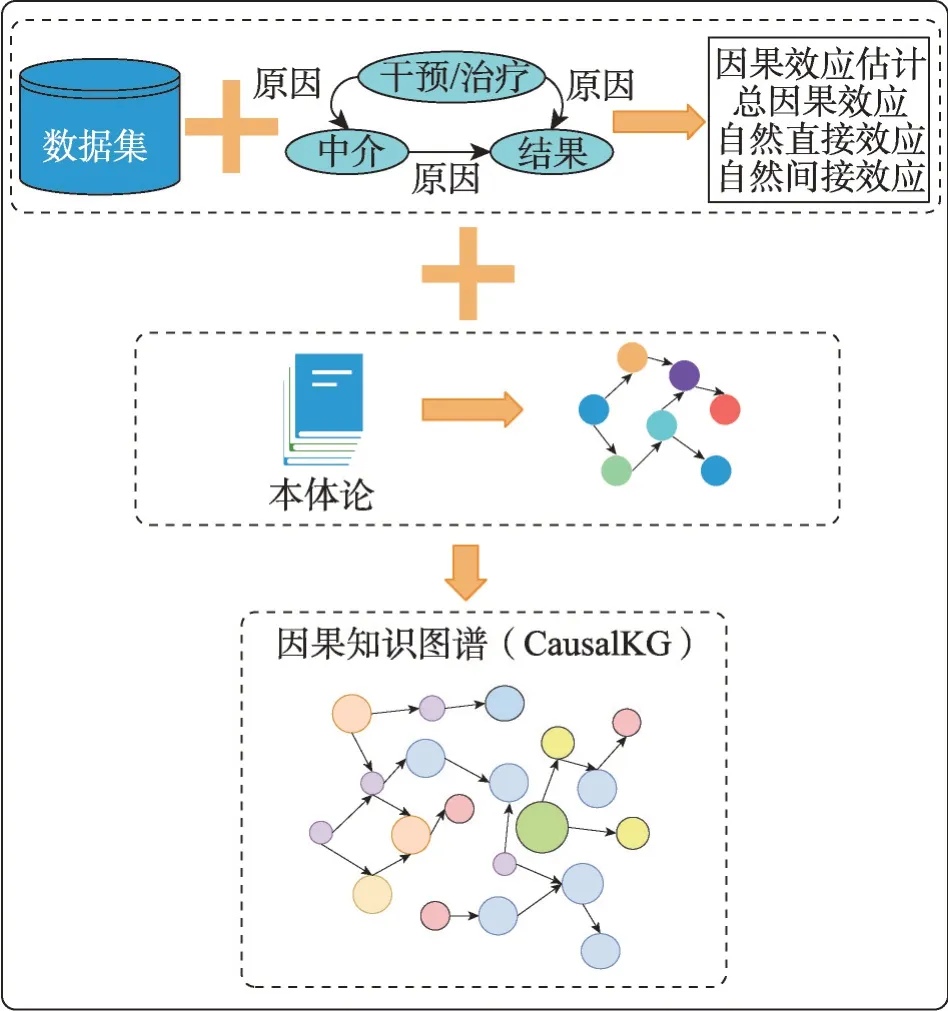
图4 CausalKG框架Fig.4 Framework of CausalKG
Munch 等在文献[63]中引入了一种利用本体论和专家知识将数据转换为关系模式的方法,利用贝叶斯网络模型学习概率关系模型。然后,提出了变量之间的联合概率分布,但这并不一定表明是因果关系。因此,Simonne 等在文献[64]中引入了一种差异因果规则的挖掘方法。差异因果规则挖掘在知识图谱中使用控制变量的概念来检查可能的因果关系,旨在比较目标类别的相似实例,研究治疗效果对目标类别及其子类的影响。并使用比值比的质量度量方法来评估因果关系的强度。此方法与实体或类别密切相关。一些方法挖掘类别中可以用于描述或分类实例的对比模式[65]。然而,这种方法不适用于计算两个特定实例之间的差异。其他方法侧重于发现在KGs中两个实例共享的属性集[66],或旨在生成实例之间差异最大的属性集[67]。这些方法不允许描述一组实例对的相似性和差异性并且缺乏可解释性。
Du 等在文献[68]中提出了一个事件图谱知识增强的可解释因果关系推断算法ExCAR。该算法首先从大规模因果事件图中获取额外的证据信息作为因果推断的逻辑规则;其次应用条件马尔可夫神经逻辑网络(conditional Markov neural logic network,CMNLN)学习逻辑规则的条件概率,并且以端到端可微的方式结合了逻辑规则的表示学习和结构学习。实验结果表明,ExCAR 的性能优于以往的基线方法并拥有良好的可解释性。
本章对面向知识图谱的因果关系推断方法和框架进行了总结。这些方法主要通过利用知识图谱中的结构信息和属性信息来进行因果关系推断。其中,一些方法采用了基于图的推理和因果推断工具,通过分析知识图谱中的实体之间的关系,识别因果路径和推断因果效应。另一些方法则将因果关系建模为图神经网络模型[69],将知识图谱作为输入,通过学习实体之间的表示来捕捉因果关系。同时,研究者们也提出了一些特定领域的因果关系推断框架,如基于知识图谱的因果推荐系统[70]。这些框架结合了知识图谱中的属性信息和用户行为数据,通过因果推断来解决推荐系统中的偏差和用户偏好建模的问题。
总体而言,面向知识图谱的因果关系推断方法和框架提供了一种利用知识图谱来理解和推断变量之间因果关系的途径[71]。这些方法和框架有助于揭示知识图谱中的因果机制,提供更深入的理解和洞察,并为相关领域的研究和应用提供了新的工具和方法。
4 面向大语言模型的因果关系推断
近来,随着GPT-4和ChatGPT进入公共大众的视野,对于大语言模型(large language models,LLMs)在因果关系推断方法的探讨也随之增多[72]。对于面向大模型的因果关系推断方法,其因果关系推断具有如下几方面的优势:(1)数据驱动的学习,大模型通过在大量文本数据上进行训练,可以学习到更多复杂的语言和语境表达方式。这使得它们能够从各种来源中自动提取因果关系的线索,而不仅仅依赖于预先构建的知识图谱。(2)上下文理解,大模型在文本中可以理解上下文,并将先前提到的信息融合到后续推理中。这对于因果关系的推断尤其有用,因为往往需要考虑事件之间的时间顺序和因果链条。(3)概念联想,大模型可以将不同领域的信息进行关联,从而找到不同领域中的因果关系。这种概念联想能力使得模型能够挖掘出传统知识图谱中可能不存在的因果关系。(4)适应多样性,大型模型在处理多种语言和领域的数据时表现良好。它们可以通过学习不同语言和文化中的因果表达方式,从而更全面地理解因果关系。
Jin 等在文献[73]中引入了一项新的任务(数据集)CORR2CAUSE,此任务可以从相关性中推断因果关系,从而评测大模型的因果推断的能力。此任务首先是在原始数据的基础上构造一个因果图,再由D-分离原理将其转化为自然语言。Jin等收集了40万样本的大规模数据集,并在6个常用的基于BERT的NLI 模型以及GPT-3.5(即CharGPT)和最新的GPT-4等模型上进行了实验(实验数据引自文献[73],如表2)。从实验结果上看,普遍认为的版本更高的或者推理能力更好的大模型在因果关系推断任务中并没有表现出正相关的结果。因为大模型在因果关系推断任务中的性能表现是随机的。
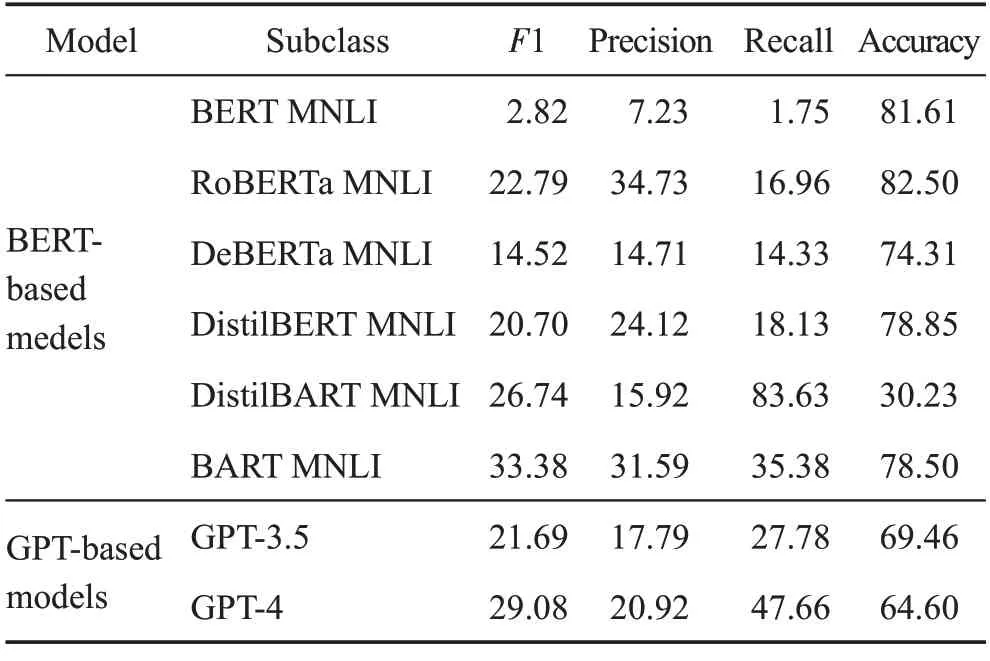
表2 大语言模型因果关系推断实验数据Table 2 Experimental data on causal inference using large language models 单位:%
5 知识图谱与大语言模型结合的因果关系推断
知识图谱与大语言模型(LLMs)结合在因果关系推断方面具有巨大的潜力。知识图谱提供了大量的结构化知识,包括实体、关系和属性,这些知识可以用于验证、补充和增强LLMs的因果推断能力。首先,知识图谱可以用于验证和补充LLMs的推理过程中的假设。LLMs 在推断中可能会产生与事实不符的错误,而知识图谱中的信息可以用来验证这些错误并提供更准确的因果关系。其次,知识图谱可以用于建模实体之间的因果关系。LLMs 可以通过学习知识图谱中的关系来理解实体之间的因果联系,并在推断中应用这些关系,从而提高因果推断的准确性。此外,知识图谱为LLMs 提供了上下文信息,帮助它们更好地理解文本中的信息。通过将文本中的实体和关系与知识图谱中的实体和关系关联起来,LLMs 可以更准确地理解文本中的因果关系,特别是在存在歧义或隐含信息的情况下。知识图谱还具有高度的可解释性,因为它们是结构化的且具有明确的语义。因此,与知识图谱结合,LLMs 可以生成更具可解释性的因果推断结果,增强了结果的可理解性和可信度。最后,知识图谱通常跨足多个领域和主题,因此结合LLMs可以扩展因果推断的应用范围,使其在各种领域中发挥更大的作用。综合而言,知识图谱与LLMs结合可以为因果关系推断提供强大的支持,促进了在知识表示和推理领域的进一步发展。
5.1 知识图谱增强大模型
大模型(LLMs)在很多自然语言处理的任务中取得了让人满意的结果。然而,LLMs在推理的过程中产生与事实不符的错误,以及在推理后得到的结果缺乏可解释性等方面并不令人满意。知识图谱可以为解决这些问题提供有力的支持。知识图谱是一种结构化的数据表示方式,其中包含了实体、关系和属性的信息。通过将LLMs与知识图谱相结合,从而可以利用图谱中的丰富信息来指导推理过程,进而提高推理的准确性和可解释性。
本节首先介绍了知识图谱增强LLMs 推理的方法。其次介绍了KGs增强LLMs的可解释性,目的是提高LLMs的可解释性。KGs增强LLMs的典型方法总结在表3中。
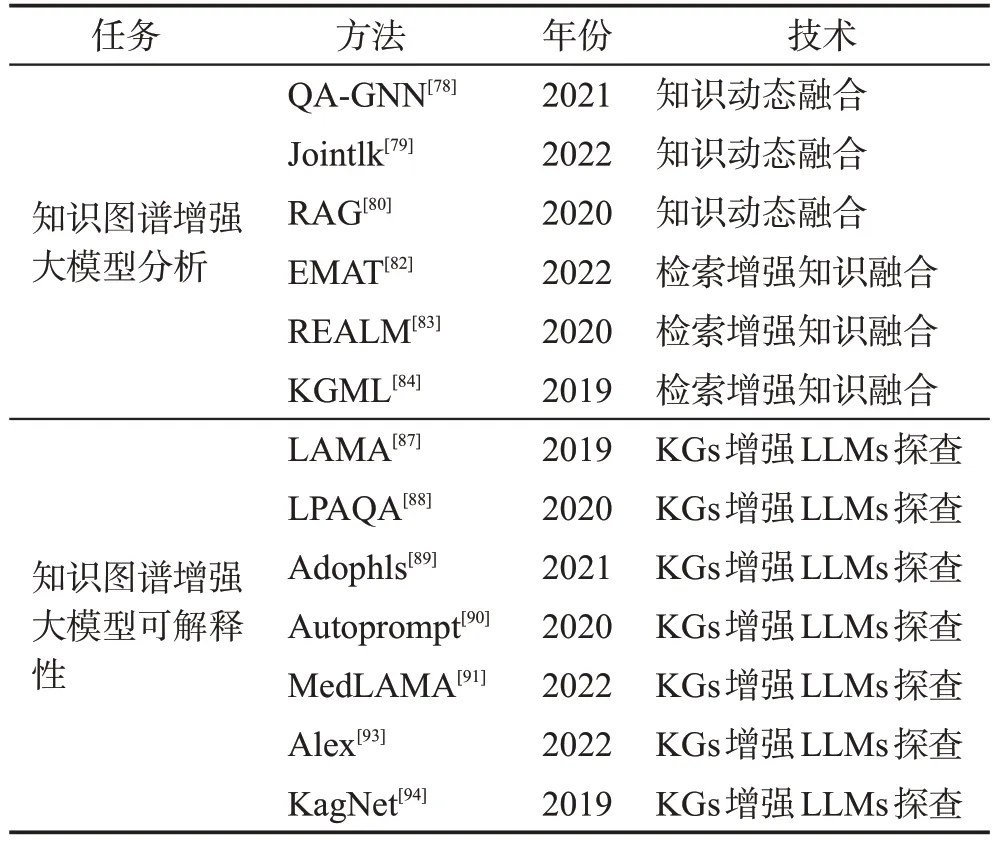
表3 知识图谱增强大模型Table 3 Large model enhanced with knowledge graph
5.1.1 知识图谱增强大模型的推理
在利用大模型进行推理的过程中,由于LLMs可能无法很好地推广到未见过的知识,很多方法致力于研究在推理过程中注入知识[74]。这些方法主要关注问答任务,因为问答任务要求模型捕捉文本含义和最新的现实世界的知识。
(1)知识动态融合。当处理文本输入和相关KGs输入时,有几种不同的方法,每种方法在文本和知识之间的交互方式上存在一些特点。一个直接的方法是双塔架构方法:这种方法使用两个独立的模块,一个处理文本输入,另一个处理知识图谱输入[75]。然而,这种方法缺乏文本和知识之间的交互。在之后的研究过程中Lin 等在文献[76]中引入了KagNet 框架,KagNet首先对输入的知识图谱进行编码,然后增强输入的文本表示。这种方法强调在文本和知识之间建立关联。Feng 等在文献[77]中引入MHGRN(multi-hop graph relation network)方法,MHGRN 则是使用输入文本的最终LLMs 的输出来指导对知识图谱的推理过程。然而,这些方法通常只考虑文本到知识的单向交互。因此,为了解决此问题,Yasunaga 等在文献[78]中引入了QA-GNN(question answering graph neural network)方法。QA-GNN 使用基于GNN 的模型,通过消息传递共同推理输入上下文和知识图谱信息。它将文本信息表示为特殊节点,并将其与知识图谱中的实体相连。然而,这些方法在信息融合方面可能受限,因为文本输入只被汇集成一个密集向量。Sun 等在文献[79]中提出JointLK(joint reasoning with language models and knowledge graphs)方法。JointLK 提出了一个具有细粒度交互的框架,通过LM到KGs和KGs到LM的双向注意机制,在文本输入的标记和知识图谱实体之间进行交互。该方法通过计算成对的点积分数来实现交互,同时动态修剪知识图谱以便后续层可以关注更重要的子图结构。
(2)检索增强知识融合。不同于上述将所有知识存储在参数中的方法,RAG(retrieval augmentation)[80]提出了结合非参数和参数模块来处理外部知识。给定输入文本,RAG 首先在非参数模块中通过MIPS(maximum inner product search)搜索相关的知识图谱,以获取多个文档。然后,RAG将这些文档视为隐藏变量z,并将它们作为额外的上下文信息馈送到由Seq2SeqLLMs 强化的输出生成器中。研究表明,在不同的生成步骤中使用不同的检索文档作为条件比仅使用单个文档来指导整个生成过程效果更好。实验结果显示,在开放域问答中,RAG要优于仅使用参数的基线模型和仅使用非参数的基线模型。RAG还可以生成比其他仅参数基线更具体、多样和真实的文本。Story-fragments[81]进一步通过添加额外的模块来确定显著的知识实体,并将它们融入生成器中,以提高生成的长篇故事的质量。MAT(external memoryaugmented transformers)[82]进一步通过将外部知识编码成键值内存,并利用快速的最大内积搜索来进行内存查询,提高了这种系统的效率。REALM(retrievalaugmented language model pre-training)[83]提出了一种新颖的知识检索器,帮助模型在预训练阶段从大型语料库中检索和关注文档,并成功提高了开放域问答的性能。KGLM(knowledge graphs for fact-aware language modeling)[84]使用当前上下文从知识图谱中选择事实,以生成事实性句子。在外部知识图谱的帮助下,KGLM 可以使用领域外的词语或短语描述事实。
5.1.2 知识图谱增强大模型可解释性
虽然LLMs 在自然语言处理的许多任务中获得了显著的成功,但是其仍然面临缺乏可解释性的困难或不足。LLMs的可解释性指的是对模型内部的运转以及推理过程的解释或理解[85]。解决这项不足将提高LLMs 的信任度。为此,研究人员对增强LLMs的可解释性进行了相关研究。研究的大致方向可分为:(1)知识图谱增强LLMs 探测;(2)知识图谱增强LLMs分析。
(1)知识图谱增强LLMs探测:LLMs探测目的是理解已经存储在LLMs 中的知识。经过规模庞大的语料库锁训练好的LLMs 通常会被认为包含大量知识。但是LLMs是采用一种隐藏的方式存储知识,这使得研究人员难以弄清楚或理解LLMs 中存储的知识。此外,LLMs存在幻视问题[86],幻视问题即生成的与事实真理相矛盾的陈述。这个问题会严重影响LLMs 的可靠性。因此,探测和验证LLMs 中存储的知识的可靠性与真实性是十分必要的。
Patroni 等在文献[87]中提出了LAMA(language model analysis)框架,其是第一个使用知识图谱来探测LLMs 中知识的工作。LAMA 首先通过预定义的提示模板将知识图谱中的事实转换为填空陈述,然后使用LLMs 来预测缺失的实体。预测结果用于评估LLMs 中存储的知识。例如,尝试探测LLMs 是否知道事实(马礼,职业,院长)。首先将事实三元组转换成一个带有对象掩码的填空问题“马礼的职业是什么?”,然后测试LLMs 是否能够正确预测出对象“院长”。然而,LAMA忽视了提示不恰当的事实。例如,提示“Mali worked as a”可能比“Mali is a by profession”更有利于语言模型预测空白部分。因此,Jiang 等在文献[88]中提出了LPAQA(language model prompt augmentation for question answering),这是一种基于挖掘和改写的方法,LPAQA 可以自动生成高质量且内容丰富的提示,从而可以更准确地评估LLMs中所包含的知识。此外,Adolphs 等在文献[89]中尝试使用示例来让LLMs理解查询,并在T-REx数据集上取得了对BERT-large 的实质性改进。相比手动定义提示模板不同,AutoPrompt[90]是一种自动化方法,此方法基于梯度引导的搜索来创建提示。与使用百科和常识知识图谱探测一般知识不同,在BioLAMA[91]和MedLAMA[92]中通过应用医学知识图谱来探测LLMs中的医学知识。Mallen等在文献[93]中对LLMs保留相对缺乏流行性的事实知识的能力进行了相关研究。他们从维基数据知识图谱中选择具有低频率点击实体的低流行性事实。然后将这些事实用于评估,结果表明LLMs 在处理这种知识时存在困难,并且扩展未能明显改善LLMs对尾部事实知识的记忆。
(2)知识图谱增强LLMs 的分析:知识图谱对于LLMs 的分析目的在回答诸如“LLMs 怎样生成结果?”或者“LLMs中的功能和架构是如何工作的?”等问题。因此,为了分析LLMs的推理过程,如Lin等在文献[94]中引入了KagNet,Yasunaga 等在文献[78]中引入了QA-GNN。通过KGs 将LLMs 生成的每个推理步骤的结果进行了实质性的支持。通过这种方式,可以通过从KGs中提取图结构来解释LLMs的推理过程。Li 等[95]研究了LLMs 如何正确生成结果。他们采用了从知识图谱中提取的事实的因果关系分析。该分析定量地衡量了LLMs 生成结果所依赖的词语模式。结果显示,LLMs生成缺失的事实更多地依赖于位置封闭的词语,而不是依赖于知识相关的词语。因此,他们声称LLMs由于不准确的依赖关系而不能很好地记忆事实知识。为了解释LLMs 的训练过程,Swamy等[96]采用了在预训练期间生成知识图谱的语言模型。LLMs 在训练过程中获得的知识可以通过KGs中的事实来揭示。为了探索隐含知识如何存储在LLMs 的参数中,Dai 等在文献[97]提出了“知识神经元”的概念。具体而言,已识别的知识神经元的激活与知识表达高度相关。因此,他们通过抑制和放大知识神经元来探索每个神经元所表示的知识和事实。
5.2 大模型增强知识图谱
ChatGPT 是OpenAI 开发的一种高级LLMs,主要用于进行类似人类的对话。在最终调整过程中,ChatGPT利用文献[98],从而增强其与人类偏好和价值观的一致性。作为OpenAI开发的一种尖端的大型语言模型,GPT-4是在GPT-3和ChatGPT等前辈的成功基础上构建的。这一发展是通过利用大规模的计算和数据规模进行训练的结果,它在不同领域表现出非凡的泛化、参考和解决问题的能力。这种进步为未来LLMs的发展提供了新的见解,同时也为构建KGs提供了新的方法和机会,以及提供了通过问答类LLMs帮助因果关系推断的新思路。
此外,GPT-4 作为一个大规模的多模态模型,具备处理图像和文本输入的能力,进一步扩展了其应用领域。这一多模态特性使其在处理复杂信息时更加全面。与此同时,ChatGPT也在信息提取[99]和推理[100]的能力方面引起了研究者的关注,为在自然语言处理领域的知识推断提供了新的机会。这些发展彼此之间存在因果关系,共同推动了LLMs 技术的前进,为在大语言模型领域的创新和探索因果关系推断开辟了新的道路。
在涉及到KGs 构造和推理的实验中[101],通常可以观察到大型语言模型(LLMs)在推理能力方面表现优于它们在KGs构造任务上的性能。对于KGs构造任务,LLMs在零样本和一次性方式上都未能超越当前最先进的模型。这一发现与之前在信息提取任务上的实验[102]结果一致,表明LLMs通常不是有效的信息提取器,尤其是对于少数镜头的信息提取任务。相反地,在KGs 推理任务中,所有LLMs 在一次性设置中表现出卓越的性能,而GPT-4甚至在零样本设置中也达到了最先进水平。这些观察结果为后续研究提供了有意义的见解,强调了大型语言模型在知识图谱领域内的适应性和性能提升的重要性。这一现象[101]可以解释如下:首先,KGs构建任务涉及到实体、关系、事件等复杂元素的识别和提取,使得任务更加复杂和困难。相比之下,KGs 推理任务,尤其是以链接预测为代表的推理任务,主要依赖于已有的实体和关系进行推理,因此任务相对较简单。其次,LLMs在推理任务中的卓越表现可能归因于它们在预训练阶段暴露于广泛的知识,这有助于更好地理解和处理与知识图谱相关的信息,从而提高了推理性能。这些发现强调了大型语言模型在增强知识图谱中的因果关系推断方面的潜力,尤其是在KGs推理任务中。
实体和关系在知识图谱中以结构化的方式进行表示,因此在面向知识图谱的因果关系推断和图谱推理等许多下游任务中得到了广泛的应用,但是传统的知识图谱通常是不完整的,且对文本信息的利用并不完全。因此,考虑通过大语言模型来增强知识图谱。LLMs对KGs进行增强是一种新颖的方法,其能够补全知识图谱的不足并提供更准确、更全面的知识因果推理,LLMs可以通过增强知识图谱的嵌入、知识图谱的完整性、知识图谱的结构等方面对KGs进行增强(如表4)。

表4 大语言模型增强知识图谱的方法Table 4 Methods for enhancing knowledge graphs using large language models
5.2.1 大模型增强知识图谱嵌入
知识图谱嵌入(knowledge graph embedding,KGE)的主要目标是将每个实体和关系映射到低维向量空间中,以捕捉知识图谱的语义和结构信息,从而可以应用于多种任务,包括因果关系推断、知识图谱推理[103]和推荐等领域。传统的知识图谱嵌入方法主要依赖于知识图谱的结构信息,通过优化定义的得分函数(例如DisMult)来实现。然而,由于结构连接性的限制,这些方法通常难以有效地表示未见实体和长尾关系。为了解决这一问题,近期的研究采用了大型语言模型(LLMs)来增强知识图谱的表示能力,通过编码实体和关系的文本描述来提高表征的质量。例如,Nayyeri等在文献[104]中使用LLMs生成全球级、句子级和文档级的表示,然后将这些表示与图结构融合为四维超复数的Dihedron 和Quaternion 表示。Huang等在文献[105]中将LLMs与其他视觉和图形编码器相结合,以学习多模态知识图嵌入,从而提高了下游任务的性能。CoDEx[106]提出了一种新型的、由LLMs强化的损失函数,通过考虑文本信息来指导KGE模型测量三元组的可能性。这种损失函数对于模型结构是不可知的,因此可以与任何知识图谱嵌入模型相结合使用。除了考虑图结构外,另一类方法则直接利用LLMs 将图数据和文本信息融合到嵌入空间中。例如,KNN-KGE[107]将实体和关系视为LLMs中的特殊标记,然后将每个三元组(h,r,t)及相应的文本描述转化为一个句子。训练结束后,LLMs中对应的标记表示被用作实体和关系的嵌入。LambdaKG[108]采用对比学习的方法,同时为了更好地捕捉图结构,对1跳邻居实体进行采样,然后将它们的标记与三元组拼接为一个句子,最后输入到LLMs中进行训练。
总的来说,这些研究展示了大型语言模型在增强知识图谱嵌入中的潜力,尤其在将文本信息与图结构相结合以更好地进行因果关系推断方面。通过利用LLMs,可以更全面地理解和分析知识图谱,为因果关系推断提供了更强大的工具和方法。
5.2.2 大模型增强知识图谱完整性
知识图谱补全(knowledge graph completion,KGC)是指在给定知识图谱中推断缺失的事实,增强知识图谱的完整性,将有利于因果关系推断。与知识图谱嵌入(KGE)相似,传统的知识图谱补全方法主要考虑和关注图结构,但并未考虑更广泛的文本信息。近来,LLMs的整合使得知识图谱补全方法能够对文本进行编码或生成事实,从而可以获得更好的知识图谱补全性能。LASS(language and structure-sensitive embeddings)[109]认为语言语义与图结构对于KGC 同等重要。因此LASS 提出了联合学习两种类型的嵌入:语义嵌入和结构嵌入。在此方法中,三元组的完整文本信息被传入到LLMs中,并分别计算h、r和t对应的LLMs 输出的平均池化。最后将得到的嵌入传入给基于图的方法,从而重建出知识图谱结构。之后,许多方法引入了掩码语言模型(MLM)的概念对知识图谱文本进行编码。MEM-KGC(meta-embedding models for knowledge graph completion)使用掩码实体模型分类机制来预测三元组中的掩码实体。Open-World KGC[110]对MEM-KGC模型进行了扩展,从而解决OpenWorld KGC的挑战,其采用一个流水线框架,其中定义了两个基于MLM的顺序模块:实体描述预测(entity description prediction,EDP)和不完整三元组预测(incomplete triple prediction,ITP)。EDP首先对三元组进行编码,并生成最终的隐藏状态,然后将其作为头实体的嵌入,传递给ITP 以预测目标实体。LPBERT(language-pretrained BERT)[111]是一种混合式的知识图谱补全方法,结合了MLM编码和分离编码。该方法由预训练和微调两个阶段组合而成,在预训练阶段利用MLM 机制对KGC 数据进行预训练。在微调阶段,LLMs 对两个部分进行编码,并采用对比学习方法进行优化。AutoKG[112]采用提示工程方法设计定制的提示语,这些提示语包含任务描述、少样本示例和测试输入,指导LLMs预测知识图谱补全中的尾部实体。这些方法结合了文本信息和图结构,使知识图谱补全更加强大和精确。同时,它们也为因果关系推断提供了有用的框架,可以用于分析知识图谱中的因果关系。
5.2.3 大模型增强知识图谱构建
知识图谱构建是指对特定领域内创建的知识进行结构化表示[113]。传统知识图谱构建主要包含实体发现、共指消解和关系提取。近来的方法探索了端到端的知识图谱构建,即可以在一步中构建完整的知识图谱,或直接从LLMs 中提取知识图谱。LRN(label-relational reasoning network)[114]考虑了标签之间的内在和外在的依赖关系。它使用BERT 对上下文和实体进行编码,并利用这些输出嵌入进行演绎和归纳推理。CrossCR[115]利用端到端模型进行跨文档共指消解,该模型在黄金提及跨度上进行了提及得分器的预训练,并使用成对得分器来比较所有文档中的所有提及及跨度之间的关系。PiVE(prompt with iterative verification for KGs enhancement)[116]提出了一个迭代验证的提示框架,利用像T5 这样较小的LLMs来纠正较大的LLMs(例如ChatGPT等)生成的知识图谱中的错误。West等在文献[117]中提出一个符号知识提取框架,从LLMs 中提取符号知识,从而增强知识图谱的结构。
近来,LLMs和KGs的协同作用引来了越来越多的关注。因此,大语言模型与知识图谱的结合可以成为因果关系推断强大的工具。知识图谱提供了结构化的知识表示,而大语言模型则能够理解和推理文本信息。通过结合两者,可以弥补知识图谱的不足,例如自动补全和扩展知识图谱、理解上下文和隐含知识、整合多模态数据等。大语言模型通过语义理解和推理能力,提供更全面和准确的因果关系推断。它可以从大规模的文本数据中学习,并通过在线学习和增量更新,不断提升因果关系推断的准确性和可靠性。这种结合为在理解和应用因果关系方面提供了一种强大的方法。
6 未来研究方向
(1)跨模态知识图谱构建的方向
跨模态知识图谱自动构建[101]是一个充满前景的研究方向,如何在跨模态知识图谱上进行因果关系推断涉及到将来自不同模态(如文本、图像、语音等)的信息融合到一个统一的知识图谱中。因此,在未来的研究方向中可以对跨模态知识图谱的表示学习进行探索:①探索如何将来自不同模态的数据转化为统一的表示,以便在知识图谱中进行一致性建模。研究关注如何捕捉不同模态之间的关联,提高跨模态表示的语义一致性。②探索多模态数据之间的融合与对齐,开发融合和对齐技术,将不同模态的数据融合到一个综合的知识图谱中。这需要解决模态差异、异构性和不完整性等问题,以实现模态之间的有效对应。③探索基于大模型的问答及推理能力,从而发现已有知识图谱上尚未关联的具有潜在关系的图节点,将信息反馈给知识图谱,进而帮助知识图谱自动更新。
(2)多元因果关系推断的方向
目前面向知识图谱的因果关系推断主要是面对两个节点建立的,即一因一果关系,但对于一对多、多对一的多元因果关系的推断效果并不理想,因此,现如今对于多元的因果关系推断还亟需进一步的研究。引入图神经网络可以解决部分的问题,但是多因果关系的推断、标注和评价体系,都需要进一步的完善和发展[118]。现实生活场景中,气压低是降水的原因,而降水又是城市交通拥堵的原因,这就是一个典型的多元关系结构[119-120]。
(3)动态知识图谱更新的方向
在面向知识图谱的因果关系推断中,动态更新知识图谱亦是一个十分重要的研究方向,动态更新知识图谱以发现图中的新的具有因果关系的节点。未来可以考虑如何根据事件触发来自动更新知识图谱。例如,从新闻、社交媒体等信息源中识别事件并将其反映到知识图谱中。其次可以考虑从时间角度对知识图谱建模,在知识图谱中引入时间维度,以更好地建模实体和关系的演化。时间感知的建模有助于揭示知识图谱中的动态模式和趋势。
(4)面向大模型的因果关系推断的可解释性方向
解释大模型的复杂因果推断结果对于应用和领域专家至关重要,因为这有助于确保结果的可理解性、可信度和有效应用。然而,将这些复杂的结果以可解释的方式呈现给非专业人士是一个具有挑战性的问题,因为这涉及到如何将高度技术性的概念和分析转化为易于理解和可操作的信息。未来可以考虑应用可视化工具提高大模型因果关系推断结果的可解释性。利用可视化工具来呈现因果推断结果,将抽象的概念转化为图表、图像等可视化形式。这有助于非专业人士更直观地理解因果关系和结果。
7 总结
“因果关系”推断作为近几年热门的研究方向,得到了越来越多的研究人员和学者关注研究。随着知识图谱的兴起,面向知识图谱的因果关系推断逐渐成为了研究热门。因此,通过阅读近年来大部分有关因果关系推断的方法和应用的文献,本文对因果关系推断进行了较为系统的综述。本文在介绍传统因果关系推断方法的同时,重点分析讨论了现如今流行的面向知识图谱和大模型的因果关系推断方法。本文对面向知识图谱和大模型的因果关系推断方法研究现状进行了深入的综述和讨论,并对这两类方法的未来研究趋势进行了展望和总结。
猜你喜欢
小学生学习指导(高年级)(2021年4期)2021-04-29
南大法学(2021年6期)2021-04-19
少先队活动(2020年12期)2021-01-14
河北理科教学研究(2020年2期)2020-09-11
高中生·天天向上(2018年7期)2018-07-23
中成药(2017年3期)2017-05-17
湘江法律评论(2016年0期)2016-06-15
领导科学论坛(2016年9期)2016-06-05
数学年刊A辑(中文版)(2015年2期)2015-10-30
中国检察官(2015年12期)2015-02-27
