
图神经网络在知识图谱构建与应用中的研究进展
2023-10-29 04:20许鑫冉王腾宇
计算机与生活 2023年10期
许鑫冉,王腾宇,鲁 才
1.电子科技大学 资源与环境学院,成都 611731
2.中国石油天然气股份有限公司塔里木油田分公司 勘探开发研究院,新疆 库尔勒 841000
3.电子科技大学 信息与通信工程学院,成都 611731
知识图谱的概念最早在2012 年由Google 提出,随后在工业界和学术界掀起了热潮。在数据库技术和Web应用的快速发展下,数据呈现了爆炸式增长,并产生了大量有价值的知识,传统的数据库技术已无法满足现有市场环境中不断扩大的应用需求。大量研究人员在知识工程的基础上,通过引用语义上有意义的元数据,将实例数据同上下文结构集成,从非结构化和半结构化数据中提取出有用的知识信息[1],推动了知识图谱在人工智能领域的应用。近年来,开发了大量有意义的大型知识库,如YAGO(yet another great ontology)[2]、Freebase[3]、DBpedia[4]等,存储公共知识的结构化信息。
但是,由于知识图谱系统存在数据稀疏问题,使得大规模知识图谱计算和管理存在困难,为了解决该问题,提出了知识图谱嵌入的思路,将知识图谱的实体和关系嵌入到低维连续的实体向量空间中,并参与知识图谱构建。知识图谱构建的关键在于信息抽取[5]和知识合并与加工[6]两部分。信息抽取是知识图谱中基础的操作,从非结构化和半结构化数据中提取知识。同时,知识图谱总是不完整的,常常存在很多缺失信息,需要对知识图谱的信息融合和加工,在此基础上提出了链接预测[7]、实体对齐[8]、实体消歧[9]、知识推理[10]等任务。
图神经网络(graph neural network,GNN)作为深度学习的热点之一,归结为其强大的数据处理能力。首先,图神经网络扩展了现有的马尔可夫链路模型和递归神经网络模型方法来处理图域中的数据,保留了二者的特征,能够处理现实中大多数可用的数据类型,实现将一个图及其节点映射到一维的欧几里德空间[11];其次,GNN模型能够保留图上的结构信息,通过消息传递规则来捕获图上的依赖关系,达到聚合邻域信息迭代更新的目的[12]。近年来,很多研究人员尝试将图神经网络应用到知识图谱处理中,借助其强大的处理结构化数据的能力,提高知识图谱在构建和推理的准确性和鲁棒性,并应用于下游任务中,如推荐系统[13]、自然语言处理[14]、计算机视觉[15]等,提高在下游应用场景中的效率。
近几年的综述文章,侧重于对早期的知识图谱嵌入[16]和应用[17]进行全面的总结,或者针对图神经网络[18]现有的方法进行全面论述,介绍各个图神经网络模型,较少涉及图神经网络在知识图谱公开数据集上进行广泛且深入的研究。譬如,文献[19]图神经网络应用于知识推理进行了综述,按照图神经网络模型对知识推理研究进行了分类,并着重介绍了知识推理在医学、军事等领域的应用;文献[20]对2019 年到2022 年知识图谱的构建相关工作进行了综述,梳理了知识抽取、知识融合和知识推理三类知识图谱构建的研究工作,并进行了分析和讨论;文献[21]对知识图谱增强的图神经网络进行了研究;文献[22]面向图神经网络的知识图谱嵌入研究进展进行了综述,将模型框架分为图卷积网络、图神经网络、图注意力网络和图自编码器的知识图谱嵌入研究,分析了图神经网络参与知识图谱嵌入研究的优势;文献[23]开放领域知识图谱问答研究综述,将知识图谱的问答系统分为基于规则的知识图谱问答和基于深度学习的知识图谱问答系统,对2021 年以前的问答系统进行了深入研究。其余知识图谱相关的研究可以归纳为两类(表1):知识图谱构建研究工作(知识图谱表示学习、实体对齐、知识推理等)[24]和知识图谱应用相关研究(推荐系统、问答系统等)[25]。
虽然上述已有诸多文献对知识图谱相关工作进行研究[26],但仍缺乏图神经网络参与知识图谱构建广泛而又系统的研究,深入且详细的梳理工作。与其他综述不同的是,本文主要关注图神经网络参与知识图谱构建和应用中的研究,对近三年的文章进行深入分析,并提出了一些现存的问题和未来的研究方向,本文脉络框架如图1所示。本文面向图神经网络参与知识图谱构建工作进行了系统的总结,并涵盖了近几年的最新研究。本文的贡献总结如下:
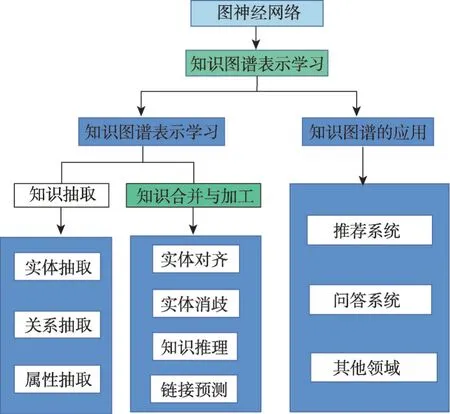
图1 基于图神经网络的知识图谱构建及应用Fig.1 Construction and application of knowledge graph based on graph neural network
(1)对知识图谱构建中的相关任务进行分类整理,类别包括知识抽取中的实体、关系和属性抽取,以及知识合并与加工中的链接预测、知识推理、实体对齐等,探索了基于图神经网络的最新研究方法;
(2)对链接预测模型文献进行了系统的分类整理,类别包括图卷积网络模型、图注意力网络模型、子图提取模型和曲率空间模型,阐述并比较了不同链接预测方法的原理及优缺点;
(3)梳理了基于图神经网络方法在知识图谱应用方面的相关文献和探索了本研究未来发展前景。
1 知识图谱表示学习
知识图谱表示学习(knowledge graph embedding,KGE)旨在将知识图谱映射到低维连续向量空间中,并为下游任务提供统一的底层表示。现有的知识图谱表示学习模型分为四类,分别包括基于翻译模型、语义匹配模型、神经网络模型和图神经网络模型,如表2 所示,列举了常见的知识图谱表示学习模型,并给出了各个模型的优缺点。
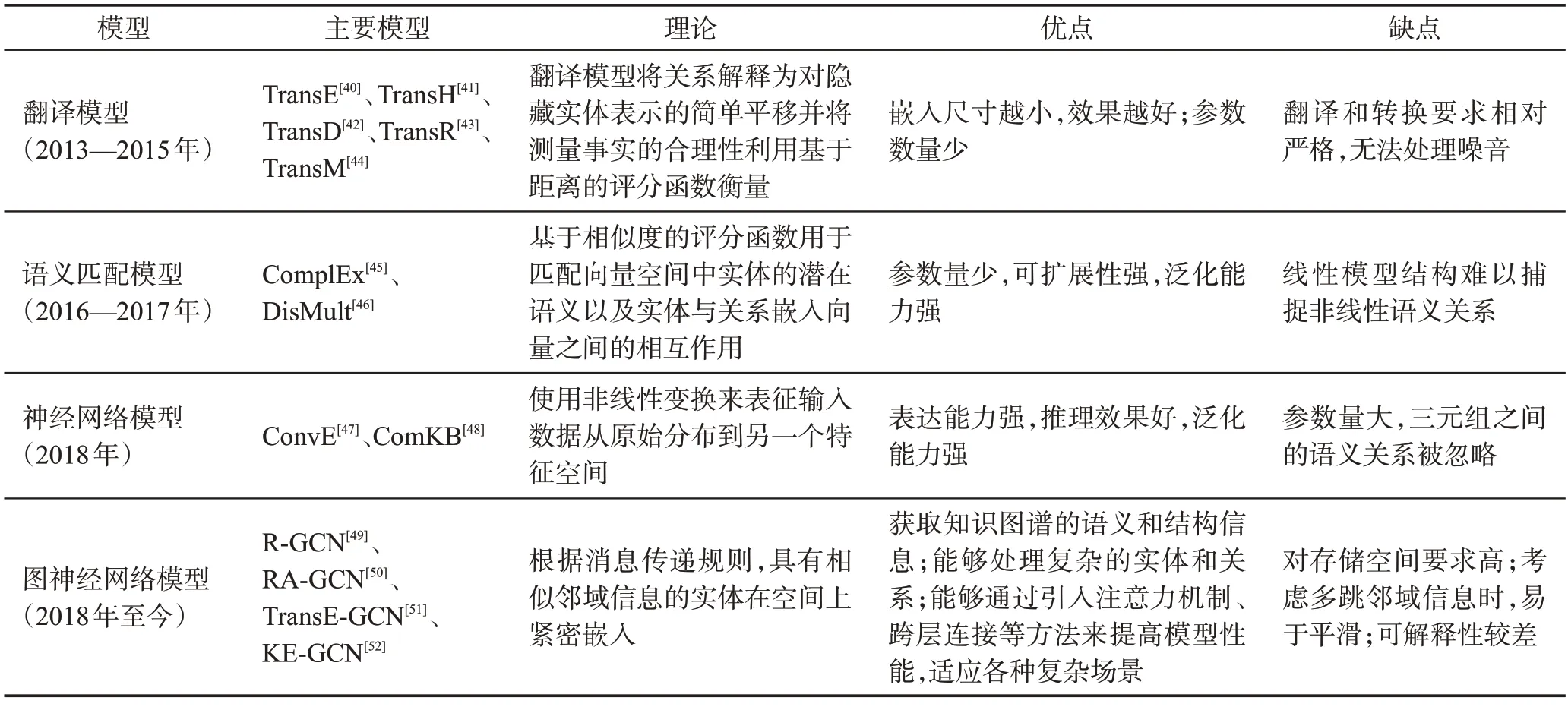
表2 知识图谱表示学习模型Table 2 Knowledge graph representing learning model
翻译模型将关系解释为对隐藏实体表示的简单平移并试图找到与实体平移相关的实体的低维向量表示。TransE[40]是最常见的翻译模型之一,TransE模型将关系表示为实体之间的平移操作,即将头实体与关系向量相加得到尾实体。它的目标是最小化平移后的头实体与尾实体之间的距离,其中实体和关系都被建模成同一空间中的向量,但是在对于一对多和多对多关系时表现不佳,为此提出了一系列扩展模型,如TransH[41]、TransD[42]、TransR[43]、TransM[44]等。
语义匹配模型使用张量积来捕获丰富的交互,试图将实体的潜在语义与关系联系起来。如Compl-Ex[45]和DistMult[46]等。ComplEx模型扩展了DistMult模型,使用复数向量表示实体和关系。它通过在实体和关系的复数向量之间进行乘法操作来计算得分,可以更好地捕捉实体和关系之间的多样性和对称性。上述嵌入方法通常不适用于巨大的KG(knowledge graph),因为它们需要增加KG 嵌入的维度以增强其表现力。
神经网络方法使用不同的神经网络模型从纯嵌入中获得表达表示,具体来讲ConvE[47]和ComKB[48]是一种基于卷积神经网络的知识图谱表示学习模型,它将实体和关系映射到二维矩阵中,并通过卷积操作来计算实体和关系之间的语义关系,能很好地应对参数量大的问题。
近年来,图神经网络(GNN)因其强大的特征提取能力被广泛应用于知识图谱嵌入,大多数基于GNN的知识图谱表示学习模型使用聚合运算从三元组中提取潜在信息,通过使用KG中的拓扑结构来学习强大的嵌入[49]。GNN通常通过聚合和传播图中的节点特征来更新节点表示。与传统嵌入不同,GNN能够进行端到端的监督学习,获取知识图谱的语义和结构信息,并通过模型的自由参数共享学习的知识,如图2 所示,为图神经网络模型及其隐藏层数据嵌入信息。这使它们能够获得更具表现力的表示并降低嵌入的维数,同时减少性能下降,可以执行各种分类及推理任务;其次图神经网络能够处理知识图谱中实体和关系之间复杂的关系结构,有效地捕捉语义特征和结构信息;最后图神经网络适应性强,能够通过引入注意力机制、跨层连接等方法来实现模型性能的提升,并能够适应复杂的应用场景。
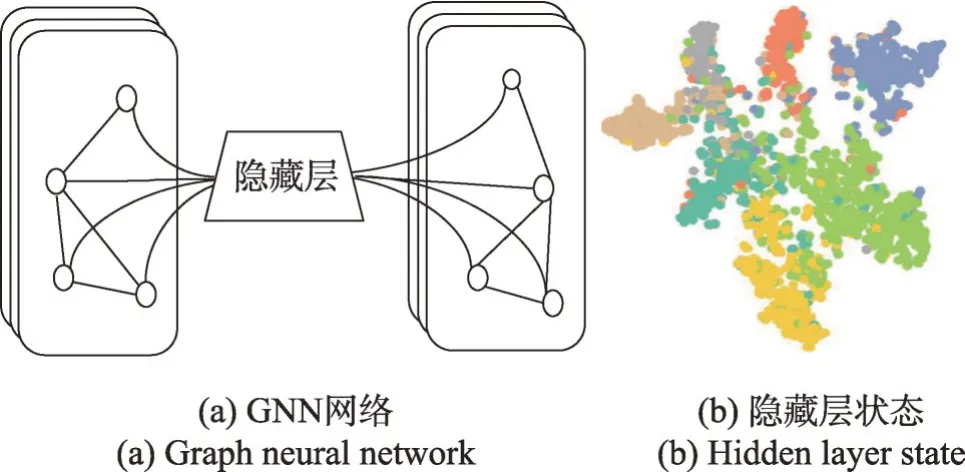
图2 GNN网络及隐藏层数据形式Fig.2 Data form of GNN network and hidden layer
2 基于图神经网络的知识图谱构建
2.1 信息抽取
信息抽取的关键在于从结构化和非结构化的数据中抽取出结构化的实体及关系信息,为查询、组织和数据分析开辟新途径[53],是知识图谱构建过程中重要的一环,信息抽取在知识图谱中主要包含实体、关系和属性信息的抽取等,在实体抽取和属性抽取方面,图神经网络的研究相对较少,因此信息抽取方面主要侧重于关系抽取的研究。
2.1.1 实体抽取
实体抽取在知识图谱中指从原始语料库中自动识别出命名实体,因为实体是知识图谱处理的最基本的元素,所以实体抽取的准确性将直接关系到后续知识库的质量,对学习知识图谱起到关键性的作用。实体抽取的方法可以归纳为三种:(1)基于规则的方法,该方法的特点是在限定的语义和文本邻域的条件下进行,在定义好的规则下抽取出实体信息,但是该方法大量依赖专家的经验,很难适应各种变化数据的新要求;(2)基于统计学习的实体抽取方法[54-55],将命名实体识别问题视为序列标注问题,使用部分标注或完全标注的语义信息进行训练;(3)基于深度学习的方法[56-57],深度学习对于复杂非线性问题具有较好的拟合能力,能够学习到复杂的特征。
目前在实体抽取方面,图神经网络研究较少,传统的基于深度学习和机器学习的方法,在实体抽取方面已经取得了很好的效果,图神经网络尚在发展阶段,相信不久的将来图神经网络在实体抽取方面也会有相应的探索。
2.1.2 关系抽取
关系抽取经典的方法是基于依赖树的方法挖掘语义信息,关系抽取从抽取类型来看,可以分为基于句子级别的关系抽取和基于文档级别的关系抽取。C-GCN[58]是一种新颖的基于上下文的图卷积网络的方法用于关系抽取,有效地将信息汇集在任意依赖树中的关系结构上。如图3所示,使用一种新颖的以路径为中心的剪枝技术,在最大限度保留相关内容的同时,从树中删除无关的信息,提高建模的鲁棒性,实体之间的依赖关系用粗体表示,通过使用以路径为中心的剪枝技术,使用图卷积网络进行关系提取,在不忽略关键信息的基础上删除无关信息。同样基于依赖树的另一种方法为Guo 等人提出的AGGCN(attention guided graph convolutional networks for relation extraction)[59],以完整的依赖树作为输入,采用注意力机制用一种软加权策略来自动学习如何选择有助于关系提取任务的句子,这种方法充分利用有用的信息,忽略无用的信息,但是破坏了原始依赖树的结构信息。为解决这个问题,Sun等人提出LSTAGGCN[60],在不破坏原始依赖树结构的基础上,利用注意力机制聚合分类任务中不同传播层次的最终表示,图中的节点和边缘将得到不同的权值,同样也能够实现有效信息的有效利用,忽略无用信息。Bastos等人提出RECON(relation extraction using knowledge graph context)[61]新方法,使用图神经网络学习存储在知识图谱中的句子和事实的表示,该方法可以自动识别句子中的关系并对齐到知识图谱中。上述研究大多存在依赖树的噪声,特别是当依赖树自动生成时。A-GCN(attentive graph convolutional networks)[62]基于图卷积网络的注意机制考虑到单词之间的依赖关系类型及重要的上下文指导,有助于关系的提取。
以上模型都是基于句子级别的关系抽取,实现更加完备的知识理解需要多个句子实现句子间的关系捕获,文献[63]提出了面向边缘的图神经网络模型,实现文档级别关系的提取,实体之间的关系使用节点之间路径形成的唯一的边来表示。GCNN(genetic convolutional neural network)[64]、GLRE(globalto-local neural networks for document-level relation extraction)[65]、dialog-HGAT(dialogue relation extraction with document-level heterogeneous graph attention networks)[66]模型侧重于模型优化和实体集上下文的细粒度实现对文档的语义信息的使用,进行关系抽取。上述方法大多不考虑对文档级别图的推理,图聚合推理网络(graph aggregation-and-inference network,GAIN)[67],使用一种新的路径推理机制来推断实体之间的关系,异构的MG(mention-level graph),它带有一个基于图的神经网络,用于对文档中不同提及之间的交互进行建模,并提供文档感知提及表示,实验表明,该增益模型具有良好的性能,不仅能够准确识别关系抽取,还能提高知识图谱的可解释性。同样,KRST[66]也通过引入关系路径覆盖和关系路径置信度的概念,在模型训练前过滤不可靠路径,以提高模型性能。
通过上述对关系抽取研究,如表3 所示,可以通过挖掘句子之间和句子之间的关系路径来实现关系抽取,来提高知识抽取的可解释性和充分发挥图神经网络挖掘图结构信息的优势。

表3 关系抽取模型Table 3 Relational extraction model
2.2 知识合并及加工
2.2.1 链接预测
尽管在创建和维护上投入了大量努力,但大多数现有的知识图谱还是不完整的,从而导致下游任务执行时性能略差。为了避免这种情况,需要对知识图谱进行链接预测,也称为知识库完成,根据给定的事实推断缺失的事实,如图4 所示,为知识图谱链接预测的通用流程。通过输入原始知识图谱,图神经网络作为编码器[70],生成实体及关系级别的知识嵌入,最后使用不同的解码器实现链接预测,目前几乎所有主流的基于图神经网络的链接预测模型都遵循图4所示的编码器-解码器架构。现将链接预测模型大致分为四类,具体如表4 和表5 所示,对各个模型的特点及其优缺点进行介绍,并列举了各个模型用到的信息。
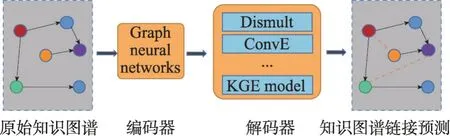
图4 链接预测通用模型框架Fig.4 Common model framework for link prediction
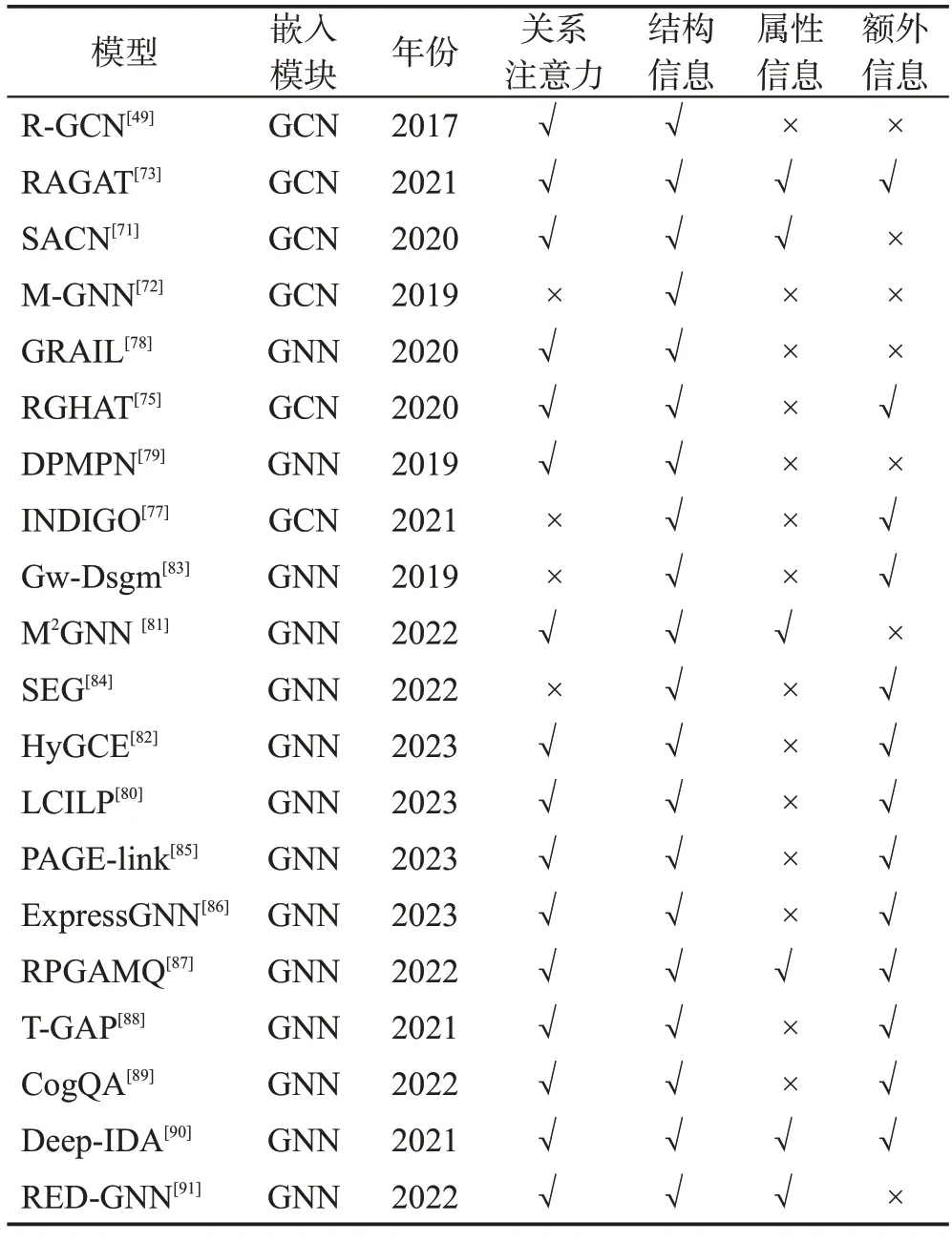
表5 链接预测模型关键信息Table 5 Link prediction model key information
(1)基于卷积神经网络模型。R-GCN(relational graph convolutional networks)[49]用图神经网络实现链接预测任务的模型,如图5 所示,显示的知识图谱表示中单个节点信息更新的过程,从相邻的蓝色收集信息,聚合更新到红色节点的表示中,通过下游任务不断迭代更新,直到节点向量达到不动点,在知识图表示学习之后使用DisMult 解码器为图中每个潜在的边生成可能性评分,最终挑选出最具可能性的边的预测。虽然R-GCN 模型有效聚合了邻域信息,实现信息的迭代加强,但是该模型也存在一些不足,比如:①平等地对待邻域中不同的实体;②表征能力低、叠加平直和对噪声的鲁棒性差;③不涉及向量化的关系嵌入。针对第一个问题,Shang 提出了SACN(structure-aware convolutional networks)模型[71],相较于R-GCN 在相同关系的实体聚合上引入了加权GCN 来对相邻实体之间的关系进行定义,核心思想是利用节点的结构和属性信息,以及关系类型捕获知识图谱中的结构信息,最终传入解码器来进行链接预测任务;针对第二个问题,Wang 等人提出了MGNN(multi-level structures graph neural network)模型[72],该模型对于不同的关系拥有不同的权重,邻域聚合时引入多层感知机(multilayer perceptron,MLP)弥补R-GCN 表征能力低、叠加平直和对噪声的鲁棒性差的问题,对图上的多个GNN进行堆叠,对原始图的多层次结构进行建模;针对第三个问题,Liu等人提出了RAGAT(relation aware graph attention network)[73],引入了关系特定网络参数,来自适应地研究不同关系下相邻实体的消息,从而弥补了R-GCN 网络可扩展性差的问题。
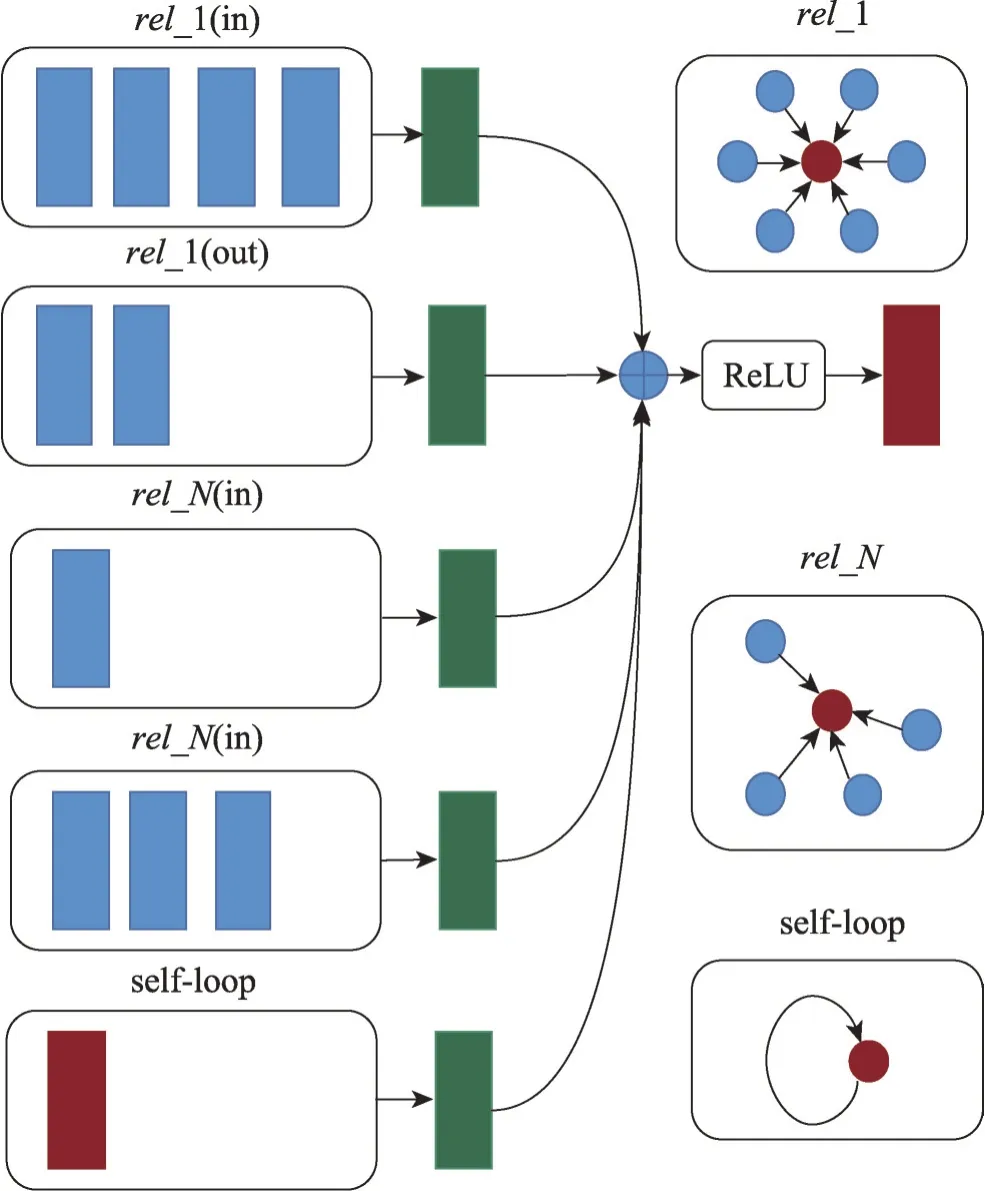
图5 关系图神经网络模型Fig.5 Relational graph neural network model
(2)基于图注意力网络模型。Luo 等人提出的RGHAT(relational graph neural network)模型[75],引入了实体和关系级别的注意力机制,强调了不同相邻实体在同一关系下的重要性,即在同一关系下,不同的实体也拥有不同的权重信息。分层注意力机制,使得该模型更为有效地利用邻域信息,但是相应的算法复杂度也会增大。在此基础上,HRAN(hierarchical recurrent attention network)模型[76]针对知识图谱中不同的关系拥有不同重要性,使用新颖的注意力聚合机制,获得不同关系路径的重要性。和上述模型不同的是,它能够捕获各种类型的语义信息,并且可以有选择性地对特征信息进行有效的聚合,在链路预测任务上实现了鲁棒性的效果。Liu等人提出INDIGO(inductive knowledge graph completion)模型[77],KG以透明的方式完全编码为GNN,并且预测的三元组可以直接从GNN 的最后一层读出,而无需额外的组件或评分函数。通过图注意力网络,让知识图谱的实体通过多次迭代聚合操作,更高效地使知识图谱上所有不同距离的实体通过边互相分享其带有的信息,辅助完成预测推理工作。
(3)基于子图提取模型。通常三元组的预测依赖于其常量在输入KG中的独立邻域,但没有考虑到这些邻域的共同部分是什么,因此提出了构造局部子图的方法。Teru 等人提出GraIL(graph inductive relation)模型[78],通过提取两个节点周围的封闭子图结构来预测两个节点之间的关系,并以类似于RGCN 的方式对其进行编码,并使用评分函数对其专用子图中所有节点的输出向量进行全局应用,从而对这个三元组进行预测。Xu 等人提出DPMPN(dynamically pruned message passing network)[79],通过修改给定查询的不相关实体来构造局部子图,对GNN模型做的预测提供一些解释,而不是将GNN视为一个黑盒子,在这些子图中,可以对每个节点使用注意力权值进行差分着色,从而可以看到哪些节点对于预测是重要的。GraIL[78]模型不需要经过训练的嵌入就可以对子图做归纳式推理,这就使得对于未知节点也可以使用图结构进行打分,但是在子图抽取和子图标签中复杂度较高,不适合在大规模图中应用。针对这个问题,Zhang 等人提出RED-GNN(relational digraph graph neural network)模型[91],结合基于路径方法的可解释性和基于子图结构的保留特性的优点,使用递归和并行计算的方法,使GNN可以一次性建模多个关系子图,在聚合方面是基于实体之间的关系进行消息聚合。他们首先根据k跳邻域,使用图神经网络(GNN)对子图进行编码,然后学习映射子图结构模式以链接存在的函数。尽管这些方法取得了巨大的成功,但通常会导致邻域呈指数级别的扩展,从而由于过度平滑而降低GNN 表现力。基于此问题,LCILP(locality-aware subgraphs for inductive link prediction)[80]模型将子图提取表述为一种局部聚类过程,旨在基于个性化PageRank 方法对目标链接周围紧密相关的子图进行采样。
(4)基于曲率空间模型。Wang 等人提出的混合曲率多关系图神经网络(metapath and multi-interest aggregated graph neural network,M2GNN)[81],将知识图谱嵌入到双曲空间中,而非传统的欧几里德空间中,便于捕获层次结构。传统的嵌入欧几里德空间的方法忽略了知识图谱的异质性,无法捕捉知识图谱的结构。M2GNN将多关系知识图谱嵌入到混合曲率知识空间,来模拟各种结构。缺点是混合曲率空间曲率需手动定义固定曲率,需要邻域外的知识和额外的数据分析,如果无法定义到准确的曲率空间就无法准确捕捉知识图谱的结构。为了解决这个问题,将该混合曲率设置为可以训练的参数,以便更好地捕捉知识图谱的底层结构,使用了图神经网络的更新器,可以更好地捕捉知识图谱的底层结构。Wang 等人[82]提出了双曲空间图注意力网络模型(hyperbolic graph attention network for reasoning over knowledge graphs,HyGGE),使得限制性能的复杂关系在该模型的基础上得到提升。一方面,对邻域结构和关系特征的关注弥补了嵌入空间完全由三元组单独诱导的奇异性,从而优化了嵌入空间的表达能力;另一方面,它们配合双曲几何的作用,捕获局部结构中包含的层次特征,从而使双曲嵌入的优势得到更充分的发挥。
2.2.2 知识推理
知识推理[83]在某种程度上可以看作链接预测的一种,和链接预测不同的是,它是在已有的数据的基础上,利用特定的方法来推断新的关系或者识别错误的信息,以解决知识图谱不完备的问题。知识推理可以通过引入马尔可夫逻辑网络和路径机制来提高知识推理的可解释性和鲁棒性。
Zhang 等人提出ExpressGNN 模型[86],首次将马尔可夫逻辑网络引入到图神经网络中,将概率逻辑与图神经网络结合起来,从而实现应用少量数据实现更高的性能,马尔可夫逻辑网络不需要对目标任务使用很多标记。而对于大规模知识图谱推理任务,DPMPN[79]包含两个遵循消息传递神经网络框架的模块,其中一个基于全局的消息传播,另一个基于局部的信息传播,能有效聚合知识图谱的邻域信息,缓解规模问题带来的推理效果的影响。
现有的知识推理可以利用关系路径增强推理效果及可解释性。Lin 等人提出基于图的关系推理模型(KagNet)[26],该模型使用GCN 更新知识图谱中的实体表示后,利用长短记忆网络为候选路径打分,从而选出最佳推理路径。由于数据标注成本过高,对于监督信号的缺乏成为了重大挑战,可以通过KGQA(knowledge graph question answer)模型[87]实现将多条知识图谱问答转换为知识图谱中的路径生成任务。Jung等人提出了T-GAP(time-aware knowledge graph completion)模型[88],其编码器和解码器最大限度地利用时间信息和图结构。T-GAP 通过关注每个事件与查询时间之间的时间位移来编码TKG(timeaware knowledge graph)的特定查询子结构,并通过在图中传播注意力来执行基于路径的推理,有效应对知识图谱的动态特性和可解释性。Acheampong等人提出CogQA(cognitive graph QA)模型[89],使用BERT(bidirectional encoder representation from transformers)输出的若干片段构建一个知识图谱,并利用图神经网络的消息传播机制,实现认知图谱的多跳计算。Deep-IDA(deep predicting isoform-disease associations)[90]通过结合基于路径的算法支持基于嵌入的方法。首次将传统的路径搜索算法与深度神经网络相结合进行KG推理。Zhang等人提出RED-GNN[91]方法,利用动态规划的方法对多个具有共享边信息的有向图进行递归编码,用查询注意力机制选择强相关的边,同时学习到的权重信息可以为知识图谱的推理任务提供可解释性证据。
2.2.3 实体对齐
实体对齐也可称为实体匹配或者实体链接,用于发现不同知识图谱中指代的具有同一事物的实体,是知识图谱中知识融合的关键技术。传统的知识图谱对齐技术、基于关系推理和基于相似度计算的方法等,忽略了知识图谱的结构特性,基于图神经网络的实体对齐模型,利用图神经网络来学习知识图谱不同实体的低维向量表示。和传统的基于相似度的方法相比,基于嵌入的方法进行实体对齐任务,解决了需要大量专家的参与或者由其他用户贡献外部资源的问题,无需人工设计相似度特征即可实现实体对齐,表6 为基于图神经网络的实体对齐模型,对它们注意力机制对象和应用的信息进行了详细的描述。
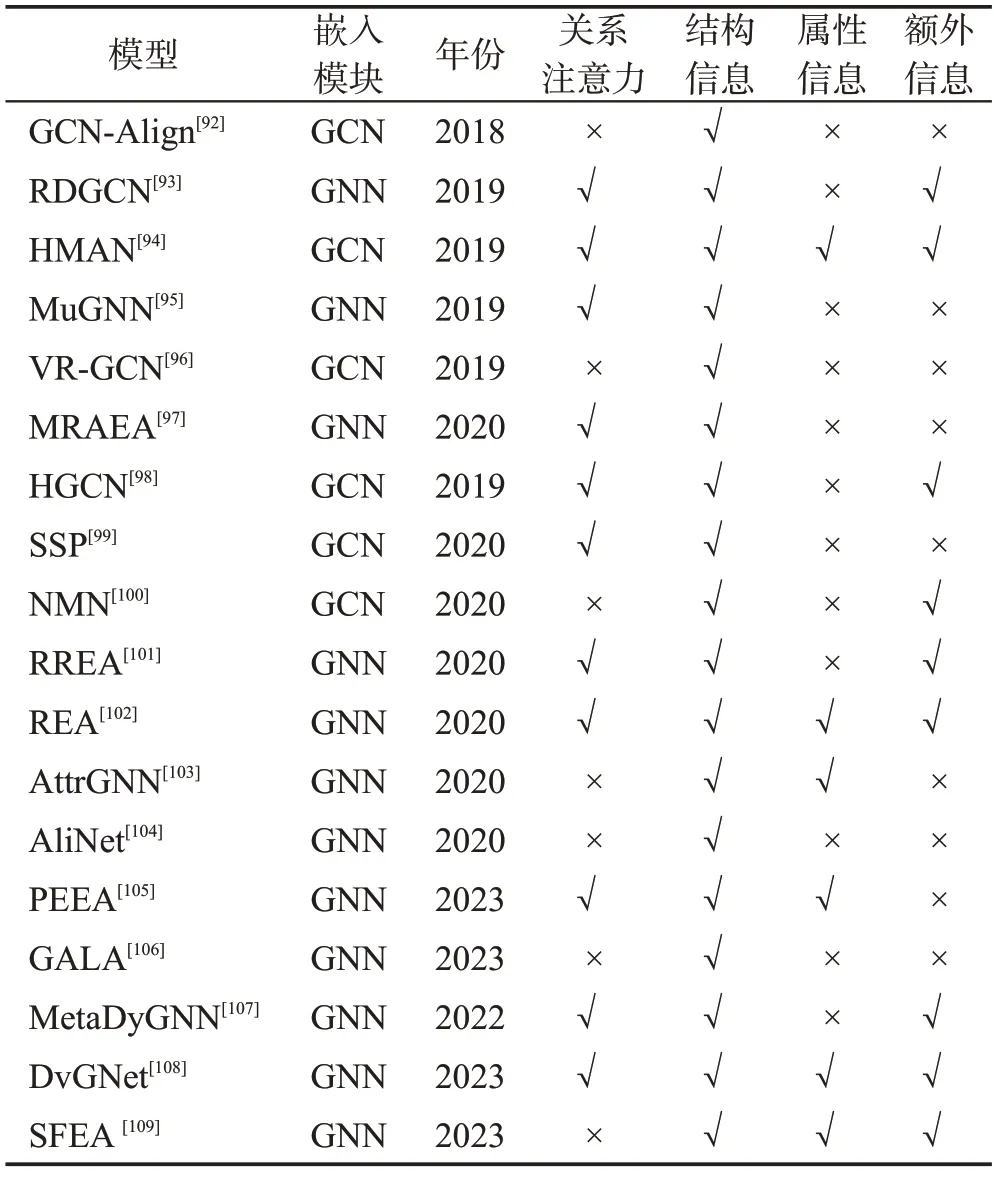
表6 实体对齐模型关键信息Table 6 Entity alignment model key information
(1)图卷积网络模型
图卷积网络模型通过递归聚合邻居节点的特征来表征实体,优点是能获得全面、鲁棒的实体表示。最早使用图神经网络进行实体对齐的是Wang 等人提出的GCN-Align[92],如图6(a)所示。通过多层GCN将实体和属性的信息嵌入低维向量,等效实体期望尽可能接近,同时允许编码不同知识图谱的两个GCN 模型使用相同的参数,利用实体之间的结构传播实体之间的对齐关系。但是该模型只考虑节点级别的实体对齐,无法对异构数据图进行建模并利用知识图谱中丰富的关系信息。针对这种情况,Wu等人提出了RDGCN(region-enhanced deep graph convolutional networks)模型[93],通过GCN来实现实体的嵌入,并建立知识图谱的对偶关系图,将关系视为节点,实体视为边,通过对偶图的约束增强对不同实体网络结构的判别,极大增加了知识图谱的效率。Wu等人提出HGCN(hierarchical graph convolution networks)[98],不仅考虑到了异构关系的嵌入,还考虑到聚合邻居节点时可能存在的噪声问题,通过增加Highway Gate 控制噪声在GCN 结构中的传播,使用实体表示来近似关系表示,从而优化关系对齐的目标。和前几个模型相似,还有两个模型也考虑到了实体关系属性的建模,分别是Yang 等人提出的HMAN(hybrid multi-aspect alignment networks)[94],使用一个GCN和两个全连接网络分别对知识图的拓扑结构、关系特征和属性特征进行编码,同时将训练前模型BERT 纳入框架,进一步提高模型效果。Wu 等人提出的NMN(neighborhood matching network)模型[100]通过同时考虑拓扑结构和邻域相似性来估计两个实体的相似性,在使用GCN 嵌入的同时采用跨图注意力机制设计了一个近邻匹配模块来获取邻域实体之间的差异,以解决知识图谱中普遍存在的邻域异质性。

图6 实体对齐模型Fig.6 Entity alignment model
在聚合邻域信息的同时,会考虑到邻域多跳邻域的信息可否被利用。Sun 等人提出AliNet(alignment network)模型[104],使用一个全局结构和局部语义保持网络,以粗到细的方式学习实体表示,通过引入远端邻居的注意机制来扩大其邻域结构的重叠,并限制等效实体对的两个实体在每个GCN层中具有相同的隐藏状态,最后使用关系损失来细化实体表示。聚合信息时,AliNet[104]视一个实体的所有单跳邻居同等重要,但并不是所有的单跳邻居都对目标实体的特征化有积极的贡献。因此如果不仔细选择,会引入噪声,从而降低性能。上文提出的NMN模型[100]避免了该问题,使用部分预先对齐的实体作为训练数据,选择信息最丰富的邻居进行实体对齐,极大提高了实体对齐的效果。同样的想法,如图6(b)所示,Nie等人提出SSP(global structure and local semanticspreserved embeddings)[99],互补地利用全局结构和局部语义来学习鲁棒和准确的实体表示,全局结构和局部语义可以为实体对齐提供互补的信息:全局结构可以为实体表示提供全面和健壮的信息,而局部语义可以提供细粒度的细节来细化粗粒度的实体表示。
在图卷积网络模型进行实体对齐时,通过考虑邻域信息来聚合实体及关系的特征,同时,会考虑到单跳和多跳邻域信息来实现高效的特征聚合过程,提高实体对齐的效率。
(2)图注意力网络模型
①从注意力机制角度考虑。图注意力网络通过对边缘赋予不同的权重信息,如图7 所示,来实现对有用信息的高效处理。Ye 等人提出AVR-GCN(a vectorized relational graph convolutional network)模型[96],采用不同于传统GAT的邻域特征融合方法,与TransE模型一样,实体的不同邻居通过添加(或减去)不同的关系向量来合并和表示,从而更直接地将邻域关系引入模型中。Mao 等人提出MRAEA(meta relation aware entity alignment)[97],采用不同于AVRGCN 的方法,在图神经网络的框架下考虑实体之间的关系,将关系划分为若干元关系,学习彼此之间的注意参数,并将其集成到实体表示中,最后对模型进行半监督训练。Cao 等人提出多通道图神经网络模型MuGNN(multi-channel graph neural network)[95],在GNN 模型的基础上,使用多个通道稳健地编码两个知识图谱,在每个通道中添加自注意力机制和图交叉知识图谱注意力机制,采用图池化操作对二者进行彻底集成,该模型发现了知识图谱矩阵的结构不完备性,并针对基于规则的KG矩阵完备性进行了研究。Zhu等人提出了NAEA(neighborhood-aware attentional representation)模型[110],该模型合并了实体的邻域子图级信息,通过图注意力网络捕获邻域级信息。上述模型中,MuGNN[95]、NAEA[110]和MRAEA[97]根据实体之间的关系类型赋予不同的权重系数,使模型能够区分不同实体之间的重要性。NAEA 同时考虑了单跳邻居对齐,并使用GAT 对实体之间的结构信息进行编码,从而提升实体对齐的效率。

图7 实体对齐模型SSPFig.7 Entity alignment model SSP
②从数据集偏差的角度考虑。许多先进的KG嵌入模型都有一个共同的思想,将实体嵌入转化为特定关系的嵌入。Mao等人提出RREA(relational reflection entity alignment)模型[101],指出它们的变换矩阵很难符合正交性质,这就是它们在实体对齐方面表现不佳的根本原因。RREA 模型采用一种称为关系反射的新转换操作来满足实体对齐的理想转换操作的两个关键标准:关系分化和维度等距,提高实体对齐的准确性。Liu 等人提出AttrGNN(attributes graph neural network)模型[103],集成属性和关系三元组,采用不同的重要性,以获得更好的性能,该模型可以有效地缓解严重的数据集偏差,取得显著的改进效果。
③从噪声的角度考虑。Pei等人提出REA(robust entity alignment)模型[102],使用GNN 嵌入,假设人工标记的对齐实体对在真实的实体对齐任务中可能有噪声,噪声检测模块采用生成式对抗网络来达到降噪的目的。Chen 等人提出SS-AGA(self-supervised adaptive graph alignment)模型[111],将对齐实体视为一种新的边缘类型,引入关系感知的图注意力机制来控制知识传播和噪声影响,并使用新的具有自我监督的对齐生成机制来缓解种子对齐的稀缺性。
2.2.4 实体消歧
实体消歧不同于实体对齐,实体消歧需要将文本内容中提及的实体链接到文本内容中所提到的实体,实体对齐是将两个多结构化的知识图谱或知识图谱中的实体进行等价对齐。知识图谱利用图神经网络(GNN)进行实体消歧,能更好地实现对图结构数据的特征表示。Hu 等人提出GNED(graph neural entity disambiguation)模型[112],是一种端到端的利用图神经网络进行实体消歧的模型,充分利用全局语义信息通过为每个文档建立一个异构实体单词图,来模拟同一文档中候选实体之间的全局语义关系,将图卷积神经网络用于实体子图上来生成编码全局语义的增强型实体嵌入,最终送入CRF(conditional random field)中进行实体消歧。Li 等人针对现有的实体消歧中存在信息利用不充分、准确率低等特点,提出一种基于常用实体关系图的实体消歧方法,通过路径长度和个数实现连接强度和阈值的比较,最终实现实体消歧[113]。为应对互联网中内容模式的增加,提出MMGraph(multi-modal graph convolution network)模型,使用多模态图卷积网络来聚合上下文语言信息,加上自监督的三元组网络,在多模态无标签数据中学习知识表示,来进行实体消歧,为后续语义网建模提供了思路。
2.3 数据集分析
本节将全面介绍在图神经网络参与知识图谱构建任务中使用的数据集,因为在设计关系提取模型之前需要确定该数据集。本文总共调查了7 个数据集,并统计了7 个常用的关系提取数据集的细节,如表7所示。本节还介绍了数据集的局限性。

表7 知识图谱常用数据集Table 7 Common datasets of knowledge graph
(1)WN18RR:WordNet 18(简称WN18)是一个英语词汇数据库,包含大量的单词、同义词和词汇间的语义关系。WN18RR 是对WN18 数据集的重新划分。
(2)NELL-955:NELL(never-ending language learner)是一个自动化的知识抽取系统,旨在从互联网上自动学习知识。NELL-955是从NELL中提取出来的一个小型知识图谱数据集,其中实体涵盖了人、组织机构、地点和其他类型。
(3)FB15K-237:Freebase 15(简称FB15K)是一个基于Freebase 知识图谱数据集的链接预测任务数据集。FB15K-237 是对FB15K 数据集的重新划分,它只保留那些出现次数大于等于50 次的关系,并将其数量从1 345 个减少到237 个,便于模型更好地学习和推理。
(4)WN18:WN18 是一个英语词汇数据库,包含大量的单词、同义词和词汇间的语义关系。WordNet中的单词被组织成一个层次结构,其中每个单词都与其他单词之间存在不同类型的关系。WN18 是一个用于链接预测任务的基准数据集,其中包含有40 943个实体和93 003个三元组。
(5)FB15K:FB15K 是一个基于Freebase 知识图谱数据集的链接预测任务数据集。FB15K是一个用于链接预测任务的基准数据集,其中包含有14 951个实体和592 213个三元组。
(6)YOGO3-10[114]:YOGO3-10 是一个日本语言的知识图谱数据集,包括人物、地点和组织机构等。该数据集可以用于实现文本到知识图谱的实体链接任务。
(7)DBP15K[4]:DBP15K 是南京大学提出的,用于跨语言实体对齐数据集,其中包含ZH-EN、JA-EN、FR-EN三种跨语言实体对齐的语料库。
这些数据集都是非常有价值的资源,它们可以用于支持各种类型的知识图谱构建任务,并且可以帮助机器理解自然语言文本中的含义。现有的通用领域数据集并不适用于所有的知识图谱构建研究工作,只适用于一些方法研究。关于垂直领域知识图谱的构建需要用到领域知识图谱数据集,具有行业特殊性,无法一一列举。下面列举了现有的图神经网络应用于知识图谱构建中常见的数据集会存在的问题:
(1)数据集噪声:知识图谱数据集中可能包含错误和不一致的实体和关系标注。这些错误可能会对模型的性能产生负面影响[83,98,102,111]。
(2)数据集分布:知识图谱中的实体和关系并不是平均分布的,可能存在一些关系样本非常稀少的情况,这可能导致模型对这些关系的学习效果较差[101]。
(3)特征选择:特征工程在知识图谱中的关系预测任务中起着至关重要的作用。如果选择的特征不足或者不合适,可能会导致性能较差[77,82,94]。
(4)算法选择:不同的算法对于不同的数据集通常具有不同的表现。可能有一些算法在某些数据集上表现不佳,但在其他数据集上表现良好[13]。
(5)数据不平衡性:知识图谱中的实体和关系通常是不平衡的,即某些实体和关系比其他实体和关系更常见。这种不平衡性会导致图神经网络在处理知识图谱时出现偏差或误差等问题。
这些问题都会对图神经网络在知识图谱构建任务中的应用产生影响,因此需要采取一些有效的方法来解决这些问题,例如使用更加鲁棒的模型、采用更加有效的数据预处理方法等。
3 基于图神经网络的知识图谱应用
3.1 推荐系统
图神经网络和知识图谱的结合在下游有很多应用,具体见表8,列举了知识图谱常见的应用。推荐系统是互联网发现潜在用户兴趣的必要工具,来自知识图谱的信息需要聚合项目之间的相关性来进行推荐,GNN 的主要特征之一是能够在生成的密集表示中保留邻居之间的结构属性,通常这一操作称为平滑,在存在同质图时特别需要平滑。推荐系统中知识图谱的构建分为四步:(1)收集用户信息;(2)收集购买物品信息;(3)提取用户和物品属性特征;(4)构建知识图谱,将用户和物品进行相关性连接,属性被提取为实体连接到用户和项目。输入的知识图谱为协同知识图谱,协同知识图谱由用户和项目组成的二部图和项目的附加信息组成的知识图谱结合组成。
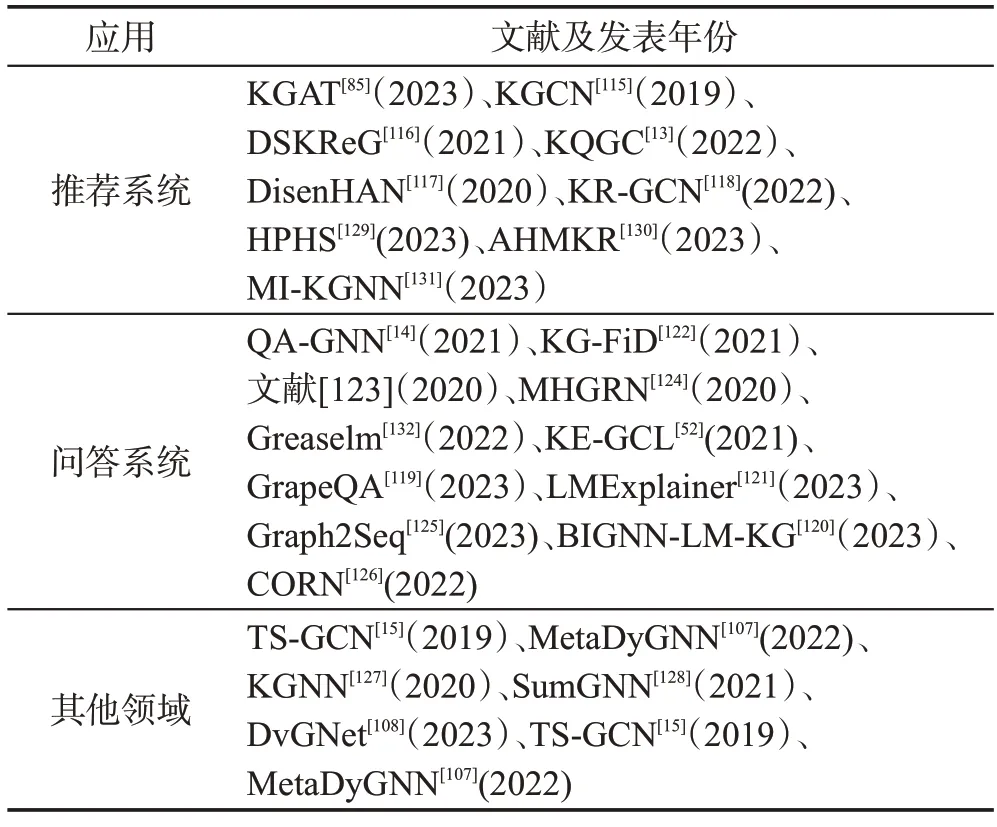
表8 知识图谱应用相关文献Table 8 Literature related to application of knowledge graph
基于图神经网络的知识图谱推荐系统不同点在于嵌入操作采用的方式不同。Zhang等人提出KGAT(knowledge graph attention network)模型[85],如图8(a)所示,由知识图谱嵌入和图神经网络两层组成,将GNN 层应用到TransR 中获得知识图谱嵌入基础上,生成节点嵌入。推荐系统具体操作流程为:(1)嵌入层,通过保留协同知识图谱的结构将每个节点参数化为向量;(2)注意力嵌入传播层,递归地从节点的邻居传播嵌入以更新其表示,并采用知识感知注意力机制来学习传播过程中每个邻居的权重;(3)预测层,聚合来自所有传播层的用户和项目的表示,并输出预测的匹配分数。
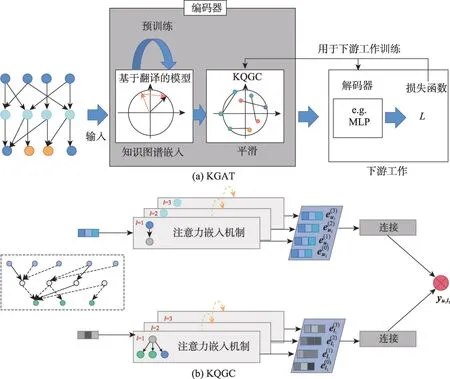
图8 推荐系统模型Fig.8 Recommendation system model
Wang等人提出KGCN(knowledge graph convolutional network)[115]是采用图神经网络聚合知识图谱中的实体的开创性项目之一,通过基于感知的注意力图神经网络层在知识图谱中生成实体和关系的嵌入。Wang 等人提出DSKReG(differentiable sampling on knowledge graph for recommendation with relational GNN)模型[116],使用关系图神经网络在知识图谱上进行推荐的可微分抽样,从知识图谱中需学习连接项目的相关性分布,并使用该分布对合适的项目进行推荐,设计可区分的抽样策略使项目在选择和模型训练过程共同优化。以往的知识图谱嵌入忽略了图神经网络出现的平滑性问题,基于此,Kikuta 等人提出基于知识查询的图卷积KQGC(knowledge querybased graph convolution)[13]模型,如图8(b)所示,利用图卷积网络的平滑效果增强知识图谱嵌入。Wang等人提出DisenHAN(disentangled heterogeneous graph attention network for recommendation)模型[117],为编码用户和项目之间的协作信号,利用嵌入传播来显式地合并具有丰富语义结构的上下文信息。利用元关系分解中的高阶连通性,并提出一个解纠缠的嵌入传播层,分别聚合用户和项目的语义信息的不同方面,自动生成具有语义信息的元路径。Ma等人[118]设计了基于图卷积网络的知识感知推理方法,使用一种基于过渡的方法来确定三元组得分,并利用核抽样在每个用户-商品对之间的路径内自适应地选择三元组,为了提高推荐性能和保证解释的多样性,将用户-物品交互和知识图谱集成到异构图中,通过图卷积网络实现,采用路径层面的自我注意机制,区分不同选择路径的贡献,预测交互概率,提高最终解释的相关性。
3.2 问答系统
知识图谱最早在自然语言基础上构建发展起来,知识图谱在自然语言处理上有着大量的应用,比如知识问答等任务。常识性问题旨在回答哪些需要背景知识的问题,而这些知识在问题中并没有明确表达出来,需要从外部知识中获取证据,并在证据基础上进行预测。
知识图谱问答目的是利用知识图谱中的事实来回答自然语言的问题,它帮助终端用户在不了解知识图谱数据结构的情况下,更有效、更容易地访问KG中的大量和有价值的知识。
通过结合预训练模型和KG 实现智能问答。Yasunaga 等人提出QA-GNN(question answering-GNN)模型[14],如图9所示,该模型利用预训练的语言模型及知识图谱的端到端的问答系统模型,在给定的问答系统上下文的条件下来计算知识图谱节点的相关性,并在问答系统的上下文和知识图谱节点上进行联合推理,通过图神经网络的消息传递机制公共更新它们的表示。同样的方法Taunk 等人[119]提出了GrapeQA 模型,结合预训练模型和知识图谱的推理能力,通过识别问答系统中的相关文本块和预训练语言模型中的相应潜在表示增强知识图谱,以及在上下文感知节点修剪和删除与问答系统不相关的节点。Yang等人[120]提出了一种基于双模态图神经网络的外部知识推理的视觉问答方法。视觉问答是指通过计算机视觉和自然语言处理技术,让计算机能够回答与图像相关的问题。通过双模态图神经网络处理图像和文本数据,根据已有的信息和规则,推出新的结论或答案,这种方法的目的是让计算机能够利用外部知识进行推理,提高视觉问答的准确性和可靠性。
针对大型语言模型(large lauguage models,LM)的解释问题,虽然这些模型可以处理不同种类的自然语言处理(natural language processing,NLP)任务,但由于其多层非线性模型结构和数百万个参数,结果的解释可能很困难。Chen等人利用注意力权重来提供模型预测的解释。然而纯基于注意力的解释无法支持模型日益复杂的情况,并且不能推理其决策过程,因此提出LMExplainer[121](知识增强的解释模块),使用知识图谱(KG)和图注意力神经网络来提取LM的关键决策信号。
结合注意力机制实现问答系统。Yu 等人提出KG-FiD(knowledge graph in fusion-in-decoder)[122],解决了开放邻域问答的任务,在融合译码器框架的基础上,应用图神经网络计算排序得分。Lv 等人[123]提出从异构的知识来源中自动获取证据,并提出两个模块。首先利用图结构重新定义单词之间的距离,后续采用图卷积网络将邻居信息编码为节点的最终表示形式,利用图注意力机制聚合证据预测最终的答案。
将智能问答从单个KG三元组中生成问题,转换为从一个更复杂的KG 子图中生成问题。Feng 等人提出了一个多跳图关系网络(MHGRN)[124],从外部知识图中提取子图执行多跳、多关系推理任务,该模块将基于推理的方法和基于图神经网络的方法结合,具有比较好的扩展性和可解释性。Chen等人[125]采用了双向图到序列(Graph2Seq)模型来编码KG 子图,以更好地保留KG子图的显式结构信息。同时,该模型还使用了节点级别的复制机制,允许将KG子图中的节点属性直接复制到输出问题中。Guan等人[126]采用基于Co-Attention Transformer 的双向多级连接结构。该结构建立了桥梁,连接了文本编码器和图编码器的每一层,可以将QA 实体关系从KG 引入到文本编码器,并将上下文文本信息带到图编码器,以便深度交互融合这些特征以形成综合的文本和图节点表示,并提出了一种QA 感知节点的KG 子图构建方法,QA感知节点聚合了问题实体节点和答案实体节点,并进一步指导子图的扩展和构建过程,以增强连通性并减少噪声的引入。上述考虑子图级别的注意力机制能够充分利用知识图谱中的子图结构信息进行特征融合。
3.3 其他领域
图神经网络应用于知识图谱研究除了上述常见的推荐系统和智能问答外,还可以在药物预测、社交网络中使用。有的研究需要用到特定领域数据集实现知识图谱的成功应用。如图10 所示,通过知识图谱进行关系预测,得到关系网络中缺失的实体及关系信息。对药物之间的相互作用可以建模为基于知识图谱的链接预测问题,使用基于图神经网络嵌入的方式用于知识图谱的药物发现,预测的步骤分为以下三个步骤:(1)从数据源中提取数据,输入三元组实体-关系数据和药物之间的相互作用矩阵;(2)在嵌入过程中,使用各种结构的模型来学习知识图谱的表示,使用特定的打分函数和损失函数来进行训练;(3)通过识别三元组是否为给定的事实来实现药物预 测。KGNN(knowledge graph neural network)[127]、MGAN(meta-path guided graph attention network)[108]和SumGNN(knowledge summarization graph neural network)[128]等模型使用图神经网络挖掘药物及其潜在领域知识图谱中的关联关系,其过程本质上类似于知识图谱的链接预测,通过捕获多跳邻域的相关子图,并使用图神经网络进行消息融合,有效地捕获药物及其潜在邻域的相关性,实现对药物性能的预测,实现药物预测和药物的再利用。上述应用表明图神经网络同知识图谱构建相结合,挖掘领域知识图谱中潜在的关联关系,可以是社交网络关系、药物关联关系、商品关联关系、问答系统中的语义关系等。

图10 知识问答流程Fig.10 Question and answer process
4 总结与展望
4.1 总结
知识图谱是一种图结构,用来建模事物之间的联系,针对知识图谱构建存在的问题,提出了使用GNN 的方法解决相应的问题,主要关注四类图神经网络参与知识图谱构建的问题,具体包括:链接预测、知识图谱对齐、实体消歧和知识推理等。在了解相应的模型细节和这些策略之后,本文对基于GNN的知识图谱的应用方面进行了阐述,主要包括推荐系统、知识问答、计算机视觉和药物关系预测等。虽然图神经网络应用于知识图谱已经取得了上述发展,但仍面临以下挑战,具体如表9所示。
(1)图神经网络可解释性
现有的解释大多基于实例分析和实现的效果推理得到,图神经网络尝试从基于梯度、扰动、代理和分解等角度对黑盒问题进行解释,在知识图谱上应用图神经网络也有基于逻辑推理的方法尝试提高深度学习的可解释性,可解释性依旧是未来持续研究的方向。现有的研究通过引入额外信息来增加可解释性,比如文献[109]提出了减少基于文本信息的同构-多深度联合实体对齐的需求模型,利用实体的名称信息和属性信息,同时将实体对齐问题转化为分配问题,大大提高了模型的可解释性。还有一些文献[79,88,129]引入路径机制或者规则,用于缓解知识图谱的可解释性问题[130],但是由于可解释性仍然是深度学习的黑盒子,仍旧需要不断探索。
(2)知识图谱的动态特性
知识图谱的构建是一个不断更新迭代的过程,现有的知识图谱是相对静态的,大多数知识图谱是动态实时变化的,动态图神经网络已经成为当前发展的主要趋势,利用图时空网络研究动态图是未来的发展方向,近有研究从元学习框架新模型(dynamic graph neural network,MetaDyGNN)[107]出发,用动态网络中的少镜头进行链接预测提出了动态图神经网络模型(dynamic graph neural network,DGNN)处理动态图问题。Jung等人提出了T-GAP模型[88],其编码器和解码器最大限度地利用时间信息和图结构,TGAP通过关注每个事件与查询时间之间的时间位移来编码TKG 的特定查询子结构,并通过在图中传播注意力来执行基于路径的推理,有效应对知识图谱的动态特性。Gao 等人通过TS-GCN(two-stream graph convolutional networks)[15]模式实现零镜头动作识别,巧妙实现了动作识别预测。动态图神经网络研究将成为未来不断研究的热点之一。
(3)标记数据的依赖
垂直领域知识图谱对准确数据有严格的要求,希望能够克服对标记数据的依赖,缓解数据稀疏的问题,这将是未来领域知识图谱的一个发展方向。例如:在实体对齐任务中,通过将位置信息整合到具有位置注意力层的表示学习中来增强远处实体与标记实体之间的联系,并提出一种弱监督学习框架来增强实体对齐[105],缓解缺乏标记数据而导致的性能瓶颈。MI-KGNN(multi-dimension user-item interactions with attentional knowledge graph neural networks)[131]可以有效地捕获和表示知识图谱中的结构信息(即交互的拓扑结构)和语义信息(即交互的权重),缓解数据稀疏的问题。对数据的依赖性可以通过修改模型来进行,采用无监督或弱监督学习的方式,学习现有的有限数据信息。如何解决样本不足或缺失问题,是未来一个充满前景的方向。
(4)知识图谱结构异质性
KG 之间的结构异质性[132]严重阻碍了实体对齐的发展,现有研究主要从实体邻域异质性的角度缓解结构异质性,而忽略了关系异质性对其的重要作用。基于此,可以采用基于门控机制DvGNet的双视图神经网络(GNN)[108],从实体和关系交互的角度全面缓解KG的结构异质性。MuGNN[95]提出了一种多通道图神经网络框架,并利用规则生成三元组来补充KG,从而缓解实体的邻域异质性,并利用邻域聚类来应对实体邻域异质性。并将实体对齐视为最大二分匹配问题,由匈牙利算法解决;AliNet[104]通过使用门控策略和注意力机制聚合多跳邻域来缓解实体的邻域异构性。关系异质性也是KG 结构异质性的重要原因。此外,一些研究,如KDCoE(co-training embeddings of knowledge graphs and entity descriptions)[133]和AttrE(attribute embeddings)[134]在学习实体嵌入的过程中加入了实体的其他配置文件信息,缓解结构异质性。但知识图谱的异质性仍然是长期存在的问题,需要不断研究。表9总结了现如今存在的问题及其解决方案。
4.2 展望
(1)GNN模型的可扩展性
GNN(图神经网络)模型长期存在可扩展性问题,在处理大规模图数据时,虽然许多新的技术和算法已被开发用于提高GNN 模型的可扩展性,但是仍然存在一些问题导致GNN模型的可扩展性较差。首先是图的规模,GNN 模型需要处理大规模的节点和边实体,会导致内存消耗和复杂度等问题;其次是许多GNN 模型在设计时考虑了特定类型的图数据,可能不太适合处理其他类型的数据(例如:现有的GNN模型主要用于处理自然语言处理数据,但对于医疗数据、地震解释数据,还未能挖掘到有效的处理方法),为了提高GNN的可扩展性,需要考虑这些因素,并寻找相应的解决方案。
(2)图神经网络的工业应用
现有的图神经网络的研究大多基于理论上公开数据集,没有应用于大规模的实际应用领域,例如地质构造建模、航空航天、金融领域等,很少使用图神经网络进行处理,领域知识图谱对数据的准确性要求很高,需要得到准确的结果,但图神经网络的泛化能力仍有待提升,最终实现工业落地并发挥图神经网络处理像知识图谱这样图结构的数据,仍旧需要不断研究。
(3)知识图谱的工业落地
现如今对知识图谱的需求呈现爆炸式增长,但是对于领域知识图谱的构建仍然存在一些局限性。首先是知识图谱的用处,通过各个深度学习的方法构建的知识图谱能否应用于垂直领域,会不会存在花费大量人力、物力构建知识图谱的问题,因为深度学习的不可解释性和不确定性,导致无法满足实际工程的需求。以及会不会存在知识图谱交叉的问题,构建的多个领域知识图谱在很大程度上是重合的,从而造成了资源浪费。由于图神经网络仍然是个黑盒子,使用图神经网络构建的知识图谱仍旧无法在工业上落地。
猜你喜欢
少先队活动(2020年12期)2021-01-14
吉林大学学报(理学版)(2020年3期)2020-05-29
中国外汇(2019年18期)2019-11-25
自动化学报(2018年7期)2018-08-20
哲学评论(2017年1期)2017-07-31
中成药(2017年3期)2017-05-17
领导决策信息(2017年9期)2017-05-04
领导决策信息(2017年9期)2017-05-04
周口师范学院学报(2016年5期)2016-10-17
领导科学论坛(2016年9期)2016-06-05
