
斑马鱼肌肉Smyd1a蛋白生物信息学分析
2023-10-25 08:23杨明勇麦晓雯张在宝刘慧娟李红敬
信阳师范学院学报(自然科学版) 2023年4期
杨明勇, 麦晓雯,张在宝,刘慧娟*,李红敬
(1. 信阳师范大学 a. 体育学院; b. 生命科学学院, 河南 信阳 464000; 2. 琼台师范学院 a. 理学院; b. 热带生物多样性与资源利用实验室, 海南 海口 571127)
0 引言
生物信息学是一门集数学、信息、生物学和计算机为一体的新兴学科。随着人类基因组计划的启动,大量的蛋白序列、结构、功能的数据被生成出来。面对如此巨大的数据,一定要运用生物信息学技术对这些数据展开处理,生物信息技术已经成为蛋白质组学研究中不可或缺的工具。组蛋白赖氨酸甲基转移酶(Smyd)是一类在动物骨骼肌和心脏发育中发挥关键调控功能的蛋白,它是一类由Smyd1、Smyd2、Smyd3、Smyd4、Smyd5等组成的蛋白家族[1-2]。Smyd1有3种异构体,其中Smyd1a是一种在肌肉组织中表达的组蛋白甲基化酶,对肌肉纤维的形成具有关键作用[3]。通过对Smyd1a蛋白的生物信息分析,能够对其结构和功能进行快速的预测,从而为研究Smyd1a蛋白的生理功能提供理论依据。
1995年,HWANG等[4]在细胞毒性T淋巴细胞和胸腺细胞中发现了Smyd1,也称肌肉特异Bop基因。Smyd1具有H3K4组蛋白甲基转移酶活性,对于肌细胞分化和成熟至关重要,是小鼠心肌细胞分化和斑马鱼肌生成必不可少的关键转录因子[5]。研究表明,Smyd1通过不同的方式能剪切成Smyd1a和Smyd1b,斑马鱼中Smyd1a和Smyd1b具有相似的生物学活性[6-7]。而Smyd1b在快肌中的功能已发现,但其慢肌中的功能以及Smyd1a的功能总体上仍不能确定。通过对Smyd1a蛋白生物信息学分析,有助于今后对基因组进行动态的生物学功能研究。本文首先采用生物信息学的方法分析出Smyd1a的氨基酸序列,然后使用各种线上软件来分析Smyd1a的基本结构特征及理化性质,并完成适应性的进化分析。
1 材料与方法
1.1 获取Smyd1a蛋白序列
登录美国国家生物信息技术中心(National Center for Biotechnology Information,NCBI)主页(National Center for Biotechnology Information (nih.gov)),在“All Databases”对话框栏中输入Smyd1a,单击Search检索。数据库选中78条记录,点击“Proteins-Protein”进入数据库,其中第一位,登录号为QBB20354.1的记录是符合要求的记录,单击进入显示相关信息。单击右上角的“Send to”下拉菜单选择“File/FASTA”选项,将该蛋白序列(sequence.fasta)进行本地下载,并将序列保存在sequence.txt文件中。
1.2 测定Smyd1a的理化性质
通过瑞士生物信息学研究所的蛋白分析专家系统(Expert Protein Analysis Systerm,ExPASY,https://web.expasy.org/protparam/)所提供的蛋白质组学和序列分析工具,测定Smyd1a蛋白的分子量、等电点、氨基酸组成、摩尔消光系数、脂肪系数和总平均亲水性等理化性质。使用ProtScale程序(https://web.expasy.org/protscale/)预测Smyd1a的亲疏水性。利用在线工具SignalP-5.0(SignalP-5.0-Services-DTU Health Tech)预测Smyd1a的蛋白质信号肽。利用TMHMM服务器(TMHMM-2.0-Services-DTU Health Tech)预测跨膜区结构域。利用波兰Network Protein Sequence Analysis(NPS@ SOPMA secondary structure prediction results (ibcp.fr))预测Smyd1a的蛋白质的二级结构。运用Swiss-modelWorkspace(SWISS-MODEL Interactive Workspace (expasy.org))对其蛋白质的空间构想建模。
1.3 构建Smyd1a蛋白系统发育树
进入Pfam(Pfam: Home page (xfam.org))主页,从“SEQUENCE SEARCH”栏中粘贴Smyd1a的蛋白序列,得到该蛋白质的PFAM domain为SET,其Pfam号为PF00856,将其记录下来,并对该蛋白质进行信息了解。通过使用Multiple Em for Motif Elicitation(MEME-Submission form (meme-suite.org))线上软件来预测Smyd1a的motif模型。
为了研究Smyd1a与不同种属家族的关系,登录NCBI的主页(National Center for Biotechnology Information (nih.gov)),在右边找到“BLAST”点击进入页面,然后点击“Protein BLAST”,进入后点击选择文件,选择1.1中下载的蛋白序列文件,然后下划单击“BLAST”,搜索出产生显著比对的序列,选择达到97%以上的序列进行下载,至少选择5个序列,下载完成后。打开文件,将前面的核酸序列复制到该文件所有序列的前面,并将该文件的格式从“txt”改成“fasta”。然后直接打开该文件,进入MEGA7.0选择“Align”后,单击“Alignment”选择“Align by Musle”,点击OK,对不同来源的序列进行对齐序列,将对齐后的序列保存下来。然后打开对齐的序列,点击“Phylogeny”中的“Construct/Test Neighbor-Joining tree”,得到NJ(neighbor-joining)进化树。
2 结果
2.1 Smyd1a蛋白信息
从NBCI数据库主页(National Center for Biotechnology Information (nih.gov))中Protein数据库中检索得到Smyd1a的蛋白质序列文件。结果如图1。

图1 Smyd1a蛋白的序列Fig. 1 Protein sequences of Smyd1a
2.2 Smyd1a蛋白理化性质
Smyd1a蛋白的氨基酸数量是489个,其分子式是C2468H3856N700O731S42,分子量是56 376.54 Da,理论等电点是6.27。Smyd1a蛋白不稳定系数是40.31,标准的蛋白的不稳定参数值在40以下,推测出Smyd1a蛋白的稳定性一般。含有负电荷残基数为68,正电荷残基数为60,脂肪族氨基酸指数是73.99,疏水性评估系数为-0.467。Smyd1a蛋白中谷氨酸(Glu)含量最高,为8.4%;其次是亮氨酸(Leu)和丙氨酸(Ala),分别为8.0%和7.0%。
2.3 Smyd1a蛋白结构分析
精氨酸是Smyd1a蛋白亲水性最大的氨基酸(图2),分值是-2.6;异亮氨酸是疏水性最大的氨基酸(图2),分值是1.8。从Smyd1a蛋白亲疏水性物性图2看出,疏水性氨基酸少,亲水性氨基酸多,确定Smyd1a蛋白是亲水性蛋白。

图2 Smyd1a氨基酸的亲疏水特性Fig. 2 Hydrophilic/hydrophobic profile of Smyd1a amino acid
从图3可以看出,利用 SignalP-5.0软件对Smyd1a的信号多肽进行了预测,但结果是没有任何信号多肽,也没有给出其剪切位点,提示Smyd1a不是一种分泌性蛋白。

图3 Smyd1a多肽的预测Fig. 3 Prediction of Smyd1a SIGNAL peptide
跨膜区一般为α-螺旋型,也有部分为β-折叠型,含有20~25个疏水性氨基酸[4]。利用TMHMM服务器对Smyd1a蛋白进行跨膜区预测,结果如图4所示。由图4可知,Smyd1a不存在跨膜结构域。
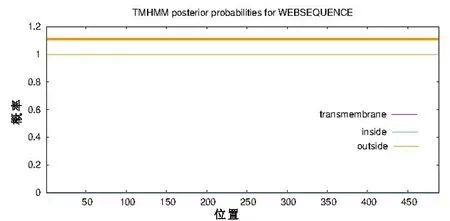
图4 对Smyd1a跨膜区域的预测Fig. 4 Predicted results of the Smyd1a transmembrane region
2.4 Smyd1a蛋白的二级结构分析
如图5所示。Smyd1a蛋白二级结构包括57.26%的α-螺旋、10.63%的β-折叠、4.09%的β-转角以及28.02%的无规则卷曲等构象。

图5 Smyd1a蛋白二级结构预测结果Fig. 5 Smyd1a secondary structure prediction results
2.5 Smyd1a蛋白的三维结构构建
蛋白质结构的理论预测方法都是建立在氨基酸的一级结构决定高级结构的理论基础上的,蛋白质三维结构的预测方法通常有两种:同源性建模和从头开始的预测方法。通过同源建模的方法,利用Expasy中的SWISS-MODEL的在线软件预测了Smyd1a蛋白的三维结构,三维结构如图6所示,由图6可知无规则卷曲占主要部分。
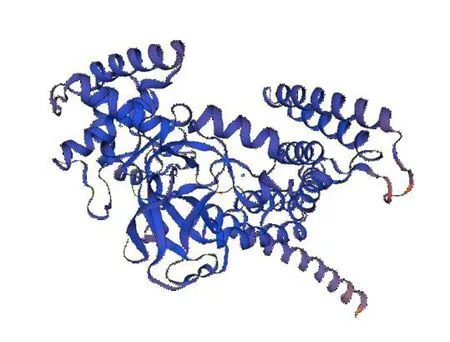
图6 Smyd1a蛋白的三维结构模型Fig. 6 Three-dimensional structure model of Smyd1a
2.6 Smyd1a蛋白系统发生树
从Pfam中知,Smyd1a蛋白的PFAM domain为SET(如图7所示),其Pfam号为PF00856。在动植物中广泛存在着一种含有 SET结构域的蛋白质,其高度保守的组蛋白甲基化酶(Su (var)3-9, Zeste Enhancer (E (z)), trithorax (tx)3-9)。在MEME线上软件预测Motif模型如图8所示,由图可知,这3个序列e值都小于10,所示的基序的位置p值小于 0.000 1。

图7 Smyd1a蛋白的结构域Fig. 7 Domains of the Smyd1a protein

图8 Smyd1a的3个物种的motif模型Fig. 8 Motif model of the three species of Smyd1a
为了研究Smyd1a与不同种之间的关系,通过使用NCBI数据库进行检测,下载与Smyd1a同源性高的不同种属蛋白质序列,并用MEGA7.0进行比对,得到的比对结果如图9所示。然后通过邻接式来构建Smyd1a的系统进化树,结果如图10所示。结果显示:该基因与XP_034452872.1相近。

图9 Smyd1a蛋白进行序列比对的结果Fig. 9 Results of the sequence alignment of the Smyd1a proteins

注:射水鱼:XP_040899085.1;大西洋庸鲽:XP_034452872.1;翘嘴鳜:XP_044053772.1;鱼:XP_029366828.1;眼斑双锯鱼:XP_023133434.1
3 结论
Smyd1作为组蛋白甲基转移酶,在肌原纤维的形成中起着重要的作用,是肌肉收缩所必需的。斑马鱼胚胎有Smyd1a和Smyd1b等3种蛋白,Smyd1a和Smyd1b在肌原纤维的组装中有相似的生物学活性,Smyd1b对于肌原纤维的组装是必不可少的[8]。SET是Smyd1蛋白赖氨酸甲基转移酶活性的结构域,在进化过程中非常保守,但是它与组蛋白修饰有着密切的关系[9-10]。
通过生物信息学分析和预测马鱼Smyd1a蛋白序列和结构,可以为人类Smyd1a蛋白的研究提供依据,为后续进行的Smyd1a相关功能的研究打下重要的理论基础。同时,Smyd1a蛋白在动物体内是如何发挥作用,这些作用又与哪些基因和蛋白有关,还需进一步研究。
猜你喜欢
现代畜牧科技(2021年4期)2021-07-21
中国洗涤用品工业(2019年4期)2019-05-11
广州大学学报(自然科学版)(2019年1期)2019-05-07
中国博物馆(2018年2期)2018-12-05
中成药(2018年1期)2018-02-02
天津科技大学学报(2016年1期)2016-02-28
湖北师范大学学报(自然科学版)(2015年2期)2016-01-10
动物医学进展(2015年10期)2015-12-07
现代检验医学杂志(2015年4期)2015-02-06
现代检验医学杂志(2015年2期)2015-02-06
