
大语言模型融合知识图谱的问答系统研究
2023-10-29 04:20张鹤译韩立帆陈子睿
计算机与生活 2023年10期
张鹤译,王 鑫+,韩立帆,李 钊,陈子睿,陈 哲
1.天津大学 智能与计算学部,天津 300354
2.天津中医药大学 循证医学中心,天津 301617
问答系统(question answering,QA)能够自动回答用户提出的自然语言问题,是信息检索和自然语言处理的交叉研究方向。将知识图谱(knowledge graph,KG)与问答系统融合,正确理解用户语义是一大挑战[1]。虽然知识图谱问答能够通过对问题进行分析理解,最终获取答案,但面对自然语言的灵活性与模糊性,如何处理复杂问题的语义信息,如何提高复杂推理问答的高效性仍是研究难点[2]。
近年来,大语言模型(large language models,LLM)在多种自然语言处理任务[3-4]上取得了显著的成果,并表现出若干涌现能力[5]。InstructGPT[6]、ChatGPT(https://openai.com/blog/chatgpt/)、GPT4[7]等自回归大语言模型[8]通过预训练、微调(fine-tuning)等技术理解并遵循人类指令,使其能够正确理解并回答复杂问题。LLM 在各种自然语言处理任务上表现卓越,甚至能够对未见过的任务表现出不错的性能,这为正确处理复杂问题展示了能够提供统一解决方案的潜力。然而,这些模型都存在一些固有的局限性,包括处理中文能力较差,部署困难,无法获得关于最近事件的最新信息以及产生有害幻觉事实(halluci-natory fact)[9]等。由于这些局限性,将大语言模型直接应用于专业领域问答仍然存在诸多问题。一方面难以满足大语言模型对于硬件资源的要求;另一方面,面对专业领域,大语言模型的能力仍然有所不足。
面对专业领域的问题,大语言模型的生成结果可能缺乏真实性和准确性,甚至会产生“幻觉事实”。为了增强大语言模型应对专业领域问题的能力,很多工作采取数据微调的方式修改模型参数,从而让大模型具有更高的专业能力。然而一些文献指出这些数据微调的方法会产生灾难性遗忘(catastrophic forgetting)[10],致使模型原始对话能力丧失,甚至在处理非微调数据时会出现混乱的结果。为了应对这些问题,本文结合大语言模型与知识图谱,设计了一种应用于专业领域的问答系统。该问答系统通过将知识库(knowledge base,KB)中的文本知识、知识图谱的结构化知识、大语言模型中的参数化知识三者融合,生成专业问答结果,因此无需使用数据微调的方式修改模型参数,就能够理解用户语义并回答专业领域的问题。同时,通过采用类似于ChatGLM-6B这样对硬件资源要求较低的模型,以降低硬件对系统的约束。
另外,随着大语言模型技术的发展,认知智能范式的转变将是接下来的研究重点,如何将大语言模型与知识图谱进行有效结合是一个值得研究的课题。因此,本文参照研究问答系统的形式,进一步研究“大语言模型+知识图谱”的智能信息系统新范式,探索知识图谱与大语言模型的深度结合,利用专业性知识图谱来增强LLM的生成结果,并利用LLM理解语义抽取实体对知识图谱进行检索与增强。
本文的主要贡献有两点:
(1)提出大语言模型+专业知识库的基于提示学习(prompt learning)的问答系统范式,以解决专业领域问答系统数据+微调范式带来的灾难性遗忘问题。在提升大模型专业能力的同时,保留其回答通用问题的能力。在硬件资源不足的情况下,选择较小的大模型部署专业领域的问答系统,实现能和较大的大模型在专业领域相媲美甚至更好的效果。
(2)探索了大语言模型和知识图谱两种知识范式的深度结合。实现了将大语言模型和知识图谱的双向链接,可以将易读的自然语言转换为结构化的数据,进而和知识图谱中的结构化数据匹配,以增强回答专业性;可以将KG中的结构化知识转换为更易读的自然语言知识来方便人们理解。
本文相关代码开源在https://github.com/zhangheyi-1/llmkgqas-tcm/。
1 相关工作
随着以ChatGPT 为代表的大语言模型表现出令人震惊的能力,国内诸多厂商纷纷投入构建中文大语言模型,并涌现出了一系列的模型,如百度的文心一言、阿里的通义千问、华为的盘古大模型等。这些模型虽然具有一定的问答能力,但是正如上文所言,它们在专业领域都有着巨大的局限性。GLM(general language model)[11]是清华提出的预训练语言模型,它的底层架构是通用语言模型,在超过4 000亿个文本标识符上进行预训练。本文系统的应用示例同样是基于GLM。
在垂直领域存在很多的工作,它们主要采用的方法仍然是数据+微调的范式,即使用不同的专业数据对预训练语言模型进行微调,如P-tuning[12]、Ptuning v2[13]等,以获取语言模型在相应领域的专业能力。通过更新少量参数,减少了对硬件资源的要求。虽然减弱了微调产生的灾难性遗忘问题,但是此问题仍然存在。PMC-LLaMA[14]提出一种基于生物医学文献的预训练语言模型,通过对LLaMA模型进行微调,注入医疗知识以增强其在医疗领域专业的能力,从而提高其在医疗问答基准测试中的表现。Med-PaLM[15]针对医疗领域,提出了MultiMedQA 医学问题回答基准,涵盖了医学考试、医学研究和消费者医学问题。基于Flan-PaLM 进行指令微调(instruction tuning),在多个方面缩小了与临床医生的差距,证明了指令提示调整的有效性。ChatDoctor[16]使用医疗领域知识对LLaMA 模型进行微调获取医疗聊天模型,其根据在线医疗咨询网站的10万真实世界患者-医生对话,对模型进行了微调,添加了自主知识检索功能,通过构建适当的提示在大语言模型中实现具体检索功能。华佗(本草)[17]基于中文医学知识的LLaMA 微调模型,采用了公开和自建的中文医学知识库,主要参考了中文医学知识图谱CMeKG(https://github.com/king-yyf/CMeKG_tools)。DoctorGLM[18]是基于ChatGLM-6B 的中文问诊模型,由ChatGPT生成与医学知识内容与逻辑关系相关的若干问题构建训练数据,再通过“文本段-问题”对的方式让ChatGPT回答问题,使ChatGPT生成含有医学指南信息的回答,保证回答的准确性。从以上工作可以总结出,垂直领域的范式还是通过不同来源的数据+不同的模型基座进行微调,仍然无法避免微调的固有缺陷,而本文使用的专业知识库+大语言模型的新范式能够解决这一问题。
LangChain(https://www.langchain.com/)是一 个强大的框架,旨在帮助开发人员使用语言模型构建端到端的应用程序,可以为LLM 的开发利用提供有力支撑。它提供了一套工具、组件和接口,可以简化创建由LLM 或聊天模型提供支持的应用程序的过程。LangChain可以轻松管理与大语言模型的交互,将多个组件链接在一起,并集成额外的资源。利用LangChain,本文设计的问答系统可以轻松建立知识库与大语言模型间的链接,将知识注入到大语言模型当中。
2 系统概述
本文提出的专业问答系统基于大语言模型与知识图谱,旨在探索大语言模型+专业知识库的问答系统范式,探索大语言模型与知识图谱的深度结合,以实现专业的垂直领域问答效果,并为用户提供专业问答服务和友好交互服务。
基于以上目标系统实现了以下功能:信息过滤、专业问答、抽取转化。
为了实现这些功能,系统基于专业知识与大语言模型,利用LangChain 将两者结合,设计并实现了大语言模型与知识图谱的深度结合新模式。
信息过滤模块旨在减少大语言模型生成虚假信息的可能性,以提高回答的准确性。专业问答模块通过将专业知识库与大语言模型结合,提供专业性的回答。这种方法避免了重新训练大语言模型所需的高硬件要求和可能导致的灾难性遗忘后果。
抽取转化是指从自然语言文本抽取出知识图谱结构化数据,将知识图谱结构化数据转化为自然语言文本,是为了进一步探索问答系统新范式而设计的。一方面基于大语言模型提取出专业知识,将知识图谱结构化数据转化为自然语言文本,易于用户理解;另一方面利用知识抽取出三元组和知识图谱对比验证,可以增强大语言模型回答的专业性,同时抽取出的三元组在经专家验证后可以插入知识图谱中以增强知识图谱。除此之外,本系统还实现了用户友好的交互服务。
如图1所示,系统交互流程如下:(1)用户向系统提出问题,问题通过信息过滤后,与知识库中的相关专业知识组成提示,输入到专业问答模块中得到答案;(2)信息抽取模块从回答中提取出三元组,与知识图谱进行匹配,获取相关节点数据;(3)这些节点数据经用户选择后,同样以提示的形式输入专业问答模块得到知识图谱增强的回答。这种双向交互实现了大语言模型和知识图谱的深度结合。

图1 问答系统流程图Fig.1 Flow chart of Q&A system
总而言之,本文提出的专业问答系统通过大语言模型与知识图谱深度结合,实现了专业的垂直领域问答效果,并且提供用户友好的交互服务。系统的信息过滤模块减少了虚假信息生成的可能性,专业问答模块提供了专业性的回答,抽取转化模块进一步增强了回答的专业性,并可以对结构化数据进行解释,降低用户理解难度,同时可用专家确认无误的知识进一步增强知识图谱。这种新的问答系统范式为用户提供了更准确、更专业的答案,同时保持了用户友好的交互体验。
3 系统构建方法
本文从数据构造与预处理、信息过滤、专业问答、抽取转化四方面,以中医药方剂领域的应用为例,介绍如何构建系统。
本文针对专业领域,收集相关领域数据进行预处理,设计流程来训练一套易于部署的专业领域问答系统,并探索大语言模型与知识图谱的融合。
图2 以中医药方剂专业领域为例展示了该系统的问答流程。首先,对输入的中医药方剂相关问题文本进行信息过滤,即文本分类,判断出该文本是否与中医药方剂相关。其次,通过LangChain在知识库中检索与文本相关的知识,以提示的方式和问题一起输入大模型,如:ChatGPT、ChatGLM 等,大模型通过推理生成具备专业知识的答案。然后,对该回答进行知识抽取,从回答中抽取出三元组。将抽取出的三元组和已有的方剂知识图谱进行匹配,以验证回答的专业性,同时将知识图谱中的节点以问题的形式输入大模型,获取易读的自然语言解释,从而实现了大模型和知识图谱的双向转换。

图2 大语言模型融合知识图谱问答流程示例Fig.2 Example of question-answer process for integrating knowledge graph in a large language model
3.1 数据构造与预处理
本系统的实现需要收集整理专业数据集,以支持系统的实现。本文基于多种数据构造系统所需的数据集、知识库,并对这些数据进行数据预处理。
(1)基于已有的专业领域数据集。本文直接搜集专业领域已有的相关数据集,参考其构成,从中整理筛选出所需的数据。对于中医药方剂领域,参考MedDialog[19]、CBLUE[20]、COMETA[21]、CMeKG 数 据集,整理并构建相关专业数据。相关介绍如表1所示。

表1 相关专业数据集Table 1 Related professional datasets
(2)权威数据。权威数据从专业书籍或权威网站收集。这部分数据来自于相关领域的专业书籍和权威网站,用于构建知识库,为大模型的回答提供专业知识支撑。对于中医药方剂领域,主要基于方剂学等专业书籍构建了中医药方剂专业知识库,同时从NMPA(国家药品监督管理局)、药融云-中医药数据库群、TCMID中医药数据库、中医药证候关联数据库等专业权威网站收集中医药方剂领域的相关数据知识。
(3)问题数据。问题数据用来训练信息过滤模型。由于某些专业领域存在问题数据缺失的情况,本文设计了一种基于提示的方法,使用大模型生成问题数据(图3 所示)。首先从相关数据中选择一条数据用来生成提示,将提示输入大模型生成一条数据,重复以上述步骤,直到相关数据被选完。

图3 基于LLM生成数据方法Fig.3 Method for generating datasets based on LLM
算法1基于LLM生成数据
输入:相关文本D,LLM(如ChatGPT)的API_KEY。
输出:基于LLM生成的问题数据R。
其中D表示所有的相关数据,d表示一条相关数据,R表示所有生成的问题数据,r表示一条生成的数据。create 根据用户提供的API_KEY 创建与LLM(如ChatGPT)的链接,select表示选择一条数据,P表示根据数据生成合适的提示,llmresult表示获取LLM 生成的回复,abstract 表示从生成回复中提取出问题数据并进行汇总。
在中医药方剂领域,如表2中P1所示,将提示P1输入LLM 中,生成相关问题。中医药方剂领域问答系统的问题数据,80%来自于现有的问答数据集,如MultiMedQA[15]、CMRC2018[22]、CMedQA-System[23]、cMedQA2(https://github.com/zhangsheng93/cMedQA2)等,本文从中整理相关问题,并按照是否为中医药方剂专业领域添加标签。20%的中医药方剂相关问题使用大模型生成的方式构建。

表2 提示示例Table 2 Prompt example
(4)激活知识抽取能力的微调数据。如图3 所示,使用基于提示的方法,通过让LLM 回答问题,生成合适的微调数据。提示如表2 中P2所示,结合信息抽取示例,将P2输入LLM 生成25 条微调数据,利用这些数据微调大模型以激活大模型的信息抽取能力。
系统使用(1)、(2)中的数据构建知识库,知识库支持多种形式的数据,包括txt、html、pdf 等格式。使用(3)中的数据训练信息过滤模型。使用(4)中的数据训练知识抽取模型。
3.2 信息过滤
针对专业领域的问答,大语言模型无需回答其他领域的问题,为此本系统添加了基于BERT(bidirectional encoder representations from transformers)[24]的文本过滤器对问题进行过滤,以限制大模型可以回答的问题范围。
其他模型在面对专业领域的边界问题或交叉问题时往往会产生微妙的幻觉事实,生成错误文本。尽管使用微调的形式同样也可以使得大模型具备一定的问题甄别能力,但是这种能力在面对与微调数据集中相似的其他问题时,仍然会被迷惑,甚至对于原本可以正确回答的问题也会生成错误的答案。因此需要单独设计文本过滤器以对信息进行过滤。
假设可输入大模型的所有的问题集合为Q,大模型在某一专业领域可以回答的问题集合为R,可以生成专业回答的问题集合为D,显然有Q>R>D。使用微调方式限制将使得R→D,会让模型回答能力减弱1)>表示包含关系,若A>B,则A →B 表示集合A 的范围向集合B 的范围缩小。。而使用过滤器的形式,使得Q→R,将尽可能保证询问的问题在R的范围之内,虽然会有部分R之外的数据进入大模型,但是由于本文设计的专业增强问答系统仍然保留一定的通用能力,对R之外的问题也可以进行无专业验证的回答。
信息过滤将保证本系统尽可能回答在系统能力范围以内的问题,以减少产生幻觉事实的可能。
训练过程如图4所示,将训练数据输入BERT,再将BERT的结果输入全连接层(fully connected layer,FCL)得到对本文的分类结果[CLS]。根据数据集中的标签,训练时只需要更新全连接层的参数即可。

图4 信息过滤模型的训练过程Fig.4 Training process of information filtering model
一般来说使用BERT进行文本分类任务,会采用BERT 结果的分类词向量H,基于softmax 做一个简单的分类器,预测类别的标签L的概率:
这里W是分类任务的参数矩阵,最终通过最大化正确标签的对数概率来微调BERT 和W中的所有参数。将其修改为使用全连接层得到每个标签的概率:
训练时输入全连接层的向量维度为768,具有两个隐藏层,维度分别为384、768,输出维度为类别个数,这里是一个二分类任务,因此为2。最终选择概率更大的标签作为分类的结果[CLS]。在中医药方剂学领域中,[CLS]为问题是否与中医药方剂相关,通过过滤问题,减少生成幻觉事实的可能,并同检索结果一起判断能否进行专业回答。
3.3 专业回答
为了使得大模型知识图谱问答系统的回答更具备专业性,本文通过提示的方式注入知识库中专业知识,增强回答的专业性。通过检索知识库,大模型可以回答其本身能力之外的专业问题,使得大语言模型支持的问题边界扩大。这种方式和引入专业数据的微调方法对比,无需重新训练就可以部署一个专业领域大语言模型。
如图5 所示,在中医药方剂领域,本文使用LangChain+LLM,生成更具备专业知识的回答。本系统基于LangChain 在知识库中检索与问题相关的专业知识,然后专业知识和问题文本一起构成P4(表2 所示)输入LLM,最终得到答案文本。这里可以选择使用ChatGLM-6B、ChatGPT等作为大模型。
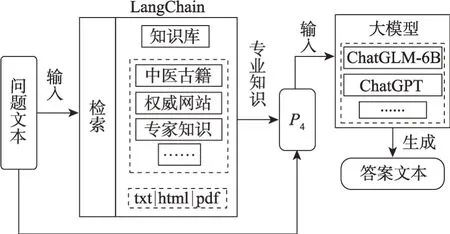
图5 基于LangChain+LLM的问答流程图Fig.5 Question-answer flow chart based on LangChain+LLM
假设知识库中的第i个文件为Fi(i=1,2,…,n),基于LangChain 进行检索会将各个文件中的文本进行分块,Dij(i=1,2,…,n;j=1,2,…,m)表示第i个文件的第j个文本块。然后对每一块文本建立向量索引Vi(i=1,2,…,n×m),在检索时将问题文本向量化,得到问题文本向量Q,最后通过向量相似度计算出和Q最相似的k个向量索引,并返回对应的文本块。将匹配到的专业知识文本D和问题文本以P4的形式拼接,最终输入LLM 中得到大模型生成的专业回答。该过程的伪代码如下所示:
算法2向量化索引检索问答
输入:问题文本q,知识库文件f。
输出:大模型的回答文本result。
算法中q表示问题文本,f表示知识库文件,d表示知识文本块,Q表示问题文本向量,V表示文本块的向量索引,split表示划分文本块的过程,trans表示从文本转化为向量,de_trans表示从向量转化为文本,score 将返回k个最相似的向量索引,model(P4(q,dk))表示将问题文本和专业知识文本以P4形式输入大模型ChatGLM-6B。
3.4 抽取转化
本节探索大语言模型和知识图谱的深度结合。大模型的回答是易读的自然语言数据,而知识图谱的数据是结构化的知识。为了将两者交互结合,需要实现两者的相互转换:(1)实现对自然语言的结构化;(2)可将结构化的知识转换为自然语言。前者是信息抽取的任务,后者可以通过提示的方式输入大模型转换成自然语言文本。
以中医药方剂领域的应用为例进行分析:
(1)对于信息抽取,使用P-tuning v2 微调的方式强化LLM 的信息抽取能力。具体来说,在语言模型的每一层上将l个可训练的注意力键和值嵌入连接到前缀上,给定原始的键向量K∈Rl×d和值向量V∈Rl×d,可训练的向量Pk、Pv将分别与K和V连接。注意力机制头的计算就变为:
其中,上标(i)代表向量中与第i个注意力头对应的部分,本文通过这种方法来微调大语言模型,第3.1 节描述了如何构建微调数据。如图1所示,将大模型生成的自然语言答案文本,输入经过信息抽取增强微调后的大模型中,提取出结构化的三元组信息,并与知识图谱进行匹配,在专家验证后,可以存储到方剂知识图谱中。
(2)对于结构数据的易读化,使用提示的方式(提示构造如表2的P3所示),将知识图谱相关节点转换为P3后,再将P3输入大模型得到自然语言的回答。
本文尝试将专业知识图谱与大语言模型结合,利用大模型生成自然语言回答,抽取出专业的结构化知识,并和已有的专业方剂知识图谱进行知识匹配,以进行专业验证。同时可以将知识图谱中的结构化知识转化成易读的自然语言。
4 实验
本章为系统的效果提供了实验证据,分为三部分:(1)不同模型回答效果展示;(2)性能评估;(3)大语言模型和知识图谱的相互转换。本文实验模型采用ChatGLM-6B 在MindSpore1.10.1 环境下,基于Ascend910硬件运行。
4.1 不同模型回答效果展示
表3 是不同模型对相同中医药方剂相关问题的一些回答结果。ChatGPT没有开源,也没有透露任何训练细节,因此无法保证评估数据是否被用于训练它们的模型,从而它们的结果在这里只能作为参考,而不应该被用来进行公平的比较[14]。

表3 不同模型结果对比Table 3 Comparison of results of different models
对于问题1,由于知识库中存在相关的知识,专家问答系统可以进行专业回答,ChatGLM 则无法生成方剂学的专业回答,相比于ChatGPT的回答,专家问答系统更精细,不仅有方剂名称,适用范围还有具体的方剂信息。对于问题2,此问题是数学和方剂学的交叉问题,知识库中并没有相关信息,直接由ChatGLM 回答,会生成幻觉事实。专业问答系统可以判断无足够专业知识进行回答,进而避免生成幻觉事实。这些结果表明,本文设计的系统具备良好的专业回答能力,同时也能对自身无法专业回复的问题表示拒绝。专业问答系统仍然保留ChatGLM本身的能力,能对一些绕过信息过滤的问题进行回答,这种能力能够保证在面对专业领域边界问题或交叉问题时可以进行较好的回答。
4.2 性能评估
为了评估系统的性能,本节从主观评估与客观评估两方面验证了在中医药方剂学领域的专业效果,并通过消融实验验证了各个模块都具备相应的提升系统性能的能力。
4.2.1 主观评估
本实验请三个中医药方面的专家对不同模型的回答进行评估,用以验证系统效果。将100个问题分别输入三个不同的模型生成答案,然后把来自不同模型的每个问题的结果,交给专家进行评估,比较对于同一个问题,专家更喜欢哪一个模型的回答。如图6所示,横坐标表示不同的专家,纵坐标表示最满意问题所占问题总数的比例。模型1 是本文所提专业问答系统,模型2表示ChatGLM,模型3表示ChatGPT。由于是对比三个模型的结果,因此只需专家最满意比例大于总体1/3 就可以证明专业问答系统的回答更好。专家们对模型1 的回答结果最满意总个数分别是37、42、42,都超过总问题个数的1/3,因此本文设计的系统更受专家喜欢。
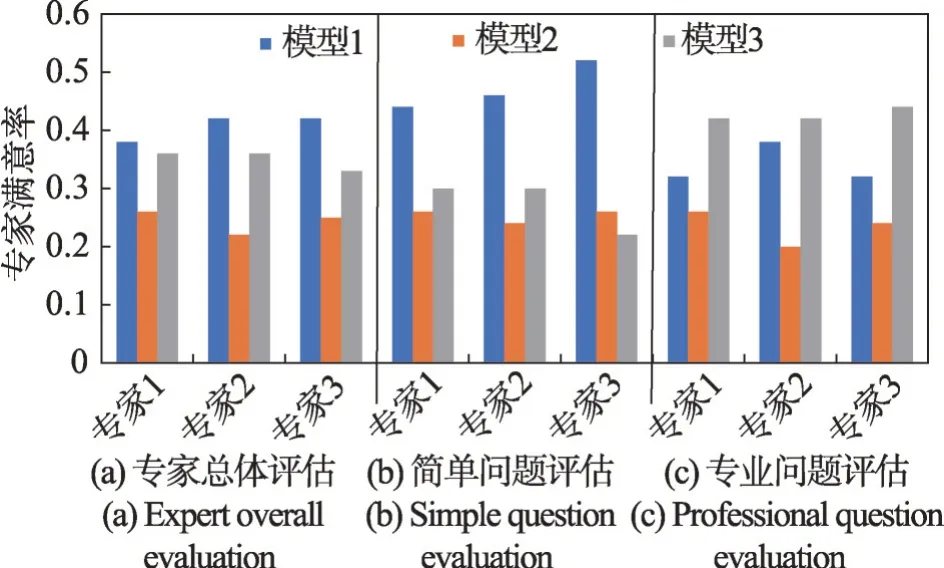
图6 专家评估Fig.6 Expert evaluation
实验过程中,问题被分为两类,一种是普通问题,另一种是专业问题,两者分别有50个问题,共100个问题。普通问题是相对常见的问题,对专业知识需求较低;专业问题是考验式问题,类似于考试题,回答专业问题需要具备更多的知识。专家总体评估如图6(a),简单问题评估如图6(b),专业问题评估如图6(c)。
在图6(a)中,模型1 取得了最高的满意率,可以看出本系统提出的方法更受中医药专家的喜欢。对于简单问题,如图6(b)所示,远远优于其他两个模型,对于专业问题,如图6(c)所示,虽然ChatGPT 取得最优的结果,但是模型1相对于模型2仍更受专家喜欢。相对于其他模型,模型1 的回复更加详细,会补充更多专业知识。但是当问题难度上升,回答问题需求知识更多,当知识库中没有这部分知识时,模型1 的回答专业性就不如ChatGPT。这可能是因为ChatGPT 训练时所用的语料中涉及专业问题,所以ChatGPT在回答专业问题时更具备优势。
结果表明,总体上本文所提系统更受专家喜欢。虽然面对复杂问题时,表现不如ChatGPT,但是相对基线模型ChatGLM-6B仍保持更高的满意率,表明了本文所提系统的有效性。
4.2.2 客观性能评估
为了客观验证系统的问答性能,让系统回答专业相关的选择题,可以客观验证系统性能。此实验收集并整理了50 条方剂学不同难度的选择题,让不同模型进行回答,计算不同模型对不同问题的得分情况,以评估系统的客观性能。
实验过程中,问题按照问题的难度分为三类,分别为简单题(simple question,SQ)、中等题(medium question,MQ)、困难题(difficult question,DQ)。准确率以正确问题个数除以总问题个数进行计算。
在表4中,小括号中的数字表示正确回答问题的个数。从其中结果看,显然随着问题难度提升,回答的正确率依次下降。对于平均正确率而言,专业问答系统显著高于ChatGLM-6,略低于ChatGPT。说明专业问答系统能够显著提升大模型的专业能力,甚至能够达到和ChatGPT相媲美的结果。
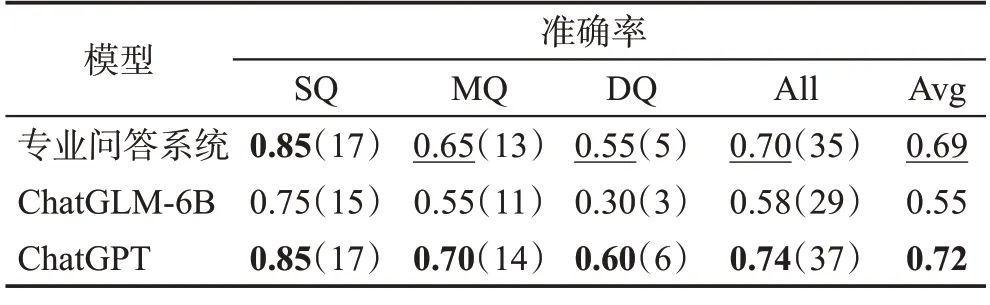
表4 选择题客观性能评估Table 4 Objective evaluation of multiple choice question
结果表明,和ChatGLM-6B相比专业问答系统答对题目的数量更多,从客观上验证了系统的性能。
4.2.3 消融实验
本文进行消融实验,进一步验证信息过滤、专业问答、知识抽取与知识图谱相互转换三个模块的功能。
对于信息过滤模块而言,其作用并非是增强回答专业性,而是对问题进行过滤,减少生成幻觉事实的可能性,因此为了验证其能力,需要使用问题数据集单独进行测试;对于专业问答模块,其本质是利用知识库增强回答专业性,因此对该模块需要测试性能;对于知识抽取与知识图谱相互转换模块,可以通过去除和知识图谱交互重新生成答案部分,以验证增强回答专业性,同样需要测试性能。因此在消融实验中,对信息过滤模块单独使用问题数据集验证其信息过滤能力,对后两者使用客观性能评估的数据集验证性能提升。
实验过程中,为了验证信息过滤模块的能力,将输入的问题按照相关程度划分为三种类型的问题,分别为无关问题(completely unrelated question,CUQ)、部分相关问题(some related question,SRQ)、完全相关问题(completely related question,CRQ)。对于部分相关问题,是在无关问题的基础上增加相关的信息或在相关问题的基础上增加无关信息,作为干扰。通过将无关信息和相关信息混合的方式制造部分相关问题,可以验证信息过滤的鲁棒性。准确率使用正确过滤问题个数除以问题总个数进行计算。
在表5 中,RIF(remove information filter)表示去除信息过滤,RKB(remove knowledge base)表示去除知识库,RKG(remove knowledge graph)表示去除知识图谱交互。去除信息过滤模块后,专业问答系统可以通过合适的提示机制进行信息过滤,从结果看,专业问答-RIF的过滤准确率低于专业问答系统的过滤准确率,说明了去除信息过滤模块后系统的信息过滤能力有所降低,验证了信息过滤模块的有效性。对于简单问题的回答,专业问答-RKB的准确率与ChatGLM-6B 基本相同,专业问答-RKG 的准确率与专业问答系统基本相同,说明对于SQ,大模型本身具备一定的回答能力,其增幅主要依靠知识库,知识图谱进行交互增强不明显。对于困难问题,专业问答-RKB和专业问答-RKG的准确率低于专业问答系统,高于ChatGLM-6B,可见对于MQ、DQ,通过知识图谱进行交互发挥一定的作用,猜测这可能是因为知识图谱能够注入相关知识或辅助大模型进行推理,激活大模型的边缘知识。总体来说RKB、RKG都会使得专业问答系统的回答准确率下降,并且高于ChatGLM-6B的准确率,由此验证了系统各个模块均发挥作用。
对于简单问题知识图谱作用不明显,这是由于回答问题相对简单时,所需要知识是孤立的,无需通过深度推理得出,当不存在相应知识时,就无法通过知识图谱辅助推理得到正确的答案,因此知识图谱交互对回答的增强不明显。
4.3 大语言模型和知识图谱的相互转换
本实验通过展示系统的用户界面截图,体现了系统用户交互服务,同时还体现了本文所设计的系统具备的大语言模型与知识图谱之间的交互能力。
本文实现了知识图谱与大模型的双向链接,探索了大语言模型和知识图谱的深度结合。用户向系统提出问题,系统进行回答,并通过图的方式,展示知识图谱相关数据节点,用户可以选择其中相关节点,再次输入大模型得到更多的解释。
图7 来自系统界面截图,展示了系统问答、图谱数据易读化、自然语言回答结构化的效果。左上角的问答截图是用户向系统发出提问,系统生成答案,然后对答案进行结构化,生成三元组,并和已有的知识图谱进行匹配后,展示出右上角的知识图谱节点。如图7 右下角所示,用户可以选择相关节点,系统将其转化为问题再次生成答案,最终两个答案相结合就是系统的回复。这样既为用户提供了良好的交互服务,也实现了大语言模型与知识图谱的双向交互。

图7 中医药方剂大模型回答与知识图谱相互转换Fig.7 Mutual transformation between large model answer and knowledge graph of traditional Chinese medicine formulas
在中医药方剂领域,系统生成的回复有一定的参考价值,但是由于中医药方剂领域本身的一些特性,系统还具有很多可以改进的地方,比如加入中医如何开方的数据和相关问诊的多模态数据,如患者的舌苔、脉象、气色等。该系统针对不同的领域,需有相应的调整。
5 结束语
在大模型时代,激活大模型中的“涌现”能力并将其适配到具体领域场景是未来在垂直领域建立竞争力的关键,其中高质量领域数据与知识不可或缺。垂直领域的数据与知识可以有两种利用方式:(1)在LLM预训练过程中,注入垂直领域知识并进行相应架构与工程的优化,或者使用微调方法修改模型参数向其中注入专业知识;(2)结合垂直领域数据与知识图谱,设计合适的提示机制,充分激发基座大模型的能力,实现垂直领域任务能力的“跃迁”。本文从第二种方式开始,研究大语言模型+专业知识库的问答系统范式,探索将专业知识图谱与大语言模型深度结合,实现了大语言模型与知识图谱的双向交互,同时实现了文本知识库、知识图谱、大语言模型三种知识的融合。
大模型知识图谱问答系统是对大模型与知识图谱结合的探索工程,仍然存在着很多值得完善的部分。在该系统中目前仅实现了在中医药方剂领域的应用,其设计思路还可以应用在不同的领域,如法律、金融、教育等垂直领域。除此之外,在系统效果的验证方面还缺少一项标准的评估系统专业能力的基准,因此在后续工作中,将开发一个专门用于评估垂直领域问答系统性能的基准。
猜你喜欢
少先队活动(2020年12期)2021-01-14
青年生活(2019年23期)2019-09-10
制造技术与机床(2019年6期)2019-06-25
中成药(2017年3期)2017-05-17
中国交通信息化(2016年9期)2016-06-06
领导科学论坛(2016年9期)2016-06-05
图书馆研究(2015年5期)2015-12-07
中共南宁市委党校学报(2015年4期)2015-02-28
中国音乐教育(2014年7期)2014-02-06
杭州科技(2013年5期)2013-03-11
