
基于图对比学习的长文本分类模型
2023-10-25 10:35:44刘宇昊严灵毓叶志伟
湖北工业大学学报 2023年5期
刘宇昊, 高 榕, 严灵毓, 叶志伟
(湖北工业大学计算机学院, 湖北 武汉 430068)
自然语言处理(natural language processing,NLP)一直是人工智能领域最重要的方向之一,文本分类[1]则是NLP领域最基本的任务,其是指通过一定的计算,得出当前文本属于某一类别的概率的过程,其运用于情感分析[2]、信息检索[3]、问答系统[4]、机器翻译[5]等非常具有实际意义的应用。例如日常生活中的内容推荐、搜索引擎、自动客服、翻译软件等就是以上应用的具体体现。可以说NLP技术正潜移默化地方便我们的生活。
文本的嵌入表示是文本分类任务的基础,嵌入表示的好坏决定了文本分类任务的质量。传统上的嵌入表示有针对目标数据集计算的词袋模型和n-gram模型[6],但由于其数据稀疏性需要大量计算资源,同时忽视文本的顺序和结构信息,所以在大多数情况下对文本的语义表达并不准确。后来谷歌推出了word2vec[7],word2vec考虑了词在上下文的关系,效果[8]与通用性有显著提升。然而word2vec是静态的方法,单词与向量是一对一的关系,无法解决一词多义问题,但此时word2vec已初具预训练模型的雏形。之后因计算机硬件的发展,研究人员着手使用大语料库训练出通用模型。2018年,谷歌使用双向的Transformer[9]在33亿字的无标注语料库上训练出BERT[10],不仅解决了一词多义的问题,同时使自监督模型的预训练加微调模式成了各个领域的热点。后来,对比学习[11]的出现,让自监督学习发展到新的高度,由于其“轻便”的结构拥有很好的泛化性,在计算机视觉、NLP、多模态中都有应用。在NLP的背景下,对比学习可以让模型针对特定领域进行自监督训练。例如金融、法律等专业领域有标注的数据集非常少,如果使用人工标注则需要付出高昂的经济代价。应用对比学习不仅可以降低经济成本,还能缓解针对特定领域准确度不高的问题。
上述工作取得了一定的成果,然而当前工作还存在以下挑战。问题1:以往大多基于字符序列的工作忽略了文本的高级结构,并且受制于文本长度。如BERT模型,由于自注意力机制需要n×n的计算矩阵(n为文本长度),所以默认只能处理512个字符内的文本。对于过长的文本会将不同句子化作同一句子并且截断[12],但这显然会导致文本的语义丢失甚至改变。问题2:对比学习在正负对选取上存在采样偏差问题。文本背景下,数据增广操作可能会改变文本的语义标签,因此增广策略需要先验知识。在负对采样[13]上,由于自监督学习没有标签信息,来自不同实例的增广对有一定概率具有相同的标签,这时将其视为负对就会导致负采样偏差。
当前基于图对比学习的长文本分类模型[14],通常把文本随机分为两部分,将来自同一文本的子文本视作正对,来自不同文本的子文本视为负对,再以句子或段落为节点,将它们的顺序关系作为边来构建图模型,接着进行对比学习后再分类。然而,文本分割的比例与分割方式需要大量的实验来确定,同时由于数据增强的方式单一,以及负采样偏差的问题,对比学习的提升效果有限。本文提出一种基于自适应视图生成器和负采样优化的图对比学习长文本分类模型(Graph Contrast Learning model based on Adaptive View Generator and Negative Sampling Optimization,GCL-AVGNSO),可以让段落节点自适应的选择数据增强方式,不仅增加了数据增强的手段,优化了不同文本的不同分割比例,同时也缓解了负采样偏差对图对比学习的影响。首先基于图模型构建文本,不仅可以捕捉句子的上下文关系,也能扩展到长文本。接着利用自适应视图生成器进行数据增广,能让文本自适应地选择划分比例。然后引入PU Learning[15]的知识,在仅访问全样本分布和正样本分布的情况下,用超参数π对负采样偏差进行修正。最后本文在两个公开中文数据集上证明了有效性,效果优于主流先进模型。
1 GCL-AVGNSO模型
GCL-AVGNSO流程见图1。
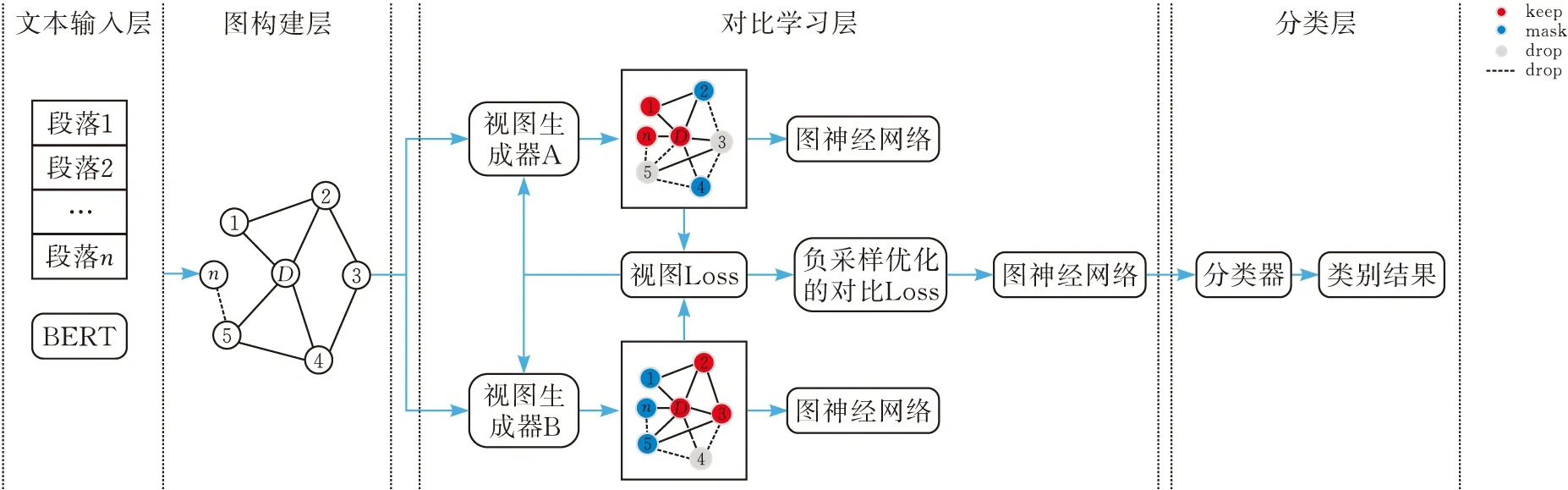
图1 GCL-AVGNSO模型流程
1.1 问题定义
将长文本D映射为图G,再将图G映射到低维空间得到G。设D={p1,p2,…,pn,p|D|},pi为文章中的段落,每个段落对应图的节点,上下文的顺序关系对应顶点间的边,所有的段落节点都与文本节点p|D|有边。设图G=(V,E),其中V={v1,v2,…,vN},E⊆V×V分别表示节点集和边集。V∈RN×F,A∈{0,1}N×N分别为特征矩阵和邻接矩阵。vi∈RF是vi的特征向量,如果(vi,vj)∈E则令邻接矩阵中的Aij=1。本文的目标是学习一个GNN编码器f(V,A)∈RN×F′,其中F>F′,N×F′≥G,将一组文本D映射成G={G1,G2,…,GM}后,在没有标签信息的情况下利用GNN编码器将G嵌入到低维空间中得到图级别表示G={G1,G2,…,GM},这些图级别表示可以用线性分类器进行分类。
1.2 文本图构建
给定一个文本D={p1,p2,…,pn,p|D|},定义一个无向图G=(V,E),其中V由n+1个节点(vpD,vp1,…,vpn)组成,图的边集E根据文本结构分别从段落节点和文本节点展开构造。
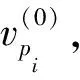
其中B(pi)为Bert-WWM。
1.2.2文本节点初始化在获得所有节点表示后,使用所有段落节点的平均值作为文本节点的初始表示:
1.3 GNN层
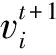
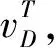
在获得所有节点的最终表示后,通过READOUT函数得到文本的图级别表示Gi。
1.4 自适应视图生成器和负采样偏差修正
在图对比学习中,会通过数据增广(Data Augment)来扩充数据样本,对于每个图G,有:
(1)
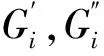
1.4.1自适应视图生成器自适应视图生成器流程见图2。
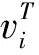
G′=(V′,E′)
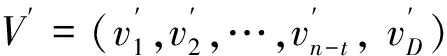
simview(x,y)=mse_loss(x,y)
Lossview=1-simview(Amat,Amat′)
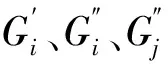
则对于所有样本f的损失期望为:
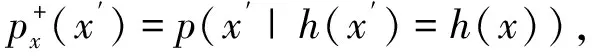
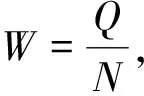
由于现实情况下,自监督的图对比学习只能获得不带标签的数据,以及由锚点样本增广而产生的增广样本,后者可视为正样本空间而前者并不能完全视为负样本空间,所以这里需要引入PU learning的知识。在无偏PU learning(uPU learning)[19]中,可访问一个正的样本空间χ+,和无标注的样本空间χ,即:
(2)
则可以将本文中(2)的分布重写为(3),并得到负采样的表达式(4):
(3)
(4)
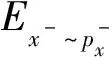
此时的全样本空间可以是整个内存库也可以是一个批次内的样本,正样本空间只有增广后的一对样本,如果将其中一个视为锚点样点,那么正样本空间只有一个样本。由此可以计算对应的损失期望:
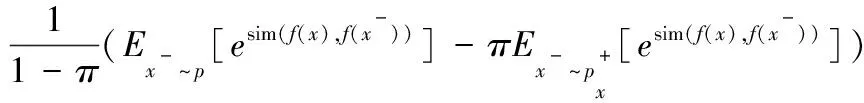
其中u为无标注的样本。由于对比学习损失函数的负对项的理论最小值为e-1,所以本文要求当上式的值小于e-1时,取e-1。出于简单考虑,设W=1,则Q=N,则最终加入温度系数T[20]后的修正损失函数为:
(5)
其中π为超参数,N为全样本空间的样本数量。则最终模型的损失函数为:
Loss=λLossview+LossCL
其中λ为损失系数,默认取1。
1.5 分类层
理想情况下,对比学习可以将样本的嵌入表示按照相似度大小,均匀地分布在一个超球面上[21],所以使用线性分类器就可以很容易地把某类与其他类分开。本文使用两层线性层来实现分类。
y1=Relu(Fullyconnected(Gi))
y2=Softmax(Fullyconnected(y1))
2 实验
2.1 数据集和数据预处理
本文在2个不同的中文数据集THUCnews[22]、SogouCS[23]上进行了实验,验证了在长文本分类上的有效性,各数据集的相关信息见表1。
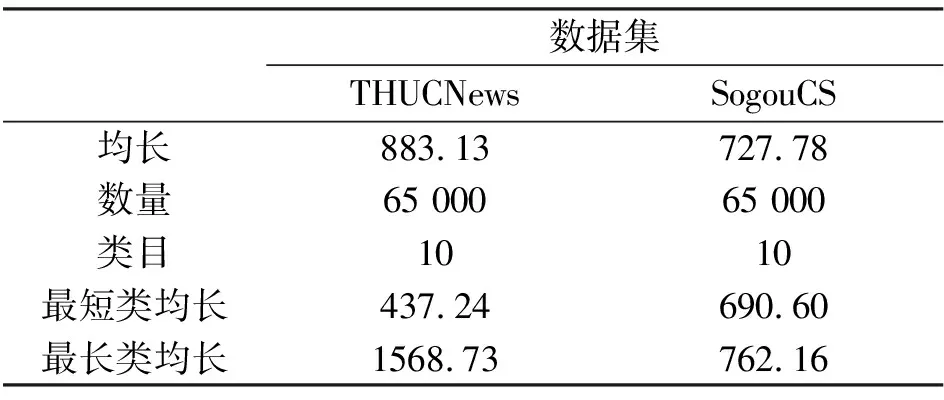
表1 数据集统计详情
THUCnews是清华大学根据新浪新闻RSS订阅频道2005到2011间的历史数据筛选而成,有14个类别共74万多条数据组成。SogouCS是来自搜狐新闻2012年6月到7月间共18个频道的新闻数据,本文以频道类别作为数据标签,对其中足够数量的类目进行筛选。选取好数据后进行数据清洗,首先依照哈工大中文停词表删除文本中大量无意义的词,再删除如网址、邮箱、电话号码等无意义但形式固定的内容。
实验里,在THUCNews中抽取65 000条长文本数据。为了兼顾一定的泛化性,本文选取文本最短长度可在400,但总平均长度大于600的数据,并在对65 000条数据进行预训练后,以5∶1∶0.5的比例划分训练集、测试集与验证集。在SogouCS中抽取65 000条长文本数据,由于部分标签数据数量不足,本文仅抽取长度大于300且平均长度大于600的数据,并在对65 000条数据进行预训练后,以5∶1∶0.5的比例划分训练集、测试集与验证集。
2.2 评估指标与参数设置
本文基于三个评估指标精确率(Precision)、召回率(Recall)和F1值(F1_Score)进行性能评估,有:
其中,FP表示被预测为正的负样本数量,FN表示被预测为负的正样本数量,TN表示被预测正确的负样本数量,TP表示被预测正确的正样本数量,P为精准率,R为召回率。
参数设置:在对比学习阶段使用两层的GAT和0.0001的学习率,32的batch和10的epoch,并且设置了多组关于温度系数T和修正系数π的实验,最终效果最好的温度系数T和修正系数π分别为0.5和0.12。在分类阶段,使用0.0001的学习率,32的batch和100的epoch。
2.3 实验设计及参数分析
本文设计了对比实验、消融实验和参数分析实验。对比实验显示本文模型优于当前主流先进模型;消融实验分析了各个模块的作用;参数分析实验得出了温度系数T和修正系数π的最优值。
2.3.1对比实验TextRCNN[24]:结合CNN与RNN的算法,通过双向的RNN获取上下文信息来学习包含语境信息的字符表示,再通过最大池化获取值最大的字符来代表整个文本的嵌入表示。
BiLSTM-Attention[25]:通过双向的LSTM获得每个字符的向量表示,再通过Attention机制对所有向量进行加权求和从而得到文本的嵌入表示。
Capsule Network[26]:将CNN中的神经元合并成一个模块记为胶囊。与传统神经网络将隐藏层数据当作标量计算不同,胶囊网络的每一步计算都是向量计算。当某个低层胶囊的输出与高层胶囊的输出方向较小甚至相反时,算法会减小这个低层胶囊对该高层胶囊的影响,在胶囊网络中这一过程被称作动态路由。输出的向量可以代表文本的特征,弥补了CNN不能理解语义关系的缺陷。
Longformer[27]:针对BERT模型仅能支持512个字符的问题而提出的可支持4096个字符的预训练模型。
BERT+NEBi-LSTM+HAN[28]:基于[29]提出的一种特征增强的非平衡Bi-LSTM模型(NEBi-LSTM)加上BERT对文本进行初步特征提取,最后用HAN从单词和句子两个方面对文本进行加权。
实验结果见图3、4。
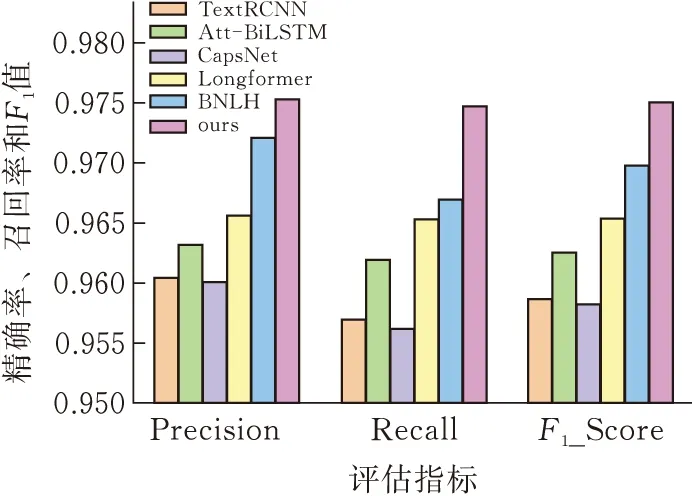
图3 THUCnews对比实验结果
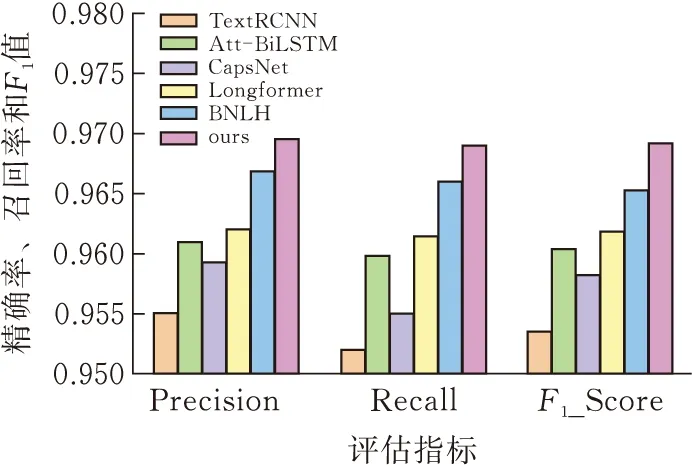
图4 SogouCS对比实验结果
实验分析:根据结果可以得出,本文提出的GCL-AVGNSO在两个数据集上均优于当前主流先进模型。原因如下:首先,文本非常适合利用高级结构来构建图模型。其次,不同的段落对于文本的贡献度不同,基于注意力机制的图模型能非常好的学习哪些段落对语义的贡献度更高。
TextRCNN:双向的RNN可以捕捉较长的语义信息,然而其存在越远的字符越会被重视的缺点,所以获得的上下文语境信息可能不准确。并且其是通过最大池化选取文本中最重要的含有语境信息的字符来表示整个文本,可以认为是通过字符来表示主题,再进行主题分类。关键在于文本中是否有可以代表文本主题的字符,并且通过最大池化的方法得到的字符是否就是目标字符,如果有一点不成立就会影响分类效果。
BiLSTM-Attention:BiLSTM已经可以较好地获取上下文的信息,并且通过注意力机制增强了文本的表示能力,实验结果也显示其好于胶囊网络。然而对于过长的文本,仍然不能很好的捕捉长距离依赖,并且通过拼接来融合前后向特征的方式不够好。对于长文本的分类任务,增加了文本结构信息的工作。
CapsNet:胶囊网络的核心路由算法与BERT的自注意力机制类似。自注意力机制通过Q、K、V三个矩阵计算出序列中其他字对当前字的权重以及加权后的向量表示,而胶囊网络通过路由权重矩阵计算所有的字符权重。相比之下,BERT的自注意力机制比胶囊网络拥有更多的权重矩阵和更深的网络结构,并且BERT经过庞大的语料库进行预训练,因此基于BERT的分段文本工作会得到比胶囊网络更好的结果。
Longformer:Longformer在长文本的语义表示上较传统模型已有很好提升,实验显示其效果差于基于BERT的分段文本工作,说明Longformer在远距离的语义表示上并不准确。
2.3.2消融实验BERT:将文本截取为510个字符再通过BERT获取文本表示。
BERT+GraphCL[30]:通过GraphCL的对比学习框架训练出一个GAT,将其作为文本的特征表示器。
BERT+view+GCL:用自适应视图生成器view代替GraphCL中的数据增强模块,训练出一个GAT作为文本的特征表示器。
BERT+Debias+GCL:优化GraphCL中负采样模块,训练出一个GAT作为文本的特征表示器。
实验结果见图5、6(中间三项省略BERT名称)。
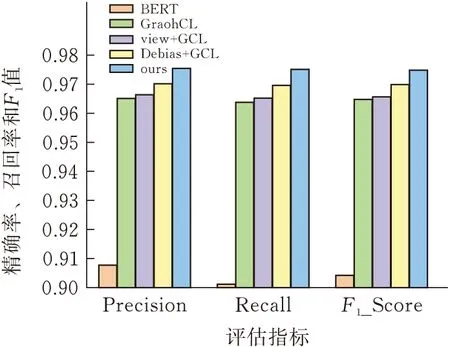
图5 THUCnews对比实验结果
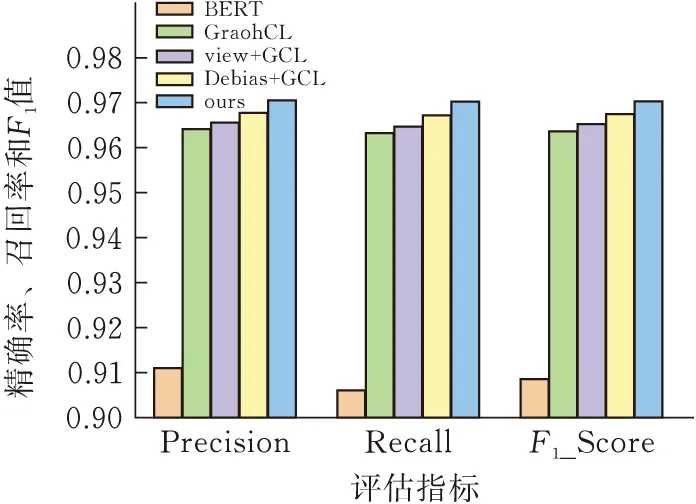
图6 SogouCS对比实验结果
根据结果可知,用GraphCL也可以得到很好的效果,但是需要大量的实验筛选出增广策略的超参数,本文并没有对其做大量的实验,所以得出中等偏上的结果是非常符合直觉的。同时用自适应视图生成器后效果略好于GraphCL,在未做大规模实验来选择数据增广策略时,用自适应视图生成器就可以得到不错的效果。接着修正负采样偏差后,效果好于GraphCL,可以认为负采样偏差确实会影响对比学习的效果。最后GCL-AVGNSO的效果达到最优,说明本文提出的两项工作在文本分类的背景下,对图对比学习有加强作用。
2.3.3参数分析实验固定温度系数T=0.5,再设置不同的修正系数π,来选择对当前数据集修正负采样偏差最好的π。固定修正系数π=0.1,再设置不同的温度系数T来选择最好的温度系数。THUCnews数据集结果见图7、9,SogouCS数据集结果见图7-10。
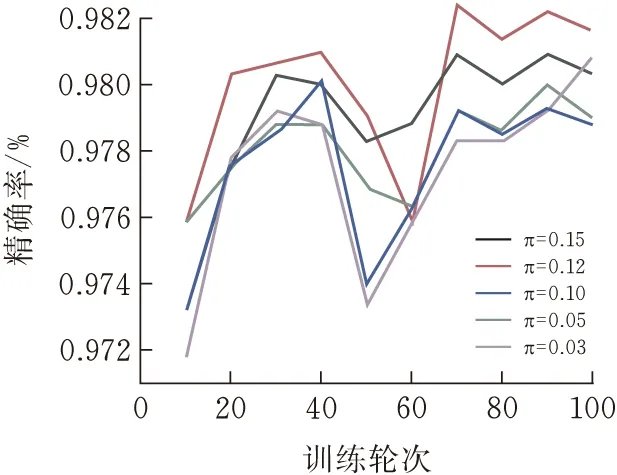
图7 THUCnewsπ实验结果
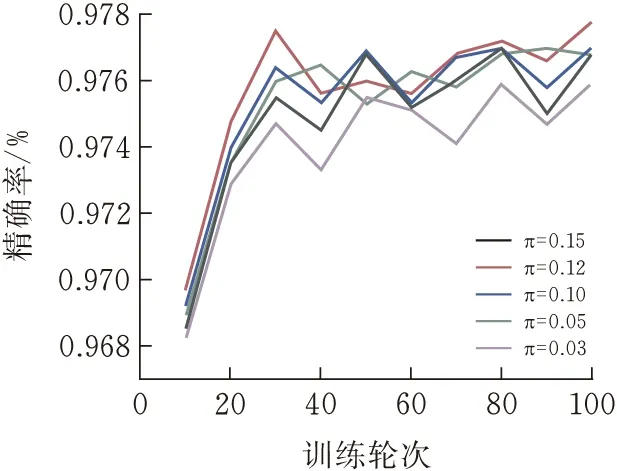
图8 SogouCSπ实验结果
从式(5)的推导显示,当所有类目中的实例数量相等时,π的理论取值为某类目的实例总数除以总数据数。对于当前THUCnews和SogouCS数据集,理论最优值均为0.1,但实验结果显示0.12为最优值,说明数据集中某些类在相似度上较为靠近。
T的取值不是越小越好,当T=0.5时能最优地区分正负样本。
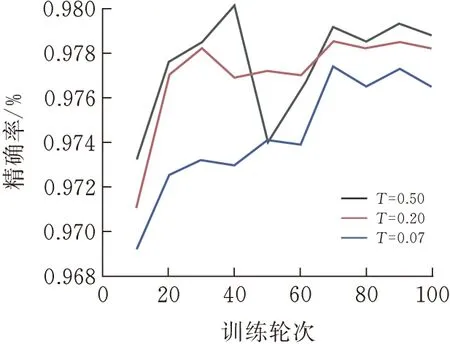
图9 THUCnewsT实验结果
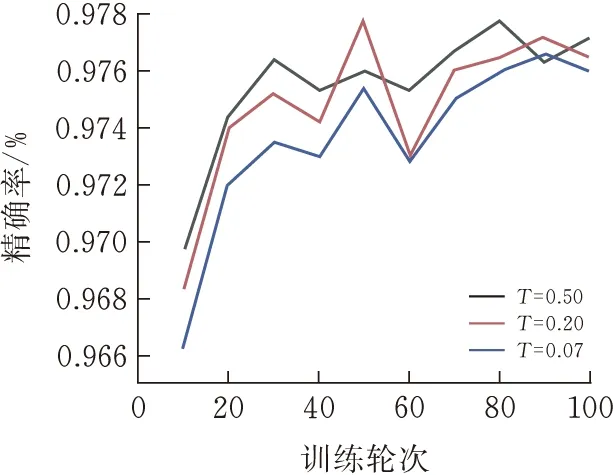
图10 SogouCST实验结果
3 结束语与展望
本文利用文本的高级结构构建图模型,通过对比学习的方法学习一个图神经网络来获得文本的嵌入表示,并在细粒度上适配任何基于Transformer的文本预训练模型。在对比学习的数据增广阶段,基于传统NLP领域数据增广中将一篇文本随机划分为两个文本的方法,引入一个自适应视图生成器,利用段落本身的属性,能在微观上让每个段落都自发地选择增广方式,同时在宏观上也实现了文本可以自发的选择划分比例。在负采样阶段,通过引入修正系数π,实现在仅访问正样本分布和全样本分布下对负采样进行修正。在两个数据集上进行实验对比,结果显示本文方法好于主流先进模型。
本文是通过引入图节点的属性来实现自适应视图生成器,相比于GraphCL而言少了对边的利用。由此在构造图的时候,如何利用段落间的关系来对边进行赋值便成了很直观的问题。如果有很好的对边赋值的方法,那么就可以让文本的图结构更加多样化,数据增广的策略也会相应变多,或许可以得到更好的效果。同时,对比学习如果训练过多会导致数据间的距离被拉得过开,如何设置停止机制也将是未来研究的重点。
猜你喜欢
Journal of Traditional Chinese Medicine(2022年5期)2022-11-16 01:54:34
Journal of Traditional Chinese Medicine(2021年6期)2021-08-09 12:36:44
小学阅读指南·低年级版(2020年9期)2020-10-12 02:43:08
阅读(快乐英语高年级)(2020年9期)2020-01-08 02:20:52
散文诗(2017年17期)2018-01-31 02:34:11
中学生数理化·中考版(2017年6期)2017-11-09 02:46:46
非公有制企业党建(2017年10期)2017-11-03 02:26:27
现代兵器(2017年4期)2017-06-02 15:59:24
现代兵器(2017年4期)2017-06-02 15:58:14
读写算(下)(2016年11期)2016-05-04 03:44:07
